
1с что за файл vocabularymain dat
Обновлено: 04.07.2024
Работа с новым форматом файловой базы данных, начиная с "1С:Предприятие" 8.3.8
Начиная с версии платформы "1С:Предприятие" 8.3.8 появилась поддержка нового формата файловых баз данных (включая работу в режиме совместимости с предыдущими версиями). Новый формат файловых баз данных предназначен для ускорения процесса открытия и работы с информационной базой, поэтому, начиная с версии платформы 8.3.9, новый формат используется по умолчанию при создании новых файловых баз данных.
В новом формате (версии " 8.3.8" ) появились следующие возможности:
- Уменьшен размер и оптимизирована структура заголовка с метаинформацией в файле 1Cv8.1CD . Это позволяет существенно снизить число операций чтения файла при открытии базы данных и, тем самым, заметно ускорить время старта и начала работы программы.
- Теперь можно настраивать размер внутренней страницы файла данных. Это размер порции данных, в которых хранится информация и которыми обменивается программа с файловой системой. Предыдущий формат файловой базы данных (версии " 8.2.14" ) поддерживал единственный размер внутренней страницы файла – 4Кб . Новый формат по умолчанию использует размер страницы 8Кб , но позволяет его менять в диапазоне от 4Кб до 64Кб .
Наибольший эффект от использования нового формата файловых баз данных ожидается в следующих сценариях:
- "холодный" запуск программы,
- работа с файлами базы данных по локальной сети,
- работа с сильно фрагментированной базой данных,
- использование дисковых подсистем с невысокой производительностью.
При создании новых файловых баз данных рекомендуется использовать настройки формата базы по умолчанию (версия формата " 8.3.8 ", размер страницы файла 8Кб ). Если Вы используете базу данных, созданную в предыдущих версиях платформы, и наблюдаете недостаточно высокую производительность при старте и во время работы программы, то рекомендуется сконвертировать базу данных на новый формат файла.
Для преобразования формата файловой базы данных в комплектацию поставки платформы "1С:Предприятие" добавлена утилита CNVDBFL.EXE , которая должна находиться в папке " \bin " вашей установки "1С:Предприятие". Например, полный путь к папке, где находится утилита, может быть " C:\Program Files (x86)\1cv8\8.3.9.1850\bin ", где " 8.3.9.1850 " – номер версии установленной платформы "1С:Предприятие". В этой же папке находятся другие исполняемые файлы платформы, такие как, например, "1Cv8.exe".
Если Вы не можете найти утилиту CNVDBFL.EXE в папке " \bin ", проверьте, что Вы используете версию "1С:Предприятие" 8.3.8 и выше.
Подробно про использование утилиты CNVDBFL.EXE можно почитать в документации по администрированию "1С:Предприятие", или в документации: "Утилита преобразования cnvdbfl". Также информация о возможностях и командах утилиты CNVDBFL.EXE выводится при её запуске без параметров, или с ключом " -h ".
Если Вы хотите проверить параметры Вашей файловой базы данных, используйте следующий вызов утилиты (указав в команде правильный путь к Вашей базе данных):
При этом утилита выведет версию формата файла и размер страницы.
Версия формата " 8.3.8 " указывает на то, что используется новый формат файла. Версия формата " 8.2.14 " означает, что формат – старый, и имеет смысл выполнить конвертацию базы данных в новый формат.
Размер страницы может принимать одно из значений: 4096 , 8192 , 16384 , 32768 , или 65536 байт. Для старой версии формата файла используется размер страницы 4096 байтов ( 4Кб ), для новой версии по умолчанию установлен размер в 8192 байта ( 8Кб ).
Для конвертации файловой базы данных Вы можете использовать следующую команду:
где 16k замените на нужный размер страницы файла ( 4k , 8k , 16k , 32k , или 64k ) и укажите правильный путь к Вашей базе данных.
ВНИМАНИЕ!
Напоминаем, что чтобы избежать риска потери Ваших данных, всегда имейте свежую резервную копию Вашей файловой базы данных перед выполнением операции конвертации файлов.
Анализ причин роста сеансовых данных
Платформа "1С:Предприятие" в своей работе постоянно использует механизм, называемый "сеансовые данные". В этих данных хранится служебная информация, необходимая для работы сеанса "1С:Предприятия". Например, все, что введено в поля ввода на форме, при серверных вызовах сбрасывается в сеансовые данные.
При вызове методов: ПоместитьВоВременноеХранилище, ПоместитьФайл, НачатьПомещениеФайла, значения указанные в параметрах, записываются в сеансовые данные.
При фоновом исполнении отчетов СКД, результат отчета помещается в сеансовые данные, а затем передается в клиентскую часть.
С точки зрения операционной системы, сеансовые данные представляют собой файлы в каталоге …\srvinfo\reg_<номер порта>\snccntx<GUID>.
С точки зрения внутренней структуры - это noSQL база данных (key-value storage).
Особенности работы платформы с сеансовыми данными
За работу с сеансовыми данными отвечает менеджер кластера – rmngr.exe Если в кластере несколько рабочих серверов, то сеансовые данные будут расположены в соответствии с требованиями назначения функциональности.
Если требования не заданы, то сеансовые данные распределятся равномерно по всем рабочим серверам.
Сеансовые данные растут блоками по 64 Мб. Когда заканчивается блок, то менеджер кластера выделяет следующий блок в 64Мб.Блоки большего объема возможны в результате помещения объемных данных во временные хранилища.
Для обеспечения скорости работы, платформа всегда пишет новые данные в конец, аналогично transaction log в СУБД. Таким образом, размер сеансовых данных постоянно растет. Во всем объеме сеансовых данных, существуют как актуальные, так и устаревшие данные. Актуальность данных определяется способом их помещения:
- Если сеансовые данные помещены из формы и в качестве идентификатора передается идентификатор формы (ЭтаФорма.УникальныйИдентификатор), то данные считаются актуальными, пока открыта форма.
- Если в качестве идентификатора передан УникальныйИдентификатор, не являющийся уникальным идентификатором формы (Новый УникальныйИдентификатор), то значение перестанет быть актуальным после завершения сеанса пользователя.
- Если ничего не передано, то значение перестанет быть актуальным при любом следующем серверном вызове.
Перед выделением следующего блока на диске, проверяется, прошло ли 5 секунд с момента выделения предыдущего блока. Если 5 секунд прошло, то запускается "сборщик мусора" (key value garbage collector). Сборщик оценивает процент актуальных сеансовых данных в общем объеме. Если актуальные данные занимают менее 25% от общего объема, то все актуальные данные копируются в новые файлы, а затем все старые файлы сеансовых данных удаляются.

Так как каждый сеанс (клиенты, фоновые задания, web-сервисы) в своей работе постоянно пишет информацию в сеансовые данные, то при большом количестве пользователей, скорость дисковой подсистемы, на которой расположены файлы сеансовых данных, играет очень важную роль. При большом количестве пользователей, рекомендуется располагать файлы сеансовых данных на максимально быстрых дисках. Желательно RAM-drive. Отказоустойчивость дисков не важна, т.к. при потере сеансовых данных, никакой важной информации утеряно не будет.
Следует отметить порядок размещения сеансовых данных. Если поместить во временное хранилище двоичные данные или файл, то эти данные пройдут в качестве потока байт через rphost, затем в rmngr, который сбросит этот поток на диск. Если же, в качестве помещаемого значения, будет выступать коллекция (таблица значений, результат запроса, массив…), то сначала вся эта коллекция разместиться в памяти rphost, а только затем преобразуется в поток байт и будет передана в rmngr.
Размещение сеансовых данных в памяти
При работе кластера "1С:Предприятия", файлы сеансовых данных отображаются в память (mapping). Подробнее см. статью.
За счет данного механизма, процесс работает с файлом как с оперативной памятью. Файл загружается в память не целиком, а только необходимая часть.
Однако, в операционной системе Windows, отображенные в память файлы, влияют на счетчик Memory\Available Mbytes. При сильном росте сеансовых данных можно увидеть следующую картину:

Свободное место на диске, где расположены сеансовые данные, уменьшается синхронно со свободной памятью сервера. На самом деле, если посмотреть данные RamMap то видно, что большая часть оперативной памяти выделена под Mapped File

Размер памяти, указанный в колонке Standby – это неиспользуемая память (фактически свободная). При запросе памяти любым процессом, ему будет выделена память из этой области.
Следует учитывать данную особенность счетчика Memory\Available Mbytes при построении систем мониторинга или приложений, которые опираются на объем доступной оперативной памяти.
Для косвенной оценки эффективности работы операционной системы с сеансовыми данными, можно использовать счетчик Memory\Page Faults/sec, который показывает на сколько часто процессы обращаются за страницами в память, но не находят их там и подгружают с диска.
Если значение данного счетчика велико, то это может свидетельствовать о нехватке оперативной памяти для кэширования в ней сеансовых данных. В этом случае, необходимо принять решение об увеличении оперативной памяти, либо об оптимизации работы приложения с сеансовыми данными.
Проблемы сеансовых данных
Ошибка совместного доступа к файлу snccntx.dat

При появлении данной ошибки необходимо действовать по алгоритму:
1. Проверить права на папку сеансовых данных для пользователя, от которого запущена служба сервера "1С:Предприятия". Должны быть полные права.
2. Открыть на рабочем сервере диспетчер задач, установить видимость колонки "Командная строка"

3. Необходимо найти процессы rmngr.exe с одинаковым значением параметра –pid.

4. Открыть консоль кластера. Развернуть ветку кластера, порт которого соответствует параметру –regport , найденных rmngr.exe с одинаковым значением параметра –pid

5. Сопоставить PID из диспетчера задач с PID в консоли кластера. Тот процесс rmngr.exe, которого нет в консоли – принудительно завершить.
Закончилось место на диске, где расположены сеансовые данные
Необходимо следить за наличием свободного места на диске, где расположены сеансовые данные.
Не следует размещать файлы технологических журналов на одном диске с сеансовыми данными.
Если на диске, где расположены сеансовые данные, закончится место, то картина будет совершенно "апокалиптическая". Менеджер кластера будет постоянно завершаться с формированием дампа. Начнутся сотни попыток запусков рабочих процессов, которые сразу же будут завершаться с ошибками. После того, как на диске появится свободное место, сервер "1С:Предприятия" запустится в нормальном режиме.
Так же, необходимо следить за размером самих сеансовых данных. Если периодически их размер становится существенным, то необходимо обратить на это особое внимание. Следует помнить, что при срабатывании "сборки мусора" необходимо наличие свободного места на диске, в размере 25% от общего объема сеансовых данных. Если этих 25% не будет, то кластер завершит свою работу аварийно.
Изменить расположение сеансовых данных, можно указав параметр –d в строке запуска службы агента сервера.
В данном каталоге, также расположены: реестр кластера, индекс полнотекстового поиска и журнал регистрации.
Влияние циклических ссылок на рост сеансовых данных
Чаще всего при выполнении процедуры ПоместитьВоВременноеХранилище, указывается идентификатор формы (ЭтаФорма.УникальныйИдентификатор). Как написано в документации, при указании идентификатора формы данные перестают считаться актуальными после того как форма будет закрыта.
Однако, если форма содержит в себе циклические ссылки (см. статью), то после закрытия формы она не уничтожается. Это приводит следующим отрицательным эффектам:
- данные формы остаются в памяти
- сеансовые данные, выделенные для формы, считаются актуальными, пока не будет завершен сеанс
Чтобы избежать данной ситуации, необходимо исключить все циклические ссылки в форме (см. статью).
Необходимо стараться формировать отчеты СКД в фоновом режиме. Так как результат отчета помещается во временное хранилище фоновым заданием, то после завершения задания данный результат будет считаться неактуальным.
Методика анализа роста сеансовых данных
Сбор данных
Необходимо собрать технологический журнал:
Данный технологический журнал может занимать значительный объем. Поэтому необходимо располагать его на дисках имеющих достаточно свободного пространства, периодически переносить старые файлы журнала на другой диск и там архивировать (сохраняя структуру папок).
После того, как технологический журнал будет собран, необходимо провести "парсинг" и выгрузить его данные в файлы csv формата:
На основании данных, которые собраны в папках rmngr_*, необходимо сформировать csv файл вида:
- <файл ТЖ> – имя файла технологического журнала,
- <CallID> – значение свойства CallID,
- <InBytes> - значение свойства InBytes.
В файле …/rmngr_7188/ 15063011. log есть строка:
Данная строка должна быть преобразована в строку:
Необходимо исключить из итогового файла строки с InBytes=0, т.к. они не представляют интереса, но занимают значительный объем.
На основании данных, которые собраны в папках rphost_*, необходимо сформировать csv файл вида:
- <процесс>– имя папки рабочего процесса,
- <файл ТЖ> – имя файла технологического журнала,
- <t:clientID> – значение свойства t:clientID,
- <CallID> – значение свойства CallID.
В файле …/ rphost_1352 / 15063011 .log есть строка:
Данная строка должна быть преобразована в строку:
На основании данных, которые собраны в папках rphost_*, необходимо сформировать csv файл вида:
- <процесс> – имя папки рабочего процесса,
- <t:clientID> – значение свойства t:clientID,
- <Usr> – Имя пользователя из свойства Usr.
В файле …/ rphost_1352 /15063011.log есть строка:
Данная строка должна быть преобразована в строку:
В итоге должно получиться 3 файла: scall.csv, call.csv, conn.csv
Пример создания файлов csv, на основании данных технологического журнала, см. в обработке.
Создание базы данных для анализа
Необходимо создать пустую базу данных (MS SQL Server), в которую добавить таблицы:
Затем, в эти таблицы необходимо загрузить данные из соответствующих csv файлов. Сделать это можно с помощью SQL Server Integration Services

После того, как информация будет загружена в таблицы, можно проводить анализ.
Анализ работы с сеансовыми данными
TOP – 10 пользователей в разрезе процессов и времени
Запрос покажет топ-10 пользователей, которые поместили больше всего сеансовых данных в час. Затем необходимо разобраться с самым верхним (в текущем случае):
Т.е. в процессе rphost_1352 за час с 11-00 по 12-00 пользователь с идентификатором 518 записал в сеансовые данные 2 046 616 858 байт (2Гб).
Далее, необходимо найти все идентификаторы вызовов, которые записывал сеанс 518:
Говорим о принципах работы этого P2P-протокола и проектах, построенных на его основе.

/ Unsplash / Alina Grubnyak
Что такое Dat
Его участники разрабатывают сервисы, способствующие улучшению муниципальных услуг. Dat создавался как инструмент для передачи персональных данных граждан между гос. организациями. Но позже фокус проекта сместился в сторону научной информации.
Вокруг Dat сформировалось крупное сообщество (7 тыс. звезд на GitHub). Продвижением протокола и построенных на его основе приложений занимается некоммерческая организация Dat Foundation. Её поддерживают Mozilla, открытый фонд Code for Science & Society и разработчик P2P-сетей Wireline.
Как он работает
Для загрузки файла в сети Dat необходимо указать его URL. Вот пример:
О других протоколах и стандартах в нашем блоге на Хабре:
Когда пир узнает IP-адрес и номер порта другого пира, они устанавливают TCP-соединение. Все передаваемые данные шифруются — для этого используется система поточного шифрования XSalsa20. Алгоритм применяет хеш-функцию с двадцатью циклами. Операции преобразования напоминают те, что задействованы в AES.
Данные в Dat-сети передаются отдельными фрагментами (chunks), размеры которых могут отличаться. Система позволяет добавлять новые фрагменты в Dat-файл, но не разрешает модифицировать или удалять существующие. По словам разработчиков, такой подход позволяет сохранить всю историю изменения документов. Система получает возможность свободно функционировать в условиях с нестабильным подключением.

/ Unsplash / Sven Brandsma
Сейчас члены Dat Foundation улучшают протокол, чтобы он мог работать с большими объемами данных. В частности, планируют переработать файловую систему (называется Hyperdrive), чтобы она справлялась с миллионами файлов, и внедрить новые механизмы поиска пиров (Hyperswarm).
Кто использует
Примером может быть открытый проект ScienceFair. Это — десктопное приложение для просмотра и поиска научной литературы. На этой платформе ученые и исследователи могут работать с личными заметками, журналами или выжимками из них. Для отображения контента из научной литературы ScienceFair использует ридер Lens — он отвечает за рендер формата JATS XML.
Хотя Dat изначально задумывался как протокол для обмена научной информацией, комьюнити использует его для создания веб-сайтов, чатов и других приложений.
Один из свежих примеров — P2P-браузер Beaker, который разработан в партнерстве с командой, развивающей Dat. Его цель — дать пользователям возможность размещать веб-сайты «прямо в браузере». Авторы Beaker запустили облачный сервис Hashbase, поддерживающий постоянный доступ к Dat-сайтам, чьи локальные копии недоступны.
Проект полностью открыт, и его исходники можно найти на GitHub. Если вы хотите оценить возможности браузера самостоятельно, то для его запуска на Linux понадобится установить libtool, m4 и autoconf:
После достаточно запустить:
Больше примеров приложений можно найти на сайте проекта.
Аналог
Решение уже использует хостинг Neocities и маркетплейс OpenBazaar. Разработчики протоколов, подобных IPFS и Dat, надеются, что их проекты дадут интернет-пользователям больше контроля над своими данными.
О чем мы пишем в корпоративном блоге VAS Experts:

За несколько лет сначала вынужденного, а потом и вполне занимательного администрирования 1С у меня накопился набор решений под большинство особенностей продукта. Предлагаю отложить в сторону высокие материи про кластеры и тюнинг SQL, и перетряхнуть запасы скриптов и механизмов, которые облегчают жизнь с 1С.
Будут как простые инструменты создания новых пользователей и мониторинга "все ли вышли из базы", так и более изощренные интерфейсы проверки целостности базы и ее перемещения.
Как у большинства сложных приложений, у 1С через некоторое время работы вылезают странные ошибки, и возникает порой необъяснимое поведение. Специальные люди по 1С советуют в таких случаях почистить кэш.
Если запустить 1С с параметром /ClearCache, то будут очищены только клиент-серверные запросы. Локальные метаданные останутся и их нужно удалять отдельно на уровне файлов и папок. Эти данные хранятся в профиле пользователя, в папках с длинными названиями из GUID баз данных. Если баз на сервере немного, то такой кэш нетрудно удалить руками. Но если БД исчисляется десятками, то чистке вручную вы не обрадуетесь.
В подобных ситуациях выручит скрипт на Powershell, который запускается каждый раз при выходе пользователя из системы:
И никаких связанных со старым кэшем проблем.
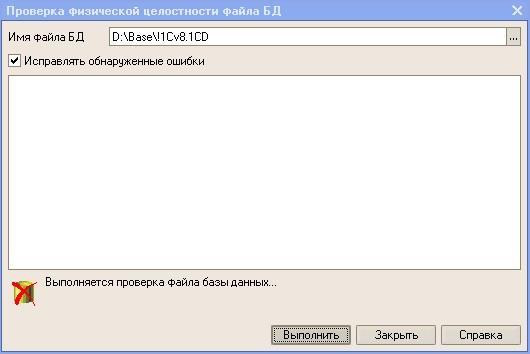
Для исправления испорченной файловой базы в поставку 1С входит утилита chdbfl.exe, которая просто считывает содержимое базы во временный файл. Если какие-то данные считать не может — пропускает. При этом у нее нет ключей запуска для автоматизации, и проверку приходится запускать вручную.
Вообще, правильнее запускать проверку БД конфигуратором, но этот процесс проходит значительно дольше. Если же использовать только проверку физической целостности средствами chdbfl.exe, то не забывайте делать резервную копию из-за возможной потери данных.
Для баз 8.1 Андрей Скляров создал хороший инструмент Check1CD, с двумя параметрами запуска: "исправлять найденные ошибки" и “путь к базе”.
Но в Check1CD не хватает двух вещей:
Раз есть "хотелка" и немного свободного времени, то почему бы не попробовать решить вопрос самостоятельно?
Доработать код для передачи параметров через ключи командной строки — дело техники.
С выходом 1С 8.2 возникла проблема — путь к chdbfl менялся с установкой нового релиза. Что ж, дополним скрипт:
Надо сказать, недавно был опубликован исходный код Check1CD. Да, тоже на AutoIT.
Аналогичный механизм можно применять и для автоматического запуска различных регламентных механизмов, где нужно запускать 1С и ждать завершения операции.
При различных регламентных операциях с 1С (ночное обновление конфигурации или бэкап в .dt) важно обеспечить отсутствие подключенных к ней пользователей. Можно конечно запускать 1С: Предприятие с ключом /C ЗавершитьРаботуПользователей, но это не всегда удобно, да и хочется же потом написать личное письмо с рекомендациями по устранению склероза.
Можно использовать штатную возможность подключения к 1С через COMConnector и скрипт на AutoIT. Код написан под 1С 8.1 и позволяет выкинуть пользователей из базы с записью в журнал.
Но операцию иногда нужно проворачивать по просьбе самого пользователя, который запустил "тяжелый" отчет и повесил 1С. Если не хотите решать эти вопросы самостоятельно, то просто выведите любителям “тяжелых” отчётов ярлык на скомпилированный скрипт:
Еще COMConnector помогает проверить наличие обновлений конфигурации, получить какую-то информацию из базы, и автоматизировать заведение пользователей в 1С.
На мой взгляд, создавать новых пользователей 1С должен системный администратор, а не программист 1С. Но последнему нужно сделать процесс максимально простым. Чтобы администратору не приходилось "заглядывать" в каждую базу отдельно, можно использовать еще один скрипт.
Для примера приведу функцию создания пользователей в типовой Бухгалтерии 2.0.
Юрлиц развелось слишком много — нужно разбивать на столбцы.
Занятно, но после смены нескольких поколений администраторов в одной компании из далекого прошлого новенькие уже не знали как создать пользователя вручную.
Если нужно перенести базу 1С: Предприятия вместе с ее данными в SQL на другой сервер, то делать это вручную целесообразно только для 1-2 БД.
При большем их числе рутина станет утомительной - лучше воспользоваться скриптом.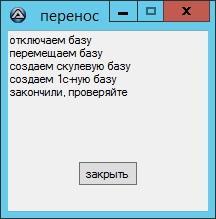
Список баз для миграции можно брать и из файла, а лог выводить в текстовый файл. Аналогичным образом можно конвертировать несколько десятков баз из файловых в SQL простой выгрузкой-загрузкой в .dt
Конечно, это далеко не все, что можно автоматизировать в связке с 1С. Но разного рода обмены, получение real-time информации из 1С в других приложениях и прочие сценарии не попали в этот обзор из-за узкой направленности и специфики.
Наверняка у вас тоже есть свой набор "ноу хау" для администрирования 1С — будет здорово если поделитесь с коллегами в комментариях.
Скрипты и ноу-хау предоставлены avelor, за что ему огромное спасибо!
Читайте также: