
F табличное фишера как определить в эксель для множественной регрессии
Обновлено: 06.07.2024
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
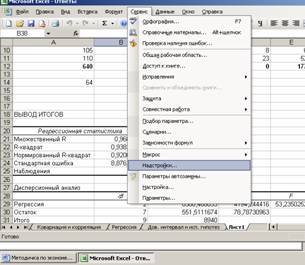
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
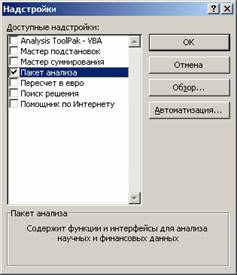
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» - первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» - второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.
Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
- Строим корреляционное поле: «Вставка» - «Диаграмма» - «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».
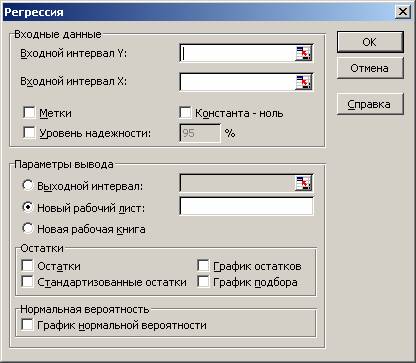
Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия . (В Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия ) Появится диалоговое окно, которое нужно заполнить:
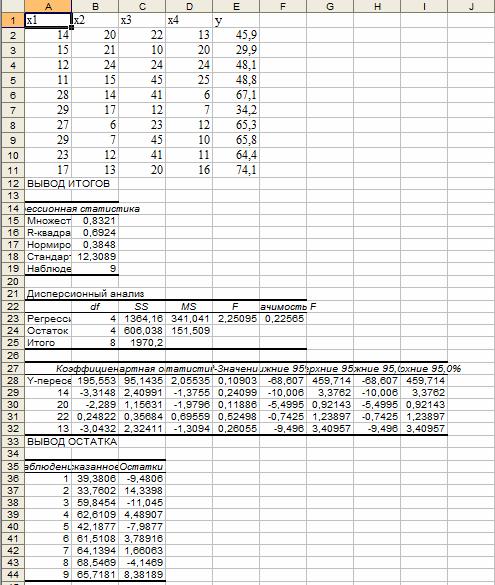
В результате выводится информация, содержащая все необходимые сведения и сгруппированная в три блока: Регрессионная статистика, Дисперсионный анализ, Вывод остатка. Рассмотрим их подробнее.
1. Регрессионная статистика:
множественный R определяется формулой ;
R-квадрат вычисляется по формуле ;
Нормированный R -квадрат вычисляется по формуле ;
Стандартная ошибка S вычисляется по формуле ;
Наблюдения - это количество данных n.
3. Дисперсионный анализ, строка Остаток:
Параметр df равен n-m-1;
Параметр SS определяется формулой ;
Параметр MS определяется формулой .
4. Дисперсионный анализ, строка Итого содержит сумму первых двух столбцов.
6. Дисперсионный анализ, строки x1, x2. xm содержат значения коэффициентов, стандартных ошибок, t-статистик, P-значений и доверительных интервалов для соответствующих xi.
Блок Вывод остатка содержит значения предсказанного y (в наших обозначениях это ) и остатки .
Алгоритм работы
Вводим заданные значения xi и y , затем выбираем пункт меню Сервис/Анализ данных/Регрессия. Далее указываем интервалы значений xи y, включаем режим Метки, оставляем уровень надежность по умолчанию, указываем выходной интервал и включаем вывод остатков: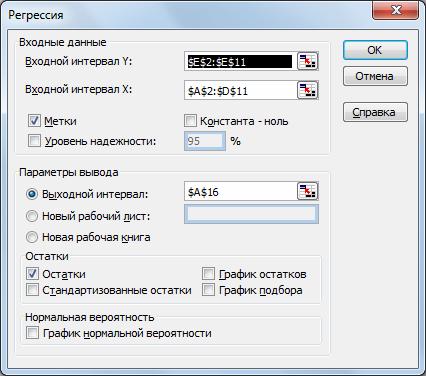
- Среднее значение: СРЗНАЧ(диапазон)
- Квадратическое отклонение: КВАДРОТКЛ(диапазон)
- Дисперсия: ДИСП(диапазон)
- Дисперсия для генеральной совокупности: ДИСПР(диапазон)
- Среднеквадратическое отклонение: СТАНДОТКЛОН(диапазон)
- Уравнение регрессии y = b1x1+b2x2+. bnxn+b0: ЛИНЕЙН(диапазон Y;диапазон X;1;1) .
- Выделите блок ячеек размером (n+1) столбцов и 5 строк.
6. Коэффициенты множественной линейной регрессии вычисляются с помощью функции ЛИНЕЙН . Для того чтобы использовать эту функцию для вычисления параметров множественной регрессии необходимо
1) Сначала выделить на рабочем листе область размером 5x(k+1), где k — число объясняющих переменных.
2) Затем заполнить поля аргументов этой функции, которые имеют тот же смысл, что и в случае парной регрессии:
Известные_значения_y — адреса ячеек, содержащих значения признака y;
Известные_значения_x — адреса ячеек, содержащих значения всех объясняющих переменных.
Обратите внимание: выборочные значения факторов должны располагаться рядом друг с другом (в смежной области), причем предполагается, что в первом столбце (строке) содержатся значения первой объясняющей переменной, во втором столбце — второй и т.д.
Константа — значение (логическое), указывающее на наличие свободного члена в уравнении регрессии: укажите в поле Константа значение 1, тогда свободный член рассчитывается обычным образом (если значение поля Константа равно 0, то свободный член полагается равным 0);
Статистика — значение (логическое), которое указывает на то, следует ли выводить дополнительную информацию по регрессионному анализу или нет: укажите в поле Статистика значение равное 1, тогда будет выводиться дополнительная регрессионная информация (если Статистика=0, то выводятся только оценки коэффициентов уравнения регрессии);
Критерий Фишера предназначен для сопоставления двух выборок по частоте встречаемости интересующего исследователя эффекта.
При увеличении расхождения между углами φ1 и φ2 и увеличения численности выборок значение критерия возрастает. Чем больше величина φ*, тем более вероятно, что различия достоверны.
Гипотезы критерия Фишера
H0: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 не больше, чем в выборке 2.
H1: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 больше, чем в выборке 2.
Графики функций
F -распределение при небольших параметрах (
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .

Примечание : Для построения функции распределения и плотности вероятности можно использовать диаграмму типа График или Точечная (со сглаженными линиями и без точек). Подробнее о построении диаграмм читайте статью Основные типы диаграмм .
F-распределение в MS EXCEL
Примечание : Плотность вероятности можно также вычислить впрямую, с помощью формул (см. файл примера ).
Примеры расчетов приведены в файле примера на листе Функции .
Оценка взаимосвязи прибыли и затрат по функции ФИШЕР
Пример 1. Используя данные об активности коммерческих организаций, требуется сделать оценку связи прибыли Y (млн руб.) и затрат X (млн руб.), используемых для разработки продукции (приведены в таблице 1).
Таблица 1 – Исходные данные:
| № | X | Y |
| 1 | 210 000 000,00 ₽ | 95 000 000,00 ₽ |
| 2 | 1 068 000 000,00 ₽ | 76 000 000,00 ₽ |
| 3 | 1 005 000 000,00 ₽ | 78 000 000,00 ₽ |
| 4 | 610 000 000,00 ₽ | 89 000 000,00 ₽ |
| 5 | 768 000 000,00 ₽ | 77 000 000,00 ₽ |
| 6 | 799 000 000,00 ₽ | 85 000 000,00 ₽ |
Схема решения таких задач выглядит следующим образом:
-
Рассчитывается линейный коэффициент корреляции rxy Рисунок 1 – Пример расчетов.
| № п/п | Наименование показателя | Формула расчета |
| 1 | Коэффициент корреляции | =КОРРЕЛ(B2:B7;C2:C7) |
| 2 | Расчетное значение t-критерия tp | =ABS(C8)/КОРЕНЬ(1-СТЕПЕНЬ(C8;2))*КОРЕНЬ(6-2) |
| 3 | Табличное значение t-критерия trh | =СТЬЮДРАСПОБР(0,05;4) |
| 4 | Табличное значение стандартного нормального распределения zy | =НОРМСТОБР((0,95+1)/2) |
| 5 | Значение преобразования Фишера z’ | =ФИШЕР(C8) |
| 6 | Левая интервальная оценка для z | =C12-C11*КОРЕНЬ(1/(6-3)) |
| 7 | Правая интервальная оценка для z | =C12+C11*КОРЕНЬ(1/(6-3)) |
| 8 | Левая интервальная оценка для rxy | =ФИШЕРОБР(C13) |
| 9 | Правая интервальная оценка для rxy | =ФИШЕРОБР(C14) |
| 10 | Стандартное отклонение для rxy | =КОРЕНЬ((1-C8^2)/4) |
Таким образом, с вероятностью 0,95 линейный коэффициент корреляции заключен в интервале от (–0,386) до (–0,990) со стандартной ошибкой 0,205.
Проверка статистической значимости регрессии по функции FРАСПОБР
Пример 2. Произвести проверку статистической значимости уравнения множественной регрессии с помощью F-критерия Фишера, сделать выводы.
Для проверки значимости уравнения в целом выдвинем гипотезу Н0 о статистической незначимости коэффициента детерминации и противоположную ей гипотезу Н1 о статистической значимости коэффициента детерминации:
Проверим гипотезы с помощью F-критерия Фишера. Показатели приведены в таблице 2.
Таблица 2 – Исходные данные
Для этого используем в пакете Excel функцию:
- α – вероятность, связанная с данным распределением;
- p и n – числитель и знаменатель степеней свободы, соответственно.
Зная, что α = 0,05, p = 2 и n = 53, получаем следующее значение для Fкрит (см. рисунок 2).

Рисунок 2 – Пример расчетов.
Таким образом можно сказать, что Fрасч > Fкрит. В итоге принимается гипотеза Н1 о статистической значимости коэффициента детерминации.
Таблицы по нахождению критерия Фишера и Стьюдента
Таблицы значений F-критерия Фишера и t-критерия Стьюдента Вы можете посмотреть здесь.
Табличное значение критерия Фишера вычисляют следующим образом:
- Определяют k1, которое равно количеству факторов (Х). Например, в однофакторной модели (модели парной регрессии) k1=1, в двухфакторной k=2.
- Определяют k2, которое определяется по формуле n — m — 1, где n — число наблюдений, m — количество факторов. Например, в однофакторной модели k2 = n — 2.
- На пересечении столбца k1 и строки k2 находят значение критерия Фишера
Для нахождения табличного значения критерия Стьюдента определяют число степеней свободы, которое определяется по формуле n — m — 1 и находят его значение при определенном уровне значимости (0,10, 0,05, 0,01).
Критерии Стьюдента
Для оценки статистической значимости модели по параметрам рассчитывают t-критерии Стьюдента.
Оценка значимости модели с помощью критерия Стьюдента проводится путем сравнения их значений с величиной случайной ошибки:

Случайные ошибки коэффициентов линейной регрессии и коэффициента корреляции определяются по формулам:

Сравнивая фактическое и табличное значения t-статистики и принимается или отвергается гипотеза о значимости модели по параметрам.
Зависимость между критерием Фишера и значением t-статистики Стьюдента определяется так

Как и в случае с оценкой значимости уравнения модели в целом, модель считается ненадежной если tтабл > tфакт
Порядок расчета критерия φ*
1. Формулируем статистические гипотезы:
Но: доля студентов, получивших оценки 4 и 5 до эксперимента такая же, как и после эксперимента;
Н1: доля студентов, получивших оценки 4 и 5 после эксперимента больше, чем до эксперимента.
2. Определяем значения углов φ1 и φ2, соответствующие долям p1 = 0,666; p2 = 0,888
φ1= 2arcsin (√p1)= 2 arcsin √0,6662 arcsin (0,816)= 2·0.954=1.908
φ2= 2arcsin (√p2)= 2 arcsin √0,888=2 arcsin (0,942)= 2·1.228=2.457
3. Вычисляем эмпирическое значение φ по формуле.
4. Сравниваем эмпирическое значение критерия с критическим (представлено в таблице 2)
Таблица 2. Критические значения критерия при различных значениях уровнях значимости α (Попов Г.И. с соавт., 2007).
| α | критические значения критерия φ* |
| 0,001 | 2,91 |
| 0,01 | 2,31 |
| 0,05 | 1,64 |
| 0,1 | 1,29 |
Расчет в программе Excel
В программу введен контрольный пример. В верхней части программы показано, как должны быть представлены исходные данные в случае связанных выборок (слева) и в случае независимых выборок (справа).
Чтобы выполнить расчет, нужно заполнить клетки, выделенные желтым цветом в нижней части таблицы. После этого будет получено эмпирическое значение критерия (фи*эмп). Затем подученное значение эмпирического значения фи нужно сравнить с критическим значением (фи* крит) на заданном уровне значимости. Эти значения приведены в табл.1. Если фи*эмп больше чем фи*крит, различия между группами статистически достоверны.
Показатели качества уравнения регрессии
| Показатель | Значение |
| Коэффициент детерминации | 0.49 |
| Средний коэффициент эластичности | 0.51 |
| Средняя ошибка аппроксимации | 10.89 |
Для чего используется точный критерий Фишера?
Точный критерий Фишера в основном применяется для сравнения малых выборок. Этому есть две весомые причины. Во-первых, вычисления критерия довольно громоздки и могут занимать много времени или требовать мощных вычислительных ресурсов. Во-вторых, критерий довольно точен (что нашло отражение даже в его названии), что позволяет его использовать в исследованиях с небольшим числом наблюдений.
Особое место отводится точному критерию Фишера в медицине. Это важный метод обработки медицинских данных, нашедший свое применение во многих научных исследованиях. Благодаря ему можно исследовать взаимосвязь определенных фактора и исхода, сравнивать частоту патологических состояний между разными группами пациентов и т.д.
В каких случаях можно использовать точный критерий Фишера?
- Сравниваемые переменные должны быть измерены в номинальной шкале и иметь только два значения, например, артериальное давление в норме или повышено, исход благоприятный или неблагоприятный, послеоперационные осложнения есть или нет.
- Критерий подходит для сравнения очень малых выборок: точный критерий Фишера может применяться для анализа четырехпольных таблиц в случае значений ожидаемого явления менее 10, что является ограничением для применения критерия хи-квадрат Пирсона.
- Точный критерий Фишера бывает односторонним и двусторонним. При одностороннем варианте точно известно, куда отклонится один из показателей. Например, во время исследования сравнивают, сколько пациентов выздоровело по сравнению с группой контроля. Предполагают, что терапия не может ухудшить состояние пациентов, а только либо вылечить, либо нет.
Двусторонний тест является предпочтительным, так как оценивает различия частот по двум направлениям. То есть оценивается верятность как большей, так и меньшей частоты явления в экспериментальной группе по сравнению с контрольной группой.
Аналогом точного критерия Фишера является Критерий хи-квадрат Пирсона, при этом точный критерий Фишера обладает более высокой мощностью, особенно при сравнении малых выборок, в связи с чем в этом случае обладает преимуществом.
Критические точки распределения Фишера
(k1— число степеней свободы большей дисперсии,
k2—число степеней свободы меньшей дисперсии)
Уровень значимости a =0.01
Распределение Фишера (F-распределение). Распределения математической статистики в EXCEL
Рассмотрим распределение Фишера (F-распределение). С помощью функции MS EXCEL F .РАСП() построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
F-распределение (англ. F-distribution) применяется для целей дисперсионного анализа (ANOVA), при проверке гипотезы о равенстве дисперсий двух нормальных распределений (F-тест) и др.

Определение : Если U 1 и U 2 независимые случайные величины, имеющие ХИ2-распределение с k 1 и k 2 степенями свободы соответственно, то распределение случайной величины:
носит название F -распределения с параметрами k 1 и k 2 .

Плотность F -распределения выражается формулой:

где Г(…) – гамма-функция:
если альфа – положительное целое, то Г( альфа )=( альфа -1)!
Приведем пример случайной величины, имеющей F -распределение.
Пусть имеется 2 нормальных распределения N(μ 1 ;σ 1 ) и N(μ 2 ; σ 2 ), из которых сделаны выборки размером n 1 и n 2 . Если s 1 2 и s 2 2 – дисперсии этих выборок , то отношение

имеет F -распределение. Это соотношение нам потребуется при проверке гипотезы о равенстве дисперсий двух нормальных распределений (F-тест) .
Графики функций
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .

Примечание : Для построения функции распределения и плотности вероятности можно использовать диаграмму типа График или Точечная (со сглаженными линиями и без точек). Подробнее о построении диаграмм читайте статью Основные типы диаграмм .
F-распределение в MS EXCEL
Примеры расчетов приведены в файле примера на листе Функции .
Обратная функция F-распределения
Вышеуказанные функции можно взаимозаменять, т.к. следующие формулы возвращают одинаковый результат: =F.ОБР(0,05;k1;k2) =F.ОБР.ПХ(1-0,05;k1;k2) = FРАСПОБР (1-0,05;k1;k2)
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье Распределения случайной величины в MS EXCEL .
Функция ФИШЕР в Excel и примеры ее работы
Функция ФИШЕР выполняет возвращение преобразования Фишера для аргументов X . Это преобразование строит функцию, которая имеет нормальное, а не асимметричное распределение. Используется функция ФИШЕР для того чтобы проверить гипотезу с помощью коэффициента корреляции.
Описание работы функции ФИШЕР в Excel
При работе с данной функцией необходимо задать значение переменной. Сразу стоит отметить, что существуют некоторые ситуации, при которых данная функция не будет выдавать результатов. Это возможно, если переменная:
Уравнение, которое используется для математического описания функции ФИШЕР, имеет вид:
Рассмотрим применение данной функции на 3-x конкретных примерах.
Оценка взаимосвязи прибыли и затрат по функции ФИШЕР
Пример 1. Используя данные об активности коммерческих организаций, требуется сделать оценку связи прибыли Y (млн руб.) и затрат X (млн руб.), используемых для разработки продукции (приведены в таблице 1).
Таблица 1 – Исходные данные:
| № | X | Y |
| 1 | 210 000 000,00 ₽ | 95 000 000,00 ₽ |
| 2 | 1 068 000 000,00 ₽ | 76 000 000,00 ₽ |
| 3 | 1 005 000 000,00 ₽ | 78 000 000,00 ₽ |
| 4 | 610 000 000,00 ₽ | 89 000 000,00 ₽ |
| 5 | 768 000 000,00 ₽ | 77 000 000,00 ₽ |
| 6 | 799 000 000,00 ₽ | 85 000 000,00 ₽ |
Схема решения таких задач выглядит следующим образом:
- Рассчитывается линейный коэффициент корреляции rxy;
- Проверяется значимость линейного коэффициента корреляции на основе t-критерия Стьюдента. При этом выдвигается и проверяется гипотеза о равенстве коэффициента корреляции нулю. При проверке этой гипотезы используется t-статистика. Если гипотеза подтверждается, t-статистика имеет распределение Стьюдента. Если расчетное значение tр > tкр, то гипотеза отвергается, что свидетельствует о значимости линейного коэффициента корреляции, а следовательно, и о статистической существенности зависимости между Х и Y;
- Определяется интервальная оценка для статистически значимого линейного коэффициента корреляции.
- Определяется интервальная оценка для линейного коэффициента корреляции на основе обратного z-преобразования Фишера;
- Рассчитывается стандартная ошибка линейного коэффициента корреляции.
Результаты решения данной задачи с применяемыми функциями в пакете Excel приведены на рисунке 1.

Рисунок 1 – Пример расчетов.
| № п/п | Наименование показателя | Формула расчета |
| 1 | Коэффициент корреляции | =КОРРЕЛ(B2:B7;C2:C7) |
| 2 | Расчетное значение t-критерия tp | =ABS(C8)/КОРЕНЬ(1-СТЕПЕНЬ(C8;2))*КОРЕНЬ(6-2) |
| 3 | Табличное значение t-критерия trh | =СТЬЮДРАСПОБР(0,05;4) |
| 4 | Табличное значение стандартного нормального распределения zy | =НОРМСТОБР((0,95+1)/2) |
| 5 | Значение преобразования Фишера z’ | =ФИШЕР(C8) |
| 6 | Левая интервальная оценка для z | =C12-C11*КОРЕНЬ(1/(6-3)) |
| 7 | Правая интервальная оценка для z | =C12+C11*КОРЕНЬ(1/(6-3)) |
| 8 | Левая интервальная оценка для rxy | =ФИШЕРОБР(C13) |
| 9 | Правая интервальная оценка для rxy | =ФИШЕРОБР(C14) |
| 10 | Стандартное отклонение для rxy | =КОРЕНЬ((1-C8^2)/4) |
Таким образом, с вероятностью 0,95 линейный коэффициент корреляции заключен в интервале от (–0,386) до (–0,990) со стандартной ошибкой 0,205.
Проверка статистической значимости регрессии по функции FРАСПОБР
Пример 2. Произвести проверку статистической значимости уравнения множественной регрессии с помощью F-критерия Фишера, сделать выводы.
Для проверки значимости уравнения в целом выдвинем гипотезу Н о статистической незначимости коэффициента детерминации и противоположную ей гипотезу Н1 о статистической значимости коэффициента детерминации:
Проверим гипотезы с помощью F-критерия Фишера. Показатели приведены в таблице 2.
Таблица 2 – Исходные данные
Для этого используем в пакете Excel функцию:
- α – вероятность, связанная с данным распределением;
- p и n – числитель и знаменатель степеней свободы, соответственно.
Зная, что α = 0,05, p = 2 и n = 53, получаем следующее значение для Fкрит (см. рисунок 2).

Рисунок 2 – Пример расчетов.
Таким образом можно сказать, что Fрасч > Fкрит. В итоге принимается гипотеза Н1 о статистической значимости коэффициента детерминации.
Расчет величины показателя корреляции в Excel
Определим Fкрит из выражения:
где R – коэффициент детерминации, равный 0,67.
Таким образом, расчетное значение Fрасч = 46.
Для определения Fкрит используем распределение Фишера (см. рисунок 3).

Рисунок 3 – Пример расчетов.
Таким образом, полученная оценка уравнения регрессии надежна.
Критерий Фишера и Стьюдента
С помощью критерия Фишера оценивают качество регрессионной модели в целом и по параметрам.
Для этого выполняется сравнение полученного значения F и табличного F значения. F-критерия Фишера. F фактический определяется из отношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:
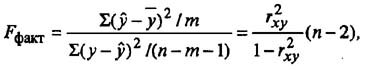
где n — число наблюдений;
m — число параметров при факторе х.
F табличный — это максимальное значение критерия под влиянием случайных факторов при текущих степенях свободы и уровне значимости а.
Уровень значимости а — вероятность не принять гипотезу при условии, что она верна. Как правило а принимается равной 0,05 или 0,01.
Если Fтабл > Fфакт то признается статистическая незначимость модели, ненадежность уравнения регрессии.
Таблицы по нахождению критерия Фишера и Стьюдента
Таблицы значений F-критерия Фишера и t-критерия Стьюдента Вы можете посмотреть здесь.
Табличное значение критерия Фишера вычисляют следующим образом:
- Определяют k1, которое равно количеству факторов (Х). Например, в однофакторной модели (модели парной регрессии) k1=1, в двухфакторной k=2.
- Определяют k2, которое определяется по формуле n — m — 1, где n — число наблюдений, m — количество факторов. Например, в однофакторной модели k2 = n — 2.
- На пересечении столбца k1 и строки k2 находят значение критерия Фишера
Для нахождения табличного значения критерия Стьюдента определяют число степеней свободы, которое определяется по формуле n — m — 1 и находят его значение при определенном уровне значимости (0,10, 0,05, 0,01).
Критерии Стьюдента
Для оценки статистической значимости модели по параметрам рассчитывают t-критерии Стьюдента.
Оценка значимости модели с помощью критерия Стьюдента проводится путем сравнения их значений с величиной случайной ошибки:
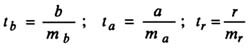
Случайные ошибки коэффициентов линейной регрессии и коэффициента корреляции определяются по формулам:
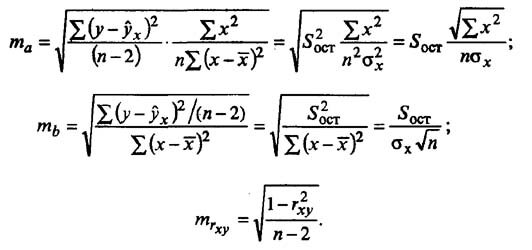
Сравнивая фактическое и табличное значения t-статистики и принимается или отвергается гипотеза о значимости модели по параметрам.
Зависимость между критерием Фишера и значением t-статистики Стьюдента определяется так
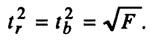
Как и в случае с оценкой значимости уравнения модели в целом, модель считается ненадежной если tтабл > tфакт
Видео лекциий по расчету критериев Фишера и Стьюдента
Для более подробного изучения расчетов критериев Фишера и Стьюдента советуем посмотреть это видео
Лекция 1. Критерии и Гипотезы
Лекция 2. Критерии и Гипотезы
Лекция 3. Критерии и Гипотезы
Определение доверительных интервалов
Для построения доверительного интервала определяется предельная ошибка А для обоих показателей:

Формулы для нахождения доверительных интервалов выглядят так
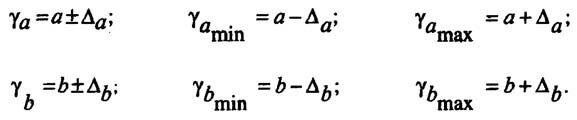
Прогнозное значение у определяется с помощью подстановки в
уравнение регрессии прогнозного значения х. Вычисляется средняя стандартная ошибка прогноза
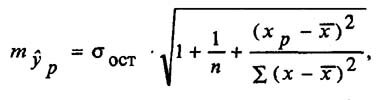
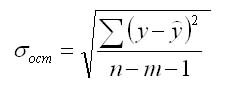
и находится доверительный интервал
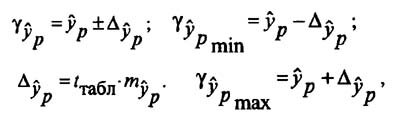
Задача регрессионного анализа в предмете эконометрика состоит в анализе дисперсии изучаемого показателя y:
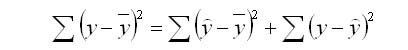
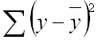
общая сумма квадратов отклонений (TSS)
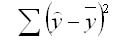
сумма квадратов отклонений, обусловленная регрессией (RSS)
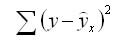
остаточная сумма квадратов отклонений (ESS)
Долю дисперсии, обусловленную регрессией, в общей дисперсии показателя у характеризует коэффициент детерминации R, который должен превышать 50% (R 2 > 0,5). В контрольных по эконометрике в ВУЗах этот показатель рассчитывается всегда.
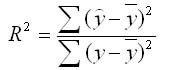
Любые задачи по эконометрике решаются здесь
4.2. Критерий Фишера

,
Число степеней свободы числителя определяется по формуле:

,
Число степеней свободы знаменателя определяется по формуле:

,
Если (вычисленное значение критерия не больше критического), то принимается гипотезаH (дисперсии равны), в противном случае () принимается гипотезаH1 (дисперсии различны).
Результаты были записаны в виде отклонений от значения эталона. Требуется выяснить: одинаковой ли точностью обладают приборы.
В результате расчета были получены соответственно следующие значения дисперсий: =7.35 и=2.188.

Значение критерия =7.35 /2.188 = 3.36.
Для уровня значимости α =0.05; числа степеней свободы числителяr1 =11-1=10 и числа степеней свободы знаменателяr2 = 9-1= 8 находим с помощью встроенной функции FРАСПОБР().Fкрит= 3.347.

Поскольку то гипотезаH отклоняется, и принимается альтернативная гипотезаH1 (дисперсии различны). Следовательно, приборы имеют различную точность.

Рис. 4.4 Сравнение двух выборочных дисперсий
(фрагмент рабочего листа MSExcelв режиме отображения данных)

Рис. 4.5. Сравнение двух выборочных дисперсий
(фрагмент рабочего листа MSExcelв режиме отображений формул)
Средство анализа «Двухвыборочный f-тест для дисперсии» надстройки «Пакет анализа» ms Excel
Средство анализа «Двухвыборочный F-тест для дисперсии» надстройки «Пакет анализа»MSExcelслужит для проверки гипотезы о равенстве дисперсий двух выборок. Для проверки необходимо заполнить диалоговое окно, приведенное на рис.4.6, назначение всех полей ввода очевидно.

Рис. 4.6 Диалоговое окно средства анализа «Двухвыборочный F-тест для дисперсии» надстройки «Пакет анализа»MSExcel
Читайте также: