
График битового поля не поддерживается процессором
Обновлено: 06.07.2024
Битовое поле системного программирования Linux (битовое поле) структуры C
При хранении некоторой информации она не обязательно должна занимать полный байт, а только несколько или один двоичный бит. Например, при сохранении значения переключателя есть только два состояния: 0 и 1, просто используйте один двоичный бит. Чтобы сэкономить место для хранения и упростить обработку, язык C предоставляет структуру данных, называемую «битовым полем» или «битовым сегментом». Так называемое «битовое поле» предназначено для разделения двоичных битов в байте на несколько различных областей и определения количества битов в каждой области. У каждого домена есть доменное имя, которое позволяет вам работать с доменным именем в программе. Таким образом, несколько различных объектов могут быть представлены однобайтовым двоичным битовым полем.
1. Определение битового поля и описание переменных битового поля.
Определение битового поля аналогично определению структуры и имеет следующую форму:
Форма списка битовых полей:
Описание переменных битового поля такое же, как и у структурных переменных. Эти три метода можно использовать, чтобы сначала определить, а затем объяснить, определить и объяснить одновременно или напрямую объяснить. Например:
Объясните, что данные - это переменная bs, занимающая всего два байта. Среди них битовое поле a занимает 8 битов, битовое поле b занимает 2 бита, а битовое поле c занимает 6 бит. Определение битового поля имеет следующие моменты:
1. Битовое поле должно храниться в одном байте и не может занимать два байта.
Если оставшегося места в одном байте недостаточно для хранения другого битового поля, битовое поле должно быть сохранено из следующего блока. Вы также можете намеренно начать битовое поле со следующего блока. Например:
2. Поскольку битовое поле не может занимать два байта, длина битового поля не может быть больше длины одного байта.
3. Битовое поле может быть безразрядным доменным именем, в настоящее время оно используется только для заполнения или корректировки позиции. Безымянные битовые поля использовать нельзя. Например:
например:
Пример общей структурной памяти:
Анализ: (номер выравнивания по умолчанию - 8 в VS, 4 в Linux, а следующая среда - VS)
1. Первый член a в структуре размещен по смещению 0, a имеет тип double, который занимает 8 байтов, а номер выравнивания равен 8, начиная со смещения 0 и идя назад, 0-7.
2. b занимает 1 байт, номер выравнивания - 1 (собственный размер b - 1, значение по умолчанию - 8, меньшее значение - 1, то есть число выравнивания - 1), 8 - кратно 1, поэтому начните с смещения 8 Положите, 8.
3.c занимает 4 байта, номер выравнивания 4, 9-11 - отходы, начиная с 12 ставим c, 12-15.
4.d занимает 4 байта, номер выравнивания 4, 16 кратно 4, начиная с 16, 16-19.
5.0-19 - это 20 байтов, максимальное число выравнивания - 8, минимальное кратное 8 - 24, а 20-24 - пустая трата.
6. Следовательно, размер конструкции равен 24.

Расчет размера битового сегмента и метода хранения компьютера:
(1) Тип члена битового сегмента должен быть указан как тип без знака или int.
(2) Битовый сегмент должен храниться в одном блоке памяти и не может охватывать два блока. Если первое пространство блока не может вместить следующий битовый сегмент, пространство не используется, и битовый сегмент сохраняется из следующего блока.
(3) Могут быть определены безымянные битовые сегменты.
(4) Из рисунка видно, как хранится битовый сегмент. A, b и c помещаются в блок памяти размером 4 байта, а оставшееся пространство не может уместиться в d, и помещаются в следующий блок хранения, занимающий 4 байта. Всего 8 байт.

Во-вторых, использование битовых полей
Вывод на 32-битную машину x86:
Парсинг: По умолчанию, чтобы облегчить доступ и управление элементами в структуре, когда длина элементов в структуре меньше, чем количество бит в процессоре, единица измерения является самым длинным элементом в структуре, то есть структурой. Длина должна быть целым числом, кратным самому длинному элементу данных; если существует элемент, длина структурной памяти которого больше, чем количество бит процессора, то количество бит процессора является единицей выравнивания. Поскольку это 32-разрядный процессор, а типы элементов a и b в структуре - int (также 4 байта), объем памяти A структуры составляет 4 байта.
Структура битового поля A определена в приведенном выше примере программы. Два битовых поля - это a (занимает 5 бит) и b (занимает 3 бита), поэтому a и b занимают в общей сложности один байт структуры A (младший байт) .
Когда программа переходит к строке 14, выделение памяти d:
D.a Двоичное представление в памяти - 10000. Так как d.a является целочисленной переменной со знаком, знаковый бит должен быть расширен при выводе, поэтому результат будет -16 (двоичное - 111111111111111111111111110000)
D.b Двоичное представление в памяти - 001. Поскольку d.b является целочисленной переменной со знаком, знаковый бит должен быть расширен при выводе, поэтому результат равен 1 (двоичный файл - 00000000000000000000000000000001)
В-третьих, выравнивание битовых полей
Если структура содержит битовое поле, то критерии в VC следующие:
1) Если соседние поля битовых полей имеют один и тот же тип, а сумма их битовой ширины меньше, чем размер типа, следующие поля будут храниться рядом с предыдущим полем до тех пор, пока его нельзя будет разместить;
2) Если соседние поля битовых полей имеют один и тот же тип, но сумма их битовой ширины больше, чем размер типа, следующие поля будут начинаться с новой единицы хранения со смещением, которое является целым кратным размеру типа;
3) Если типы смежных полей битовых полей различны, конкретная реализация каждого компилятора отличается. VC6 принимает режим без сжатия (разные поля битовых полей хранятся в байтах разных типов битовых полей), Dev-C ++ и GCC Все используют метод сжатия;
Система сначала выделит пространство и заполнение для элементов структуры в соответствии с выравниванием, а затем выполнит операции с битовыми полями для переменных.
В-четвертых, битовое поле и тип данных uint8_t uint16_t uint32_t uint64_t size_t ssize_t
Кажется, что в языке C нет такого типа данных, но в процессе практического применения обнаруживается, что этот способ выражения существует во многих кодах людей. Фактически, uintX-t определяется typedef. Использование предварительной компиляции и typedef может повысить эффективность и облегчить миграцию кода. Резюмируется следующим образом:
Typedef unsigned char uint8_t; // 8 цифр без знака
Typedef signed char int8_t; // Подписанные 8 цифр
Typedef unsigned int uint16_t; // 16 цифр без знака
Typedef signed int16_t; // 16 цифр со знаком
Typedef unsigned long uint32_t; // 32 цифры без знака
Typedef signed long int32_t; // 32 цифры со знаком
Typedef float float32; // число одинарной точности с плавающей запятой
Typedef double float64; // число двойной точности с плавающей запятой
Вообще говоря, тип * _t, соответствующий формированию:
uint8_t - 1 байт
Оказывается, кроме полей размером, кратным байту, мы можем в структурах (а также, конечно, и в объединениях) работать с битами, то есть мы можем объявить поле в какое-то количество бит. Хотя язык C не предусматривает операции с отдельным битом, но с помощью битовых полей это ограничение можно обойти. Это, конечно же, не является полной заменой битовых операций ассемблера, но для удобства работы с кодом, для его читабельности, мы это вполне можем применять.
Также, если мы и не будем в своих кодах применять битовые поля, то нам такое может попасться в чужих кодах, и после данного урока мы будем хотя бы знать, что это такое.
Также битовые поля нам могут потребоваться для каких-то флагов, для каких-то значений, диапазон которых отличается от диапазона стандартных типов.
Битовое поле в структуре объявляется следующим образом

В различной литературе я читал про разные ограничения типов для битовых полей. Видимо, всё это исходит из различных стандартов, выходящих время от времени. Поэкспериментировав немного, я понял, что самое главное, чтобы этот тип был целочисленным.
Если в структуре есть и битовые поля и обычные поля, то лучше битовые поля располагать подряд и стараться их не чередовать с обычными для того, чтобы меньше потребовалось памяти под структуру. Также по возможности выравнивание полей тоже лучше отключить. Можно и оставить, если, конечно, у нас в сумме размер всех битовых полей, идущих подряд в структуре будет стремиться к 32.
Вот пример объявления битовых полей в структуре, которой есть и обычные поля
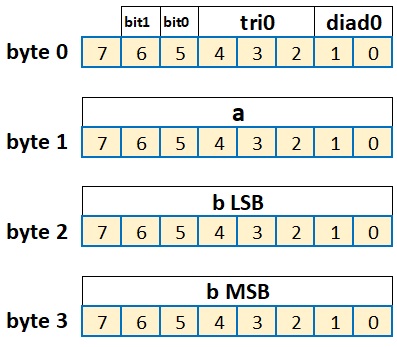
typedef struct
unsigned char diad0 :2;
unsigned char tri0 :3;
unsigned char bit0 :1;
unsigned char bit1 :1;
unsigned char a ;
unsigned short b ;
> my_arg_t ;
Так как мы отключили выравнивание, то под переменную такой структуры будет выделена память в 4 байта.
Небольшое выравнивание в данном случае все равно произойдёт, так как если посчитать суммарное количество битов в битовых полях, то их у нас 7, а не 8, то есть если количество битов в непрерывно следующих битовых полях в структуре не кратно восьми, то следующее за ним небитовое обычное поле будет выравниваться по биту следующего адреса, так как адресоваться в битах мы не можем.
В случае конкретной структуры, которую мы только что объявили поля её расположатся в памяти следующим образом
Думаю, теперь немного прояснилась картина по битовым полям.
Ну а чтобы она совсем прояснилась, давайте поработаем с ними на практике.
Поэтому давайте приступим к проекту, который мы сделаем, как всегда, из проекта прошлого урока с именем MYPROG31 и присвоим ему имя MYPROG32.
Откроем наш проект в Eclipse, произведём его первоначальную настройку и удалим весь наш код из функции main() за исключением возврата. Функция main() приобретёт вот такой вид
int main()
return 0; //Return an integer from a function
Глобальное объединение my_arg_t и одноимённую закомментированную структуру также удалим и добавим вместо них структуру с битовыми полями, точь в точь такую же, как в теоретической части
Недавно познакомился со структурами C/C++ — struct. Господи, да «что же с ними знакомиться» скажете вы? Тем самым вы допустите сразу 2 ошибки: во-первых я не Господи, а во вторых я тоже думал что структуры — они и в Африке структуры. А вот как оказалось и — нет. Я расскажу о нескольких жизненно-важных подробностях, которые кого-нибудь из читателей избавят от часовой отладки…

Выравнивание полей в памяти
Обратите внимание на структуру:
Ну во-первых какой у этой структуры размер в памяти? sizeof(Foo) ?
Размер этой структуры в памяти зависит от настроек компилятора и от директив в вашем коде…
В общем выравниваются в памяти поля по границе кратной своему же размеру. То есть 1-байтовые поля не выравниваются, 2-байтовые — выравниваются на чётные позиции, 4-байтовые — на позиции кратные четырём и т.д. В большинстве случаев (или просто предположим что сегодня это так) выравнивание размера структуры в памяти составляет 4 байта. Таким образом, sizeof(Foo) == 8 . Где и как прилепятся лишние 3 байта? Если вы не знаете — ни за что не угадаете…
- 1 байт: ch
- 2 байт: пусто
- 3 байт: пусто
- 4 байт: пусто
- 5 байт: value[0]
- 6 байт: value[1]
- 7 байт: value[2]
- 8 байт: value[3]
Оно выглядит вот так:
- 1 байт: ch
- 2 байт: пусто
- 3 байт: id[0]
- 4 байт: id[1]
- 5 байт: value[0]
- 6 байт: value[1]
- 7 байт: value[2]
- 8 байт: value[3]
Посмотрим на размещение полей в памяти:
- 1 байт: ch
- 2 байт: пусто
- 3 байт: id[0]
- 4 байт: id[1]
- 5 байт: opt[0]
- 6 байт: opt[1]
- 7 байт: пусто
- 8 байт: пусто
- 9 байт: value[0]
- 10 байт: value[1]
- 11 байт: value[2]
- 12 байт: value[3]
Мы установили размер выравнивания в 1 байт, описали структуру и вернули предыдущую настройку. Возвращать предыдущую настройку — категорически рекомендую. Иначе всё может закончиться очень плачевно. У меня один раз такое было — падало Qt. Где-то заинклюдил их .h-ник ниже своего .h-ника…
Битовые поля
В комментариях мне указали на то, что битовые поля в структурах по стандарту являются «implementation defined» — потому их использования лучше избежать, но для меня соблазн слишком велик.
Мне становится не то что неспокойно на душе, а вообще становится хреново, когда я вижу в коде заполнение битовых полей при помощи масок и сдвигов, например так:
Всё это пахнет такой печалью и такими ошибками и их отладкой, что у меня сразу же начинается мигрень! И тут из-за кулис выходят они — Битовые Поля. Что самое удивительное — были они ещё в языке C, но кого ни спрашиваю — все в первый раз о них слышат. Этот беспредел надо исправлять. Теперь буду давать им всем ссылку, ну или хотя бы ссылку на эту статью.
Как вам такой кусок кода:
А дальше в коде мы можем работать с полями как и всегда работаем с полями в C/C++. Всю работу по сдвигам и т.д. берет на себя компилятор. Конечно же есть некоторые ограничения… Когда вы перечисляете несколько битовых полей подряд, относящихся к одному физическому полю (я имею ввиду тип который стоит слева от имени битового поля) — указывайте имена для всех битов до конца поля, иначе доступа к этим битам у вас не будет, иными словами кодом:
Получилась структура на 4 байта! Две половины первого байта — это поля a и b . Второй байт не доступен по имени и последние 2 байта доступны по имени c . Это очень опасный момент. После того как описали структуру с битовыми полями обязательно проверьте её sizeof !
Также порядок размещения битовых болей в байте зависит от порядка байтов. При порядке LITTLE_ENDIAN битовые поля раздаются начиная со первых байтов, при BIG_ENDIAN — наоборот…
Порядок байтов
Меня также печалят в коде вызовы функций htons() , ntohs() , htonl() , nthol() в коде на C++. На C это ещё допустимо, но не на С++. С этим я никогда не смирюсь! Внимание всё нижесказанное относится к C++!
Ну тут я буду краток. Я в одной из своих предыдущих статей уже писал что нужно делать с порядками байтов. Есть возможность описать структуры, которые внешне работают как числа, а внутри сами определяют порядок хранения в байтах. Таким образом наша структура IP-заголовка будет выглядеть так:
Внимание собственно обращать на типы 2-байтовых полей — u16be . Теперь поля структуры не нуждаются ни в каких преобразованиях порядка байт. Остаются проблемы с fragment_offset , ну а у кого их нет — проблем-то. Тем не менее тоже можно придумать шаблон, прячущий это безобразие, один раз его оттестировать и смело использовать во всём своём коде.
«Язык С++ достаточно сложен, чтобы позволить нам писать на нём просто» © Как ни странно — Я
З.Ы. Планирую в одной из следующих статей выложить идеальные, с моей точки зрения, структуры для работы с заголовками протоколов стека TCP/IP. Отговорите — пока не поздно!
О бъединения в си похожи на структуры, с той разницей, что все поля начинаются с одного адреса. Это значит, что размер объединения равен размеру самого большого его поля. Так как все поля начинаются с одного адреса, то их значения перекрываются. Рассмотрим пример:
Здесь было создано объединение, которое содержит три поля – одно поле целого типа (4 байта), два поля типа short int (2 байта каждое) и 4 поля по одному байту. После того, как значение было присвоено полю dword, оно также стало доступно и остальным полям.
Напоминаю, что на x86 байты располагаются справа налево. Все поля объединения "обладают" одинаковыми данными, но каждое поле имеет доступ только до своей части.
Вот ещё один пример: рассмотрим представление числа с плавающей точкой:
Обратите внимание, что объединение можно инициализировать, как и структуру. При этом значение будет приводиться к типу, который имеет самое первое поле. Сравните результаты работы
Битовые поля
Битовые поля в си объявляются с помощью структур. Они позволяют получать доступ до отдельных битов или групп битов. Доступ до отдельных битов можно осуществлять и с помощью битовых операций, но использование битовых полей часто упрощает понимание программы.
Синтаксис объявления битового поля
В этом примере каждое поле структуры обозначено как битовое поле, длина каждого поля равна единице. Обращаться к каждому полю можно также, как и к полю обычной структуры. Битовые поля имеют тип unsigned int, так как имеют длину один бит. Если длина поля больше одного бита, то поле может иметь и знаковый целый тип.
Размер структуры, содержащей битовые поля, всегда кратен 8. То есть, если одно поле содержит 5 бит, а второе 4, то второе поле начинается с восьмого бита и три бита остаются неиспользованными.
Неименованное поле может иметь нулевой размер. В этом случае следующее за ним поле смещается так, чтобы добрать до 8 бит.
Если же адрес поля уже кратен 8 битам, то нулевое поле не добавит сдвига.
Кроме того, если имеются обычные поля и битовые поля, то первое битовое поле будет сдвинуто так, чтобы добрать до 8 бит.
В этих примерах видно, что структура добирает даже не до 8 бит, а больше - до адреса, кратного 4 байтам. Работать подобным образом, инициализируя каждое поле по отдельности, неудобно. Поэтому структуры с битовыми полями делают полем объединения, например:
Те же самые действия можно было сделать и с помощью обычного сдвига
Рассмотрим ещё один пример – знакопостоянный сдвиг вправо. Сдвиг вправо (>>) выталкивает самый левый бит и справа записывает ноль. Из-за этого операцию сдвига вправо нельзя применить, например, для чисел со знаком, так как будет потерян бит знака. Исправим ситуацию, сделаем знакопостоянный сдвиг: будем проверять последний бит числа (напомню, что мы работаем с архитектурой x86 и биты расположены «задом наперёд»)
Здесь я специально использовал тип int32_t (библиотека stdint.h), чтобы гарантировать размер переменных в 32 бита. Теперь можно вызвать функцию и посмотреть результат.

Читайте также: