
1с не считает регрессию
Обновлено: 07.07.2024
При перерасчете начислений за месяц, в котором была достигнута предельная величина базы по страховым взносам, страховые взносы пересчитываются неправильно.
В релизах ЗУП до исправления ошибки разработчики рекомендуют 2 варианта решения проблемы:
-
Корректировать сумму исчисленных взносов документом Операция учета взносов ( Налоги и взносы – Операции учета взносов ), а сведения о сумме превышения предельной базы, а также о базе для исчисления взносов исправлять в отчетности вручную;
При использовании данного варианта сумма взносов, доначисленная документом Операция учета взносов , будет сторнироваться при каждом расчете взносов по сотруднику и сторно-строку придется удалять.
Рассмотрим описанную ситуацию на примере.
Сотруднику Бархатцеву И.В. в июне 2019 оформлен документ Отпуск ( Зарплата – Отпуска ) за период с 27.06.2019 по 21.08.2019.
В июне доходы Бархатцева И.В. достигли предельной величины базы для начисления взносов на обязательное социальное страхование. Согласно данным Карточки учета страховых взносов ( Налоги и взносы – Отчеты по налогам и взносам – Карточка учета страховых взносов ) сумма превышения составила 100 000 руб., база для исчисления взносов нарастающим итогом с начала года – 865 000 руб., а сумма исчисленных взносов с начала года – 25 085 руб.
В июле доходов у сотрудника не было. В августе Бархатцев И.В. предоставил больничный лист за период с 01.08.2019 по 08.08.2019, на основании которого в программе создан документ Больничный лист ( Зарплата – Больничные листы ).
Сотрудник написал заявление о том, что продлевать отпуск не намерен. Сторнирование отпускных за период болезни (40 000 руб.) произведено документом Больничный лист на вкладке Пересчет прошлого периода .
Заработная плата Бархатцева И.В. за август составила 30 000 руб. Таким образом, доход за август, облагаемый страховыми взносами, не перекрыл сумму сторнированных отпускных (40 000 руб.). Поэтому необходимо произвести перерасчет взносов за июнь.
Произведем перерасчет страховых взносов на обязательное социальное страхование за июнь. При расчете будем использовать исходные данные, приведенные в Карточке учета страховых взносов .
- Общая сумма доходов за июнь:
- 385 000 (общая сумма доходов за июнь до перерасчета) – 40 000 (сумма сторнированных отпускных) = 345 000 руб.
- Общая сумма доходов нарастающим итогом с начала года:
- 965 000 (общая сумма доходов нарастающим итогом с начала года до перерасчета) – 40 000 (сумма сторнированных отпускных) = 925 000 руб.
- Сумма превышения предельной базы для исчисления взносов нарастающим итогом с начала года:
- 925 000 (общая сумма доходов нарастающим итогом с начала года) – 865 000 (предельная величина базы для начисления взносов для 2019 г.) = 60 000 руб.
В связи с тем, что предельная величина базы для исчисления взносов была достигнута в июне, сумма доходов Бархатцева И.В. за июнь, превышающая предельную величину, также будет равна 60 000 руб.
- 925 000 (общая сумма доходов нарастающим итогом с начала года) – 865 000 (предельная величина базы для начисления взносов для 2019 г.) = 60 000 руб.
- База для исчисления взносов нарастающим итогом с начала года равна предельной величине базы для исчисления взносов – 865 000 руб.
- База для исчисления взносов за июнь:
- 345 000 (общая сумма доходов за июнь) – 60 000 (сумма превышения предельной базы за июнь) = 285 000 руб.
- Страховые взносы на ОСС за июнь:
- 285 000 (база для исчисления взносов за июнь) * 2,9% (ставка взносов на ОСС) = 8 265 руб.
- Страховые взносы на ОСС нарастающим итогом с начала года:
- 865 000 (база для исчисления взносов нарастающим итогом с начала года) * 2,9% (ставка взносов на ОСС) = 25 085 руб.
Таким образом, сумма исчисленных взносов на обязательное социальное страхование за июнь измениться не должна. В учете по страховым взносам должны быть уменьшены только показатели общей суммы дохода сотрудника и превышения предельной базы для исчисления взносов.
Проверим перерасчет взносов на обязательное социальное страхование за июнь на вкладке Взносы документа Начисление зарплаты и взносов за август. При заполнении документа были сторнированы взносы на ОСС за июнь в размере 2 900 руб.

Расчет данной суммы является программной ошибкой. Отклонение суммы рассчитанных программой взносов на ОСС за июнь от корректного значения составляет – 2 900 руб.
Сформируем Карточку учета страховых взносов и проверим, как заполнены показатели участвующие в расчете взносов, за июнь. По данным отчета видно, что программа некорректно определила следующие показатели:
- сумму превышения предельной базы нарастающим итогом с начала года за июнь (160 000 руб., корректное значение – 60 000 руб.);
- базу для исчисления взносов за июнь (185 000 руб., корректное значение – 285 000 руб.);
- базу для исчисления взносов нарастающим итогом с начала года (765 000 руб., корректное значение – 865 000 руб.);
- сумму исчисленных страховых взносов за июнь (5 365 руб., корректное значение – 8 265 руб.);
- сумму исчисленных страховых взносов нарастающим итогом с начала года (22 185 руб., корректное значение – 25 085 руб.).

Далее рассчитаем страховые взносы на обязательное социальное страхование за август. Т.к. перерасчет взносов с суммы сторнированных отпускных был произведен в июне, при расчете за август будем учитывать только данные текущего месяца:
- сумма дохода, облагаемого страховыми взносами, (заработная плата) – 30 000 руб.;
- сумма необлагаемых доходов (пособие по больничному листу) – 20 000 руб.
Для расчета показателей нарастающим итогам с начала года используем данные Карточки учета страховых взносов .
- Общая сумма доходов за август:
- 30 000 (сумма дохода, облагаемого страховыми взносами) + 20 000 (сумма необлагаемых доходов) = 50 000 руб.
- Общая сумма доходов нарастающим итогом с начала года:
- 925 000 (общая сумма доходов нарастающим итогом с начала года до июля) + 50 000 (общая сумма доходов за август) = 975 000 руб.
- Сумма превышения предельной базы для исчисления взносов нарастающим итогом с начала года:
- 975 000 (общая сумма доходов нарастающим итогом с начала года) – 20 000 (сумма необлагаемых доходов) – 865 000 (предельная величина базы для начисления взносов для 2019 г.) = 90 000 руб.
- Сумма доходов за август, превышающая предельную величину:
- 90 000 (сумма превышения предельной базы нарастающим итогом с начала года) – 60 000 (сумма превышения предельной базы нарастающим итогом с начала года до июля) = 30 000 руб.
- База для исчисления взносов нарастающим итогом с начала года равна предельной величине базы для исчисления взносов в 2019 г. – 865 000 руб.
- База для исчисления взносов за август:
- 50 000 (общая сумма доходов за август) – 20 000 (сумма необлагаемых доходов) – 30 000 (сумма превышения предельной базы за август) = 0 руб.
- Страховые взносы на ОСС за август также составят 0 руб.
- Страховые взносы на ОСС нарастающим итогом с начала года:
- 865 000 (база для исчисления взносов нарастающим итогом с начала года) * 2,9% (ставка взносов на ОСС) = 25 085 руб.
Проверим перерасчет взносов на обязательное социальное страхование за август на вкладке Взносы документа Начисление зарплаты и взносов за август. При заполнении документа были исчислены взносы на ОСС за август в размере 1 160 руб.

Сформируем Карточку учета страховых взносов и проверим, как заполнены показатели, участвующие в расчете взносов, за август. По данным отчета видно, что программа некорректно определила следующие показатели:
- сумму превышения предельной базы за август (-10 000 руб., корректное значение = 30 000 руб.);
- сумму превышения предельной базы нарастающим итогом с начала года (150 000 руб., корректное значение – 90 000 руб.);
- базу для исчисления взносов за август (40 000 руб., корректное значение – 0 руб.);
- базу для исчисления взносов нарастающим итогом с начала года (805 000 руб., корректное значение – 865 000 руб.);
- сумму исчисленных страховых взносов за август (1 160 руб., корректное значение – 0 руб.);
- сумму исчисленных страховых взносов нарастающим итогом с начала года (22 185 руб., корректное значение – 25 085 руб.).

Создадим документ Начисление зарплаты и взносов за сентябрь, чтобы проверить, как программа будет производить расчет взносов в дальнейшем. Сумма заработной платы Бархатцева И.В. за сентябрь составила 75 000 руб.

По данным вкладки Взносы документа Начисление зарплаты и взносов за сентябрь, расчет взносов на обязательное социальное страхование произведен не был.

Сформируем Карточку учета страховых взносов . По данным отчета в сентябре показатели расчета страховых взносов также определены некорректно.
Неверно рассчитаны следующие показатели:

Подводя итоги, можно сделать вывод, что страховые взносы по Бархатцеву И.В. будут исчислены неправильно не только в отдельных месяцах (июнь и август), но и в целом по итогам года.
Если Вы еще не подписаны:
Активировать демо-доступ бесплатно →
или
Оформить подписку на Рубрикатор →
После оформления подписки вам станут доступны все материалы по 1С ЗУП, записи поддерживающих эфиров и вы сможете задавать любые вопросы по 1С.
Помогла статья?
Получите еще секретный бонус и полный доступ к справочной системе БухЭксперт8 на 14 дней бесплатно
Похожие публикации
-
У вас нет доступа на просмотр Чтобы получить доступ:Оформите коммерческую.Ранее на сайте БухЭксперт8 разбирался весьма спорный алгоритм расчета страховых.К нам поступают обращения наших подписчиков по поводу некорректного расчета.Начиная с ЗУП 3.1.6 классификаторы в информационных базах, в том.
Карточка публикации
(4 оценок, среднее: 5,00 из 5)
Данную публикацию можно обсудить в комментариях ниже.Обратите внимание! В комментариях наши кураторы не отвечают на вопросы по программам 1С и законодательству.
Задать вопрос нашим специалистам можно по ссылке >>
Все комментарии (5)
Как привести в соответствие суммы исчисленных взносов после обновления на версии 3.1.12.
Важно, полезно, спасибо большое.
Вы можете задать еще вопросов
Доступ к форме "Задать вопрос" возможен только при оформлении полной подписки на БухЭксперт8
Вы можете оформить заявку от имени Юр. или Физ. лица Оформить заявкуНажимая кнопку "Задать вопрос", я соглашаюсь с
регламентом БухЭксперт8.ру >>
Видеоролик выполнен в программе «1С:Зарплата и управление персоналом 8» версии 3.1.16.134.
Федеральным законом от 23.11.2020 № 372-ФЗ внесены изменения в главу 23 НК РФ. С 1 января 2021 года ставка налога на доходы физических лиц для резидентов РФ устанавливается в следующих размерах (п. 1 ст. 224 НК РФ):
13% – с суммы доходов в пределах 5 млн рублей за налоговый период (год);
15% – с суммы доходов, превышающих 5 млн рублей за налоговый период (год).
Эти ставки применяются к доходам резидентов, налоговые базы по которым исчисляются отдельно (п. 2.1 ст. 210 НК РФ)
Налоговая ставка для некоторых нерезидентов устанавливается также в размере 13% и 15% (абз. 2 и 3 п. 3.1 ст. 224 НК РФ) :
высококвалифицированных иностранных специалистов;
участников Государственной программы по переселению в РФ;
работающих в РФ по патенту иностранцев;
членов экипажей судов, плавающих под госфлагом РФ;
иностранных граждан или лиц без гражданства, признанных беженцами или получивших временное убежище на территории РФ.
Выделены налоговые базы по доходам со ставкой 13%:
основная налоговая база;
доходы по ценным бумагам (5 налоговых баз);
особые доходы (выигрыши на тотализаторе).
В программе для определения налоговой базы используется категория доходов.

Расчет налога производится нарастающим итогом по каждой из налоговых баз в отдельности:
по ставке 13% с доходов до 5 млн;
по ставке 15% с доходов, превышающих 5 млн;
расчет одинаковый как для резидентов, так и для «льготных резидентов».
В настройках учетной политики организации появилась новая настройка Выполнять расчет НДФЛ по прогрессивной шкале.
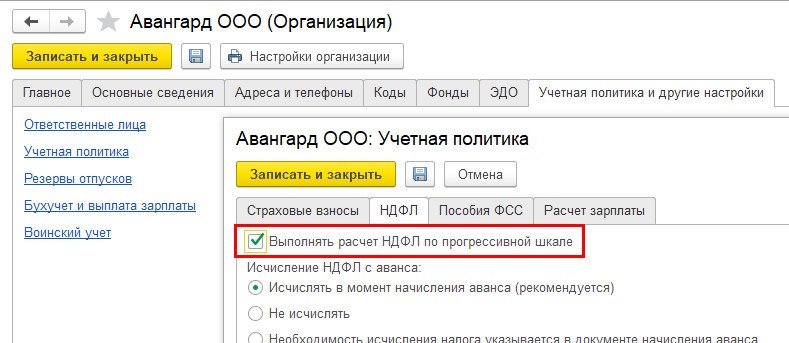
Ее можно включить вручную или она включится автоматически, когда доход хотя бы одного сотрудника достигнет 5 млн руб.
После включения настройки в документах, производящих расчет НДФЛ, а также в ведомостях на выплату появляется колонка Налог с превышения.

Налог с превышения необходимо выделять в отчетности и уплачивать по отдельному КБК 182 1 01 02080 01 1000 110 (реализовано в «1С:Бухгалтерии 8» с релиза 3.0.87.28).

В статье указаны основные ошибки, которые совершают начинающие администраторы 1С, и показаны способы их решения на примере теста Гилева.
Основная цель написания статьи — чтобы не повторять очевидные нюансы тем администраторам (и программистам), которые еще не набрали опыта с 1С.
Вторичная цель, если у меня будут какие-то недочеты, — на Инфостарте мне это укажут быстрее всего.
Неким стандартом "де факто" уже стал тест В. Гилева. Автор на своем сайте дал вполне понятные рекомендации, я же просто приведу некоторые результаты, и прокомментирую наиболее вероятные ошибки. Естественно, что результаты тестирования на Вашем оборудовании могут отличаться, это просто для ориентира, что должно быть и к чему можно стремиться. Сразу хочу отметить, что изменения надо делать пошагово, и после каждого шага проверять, какой результат это дало.
На Инфостарте подобные статьи есть, в соответствующих разделх буду ставить на них ссылки (если пропущу что-то - просьба подсказать в комментариях, добавлю). Итак, предположим у вас тормозит 1С. Как диагностировать проблему, и как понять кто виноват, администратор или программист?
Тестируемый компьютер, основной подопытный кролик: HP DL180G6, в комплектации 2*Xeon 5650, 32 Gb, Intel 362i , Win 2008 r2. Для сравнения, сопоставимые результаты в однопоточном тесте показывает Core i3-2100. Оборудование специально взял не самое новое, на современном оборудовании результаты заметно лучше.
Для тестирования разнесенных серверов 1С и SQL, сервер SQL: IBM System 3650 x4, 2*Xeon E5-2630, 32 Gb, Intel 350, Win 2008 r2.
Для проверки 10 Gbit сети использовались Intel 520-DA2 адаптеры.
Файловая версия. (база лежит на сервере в расшаренной папке, клиенты подключаются по сети, протокол CIFS/SMB). Алгоритм по шагам:
0. Добавляем на файловый сервер тестовую базу Гилева в ту же папку, что и основные базы. С клиентского компьютера подключаемся, запускаем тест. Запоминаем получившийся результат.
Подразумевается, что даже для старых компьютеров 10 летней давности (Pentium на 775 socket) время от нажатия на ярлык 1С:Предприятие до появления окна базы должно пройти меньше минуты. (Celeron = медленная работа).
Если у Вас компьютер хуже, чем пентиум на 775 socket с 1 гб оперативной памяти, то я Вам сочувствую, и комфортной работы на 1С 8.2 в файловой версии Вам будет добиться тяжело. Задумайтесь или об апгрейде (давно пора), или о переходе на терминальный (или web, в случае тонких клиентов и управляемых форм) сервер.
Если компьютер не хуже, то можно пинать администратора. Как минимум — проверить работу сети, антивируса и драйвера защиты HASP.
Если тест Гилева на этом этапе показал 30 "попугаев" и выше, но рабочая база 1С все равно работает медленно - вопросы уже к программисту.
1. Для ориентира, сколько же может "выжать" клиентский компьютер, проверяем работу только этого компьютера, без сети. Тестовую базу ставим на локальный компьютер (на очень быстрый диск). Если на клиентском компьютере нет нормального ССД, то создается рамдиск. Пока, самое простое и бесплатное — Ramdisk enterprise.
Для тестирования версии 8.2 вполне достаточно 256 мб рамдиска, и! Самое главное. После перезагрузки компьютера, с работающим рамдиском, на нем должно быть свободно 100-200 мб. Соответственно, без рамдиска, для нормальной работы свободной памяти должно быть 300-400 мб.
Для тестирования версии 8.3 рамдиска 256 мб хватит, но свободной оперативной памяти надо больше.
При тестировании нужно смотреть на загрузку процессора. В случае, близком к идеальному(рамдиск), локальная файловая 1с при работе загружает 1 ядро процессора. Соответственно, если при тестировании у вас ядро процессора загружено не полностью — ищите слабые места. Немного эмоционально, но в целом корректно, влияние процессора на работу 1С описано здесь. Просто для ориентира, даже на современных Core i3 с высокой частотой вполне реальны цифры 70-80.
Наиболее часто встречающиеся ошибки на этом этапе.
- Неправильно настроенный антивирус. Антивирусов много, настройки для каждого свои, скажу лишь то, что при грамотной настройке ни веб, ни касперский 1С не мешают. При настройках "по умолчанию" - может отниматься примерно 3-5 попугаев (10-15%).
- Режим производительности. Почему-то на это мало кто обращает внимания, а эффект - самый весомый. Если нужна скорость - то делать это обязательно, и на клиентских и на серверных компьютерах. (Хорошее описание у Гилева. Единственный нюанс, на некоторых материнских платах если выключить Intel SpeedStep то нельзя включать TurboBoost).
Включать режим производительности можно (и желательно) в двух местах:
- через BIOS. Отключить режимы C1, C1E, Intel С-state (C2, C3,C4). В разных биосах они называтся по разному, но смысл один. Искать долго, требуется перезагрузка, но если сделал один раз - потом можно забыть. Если в BIOS все сделать правильно, то скорости добавится. На некоторых материнских платах настройками BIOS можно сделать так, что режим производительности Windows роли играть не будет. (Примеры настройки BIOS у Гилева). Эти настройки в основном касаются серверных процессоров или "продвинутых" BIOS, если Вы такое у себя не нашли, и у вас НЕ Xeon - ничего страшного.
- Панель управления - Электропитание - Высокая производительность. Минус - если ТО комптютера давно не проводилось, он будет сильнее гудеть вентилятором, будет больше греться и потреблять больше энергии. Это - плата за производительность.
В BIOS C-state включены,
режим энергопотребления сбалансированный
Для Pentium и Core на этом можно остановиться,
из Xeon еще можно выжать немного "попугайчиков"
Если не использовать Turbo boost - именно так должен выглядеть
сервер, настроенный на производительность
А теперь цифры. Напомню: Intel Xeon 5650, ramdisk. В первом случае тест показывает 23.26, в последнем - 49.5. Разница - почти двухкратная. Цифры могут варьироваться, но соотношение остается практически таким же для Intel Core.
в) Turbo Boost. Сначала надо понять, поддерживает ли Ваш процессор эту функцию, например здесь. Если поддерживает, то можно еще вполне легально получить немного производительности. (вопросы разгона по частоте, особенно серверов, касаться не хочу, делайте это на свой страх и риск. Но соглашусь с тем, что повышение Bus speed со 133 до 166 дает очень ощутимый прирост как скорости, так и тепловыделения)
Как включать turbo boost написано, например, здесь. Но! Для 1С есть некоторые нюансы (не самые очевидные). Сложность в том, что максимальный эффект от turbo boost проявляется тогда, когда включены C-state. И получается примерно такая картинка:

Обратите внимание, что множитель - максимальный, частота Core speed - красивейшая, производительность - высокая. Но что же будет в результате с 1с?
Core speed (частота), GHz
CPU-Z Single Thread
Тест Гилева Ramdisk
Тест Гилева Ramdisk
А в итоге получается, что по тестам производительности ЦПУ вариант с множителем 23 впереди, по тестам Гилева в файловой версии - производительность с множителем 22 и 23 одинаковая, а вот в клиент-серверной - вариант с множителем 23 ужас ужас ужас (даже, если C-state выставить на уровень 7, то все равно медленнее, чем с выключенным C-state). Поэтому рекомендация, проверьте оба варианта у себя, и выберите из них лучший. В любом случае, разница 49,5 и 53 попугая - достаточно значительная, тем более это без особых усилий.Вывод - turbo boost включать обязательно. Напомню, что недостаточно включить пункт Turbo boost в биосе, надо еще посмотреть и другие настройки (BIOS: QPI L0s, L1 - disable, demand scrubbing - disable, Intel SpeedStep - enable, Turbo boost - enable. Панель управления - Электропитание - Высокая производительность). И я бы все-таки (даже для файловой версии) остановился на варианте, где c-state выключен, хоть там множитель и меньше. Получится как-то так.

Достаточно спорным моментом является частота памяти. Например вот тут частота памяти показывается как очень сильно влияющая. Мои же тесты - такой зависимости не выявили. Я не буду сравнивать DDR 2/3/4, я покажу результаты изменения частоты в пределах одной линейки. Память одна и та же, но в биосе принудительно ставим меньшие частоты.
 |  |  |
| 800 | 1066 | 1333 | |
| 48,54 | 49,50 | 50,51 | |
| 1с 8.2 файловый вариант | 49,50 | 49,50 | 49,02 |
| 49,02 | 49,02 | 49,50 | |
| 36,76 | 36,76 | 37,04 | |
| 1с 8.2 клиент-сервер | 37,04 | 37,04 | 36,50 |
| 36,23 | 36,76 | 36,76 |
2. Когда с процессором и памятью клиентского компьютера разобрались, переходим к следующему очень важному месту - сети. Про тюнинг сети написаны многие тома книг, есть статьи на Инфостарте (1, 2 и другие), здесь я на эту тему заострять внимание не буду. Перед началом тестирования 1С просьба убедиться, что iperf между двумя компьютерами показывает всю полосу (для 1 гбит карточек - ну хотя бы 850 мбит, а лучше 950-980), что выполнены советы Гилева. Потом - самой простой проверкой работы будет, как это ни странно, копирование одного большого файла (5-10 гигабайт) по сети. Косвенным признаком нормальной работы на сети в 1 гбит будет средняя скорость копирования 100 мб/сек, хорошей работы — 120 мб/сек. Хочу обратить внимание, что слабым местом (в том числе) может быть и загруженность процессора. SMB протокол на Linux достаточно плохо параллелится, и во время работы он вполне спокойно может «скушать» одно ядро процессора, и больше не потреблять.
И еще. С настройками по умолчанию windows клиент лучше всего работает с windows server (или даже windows рабочая станция) и протоколом SMB/CIFS, linux клиент (debian, ubuntu остальные не смотрел) лучше работает с linux и NFS (с SMB тоже работает, но на NFS попугаи выше). То, что при линейном копировании вин-линукс сервер на нфс копируется в один поток быстрее, еще ни о чем не говорит. Тюнинг debian для 1С - тема отдельной статьи, я к ней еще не готов, хотя могу сказать, что в файловой версии получал даже немного бОльшую производительность, чем Win вариант на этом же оборудовании, но с postgres при пользователях свыше 50 у меня пока еще все очень плохо.
Самое главное, о чем знают "обжегшиеся" администраторы, но не учитывают начинающие. Есть очень много способов задать путь к базе 1с. Можно сделать servershare, можно 192.168.0.1share, можно net use z: 192.168.0.1share (и в некоторых случаях такой способ тоже сработает, но далеко не всегда) и потом указывать диск Z. Вроде бы все эти пути указывают на одно и то же место, но для 1С есть только один способ, достаточно стабильно дающий нормальную производительность. Так вот, правильно делать надо так:
В командной строке (или в политиках, или как Вам удобно) - делаете net use DriveLetter: servershare. Пример: net use m: serverbases. Я специально подчеркиваю, НЕ IP адрес, а именно имя сервера. Если сервер по имени не виден - добавьте его в dns на сервере, или локально в файл hosts. Но обращение должно быть по имени. Соответственно - в пути к базе обращаться к этому диску (см картинку).

А теперь я на цифрах покажу, почему именно такой совет. Исходные данные: Карты Intel X520-DA2, Intel 362, Intel 350, Realtek 8169. ОС Win 2008 R2, Win 7, Debian 8. Драйвера последние, обновления применены. Перед тестированием я убедился, что Iperf дает полную полосу (кроме 10 гбит карточек, там получилось только 7.2 Gbit выжать, позже посмотрю почему, тестовый сервер еще не настроен как надо). Диски разные, но везде SSD(специально вставил одиночный диск для тестирования, больше ничем не нагружен) или рейд из SSD. Скорость 100 Mbit получена путем ограничения в настройках адаптера Intel 362. Разницы между 1 Gbit медь Intel 350 и 1 Gbit оптика Intel X520-DA2 (полученной путем ограничения скорости адаптера) не обнаружено. Максимальная производительность, турбобуст выключен (просто для сопоставимости результатов, турбобуст для хороших результатов добавляет чуть меньше 10%, для плохих - вообще может никак не сказаться). Версии 1С 8.2.19.86, 8.3.6.2076. Цифры привожу не все, а только самые интересные, чтобы было с чем сравнивать.
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.

Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.
Введение в регрессионный анализ
Если имеется корреляционная зависимость между переменными y и x , возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения называется регрессией y по x .
Основу регрессионного анализа составляет метод наименьших квадратов (МНК), в соответствии с которым в качестве уравнения регресии берется функция такая, что сумма квадратов разностей минимальна.

Карл Гаусс открыл, или точнее воссоздал, МНК в возрасте 18 лет, однако впервые результаты были опубликованы Лежандром в 1805 г. По непроверенным данным метод был известен еще в древнем Китае, откуда он перекочевал в Японию и только затем попал в Европу. Европейцы не стали делать из этого секрета и успешно запустили в производство, обнаружив с его помощью траекторию карликовой планеты Церес в 1801 г.
Вид функции , как правило, определен заранее, а с помощью МНК подбираются оптимальные значения неизвестных параметров. Метрикой рассеяния значений вокруг регрессии является дисперсия.
- k — число коэффициентов в системе уравнений регрессии.
Чаще всего используется модель линейной регрессии, а все нелинейные зависимости приводят к линейному виду с помощью алгебраических ухищрений, различных преобразования переменных y и x .
Линейная регрессия
Уравнения линейной регрессии можно записать в виде
В матричном виде это выгладит
- y — зависимая переменная;
- x — независимая переменная;
- β — коэффициенты, которые необходимо найти с помощью МНК;
- ε — погрешность, необъяснимая ошибка и отклонение от линейной зависимости;

Случайная величина может быть интерпретирована как сумма из двух слагаемых:
- — полная дисперсия (TSS).
- — объясненная часть дисперсии (ESS).
- — остаточная часть дисперсии (RSS).
Еще одно ключевое понятие — коэффициент корреляции R 2 .
Ограничения линейной регрессии
Для того, чтобы использовать модель линейной регрессии необходимы некоторые допущения относительно распределения и свойств переменных.
- Линейность, собственно. Увеличение, или уменьшение вектора независимых переменных в k раз, приводит к изменению зависимой переменной также в k раз.
- Матрица коэффициентов обладает полным рангом, то есть векторы независимых переменных линейно независимы.
- Экзогенность независимых переменных — . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
- Однородность дисперсии и отсутствие автокорреляции. Каждая εi обладает одинаковой и конечной дисперсией σ 2 и не коррелирует с другой εi. Это ощутимо ограничивает применимость модели линейной регрессии, необходимо удостовериться в том, что условия соблюдены, иначе обнаруженная взаимосвязь переменных будет неверно интерпретирована.
Как обнаружить, что перечисленные выше условия не соблюдены? Ну, во первых довольно часто это видно невооруженным глазом на графике.

Неоднородность дисперсии
При возрастании дисперсии с ростом независимой переменной имеем график в форме воронки.

Нелинейную регрессии в некоторых случая также модно увидеть на графике довольно наглядно.
Тем не менее есть и вполне строгие формальные способы определить соблюдены ли условия линейной регрессии, или нарушены.
- Автокорреляция проверяется статистикой Дарбина-Уотсона (0 ≤ d ≤ 4). Если автокорреляции нет, то значения критерия d≈2, при позитивной автокорреляции d≈0, при отрицательной — d≈4.
- Неоднородность дисперсии — Тест Уайта, , при нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же можно еще применить тест Бройша-Пагана.
- Мультиколлинеарность — нарушения условия об отсутствии взаимной линейной зависимости между независимыми переменными. Для проверки часто используют VIF-ы (Variance Inflation Factor).
В этой формуле — коэффициент взаимной детерминации между и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
Почему нам так важно соблюдение всех выше перечисленных условий? Все дело в Теореме Гаусса-Маркова, согласно которой оценка МНК является точной и эффективной лишь при соблюдении этих ограничений.
Как преодолеть эти ограничения
Нарушения одной или нескольких ограничений еще не приговор.
- Нелинейность регрессии может быть преодолена преобразованием переменных, например через функцию натурального логарифма ln .
- Таким же способом возможно решить проблему неоднородной дисперсии, с помощью ln , или sqrt преобразований зависимой переменной, либо же используя взвешенный МНК.
- Для устранения проблемы мультиколлинеарности применяется метод исключения переменных. Суть его в том, что высоко коррелированные объясняющие переменные устраняются из регрессии, и она заново оценивается. Критерием отбора переменных, подлежащих исключению, является коэффициент корреляции. Есть еще один способ решения данной проблемы, который заключается в замене переменных, которым присуща мультиколлинеарность, их линейной комбинацией. Этим весь список не исчерпывается, есть еще пошаговая регрессия и другие методы.
К сожалению, не все нарушения условий и дефекты линейной регрессии можно устранить с помощью натурального логарифма. Если имеет место автокорреляция возмущений к примеру, то лучше отступить на шаг назад и построить новую и лучшую модель.
Линейная регрессия плюсов на Хабре
Итак, довольно теоретического багажа и можно строить саму модель.
Мне давно было любопытно от чего зависит та самая зелененькая цифра, что указывает на рейтинг поста на Хабре. Собрав всю доступную статистику собственных постов, я решил прогнать ее через модель линейно регрессии.
Загружает данные из tsv файла.
Теперь собственно сама модель, используем функцию lm .
В первой строке мы задаем параметры линейной регрессии. Строка points
. определяет зависимую переменную points и все остальные переменные в качестве регрессоров. Можно определить одну единственную независимую переменную через points
reads , набор переменных — points
Перейдем теперь к расшифровке полученных результатов.
- Intercept — Если у нас модель представлена в виде , то тогда — точка пересечения прямой с осью координат, или intercept .
- R-squared — Коэффициент детерминации указывает насколько тесной является связь между факторами регрессии и зависимой переменной, это соотношение объясненных сумм квадратов возмущений, к необъясненным. Чем ближе к 1, тем ярче выражена зависимость.
- Adjusted R-squared — Проблема с в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
- F-statistic — Используется для оценки значимости модели регрессии в целом, является соотношением объяснимой дисперсии, к необъяснимой. Если модель линейной регрессии построена удачно, то она объясняет значительную часть дисперсии, оставляя в знаменателе малую часть. Чем больше значение параметра — тем лучше.
- t value — Критерий, основанный на t распределении Стьюдента . Значение параметра в линейной регрессии указывает на значимость фактора, принято считать, что при t > 2 фактор является значимым для модели.
- p value — Это вероятность истинности нуль гипотезы, которая гласит, что независимые переменные не объясняют динамику зависимой переменной. Если значение p value ниже порогового уровня (.05 или .01 для самых взыскательных), то нуль гипотеза ложная. Чем ниже — тем лучше.
Можно попытаться несколько улучшить модель, сглаживая нелинейные факторы: комментарии и посты в социальных сетях. Заменим значения переменных fb и comm их степенями.
Проверим значения параметров линейной регрессии.
Как видим в целом отзывчивость модели возросла, параметры подтянулись и стали более шелковистыми , F-статистика выросла, так же как и скорректированный коэффициент детерминации .
Проверим, соблюдены ли условия применимости модели линейной регрессии? Тест Дарбина-Уотсона проверяет наличие автокорреляции возмущений.
И напоследок проверка неоднородности дисперсии с помощью теста Бройша-Пагана.
В заключение
Конечно наша модель линейной регрессии рейтинга Хабра-топиков получилось не самой удачной. Нам удалось объяснить не более, чем половину вариативности данных. Факторы надо чинить, чтобы избавляться от неоднородной дисперсии, с автокорреляцией тоже непонятно. Вообще данных маловато для сколь-нибудь серьезной оценки.
Но с другой стороны, это и хорошо. Иначе любой наспех написанный тролль-пост на Хабре автоматически набирал бы высокий рейтинг, а это к счастью не так.
Читайте также: