
Процессор в программировании это
Обновлено: 07.07.2024
Инструмент проще, чем машина. Зачастую инструментом работают руками, а машину приводит в действие паровая сила или животное.
Компьютер тоже можно назвать машиной, только вместо паровой силы здесь электричество. Но программирование сделало компьютер таким же простым, как любой инструмент.
Процессор — это сердце/мозг любого компьютера. Его основное назначение — арифметические и логические операции, и прежде чем погрузиться в дебри процессора, нужно разобраться в его основных компонентах и принципах их работы.
Два основных компонента процессора
Устройство управления
Устройство управления (УУ) помогает процессору контролировать и выполнять инструкции. УУ сообщает компонентам, что именно нужно делать. В соответствии с инструкциями он координирует работу с другими частями компьютера, включая второй основной компонент — арифметико-логическое устройство (АЛУ). Все инструкции вначале поступают именно на устройство управления.
Существует два типа реализации УУ:
- УУ на жёсткой логике (англ. hardwired control units). Характер работы определяется внутренним электрическим строением — устройством печатной платы или кристалла. Соответственно, модификация такого УУ без физического вмешательства невозможна.
- УУ с микропрограммным управлением (англ. microprogrammable control units). Может быть запрограммирован для тех или иных целей. Программная часть сохраняется в памяти УУ.
УУ на жёсткой логике быстрее, но УУ с микропрограммным управлением обладает более гибкой функциональностью.
Арифметико-логическое устройство
Это устройство, как ни странно, выполняет все арифметические и логические операции, например сложение, вычитание, логическое ИЛИ и т. п. АЛУ состоит из логических элементов, которые и выполняют эти операции.
25–27 ноября, Онлайн, Беcплатно
Большинство логических элементов имеют два входа и один выход.
Ниже приведена схема полусумматора, у которой два входа и два выхода. A и B здесь являются входами, S — выходом, C — переносом (в старший разряд).
Схема арифметического полусумматора
Хранение информации — регистры и память
Как говорилось ранее, процессор выполняет поступающие на него команды. Команды в большинстве случаев работают с данными, которые могут быть промежуточными, входными или выходными. Все эти данные вместе с инструкциями сохраняются в регистрах и памяти.
Регистры
Регистр — минимальная ячейка памяти данных. Регистры состоят из триггеров (англ. latches/flip-flops). Триггеры, в свою очередь, состоят из логических элементов и могут хранить в себе 1 бит информации.
Прим. перев. Триггеры могут быть синхронные и асинхронные. Асинхронные могут менять своё состояние в любой момент, а синхронные только во время положительного/отрицательного перепада на входе синхронизации.
По функциональному назначению триггеры делятся на несколько групп:
- RS-триггер: сохраняет своё состояние при нулевых уровнях на обоих входах и изменяет его при установке единице на одном из входов (Reset/Set — Сброс/Установка).
- JK-триггер: идентичен RS-триггеру за исключением того, что при подаче единиц сразу на два входа триггер меняет своё состояние на противоположное (счётный режим).
- T-триггер: меняет своё состояние на противоположное при каждом такте на его единственном входе.
- D-триггер: запоминает состояние на входе в момент синхронизации. Асинхронные D-триггеры смысла не имеют.
Для хранения промежуточных данных ОЗУ не подходит, т. к. это замедлит работу процессора. Промежуточные данные отсылаются в регистры по шине. В них могут храниться команды, выходные данные и даже адреса ячеек памяти.
Принцип действия RS-триггера
Память (ОЗУ)
ОЗУ (оперативное запоминающее устройство, англ. RAM) — это большая группа этих самых регистров, соединённых вместе. Память у такого хранилища непостоянная и данные оттуда пропадают при отключении питания. ОЗУ принимает адрес ячейки памяти, в которую нужно поместить данные, сами данные и флаг записи/чтения, который приводит в действие триггеры.
Прим. перев. Оперативная память бывает статической и динамической — SRAM и DRAM соответственно. В статической памяти ячейками являются триггеры, а в динамической — конденсаторы. SRAM быстрее, а DRAM дешевле.
Команды (инструкции)
Команды — это фактические действия, которые компьютер должен выполнять. Они бывают нескольких типов:
- Арифметические: сложение, вычитание, умножение и т. д.
- Логические: И (логическое умножение/конъюнкция), ИЛИ (логическое суммирование/дизъюнкция), отрицание и т. д.
- Информационные: move , input , outptut , load и store .
- Команды перехода: goto , if . goto , call и return .
- Команда останова: halt .
Прим. перев. На самом деле все арифметические операции в АЛУ могут быть созданы на основе всего двух: сложение и сдвиг. Однако чем больше базовых операций поддерживает АЛУ, тем оно быстрее.
Инструкции предоставляются компьютеру на языке ассемблера или генерируются компилятором высокоуровневых языков.
В процессоре инструкции реализуются на аппаратном уровне. За один такт одноядерный процессор может выполнить одну элементарную (базовую) инструкцию.
Группу инструкций принято называть набором команд (англ. instruction set).
Тактирование процессора
Быстродействие компьютера определяется тактовой частотой его процессора. Тактовая частота — количество тактов (соответственно и исполняемых команд) за секунду.
Частота нынешних процессоров измеряется в ГГц (Гигагерцы). 1 ГГц = 10⁹ Гц — миллиард операций в секунду.
Чтобы уменьшить время выполнения программы, нужно либо оптимизировать (уменьшить) её, либо увеличить тактовую частоту. У части процессоров есть возможность увеличить частоту (разогнать процессор), однако такие действия физически влияют на процессор и нередко вызывают перегрев и выход из строя.
Выполнение инструкций
Инструкции хранятся в ОЗУ в последовательном порядке. Для гипотетического процессора инструкция состоит из кода операции и адреса памяти/регистра. Внутри управляющего устройства есть два регистра инструкций, в которые загружается код команды и адрес текущей исполняемой команды. Ещё в процессоре есть дополнительные регистры, которые хранят в себе последние 4 бита выполненных инструкций.
Ниже рассмотрен пример набора команд, который суммирует два числа:
- LOAD_A 8 . Это команда сохраняет в ОЗУ данные, скажем, <1100 1000> . Первые 4 бита — код операции. Именно он определяет инструкцию. Эти данные помещаются в регистры инструкций УУ. Команда декодируется в инструкцию load_A — поместить данные 1000 (последние 4 бита команды) в регистр A .
- LOAD_B 2 . Ситуация, аналогичная прошлой. Здесь помещается число 2 ( 0010 ) в регистр B .
- ADD B A . Команда суммирует два числа (точнее прибавляет значение регистра B в регистр A ). УУ сообщает АЛУ, что нужно выполнить операцию суммирования и поместить результат обратно в регистр A .
- STORE_A 23 . Сохраняем значение регистра A в ячейку памяти с адресом 23 .
Вот такие операции нужны, чтобы сложить два числа.
Все данные между процессором, регистрами, памятью и I/O-устройствами (устройствами ввода-вывода) передаются по шинам. Чтобы загрузить в память только что обработанные данные, процессор помещает адрес в шину адреса и данные в шину данных. Потом нужно дать разрешение на запись на шине управления.

У процессора есть механизм сохранения инструкций в кэш. Как мы выяснили ранее, за секунду процессор может выполнить миллиарды инструкций. Поэтому если бы каждая инструкция хранилась в ОЗУ, то её изъятие оттуда занимало бы больше времени, чем её обработка. Поэтому для ускорения работы процессор хранит часть инструкций и данных в кэше.
Если данные в кэше и памяти не совпадают, то они помечаются грязными битами (англ. dirty bit).
Поток инструкций
Современные процессоры могут параллельно обрабатывать несколько команд. Пока одна инструкция находится в стадии декодирования, процессор может успеть получить другую инструкцию.

Однако такое решение подходит только для тех инструкций, которые не зависят друг от друга.
Если процессор многоядерный, это означает, что фактически в нём находятся несколько отдельных процессоров с некоторыми общими ресурсами, например кэшем.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Прерывания
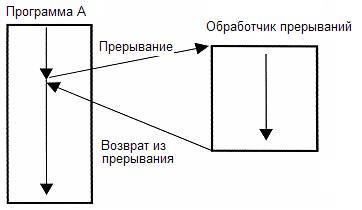
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно
1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Структура центрального процессора
Функционально центральный процессор можно разделить на две части:

Обе части ЦП работают параллельно, причем интерфейсная часть опережает операционную, так что выборка очередной команды из памяти (ее запись в блок регистров команд и предварительный анализ) происходит во время выполнения операционной частью предыдущей команды. Такая организация ЦП позволяет существенно повысить его эффективное быстродействие.
Устройство управления (УУ) вырабатывает управляющие сигналы, поступающие по кодовым шинам инструкций в другие блоки вычислительной машины. УУ формирует управляющие сигналы для выполнения команд центрального процессора.
Арифметико-логическое устройство (АЛУ) предназначено для выполнения арифметических и логических операций преобразования информации.
Системная шина – набор проводников, по которым передаются сигналы, соединяющая процессор с другими компонентами на системной плате. Системная шина состоит из шины данных, шины адреса, шины управления.
- Шина данных – служит для пересылки данных между процессором и оперативным запоминающим устройством (ОЗУ).
- Шина адреса – используется для передачи сигналов, с помощью которых определяется местоположение ячейки памяти для выполняемых процессором операций чтения/записи и ввода-вывода.
- Шина управления – служит для пересылки управляющих сигналов. Каждая линия этой шины имеет своё особое назначение, поэтому они могут быть как однонаправленными, так и двунаправленными.
Микропроцессорная память
Микропроцессорная память представляет собой набор регистров, которые условно можно разделить на 4 группы:
- регистры общего назначения;
- сегментные регистры;
- регистр счетчика команд;
- регистр признаков.
Регистр – устройство сверхбыстродействующей памяти в процессоре, служащее для временного хранения управляющей информации, операндов и/или результатов выполняемых операций. Совокупность регистров процессора называется набором регистров .
Набор регистров общего назначения 32-битной архитектуры центрального процессора включает в себя
- 4 универсальных регистра: EAX, EBX, ECX, EDX ;
- 2 индексных регистра: ESI, EDI ;
- 2 регистра для работы со стеком: ESP, EBP .


Регистр EAX (аккумулятор) – автоматически применяется при операциях умножения, деления и при работе с портами ввода-вывода. Его использование в арифметических, логических и некоторых других операциях позволяет увеличить скорость их выполнения. Используется для записи возвращаемого значения из функции.
Регистр EBX (регистр базы) – может содержать адреса элементов оперативной памяти. По умолчанию эти адреса будут представлять собой смещение в сегменте данных.
Регистр ECX (счетчик) – используется в операциях повторения, например в циклах, в строковых командах и т.д.
Регистр EDX (регистр данных) – является единственным элементом, который может хранить адреса портов ввода-вывода в командах типа IN (получить из порта) и OUT (вывести в порт). Без его помощи невозможно обратиться к портам с адресами в адресном пространстве больше 1 байта. Автоматически применяется также в операциях умножения и деления.
Индексные регистры используются для выполнения косвенной адресации, а также автоматически используются в строковых командах. Каждый 32-разрядный индексный регистр представляет собой логическое объединение, позволяющее отдельно обратиться к своей младшей 16-разрядной части.
Регистр ESI (регистр индекса источника) может содержать адреса элементов в оперативной памяти. По умолчанию эти адреса будут представлять собой смещение в сегменте данных. При выполнении операций со строками в этом регистре содержится смещение строки источника в сегменте данных.
Регистр EDI (регистр индекса приемника) может содержать адреса элементов в оперативной памяти. По умолчанию эти адреса будут представлять собой смещение в сегменте данных. При выполнении операций со строками в этом регистре содержится смещение строки приемника в сегменте данных.
Регистр счетчика команд
Регистр EIP (указатель команд) содержит смещение в сегменте кода следующей выполняемой команды. Как только некоторая команда начинает выполняться, значение регистра EIP увеличивается на ее длину так, что будет адресовать следующую команду. Физический адрес команды в памяти выполняемой программы определяет пара регистров CS:EIP , то есть к физическому адресу начала сегмента кода добавляется смещение следующей команды в сегменте кода, хранящееся в регистре EIP .

Обычно команды выполняются в той последовательности, в которой они расположены в программе. Нарушают эту последовательность только команды переходов (они начинаются с буквы j: jxx ), команды вызова подпрограммы ( call ), обработчиков прерываний ( int ) и возврата ( ret, iret ). Непосредственно содержимое EIP нельзя изменить или прочитать. Косвенно загрузить в регистр EIP новое значение могут только команды jxx, call, int, ret, iret . Регистр EIP является 32-битным. Младшая 16-битная часть регистра счетчика команд имеет имя IP .
Регистр признаков
Регистр признаков EFLAGS включает биты, каждый из которых устанавливается в единичное или в нулевое состояние при определенных условиях. Регистр EFLAGS 32-битный. Младшая 16-битная часть регистра признаков имеет имя FLAGS .
Все биты регистра признаков подразделяются на

CF – бит переноса: устанавливается в 1, когда арифметическая операция генерирует перенос или выход за разрядную сетку результата. сбрасывается в 0 в противном случае. Этот флаг показывает состояние переполнения для беззнаковых целочисленных арифметических действий. Он также используется в арифметических действиях с повышенной точностью. Может быть установлен командой STC или сброшен командой CLC .
PF – бит четности: устанавливается в 1, если результат последней операции имеет четное число единиц.
AF – бит вспомогательного переноса: устанавливается в 1, если арифметическая операция генерирует перенос из младшей тетрады битов (из 3 бита в 4), сбрасывается в 0 в противном случае. Этот флаг используется в двоично-десятичной арифметике.
ZF – бит нулевого значения: устанавливается в 1, если результат нулевой, сбрасывается в 0 в противном случае.
SF – знаковый бит: устанавливается равным старшему биту результата, который определяет знак в знаковых целочисленных операциях (0 – положительное число, 1 – отрицательное число).
TF – бит пошаговой отладки: устанавливается в 1 для включения режима пошаговой отладки программы, сбрасывается в 0 в противном случае.
IF – бит прерываний: при значении 1 микропроцессор реагирует на внешние аппаратные прерывания по входу INTR. При значении 0 микропроцессор игнорирует внешние прерывания.
DF – бит направления: управляет строковыми командами ( MOVS, CMPS, SCAS, LODS, STOS ). Если DF = 1 (команда STD ), то содержимое индексных регистров ESI, EDI увеличивается, если DF = 0 (команда CLD ), то содержимое индексных регистров ESI, EDI уменьшается.
OF – бит переполнения: устанавливается в 1, если целочисленный результат выходит за пределы разрядной сетки. Тем самым данный бит указывает на потерю старшего бита результата.
IOPL – уровень приоритета: 2-битовое поле, которое отображает уровень приоритета ввода-вывода для выполняемой в данное время программы или задачи. Действительный приоритет задачи может быть меньше или равен IOPL.
NT – флаг вложенной задачи: управляет последовательностью вызванных и прерванных задач. Установлен в 1, если текущая задача связана с предыдущей, сброшен в 0, если текущая задача не связана с другими задачами.
RF — флаг возобновления: используется при обработке прерываний от регистров отладки.
VM — флаг виртуального 8086: признак работы процессора в режиме виртуального 8086: 1 – процессор работает в режиме виртуального 8086, 0 – процессор работает в реальном или защищенном режиме.
AC — флаг контроля выравнивания: предназначен для разрешения контроля выравнивания при обращениях к памяти. Если требуется контролировать выравнивание данных и команд по адресам, кратным 2 или 4, то установка данных битов приведет к тому, что все обращения по некратным адресам будут вызывать исключительную ситуацию.
VIF — флаг виртуального прерывания: при определенных условиях (одно из которых – работа микропроцессора в V-режиме) является аналогом флага IF . Флаг VIF используется совместно с флагом VIP .
VIP — флаг отложенного виртуального прерывания: устанавливается в 1 для индикации отложенного прерывания. Используется совместно с VIF в виртуальном режиме.
ID — флаг поддержки идентификации процессора: используется для отображения поддержки микропроцессором инструкции CPUID .
2.1. Процессор.
Самый основной элемент компьютера, это, конечно, процессор. Давайте подробней его рассмотрим. Упрощённая структура процессора (рис. 4):

Рис. 4. Упрощённая структура процессора
Основные элементы процессора:
· Регистры – это специальные ячейки памяти, физически расположенные внутри процессора. В отличие от ОЗУ, где для обращения к данным требуется использовать шину адреса, к регистрам процессор может обращаться напрямую. Это существенно ускорят работу с данными.
· Арифметико-логическое устройство выполняет арифметические операции, такие как сложение, вычитание, а также логические операции.
· Блок управления определяет последовательность микрокоманд, выполняемых при обработке машинных кодов (команд).
· Тактовый генератор , или генератор тактовых импульсов, задаёт рабочую частоту процессора.
2.2. Режимы работы процессора.
Процессор архитектуры x86 может работать в одном из пяти режимов и переключаться между ними очень быстро:
1. Реальный (незащищенный) режим (real address mode) — режим, в котором работал процессор 8086. В современных процессорах этот режим поддерживается в основном для совместимости с древним программным обеспечением (DOS-программами).
2. Защищенный режим (protected mode) — режим, который впервые был реализован в 80286 процессоре. Все современные операционные системы (Windows, Linux и пр.) работают в защищенном режиме. Программы реального режима не могут функционировать в защищенном режиме.
3. Режим виртуального процессора 8086 (virtual-8086 mode, V86) — в этот режим можно перейти только из защищенного режима. Служит для обеспечения функционирования программ реального режима, причем дает возможность одновременной работы нескольких таких программ, что в реальном режиме невозможно. Режим V86 предоставляет аппаратные средства для формирования виртуальной машины, эмулирующей процессор8086. Виртуальная машина формируется программными средствами операционной системы. В Windows такая виртуальная машина называется VDM (Virtual DOS Machine — виртуальная машина DOS). VDM перехватывает и обрабатывает системные вызовы от работающих DOS-приложений.
4. Нереальный режим (unreal mode, он же big real mode) — аналогичен реальному режиму, только позволяет получать доступ ко всей физической памяти, что невозможно в реальном режиме.
5. Режим системного управления System Management Mode (SMM) используется в служебных и отладочных целях.
При загрузке компьютера процессор всегда находится в реальном режиме, в этом режиме работали первые операционные системы, например MS-DOS, однако современные операционные системы, такие как Windows и Linux переводят процессор в защищенный режим. Вам, наверное, интересно, что защищает процессор в защищенном режиме? В защищенном режиме процессор защищает выполняемые программы в памяти от взаимного влияния (умышленно или по ошибке) друг на друга, что легко может произойти в реальном режиме. Поэтому защищенный режим и назвали защищенным.
2.3. Регистры процессора (программная модель процессора).
Для понимания работы команд ассемблера необходимо четко представлять, как выполняется адресация данных, какие регистры процессора и как могут использоваться при выполнении инструкций. Рассмотрим базовую программную модель процессоров Intel 80386, в которую входят:
· 8 регистров общего назначения, служащих для хранения данных и указателей;
· регистры сегментов — они хранят 6 селекторов сегментов;
· регистр управления и контроля EFLAGS, который позволяет управлять состоянием выполнения программы и состоянием (на уровне приложения) процессора;
· регистр-указатель EIP выполняемой следующей инструкции процессора;
· система команд (инструкций) процессора;
· режимы адресации данных в командах процессора.
Начнем с описания базовых регистров процессора Intel 80386.
Базовые регистры процессора Intel 80386 являются основой для разработки программ и позволяют решать основные задачи по обработке данных. Все они показаны на рис. 5.

Рис. 5. Базовые регистры процессора Intel 80386
Среди базового набора регистров выделим отдельные группы и рассмотрим их назначение.
2.4. Регистры общего назначения.
Остальные четыре регистра – ESI (индекс источника), EDI (индекс приемника), ЕВР (указатель базы), ESP (указатель стека) – имеют более конкретное назначение и применяются для хранения всевозможных временных переменных. Регистры ESI и EDI необходимы в строковых операциях, ЕВР и ESP – при работе со стеком. Так же как и в случае с регистрами ЕАХ - EDX, младшие половины этих четырех регистров называются SI, DI, BP и SP соответственно, и в процессорах до 80386 только они и присутствовали.
2.5. Сегментные регистры.
При использовании сегментированных моделей памяти для формирования любого адреса нужны два числа – адрес начала сегмента и смещение искомого байта относительно этого начала (в бессегментной модели памяти flat адреса начал всех сегментов равны). Операционные системы (кроме DOS) могут размещать сегменты, с которыми работает программа пользователя, в разных местах памяти и даже временно записывать их на диск, если памяти не хватает. Так как сегменты способны оказаться где угодно, программа обращается к ним, применяя вместо настоящего адреса начала сегмента 16-битное число, называемое селектором. В процессорах Intel предусмотрено шесть 16-битных регистров - CS, DS, ES, FS, GS, SS , где хранятся селекторы. (Регистры FS и GS отсутствовали в 8086, но появились уже в 80286.) Это означает, что в любой момент можно изменить параметры, записанные в этих регистрах.
В отличие от DS, ES, GS, FS, которые называются регистрами сегментов данных, CS и SS отвечают за сегменты двух особенных типов – сегмент кода и сегмент стека. Первый содержит программу, исполняющуюся в данный момент, следовательно, запись нового селектора в этот регистр приводит к тому, что далее будет исполнена не следующая по тексту программы команда, а команда из кода, находящегося в другом сегменте, с тем же смещением. Смещение очередной выполняемой команды всегда хранится в специальном регистре EIP (указатель инструкции, 16-битная форма IP), запись в который так же приведет к тому, что далее будет исполнена какая-нибудь другая команда. На самом деле все команды передачи управления – перехода, условного перехода, цикла, вызова подпрограммы и т.п. – и осуществляют эту самую запись в CS и EIP.
2.6. Регистр флагов.
Еще один важный регистр, использующийся при выполнении большинства команд, - регистр флагов. Как и раньше, его младшие 16 бит, представлявшие собой весь этот регистр до процессора 80386, называются FLAGS. В EFLAGS каждый бит является флагом, то есть устанавливается в 1 при определенных условиях или установка его в 1 изменяет поведение процессора. Все флаги, расположенные в старшем слове регистра, имеют отношение к управлению защищенным режимом, поэтому здесь рассмотрен только регистр FLAGS (см. рис. 6):

Рис. 6. Регистр флагов FLAGS.
CF – флаг переноса. Устанавливается в 1, если результат предыдущей операции не уместился в приемнике и произошел перенос из старшего бита или если требуется заем (при вычитании), в противном случае – в 0. Например, после сложения слова 0 FFFFh и 1, если регистр, в который надо поместить результат, – слово, в него будет записано 0000 h и флаг CF = 1.
PF – флаг четности. Устанавливается в 1, если младший байт результата предыдущей команды содержит четное число битов, равных 1, и в 0, если нечетное. Это не то же самое, что делимость на два. Число делится на два без остатка, если его самый младший бит равен нулю, и не делится, когда он равен 1.
AF – флаг полупереноса или вспомогательного переноса. Устанавливается в 1, если в результате предыдущей операции произошел перенос (или заем) из третьего бита в четвертый. Этот флаг используется автоматически командами двоично-десятичной коррекции.
ZF – флаг нуля. Устанавливается в 1, если результат предыдущей команды – ноль.
SF – флаг знака. Он всегда равен старшему биту результата.
TF – флаг ловушки. Он был предусмотрен для работы отладчиков, не использующих защищенный режим. Установка его в 1 приводит к тому, что после выполнения каждой программной команды управление временно передается отладчику.
IF – флаг прерываний. Сброс этого флага в 0 приводит к тому, что процессор перестает обрабатывать прерывания от внешних устройств. Обычно его сбрасывают на короткое время для выполнения критических участков кода.
DF – флаг направления. Он контролирует поведение команд обработки строк: когда он установлен в 1, строки обрабатываются в сторону уменьшения адресов, когда DF =0 – наоборот.
OF – флаг переполнения. Он устанавливается в 1, если результат предыдущей арифметической операции над числами со знаком выходит за допустимые для них пределы. Например, если при сложении двух положительных чисел получается число со старшим битом, равным единице, то есть отрицательное, и наоборот.
Флаги IOPL (уровень привилегий ввода-вывода) и NT (вложенная задача) применяются в защищенном режиме.
2.7. Цикл выполнения команды
Программа состоит из машинных команд. Программа загружается в оперативную память компьютера. Затем программа начинает выполняться, то есть процессор выполняет машинные команды в той последовательности, в какой они записаны в программе.
Для того чтобы процессор знал, какую команду нужно выполнять в определённый момент, существует счётчик команд – специальный регистр, в котором хранится адрес команды, которая должна быть выполнена после выполнения текущей команды. То есть при запуске программы в этом регистре хранится адрес первой команды. В процессорах Intel в качестве счётчика команд (его ещё называют указатель команды) используется регистр EIP (или IP в 16-разрядных программах).
Счётчик команд работает со сверхоперативной памятью, которая находится внутри процессора. Эта память носит название очередь команд, куда помещается одна или несколько команд непосредственно перед их выполнением. То есть в счётчике команд хранится адрес команды в очереди команд, а не адрес оперативной памяти.
Цикл выполнения команды – это последовательность действий, которая совершается процессором при выполнении одной машинной команды. При выполнении каждой машинной команды процессор должен выполнить как минимум три действия: выборку, декодирование и выполнение. Если в команде используется операнд, расположенный в оперативной памяти, то процессору придётся выполнить ещё две операции: выборку операнда из памяти и запись результата в память. Ниже описаны эти пять операций.
- Выборка команды . Блок управления извлекает команду из памяти (из очереди команд), копирует её во внутреннюю память процессора и увеличивает значение счётчика команд на длину этой команды (разные команды могут иметь разный размер).
- Декодирование команды . Блок управления определяет тип выполняемой команды, пересылает указанные в ней операнды в АЛУ и генерирует электрические сигналы управления АЛУ, которые соответствуют типу выполняемой операции.
- Выборка операндов . Если в команде используется операнд, расположенный в оперативной памяти, то блок управления начинает операцию по его выборке из памяти.
- Выполнение команды . АЛУ выполняет указанную в команде операцию, сохраняет полученный результат в заданном месте и обновляет состояние флагов, по значению которых программа может судить о результате выполнения команды.
- Запись результата в память . Если результат выполнения команды должен быть сохранён в памяти, блок управления начинает операцию сохранения данных в памяти.
Суммируем полученные знания и составим цикл выполнения команды:
- Выбрать из очереди команд команду, на которую указывает счётчик команд.
- Определить адрес следующей команды в очереди команд и записать адрес следующей команды в счётчик команд.
- Декодировать команду.
- Если в команде есть операнды, находящиеся в памяти, то выбрать операнды.
- Выполнить команду и установить флаги.
- Записать результат в память (по необходимости).
- Начать выполнение следующей команды с п.1.
Это упрощённый цикл выполнения команды. К тому же действия могут отличаться в зависимости от процессора. Однако это даёт общее представление о том, как процессор выполняет одну машинную команду, а значит и программу в целом.
Читайте также: