
Core в видеокарте что значит
Обновлено: 06.07.2024
Думаю, для большинства пользователей это уже не секрет, но все-таки мы рассмотрим, и вникнемся за что отвечают те или иные блоки и сами гигабайты.
Начнем с основных характеристик всех видеоадаптеров.
- Ширина шины памяти , измеряется в битах — количество бит информации, передаваемой за такт. Важный параметр в производительности карты.
- объём видеопамяти , измеряется в мегабайтах — объём собственной оперативной памяти видеокарты. Больший объём далеко не всегда означает большую производительность.
- частоты ядра и памяти — измеряются в мегагерцах, чем больше, тем быстрее видеокарта будет обрабатывать информацию.
- текстурнаяипиксельнаяскорость заполнения , измеряется в млн. пикселей в секунду, показывает количество выводимой информации в единицу времени.
И перейдем к самым важным, особенно для игровых видеокарт
- Количество вычислительных (шейдерных) блоков или процессоров
- Блоки текстурирования (TMU)
- Блоки операций растеризации (ROP)
- И пожалуй тип памяти (GDDR-X или HBM-X)
Теперь немного разжуем, что это и какие задачи выполняет.
- Количество вычислительных (шейдерных) блоков или процессоров
Пожалуй, сейчас эти блоки — главные части видеочипа. Они выполняют специальные программы, известные как шейдеры. Причём, если раньше пиксельные шейдеры выполняли блоки пиксельных шейдеров, а вершинные — вершинные блоки, то с некоторого времени графические архитектуры были унифицированы, и эти универсальные вычислительные блоки стали заниматься различными расчётами: вершинными, пиксельными, геометрическими и даже универсальными вычислениями.
Впервые унифицированная архитектура была применена в видеочипе игровой консоли Microsoft Xbox 360 , этот графический процессор был разработан компанией ATI (впоследствии купленной AMD ). А в видеочипах для персональных компьютеров унифицированные шейдерные блоки появились ещё в плате NVIDIA GeForce 8800 . И с тех пор все новые видеочипы основаны на унифицированной архитектуре, которая имеет универсальный код для разных шейдерных программ (вершинных, пиксельных, геометрических и пр.), и соответствующие унифицированные процессоры могут выполнить любые программы.
По числу вычислительных блоков и их частоте можно сравнивать математическую производительность разных видеокарт. Большая часть игр сейчас ограничена производительностью исполнения пиксельных шейдеров, поэтому количество этих блоков весьма важно. К примеру, если одна модель видеокарты основана на GPU с 384 вычислительными процессорами в его составе, а другая из той же линейки имеет GPU с 192 вычислительными блоками, то при равной частоте вторая будет вдвое медленнее обрабатывать любой тип шейдеров, и в целом будет настолько же производительнее.
Эти блоки GPU работают совместно с вычислительными процессорами, ими осуществляется выборка и фильтрация текстурных и прочих данных, необходимых для построения сцены и универсальных вычислений. Число текстурных блоков в видеочипе определяет текстурную производительность — то есть скорость выборки текселей из текстур.
Хотя в последнее время больший упор делается на математические расчеты, а часть текстур заменяется процедурными, нагрузка на блоки TMU и сейчас довольно велика, так как кроме основных текстур, выборки необходимо делать и из карт нормалей и смещений, а также внеэкранных буферов рендеринга render target.
С учётом упора многих игр в том числе и в производительность блоков текстурирования, можно сказать, что количество блоков TMU и соответствующая высокая текстурная производительность также являются одними из важнейших параметров для видеочипов. Особенное влияние этот параметр оказывает на скорость рендеринга картинки при использовании анизотропной фильтрации, требующие дополнительных текстурных выборок, а также при сложных алгоритмах мягких теней и новомодных алгоритмах вроде Screen Space Ambient Occlusion.
Блоки растеризации осуществляют операции записи рассчитанных видеокартой пикселей в буферы и операции их смешивания (блендинга). Как мы уже отмечали выше, производительность блоков ROP влияет на филлрейт и это — одна из основных характеристик видеокарт всех времён. И хотя в последнее время её значение также несколько снизилось, всё ещё попадаются случаи, когда производительность приложений зависит от скорости и количества блоков ROP. Чаще всего это объясняется активным использованием фильтров постобработки и включенным антиалиасингом при высоких игровых настройках.
В бюджетных видеокартах в основном стоит GDDR3 , но и бывает GDDR5 , соответственно лучше GDDR5 , но в наше время, лучший тип памяти это - GDDR6 или HBM2 (пока слишком дорогая).
Это пусть и не самый главный, но далеко не маловажный аспект в видеопамяти, благодаря охлаждению, будут более приемлемые температуры и более низкий уровень шума. Что сделает видеокарту, более приятной и не сбрасывающей вольтаж/частоты, соответственно подарит ей более стабильную и долгую работу.
Ну и не забываем про тип подключения основной - PCI-Express х16 3.0 пока что, но уже у AMD есть PCI-Express х16 4.0 и к примеру для RX 5500 XT этот параметр важен, видеокарта становится производительнее до 40% , но это особенность видеокарты, ведь дорожек у нее не ( х16 ), а всего ( х8 ).
Вывод таков, всегда выбирайте те или иные видеокарты с умом, и желательно предварительно просматривать тесты в играх, которые необходимы, или можете захватить сразу все, чтобы было видно результат "на лицо".

В течение последних трёх лет Nvidia создавала графические чипы, в которых помимо обычных ядер, используемых для шейдеров, устанавливались дополнительные. Эти ядра, называемые тензорными, уже есть в тысячах настольных PC, ноутбуков, рабочих станций и дата-центров по всему миру. Но что же они делают и для чего применяются? Нужны ли они вообще в графических картах?
Сегодня мы объясним, что такое тензор, и как тензорные ядра используются в мире графики и глубокого обучения.
Краткий урок математики
Чтобы понять, чем же заняты тензорные ядра и для чего их можно использовать, нам сначала разобраться, что такое тензоры. Все микропроцессоры, какую бы задачу они ни выполняли, производят математические операции над числами (сложение, умножение и т.д.).
Иногда эти числа необходимо группировать, потому что они обладают определённым значением друг для друга. Например, когда чип обрабатывает данные для рендеринга графики, он может иметь дело с отдельными целочисленными значениями (допустим, +2 или +115) в качестве коэффициента масштабирования или с группой чисел с плавающей точкой (+0.1, -0.5, +0.6) в качестве координат точки в 3D-пространстве. Во втором случае для позиции точки требуются все три элемента данных.
Тензор — это математический объект, описывающий соотношения между другими математическими объектами, связанными друг с другом. Обычно они отображаются в виде массива чисел, размерность которого показана ниже.

Простейший тип тензора имеет нулевую размерность и состоит из единственного значения; иначе он называется скалярной величиной. При увеличении количества размерностей мы сталкиваемся с другими распространёнными математическими структурами:
- 1 измерение = вектор
- 2 измерения = матрица
Одна из самых важных математических операций, выполняемых над матрицами — это умножение (или произведение). Давайте взглянем на то, как перемножаются друг на друга две матрицы, имеющие по четыре строки и столбца данных:

Окончательным результатом умножения всегда будет то же количество строк, что и в первой матрице, и то же количество столбцов, что и во второй. Как же перемножить эти два массива? Вот так:

На пальцах это посчитать не удастся
Как вы видите, вычисление «простого» произведения матриц состоит из целой кучи небольших умножений и сложений. Так как любой современный центральных процессор может выполнять обе эти операции, простейшие тензоры способен выполнять каждый настольный компьютер, ноутбук или планшет.
Однако показанный выше пример содержит 64 умножений и 48 сложений; каждое небольшое произведение даёт значение, которое нужно где то хранить, прежде чем его можно будет сложить с другими тремя небольшими произведениями, чтобы позже можно было сохранить окончательное значение тензора. Поэтому, несмотря на математическую простоту умножений матриц, они затратны вычислительно — необходимо использовать множество регистров, а кэш должен уметь справляться с кучей операций считывания и записи.

Архитектура Intel Sandy Bridge, в которой впервые появились расширения AVX
На протяжении многих лет в процессорах AMD и Intel появлялись различные расширения (MMX, SSE, а теперь и AVX — все они являются SIMD, single instruction multiple data), позволяющие процессору одновременно обрабатывать множество чисел с плавающей запятой; это как раз то, что требуется для перемножения матриц.
Но существует особый тип процессоров, который специально спроектирован для обработки операций SIMD: графические процессоры (graphics processing unit, GPU).
Умнее, чем обычный калькулятор?
В мире графики одновременно необходимо передавать и обрабатывать огромные объёмы информации в виде векторов. Благодаря своей способности параллельной обработки GPU идеально подходят для обработки тензоров; все современные графические процессоры поддерживают функциональность под названием GEMM (General Matrix Multiplication).
Это «склеенная» операция, при которой перемножаются две матрицы, а результат затем накапливается с другой матрицей. Существуют важные ограничения на формат матриц и все они связаны с количеством строк и столбцов каждой матрицы.

Требования GEMM к строкам и столбцам: матрица A(m x k), матрица B(k x n), матрица C(m x n)
Алгоритмы, используемые для выполнения операций с матрицами, обычно лучше всего работают, когда матрицы квадратные (например, массив 10 x 10 будет работать лучше, чем 50 x 2) и довольно небольшие по размеру. Но они всё равно будут работать лучше, если обрабатываются на оборудовании, которое предназначено исключительно для таких операций.
В декабре 2017 года Nvidia выпустила графическую карту с GPU, имеющим новую архитектуру Volta. Она была нацелена на профессиональные рынки, поэтому этот чип не использовался в моделях GeForce. Уникальным он был потому, что стал первым графическим процессором, имеющим ядра только для выполнения тензорных вычислений.

Графическая карта Nvidia Titan V, на которой установлен чип GV100 Volta. Да на ней можно запустить Crysis
Тензорные ядра Nvidia были предназначены для выполнения по 64 GEMM за тактовый цикл с матрицами 4 x 4, содержащими значения FP16 (числа с плавающей запятой размером 16 бит) или умножение FP16 со сложением FP32. Такие тензоры очень малы по размеру, поэтому при обработке настоящих множеств данных ядра обрабатывают небольшие части больших матриц, выстраивая окончательный ответ.

В начале этого года архитектура Ampere дебютировала в графическом процессоре дата-центра A100, и на этот раз Nvidia повысила производительность (256 GEMM за цикл вместо 64), добавила новые форматы данных и возможность очень быстрой обработки разреженных тензоров (sparse tensor) (матриц со множеством нулей).
Программисты могут получить доступ к тензорным ядрам чипов Volta, Turing и Ampere очень просто: код всего лишь должен использовать флаг, сообщающий API и драйверам, что нужно применять тензорные ядра, тип данных должен поддерживаться ядрами, а размерности матриц должны быть кратными 8. При выполнении всех этих условий всем остальным займётся оборудование.
Всё это здорово, но насколько тензорные ядра лучше в обработке GEMM, чем обычные ядра GPU?
Когда появилась Volta, сайт Anandtech провёл математические тесты трёх карт Nvidia: новой Volta, самой мощной из линейки Pascal и старой карты Maxwell.
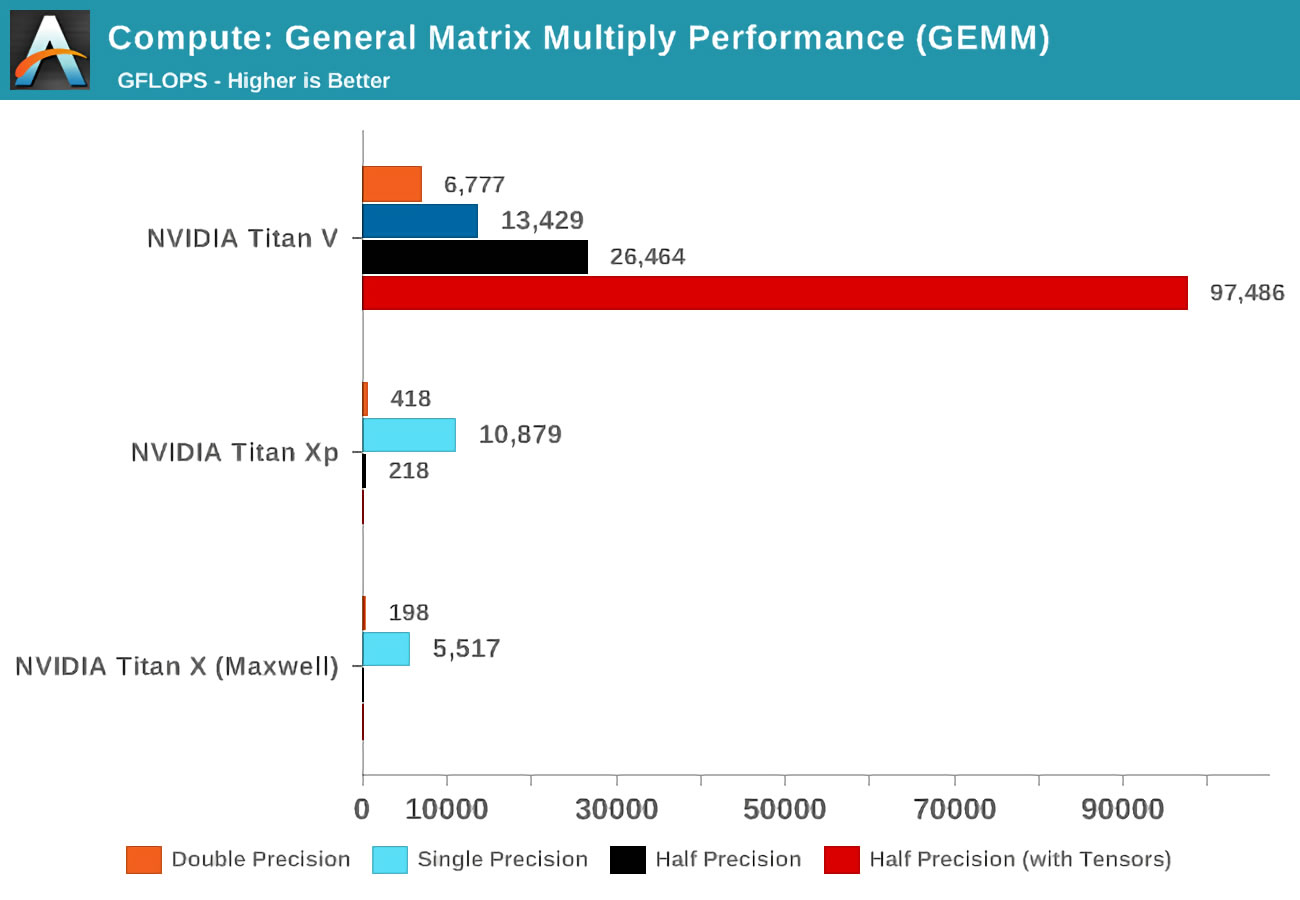
Понятие точности (precision) относится к количеству бит, использованных для чисел с плавающей запятой в матрицах: двойная (double) обозначает 64, одиночная (single) — 32, и так далее. По горизонтальной оси отложено максимальное количество операций с плавающей запятой, выполняемое за секунду, или сокращённо FLOPs (помните, что одна GEMM — это 3 FLOP).
Просто взгляните на результаты при использовании тензорных ядер вместо так называемых ядер CUDA! Очевидно, что они потрясающе справляются с подобной работой, но что же мы можем делать при помощи тензорных ядер?
Математика, делающая всё лучше
Тензорные вычисления чрезвычайно полезны в физике и проектировании, они используются для решения всевозможных сложных задач в механике жидкостей, электромагнетизме и астрофизике, однако компьютеры, которые использовались для обработки подобных чисел, обычно выполняли операции с матрицами в больших кластерах из центральных процессоров.
Ещё одна область, в которой любят применять тензоры — это машинное обучение, особенно её подраздел «глубокое обучение». Его смысл сводится к обработке огромных наборов данных в гигантских массивах, называемых нейронными сетями. Соединениям между различными значениями данных задаётся определённый вес — число, выражающее важность конкретного соединения.
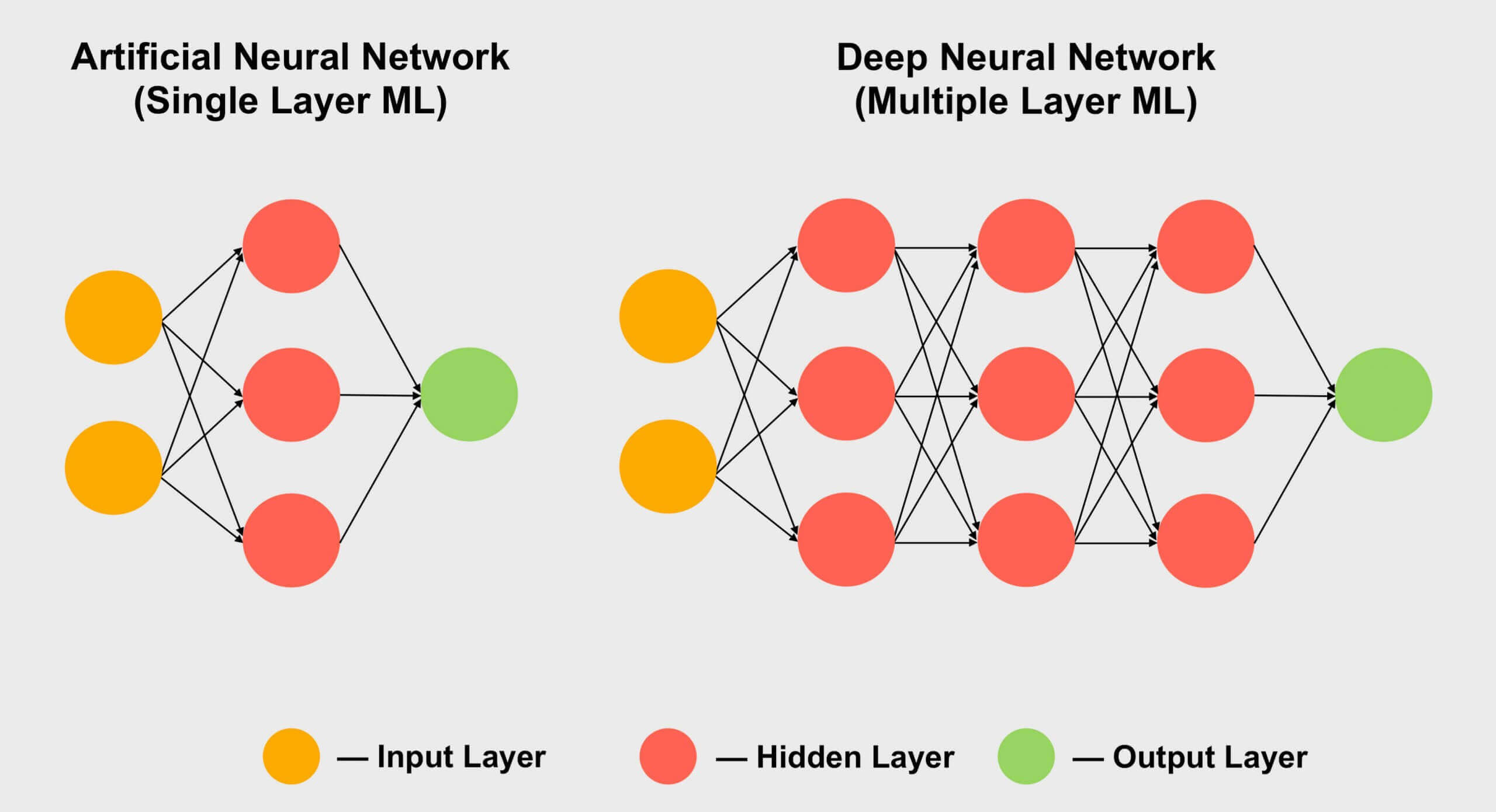
Поэтому когда нам нужно разобраться, как взаимодействуют все эти сотни, если не тысячи соединений, нужно умножить каждый элемент данных в сети на все возможные веса соединений. Другими словами, перемножить две матрицы, а это классическая тензорная математика!

Чипы Google TPU 3.0, закрытые системой водяного охлаждения
Именно поэтому во всех суперкомпьютерах глубокого обучения используются GPU, и почти всегда это Nvidia. Однако некоторые компании даже разработали собственные процессоры из тензорных ядер. Google, например, в 2016 году объявила о разработке своего первого TPU (tensor processing unit), но эти чипы настолько специализированные, что не могут выполнять ничего, кроме операций с матрицами.
Тензорные ядра в потребительских GPU (GeForce RTX)
Но что если я куплю графическую карту Nvidia GeForce RTX, не являясь ни астрофизиком, решающим задачи римановых многообразий, ни специалистом, экспериментирующим с глубинами свёрточных нейронных сетей. Как я могу использовать тензорные ядра?
Чаще всего они не применяются для обычного рендеринга, кодирования или декодирования видео, поэтому может показаться, что вы потратили деньги на бесполезную функцию. Однако Nvidia встроила тензорные ядра в свои потребительские продукты в 2018 году (Turing GeForce RTX), внедрив при этом DLSS — Deep Learning Super Sampling.

Принцип прост: рендерим кадр в довольно низком разрешении, а после завершения повышаем разрешение конечного результата так, чтобы он совпадал с «родными» размерами экрана монитора (например, рендерим в 1080p, а затем изменяем размер до 1400p). Благодаря этому повышается производительность, ведь обрабатывается меньшее количество пикселей, а на экране всё равно получается красивое изображение.
Консоли имели такую функцию уже многие годы, и многие современные игры для PC тоже обеспечивают эту возможность. В Assassin's Creed: Odyssey компании Ubisoft можно уменьшить разрешение рендеринга до всего 50% от разрешения монитора. К сожалению, результаты выглядят не так красиво. Вот как игра выглядит в 4K с максимальными настройками графики:

В высоких разрешениях текстуры выглядят красивее, потому что сохраняют в себе больше деталей. Однако для вывода этих пикселей на экран требуется много обработки. Теперь взгляните на то, что происходит при установке рендеринга на 1080p (25% от предыдущего количества пикселей), с использованием шейдеров в конце для растягивания картинки до 4K.

Из-за сжатия jpeg разница может быть заметной не сразу, но видно, что броня персонажа и скала вдали выглядят размытыми. Давайте приблизим часть изображения для более детального изучения:

Изображение слева отрендерено в 4K; изображение справа — это 1080p, растянутые до 4K. Разница гораздо заметнее в движении, потому что смягчение всех деталей быстро превращается в размытую кашу. Частично чёткость можно восстановить благодаря эффекту резкости драйверов графической карты, но лучше бы нам вообще не приходилось этим не заниматься.
Именно здесь в ход идёт DLSS — в первой версии этой технологии Nvidia анализировались несколько выбранных игр; они запускались в высоких разрешениях, низких разрешениях, со сглаживанием и без него. Во всех этих режимах был сгенерирован набор изображений, загруженный затем в суперкомпьютеры компании, которые использовали нейронную сеть, чтобы определить, каким образом лучше всего превратить изображение в разрешении 1080p в идеальную картинку в более высоком разрешении.

Нужно сказать, что DLSS 1.0 не был идеальным: детали часто терялись и в некоторых местах возникало странное мерцание. К тому же он не использовал сами тензорные ядра графической карты (он выполнялся в сети Nvidia) и каждой игре с поддержкой DLSS для генерации алгоритма повышения масштаба требовалось отдельное исследование компанией Nvidia.

Когда в начале 2020 года вышла версия 2.0, в неё были внесены серьёзные улучшения. Самым важным стало то, что суперкомпьютеры Nvidia теперь использовались только для создания общего алгоритма увеличения масштаба — в новой версии DLSS для обработки пикселей с помощью нейронной модели (тензорными ядрами GPU) используются данные из отрендеренного кадра.

Нас впечатляют возможности DLSS 2.0, но пока его поддерживает очень мало игр — на момент написания статьи их было всего 12. Всё больше разработчиков хочет реализовать его в своих будущих играх, и на то есть причины.
Благодаря любому увеличению масштаба можно добиться серьёзного роста производительности, поэтому можно быть уверенными, что DLSS продолжит эволюционировать.

Хотя визуальные результаты работы DLSS не всегда идеальны, освободив занятые рендерингом ресурсы, разработчики смогут добавить больше визуальных эффектов или обеспечить один уровень графики на более широком диапазоне платформ.
Например, DLSS часто рекламируют вместе с трассировкой лучей (ray tracing) в играх с «поддержкой RTX». Карты GeForce RTX содержат дополнительные вычислительные блоки, называемые RT-ядрами, это специализированные логические блоки для ускорения вычислений пересечения луча с треугольником и обхода иерархии ограничивающих объёмов (bounding volume hierarchy, BVH). Эти два процесса являются очень длительными процедурами, определяющими способ взаимодействия света с другими объектами сцены.
Как мы выяснили, ray tracing — очень трудоёмкий процесс, поэтому чтобы обеспечить в играх приемлемый уровень частоты кадров, разработчики должны ограничить количество лучей и выполняемых в сцене отражений. При выполнении этого процесса могут создаваться зернистые изображения, поэтому необходимо применять алгоритм устранения шумов, что повышает сложность обработки. Ожидается, что тензорные ядра повысят производительность этого процесса благодаря устранению шумов с использованием ИИ, однако это ещё предстоит реализовать: большинство современных приложений по-прежнему использует для этой задачи ядра CUDA. С другой стороны, благодаря тому, что DLSS 2.0 становится вполне практичной техникой повышения размера, тензорные ядра можно будет эффективно использовать для повышения частоты кадров после применения в сцене трассировки лучей.
Существуют и другие планы по использованию тензорных ядер карт GeForce RTX, например, улучшение анимаций персонажей или симуляция тканей. Но как и в случае с DLSS 1.0, пройдёт ещё немало времени, прежде чем появятся сотни игр, использующие специализированные матричные вычисления на GPU.
Многообещающее начало
Итак, ситуация такова — тензорные ядра, отличные аппаратные блоки, которые, однако, встречаются только в некоторых картах потребительского уровня. Изменится ли что-то в будущем? Так как Nvidia уже значительно улучшила производительность каждого тензорного ядра в своей архитектуре Ampere, есть большая вероятность того, что они будут устанавливаться и в модели нижнего и среднего ценового уровня.
Хотя таких ядер пока нет в GPU компаний AMD и Intel, возможно, в будущем мы их увидим. У AMD есть система повышения резкости или улучшения деталей в готовых кадрах ценой небольшого снижения производительности, поэтому компания, возможно, будет придерживаться этой системы, особенно учитывая то, что её не нужно интегрировать разработчикам, достаточно включить её в драйверах.
Существует также мнение, что пространство на кристаллах в графических чипах лучше было бы потратить на дополнительные шейдерные ядра — так поступила Nvidia при создании бюджетных версий своих чипов Turing. В таких продуктах, как GeForce GTX 1650, компания полностью отказалась от тензорных ядер и заменила их дополнительными FP16-шейдерами.
Но пока, если вы хотите обеспечить сверхбыструю обработку GEMM и воспользоваться всеми её преимуществами, то у вас есть два варианта: купить кучу огромных многоядерных CPU или просто один GPU с тензорными ядрами.
Руководство покупателя игровой видеокарты
Современные графические процессоры содержат множество функциональных блоков, от количества и характеристик которых зависит и итоговая скорость рендеринга, влияющая на комфортность игры. По сравнительному количеству этих блоков в разных видеочипах можно примерно оценить, насколько быстр тот или иной GPU. Характеристик у видеочипов довольно много, в этом разделе мы рассмотрим лишь самые важные из них.
Тактовая частота видеочипа
Рабочая частота GPU обычно измеряется в мегагерцах, т. е. миллионах тактов в секунду. Эта характеристика прямо влияет на производительность видеочипа — чем она выше, тем больший объем работы GPU может выполнить в единицу времени, обработать большее количество вершин и пикселей. Пример из реальной жизни: частота видеочипа, установленного на плате Radeon HD 6670 равна 840 МГц, а точно такой же чип в модели Radeon HD 6570 работает на частоте в 650 МГц. Соответственно будут отличаться и все основные характеристики производительности. Но далеко не только рабочая частота чипа определяет производительность, на его скорость сильно влияет и сама графическая архитектура: устройство и количество исполнительных блоков, их характеристики и т. п.
В некоторых случаях тактовая частота отдельных блоков GPU отличается от частоты работы остального чипа. То есть, разные части GPU работают на разных частотах, и сделано это для увеличения эффективности, ведь некоторые блоки способны работать на повышенных частотах, а другие — нет. Такими GPU комплектуется большинство видеокарт GeForce от NVIDIA. Из свежих примеров приведём видеочип в модели GTX 580, большая часть которого работает на частоте 772 МГц, а универсальные вычислительные блоки чипа имеют повышенную вдвое частоту — 1544 МГц.
Скорость заполнения (филлрейт)
Скорость заполнения показывает, с какой скоростью видеочип способен отрисовывать пиксели. Различают два типа филлрейта: пиксельный (pixel fill rate) и текстурный (texel rate). Пиксельная скорость заполнения показывает скорость отрисовки пикселей на экране и зависит от рабочей частоты и количества блоков ROP (блоков операций растеризации и блендинга), а текстурная — это скорость выборки текстурных данных, которая зависит от частоты работы и количества текстурных блоков.
Например, пиковый пиксельный филлрейт у GeForce GTX 560 Ti равен 822 (частота чипа) × 32 (количество блоков ROP) = 26304 мегапикселей в секунду, а текстурный — 822 × 64 (кол-во блоков текстурирования) = 52608 мегатекселей/с. Упрощённо дело обстоит так — чем больше первое число — тем быстрее видеокарта может отрисовывать готовые пиксели, а чем больше второе — тем быстрее производится выборка текстурных данных.
Хотя важность "чистого" филлрейта в последнее время заметно снизилась, уступив скорости вычислений, эти параметры всё ещё остаются весьма важными, особенно для игр с несложной геометрией и сравнительно простыми пиксельными и вершинными вычислениями. Так что оба параметра остаются важными и для современных игр, но они должны быть сбалансированы. Поэтому количество блоков ROP в современных видеочипах обычно меньше количества текстурных блоков.
Количество вычислительных (шейдерных) блоков или процессоров
Пожалуй, сейчас эти блоки — главные части видеочипа. Они выполняют специальные программы, известные как шейдеры. Причём, если раньше пиксельные шейдеры выполняли блоки пиксельных шейдеров, а вершинные — вершинные блоки, то с некоторого времени графические архитектуры были унифицированы, и эти универсальные вычислительные блоки стали заниматься различными расчётами: вершинными, пиксельными, геометрическими и даже универсальными вычислениями.
Впервые унифицированная архитектура была применена в видеочипе игровой консоли Microsoft Xbox 360, этот графический процессор был разработан компанией ATI (впоследствии купленной AMD). А в видеочипах для персональных компьютеров унифицированные шейдерные блоки появились ещё в плате NVIDIA GeForce 8800. И с тех пор все новые видеочипы основаны на унифицированной архитектуре, которая имеет универсальный код для разных шейдерных программ (вершинных, пиксельных, геометрических и пр.), и соответствующие унифицированные процессоры могут выполнить любые программы.
По числу вычислительных блоков и их частоте можно сравнивать математическую производительность разных видеокарт. Большая часть игр сейчас ограничена производительностью исполнения пиксельных шейдеров, поэтому количество этих блоков весьма важно. К примеру, если одна модель видеокарты основана на GPU с 384 вычислительными процессорами в его составе, а другая из той же линейки имеет GPU с 192 вычислительными блоками, то при равной частоте вторая будет вдвое медленнее обрабатывать любой тип шейдеров, и в целом будет настолько же производительнее.
Хотя, исключительно на основании одного лишь количества вычислительных блоков делать однозначные выводы о производительности нельзя, обязательно нужно учесть и тактовую частоту и разную архитектуру блоков разных поколений и производителей чипов. Только по этим цифрам можно сравнивать чипы только в пределах одной линейки одного производителя: AMD или NVIDIA. В других же случаях нужно обращать внимание на тесты производительности в интересующих играх или приложениях.
Блоки текстурирования (TMU)
Эти блоки GPU работают совместно с вычислительными процессорами, ими осуществляется выборка и фильтрация текстурных и прочих данных, необходимых для построения сцены и универсальных вычислений. Число текстурных блоков в видеочипе определяет текстурную производительность — то есть скорость выборки текселей из текстур.
Хотя в последнее время больший упор делается на математические расчеты, а часть текстур заменяется процедурными, нагрузка на блоки TMU и сейчас довольно велика, так как кроме основных текстур, выборки необходимо делать и из карт нормалей и смещений, а также внеэкранных буферов рендеринга render target.
С учётом упора многих игр в том числе и в производительность блоков текстурирования, можно сказать, что количество блоков TMU и соответствующая высокая текстурная производительность также являются одними из важнейших параметров для видеочипов. Особенное влияние этот параметр оказывает на скорость рендеринга картинки при использовании анизотропной фильтрации, требующие дополнительных текстурных выборок, а также при сложных алгоритмах мягких теней и новомодных алгоритмах вроде Screen Space Ambient Occlusion.
Блоки операций растеризации (ROP)
Блоки растеризации осуществляют операции записи рассчитанных видеокартой пикселей в буферы и операции их смешивания (блендинга). Как мы уже отмечали выше, производительность блоков ROP влияет на филлрейт и это — одна из основных характеристик видеокарт всех времён. И хотя в последнее время её значение также несколько снизилось, всё ещё попадаются случаи, когда производительность приложений зависит от скорости и количества блоков ROP. Чаще всего это объясняется активным использованием фильтров постобработки и включенным антиалиасингом при высоких игровых настройках.
Ещё раз отметим, что современные видеочипы нельзя оценивать только числом разнообразных блоков и их частотой. Каждая серия GPU использует новую архитектуру, в которой исполнительные блоки сильно отличаются от старых, да и соотношение количества разных блоков может отличаться. Так, блоки ROP компании AMD в некоторых решениях могут выполнять за такт больше работы, чем блоки в решениях NVIDIA, и наоборот. То же самое касается и способностей текстурных блоков TMU — они разные в разных поколениях GPU разных производителей, и это нужно учитывать при сравнении.
Вплоть до последнего времени, количество блоков обработки геометрии было не особенно важным. Одного блока на GPU хватало для большинства задач, так как геометрия в играх была довольно простой и основным упором производительности были математические вычисления. Важность параллельной обработки геометрии и количества соответствующих блоков резко выросли при появлении в DirectX 11 поддержки тесселяции геометрии. Компания NVIDIA первой распараллелила обработку геометрических данных, когда в её чипах семейства GF1xx появилось по несколько соответстующих блоков. Затем, похожее решение выпустила и AMD (только в топовых решениях линейки Radeon HD 6700 на базе чипов Cayman).
В рамках этого материала мы не будем вдаваться в подробности, их можно прочитать в базовых материалах нашего сайта, посвященных DirectX 11-совместимым графическим процессорам. В данном случае для нас важно то, что количество блоков обработки геометрии очень сильно влияет на общую производительность в самых новых играх, использующих тесселяцию, вроде Metro 2033, HAWX 2 и Crysis 2 (с последними патчами). И при выборе современной игровой видеокарты очень важно обращать внимание и на геометрическую производительность.
Собственная память используется видеочипами для хранения необходимых данных: текстур, вершин, данных буферов и т. п. Казалось бы, что чем её больше — тем всегда лучше. Но не всё так просто, оценка мощности видеокарты по объему видеопамяти — это наиболее распространенная ошибка! Значение объёма видеопамяти неопытные пользователи переоценивают чаще всего, до сих пор используя именно его для сравнения разных моделей видеокарт. Оно и понятно — этот параметр указывается в списках характеристик готовых систем одним из первых, да и на коробках видеокарт его пишут крупным шрифтом. Поэтому неискушённому покупателю кажется, что раз памяти в два раза больше, то и скорость у такого решения должна быть в два раза выше. Реальность же от этого мифа отличается тем, что память бывает разных типов и характеристик, а рост производительности растёт лишь до определенного объёма, а после его достижения попросту останавливается.
Так, в каждой игре и при определённых настройках и игровых сценах есть некий объём видеопамяти, которого хватит для всех данных. И хоть ты 4 ГБ видеопамяти туда поставь — у неё не появится причин для ускорения рендеринга, скорость будут ограничивать исполнительные блоки, о которых речь шла выше, а памяти просто будет достаточно. Именно поэтому во многих случаях видеокарта с 1,5 ГБ видеопамяти работает с той же скоростью, что и карта с 3 ГБ (при прочих равных условиях).
Ситуации, когда больший объём памяти приводит к видимому увеличению производительности, существуют — это очень требовательные игры, особенно в сверхвысоких разрешениях и при максимальных настройках качества. Но такие случаи встречаются не всегда и объём памяти учитывать нужно, не забывая о том, что выше определённого объема производительность просто уже не вырастет. Есть у чипов памяти и более важные параметры, такие как ширина шины памяти и её рабочая частота. Эта тема настолько обширна, что подробнее о выборе объёма видеопамяти мы ещё остановимся в шестой части нашего материала.
Ширина шины памяти
Современные игровые видеокарты используют разную ширину шины: от 64 до 384 бит (ранее были чипы и с 512-битной шиной), в зависимости от ценового диапазона и времени выпуска конкретной модели GPU. Для самых дешёвых видеокарт уровня low-end чаще всего используется 64 и реже 128 бит, для среднего уровня от 128 до 256 бит, ну а видеокарты из верхнего ценового диапазона используют шины от 256 до 384 бит шириной. Ширина шины уже не может расти чисто из-за физических ограничений — размер кристалла GPU недостаточен для разводки более чем 512-битной шины, и это обходится слишком дорого. Поэтому наращивание ПСП сейчас осуществляется при помощи использования новых типов памяти (см. далее).
На современные видеокарты устанавливается сразу несколько различных типов памяти. Старую SDR-память с одинарной скоростью передачи уже нигде не встретишь, но и современные типы памяти DDR и GDDR имеют значительно отличающиеся характеристики. Различные типы DDR и GDDR позволяют передавать в два или четыре раза большее количество данных на той же тактовой частоте за единицу времени, и поэтому цифру рабочей частоты зачастую указывают удвоенной или учетверённой, умножая на 2 или 4. Так, если для DDR-памяти указана частота 1400 МГц, то эта память работает на физической частоте в 700 МГц, но указывают так называемую «эффективную» частоту, то есть ту, на которой должна работать SDR-память, чтобы обеспечить такую же пропускную способность. То же самое с GDDR5, но частоту тут даже учетверяют.
Основное преимущество новых типов памяти заключается в возможности работы на больших тактовых частотах, а соответственно — в увеличении пропускной способности по сравнению с предыдущими технологиями. Это достигается за счет увеличенных задержек, которые, впрочем, не так важны для видеокарт. Первой платой, использующей память DDR2, стала NVIDIA GeForce FX 5800 Ultra. С тех пор технологии графической памяти значительно продвинулись, был разработан стандарт GDDR3, который близок к спецификациям DDR2, с некоторыми изменениями специально для видеокарт.
GDDR3 — это специально предназначенная для видеокарт память, с теми же технологиями, что и DDR2, но с улучшенными характеристиками потребления и тепловыделения, что позволило создать микросхемы, работающие на более высоких тактовых частотах. Несмотря на то, что стандарт был разработан в компании ATI, первой видеокартой, её использующей, стала вторая модификация NVIDIA GeForce FX 5700 Ultra, а следующей стала GeForce 6800 Ultra.
GDDR4 — это дальнейшее развитие «графической» памяти, работающее почти в два раза быстрее, чем GDDR3. Основными отличиями GDDR4 от GDDR3, существенными для пользователей, являются в очередной раз повышенные рабочие частоты и сниженное энергопотребление. Технически, память GDDR4 не сильно отличается от GDDR3, это дальнейшее развитие тех же идей. Первыми видеокартами с чипами GDDR4 на борту стали ATI Radeon X1950 XTX, а у компании NVIDIA продукты на базе этого типа памяти не выходили вовсе. Преимущества новых микросхем памяти перед GDDR3 в том, что энергопотребление модулей может быть примерно на треть ниже. Это достигается за счет более низкого номинального напряжения для GDDR4.
Впрочем, GDDR4 не получила широкого распространения даже в решениях AMD. Начиная с GPU семейства RV7x0, контроллерами памяти видеокарт поддерживается новый тип памяти GDDR5, работающий на эффективной учетверённой частоте до 5,5 ГГц и выше (теоретически возможны частоты до 7 ГГц), что даёт пропускную способность до 176 ГБ/с с применением 256-битного интерфейса. Если для повышения ПСП у памяти GDDR3/GDDR4 приходилось использовать 512-битную шину, то переход на использование GDDR5 позволил увеличить производительность вдвое при меньших размерах кристаллов и меньшем потреблении энергии.
Видеопамять самых современных типов — это GDDR3 и GDDR5, она отличается от DDR некоторыми деталями и также работает с удвоенной/учетверённой передачей данных. В этих типах памяти применяются некоторые специальные технологии, позволяющие поднять частоту работы. Так, память GDDR2 обычно работает на более высоких частотах по сравнению с DDR, GDDR3 — на еще более высоких, а GDDR5 обеспечивает максимальную частоту и пропускную способность на данный момент. Но на недорогие модели до сих пор ставят «неграфическую» память DDR3 со значительно меньшей частотой, поэтому нужно выбирать видеокарту внимательнее.


Вот например характеристики GeForce RTX 3090:
- Ядра CUDA: 10496 | Тензорные ядра : 328 | Ядра трассировки лучей: 82
- 28 млрд. транзисторов
- Видеопамять: 24 ГБ GDDR6X
- Пропускная системной памяти: > 1 ТБ/с
- Цена: от 136 990 руб.
Но раз видюхи такие производительные, зачем нам вообще центральный процессор? И в чем всё-таки отличия CPU от GPU?
А чем видеокарты отличаются между собой? Как такая бандура помещается в ноутбук? И главное выясним, можно ли в играть в Cyberpunk 2077 на ноутбуке на ультра-настройках. Поговорим об этом и о многом другом в большом разборе!
Сейчас видеокарты много чего умеют делать и часто делают некоторые задачи куда быстрее и эффективнее CPU? Но к такому положению вещей мы пришли не сразу. Первые видеокарты было бы справедливо назвать ASIC-ками (Application-Specific Integrated Circuit), то есть интегральными схемами специального назначения. Что это значит?
Это удобно, потому как на центральном процессоре мы можем сделать любое вычисление. И в принципе, один огромный ЦП может заменить собой вообще все остальные чипы. Но естественно, это будет неэффективно. Поэтому для специфических задач на помощь центральному процессору часто приходят сопроцессоры или ASIC-ки то есть отдельные чипы, заточенные под эффективное решение какой-то конкретной задачи.
Так в середине 90-х такой конкретной задачей стало ускорение первых 3D-игр вроде Quake!
Первые видеокарты
Без ускорения Quake выглядел достаточно постредсвенно. Всё очень пиксельное и тормозное.

Но стоило прикупить себе волшебный 3D-акселератор. Подключить его к вашей основной 2D-видеокарте снаружи коротким VGA кабелем. Да-да, раньше это делалось так. И Quake превращался в нечто запредельное. Игра становилась, плавной, красочной, а главное работала в высоком для того времени разрешении и соответственно никаких пикселей.
Тогда это воспринималось практически как магия. Но за счет чего происходило такое кардинальное улучшение картинки? Чтобы ответить на этот вопрос, давайте разберемся как работает видеокарта поэтапно.
Как работает видеокарта?
Этап 1. Растеризация.
Мы переносим координаты вершин на плоскую поверхность соединяем их при помощи уравнений прямых на плоскости и заполняем пикселями плоскости треугольников. На этом этапе мы получаем двухмерную проекцию объекта на экране.
Этап 2. Текстурирование
Дальше нам нужно как-то раскрасить модельку. Поэтому на растрированный объект по текстурным координатам натягивается текстура.
Но просто натянуть текстуру недостаточно, ее нужно как-то сгладить. Иначе при приближении к объекту вы просто будите видеть сетку текселей. Прям как в первых 3D-играх типа DOOM. Поэтому дальше к текстуре применяются различные алгоритмы фильтрации.

А вот чтобы вернуть четкости текстурам под углами к камере используют анизотропную интерполяцию. Чем выше её коэффициент тем четче получается картинка, так как для получения цвета каждого пикселя делается до 16 выборок. Особенно это заметно на поверхностях, находящихся под острым углом к камере. То есть, к примеру, на полу.

Окей, теперь мы получили цветное изображение. Но этого всё ещё недостаточно, потому как в сцене нет освещения. Поэтому переходим к следующему этапу с интригующим названием пиксельный шейдер или затенение пикселей.
Этап 3. Пиксельный шейдер.
Кстати, впервые поддержка простых шейдеров появились в 2001 году, когда появилась NVIDIA GeForce 3. До этого освещение тоже делалось, но аппаратными средствами и разработчики особо не могли влиять на результат. Так вот сегодня это самый ресурсоемкий этап, на котором для каждого пикселя нужно просчитать как он отражает, рассеивает и пропускает свет. Как ложатся тени по поверхности модели и прочее. То есть иными словами рассчитывается финальный цвет пикселя.
Каждый объект сцены описывается при помощи нескольких текстур:
- Карта нормалей, текстура, в которой хранятся векторы нормалей для каждой точки поверхности. При помощи этих векторов рассчитывается попиксельное освещение.
- Карта зеркальности, которая описывает сколько света отражается от поверхности.
- Карта шероховатостей (roughness mapbump map), которая описывает микрорельеф поверхности или то, как поверхность будет рассеивать свет.
- Альбедо карта, то есть карта диффузии или естественный цвет объекта.
- И прочие.
Этап 4. Сохранение
После кучи вычислений при помощи информации из всех вышеперечисленных текстур наступает последний этап. Мы получили финальный цвет пикселя и сохраняем его в видеопамять. А после обработки всей сцены мы уже можем выводить картинку на экран.
Мощность
Центральный процессор заточен под последовательное, но очень быстрое выполнение множества разнообразных вычислений. Поэтому ядер в центральном процессоре мало, но зато они умеют быстро щелкать любые задачи. А вот в GPU вычислительных блоков тысячи, они не умеют максимально быстро выполнять задачи с небольшим количеством данных последовательно как процессор, но очень быстро делают параллельные вычисления с большим количеством данных. Например, NVIDIA GeForce RTX 3090 в пике может делать до 38 триллионов операций с плавающей точкой в секунду.

Это позволяет видеокартам обрабатывать сотни миллиардов пикселей в секунду.

Трассировка лучей
Что такое трассировка лучей? Несмотря, на то что видеокарты за годы своей эволюции обросли поддержкой кучи эффектов. Игры действительно стали выглядеть впечатляюще круто. Но всё равно, остались выглядеть как игры. Почему?
А вот трассировка лучей впервые позволила, построить освещение по законам природы и сняла кучу ограничений. Ну практически. Как это работает?
Вместо того, чтобы поочередно считать освещение для каждого объекта Сначала выводится вся трехмерная сцена и упаковывается в BVH коробки для ускорения трассировки. После чего из камеры в упакованную 3D-сцену запускается луч и мы смотрим с какой поверхностью он пересечется. А дальше от этой точки строится по одному лучу до каждого источника освещения. Так мы понимаем где свет, а где тень.
А если луч попал на отражающий объект, то строится еще один отраженный луч и так мы можем считать переотражения. Чем больше переотражений мы считаем, тем сложнее просчет, но реалистичнее результат.
Всё практически как в жизни, но для экономии ресурсов, лучи запускаются не от источника света а из камеры. Иначе бы пришлось просчитывать много лучей, которые не попадают в поле зрения игрока, то есть делать бесполезные, отнимающие ресурсы GPU вычисления.
Новые ядра
Для реализации трассировки лучей, помимо ядер CUDA пришлось придумать ядра нового типа. Это RT-ядра, что собственно и значит ядра трассировки лучей и тензорные ядра.

Суть алгоритма: Каждый полигон вкладывается в несколько коробок разного размера, как в матрешку. И вместо того, чтобы проверять пересечения с каждым полигоном сцены, коих миллионы, сначала проверяется попал ли луч в небольшое количесчтво коробок, в которые упакованы треугольники сцены, На последнем уровне BVH матрешки содержится коробка с несколькими треугольниками сцены. Коробок намного меньше, чем треугольников, поэтому на тестирование сцены уходит намного меньше времени, чем если бы мы перебирали каждый треугольник сцены.


Но и в играх тензорные ядра имеют высокий вес. Во-первых, очищение рейтрейснутой картинки от шума в профессиональных пакетах с поддержкой OptiX.
Многовато технологий! В таком можно и запутаться, поэтому чтобы упорядочить мысли давайте пройдёмся по этапам того как работает видеокарта.
Чем отличаются видеокарты?
Окей, кажется с принципом работы видеокарты разобрались. Теперь давайте поговорим почему одни видеокарты работают быстрее, а другие медленнее.
Во-первых, на скорость и возможности видеокарты влияет поколение. Например, до появления серии GeForce RTX 20-серии вообще не было трассировки лучей и прочих плюшек. Но если говорить о производительности в рамках одного поколения, то нас интересуют 4 параметра:
- Количество ядер и прочих исполнительных блоков
- Скорость и объём памяти
- Частота ядра
- Дизайн
Допустим, сравним 20-ю серию.


Дизайн
Но причем тут дизайн?
Дело в том, что NVIDIA производит только чипы и показывает референсный дизайн видеокарты. А дальше каждый производитель сам решает какую систему охлаждения поставить и в каком размере сделать видеокарту. Соответственно, чем лучше охлаждение, тем выше будет частота работы, и больше производительность.
Но также под дизайном имеется ввиду формфактор. Дело в том что большие видеокарты, например, просто физически не влезут в ноутбук. А если даже влезут, энергопотребление в них будет запредельным. Поэтому существуют мобильные модификации видеокарт, которые просто распаиваются на материнской плате. Мобильные модификации карточек отличаются сниженными частотами и энергопотреблением.
Существуют две разновидности мобильных дизайнов:
- Просто Mobile. Это версии для жирных игровых ноутов. они не сильно отличаются по производительности от десктопных версий. Иногда такие карточки называют Max-P, типа performance. А иногда вообще ничего не приписывают. Но не обольщайтесь в ноутбуке не может стоять не мобильная версия.
- А бывает дизайн Max-Q. Такие карточки ставя в тонкие игровые ноуты. В них существенно ниже энергопотребление, но и частоты сильнее порезаны.
| RTX 2080 Super | RTX 2080 Super Mobile (Max-P) | RTX 2080 Super Max-Q | |
| CUDA ядра | 3072 | 3072 | 3072 |
| Частота яда | 1650 МГц | 1365 МГц | 975 МГц |
| Частота в режиме Boost | 1815 МГц | 1560 МГц | 1230 МГц |
| Энергопотребление (TDP) | 250 Вт | 150 Вт | 80 Вт |
Проверим на практике
У нас есть 3 ноутбука. Вот с таким железом.
ASUS ROG Zephyrus G15
Ryzen 7 4800HS
NVIDIA GeForce GTX 1650 Ti 4ГБ
ASUS ROG Zephyrus G14
Ryzen 9 4900HS
NVIDIA GeForce RTX 2060 Max-Q 6ГБ
ASUS ROG Zephirus DUO
Intel Core i9-10980HK
GeForce RTX 2080 SUPER Max-Q 8ГБ
Во всех трёх вариантах установлены разные процессоры, но они все мощные, поэтому не должны сильно повлиять на результат тестов. По крайней мере бутылочным горлышком они точно не будут.
| GTX 1650 Ti Mobile | RTX 2060 Max-Q | RTX 2080 Super Max-Q | |
| CUDA ядра | 1024 | 1920 | 3072 |
| Частота ядра | 1350 МГц | 975 МГц | 975 МГц |
| Частота в режиме Boost | 1485 МГц | 1185 МГц | 1230 МГц |
| Тензорные ядра | — | 240 | 384 |
| RT-ядра | — | 30 | 48 |
| Объем видеопамяти | 4 ГБ | 6 ГБ | 8 ГБ |
| Энергопотребление (TDP) | 65 Вт | 50 Вт | 80 Вт |
И, для начала, немного синтетических тестов. Судя по тесту 3DMark Time Spy, 2080 Super в дизайне Max-Q опережает 2060 на 25%, а 1650 Ti на 51%. А значит мы ожидаем, что 2080 будет выдавать примерно в 2 раза больший фреймрейт. Посмотрим так ли это на практике.
Тест Cyberpunk 2077
Мы всё проверяли на Cyberpunk 2077 с версией 1.04 на не самой загруженной сцене, в закрытой локации. Тем не менее с наличием экшэна. Все ноутбуки работали в режиме производительности турбо.
Итак, в Cyberpunk 2077 есть 6 стандартных пресетов графики: низкие, средние, высокие, впечатляющие. И еще две настройки с трассировкой лучей: это впечатляющие настройки + среднее качество трассировки или ультра качество. В пресетах с трассировкой сразу же включен DLSS в режиме Авто. Это стоит учитывать.
Итак, на что способны наши видеокарты?
Читайте также: