
Как загрузить файлы на гугл диск python
Обновлено: 06.07.2024
Решил написать достаточно подробную инструкцию о том как работать с API Google Drive v3 с помощью клиентской библиотеки Google API для Python. Статья будет полезна тем, кому приходится часто работать с документами в Google Drive: скачивать и загружать новые документы, удалять файлы, создавать папки.
Также я покажу пример того как можно с помощью API скачивать файлы Google Sheets в формате Excel, или наоборот: заливать в Google Drive файл Excel в виде документа Google Sheets.
Использование API Google Drive может быть полезным для автоматизации различной рутины, связанной с отчетностью. Например, я использую его для того, чтобы по расписанию загружать заранее подготовленные отчеты в папку Google Drive, к которой есть доступ у конечных потребителей отчетов.
Все примеры на Python 3.
Создание сервисного аккаунта и получение ключа
Прежде всего создаем сервисный аккаунт в консоли Google Cloud и для email сервисного аккаунта открываем доступ на редактирование необходимых папок. Не забудьте добавить в папку файлы, если их там нет, потому что файл нам понадобится, когда мы будем выполнять первый пример — скачивание файлов из Google Drive.
Я записал небольшой скринкаст, чтобы показать как получить ключ для сервисного аккаунта в формате JSON.
Установка клиентской библиотеки Google API и получение доступа к API
Сначала устанавливаем клиентскую библиотеку Google API для Python
Дальше импортируем нужные модули или отдельные функции из библиотек.
Ниже будет небольшое описание импортируемых модулей. Это для тех кто хочет понимать, что импортирует, но большинство просто может скопировать импорты и вставить в ноутбук :)
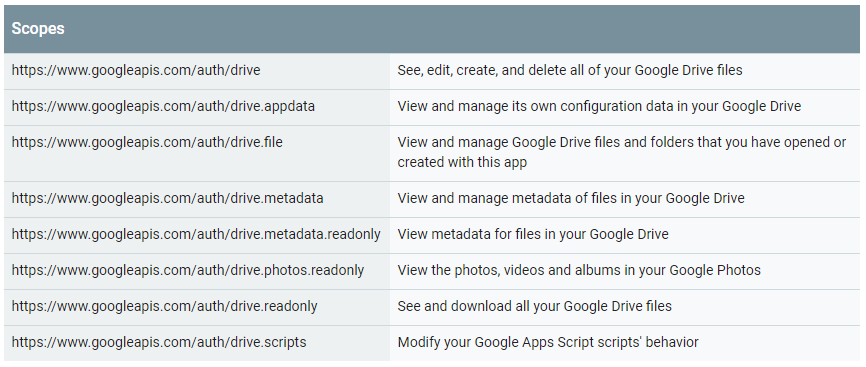
Указываем Scopes. Scopes — это перечень возможностей, которыми будет обладать сервис, созданный в скрипте. Ниже приведены Scopes, которые относятся к API Google Drive (из официальной документации):
Также указываем в переменной SERVICE_ACCOUNT_FILE путь к файлу с ключами сервисного аккаунта.
Создаем Credentials (учетные данные), указав путь к сервисному аккаунту, а также заданные Scopes. А затем создаем сервис, который будет использовать 3ю версию REST API Google Drive, отправляя запросы из-под учетных данных credentials.
Получение списка файлов
Теперь можно получить список файлов и папок, к которым имеет доступ сервис. Для этого выполним запрос list, выдающий список файлов, со следующими параметрами:
Получили вот такие результаты:

Получив из результатов nextPageToken мы можем передать его в следущий запрос в параметре pageToken, чтобы получить результаты следующей страницы. Если в результатах будет nextPageToken, это значит, что есть ещё одна или несколько страниц с результатами

Таким образом, мы можем сделать цикл, который будет выполняться до тех пор, пока в результатах ответа есть nextPageToken. Внутри цикла будем выполнять запрос для получения результатов страницы и сохранять результаты к первым полученным результатам
Дальше давайте рассмотрим какие ещё поля можно использовать для списка возвращаемых файлов. Как я уже писал выше, со всеми полями можно ознакомиться по ссылке. Давайте рассмотрим самые полезные из них:
- parents — ID папки, в которой расположен файл/подпапка
- createdTime — дата создания файла/папки
- permissions — перечень прав доступа к файлу
- quotaBytesUsed — сколько места от квоты хранилища занимает файл (в байтах)
Отобразим один файл из результатов с расширенным списком полей. Как видно permissions содержит информацию о двух юзерах, один из которых имеет role = owner, то есть владелец файла, а другой с role = writer, то есть имеет право записи.

Очень удобная штука, позволяющая сократить количество результатов в запросе, чтобы получать только то, что действительно нужно — это возможность задать параметры поиска для файлов. Например, мы можем задать в какой папке искать файлы, зная её id:

С синтаксисом поисковых запросов можно ознакомиться в документации. Ещё один удобный способ поиска нужных файлов — по имени. Вот пример запроса, где мы ищем все файлы, содержащие в названии «data»:

Условия поиска можно комбинировать. Возьмем условие поиска в папке и совместим с условием поиска по названию:

Скачивание файлов из Google Drive
Теперь рассмотрим как скачивать файлы из Google Drive. Для этого нам понадобится создать запрос request для получения файла. После этого задаем интерфейс fh для записи в файл с помощью библиотеки io, указав в filename название файла (таким образом, можно сохранять файлы из Google Drive сразу с другим названием). Затем создаем экземпляр класса MediaIoBaseDownload, передав наш интерфейс для записи файла fh и запрос для скачивания файла request. Следующим шагом скачиваем файл по небольшим кусочкам (чанкам) с помощью метода next_chunk.
Если из предыдущего описания вам мало что понятно, не запаривайтесь, просто укажите свой file_id и filename, и всё у вас будет в порядке.
Файлы Google Sheets или Google Docs можно конвертировать в другие форматы, указав параметр mimeType в функции export_media (обратите внимание, что в предыдущем примере скачивания файла мы использоали другую функцию get_media). Например, файл Google Sheets можно конвертировать и скачать в виде файла Excel.
Затем скачанный файл можно загнать в датафрейм. Это достаточно простой способ получить данные из Google Sheet в pandas-dataframe, но есть и другие способы, например, воспользоваться библиотекой gspread.

Загрузка файлов и удаление в Google Drive
Рассмотрим простой пример загрузки файла в папку. Во-первых, нужно указать folder_id — id папки (его можно получить в адресной строке браузера, зайдя в папку, либо получив все файлы и папки методом list). Также нужно указать название name, с которым файл загрузится на Google Drive. Это название может быть отличным от исходного названия файла. Параметры folder_id и name передаем в словарь file_metadata, в котором задаются метаданные загружаемого файла. В переменной file_path указываем путь к файлу. Создаем объект media, в котором будет указание по какому пути находится загружаемый файл, а также указание, что мы будем использовать возобновляемую загрузку, что позволит нам загружать большие файлы. Google рекомендует использовать этот тип загрузки для файлов больше 5 мегабайт. Затем выполняем функцию create, которая позволит загрузить файл на Google Drive.

Как видно выше, при вызове функции create возвращается id созданного файла. Можно удалить файл, вызвав функцию delete. Но мы этого делать не будет так как файл понадобится в следующем примере
Сервисный аккаунт может удалить ли те файлы, которые были с помощью него созданы. Таким образом, даже если у сервисного аккаунта есть доступ на редактирование папки, то он не может удалить файлы, созданные другими пользователями. Понять что файл был создан помощью сервисного аккаунта можно задав поисковое условие с указанием email нашего сервисного аккаунта. Узнать email сервисного аккаунта можно вызвав атрибут signer_email у объекта credentials


Дальше — больше. С помощью API Google Drive мы можем загрузить файл с определенным mimeType, чтобы Drive понял к какому типу относится файл и предложил соответствующее приложение для его открытия.

Но ещё более классная возможность — это загрузить файл одного типа с конвертацией в другой тип. Таким образом, мы можем залить csv файл из примера выше, указав для него тип Google Sheets. Это позволит сразу же конвертировать файл для открытия в Гугл Таблицах. Для этого надо в словаре file_metadata указать mimeType «application/vnd.google-apps.spreadsheet».

Таким образом, загруженный нами CSV-файл будет доступен как Гугл Таблица:

Ещё одна часто необходимая функция — это создание папок. Тут всё просто, создание папки также делается с помощью метода create, надо только в file_metadata указать mimeType «application/vnd.google-apps.folder»

Заключение
Все содержимое этой статьи также представлено в виде ноутбука для Jupyter Notebook.
В этой статье мы рассмотрели лишь немногие возможности API Google Drive, но одни из самых необходимых:
- Просмотр списка файлов
- Скачивание документов из Google Drive (в том числе, скачивание с конвертацией, например, документов Google Sheets в формате Excel)
- Загрузка документов в Google Drive (также как и в случае со скачиванием, с возможностью конвертации в нативные форматы Google Drive)
- Удаление файлов
- Создание папок
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.

Google Colaboratory — бесплатная среда Jupyter Notebook, которая выполняется на облачных серверах Google и позволяет использовать аппаратное оборудование бэкенда, например GPU and TPU. В результате вы можете работать со всеми возможностями Jupyter Notebook, не устанавливая его на локальной машине.
Colab поставляется (почти) со всеми настройками, позволяющими начать процесс программирования, за исключением датасетов. Как же с помощью Colab получить к ним доступ?
В данной статье мы рассмотрим:
- как загружать данные в Colab из разных источников;
- как произвести обратную запись из Colab в эти источники данных;
- ограничения Google Colab при работе с внешними файлами.
Операции с директориями и файлами в Google Colab
Поскольку Colab позволяет делать все, что угодно, в локально размещенном Jupyter Notebook, то появляется возможность работать с командами оболочки, такими как ls , dir , pwd , cd , cat , echo и т.д., с помощью магической команды для строки ( % ) или bash-команды ( ! ).
Для просмотра структуры директории воспользуйтесь панелью файлового менеджера слева.
Как загружать и скачивать файлы в/из Google Colab
Поскольку блокнот Colab размещается на облачных серверах Google, то по умолчанию отсутствует прямой доступ к файлам на вашем локальном диске (в отличие от расположенного на компьютере блокнота) или в любой другой среде.
Однако Colab предоставляет разные варианты подключения к практически любому источнику данных. Посмотрим, как это происходит.
Обращение к GitHub из Google Colab
Вы можете либо клонировать весь репозиторий GitHub в среду Colab, либо получить доступ к отдельным файлам по их необработанной ссылке.
Клонирование репозитория GitHub
Клонирование репозитория Github в среду Colab происходит по такому же принципу, как и на локальный компьютер, а именно с помощью git clone . По завершении этой процедуры обновите менеджер файлов для просмотра содержимого.
И теперь файлы можно читать точно так же, как и на локальном компьютере.
Скачивание отдельных файлов непосредственно с GitHub
Если для работы нужно лишь несколько файлов, а не весь репозиторий, то можно обойтись без его клонирования в Colab и скачать эти файлы непосредственно с GitHub.
- Кликните на файл в репозитории.
- Кликните на View Raw.
- Скопируйте URL необработанного файла.
- Используйте этот URL как местоположение файла.
Обращение к локальной файловой системе через Google Colab
Читать и записывать файлы из/в локальную файловую систему можно с помощью менеджера или кода Python.
Обращение к локальным файлам через менеджер файлов
Загрузка файлов из локальной файловой системы через менеджер
Для загрузки любых файлов из локальной файловой системы в текущую рабочую директорию Colab можно воспользоваться опцией Upload в верхней части панели менеджера файлов.
Для загрузки файлов напрямую в поддиректорию нужно:
- Кликнуть на три точки, появляющиеся при наведении курсора на каталог.
- Выбрать опцию Upload.
3. Выбрать файлы для загрузки из диалогового окна File Upload.
4. Подождать завершения загрузки, процесс выполнения которой отображается в нижней части панели менеджера файлов.
По окончании процесса загрузки читать файлы можно привычным для вас способом.
Скачивание файлов в локальную файловую систему через менеджер файлов
Кликните на три точки, появляющиеся при наведении курсора на имя файла и выберите опцию Download.
Обращение к локальной файловой системе посредством кода Python
Для осуществления этого шага предварительно требуется импортировать модуль files из google.colab library :
Загрузка файлов из локальной файловой системы посредством кода Python
Применяем метод загрузки объекта files :
В результате открывается диалоговое окно File Upload:
Выбираем файлы для загрузки и ждем завершения. Ход ее выполнения отображается:
Объект uploaded является словарем, где имена файлов и их содержимое хранятся в виде пар “ключ-значение”:
По окончании загрузки считать его можно точно так же, как и любой другой файл из Colab:
Также есть способ считать его напрямую из директории uploaded , используя библиотеку io :
Убедитесь, что имя файла соответствует тому файлу, который вы хотите скачать.
Скачивание файлов из Colab в локальную систему посредством кода Python
Применение метода download объекта files позволяет скачать любой файл из Colab на локальный диск. Процесс выполнения отображается, и по его завершении можно выбрать на локальном компьютере место для сохранения файла.
Обращение к Google Диску из Google Colab
Рассмотрим пошагово, как с помощью модуля drive из google.colab можно смонтировать весь Google Диск в Colab:
1. Выполняем следующий код с целью получения ссылки для аутентификации:
2. Открываем ссылку.
3. Выбираем аккаунт Google, диск которого нужно смонтировать.
4. Разрешаем Google Drive Stream доступ к вашему аккаунту Google.
5. Копируем отображенный код, вставляем его в текстовое окно, как показано ниже, и нажимаем Enter.
Теперь взаимодействовать с Google Диск можно точно так же, как и с каталогом в среде Colab. Любые изменения, связанные с этим каталогом, будут сразу же отображаться на Google Диске, файлы которого вы можете читать как и любые другие.
Кроме того, можно даже напрямую делать запись из Colab на Google Диск, применяя обычные операции с файлами/каталогами.
Эта команда создаст файл на Google Диске, который отобразится на панели менеджера файлов при ее обновлении:
Обращение к Google Таблицам из Google Colab
Для обращения к Google Таблицам:
- Прежде всего, необходимо аутентифицировать аккаунт для соединения с Colab. С этой целью выполняем следующий код:
2. В результате получаем ссылку для аутентификации и открываем ее.
3. Выбираем аккаунт Google для соединения.
4. Разрешаем Google Cloud SDK доступ к вашему аккаунту Google.
5. Наконец, копируем отображаемый код, вставляем его в текстовое окно и нажимаем Enter.
Для взаимодействия с Google Таблицами потребуется импортировать предустановленную библиотеку gspread. Чтобы разрешить ей доступ к вашему аккаунту Google воспользуемся методом GoogleCredentials из предустановленной библиотеки oauth2client.client:
После выполнения кода в текущей рабочей директории будет создан файл adc.json с учетными данными, которые нужны gspread для получения доступа к вашему аккаунту Google.
Теперь создавайте или скачивайте Google таблицы напрямую из среды Colab.
Создание/обновление Google таблицы в Colab
- Создаем рабочую книгу с помощью метода create объекта gc :
3. Прежде всего, открываем рабочую книгу для записи в нее значений:
4. Затем выбираем ячейки для заполнения:
5. Таким образом мы создаем список ячеек с индексами (R1C1) и значениями (на данный момент пустыми). Можно изменить отдельные ячейки, обновив их атрибут значения:
6. Для обновления этих ячеек в рабочей таблице применяем метод update_cells :
7. Все изменения отображаются в вашей Google таблице.
Скачивание данных из Google таблицы
1. Открываем рабочую книгу с помощью метода open объекта gc :
2. Затем считываем все строки отдельной рабочей таблицы, задействуя метод get_all_values :
3. Для загрузки этих данных в датафрейм задействуем метод from_record объекта DataFrame :
Обращение к Google Cloud Storage (GCS) из Google Colab
Для работы с GCS необходим проект Google Cloud (GCP). Вы можете создавать и подключаться к корзинам GCS в Colab через предустановленную утилиту командной строки gsutil .
1. Сначала указываем ID проекта:
2. Для доступа к GCS проводим аутентификацию вашего аккаунта Google:
3. Выполнив вышеуказанный код, получаем ссылку для аутентификации и открываем ее.
4. Выбираем аккаунт Google для соединения.
5. Разрешаем доступ Google Cloud SDK к вашему аккаунту Google.
6. Теперь копируем отображаемый код, вставляем его в текстовое окно и нажимаем Enter.
7. Затем настраиваем gsutil для работы с проектом:
8. Вы можете создать корзину с помощью соответствующей команды mb (“make bucket”). У корзин GCP должны быть универсальные уникальные имена, поэтому воспользуемся предустановленной библиотекой uuid для создания такого рода ID:
9. Как только корзина готова, загружаем в нее файл из среды Colab:
По завершении скачивания файл отображается на панели менеджера файлов в Colab в указанном месте.
Обращение к AWS S3 из Google Colab
Для доступа к S3 из Colab потребуется создать аккаунт AWS, настроить IAM, а также сгенерировать ключ доступа и секретный ключ доступа. Необходимо также установить библиотеку awscli в среду Colab:
1. Устанавливаем библиотеку awscli:
2. После установки запускаем настройку AWS командой aws configure :
3. Вводим access_key и secret_access_key в текстовое окно и нажимаем Enter:
Теперь можно скачивать любые файлы из S3:
filepath_on_s3 позволяет указать один файл или подобрать несколько файлов по шаблону.
Вам придет уведомление о завершении скачивания, после чего файлы будут доступны в заданном месте для дальнейшего использования.
Для загрузки файла просто поменяйте местами аргументы источника и назначения:
file_to_upload позволяет указать один файл или подобрать несколько файлов по шаблону.
Обращение к датасетам Kaggle из Google Colab
Для скачивания датасетов из Kaggle требуется наличие аккаунта и API-токена.
4. После создания файла kaggle.json в Colab и установки библиотеки Kaggle приступаем к поиску датасета с помощью следующей команды:
5. Скачиваем нужный датасет с помощью команды:
Датасет будет загружен и доступен по указанному пути (в данном случае /content/kaggle/ ).
Обращение к базам данных MySQL из Google Colab
1. Для работы с реляционными базами данных необходимо импортировать предустановленную библиотеку sqlalchemy.
2. Вводим данные для подключения и создаем движок:
3. Создаем SQL-запрос и загружаем его результаты в датафрейм с помощью pd.read_sql_query() :
Ограничения Google Colab при работе с файлами
При работе с Colab важно помнить о том, что доступ к загружаемым файл ограничен по времени. Colab — это временная среда, в которой тайм-аут простоя составляет 90 минут, а абсолютный тайм-аут — 12 часов. Это значит, что отключение среды выполнения происходит в случае 90 минутного простоя или 12-ти часового использования. Такое отключение приводит к потери всех переменных, состояний, установленных пакетов и файлов, вследствие чего при повторном подключении вас ждет встреча с абсолютно новой и чистой средой.
Кроме того, дисковое пространство Colab ограничено 108 Гб, только 77 Гб из которых доступны пользователю. Этого объема достаточно для решения большинства задач, но вот при работе с крупными датасетами, например изображениями или видео, данное обстоятельство нельзя упускать из внимания.
Заключение
Google Colab — превосходный инструмент для тех, кто стремится обуздать мощь высокопроизводительных вычислительных ресурсов, таких как GPU, без оглядки на их стоимость.
В данной статье мы рассмотрели большинство способов, благодаря которым вы сможете максимально продуктивно работать с Google Colab, читая внешние файлы или данные в Google Colab и производя обратную запись из нее в эти внешние источники данных.
В зависимости от сценария использования или архитектуры данных вы можете запросто применять вышеописанные методы для подключения источника данных напрямую к Colab и приступать к программированию.
Каковы обычные способы импорта личных данных в записные книжки Google Colab Laboratory? Можно ли импортировать непубличный лист Google? Вы не можете читать из системных файлов. Вступительные документы ссылаются на руководство по использованию BigQuery , но это кажется немного . много.
Самый простой способ обмениваться файлами - это подключить ваш Google Drive.
Для этого запустите следующее в ячейке кода:
После этого ваши файлы с диска будут смонтированы, и вы сможете просматривать их с помощью браузера файлов на боковой панели.

Загрузить
Список каталогов
Простой способ импортировать данные из вашего googledrive - это экономит время людей (не знаю, почему Google просто не перечисляет этот шаг явным образом).
УСТАНОВИТЬ И АУТЕНТИФИЦИРОВАТЬ PYDRIVE
если вам нужно загрузить данные с локального диска:
выполнить, и это будет отображать кнопку выбора файла - найти файл загрузки - нажмите открыть
После загрузки отобразится:
СОЗДАТЬ ФАЙЛ ДЛЯ ЗАПИСИ
Если ваш файл данных уже находится в вашем gdrive, вы можете пропустить этот шаг.
Теперь это в вашем диске Google. Найдите файл на вашем диске Google и щелкните правой кнопкой мыши. Нажмите «поделиться ссылкой». Вы получите окно с:
Скопируйте - '29PGh8XCts3mlMP6zRphvnIcbv27boawn' - это идентификатор файла.
В вашей записной книжке:
ИМПОРТ ДАННЫХ В ЗАПИСЬ
Чтобы импортировать данные, которые вы загрузили в записную книжку (в этом примере файл json - способ загрузки будет зависеть от типа файла/данных - .txt, .csv и т.д.):
Теперь вы можете распечатать, чтобы увидеть данные там:
Самый простой способ, который я сделал, это:
- Сделайте репозиторий на GitHub с вашим набором данных
- Клонировать Ваш репозиторий с! git clone --recursive [GITHUB LINK REPO]
- Найдите, где находятся ваши данные (команда! Ls)
- Откройте файл с пандами, как вы делаете это в обычном блокноте Jupyter.
Это позволяет загружать ваши файлы через Google Drive.
Запустите приведенный ниже код (нашел это где-то ранее, но я не могу найти источник снова - кредиты тому, кто это написал!):
Нажмите на первую появившуюся ссылку, которая предложит вам войти в Google; после этого появится другое, которое попросит разрешения на доступ к вашему Google Диску.
Затем запустите этот файл, который создаст каталог с именем «drive» и свяжет с ним ваш Google Drive:
Если вы сделаете !ls сейчас, будет диск с каталогом, а если вы сделаете !ls drive , вы сможете увидеть все содержимое вашего Google Диска.
Так, например, если я сохраню свой файл с именем abc.txt в папке с именем ColabNotebooks на моем Google Диске, я теперь могу получить к нему доступ через путь drive/ColabNotebooks/abc.txt
Быстрый и простой импорт из Dropbox:
Шаг 1 - Подключите Google Drive к совместной работе
шаг 2 - Теперь вы увидите файлы вашего Google Диска на левой панели (Проводник). Щелкните правой кнопкой мыши по файлу, который нужно импортировать, и выберите «Копировать путь . ». Затем импортируйте как обычно в пандах, используя этот скопированный путь.
Самое простое решение, которое я нашел до сих пор и которое идеально подходит для CSV-файлов малого и среднего размера:
Это может или не может работать для чтения текстового файла построчно или двоичных файлов.
На левой панели любой колаборатории есть раздел "Файлы" . Загрузите туда свои файлы и используйте этот путь
Затем, если вы хотите загрузить все файлы в каталоге Google Drive, просто
Сегодня рассмотрим простой пример работы с Google Drive API. Почему именно данное API, потому что оно популярно. Как-то не так давно, мне пришлось разрабатывать кое-что подобное для нескольких студентов. Там использовались не только сервисы от Google, но и от других не менее известных компаний. Для упрощения статьи я решил опустить некоторые моменты по настройке, о которых можно прочитать на других сайтах. Но хватит вступления, приступим к рассмотрению моего примера.
Подготовка к работе
Первым делом Вам необходимо иметь учетную запись в Google. Затем надо будет подключить нужное нам API и получить секретный ключ и идентификатор клиента. Подключить Google Drive API можно в Google API Console. Не забывайте, что после включения API нужно будет создать новый проект. Здесь я лишь приведу примеры изображений, как настроено у меня.


В своей работе я буду использовать использовать библиотеку Google API Client Library for PHP. Если перейти по данной ссылке, то Вы найдете описание как установить зависимости через composer.
Для удобства всю логику приложения оставил в файле index.php.
Листинг файла index.php
Внимание!
Для методов $client->setClientId() и $client->setClientSecret() нужно установить значения, которые Вы возьмете из настроек своего проекта в Google API Console.
Дополнительно вынес рекурсивную функцию в отдельный класс, который расположен в файле BuildTree.php. По факту функцию можно было бы оставить в файле index.php, но планировалось немного большее, однако как всегда не хватило времени на реализацию.
Листинг файла BuildTree.php
Хочу отметить, что функция написана для PHP 7.0.
Листинг файла для отображения создания новой папки.
Листинг файла для отображения загрузки файлов.
Вот и все основные файлы. Если все сделали правильно, то должно работать. В конце статьи добавлю ссылку на архив (если кто-то не хочет заморачиваться с composer).
А вот и результаты мое работы. Как Вы заметили, в коде нет особых проверок, т.к. это всего лишь пример, а не реальный рабочий проект.
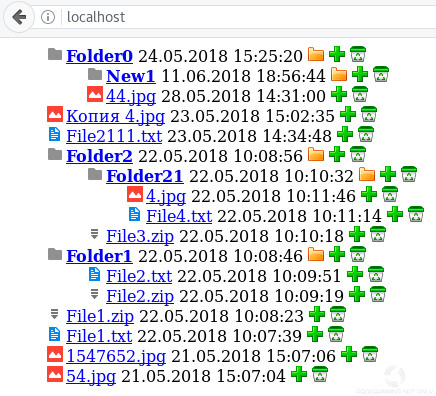
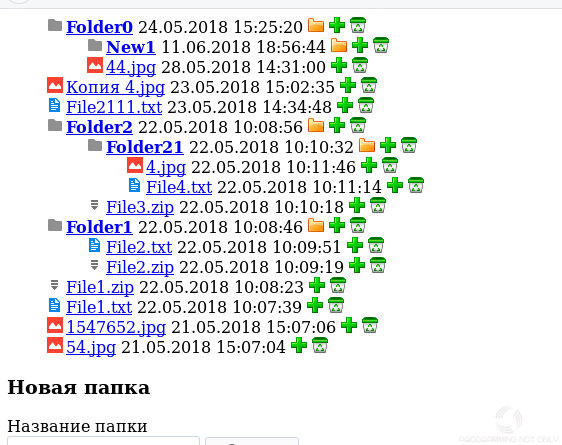
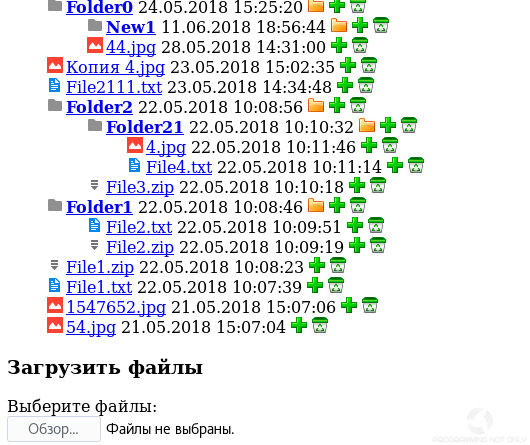
Если появились вопросы, пожалуйста, задавайте, а я постараюсь на них ответить. Спасибо и до новых встреч.
Полезные ссылки
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.

Чистый код для вебразработчика

Проверка PHP-кода онлайн
45 thoughts on “ Простая работа с Google Drive API ”
Вместо ***domain*** соответственно свой домен в котором лежит папка google-drive-amo.
Заранее благодарен!
Спасибо, помогла замена строки в файле BuildTree.php.
Сейчас след. ошибку возвращает гугл:
Так, разрешение акк получил. Теперь выдает след. ошибку:
PHP на сервере обновил до 7.0 версии.
1)var_dump($token]); возвращает: NULL
Да, видимо ошибка в скобке была (уже забил на это) . В сессии все норм было, авторизацию проходил успешно. В общем все работает прекрасно, спасибо огромное! Только у меня не заработало дерево элементов, но оно мне и не нужно было)
Добрый вечер, Денис! Подскажите пожалуйста для чего нужны ob_start(); и ob_end_flush(); ? Можно ли обойтись без них?
получаю белый пустой экран
$_SESSION[‘accessToken’] не пустой
разрешение предоставил
пару файликов на диске присутствуют
Добрый день! Да, всегда при проверке работы желательно включать вывод всех ошибок. Если ничего не выводится, то можно проверить выводимые данные с помощью отладочных функций. А так, специально для отладки здесь есть функция varDumper (хотя var_dump будет более подробной).
это оказался подключаемый файл
соответственно, для загрузки попробовал
получаю всегда File not found
Да, fid содержит идентификатор родителя, чтобы знать куда загрузить файл .
В любом случае, необходимо получить разрешение для работы с диском, как раз и будет возвращен токен. А уже потом каким образом и что будете Вы делать, решать только вам.
Если все выполнено правильно, то должно работать. Следует учитывать версию php, настройки сервера, ну и конечно, ваши данные для доступа к Google Drive (тут данные только для примера, хоть и реальные) .
вообще
на PHP 5.6 можно как то запустить?
по предыдущему отбой
мне BuildTree и не нужен, достаточно списка в том виде, что гугл отдаёт
Это пример. Данный класс действительно нужен только для построения дерева. Если дерево не нужно строить, то можно и обойтись без него
Это наверное по умолчанию 100 файлов отдается. Если не ошибаюсь, то можно указать от 1 до 1000. Также есть параметр pageToken в который нужно вставить маркер из предыдущего ответа nextPageToken.
Все в документации подробно описано здесь.
Дока это отлично, но как эти параметры задать?
туплю
$DriveService->files->pageSize(1000);
Fatal error: Call to undefined method Google_Service_Drive_Resource_Files::pageSize()
кто же запросы через fopen() дёргает?! пипец
Добрый день. Стандартная ситуация когда для получения данных используется fopen (старая и надежная функция для получения данных). Нет, зависимости, например от cUrl. Можете попробовать написать свой класс для работы с API, например через cUrl или еще как-то.
Да и это нормальный процесс, ошибки в разработке бывают. Нужно читать документация и смотреть, что передается и что возвращается.
друзья помогите настроить. чет не понимаю. залил скрипт. прописал setClientId и setClientSecret и кроме ошибки 500 не чего не получаю.
Доброго времени суток. Вы же понимаете, сложно сказать, что у вас не так по одной только 500 ошибке. Ошибка серверная, проверьте версию php, должна быть от 7. А так, функция var_dump() и die() для тестирования в помощь. Видимо не все условия выполнены как в статье.
Что здесь $tree = $buildTree->makeTree($files, ‘0AHCqnAQsA3IDUk9PVA’); надо прописать?
Вижу чужие файлы, своих не вижу.
Добрый день. Что же Вы не читаете комментарии к коду.
Читайте также: