
Qnap raid 1 замена диска
Обновлено: 07.07.2024
Допустим, у сервера 2 диска: /dev/sda и /dev/sdb . Эти диски собраны в софтверный RAID1 с помощью утилиты mdadm --assemble .
Один из дисков вышел из строя, например, это /dev/sdb . Повержденный диск нужно заменить.
Примечание: перед заменой диска желательно убрать диск из массива.
Удаление диска из массива
Проверьте, как размечен диск в массиве:
В данном случае массив собран так, что md0 состоит из sda2 и sdb2 , md1 — из sda3 и sdb3 .
На этом сервере md0 — это /boot , а md1 — своп и корень.
Удалите sdb из всех устройств:
Если разделы из массива не удаляются, то mdadm не считает диск неисправным и использует его, поэтому при удалении будет выведена ошибка, что устройство используется.
В этом случае перед удалением пометьте диск как сбойный:
Снова выполните команды по удалению разделов из массива.
После удаления сбойного диска из массива запросите замену диска, создав тикет с указанием s/n сбойного диска. Наличие downtime зависит от конфигурации сервера.
Определение таблицы разделов (GPT или MBR) и ее перенос на новый диск
После замены поврежденного диска нужно добавить новый диск в массив. Для этого надо определить тип таблицы разделов: GPT или MBR. Для этого используется gdisk .
Где /dev/sda — исправный диск, находящийся в RAID.
Для MBR в выводе будет примерно следующее:
Для GPT примерно следующее:
Перед добавлением диска в массив на нем нужно создать разделы в точности такие же, как и на sda . В зависимости от разметки диска это делается по-разному.
Копирование разметки для GPT
Для копирования разметки GPT:
Обратите внимание! Здесь первым пишется диск, на который копируется разметка, а вторым — с которого копируется (то есть с sda на sdb ). Если перепутать их местами, то разметка на изначально исправном диске будет уничтожена.
Второй способ копирования разметки:
После копирования присвойте диску новый случайный UUID:
Копирование разметки для MBR
Для копирования разметки MBR:
Обратите внимание! Здесь первым пишется диск, с которого копируется разметка, а вторым — на который копируется.
Если разделы не видны в системе, то можно перечитать таблицу разделов командой:
Добавление диска в массив
Если на /dev/sdb созданы разделы, то можно добавить диск в массив:
После добавления диска в массив должна начаться синхронизация. Скорость зависит от размера и типа диска (ssd/hdd):
Установка загрузчика
После добавления диска в массив нужно установить на него загрузчик.
Если сервер загружен в нормальном режиме или в infiltrate-root , то это делается одной командой:
Если сервер загружен в Recovery или Rescue-режиме (т.е. с live cd), то для установки загрузчика:
Смонтируйте корневую файловую систему в /mnt :
Смонтируйте /dev , /proc и /sys :
Выполните chroot в примонтированную систему:
Установите grub на sdb :
Затем попробуйте загрузиться в нормальный режим.
Как заменить диск, если он сбойный
Диск в массиве можно условно сделать сбойным с помощью ключа --fail (-f) :
Сбойный диск можно удалить с помощью ключа --remove (-r) :
Добавить новый диск в массив можно с помощью ключей --add (-a) и --re-add :
С самого своего появления NAS накопители зарекомендовали себя как очень удобные, а главное экономичные устройства для хранения информации. Простые в использовании и поддерживающие огромные массивы данных, эти устройства довольно быстро начали распространяться как среди домашних пользователей, так и в корпоративном сегменте.
Однако до сих пор довольно часто возникает одна проблема, которая вызывает сложности у очень большого количества пользователей, причем не только у не очень опытных, но и у некоторых профессионалов. Эта проблема – нехватка объема накопителей, установленных в NAS’ы.
В данном материале мы хотим помочь найти решение данной задаче, причем, как вы сможете понять после прочтения статьи, это под силу любому человеку, даже не очень знакомому с алгоритмами построения RAID массивов.
Для экспериментов мы выбрали следующие устройства:
NAS сервер с четырьмя дисковыми отсеками

Жесткие диски Western Digital Red WD10EFRX объемом 1 ТБ каждый в количестве 4 шт, которые будут играть роль накопителей, изначально установленных в наш NAS сервер.

Жесткие диски Western Digital Red WD60EFRX, на которые мы будем заменять диски меньшего объема.

Наш выборпал на жесткие диски WD серии Red не случайно. Данные накопители изначально разрабатывались для использования в NAS накопителях, поэтому при их использовании не может возникнуть проблем с совместимостью. Механика и прошивки накопителей специально рассчитаны на круглосуточную работу в режиме 24/7. Для уменьшения шума и снижения энергопотребления, что очень важно как для домашнего, так и бизнес применения, в дисках реализована технология Intellipower, которая заключается в оптимизации алгоритмов кэширования. Кроме того, вместе со своими партнерами, WD испытывает совместимость своих дисков серии Red, чтобы можно было с уверенностью выбрать накопители, оптимально подходящие для систем NAS. Так была создана NASware - технология компании WD, призванная решить трудности, возникающих при использовании в системах NAS обычных накопителей для настольных ПК. Эта инновационная микропрограмма позволяет оптимизировать работу накопителей в небольших системах NAS, обеспечивая идеальное соотношение важнейших характеристик: быстродействия, энергопотребления и надежности при работе в многодисковых устройствах. Уникальные алгоритмы технологии NASware оптимизируют быстродействие и энергопотребление, не жертвуя при этом теми качествами, которые ценят владельцы NAS.

Помимо этого, технология NASware оптимизирует энергопотребление жестких дисков WD Red, что способствует существенной экономии электроэнергии и снижению рабочей температуры накопителя. Это повышает общее быстродействие и надежность накопителя, а также снижает стоимость владения системой NAS. Интеллектуальные средства устранения ошибок, реализованные в HDD WD Red благодаря поддержке NASware, предотвращают выпадение накопителей из RAID-массивов вследствие длительности процесса устранения ошибок. Это позволяет повысить готовность систем и сократить их простои, связанные с восстановлением RAID-массива.
Перейдем непосредственно к главной теме данного исследования. Для начала запустим NAS с дисками маленького объема, проведем базовые настройки и скопируем на сетевое хранилище 24 ГБ данных. Последнее сделаем для того, чтобы убедиться в сохранности данных при увеличении объема жестких дисков.
Как писалось выше, жесткие диски WD серии Red обладают прекрасной производительностью, поэтому скорость копирования по сети с одного компьютера, несмотря на незавершившуюся процедуру инициализации накопителей в массиве, в среднем составляла 105 МБ/с, то есть полностью задействован канал в 1 Гбит/с. Это является отличным показателем производительности как самого сетевого хранилища, так и дисков, установленных в него. Небольшое падение скорости копирования происходило только тогда, когда начинали копироваться маленькие файлы, но и оно не опускалось ниже 85 МБ/с.
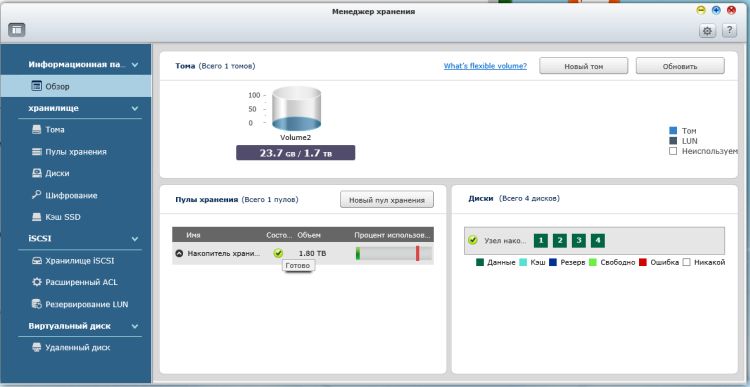
Приступим к замене дисков на накопители большего объема.В интерфейсе NAS’а открываем «Панель управления» -> «Менеджер хранения» - > «Пулы хранения»

Нажимаем кнопку «Управлять» и в открывшемся меню выбираем пункт «Увеличить емкость»
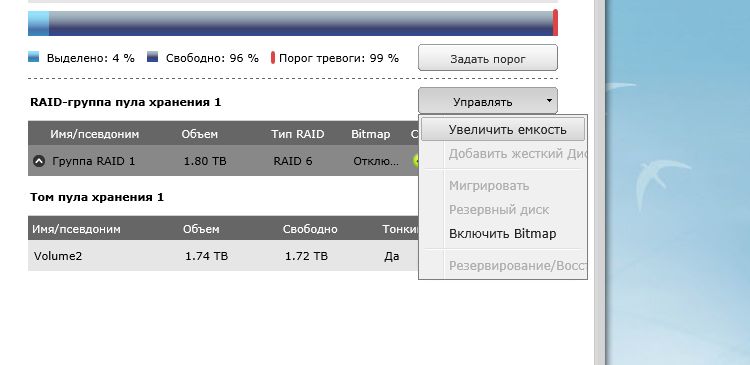
После этого открывается окно, с помощью которого нужно будет по очереди поменять каждый из дисков, выделяя его в таблице и нажимая кнопку «Заменить»
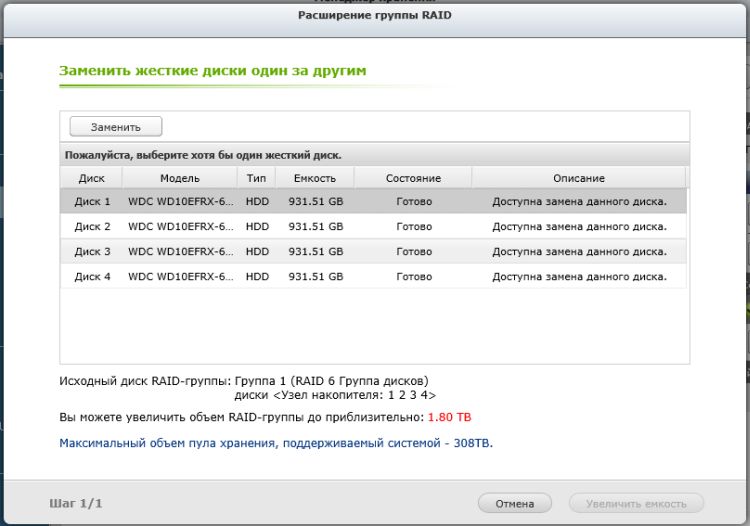
После этого извлекаем салазки с соответствующим диском, и откручиваем старый, и прикручиваем новый диск Western Digital Red WD60EFRX объемом 6 Тб. В используемом нами NAS'е для этого нужно открутить четыре винтика, снять старый диск, установить новый, обратно прикрутить винтики и вернуть диск на место в NAS. Сервер его автоматически определит, и начнет процедуру инициализации.






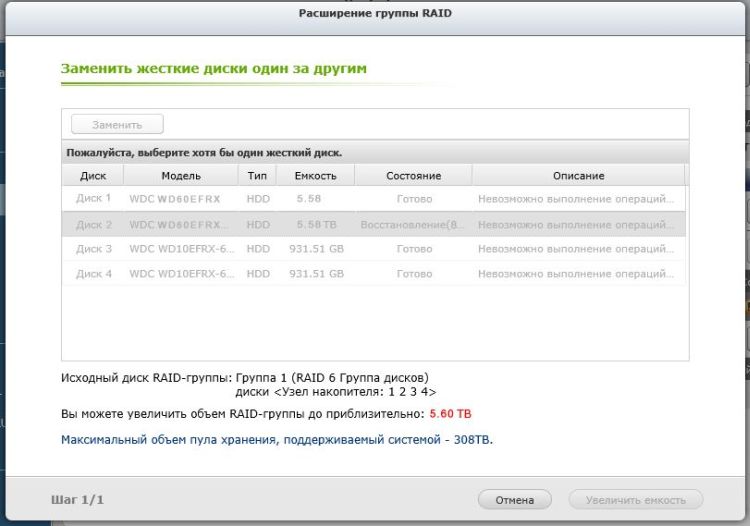
После замены каждого из дисков происходит процесс перестроения массива, который занимает довольно продолжительное время. В выбранном нами устройстве процедура замены каждого из дисков составила приблизительно семь часов. По завершении процедуры Замены дисков нужно нажать кнопку «Увеличить объем», и в результате получим систему с объемом хранимой информации в 12 Тб, так как изначально был создан массив RAID 6, обеспечивающий максимальную сохранность данных.
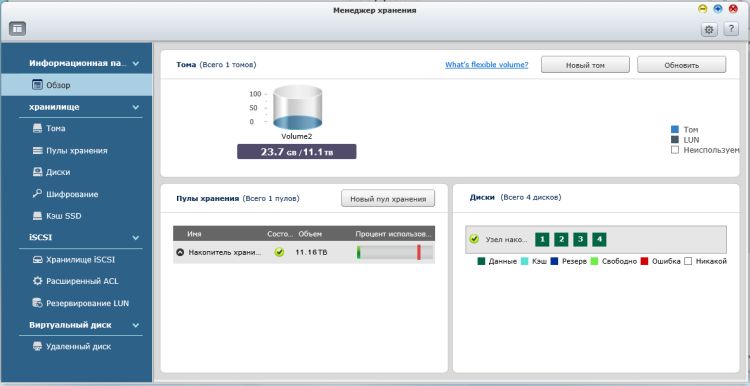
Как вы можете видеть на последнем скриншоте, в результате выполненной процедуры данные не были утеряны, что являеттся очень важным при различных операциях с дисками и их массивами. Процедура увеличения объема накопителей в NAS сервере прошла абсолютно безболезненно, причем в процессе переезда на диски большего объема, данные оставались доступными, что будет особенно важно при коммерческом использовании устройств подобного класса, когда недоступность определенной информации может повлечь за собой серьезные убытки.
В данной статье мы рассмотрели способ миграции данных в NAS сервере на диски большего объема, взяв в качестве примера накопители Western Digital Red. Однако хочется напомнить, что большая часть NAS серверов может использоваться в качестве NVR, то есть устройств, запиывающих и катологизирующих данные с цифровых систем видеонаблюдения. В таких случаях рекомендуется использовать диски Western Digital Purple.

Чтобы посмотреть какой у вас установлен raid и работает ли он вообще, используйте:
У вас должно появится картинка, примерного содержания, я ее приведу ниже.

Рабочий raid1 который мы проверили с помощью mdstat
На рисунке видно что рейд состоит из 4-х разделов ( sdb1,sdb2,sdb3,sdb4) и он полностью рабочий ( работают оба диска- это видно по опции [UU]). У меня всего 4 объединенных массива на которых: md0,md1,md2,md3.

Все изменения мы будем вносить в программный raid1 с нашей рабочей ОС ( на живую так сказать). Если вы увидели у себя нечто подобное как на рисунке выше, то пришло время заменять диск.
Убираем нерабочий ХДД из системы, а можно это сделать выполнив команды для каждого раздела по отдельности:
Не всегда может выполнить эти команды ( бывают разные случаи), если появились ошибки не расстраивайтесь, выполняйте все как написано!
Чтобы показать все диски у вашем входящем массиве (допустим в md0):
GPT используют для дисков у которых более 2ТБ (для примера, EX4 и EX6).
Если Вы используете HDD с GPT
На HDD хранится пару копий таблиц разделов GUID (GPT), по этому для того чтобы можно отредактировать их есть программы, которые поддерживают GPT, например такие как parted или такие как GPT fdisk. Программа sgdisk из GPT fdisk (она имеется в Rescue-системе и готова к использованию) которая позволяет простым и удобным способом скопировать вашу таблицу разделов на новый подключенный жёсткий диск. Для примера нам нужно скопировать все таблицы разделов с диска sda на диск sdb, то нужно выполнить:
Далее, ХДД нужно присвоить новый и случайный UUID следующей командой:
После этого HDD можно добавить в массив, а в завершении необходимо установить на него загрузчик.
Если Вы используете жёсткий ХДД с MBR
Любую таблицу разделов можно просто скопировать на новый диск с помощью утилиты sfdisk:
собственно /dev/sda — это источник, а /dev/sdb — ХДД (новый) назначения.
(Опционально): если разделы не видны в системе, то таблица разделов должна быть перечитана ядром:
Конечно же, разделы можно создать вручную с помощью fdisk, cfdisk или других инструментов. Разделы должны иметь тип Linux raid autodetect (ID fd). Сейчас уже можно добавить новый жесткий диск, как только вы удалили повреждённый диск, можно добавлять новый. Проделать это нужно для каждого раздела:
Только созданный новый HDD уже часть массива, и теперь массив будет выполнять синхронизацию.Данная процедура займет определенное время ( все зависит от объема ваших дисков). Наблюдать за происходящим можно выполнив команду:

синхронизация нового raid1 масива
Собственно последним этапом будет установка загрузчика, если вы производите починку на живую ( с под загруженной ОС), то достаточно запустить grub-install на новом жёстком диске, например можно это сделать следующим образом (если юзаете GRUB2,):
Если используете Grub1 ( это старая версия grub) то нужно выполнить немного больше шагов.
Привет, друзья. В прошлой статье мы с вами создали RAID 1 массив (Зеркало) - отказоустойчивый массив из двух жёстких дисков SSD. Смысл создания RAID 1 массива заключается в повышении надёжности хранения данных на компьютере. Когда два жёстких диска объединены в одно хранилище, информация на обоих дисках записывается параллельно (зеркалируется). Диски являются точными копиями друг друга, и если один из них выйдет из строя, мы получим доступ к операционной системе и нашим данным, ибо их целостность будет обеспечена работой другого диска. Также конфигурация RAID 1 повышает производительность при чтении данных, так как считывание происходит с двух дисков. В этой же статье мы рассмотрим, как восстановить массив RAID 1, если он развалится. Другими словами, мы рассмотрим, как сделать Rebuild RAID 1.
↑ Восстановление (Rebuild) RAID 1 массива


Развал RAID 1 массива может произойти по нескольким причинам: отказ одного из дисков, ошибки микропрограммы БИОСа, неправильные действия пользователя компьютера. При развале RAID 1 в БИОСе у него будет статус "Degraded".

В таких случаях нужно произвести восстановление (Rebuild) массива. Каким образом это можно сделать? К примеру, при отказе одного накопителя мы просто подсоединяем другой исправный, затем жмём в БИОСе кнопку "Rebuild", и происходит синхронизация данных на дисках. Таким вот образом RAID 1 массив восстанавливается, и мы можем работать дальше. Вроде, всё просто. Однако на практике при возникновении такой проблемы много нюансов. Давайте подробно рассмотрим все особенности восстановления RAID.
↑ Мониторинг состояния жёстких дисков в RAID
Если созданный с помощью БИОСа материнской платы RAID 1 массив развалился, неопытный пользователь может этого сразу и не понять. Мы не получим ни звукового оповещения, ни оповещения в иной форме, сигнализирующих о проблеме развала RAID 1. Возможностями аварийной сигнализации при развале массивов обладают только отдельные SAS/SATA/RAID-контроллеры, работающие через интерфейс PCI Express. За аварийную сигнализацию при проблемах с массивами отвечает специальное ПО таких контроллеров. Не имея таких контроллеров, можем использовать программы типа CrystalDiskInfo или Hard Disk Sentinel Pro, которые предупредят нас о выходе из строя одного из накопителей массива звуковым сигналом, либо электронным письмом на почту.
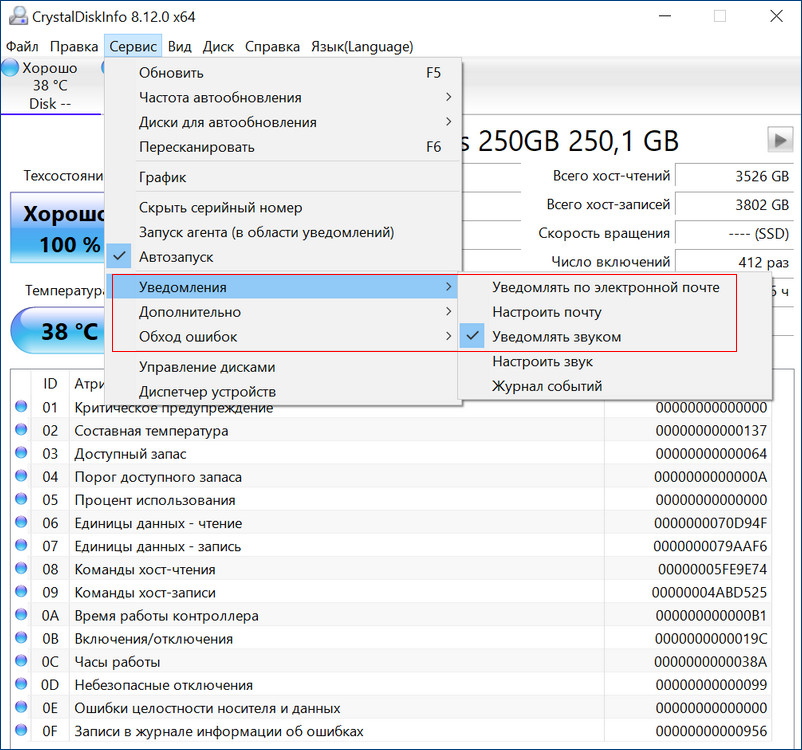
Если заглянем в управление дисками Windows, о развале RAID 1 можем догадаться, например, по исчезновению разметки одного из дисков.
Для примера возьмём мою материнскую плату на чипсете Z490 от Intel, для которого существует специальное программное обеспечение Intel Rapid Storage Technology (Intel RST). Технология Intel Rapid Storage поддерживает SSD SATA и SSD PCIe M.2 NVMe, повышает производительность компьютеров с SSD-накопителями за счёт собственных разработок. Всесторонне о бслуживает массивы RAID в конфигурациях 0, 1, 5, 10. П редоставляет пользовательский интерфейс Intel Optane Memory and Storage Management для управления системой хранения данных, в том числе дисковых массивов .
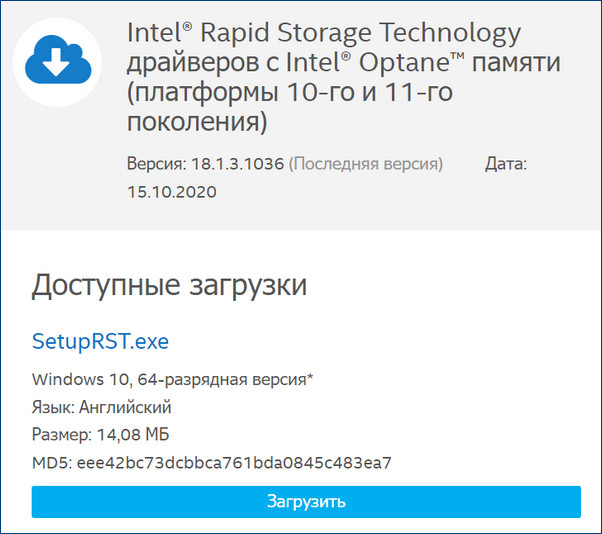

После установки Intel RST в главном окне увидим созданный нами из двух SSD M.2 NVMe Samsung 970 EVO Plus (250 Гб) RAID 1 массив, исправно функционирующий.
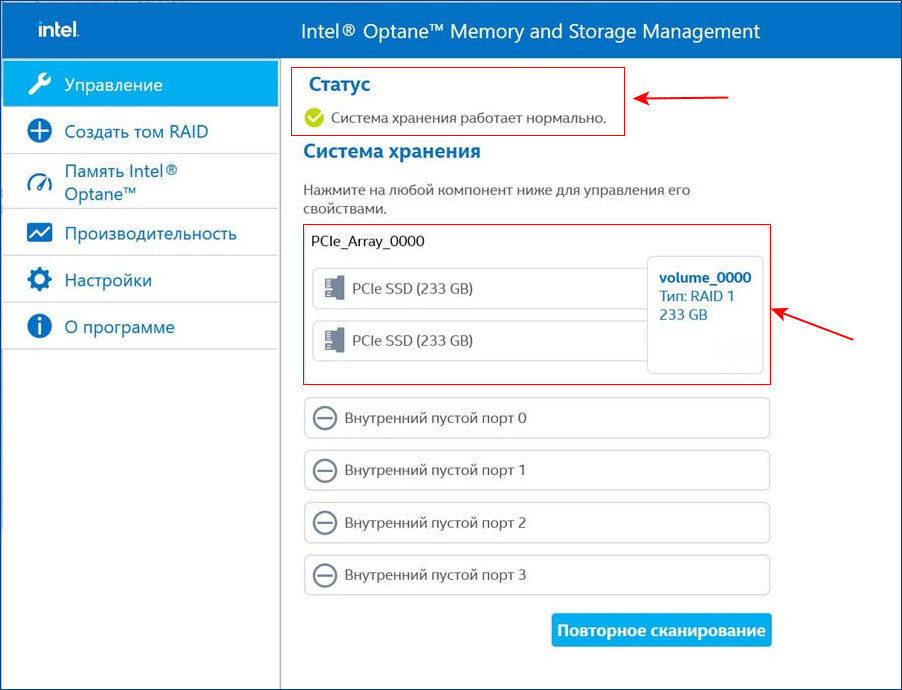
Вот этот массив в управлении дисками Windows.
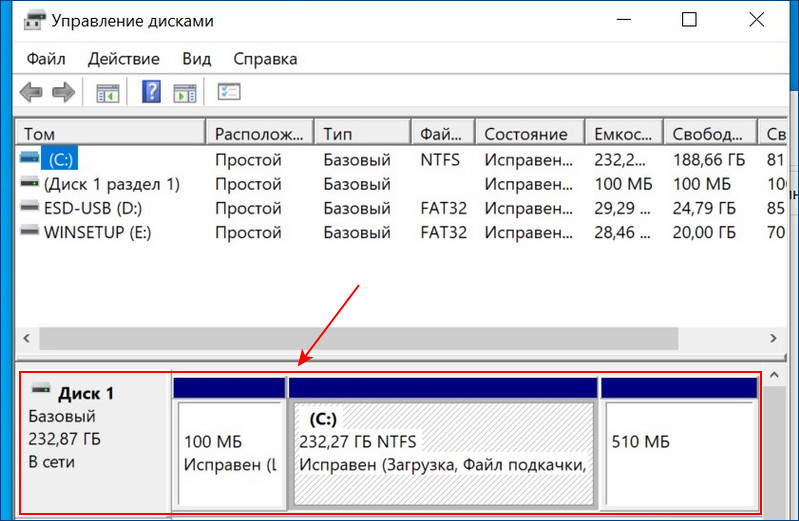
И в диспетчере устройств.
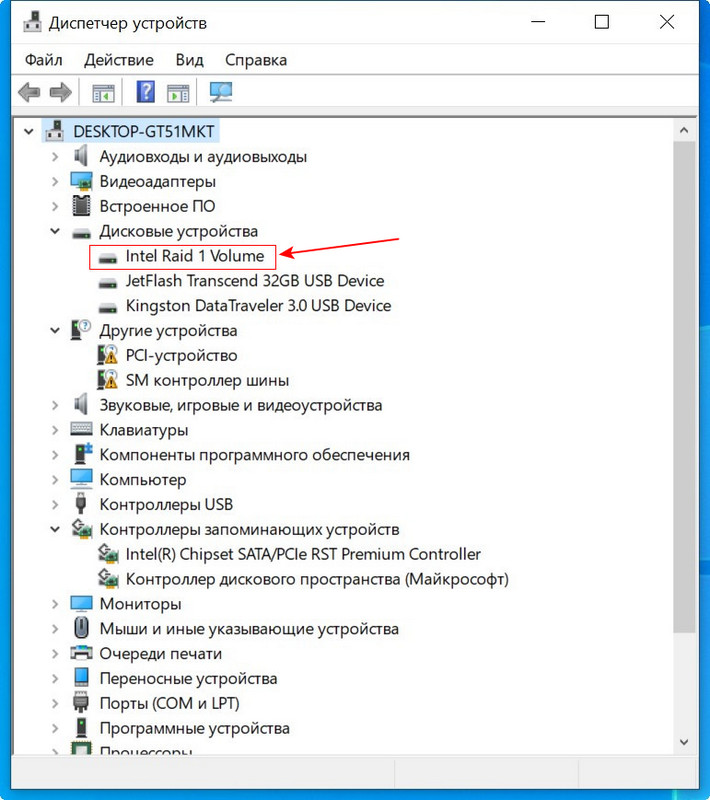
Технология Intel Rapid Storage имеет свою службу и постоянно мониторит состояние накопителей. На данный момент все находящиеся в рейде диски исправны.
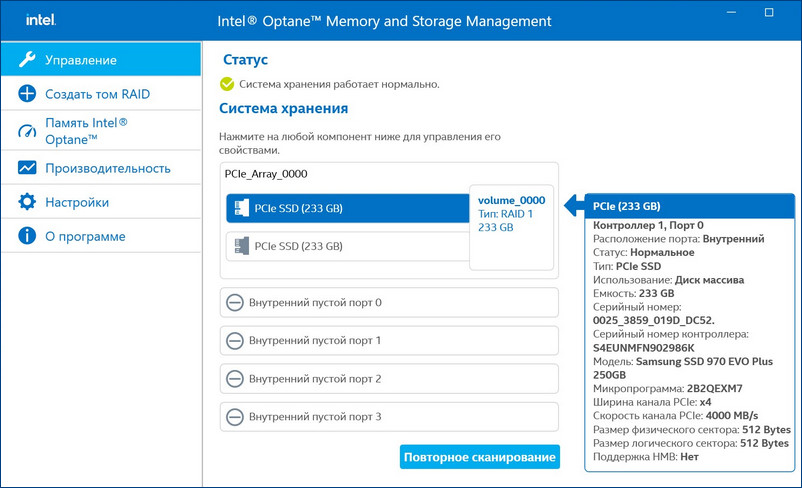
Если какой-либо накопитель неисправен, драйвер Intel RST сразу предупредит всплывающим окном о проблеме «Требуется внимание. Производительность одного из ваших томов снижена».
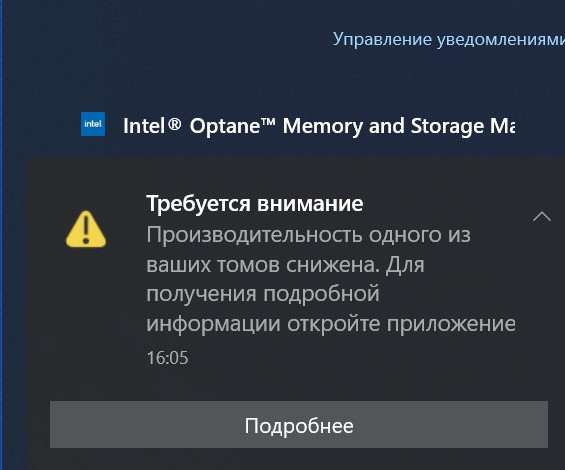
И в главном окне программы будет значиться, что один из дисков массива неисправен.
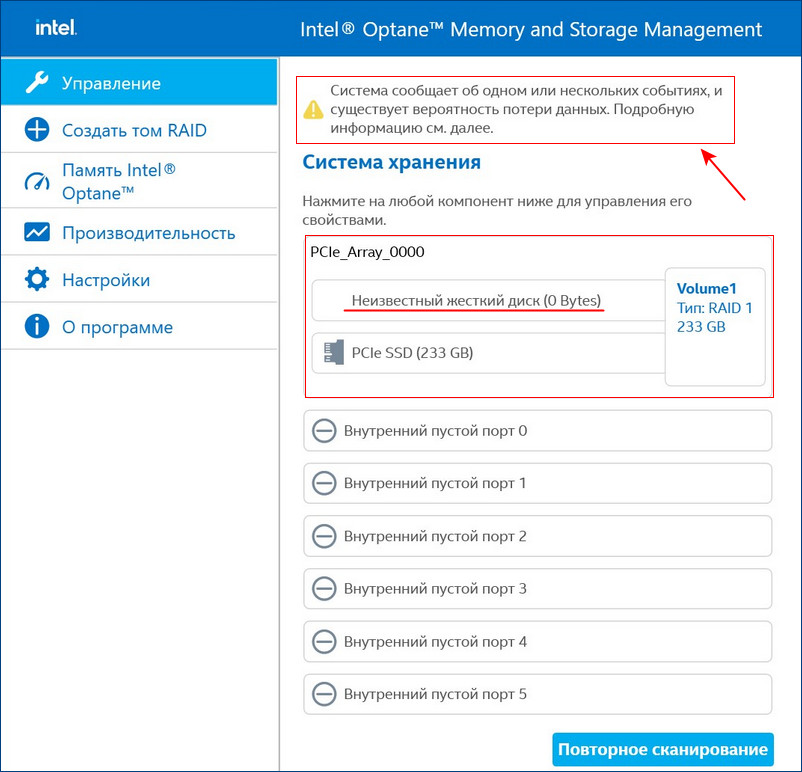
В этом случае можно произвести диагностику неисправного накопителя специальным софтом, к примеру, программой Hard Disk Sentinel Pro . Если диск неисправен или отработал свой ресурс, выключаем компьютер и заменяем диск на новый. Затем делаем Rebuild (восстановление) RAID 1 массива.
↑ Rebuild (восстановление) RAID 1 массива
После замены неисправного диска включаем ПК и входим в БИОС. Заходим в расширенные настройки «Advanced Mode», идём во вкладку «Advanced». Переходим в пункт «Intel Rapid Storage Technology».
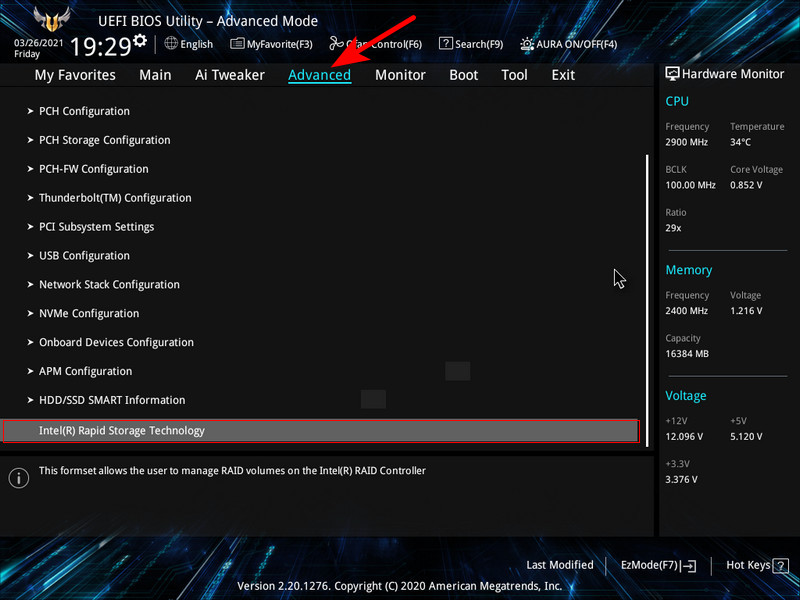
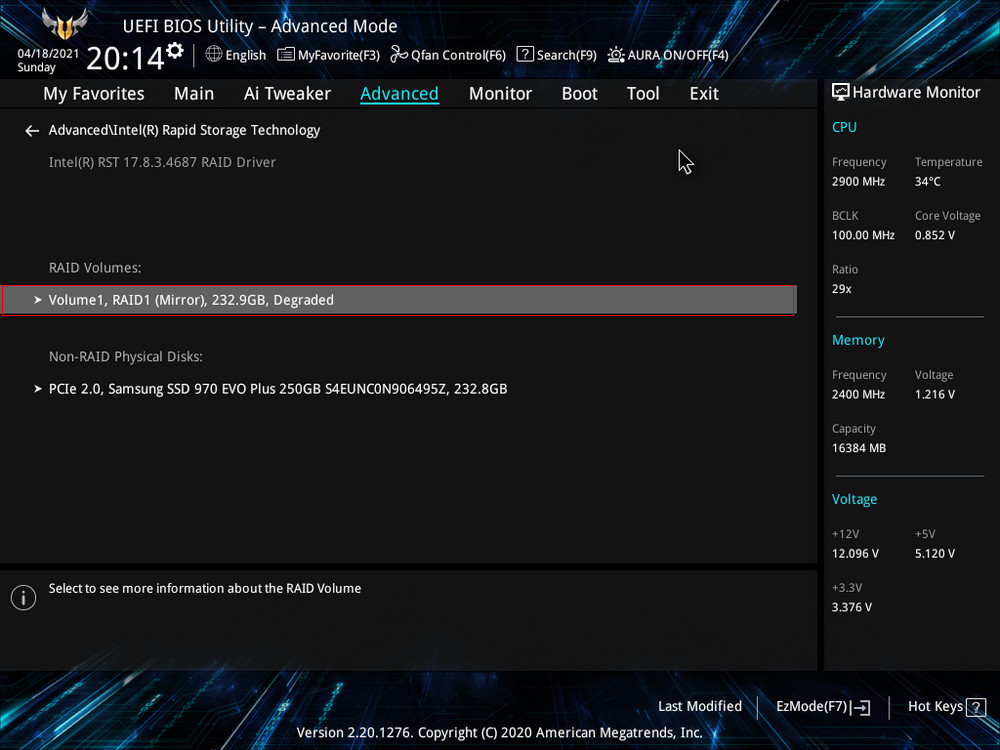
Видим, что наш RAID 1 массив с названием Volume 1 неработоспособен - "Volume 1 RAID 1 (mirroring), Degraded".Выбираем "Rebuild" (Восстановить).
Обратим внимание на уведомление внизу: "Selecting a disk initiates a rebuild. Rebuild completes in the operating system", переводится как "Выбор диска инициирует перестройку массива. Восстановление завершается в операционной системе". Выбираем новый накопитель, который нужно добавить в массив для его восстановления, жмём Enter. Появится следующий экран, указывающий, что после входа в операционную систему будет выполнено автоматическое восстановление - "All disk data will be lost", переводится как "Все данные на диске будут потеряны".RAID 1 массив восстановлен.
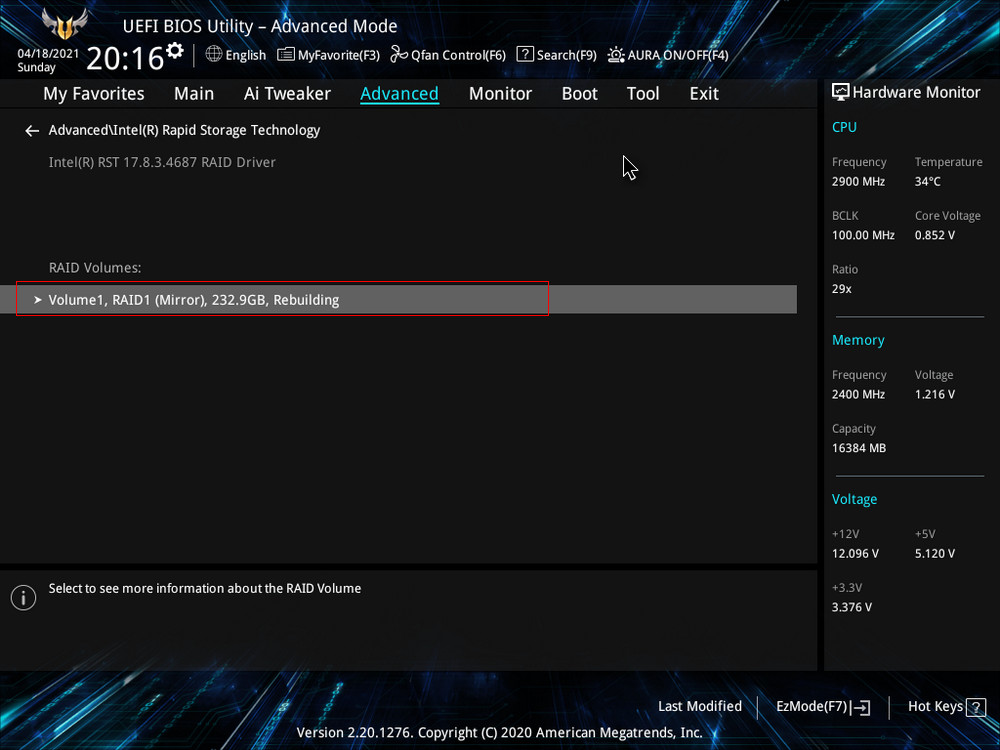
Жмём F10, сохраняем настройки, произведённые нами в БИОСе, и перезагружаемся.
После перезагрузки открываем программу Intel Optane Memory and Storage Management и видим, что всё ещё происходит перестроение массива, но операционной системой уже можно пользоваться.
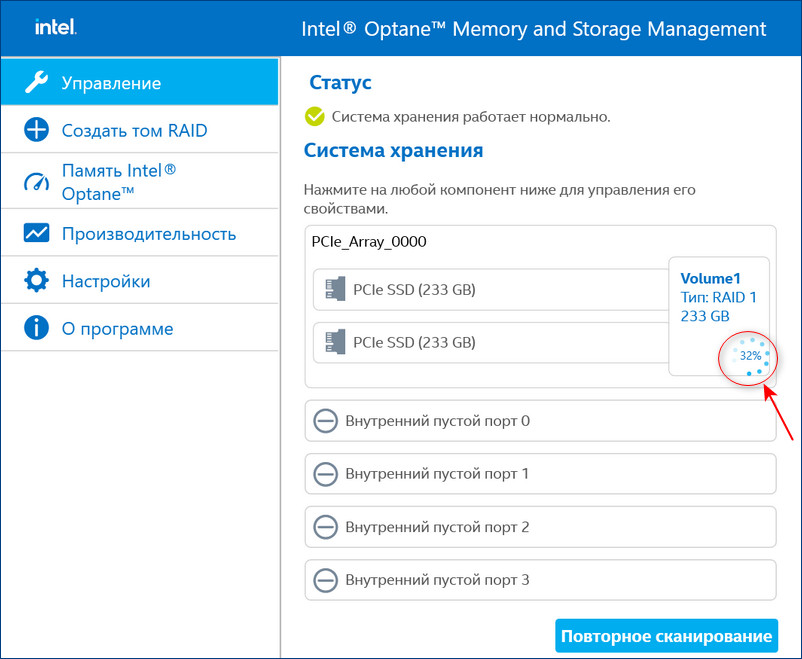
↑ Rebuild (восстановление) RAID 1 массива в пользовательском интерфейсе Intel Optane Memory and Storage Management
Восстановить дисковый массив можно непосредственно в программе Intel Optane Memory and Storage Management. К примеру, у нас неисправен один диск массива, и Windows 10 загружается с исправного накопителя. Выключаем компьютер, отсоединяем неисправный, а затем устанавливаем новый SSD PCIe M.2 NVMe, включаем ПК. Программа Intel Optane Memory and Storage Management определяет его как неизвестный жёсткий диск.
Диспетчер устройств, как и управление дисками, не видит целостный RAID, а видит два разных SSD.
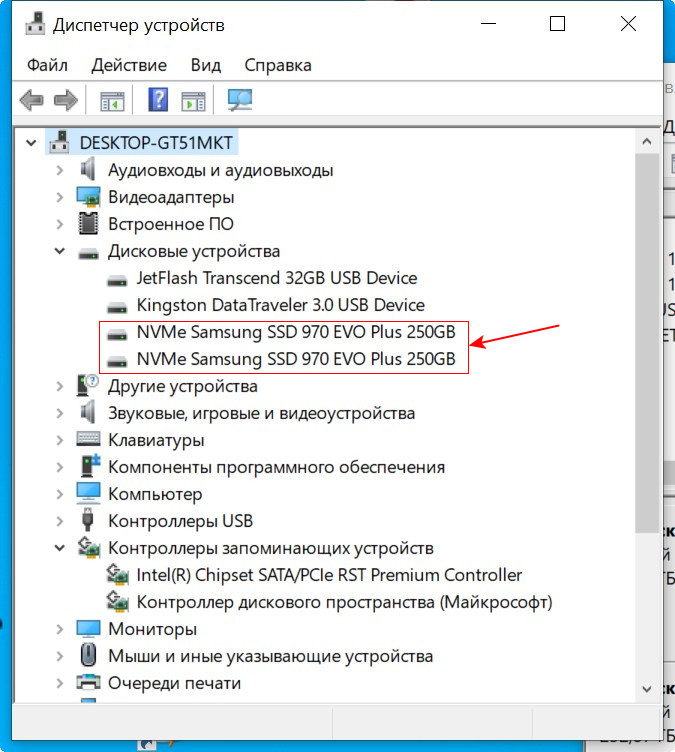
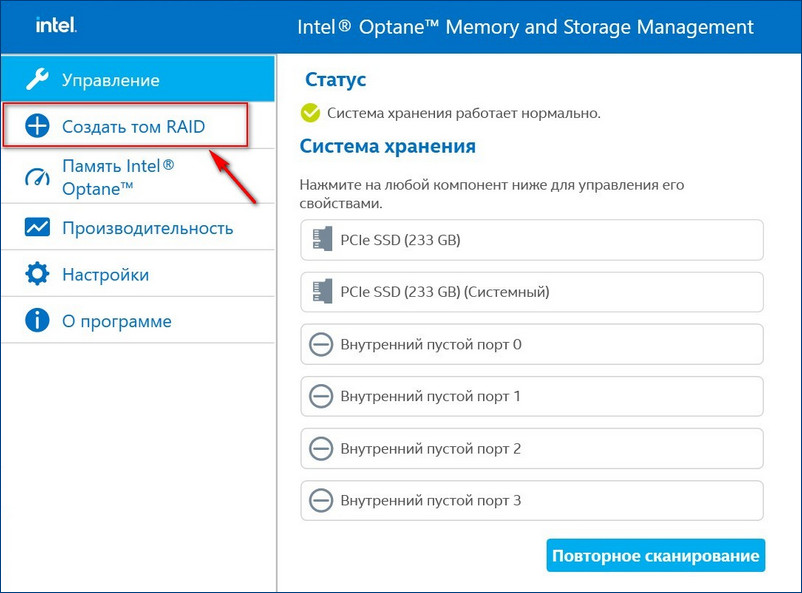
В главном окне программы жмём «Создать том RAID».
У нас SSD нового поколения с интерфейсом PCIe M.2 NVMe, значит, выбираем контроллер PCIe. Тип дискового массива - "Защита данных в режиме реального времени (RAID 1)".
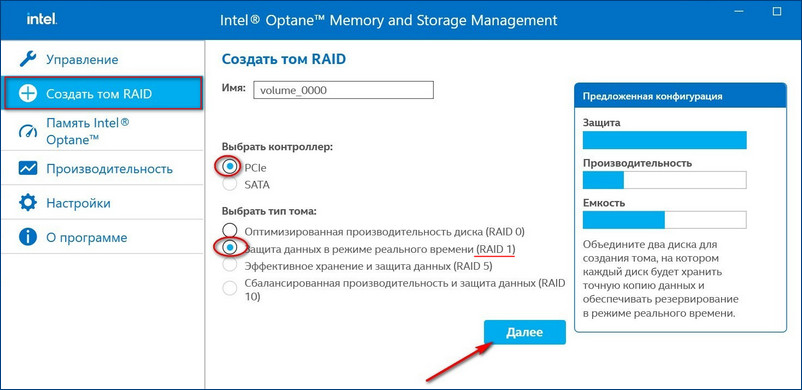
Выбираем два наших диска SSD PCIe M.2 NVMe.
Если на новом диске были данные, после перестроения массива данные на нём удалятся. Жмём "Создать том RAID". Можем наблюдать процесс восстановления массива.
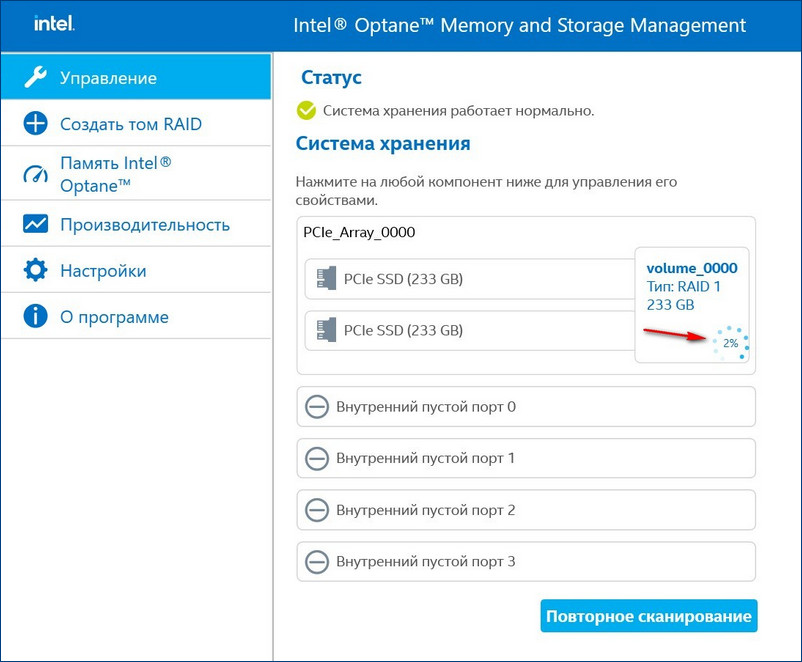
RAID 1 массив восстановлен.
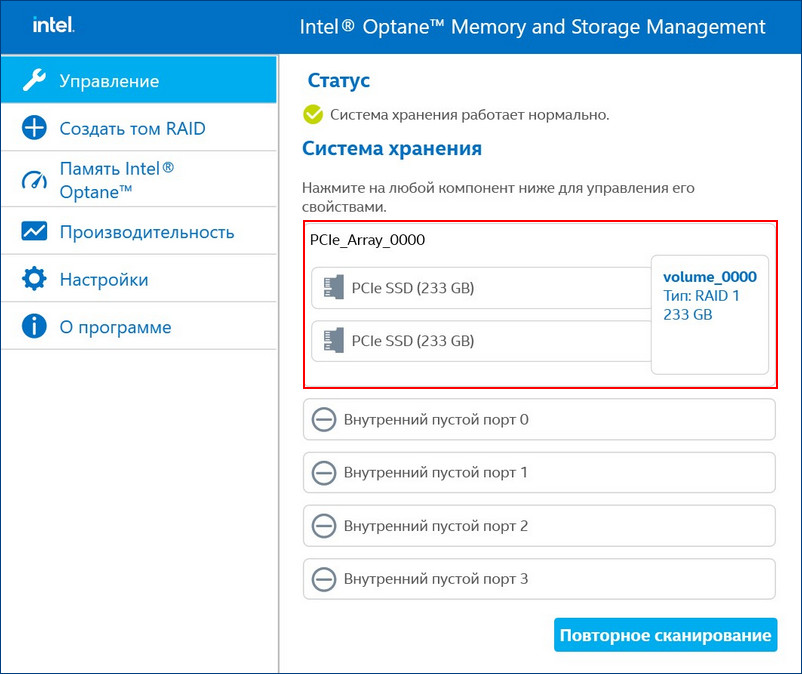
↑ Автоматический Rebuild RAID 1 массива
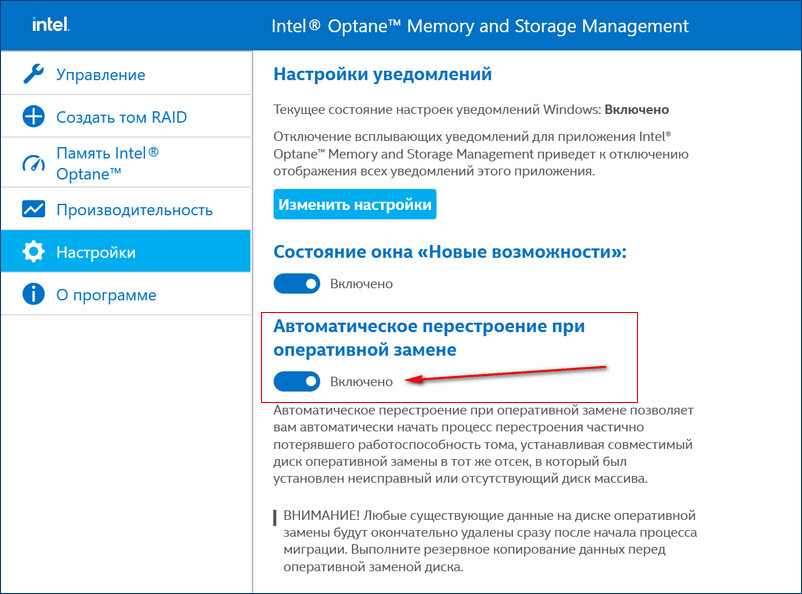
Если включить в настройках программы Intel RST «Автоматическое перестроение при оперативной замене», при замене неисправного накопителя не нужно будет ничего настраивать. Восстановление дискового массива начнётся автоматически.
↑ Восстановление массива RAID 1 из резервной копии при замене двух вышедших из строя дисков
Если у вас выйдут из строя сразу оба накопителя, то покупаем новые, устанавливаем в системный блок, затем создаём RAID 1 заново и разворачиваем на него резервную копию.
Читайте также: