
Какой параметр определяет список файлов на диске для размещения информации базы данных
Обновлено: 03.07.2024
Процесс создания базы данных в системе SQL-сервера состоит из двух этапов: сначала организуется сама база данных, а затем принадлежащий ей журнал транзакций. Информация размещается в соответствующих файлах, имеющих расширения *.mdf (для базы данных) и *.ldf. (для журнала транзакций). В файле базы данных записываются сведения об основных объектах (таблицах, индексах, просмотрах и т.д.), а в файле журнала транзакций – о процессе работы с транзакциями (контроль целостности данных, состояния базы данных до и после выполнения транзакций).
Создание базы данных в системе SQL-сервер осуществляется командой CREATE DATABASE. Следует отметить, что процедура создания базы данных в SQL-сервере требует наличия прав администратора сервера.
<определение_базы_данных> ::= CREATE DATABASE имя_базы_данных [ON [PRIMARY] [ <определение_файла> [. n] ] [,<определение_группы> [. n] ] ] [ LOG ON <<определение_файла>[. n] >] [ FOR LOAD | FOR ATTACH ]
Рассмотрим основные параметры представленного оператора.
При выборе имени базы данных следует руководствоваться общими правилами именования объектов. Если имя базы данных содержит пробелы или любые другие недопустимые символы, оно заключается в ограничители (двойные кавычки или квадратные скобки). Имя базы данных должно быть уникальным в пределах сервера и не может превышать 128 символов.
При создании и изменении базы данных можно указать имя файла, который будет для нее создан, изменить имя, путь и исходный размер этого файла. Если в процессе использования базы данных планируется ее размещение на нескольких дисках, то можно создать так называемые вторичные файлы базы данных с расширением *.ndf. В этом случае основная информация о базе данных располагается в первичном (PRIMARY) файле, а при нехватке для него свободного места добавляемая информация будет размещаться во вторичном файле. Подход, используемый в SQL-сервере, позволяет распределять содержимое базы данных по нескольким дисковым томам.
Параметр ON определяет список файлов на диске для размещения информации, хранящейся в базе данных.
Параметр PRIMARY определяет первичный файл. Если он опущен, то первичным является первый файл в списке.
Параметр LOG ON определяет список файлов на диске для размещения журнала транзакций. Имя файла для журнала транзакций генерируется на основе имени базы данных, и в конце к нему добавляются символы _log.
При создании базы данных можно определить набор файлов, из которых она будет состоять. Файл определяется с помощью следующей конструкции:
<определение_файла>::= ([ NAME=логическое_имя_файла,] FILENAME='физическое_имя_файла' [,SIZE=размер_файла ] [,MAXSIZE= ] [, FILEGROWTH=величина_прироста ] )[. n]
Здесь логическое имя файла – это имя файла, под которым он будет опознаваться при выполнении различных SQL-команд.
Физическое имя файла предназначено для указания полного пути и названия соответствующего физического файла, который будет создан на жестком диске. Это имя останется за файлом на уровне операционной системы.
Параметр SIZE определяет первоначальный размер файла; минимальный размер параметра – 512 Кб, если он не указан, по умолчанию принимается 1 Мб.
Параметр MAXSIZE определяет максимальный размер файла базы данных. При значении параметра UNLIMITED максимальный размер базы данных ограничивается свободным местом на диске.
При создании базы данных можно разрешить или запретить автоматический рост ее размера (это определяется параметром FILEGROWTH) и указать приращение с помощью абсолютной величины в Мб или процентным соотношением. Значение может быть указано в килобайтах, мегабайтах, гигабайтах, терабайтах или процентах (%). Если указано число без суффикса МБ, КБ или %, то по умолчанию используется значение MБ. Если размер шага роста указан в процентах (%), размер увеличивается на заданную часть в процентах от размера файла. Указанный размер округляется до ближайших 64 КБ.
Дополнительные файлы могут быть включены в группу:
<определение_группы>::=FILEGROUP имя_группы_файлов <определение_файла>[. n]
Пример 3.1. Создать базу данных, причем для данных определить три файла на диске C, для журнала транзакций – два файла на диске C.
CREATE DATABASE ArchiveON PRIMARY ( NAME=Arch1, FILENAME=’c:\user\data\archdat1.mdf’,SIZE=100MB, MAXSIZE=200, FILEGROWTH=20),(NAME=Arch2, FILENAME=’c:\user\data\archdat2.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20),(NAME=Arch3, FILENAME=’c:\user\data\archdat3.mdf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20)LOG ON(NAME=Archlog1, FILENAME=’c:\user\data\archlog1.ldf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20),(NAME=Archlog2, FILENAME=’c:\user\data\archlog2.ldf’, SIZE=100MB, MAXSIZE=200, FILEGROWTH=20)
В данном посте база SQLite будет рассмотрена в разрезе, вы можете найти информацию о строении файла базы данных, о представлении данных в памяти, а также информацию о структуре и файловом представлении В – дерева.
Формат файла базы данных
Вся база данных хранится в одном файле на диске под названием «main database file». Во время транзакций, SQLite хранит дополнительную информацию во втором файле: журнал отката (rollback journal), либо, если база работает в режиме WAL, лог-файл с информацией о записях. Если приложение или компьютер отключился до окончания транзакции, то данные файлы называются «hot journal» или «hot WAL file» и содержат необходимую информацию для восстановления базы в согласованное состояние.
Основной файл базы состоит из одной или нескольких страниц. Все страницы в одной базе имеют одинаковый размер, который может быть от 512 до 65536 байт. Размер страницы для файла базы определяется целым 2-ух байтовым числом со смещением 16 байт от начала файла базы данных.
Все страницы пронумерованы от 1 до 2147483646 (2^31 – 2). Минимальный размер базы: одна страница размеров 512 байт, максимальный размер базы: 2147483646 страниц по 65536 байт (
Заголовок
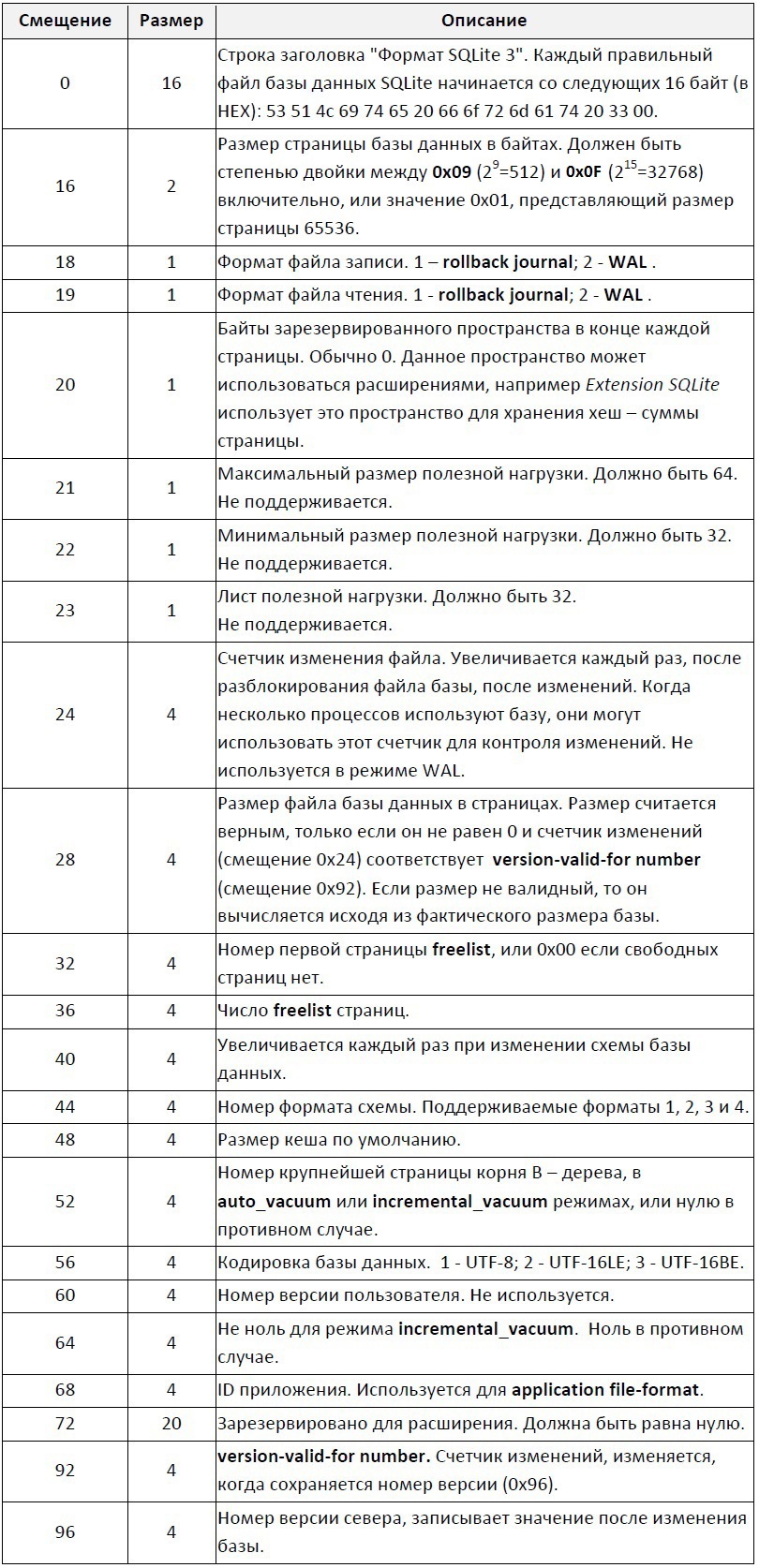
Первый 100 байт файла базы данных содержат заголовок базы, в таблице 1 представлена схема заголовка.
Lock-byte страница
Freelist
Список пустых страниц организован как связный список. Каждый элемент списка состоит из двух чисел по 4 байта. Первое число определяет номер следующего элемента freelist (trunk pointer), либо равняется нулю, если список кончился. Второе число, это указатель на страницу данных (Leaf page numbers). На рисунке ниже показана схема данной структуры.

B — tree
SQLite использует две вида деревьев: «table B – tree» (на листьях хранятся данные) и «index B – tree» (на листьях хранятся ключи).
Каждая запись в «table B – tree» состоит из 64-битового целое ключа и до 2147483647 байт произвольных данных. Ключ «table B – tree» соответствует ROWID таблицы SQL.
Каждая запись в «index B – tree» состоит из произвольного ключа до 2147483647 байт в длину.
- Заголовок файла базы данных (100 байт)
- Заголовок страницы B-дерева (8 или 12 байт)
- Массив указателей ячеек
- Незанятое пространство
- Содержимое ячейки
- Зарезервированное место
Заголовок файла базы данных встречается только на первой странице, которая всегда является старицей «table B – tree». Все остальные страницы B-дерева в базе не имеют этого заголовка.
Заголовок страницы B-дерева имеет размер 8 байт для страниц листьев и 12 байт для внутренних страниц. В таблице 2 представлена структура заголовка страницы.

Freeblock — это структура, используемая для определения незанятого пространства внутри страницы B-дерева. Freeblock организованы в виде цепочки. Первые 2 байта в freeblock (от старшего к младшему), это смещением до следующего freeblock, или ноль, если freeblock является последним в цепочке. Третий и четвертый байты – целое число, размер freeblock в байтах, включая заголовок в 4 байта. Freeblocks всегда связаны в порядке возрастания смещения.
Число фрагментированных байт – это общее число неиспользуемых байт в области содержимого ячейки.
Массив указателей ячеек состоит из K 2-байтовых целочисленных смещений содержимого ячеек (при K ячейках в B-дереве). Массив отсортирован по возрастанию (от наименьших ключей к наибольшим).
Незанятое пространство — это область между последней ячейкой массива указателей и началом первой ячейки.
Зарезервированное место в конце каждой страницы используется расширениями для хранения информации о странице. Размер зарезервированной области определяется в заголовке базы (по умолчанию равен нулю).
Representation
TABLE
TABLEWITHOUT ROWID
Каждая таблица (без ROWID) представляется в базе в виде index b — tree. Отличие от таблиц с rowid, заключается в том, что ключ каждой записи SQL таблицы хранится в виде record format, при чем столбцы ключа хранятся как указаны в PRIMARY KEY, а остальные в порядке указанном в объявлении таблицы.
Таким образом записи в index b — tree представляются также как и в table b — tree, кроме порядка столбцов и того, что содержание строки хранится в ключе дерева, а не в качестве данных на листьях как в table b — tree.
INDEX
Каждый индекс (объявленный CREATE INDEX, PRIMARY KEY или UNIQUE) представляется в базе в виду index b — tree. Каждая запись в таком дереве соответствует строки в SQL таблице. Ключ индексного дерева представляет собой последовательность значений столбцов указанных в индексе и завершается значением ключа строки (rowid или primary key) в record format.
UPD 13:44: переработан раздел Representation, спасибо за критику mayorovp (можно было конечно и пошевелиться, ну да ладно).
В различных СУБД процедура создания баз данных обычно закрепляется только за администратором баз данных . В однопользовательских системах принимаемая по умолчанию база данных может быть сформирована непосредственно в процессе установки и настройки самой СУБД. Стандарт SQL не определяет, как должны создаваться базы данных , поэтому в каждом из диалектов языка SQL обычно используется свой подход. В соответствии со стандартом SQL, таблицы и другие объекты базы данных существуют в некоторой среде. Помимо всего прочего, каждая среда состоит из одного или более каталогов , а каждый каталог – из набора схем . Схема представляет собой поименованную коллекцию объектов базы данных , некоторым образом связанных друг с другом (все объекты в базе данных должны быть описаны в той или иной схеме ). Объектами схемы могут быть таблицы , представления, домены, утверждения, сопоставления, толкования и наборы символов. Все они имеют одного и того же владельца и множество общих значений, принимаемых по умолчанию.
Стандарт SQL оставляет за разработчиками СУБД право выбора конкретного механизма создания и уничтожения каталогов , однако механизм создания и удаления схем регламентируется посредством операторов CREATE SCHEMA и DROP SCHEMA . В стандарте также указано, что в рамках оператора создания схемы должна существовать возможность определения диапазона привилегий, доступных пользователям создаваемой схемы . Однако конкретные способы определения подобных привилегий в разных СУБД различаются.
В настоящее время операторы CREATE SCHEMA и DROP SCHEMA реализованы в очень немногих СУБД. В других реализациях, например, в СУБД MS SQL Server, используется оператор CREATE DATABASE .
Создание базы данных в среде MS SQL Server
Процесс создания базы данных в системе SQL-сервера состоит из двух этапов: сначала организуется сама база данных , а затем принадлежащий ей журнал транзакций . Информация размещается в соответствующих файлах, имеющих расширения *.mdf (для базы данных ) и *.ldf . (для журнала транзакций ). В файле базы данных записываются сведения об основных объектах ( таблицах , индексах , представлениях и т.д.), а в файле журнала транзакций – о процессе работы с транзакциями (контроль целостности данных, состояния базы данных до и после выполнения транзакций).
Создание базы данных в системе SQL-сервер осуществляется командой CREATE DATABASE . Следует отметить, что процедура создания базы данных в SQL-сервере требует наличия прав администратора сервера.
Рассмотрим основные параметры представленного оператора.
При выборе имени базы данных следует руководствоваться общими правилами именования объектов. Если имя базы данных содержит пробелы или любые другие недопустимые символы, оно заключается в ограничители (двойные кавычки или квадратные скобки). Имя базы данных должно быть уникальным в пределах сервера и не может превышать 128 символов.
При создании и изменении базы данных можно указать имя файла, который будет для нее создан, изменить имя, путь и исходный размер этого файла. Если в процессе использования базы данных планируется ее размещение на нескольких дисках, то можно создать так называемые вторичные файлы базы данных с расширением *.ndf . В этом случае основная информация о базе данных располагается в первичном ( PRIMARY ) файле, а при нехватке для него свободного места добавляемая информация будет размещаться во вторичном файле . Подход, используемый в SQL-сервере, позволяет распределять содержимое базы данных по нескольким дисковым томам.
Параметр ON определяет список файлов на диске для размещения информации, хранящейся в базе данных .
Параметр PRIMARY определяет первичный файл . Если он опущен, то первичным является первый файл в списке.
Параметр LOG ON определяет список файлов на диске для размещения журнала транзакций . Имя файла для журнала транзакций генерируется на основе имени базы данных , и в конце к нему добавляются символы _log .
При создании базы данных можно определить набор файлов, из которых она будет состоять. Файл определяется с помощью следующей конструкции:
Здесь логическое имя файла – это имя файла, под которым он будет опознаваться при выполнении различных SQL-команд.
Физическое имя файла предназначено для указания полного пути и названия соответствующего физического файла, который будет создан на жестком диске. Это имя останется за файлом на уровне операционной системы.
Параметр SIZE определяет первоначальный размер файла; минимальный размер параметра – 512 Кб, если он не указан, по умолчанию принимается 1 Мб.
Параметр MAXSIZE определяет максимальный размер файла базы данных . При значении параметра UNLIMITED максимальный размер базы данных ограничивается свободным местом на диске.
При создании базы данных можно разрешить или запретить автоматический рост ее размера (это определяется параметром FILEGROWTH ) и указать приращение с помощью абсолютной величины в Мб или процентным соотношением. Значение может быть указано в килобайтах, мегабайтах, гигабайтах, терабайтах или процентах (%). Если указано число без суффикса МБ, КБ или %, то по умолчанию используется значение MБ. Если размер шага роста указан в процентах (%), размер увеличивается на заданную часть в процентах от размера файла. Указанный размер округляется до ближайших 64 КБ.
Дополнительные файлы могут быть включены в группу:
Пример 3.1. Создать базу данных , причем для данных определить три файла на диске C, для журнала транзакций – два файла на диске C.
Изменение базы данных
Большинство действий по изменению конфигурации базы данных выполняется с помощью следующей конструкции:
Как видно из синтаксиса, за один вызов команды может быть изменено не более одного параметра конфигурации базы данных . Если необходимо выполнить несколько изменений, придется разбить процесс на ряд отдельных шагов.
В базу данных можно добавить ( ADD ) новые файлы данных (в указанную группу файлов или в группу, принятую по умолчанию) или файлы журнала транзакций .
Параметры файлов и групп файлов можно изменять ( MODIFY ).
Для удаления из базы данных файлов или групп файлов используется параметр REMOVE . Однако удаление файла возможно лишь при условии его освобождения от данных. В противном случае сервер не разрешит удаление.
В качестве свойств группы файлов используются следующие:
READONLY – группа файлов используется только для чтения; READWRITE – в группе файлов разрешаются изменения; DEFAULT – указанная группа файлов принимается по умолчанию.
Удаление базы данных
Удаление базы данных осуществляется командой:
Удаляются все содержащиеся в базе данных объекты, а также файлы, в которых она размещается. Для исполнения операции удаления базы данных пользователь должен обладать соответствующими правами.
Файл представляет собой бессистемную последовательность байтов. В сущности, операционной системе все равно, что содержится в этом файле. Она видит только байты. Какое-либо значение этим байтам придается программами на уровне пользователя. Эта файловая модель используется всеми версиями UNIX, MS-DOS и Windows.
В современных ОС файлы хранятся на дисках и являются файлами произвольного доступа – ОС считывает байты файла вне порядка их размещения.
Корневой каталог – это основная папка на центральном диске, в которой содержится вся информация. Самый простой и популярный способ попадания в него – щелкаем левой кнопкой мыши меню «Пуск» и входим в «Мой компьютер», в открывшемся окне выбираем нужный диск и попадаем в его корневой каталог. В окне может быть открыто несколько папок, закройте их с помощью кнопок в правом верхнем углу окна. Повторяйте процедуру до тех пор, пока не окажетесь в корневом каталоге. Также для перехода в корневой каталог можно использовать программу Total Commander.
Для этого вам будет необходим компьютер операционной системой Windows XP и установленная на нем программа Total Commander.
Попасть в корневой каталог в операционной системе Windows XP можно таким способом: заходим в меню «Пуск» и входим в «Мой компьютер», при этом в открывшемся окне выбираем нужный диск из списка и входим в его корневой каталог. После этого мы можем просмотреть, какая информация содержится на этом диске. В адресной строке мы видим надпись «Диск:\», то есть если мы зайдем на диск «С», то надпись соответственно будет такой «С:\».
Если необходимо попасть в ту или иную папку, то это можно сделать с помощью корневого каталога диска. Найдя нужную папку и щелкнув по ней два раза, мы сможем просмотреть ее содержимое, при этом в адресной строке изменится надпись и появится название папки, в которой мы находимся «Диск:\название папки». Так, если мы зайдем в папку Temp, то надпись будет следующей «С:\Temp». В открытой папке могут находиться еще другие папки, в которые также можно зайти и в следствие этого надпись в адресной строке будет меняться, последовательно будут добавляться те папки, в которые мы заходим «Диск:\папка1\папка2\папка3…».
Если мы хотим снова попасть в корневой каталог диска, то необходимо в верхней части окна найти кнопку «Папки». Нажав на нее, в правой части появится дерево папок, которое представляет структуру всех папок, содержащихся на данном диске и другие имеющиеся диски. Нажав левой кнопкой мыши на нужный диск, мы сразу перейдем в корневой каталог. Существует еще другой способ быстрого перехода в корневой каталог диска. В верхней части окна есть кнопка «Вверх». Ее необходимо нажать столько раз, пока в адресной строке не появится надпись «Диск:\», таким образом, мы осуществляем последовательный выход из каждой папки, в которую входили. Такая же методика действует для всех версий Windows.
Попасть в корневой каталог с помощью программы Total Commander можно следующим образом:
Мы должны определить, какая папка на данный момент открыта в программе. Для этого мы смотрим в верхнюю часть окна, где отражено ее содержимое. Если там имеются две точки, то посредством их мы выйдем на уровень вверх. Такое действие необходимо продолжать до тех пор, пока эти точки исчезнут. Это будет означать, что мы попали в корневой каталог, о чем также будет свидетельствовать надпись «Диск:\» в верхней части окна.
Также для быстрого перехода в корневой каталог открытого диска, необходимо произвести нажатие комбинации клавиш Ctrl+\.
Каталоги в MS-DOS
Набрав эту команду, Вы получите список всех каталогов и файлов, находящихся в текущем каталоге диска с указанием их расширения и размеров, даты и времени создания.Все имена, имеющие справа от себя пометку , являются каталогами. Если список файлов слишком велик и не вмещается на экран, то можно использовать команду с ключом /p
c:\dir/p
Для моментального выхода в корневой каталог из подкаталога любого уровня используется команда
a:\cd\
Для перехода в родительский каталог используется команда
a:\cd..
Просмотр дерева каталогов
Для просмотра дерева каталогов в MS-DOS удобно использовать команду tree (tree-дерево). Это команда в графическом виде отображает структуру каталогов. Чтобы просмотреть дерево каталога. Выполните команду:
Будет показано дерево данного каталога со всеми его ветвями. При необходимости просмотра имен файлов в каждом каталоге следует ввести ключ /f.
a:\tree/f
Статьи к прочтению:
Как загрузить файл на яндекс,диск для общего скачивания (Как скачать из инета другим)
Похожие статьи:
Читайте также: