Sql server windows nt 64 bit грузит процессор
Обновлено: 16.05.2024
Высокая загрузка CPU на сервере СУБД MS SQL Server. Часть 2
Видим высокую загрузку CPU на сервере MS SQL Server, при этом в результате анализа на уровне СУБД не удалось установить источник проблемы. Например, имеется большое количество разных запросов, нагрузка от каждого из которых сравнительно небольшая.
Загрузку видим "сейчас", при этом по данным Performance Monitor, Диспетчера задач или Монитора ресурсов мы уверены, что основную нагрузку создает именно MS SQL Server.
Возможные причины
Невозможность установить источник высокой нагрузки может быть связана с тем, что в конфигурации присутствуют большие пакетные запросы. При этом на уровне СУБД эти пакеты разбиваются на большое количество сравнительно небольших запросов, влияние каждого из которых на общую нагрузку невелико.
Другая возможная причина - динамическое формирование текстов запросов в коде конфигурации. Это также приводит к тому, что на уровне СУБД один запрос делится на несколько, с пропорциональным размыванием нагрузки между отдельными запросами.
Что требуется сделать
Для расследования необходимо сгруппировать запросы по какому-то признаку. На практике хорошо работает группировка по строкам контекста конфигурации, из которых были вызваны запросы. Также может оказаться полезной группировка запросов по пользователям информационной базы, действия которых инициировали запрос или по сеансам этих пользователей.
Методика анализа
Суть методики заключается в параллельном сборе трассировки запросов на сервере СУБД и технологического журнала 1С:Предприятия, с последующим объединением и агрегацией данных.
Для обеспечения возможности объединения данные технологического журнала выгружаются на СУБД с помощью скрипта на perl, и далее запросы нормализуются путем удаления всех переменных и незначащих элементов (например, имен временных таблиц, имен параметров, пробелов, переносов строк), с последующим вычислением хэша MD5 от полученной в результате нормализации строки. После этого запросы трассировки группируются по хэшам, и в процессе группировки вычисляются средние значения по колонкам "Duration", "CPU", "Reads" и "Writes". Полученные данные объединяются с данными технологического журнала, и используются для оценки влияния каждого из контекстов на процессор или диск.
Поскольку тот или иной код конфигурации может быть вызван различными способами (в разных контекстах), то для анализа используются только первая и последняя строка полного стека вызова.
Сбор и подготовка данных
Для того, чтобы собрать данные для расследования, необходимо:
2. Подготовить файл настройки технологического журнала logcfg.xml с отбором по событиям DBMSSQL и по имени информационной базы. Сбор планов запросов включать не нужно.
3. Подготовить скрипт для сбора трассировки на сервере СУБД.
- Скопируйте текст шаблона Сбор трассировки.sql в SQL Server Management Studio, подключенный к анализируемому серверу баз данных
- Замените параметр скрипта <НомерБД> на номер анализируемой базы. Узнать номер базы можно с помощью запроса select db_id(‘ИмяБазыДанных‘)
- Замените параметр скрипта <ПутьКФайлуТрассировки> на полный путь к файлу, в котором будет сохраняться собранная трассировка. Обратите внимание, что:
- Каталог, указанный в параметре, должен существовать
- У пользователя Windows, от имени которого запущена служба MSSQLSERVER, должны быть права на запись в этот каталог
- Указанный файл не должен существовать до начала сбора трассировки (если ранее в этот файл уже собиралась трассировка, то нужно его удалить перед повторным запуском скрипта)
4. Синхронно включить сбор трассировки (выполнить подготовленный скрипт) и сбор технологического журнала (поместить подготовленный файл logcfg.xml в каталог настроек сервера 1С:Предприятия).
Трассировку рекомендуется включать до начала сбора ТЖ, чтобы собрать данные по всем тем запросам, которые попадут в технологический журнал.5. Через заданное время сбор трассировки завершится автоматически. Синхронно отключить сбор технологического журнала.
6. Создать базу на сервере СУБД для выгрузки таблиц трассировок и контекстов, например, базу "_Traces" . В этой базе создать функцию хэширования с помощью шаблона Создание функции хэширования.sql
7. Выгрузить собранную трассировку в таблицу на SQL-сервере, например, в таблицу "Trace" .
Для этого воспользуйтесь шаблоном скрипта Загрузка трассировки в таблицу. sql .
В шаблоне необходимо задать имя таблицы, в которую будет выгружаться трассировка, и указать путь к файлу с собранной трассировкой.
8. В той же базе создать таблицу для выгрузки контекстов с помощью шаблона Создание таблицы контекстов.sql
9. Выгрузить собранный технологический журнал в таблицу контекстов.
Для этого необходимо:- Установить Cygwin (если не установлен)
- Установить perl (если не установлен). Например, можно использовать ActivePerl.
- Выгрузить технологический журнал в файл, готовый для загрузки в СУБД с помощью скрипта parse_ context_ to_ file. pl .
Для этого в среде Cygwin запустите команду вида:
cat <ПутьКСобранномуТехнологическомуЖурналу> | perl <ПутьКСкрипту> ,
- ПутьКСобранномуТехнологическомуЖурналу - путь к журналам процессов rphost в виде шаблона, например: /cygdrive/c/Logs/rphost_*/*.log
- ПутьКСкрипту - путь к скрипту parse_ context_ to_ file.pl , например: /cygdrive/c/cygwin64/scripts/parse_context_to_file.pl
Узнать текущий каталог в среде Cygwin можно с помощью команды pwd .
- Переместить полученный файл events.csv на сервер СУБД
- Загрузить содержимое файла events.csv в таблицу базы данных.
Для этого необходимо:- Подготовить скрипт на основе шаблона Загрузка техжурнала в таблицу.sql:
- Указать имя таблицы, в которую будут загружаться данные
- Указать путь к файлу events.csv .
- Выполнить подготовленный скрипт в среде SQL Server Management Studio
10. Выполнить хэширование таблицы трассировки.
Для этого необходимо:- Подготовить скрипт на основе шаблона Хэширование таблицы трассировки.sql путем указания имени таблицы, в которую была выгружена трассировка
- Запустить скрипт на выполнение с помощью SQL Server Management Studio
11. Выполнить хэширование таблицы контекстов.
Для этого необходимо:- Подготовить скрипт на основе скрипта Хэширование таблицы контекстов.sql путем указания имени таблицы, в которую была выгружена информация из технологического журнала
- Запустить скрипт на выполнение с помощью SQL Server Management Studio
Анализ собранных данных
Для анализа собранных данных необходимо:
- Выполнить группировку таблицы трассировки по уникальным запросам, при этом вычислить средние значения показателей "Duration", "CPU", "Reads" и "Writes" по каждому виду запросов:
Для этого следует:- Подготовить скрипт на основе шаблона Агрегация трассировки.sql , путем указания таблицы, в которую была выгружена трассировка
- Выполнить подготовленный скрипт в среде SQL Server Management Studio
Копировать в буфер обмена
«%SELECT% T1._Fld13230RRef% FROM dbo._InfoRg13229 T1% T1._Fld13230RRef = @P3%».
Как понять что проблема именно в SQL Server - Заходим в Диспетчер задач, на вкладке Подробности находим sqlserver и смотрим колонку ЦП.
Если это значение постонно высокое, то значит где-то идет утечка CPU.
В этом руководстве мы собрали различные советы как решать подобную проблему
Поиск проблемных мест в SQL Server по CPU
1. Cмотрим счетчики perfmon
Определяем проблема в Kernel или User запросах.
В perfmon смотрим следующие параметры:
- Processor: % Privileged Time – Percentage of time processor spends on execution of Microsoft Windows kernel commands such as OS activity. (If more than 30% involve Windows Admins)
- Process (sqlservr): % Privileged Time – the sum of processor time on each processor for all threads of the process (SQL Kernel)
- Processor: % User Time – percentage of time the processor spends on executing user processes such as SQL Server. This includes I/O requests from SQL Server
Если это значение % Privileged Time / No of logical cpus больше 30%, то скорее всего дело в системных настройках, возможно антивирус.
2. Ищем проблемные процессы
spID с 1 до 50 - это системные. Мы можем отключать (kill spID) или смотреть запрос только для пользовательских (spID>50).
Также пробуем использовать хранимки exec sp_who, sp_who1, sp_who2, sp_who3 - они позволяют посмотреть все процессы и их текущее состояние.
По spid можно найти этот запрос:
Альтернативно вы можете посмотреть последний запрос, выполняющийся в рамках этого spID:
А также можно убить процесс через kill spID. Убили процесс - и посмотрели как это сказалось на загрузке.
3. Выявление проблем через спец запросы SQL
Также попробуйте выполнить следующие запросы для поиска проблемных мест по CPU
Еще один скрипт для поиска проблемных запросов по CPU:
Для найденных элементов можно удалить план в кеше (подставив sql_handle):
Еще 1 запрос на поиск проблем по CPU:
Также посмотрите правой кнопкой на Сервере > reports> Standard reports > Top CPU queries.
4. Анализ найденных проблемных запросов
В найденных запросах посмотрите execution plan и посмотрите где наибольший cost.
Источники и что почитать по теме утечек CPU
Альтернативная документация по поиску CPU проблем SQL Server
Что проверить в первую очередь:
- Конфигурация железа сервера.
- Дисковая подсистема.
- Свободное место.
- Антивирус на сервере стоит?
- БД (операции) не выполняются / выполняются, как часто.
- Проверка целостности
- Индексы перестройка
- Обновление статистики
- Сжатие (шринк)
Общие рекомендации
Электропитания - использовать «Высокая производительность»
настройка кэширования записи на диск
антивирус, - добавить папку SQL Server и файлов БД в исключения
настройка настроены параметры параллелизма (cost threshold for parallelism, max degree of parallelism)
настройка Hyper-Threading.
Мониторинг SSMS - «Стандартные отчеты»
«Стандартные отчеты» в пользовательском интерфейсе Management Studio
SQL Server Management Studio предоставляет минимальный необходимый набор стандартных отчетов для получения информации в режиме пользовательского интерфейса.
Доступ к этим отчетам может быть выполнен через «Обозреватель объектов» (Object explorer) → Правый клик мыши по базе данных → «Отчеты» (Reports) → «Стандартный отчет» (Standard reports)
Перечень «Стандартные отчеты»:
- Занято место на диске
- Использование дисковой памяти верхними таблицами
- Использование дисковой памяти таблицей
- Использование дисковой памяти секцией
- События резервного копирования и восстановления
- Все транзакции
- Все блокирующие транзакции
- Самые продолжительные транзакции
- Транзакции, блокирующие наибольшее кол-во транзакций при выполнении
- Транзакции с наибольшим кол-вом блокировок
- Статистика блокировки ресурсов по объектам
- Статистика выполнения объектов
- Журнал согласованности баз данных
- Статистика использования индекса
- Физическая статистика индекса
- Журнал изменений схемы
- Статистика пользователей
- Перечень «Пользовательские отчеты»
Мониторинг Activity Monitor - Монитор активности
Открыть монитор активности CTRL+ALT+A или SSMS стандарт. панель инструментов значок.
Монитор активности SQL Server 2008 объединяет данные о процессах, предоставляя наглядную информацию по выполняющимся и недавно выполнявшимся процессам.
Монитор активности предлагает администратору раздел обзора, внешне похожий на Диспетчер задач Windows, а также компоненты детального просмотра отдельных процессов, ожидания ресурсов, ввода-вывода в файлы данных и последних ресурсоемких запросов.
Мониторинг Reporting Services - Performance Dashboard Reports
Для наблюдения за SQL Server есть интересный пакет отчетов Reporting Services, называется он SQL Server Performance Dashboard Reports.
The SQL Server 2012 Performance Dashboard Reports are Reporting Services report files designed to be used with the Custom Reports feature of SQL Server Management Studio.
Возможно со стороны участников club-a будут дополнения, это только приветствуется.
Исходные данные
Высокая загрузка CPU на SQL-сервере.
Анализ
Для начала определимся, что каждый из нас подразумевает под высокой нагрузкой.
Варианта тут может быть два:
- Высокая загрузка CPU в диспетчере задач (Task Manager);
- Высокая загрузка CPU в Activity Monitor-е.
В общем случае значения этих вариантов могут совпадать, но иногда бывают частности, о которых будет упомянуто ниже (Частность 2).
Шаг 1
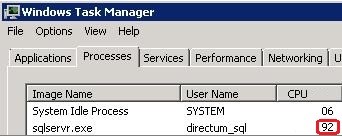
Поэтому на шаге 1 в Диспетчере задач убеждаемся, что ресурсы сервера потребляет именно процесс sqlservr.exe:
![]()
Если Диспетчер задач показывает значительную загрузку процесса sqlservr.exe, переходим к следующему шагу.
Если это не так, то ваш анализ практически завершен и достаточно выяснить почему другие процессы потребляют значительные ресурсы CPU, при необходимости завершив их.
Частность 1
Стоит отметить, если на сервере с SQL установлены такие службы DIRECTUM-a как WorkFlow, то для уменьшения нагрузки на CPU имеет смысл перенести их на другой сервер, т.к. в отдельные моменты служба WorkFlow может оказывать значительное влияние на весь сервер в целом (естественно это утверждение актуально в случае большого числа процессов, указанных в файле настроек SBWorkflowSrvSettings.xml).
Частность 2
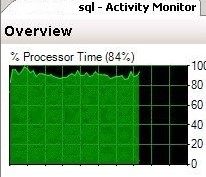
В некоторых случаях в Activity Monitor фиксируется постоянная 100% загрузка ресурсов процессора SQL-сервера, при этом в диспетчере задач загрузка CPU составляет значительно меньше (например, 50 и менее процентов) и используется только часть ядер.
![]()
Основными причинами м.б.:
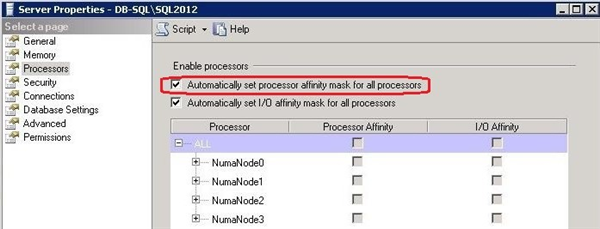
1. Отключена автоматическая установка соответствия использующихся ядер/потоков SQL-серверу, т.н. Affinity Mask. Ядра/потоки процессора заданы вручную. Для автоматического задания необходимо включить следующую настройку:- Automatically set processor affinity mask for all processors.
![]()
2. Используется неверный/ограниченный тип лицензирования по ядрам, тем самым используется только часть ядер, либо часть ядер по какой-либо причине стала неактивна. Проверить можно выполнив следующий t-sql запрос:
Статус VISIBLE OFFLINE свидетельствует о неактивном состоянии ядра/потока, т.е. никакие пользовательские запросы не обрабатываются данным ядром. Статус VISIBLE ONLINE свидетельствует о активном состоянии ядра/потока, т.е. пользовательские запросы обрабатываются данным ядром. Более подробно о статусах можно узнать в описании DMV – sys.dm_os_schedulers.
После корректной активации SQL-сервера не д.б. ядер со статусом VISIBLE OFFLINE.
Шаг 2
Итак, мы определили, что основная нагрузка исходит от процесса SQL-сервера.
Далее предположим, что к высокой нагрузке могли привести запросы, выполняемые в конкретных сессиях.
Наиболее тяжелые запросы и сессии можно определить следующими способами:
- Activity Monitor. Способ прост, но имеет один существенный недостаток, в случае высокой загрузки CPU, Activity Monitor просто перестает открываться, либо обновлять данные. Кроме того, нет информации по сессии (картинка кликабельна).
![]()
- Динамические представления: sys.dm_exec_query_stats, sys.dm_exec_sql_text и sys.dm_exec_query_plan. Основным достоинством данного способа является то, что мы узнаем среднюю нагрузку на SQL от запроса, сам текст запроса и, в случае необходимости, план запроса.
Пример запроса, использующего эти динамические представления:
Таким образом, имеем запрос который тратит ресурсов CPU на порядок больше всех остальных. Далее можем использовать план запроса для дальнейшего анализа, который может выявить проблему с индексами, статистикой и т.д.
Частность 3
Согласно документации Microsoft при первоначальной выборке из sys.dm_exec_query_stats могут быть неточности в результатах. Для повышения точности рекомендуется выполнить запрос повторно.
- Системные хранимые процедуры (ХП) sp_who, sp_who2 и их производные. Основное достоинство данного способа – идентификация наиболее нагружающей сессии. Сама по себе sp_who2 не очень удобна в использовании, но если несколько доработать Запрос , то можно получить вполне удобный вариант. Недостатком является то, что sp_who2 является недокументированной ХП, т.е. в последующих редакциях она м.б. удалена/изменена/неработоспособна.
![]()
Итак, получив SPID конкретной сессии, которая нагружает ваш SQL, в случае необходимости можно эту сессию принудительно завершить.
Шаг 3
В случае, если первые шаги не принесли никакого результата, то следующим вариантом, требующим проверки является проверка параметра Degree of Parallelism (DOP).
Если кратко, то это настройка отвечает за то, на сколько ядер может быть распараллелен запрос. Чем сложнее запрос, тем выгоднее его распараллеливать на большее число ядер процессора. С другой стороны, когда большая часть запросов простые (а именно так в большинстве своем в системе DIRECTUM), то необходимости в распараллеливании нет. Стоит учитывать, что при установке DOP=1, тяжелые запросы будут выполняться медленнее.
Изменение данной настройки не требует перезапуска SQL-сервера.
Оценить влияние можно так:
- Сравнить среднее значение загрузки CPU, например, за день до изменения и после;
- Оценить задержки вида CXPACKET в динамическом представлении dm_os_wait_stats, например, запросом вида:
Наличие в топе CXPACKET как раз и будет говорить о проблемах с параметром DOP.
Эмпирически можно подобрать наиболее подходящее значение DOP для каждой конкретной системы.
Шаг 4
В случае, если первые три шага по-прежнему не выявили проблемы с высокой нагрузкой на SQL-сервер, то наиболее вероятная причина в запросах, используемых в системе. И с точки зрения администратора системы вряд ли можно как-то повлиять на ее производительность. Примером этого может служить большое число компиляций/ре-компиляций при использовании непараметризированных запросов, описанных в статье Серия статей. SQL внутри. Статья первая. Компиляция запроса.
Обычно %Processor Time у нас занимает от 5 до 35 % процессорной мощности на сервере. Дисковая очередь в районе нуля.
А сегодня (именно сегодня) - 100%!
Я не могу понять, что происходит. Дисковая очередь в Перформенс мониторе то в районе нуля, то растет до порядка 30, иногда даже зашкаливает за 100. Cache Hit Ratio и Buffer Cache Hit Ratio - Обычно в районе 100%. А %Processor Time занимает регулярно в районе 100%!
Вот такие вот данные собрал, а как решить проблему - непонятно!
Помогите, пожалуйста! Куда дальше рыть?
Затем нажал на Columns Filters, там выбрал "Duration" "Greater than or equals to" "1000", и поставил галочку "Exclude rows that doesn't contain values".
То-есть, я имел целью выбрать все запросы, которые выполняются дольше секунды. Но таких запросов уйма. Все те запросы, которые обычно выполняются в течение десятков/сотней миллисекунд теперь выполняются по несколько секунд! В том числе примитивные запросы, которые вообще должны выполняться моментально! Что мне с этим делать? Как дальше исследовать?
Такое впечатление, что есть что-то другое, что настолько грузит процессор, что все запросы автоматически начинают выполняться медленно.
Так вот, есть один и тот же запрос, который дергают клиенты, только с разными параметрами. Этот запрос обычно выполняется меньше секунды. А тут он выполняется по 4, по 5 минут. Копирую его в SQL Server Studio - запрос выполняется меньше секунды, план строится красиво. Запрос примитивный - один джойн с группировкой, правда таблицы немаленькие (в одной полтора миллиона записей, в другой 48 миллионов).
Затем нажал на Columns Filters, там выбрал "Duration" "Greater than or equals to" "1000", и поставил галочку "Exclude rows that doesn't contain values".
То-есть, я имел целью выбрать все запросы, которые выполняются дольше секунды. Но таких запросов уйма. Все те запросы, которые обычно выполняются в течение десятков/сотней миллисекунд теперь выполняются по несколько секунд! В том числе примитивные запросы, которые вообще должны выполняться моментально! Что мне с этим делать? Как дальше исследовать?
Такое впечатление, что есть что-то другое, что настолько грузит процессор, что все запросы автоматически начинают выполняться медленно.
Помогите, пожалуйста, разобраться. Что делать дальше.
Иногда фильтр мешает найти источник проблем. Ты думаешь, что это какой-то большой SQL ?
Могут быть например тучи относительно мелких не очень медленных запросов,
короче - не попадающих под критерии фильтра, но в сумме успешно потребляющие до фига cpu.У меня такое было. Когда стоял фильтр CPU > 100 , ловил мало чего. Но оказалось что была еще тонна запросов где CPU отжирался всего на
30. Убрал фильтр , подержал трейс немного.
Потом трейс сохранил в таблицу и оттуда сделал типа
select sum ( cpu ) , substring (textdata , 1, 500 ) from trace group by substring (textdata , 1, 500 )
order by 1 desc .
для этой найденной "мелочи" создались нужные индесы, их CPU cost срубилась примерно в 10 раз . сервак тормозить перестал.Количество пользователей у Вас такое же как обычно?
Железо ведет себя нормально, отказов нет?
Втупую копирую запрос из профайлера в Студию и запускаю. Время выполнения - полсекунды. Меняю немного параметры - все равно полсекунды!
Втупую копирую запрос из профайлера в Студию и запускаю. Время выполнения - полсекунды. Меняю немного параметры - все равно полсекунды!
Втупую копирую запрос из профайлера в Студию и запускаю. Время выполнения - полсекунды. Меняю немного параметры - все равно полсекунды!
Втупую копирую запрос из профайлера в Студию и запускаю. Время выполнения - полсекунды. Меняю немного параметры - все равно полсекунды!
Как такие парадоксы могут быть? Что происходит?
Резервном - не БД-сервере, а именно java с веб-частью. БД-сервер у нас один.
Кстати, почему-то поменялся формат передаваемой даты. Правда, я сомневаюсь что из-за формата даты могут быть такие тормоза.
Читайте также:
- Подготовить скрипт на основе шаблона Загрузка техжурнала в таблицу.sql: