
В каком направлении развивается архитектура процессоров
Обновлено: 07.07.2024
Центра́льный проце́ссор (ЦП; CPU, от англ. central processing unit, дословно — центральное вычислительное устройство) — процессор машинных инструкций, часть аппаратного обеспечения компьютера или программируемого логического контроллера, отвечающая за выполнение арифметических операций, заданных программами операционной системы, и координирующий работу всех устройств компьютера.
Содержание
Современные ЦП, выполняемые в виде отдельных микросхем (чипов), реализующих все особенности, присущие данного рода устройствам, называют микропроцессорами. С середины 1980-х последние практически вытеснили прочие виды ЦП, вследствие чего термин стал всё чаще и чаще восприниматься как обыкновенный синоним слова «микропроцессор». Тем не менее, это не так: центральные процессорные устройства некоторых суперкомпьютеров даже сегодня представляют собой сложные комплексы больших (БИС) и сверхбольших (СБИС) интегральных схем.
Изначально термин Центральное процессорное устройство описывал специализированный класс логических машин, предназначенных для выполнения сложных компьютерных программ. Вследствие довольно точного соответствия этого назначения функциям существовавших в то время компьютерных процессоров, он естественным образом был перенесён на сами компьютеры. Начало применения термина и его аббревиатуры по отношению к компьютерным системам было положено в 60-х годах XX века. Устройство, архитектура и реализация процессоров с тех пор неоднократно менялись, однако их основные исполняемые функции остались теми же, что и прежде.
Ранние ЦП создавались в виде уникальных составных частей для уникальных, и даже единственных в своём роде, компьютерных систем. Позднее от дорогостоящего способа разработки процессоров, предназначенных для выполнения одной единственной или нескольких узкоспециализированных программ, производители компьютеров перешли к серийному изготовлению типовых классов многоцелевых процессорных устройств. Тенденция к стандартизации компьютерных комплектующих зародилась в эпоху бурного развития полупроводниковых элементов, мейнфреймов и миникомпьютеров, а с появлением интегральных схем она стала ещё более популярной. Создание микросхем позволило ещё больше увеличить сложность ЦП с одновременным уменьшением их физических размеров. Стандартизация и миниатюризация процессоров привели к глубокому проникновению основанных на них цифровых устройств в повседневную жизнь человека. Современные процессоры можно найти не только в таких высокотехнологичных устройствах, как компьютеры, но и в автомобилях, калькуляторах, мобильных телефонах и даже в детских игрушках. Чаще всего они представлены микроконтроллерами, где помимо вычислительного устройства на кристалле расположены дополнительные компоненты (интерфейсы, порты ввода/вывода, таймеры, и др.). Современные вычислительные возможности микроконтроллера сравнимы с процессорами персональных ЭВМ десятилетней давности, а чаще даже значительно превосходят их показатели.
Архитектура фон Неймана
Большинство современных процессоров для персональных компьютеров в общем основаны на той или иной версии циклического процесса последовательной обработки информации, изобретённого Джоном фон Нейманом.
Д. фон Нейман придумал схему постройки компьютера в 1946 году.
Важнейшие этапы этого процесса приведены ниже. В различных архитектурах и для различных команд могут потребоваться дополнительные этапы. Например, для арифметических команд могут потребоваться дополнительные обращения к памяти, во время которых производится считывание операндов и запись результатов. Отличительной особенностью архитектуры фон Неймана является то, что инструкции и данные хранятся в одной и той же памяти.
Этапы цикла выполнения:
- Процессор выставляет число, хранящееся в регистресчётчика команд, на шину адреса, и отдаёт памяти команду чтения;
- Выставленное число является для памяти адресом; память, получив адрес и команду чтения, выставляет содержимое, хранящееся по этому адресу, на шину данных, и сообщает о готовности;
- Процессор получает число с шины данных, интерпретирует его как команду (машинную инструкцию) из своей системы команд и исполняет её;
- Если последняя команда не является командой перехода, процессор увеличивает на единицу (в предположении, что длина каждой команды равна единице) число, хранящееся в счётчике команд; в результате там образуется адрес следующей команды;
- Снова выполняется п. 1.
Данный цикл выполняется неизменно, и именно он называется процессом (откуда и произошло название устройства).
Во время процесса процессор считывает последовательность команд, содержащихся в памяти, и исполняет их. Такая последовательность команд называется программой и представляет алгоритм полезной работы процессора. Очерёдность считывания команд изменяется в случае, если процессор считывает команду перехода — тогда адрес следующей команды может оказаться другим. Другим примером изменения процесса может служить случай получения команды останова или переключение в режим обработки аппаратного прерывания.
Команды центрального процессора являются самым нижним уровнем управления компьютером, поэтому выполнение каждой команды неизбежно и безусловно. Не производится никакой проверки на допустимость выполняемых действий, в частности, не проверяется возможная потеря ценных данных. Чтобы компьютер выполнял только допустимые действия, команды должны быть соответствующим образом организованы в виде необходимой программы.
Скорость перехода от одного этапа цикла к другому определяется тактовым генератором. Тактовый генератор вырабатывает импульсы, служащие ритмом для центрального процессора. Частота тактовых импульсов называется тактовой частотой.
Конвейерная архитектура
Конвейерная архитектура (pipelining) была введена в центральный процессор с целью повышения быстродействия. Обычно для выполнения каждой команды требуется осуществить некоторое количество однотипных операций, например: выборка команды из ОЗУ, дешифрация команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Например, конвейер микропроцессора с архитектурой MIPS-I содержит четыре стадии:
- получение и декодирование инструкции (Fetch)
- адресация и выборка операнда из ОЗУ (Memory access)
- выполнение арифметических операций (Arithmetic Operation)
- сохранение результата операции (Store)
После освобождения <math>k</math>-й ступени конвейера она сразу приступает к работе над следующей командой. Если предположить, что каждая ступень конвейера тратит единицу времени на свою работу, то выполнение команды на конвейере длиной в <math>n</math> ступеней займёт <math>n</math> единиц времени, однако в самом оптимистичном случае результат выполнения каждой следующей команды будет получаться через каждую единицу времени.
Действительно, при отсутствии конвейера выполнение команды займёт <math>n</math> единиц времени (так как для выполнения команды по прежнему необходимо выполнять выборку, дешифрацию и т. д.), и для исполнения <math>m</math> команд понадобится <math>n\cdot m</math> единиц времени; при использовании конвейера (в самом оптимистичном случае) для выполнения <math>m</math> команд понадобится всего лишь <math>n+m</math> единиц времени.
Факторы, снижающие эффективность конвейера:
- простой конвейера, когда некоторые ступени не используются (напр., адресация и выборка операнда из ОЗУ не нужны, если команда работает с регистрами);
- ожидание: если следующая команда использует результат предыдущей, то последняя не может начать выполняться до выполнения первой (это преодолевается при использовании внеочередного выполнения команд, out-of-order execution);
- очистка конвейера при попадании в него команды перехода (эту проблему удаётся сгладить, используя предсказание переходов).
Некоторые современные процессоры имеют более 30 ступеней в конвейере, что увеличивает производительность процессора, однако приводит к большому времени простоя (например, в случае ошибки в предсказании условного перехода.)
Суперскалярная архитектура
Способность выполнения нескольких машинных инструкций за один такт процессора. Появление этой технологии привело к существенному увеличению производительности.
CISC-процессоры
Complex Instruction Set Computing — вычисления со сложным набором команд. Процессорная архитектура, основанная на усложнённом наборе команд. Типичными представителями CISC является семейство микропроцессоров Intel x86 (хотя уже много лет эти процессоры являются CISC только по внешней системе команд).
RISC-процессоры
Reduced Instruction Set Computing (technology) — вычисления с сокращённым набором команд. Архитектура процессоров, построенная на основе сокращённого набора команд. Характеризуется наличием команд фиксированной длины, большого количества регистров, операций типа регистр-регистр, а также отсутствием косвенной адресации. Концепция RISC разработана Джоном Коком (John Cocke) из IBM Research, название придумано Дэвидом Паттерсоном (David Patterson).
Самая распространённая реализация этой архитектуры представлена процессорами серии PowerPC, включая G3, G4 и G5. Довольно известная реализация данной архитектуры — процессоры серий MIPS и Alpha.
MISC-процессоры
Minimum Instruction Set Computing — вычисления с минимальным набором команд. Дальнейшее развитие идей команды Чака Мура, который полагает, что принцип простоты, изначальный для RISC процессоров, слишком быстро отошёл на задний план. В пылу борьбы за максимальное быстродействие, RISC догнал и перегнал многие CISC процессоры по сложности. Архитектура MISC строится на стековой вычислительной модели с ограниченным числом команд (примерно 20–30 команд).
Многоядерные процессоры
Содержат несколько процессорных ядер в одном корпусе (на одном или нескольких кристаллах).
Процессоры, предназначенные для работы одной копии операционной системы на нескольких ядрах, представляют собой высокоинтегрированную реализацию системы «Мультипроцессор».
На данный момент массово доступны процессоры с двумя ядрами, в частности Intel Core 2 Duo на ядре Conroe и Athlon64X2 на базе микроархитектуры K8. В ноябре 2006 года вышел первый четырёхъядерный процессор Intel Core 2 Quad на ядре Kentsfield, представляющий собой сборку из двух кристаллов Conroe в одном корпусе.
10 сентября 2007 года были выпущены в продажу нативные (в виде одного кристалла) четырёхьядерные процессоры для серверов AMD Quad-Core Opteron, имевшие в процессе разработки кодовое название AMD Opteron Barсelona. 19 ноября 2007 вышел в продажу четырёхьядерный процессор для домашних компьютеров AMD Quad-Core Phenom. Эти процесоры реализуют новую микроархитектуру K8L (K10).
27 сентября 2006 года Intel продемонстрировала прототип 80-ядерного процессора. Предполагается, что массовое производство подобных процессоров станет возможно не раньше перехода на 32-нанометровый техпроцесс, а это в свою очередь ожидается к 2010 году.
Кэширование
Кэширование — это использование дополнительной быстродействующей памяти (кэш-памяти) для хранения копий блоков информации из основной (оперативной) памяти, вероятность обращения к которым в ближайшее время велика.
Различают кэши 1-, 2- и 3-го уровней. Кэш 1-го уровня имеет наименьшую латентность (время доступа), но малый размер, кроме того кэши первого уровня часто делаются многопортовыми. Так, процессоры AMD K8 умели производить 64 бит запись+64 бит чтение либо два 64-бит чтения за такт, процессоры Intel Core могут производить 128 бит запись+128 бит чтение за такт. Кэш 2-го уровня обычно имеет значительно большие латентности доступа, но его можно сделать значительно больше по размеру. Кэш 3-го уровня самый большой по объёму и довольно медленный, но всё же он гораздо быстрее, чем оперативная память.
Параллельная архитектура
Архитектура фон Неймана обладает тем недостатком, что она последовательная. Какой бы огромный массив данных ни требовалось обработать, каждый его байт должен будет пройти через центральный процессор, даже если над всеми байтами требуется провести одну и ту же операцию. Этот эффект называется узким горлышком фон Неймана.
Для преодоления этого недостатка предлагались и предлагаются архитектуры процессоров, которые называются параллельными. Параллельные процессоры используются в суперкомпьютерах.
Возможными вариантами параллельной архитектуры могут служить (по классификации Флинна):
- SISD — один поток команд, один поток данных;
- SIMD — один поток команд, много потоков данных;
- MISD — много потоков команд, один поток данных;
- MIMD — много потоков команд, много потоков данных.
Технология изготовления процессоров
История развития процессоров
Современная технология изготовления
Файл:AMD Athlon XP2000 Plus CPU.jpg В современных компьютерах процессоры выполнены в виде компактного модуля (размерами около 5×5×0,3 см) вставляющегося в zif-сокет. Большая часть современных процессоров реализована в виде одного полупроводникового кристалла, содержащего миллионы, а с недавнего времени даже миллиарды транзисторов. В первых компьютерах процессоры были громоздкими агрегатами, занимавшими подчас целые шкафы и даже комнаты, и были выполнены на большом количестве отдельных компонентов.
В начале 70-х годов ХХ века благодаря прорыву в технологии создания БИС и СБИС (больших и сверхбольших интегральных схем), микросхем, стало возможным разместить все необходимые компоненты ЦП в одном полупроводниковом устройстве. Появились так называемые микропроцессоры. Сейчас слова микропроцессор и процессор практически стали синонимами, но тогда это было не так, потому что обычные (большие) и микропроцессорные ЭВМ мирно сосуществовали ещё по крайней мере 10-15 лет, и только в начале 80-х годов микропроцессоры вытеснили своих старших собратьев. Надо сказать что переход к микропроцессорам позволил потом создать персональные компьютеры, которые теперь проникли почти в каждый дом. Первый микропроцессор Intel 4004 был представлен 15 ноября 1971 года корпорацией Intel. Он содержал 2300 транзисторов, работал на тактовой частоте 108 кГц и стоил 300$.
За годы существования технологии микропроцессоров было разработано множество различных их архитектур. Многие из них (в дополненном и усовершенствованном виде) используются и поныне. Например Intel x86, развившаяся вначале в 32 бит IA32 а позже в 64 бит x86-64. Процессоры архитектуры x86 вначале использовались только в персональных компьютерах компании IBM (IBM PC), но в настоящее время всё более активно используются во всех областях компьютерной индустрии, от суперкомпьютеров до встраиваемых решений. Также можно перечислить такие архитектуры как Alpha, Power, SPARC, PA-RISC, MIPS (RISC — архитектуры) и IA-64 (EPIC — архитектура).
Большинство процессоров используемых в настоящее время являются Intel-совместимыми, т. е. имеют набор инструкций и пр., как процессоры компании Intel.Будущие перспективы
В ближайшие 10-20 лет, скорее всего, изменится материальная часть процессоров ввиду того, что технологический процесс достигнет физических пределов производства. Возможно, это будут:
Квантовые процессоры
Процессоры, работа которых всецело базируется на квантовых эффектах. В настоящее время ведутся работы над созданием рабочих версий квантовых процессоров.
Российские микропроцессоры
Разработкой микропроцессоров в России занимается ЗАО «МЦСТ». Им разработаны и внедрены в производство универсальные RISC-микропроцессоры с проектными нормами 130 и 350 нм. Завершена разработка суперскалярного процессора нового поколения Эльбрус. Основные потребители российских микропроцессоров — предприятия ВПК.
Несмотря на постоянные улучшения и стабильный прогресс с каждым новым поколением, каких-то фундаментальных сдвигов в индустрии процессоров не происходит уже давно. Переход от ламп к транзисторам был огромным шагом вперёд, также как переход от отдельных компонентов на интегральные схемы. Однако после этого ничего столь же революционного и масштабного не происходило.
Да, транзисторы стали меньше, чипы стали быстрее, а их производительность выросла в сотни раз, но мы начинаем наблюдать застой.
Это четвертая и последняя статья в нашей серии, посвященной разработке и изготовлению процессоров. Начав с высокоуровневого кода, мы узнали, как он компилируется в язык ассемблера и далее – в бинарные инструкции, с которыми работает процессор. Мы заглянули в архитектуру процессоров и поняли, как они обрабатывают инструкции. Затем мы внимательно рассмотрели различные отдельные составляющие процессора.
Мы увидели, как создаются все эти структуры, как обеспечивается согласованная работа миллиардов транзисторов и как из необработанного кремния физически производятся процессоры. Мы узнали об основных свойствах полупроводников и о том, как на самом деле выглядят внутренности чипа.
Перейдём к четвёртой части. Поскольку компании-производители не разглашают результаты исследований и подробности своих актуальных технологий, трудно с уверенностью сказать, что именно находится внутри вашего процессора. Однако мы можем проанализировать современные открытые исследования и понять, в каком направлении движется отрасль.
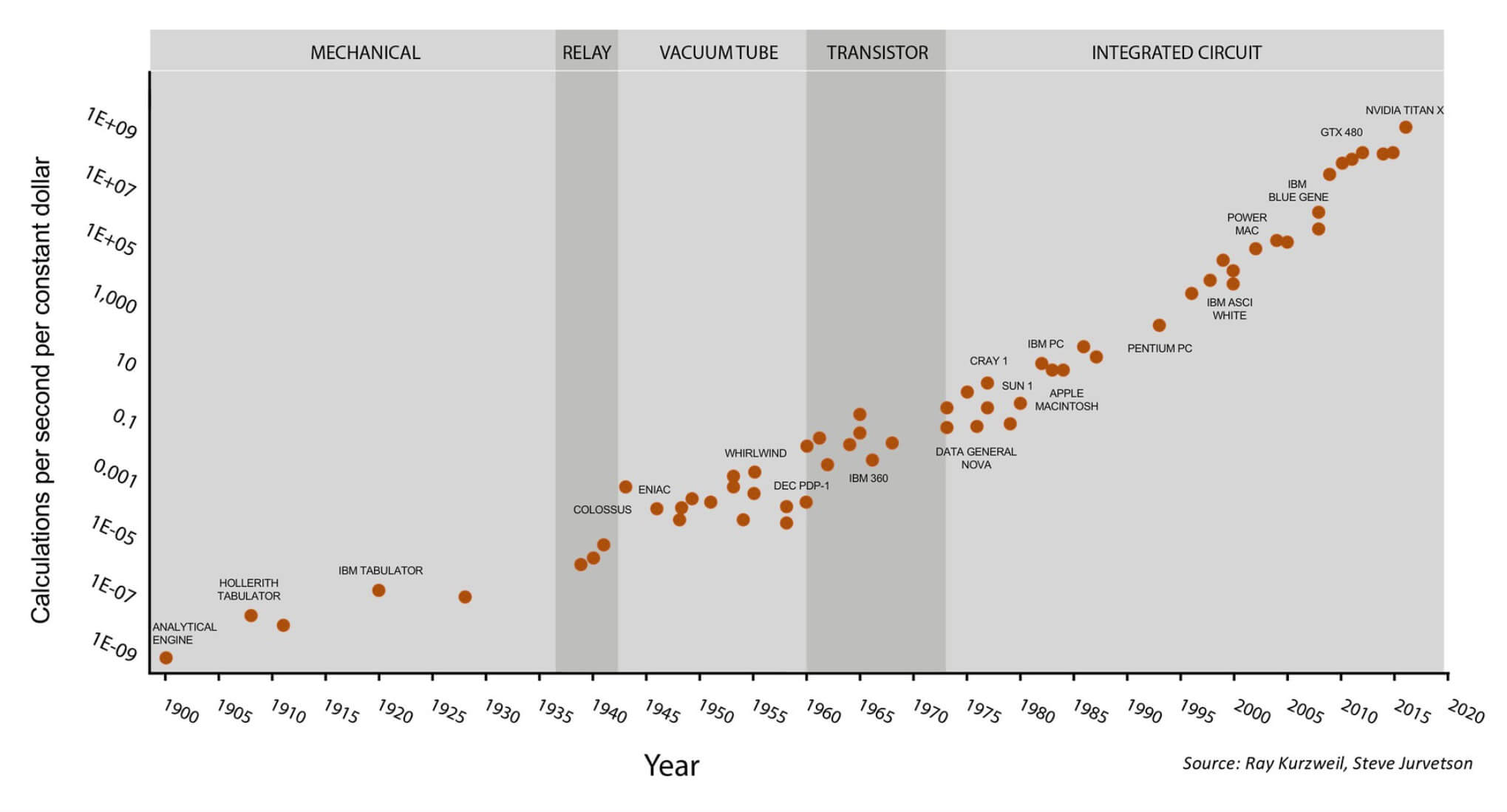
Одним из самых известных способов представления индустрии производства процессоров – это закон Мура, который гласит, что количество транзисторов в чипе удваивается примерно каждые полтора года. Долгое время этот закон оправдывал себя, но в последнее время рост стал замедляться. Транзисторы становятся настолько маленькими, что мы приближаемся к физическому пределу уменьшения размеров. Если не появится какой-либо прорывной технологии, нам придётся в будущем искать какие-то другие способы повышения производительности.
Закон Мура на протяжении последних 120 лет.
Этот график становится ещё интереснее, если обратить внимание на последние 7 точек – они относятся к GPU компании Nvidia, а не к процессорам общего назначения. Сверху: технологические периоды (механические устройства, реле, лампы, транзисторы, интегральные схемы); слева: стоимость вычислений в секунду (в "постоянных долларах"); снизу: годы. Иллюстрация Стива Джарветсона (Steve Jurvetson).
В то же время, очень многообещающе выглядит область квантовых вычислений. Я в этом не специалист, да почти и нет пока настоящих специалистов в этой области, поскольку технология лишь в процессе создания. Чтобы развеять мифы, скажу, что квантовые компьютеры не дадут вам 1000 кадров в секунду при рендеринге в реальном времени, например. Главное преимущество квантовых компьютеров на данный момент состоит в том, что они используют другие, более продвинутые и ранее недостижимые алгоритмы.

Один из прототипов квантового компьютера IBM.
В обычном компьютере транзистор либо включен, либо выключен, что соответствует 1 и 0. В квантовом компьютере возможна суперпозиция, когда бит может быть одновременно 0 и 1. Благодаря этой появившейся возможности ученые-кибернетики разрабатывают новые методы вычислений и могут решать задачи, неразрешимые с помощью существующих вычислительных мощностей. И дело не в том, что квантовые компьютеры быстрее, а в том, что они представляют собой принципиально новую модель вычислений, способную решать множество новых задач.
До массового внедрения этой технологии ещё 10-20 лет, так какие же тенденции наблюдаются сегодня в индустрии процессоров? Активно ведутся десятки исследований в разных областях, но я коснусь лишь нескольких, самых, на мой взгляд, значительных.
Растёт тенденция влияния гетерогенных вычислений. Это метод включения нескольких различных вычислительных элементов в одну систему. Большинству из нас знаком этот метод на примере отдельного GPU в компьютере. Центральный процессор очень гибок в настройке и может выполнять широкий спектр вычислений с адекватной скоростью. С другой стороны, GPU разработан специально для выполнения графических вычислений, таких как матричное перемножение. С подобными типами инструкции они справляются на порядки быстрее центрального процессора. Переложив некоторую часть нагрузки графическими вычислениями с CPU на GPU, мы можем ускорить выполнение расчетов. Любой программист легко оптимизирует своё ПО, нужным образом изменив алгоритм, а вот оптимизировать оборудование гораздо сложнее.
Но GPU – не единственная область, где применение акселерации становится обычным явлением. Большинство смартфонов имеют десятки аппаратных акселераторов, предназначенных для ускорения выполнения весьма специфических задач. Такой подход к вычислениям известен как «Море ускорителей» (Sea of Accelerators), и к примерам его применения можно привести криптографические процессоры, процессоры изображений, ускорители машинного обучения, кодеры/декодеры видео, биометрические процессоры и многое другое.
По мере того, как нагрузки становятся все более специализированными, разработчики оборудования включают в свои чипы все больше акселераторов. Провайдеры облачных сервисов, такие как AWS, начали предоставлять разработчикам карты FPGA для ускорения их вычислений в облаке. В отличие от обычных вычислительных элементов, таких как ЦП и GPU, имеющих жёсткую внутреннюю архитектуру, архитектура FPGA гибкая. Это практически программируемое оборудование, которое можно настроить в соответствии с нуждами пользователя.
Если требуется выполнять распознавание изображений, можно реализовать эти алгоритмы аппаратно. А чтобы сперва протестировать новое оборудование с помощью симуляции, прежде чем его фактически изготовлять, можно использовать FPGA. FPGA обеспечивает бо́льшую производительность и энергоэффективность, чем графические процессоры, но все же меньше, чем ASIC (application-specific integrated circuit, «интегральная схема специального назначения»). Другие компании, такие как Google и Nvidia, разрабатывают ASIC машинного обучения для ускорения распознавания и анализа изображений.

Взглянув на снимки кристаллов относительно современных процессоров, мы видим, что бо́льшую часть площади ЦП на самом деле занимает не само ядро. Всё бо́льшую долю занимают разного рода ускорители. Это позволило ускорить выполнение очень специализированных вычислений, а также значительно снизить энергопотребление.
Раньше при необходимости добавления в систему обработки видео, разработчики просто добавляли в систему новый чип. Однако это крайне неэффективный подход. Каждый раз, когда сигналу нужно пройти по физическому проводнику от одного чипа к другому, требуется огромное количество энергии на бит. Сама по себе крошечная доля джоуля не кажется особо значительной, но при передаче данных внутри, а не снаружи чипа, она используется на 3-4 порядка эффективнее. Благодаря интеграции таких акселераторов с ЦП, мы наблюдали рост количества чипов со сверхнизким энергопотреблением.
И всё же ускорители не идеальны. Чем больше мы добавляем их в схемы, тем менее гибким становится чип, и мы начинаем жертвовать общей производительностью ради пиковой производительности специализированных видов вычислений. На каком-то этапе весь чип просто превращается в набор акселераторов и перестаёт быть ЦП как таковым. Баланс между производительностью специализированных вычислений и общей производительностью всегда очень тщательно настраивается. Это разногласие между оборудованием общего назначения и специализированными нагрузками называется разрывом специализации (specialization gap).
Если некоторым кажется, что возможности GPU/Machine Learning уже достигли своего апогея, мы можем ожидать, что всё больший объём вычислений будет передаваться специализированным ускорителям. Облачные вычисления и ИИ продолжают развиваться, поэтому GPU выглядят лучшим решением для достижения требуемого уровня объёма вычислений.
Другой областью, где разработчики ищут способы повышения производительности, является память. Традиционно, чтение и запись значений всегда были одним из самых серьёзных «узких мест» для процессоров. Нам могут помочь быстрые и большие кэши, но считывание из ОЗУ или с SSD может занимать десятки тысяч тактовых циклов. Поэтому инженеры часто рассматривают доступ к памяти как более затратный, чем сами вычисления. Если процессор хочет сложить два числа, то ему сначала нужно вычислить адреса памяти, по которым хранятся числа, выяснить, на каком уровне иерархии памяти есть эти данные, считать данные в регистры, выполнить вычисления, вычислить адрес приёмника и записать значение в нужное место. Для простых инструкций, выполнение которых может занимать один-два цикла, это чрезвычайно неэффективно.
Новаторская идея, которую сейчас активно исследуют — это метод под названием Near-Memory Computing (NMC, “околопамятные вычисления”). Вместо того, чтобы извлекать небольшие фрагменты данных из памяти и вычислять их быстрым процессором, исследователи делают наоборот. Они экспериментируют с созданием небольших процессоров непосредственно в контроллерах памяти ОЗУ или SSD. Разместив вычисления ближе к памяти, мы можем получить огромную экономию энергии и времени, ведь теперь нет нужды гонять данные столь много и долго. Вычислительные модули имеют прямой доступ к нужным им данным, поскольку находятся непосредственно в памяти. Эта идея всё ещё находится в зачаточном состоянии, но результаты выглядят многообещающе.
Одно из препятствий, стоящих на пути реализации near-memory computing — это ограничения, накладываемые процессом изготовления чипа. Как говорилось в третьей части, процесс кремниевого производства очень сложен и состоит из десятков этапов. Эти процессы обычно специализированы для изготовления либо быстрых логических элементов, либо элементов памяти. Если попытаться создать чип памяти с помощью процесса, оптимизированного для вычислительных элементов, то получится чип с чрезвычайно низкой плотностью элементов. Если же попробовать создать процессор с помощью процесса, предназначенного для модулей памяти, то получим очень низкую производительность и большие тайминги.
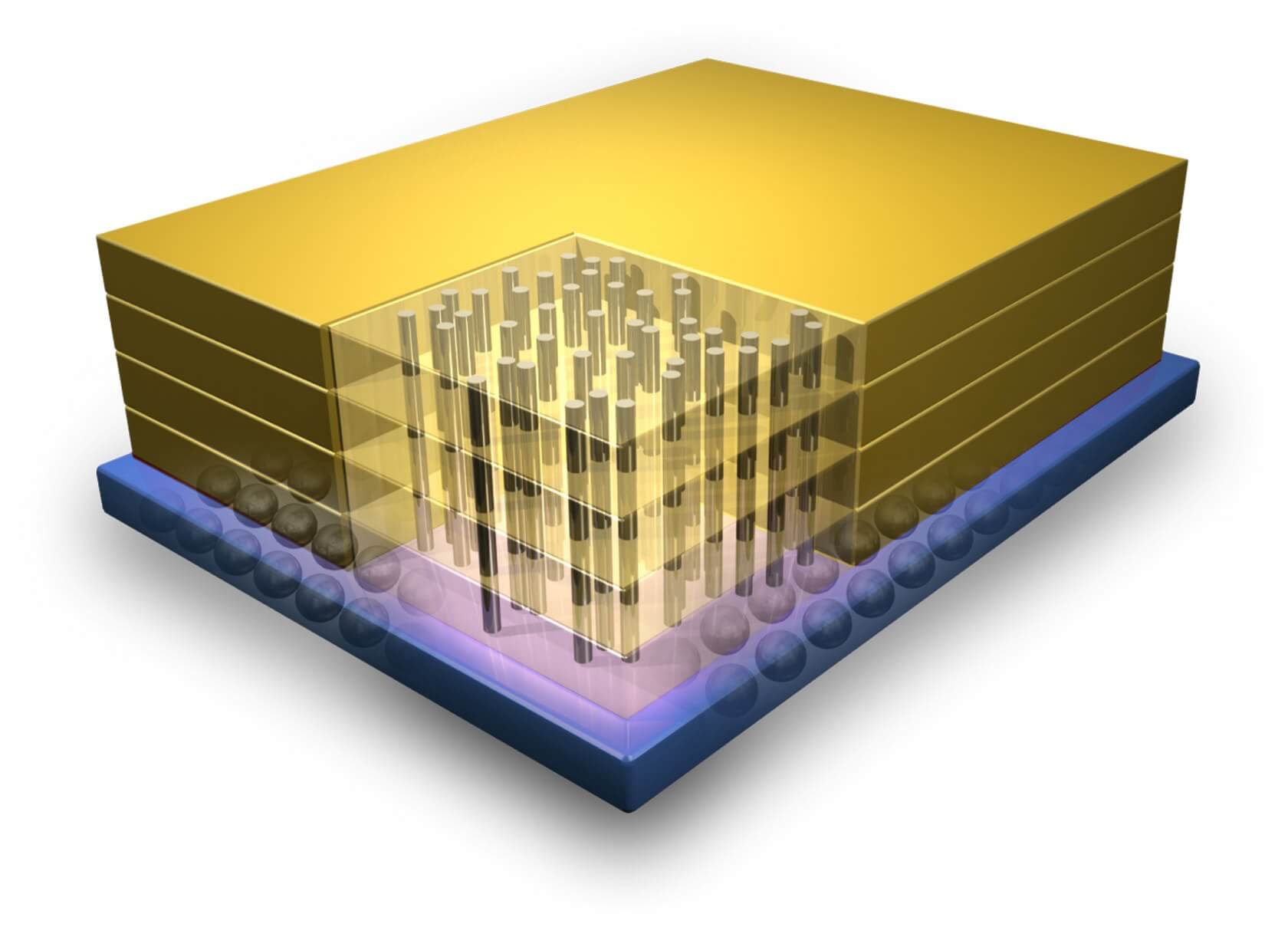
Пример 3D-интеграции, демонстрирующий вертикальные соединения между слоями транзисторов.
Одним из возможных решений этой проблемы является трёхмерная интеграция (3D Integration). Традиционные процессоры обладают одним очень широким слоем транзисторов, и это имеет свои ограничения. Как видно из названия, 3D-интеграция — это процесс расположения нескольких слоёв транзисторов друг над другом для повышения плотности и снижения задержек. Вертикальные проводники, производимые на разных процессах изготовления, используются для соединений между слоями. Эта идея была предложена уже давно, но индустрия отказалась от неё из-за серьёзных сложностей в её реализации. В последнее время мы наблюдаем возникновение технологии накопителей 3D NAND и возрождение этой области исследований.
Наряду с физическими и архитектурными изменениями, на всю индустрию полупроводников сильно повлияет тенденция усиления внимания к безопасности. До недавнего времени о безопасности процессоров думали чуть ли не в последнюю очередь. Это как если бы Интернет, электронная почта и многие другие системы, которые мы сегодня активно используем, разрабатывались почти без учёта безопасности. Все существующие меры защиты «прикручивались» по мере случавшихся инцидентов, чтобы мы чувствовали себя защищёнными. Касательно процессоров, подобная практика больно ударила по производителям, и особенно по Intel.
Уязвимости Spectre и Meltdown — это, вероятно, самые известные примеры того, как проектировщики добавляют функции, значительно ускоряющие процессор, не в полной мере осознавая связанные с этим угрозы. При разработке же современных процессоров гораздо большее внимание уделяется безопасности как ключевой части архитектуры. При её повышении часто страдает производительность, но учитывая ущерб, который компании могут понести из-за появления серьёзных уязвимостей, очевидно, что безопасностью пренебрегать не стоит в той же мере, как производительностью.
В предыдущих частях нашей серии мы коснулись таких техник, как высокоуровневый синтез, позволяющий проектировщикам сначала описать структуру на языке высокого уровня, а затем позволить сложным алгоритмам определить оптимальную для выполнения функции аппаратную конфигурацию. С каждым поколением этапы проектирования становятся всё более дорогостоящими, поэтому инженеры ищут способы ускорения разработки. Следует ожидать, что в дальнейшем и эта тенденция проектирования оборудования при помощи ПО будет только усиливаться.
Будущее предсказать невозможно, но рассмотренные нами в статье инновационные идеи и области исследований могут служить своего рода дорожной картой наших ожиданий в сфере проектирования процессоров будущего. Что с уверенностью можно сказать, так это то, что мы близимся к концу типичных усовершенствований процесса производства. Чтобы и дальше продолжать увеличивать производительность в каждом поколении, разработчикам придётся искать ещё более сложные решения.
Надеемся, что наша серия из четырёх статей пробудила ваш интерес к тому, как проектируются и производятся процессоры, как контролируется их качество и многому другому. Существует бесконечное количество материалов по этой теме, и если бы мы попытались раскрыть их все, то каждая из статей заняла бы целый университетский курс. Хочется надеяться, вы узнали для себя что-то новое и теперь лучше понимаете, насколько сложны компьютеры на каждом из уровней. Если у вас есть предложения, какую тему нам стоит рассмотреть поглубже, мы всегда готовы выслушать их.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Прерывания
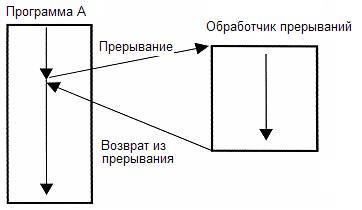
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно
1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Первые центральные процессоры были многоножками
1940–1960-е годы
Прежде чем углубляться в историю развития центральных процессоров, необходимо сказать несколько слов о развитии компьютеров в целом. Первые CPU появились еще в 40-х годах XX века. Тогда они работали с помощью электромеханических реле и вакуумных ламп, а применяемые в них ферритовые сердечники выполняли роль запоминающих устройств. Для функционирования компьютера на базе таких микросхем требовалось огромное количество процессоров. Подобный компьютер представлял собой огромный корпус размером с достаточно большую комнату. При этом он выделял большое количество энергии, а его быстродействие оставляло желать лучшего.
Компьютер, использующий электромеханические реле
Однако уже в 1950-х годах в конструкции процессоров стали применяться транзисторы. Благодаря их применению инженерам удалось добиться более высокой скорости работы чипов, а также снизить их энергопотребление, но повысить надежность.
В 1960-х годах получила свое развитие технология изготовления интегральных схем, что позволило создавать микрочипы с расположенными на них транзисторами. Сам процессор состоял из нескольких таких схем. С течением времени технологии позволили размещать все большее количество транзисторов на кристалле, в связи с чем количество используемых в CPU интегральных схем сокращалось.
Тем не менее архитектура процессоров была всё ещё очень и очень далека от того, что мы видим сегодня. Но выход в 1964 году IBM System/360 немного приблизил дизайн тогдашних компьютеров и CPU к современному — прежде всего в плане работы с программным обеспечением. Дело в том, что до появления этого компьютера все системы и процессоры работали лишь с тем программным кодом, который был написан специально для них. В своих ЭВМ компания IBM впервые использовала иную философию: вся линейка разных по производительности CPU поддерживала один и тот же набор инструкций, что позволяло писать ПО, которое работало бы под управлением любой модификации System/360.
Компьютер IBM System/360
По своей архитектуре процессор IBM System/360 являлся CISC-решением. Как вы знаете, все интегральные схемы делятся на две большие категории: RISC (Reduced Instruction Set Computer) и CISC (Complex Instruction Set Computer). Вторые работают со сложными инструкциями, а первые — с упрощенными. С точки зрения современных достижений, сложность инструкций для CISC-процессоров заключается в том, что их длина не ограничена. Вдобавок к этому они могут содержать сразу несколько арифметических действий. Однако в то время дизайн RISC не существовал в принципе, и IBM, а также другие производители использовали CISC-архитектуру вплоть до 1980-х годов.
Несмотря на высокую стоимость, System/360 стал относительно успешным на рынке. Во время презентации компьютера во всех городах США присутствовало порядка 100 тысяч бизнесменов, говорится в официальном пресс-релизе IBM от 7 апреля 1964 года. В первый месяц американская компания получила более 1000 заказов на IBM System/360 и еще одну тысячу в последующие четыре месяца. Для того времени цифры более чем впечатляющие. Компьютеры System/360 также активно использовались агентством NASA для управления космическими полетами в ходе программы «Аполлон».
IBM zSeries до сих пор поддерживают работу программного обеспечения, написанного для платформы System/360
Возвращаясь к теме совместимости System/360, нужно подчеркнуть, что IBM уделила очень много внимания данному аспекту. Например, современные компьютеры линейки zSeries до сих пор поддерживают работу программного обеспечения, написанного для платформы System/360.
Первым коммерчески успешным устройством DEC стал компьютер PDP-8, выпущенный в 1965 году. В отличие от PDP-1, новая система была 12-битной. Стоимость PDP-8 составляла 16 тысяч долларов США – это был самый дешевый миникомпьютер того времени. Благодаря столь низкой цене устройство стало доступно промышленным предприятиям и научным лабораториям. В итоге было продано около 50 тысяч таких компьютеров. Отличительной архитектурной особенностью процессора PDP-8 стала его простота. Так, в нем было всего четыре 12-битных регистра, которые использовались для задач различного типа. При этом PDP-8 содержал всего 519 логических вентилей.
Компьютер PDP-8. Кадр из фильма «Три дня Кондора»
Intel 4004
1971 год вошел в историю как год появления первых микропроцессоров. Да-да, таких решений, которые используются сегодня в персональных компьютерах, ноутбуках и других устройствах. И одной из первых заявила о себе тогда еще только-только основанная компания Intel, выпустив на рынок модель 4004 — первый в мире коммерчески доступный однокристальный процессор.
Прежде чем перейти непосредственно к процессору 4004, стоит сказать пару слов о самой компании Intel. Её в 1968 году создали инженеры Роберт Нойс и Гордон Мур, которые до того момента трудились на благо компании Fairchild Semiconductor, и Эндрю Гроувом. Кстати, именно Гордон Мур опубликовал всем известный «закон Мура», согласно которому количество транзисторов в процессоре удваивается каждый год.
Уже в 1969-ом, спустя всего лишь год после основания, компания Intel получила заказ от японской компании Nippon Calculating Machine (Busicon Corp.) на производство 12 микросхем для высокопроизводительных настольных калькуляторов. Первоначальный дизайн микросхем был предложен самой Nippon. Однако такая архитектура не приглянулась инженерам Intel, и сотрудник американской компании Тед Хофф предложил сократить число микросхем до четырех за счет использования универсального центрального процессора, который бы отвечал за арифметические и логические функции. Помимо центрального процессора, архитектура микросхем включала оперативную память для хранения данных пользователя, а также ПЗУ для хранения программного обеспечения. После утверждения окончательной структуры микросхем продолжилась работа над дизайном микропроцессора.
В апреле 1970 года к команде инженеров Intel присоединился итальянский физик Федерико Фаджин, который до этого также работал в компании Fairchild. У него был большой опыт работы в области логического проектирования компьютеров и технологий МОП (металл-оксид-полупроводник) с кремниевыми затворами. Именно благодаря вкладу Федерико инженерам Intel удалось объединить все микросхемы в один чип. Так увидел свет первый в мире микропроцессор 4004.
Процессор Intel 4004
Что касается технических характеристик Intel 4004, то, по сегодняшним меркам, конечно, они были более чем скромные. Чип производился по 10-мкм техпроцессу, содержал 2300 транзисторов и работал на частоте 740 кГц, что означало возможность выполнения 92 600 операций в секунду. В качестве форм-фактора использовалась упаковка DIP16. Размеры Intel 4004 составляли 3x4 мм, а по бокам располагались ряды контактов. Изначально все права на чип принадлежали компании Busicom, которая намеревалась использовать микропроцессор исключительно в калькуляторах собственного производства. Однако в итоге они позволили Intel продавать свои чипы. В 1971 году любой желающий мог приобрести процессор 4004 по цене примерно 200 долларов США. К слову, чуть позже Intel выкупила все права на процессор у Busicom, предрекая важную роль чипа в последующей миниатюризации интегральных схем.
Процессор Intel 4040
Спустя три года после выхода процессора Intel 4004 увидел свет его преемник — 4-битный Intel 4040. Чип производился по тому же 10-мкм техпроцессу и работал на той же тактовой частоте 740 кГц. Тем не менее, процессор стал немного «сложнее» и получил более богатый набор функций. Так, 4040 содержал 3000 транзисторов (на 700 больше, чем у 4004). Форм-фактор процессора остался прежним, однако вместо 16-пинового стали использовать 24-пиновый DIP. Среди улучшений 4040 стоит отметить поддержку 14 новых команд, увеличенную до 7 уровней глубину стека, а также поддержку прерываний. «Сороковой» использовался в основном в тестовых устройствах и управлении оборудованием.
Intel 8008
Читайте также: