
Html браузер не отображает русский
Обновлено: 06.07.2024
Помогите плз, чето мозги закипают =/
Руками в меню ". Кодировка" задашь UTF-8 - нормально читается страница. А судя по галкам, браузер считает, что страница содержит текст Win-1251. Откуда они это берут? Где поискать "зарытую собаку"?
ЗЫ. Опера, хром и FF дают одинаковый результат.
1. тег <META charset> не устанавливает кодировку, а лишь сообщает браузеру о кодировке
т.е. если фактически ваш HTML-редактор настроен под кодировку windows-1251, то вы можете
хоть двадцать пять раз прописать <META charset="utf-8"> - в браузер всё-равно
придёт кодировка windows-1251
[это как тег <META keywords description> - сайт вполне может быть по содержанию педофильским,
а в этом теге будет что-то о художественно-прекрасном
именно так раньше обманывали поисковые системы
поэтому поисковики теперь первым делом сравнивают данные этого тега с фактическими словами
в теле сайта и если находят несоответствие между первым и вторым, сразу же относят страницу к
сомнительным и существенно понижают её рейтинг]
2. если вы не знаете - какая кодировка в вашем HTML-редакторе, то напишите какой-нить
коротенький HTML-файл с русским текстом, не прописывая в нём <META charset> и запустите в
браузере, предварительно установив в браузере "Автоматическое определение кодировки"
когда страница с вашим файлом загрузится (и все русские буквы будут читабельны), посмотрите
"Информацию о странице" - там будет прописана определённая браузером фактическая кодировка
вашего HTML-редактора
3. если кодировка вашего HTML-редактора вас не устроит, соответственно, писать вам надо будет
в HTML-редакторе, в котором есть возможность сохранить файл в нужной кодировке
сам я использую Notepad++ (в сети найдёте, он бесплатен)
в нём есть пункт меню "Кодировка", в ней надо выбрать "Кодировать в UTF-8 (без BOM)"
4. всё это будет нормально работать из-под вашего локального компьютера
однако, при сохранении на сервере вполне возможна проблема
дело в том, что в серверном файле .htaccess существует команда принудительной установки
кодировки, в которую сервер преобразует ВСЕ свои файлы, отдавая их браузерам пользователей
и вполне может быть, что там у вас прописано AddDefaultCharset windows-1251
эту строчку вам надо просто удалить - тогда по умолчанию будет utf-8 (а лучше принудительно
записать AddDefaultCharset utf-8)
яса1 огромный респект, заработало =D .
CMS джумла, в БД инфа в UTF-8 - всё ОК!
Причина была в том, что у Вас описано в п.4 - зашел на хост, а там в настройках вирт сервера "Кодировка сайта - win1251".
Поменял на utf - всё встало на свои места! Стало быть настройки сервера оказались важнее для браузеров, чем мой хидер.
Были уже неск лет назад подобные заморочки - не знал, что можно было таким не сложным способом вылечить. Тогда, я помню, менял кодировку контента %
Спасибо ещё раз!
meta content="text/html; charset=utf-8, это не заголовок, вот если бы вы передавали его как
header(), вот это было бы заголовком, а так ваш сервер передавал этот заголовок со значением по умолчанию.
Возвращаясь к избитой проблеме с кодировками русских букв, хотелось бы иметь под рукой некий единый справочник или руководство, в котором можно найти решения различных сходных ситуаций. В своё время сам перелопатил множество статей и публикаций, чтобы находить причины ошибок. Задача этой публикации — сэкономить время и нервы читателя и собрать воедино различные причины ошибок с кодировками в разработке на Java и JSP и способы их устранения.
Варианты решения могут быть не единственными, охотно добавлю предложенные читателем, если они будут рабочими.
Итак, поехали.
1. Проблема: при получении разработанной мной страницы браузером весь русский текст идёт краказябрами, даже тот, который забит статически.
Причина: браузер неверно определяет кодировку текста, потому что нет явного указания.
Решение: явно указать кодировку:
a) HTML: добавляем тэг META в хидер страницы:
б) XML: указываем кодировку в заголовке:
в) JSP — задаём тип контента в заголовке:
г) JSP — задаём кодировку возвращаемой страницы
д) Java — устанавливаем хидер ответа:
2. Проблема: написанный в JSP-странице статический русский текст почему-то идёт краказабрами, хотя кодировка страницы задана.
Причина: статический текст был написан в кодировке, отличной от заданного странице.
Решение: изменить кодировку в редакторе (например, для AkelPad нажимаем «Сохранить как» и выбираем нужную кодировку).
3. Проблема: получаемый из запроса текст идёт кракозябрами.
Причина: кодировка запроса отличается от используемой для его обработки кодировки.
Решение: установить кодировку запроса или перекодировать в нужную.
а) Java, со стороны отправителя не задана нужная кодировка — перекодируем в нужную:
Примечание: кодировка ISO-8859-1 устанавливается по умолчанию, если не была задана другая.
б) Java, со стороны отправителя задана нужная кодировка — устанавливаем кодировку запроса:
4. Проблема: отправленный GET-параметром русский текст при редиректе приходит кракозябрами.
Причина: упаковка русского текста в URI по умолчанию идёт в ISO-8859-1.
Решение: упаковать текст в нужной кодировке вручную.
а) JSP, URLEncoder:
5. Проблема: текст из базы данных читается кракозябрами.
Причина: кодировка текста, прочитанного из базы данных, отличается от кодировки страницы.
Решение: установить соответствующую кодировку страницы, либо перекодировать полученные из базы данных значения.
а) Java, перекодирование считанной в db_string базы данных строки:
6. Проблема: текст записывается в базу данных кракозябрами, хотя на странице отображается правильно.
Причина: кодировка записываемой строки отличается от кодировки сессии работы с базой данных, либо от кодировки базы данных (стоит помнить, что они не всегда совпадают).
Решение: установить необходимую кодировку сессии или перекодировать строку.
а) Java, перекодирование записываемой строки db_string в кодировку сессии или базы данных:
б) Java, MySQL, настройка параметров подключения в строке dburl, передаваемой функции коннекта:
в) MySQL, настройка параметров подключения в XML-описателе контекста, добавляем атрибут к тегу \<Resource\>:
г) MySQL, прямая установка кодировки сессии вызовом SET NAMES (connect — объект подключения Connection):
7. Проблема: если ничего не помогло…
Решение: всегда остаётся самый «топорный» метод — прямое перекодирование.
а) Для известной кодировки источника:
[String MyValue = new String(source_string.getBytes("utf-8"),"cp1251");]
б) Для параметра запроса:
[String MyValue = new String(request.getParameter("MyParam").getBytes(request.getCharacterEncoding()),"cp1251");]
Дополнение, или что нужно знать:
1. Кодировки базы данных и сессии подключения могут различаться, в зависимости от конкретной СУБД и драйвера. К примеру, при подключении к MySQL стандартным драйвером com.mysql.jdbc.Driver без явного указания кодировка сессии устанавливалась в UTF-8, несмотря на другую кодировку схемы БД.
2. Кодировка упаковки строки запроса в URI по умолчанию устанавливается в ISO-8859-1. С подобным можно столкнуться, например, при передаче явно заданного текста в редиректе с одной страницы на другую.
3. Взаимоотношения кодировок страницы, базы данных, сессии, параметров запроса и ответа не зависят от языка разработки и описанные для Java функции имеют аналоги для PHP, Asp и других.
Примечание: восстановить ссылки на источники нет возможности, все примеры взяты из собственного кода, хотя когда-то так же выискивал их по многочисленным форумам.
Надеюсь, этот небольшой обзор поможет начинающим веб-программистам сократить время отладки и сберечь нервы.
При неправильной кодировке весь сайт или его часть отображаются в виде «кряпозяблов», т.е. непонятных символов, делающих текст нечитаемым. Такая ситуация может возникнуть при неверной настройке кодировки веб-сервера или при отсутствии настроек. Рассмотрим возможные варианты и способы устранения проблем
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
Как можно видеть, кодировка браузером определена неправильно:
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
Как мы можем убедиться на следующем скриншоте, проблема решена:
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
И в ней замените
После этого сервер нужно перезапустить.
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
Можно указать кодировку, которая будет применена только к файлам определённого формата:
Набор файлов может быть любым, например:
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
Как установить UTF-8 кодировку в PHP
В PHP скрипте для установки кодировки используется header, например:
Обычно вместе с кодировкой также указывают тип содержимого (в примере вариант для HTML страницы):
Ещё один вариант для RSS ленты:
Описанный способ работает только когда PHP скрипт полностью генерирует содержимое страницы. Статические страницы (такие как html) вы должны сохранять в кодировке utf-8. Большинство веб серверов обратят внимание на кодировку файла и добавят соответствующий заголовок. На самом деле, сохранение PHP файла в кодировке utf-8 приведёт к такому же результату.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:

Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
Если вы забыли имя базы данных, то выполните команду:
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
Если вы забыли имя таблиц, выполните:
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
Вы увидите примерно следующее:

Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
В PHP это можно сделать примерно так:
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
Изменение кодировки файлов
Если вы решили пойти другим путём и вместо установки новой кодировки изменить кодировку ваших файлов, то посмотрите статью «Как конвертировать файлы в кодировку UTF-8 в Linux». В ней рассказано, как узнать текущую кодировку файлов и как конвертировать файлы в любую кодировку (не только UTF-8).
Как узнать, какую кодировку отправляет сервер
Если вы хотите узнать, какие настройки кодировки имеет веб-сервер (какую кодировку передаёт в заголовках), то воспользуйтесь следующей командой:

Какую кодировку выбрать для веб-сайта
Рекомендуется выбрать кодировку UTF-8. Это более универсальная кодировка, практически, она стала стандартом. У вас не будет проблем с отображением необычных символов и букв из других алфавитов.
Случалось ли Вам получать и читать письма на “фиг каком пойми языке” или заходить на какой-нибудь интернет-ресурс и вместо привычных букв видеть сплошные кракозябры? Если да, тогда эта заметка для Вас, ибо в ней мы поговорим о кодировке страниц, её форматах, почему оная возникает и как впредь избежать непонятных иероглифов.

Итак, сегодня нас ждет не легкая софтовая статья, а суровая техническая, так что приготовьтесь: будем немного ударяться в суровые реалии.
Поехали.
Что такое кодировка текста и с чем ее едят?
Начать хотелось бы с того, что этой статьи могло бы и не быть, т.к. компьютерно-юзательная жизнь автора этих строк протекала вполне себе спокойно и достойно. Но вот в один прекрасный день, шляясь по просторам сети Интернет не со своего ПК, я столкнулся с непонятными явлениями на некоторых сайтах. Заходя на интернет-ресурсы, я видел не привычный нам русский алфавит и красивый понятный текст, а какую-то ересь в виде непонятной последовательности символов. Выглядела она примерно вот так (см. изображение).
Сначала я подумал, что моя любимая Мозилка (браузер Firefox) перегрелась и ей пора вызывать неотложку, но потом начал понимать, что проблема, скорее всего, на стороне ресурса сети и кроется она в неправильно настроенной кодировке. Это действительно оказалось так, и пошаманив немного с бубном, проблемка была оперативно решена. Результатом же всех моих любовных похождений и стал сегодняшний материал. Собственно, поехали разбираться в деталях.
Всю информацию, представленную в цифровом виде и находящуюся в глобальной паутине, нужно рассматривать с двух сторон: первая - со стороны пользователя (красивый и ухоженный текст на экране монитора) и вторая – со стороны поисковой машины (некий программный код, состоящий из различных тегов/метатегов, таблицы символов и прочее).
Если Вы хоть немного знакомы с языком разметки гипертекста ( HTML ), то должны быть в курсе, что сайт глазами поисковых машин (Google, Яндекс ) видится не как обычный текст, а как структурированный документ, состоящий из последовательностей различного рода тегов. Чтобы было понятней, о чем я говорю, давайте взглянем на всеми нами любимый сайт Заметки Сис.Админа ” проекта [ Sonikelf's Project's ], но не глазами обычного пользователя, а "глазами" поисковика. Для этого нажимаем сочетание клавиш Сtrl+U (для браузеров Firefox и Chrome ) и видим следующую картину (см. изображение):
Теперь давайте разберемся, почему же происходит так, что порой на экране монитора мы видим кракозябры. Все очень просто, проблема кроется в открытии файла в неверной кодировке. Если перевести на бытовой язык, то допустим Вас послали в магазин за молоком, а Вы притарабанили хлеб, вроде бы тоже съестное, но совсем другой формат продукта.
Итак, теперь давайте разбираться с теорией и для этого введем некоторые определения.
- Кодировка (или “ Charset ”) – соответствие набора символов набору числовых значений. Нужна для “сливания” информации в интернет, т.е. текстовая информация преобразуется в биты данных;
- Кодовая страница (“ Codepage ”) – 1 байтовая ( 8 бит) кодировка;
- Количество значений, принимаемое 1 байтом – 256 (два в восьмой).
Соответствие “символ-изображение” задается с помощью специальных кодовых таблиц, где каждому символу уже присвоен свой конкретный числовой код. Таких таблиц существует достаточно много, и в разных таблицах один и тот же символ может идентифицироваться по-разному (ему могут соответствовать разные числовые коды).
Все кодировки различаются количеством байт и набором специальных знаков, в которые преобразуется каждый символ исходного текста.
Примечание:
Декодирование – операция, в результате которой происходит преобразование кода символа в изображение. В результате этой операции информация выводится на экран монитора пользователя.
В общем.. С определениями разобрались, а теперь давайте узнаем, какие же (кодировки) бывают.
Виды кодировок текста
А их, в общем-то, хватает.
Одной из самых “древних” считается американская кодировочная таблица ( ASCII , читается как “аски”), принятая национальным институтом стандартов. Для кодировки она использовала 7 битов, в первых 128 значениях размещался английский алфавит (в нижнем и верхнем регистрах), а также знаки, цифры и символы. Она больше подходила для англоязычных пользователей и не была универсальной.
Отечественный вариант кодировки, для которого стали использовать вторую часть кодовой таблицы – символы с 129 по 256 . Заточена под русскоязычную аудиторию.
- Кодировки семейства MS Windows : Windows 1250-1258 .
Универсальный стандарт кодирования символов, позволяющий описать знаки практически всех письменных языков. Обозначение “ U+xxxx ” (хххх – 16-ричные цифры). Самые распространенные семейства кодировок UTF (Unicode Transformation Format) : UTF-8, 16, 32 .
В настоящее время, как говорится, “рулит” UTF-8 – именно она обеспечивают наилучшую совместимость со старыми ОС , которые использовали 8 -битные символы. В UTF-8 кодировке находятся большинство сайтов в сети Интернет и именно этот стандарт является универсальным (поддержка кириллицы и латиницы).
Разумеется, я привел не все виды кодировок, а только наиболее ходовые. Если же Вы хотите для общего развития знать их все, то полный список можно отыскать в самом браузере. Для этого достаточно пройти в нем на вкладку “ Вид-Кодировка-Выбрать список ” и ознакомиться со всевозможными их вариантами (см. изображение).
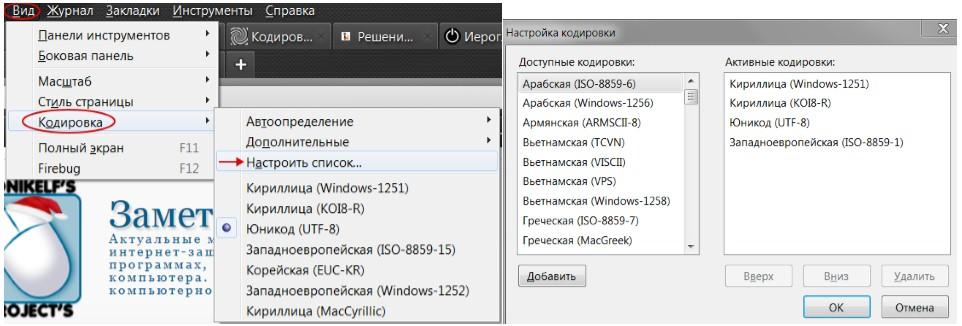
Думаю возник резонный вопрос: “ Какого лешего столько кодировок? ”. Их изобилие и причины возникновения можно сравнить с таким явлением, как кроссбраузерность/кроссплатформенность. Это когда один и тот же сайт сайт отображается по-разному в различных интернет-обозревателях и на различных гаджет-устройствах. Кстати у сайта " Заметки Сис.Админа " с этим, как Вы заметили всё в порядке :).
Ну вот, собственно, пока вся "базово необходимая" теория, которая позволит Вам “не плавать” в кодировочных вопросах, теперь переходим к практической части статьи.
Решаем проблемы с кодировкой или как убрать кракозябры?
Итак, наша статья была бы неполной, если бы мы не затронули пользовательско-бытовые вопросы. Давайте их и рассмотрим и начнем с того, как (с помощью чего) можно посмотреть кодировку?
В любой операционной системе имеется таблица символов, ее не нужно докачивать, устанавливать – это данность свыше, которая располагается по адресу: “Пуск-программы-стандартные-служебные-таблица символов”. Это таблица векторных форм всех установленных в Вашей операционной системе шрифтов.
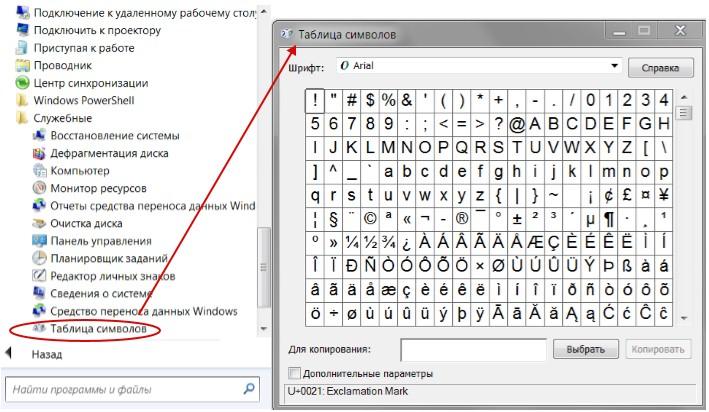
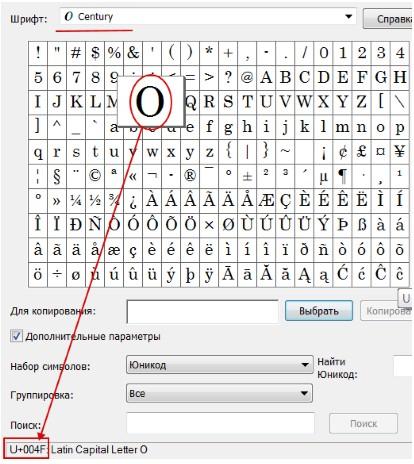
Выбрав “дополнительные параметры” (набор Unicode ) и соответствующий тип начертания шрифта, Вы увидите полный набор символов, в него входящих. Кликнув по любому символу, Вы увидите его код в формате UTF-16 , состоящий из 4 -х шестнадцатеричных цифр (см. изображение).
Теперь пара слов о том, как убрать кракозябры. Они могут возникать в двух случаях:
- Со стороны пользователя - при чтении информации в интернет (например, при заходе на сайт);
- Или, как говорилось чуть выше, со стороны веб-мастера (например, при создании/редактировании текстовых файлов с поддержкой синтаксиса языков программирования в программе Notepad ++ или из-за указания неправильной кодировки в коде сайта).
Рассмотрим оба варианта.

Также проверьте во всех вкладках, чтобы локализация была “ Россия/русский ” – это так называемая системная локаль.
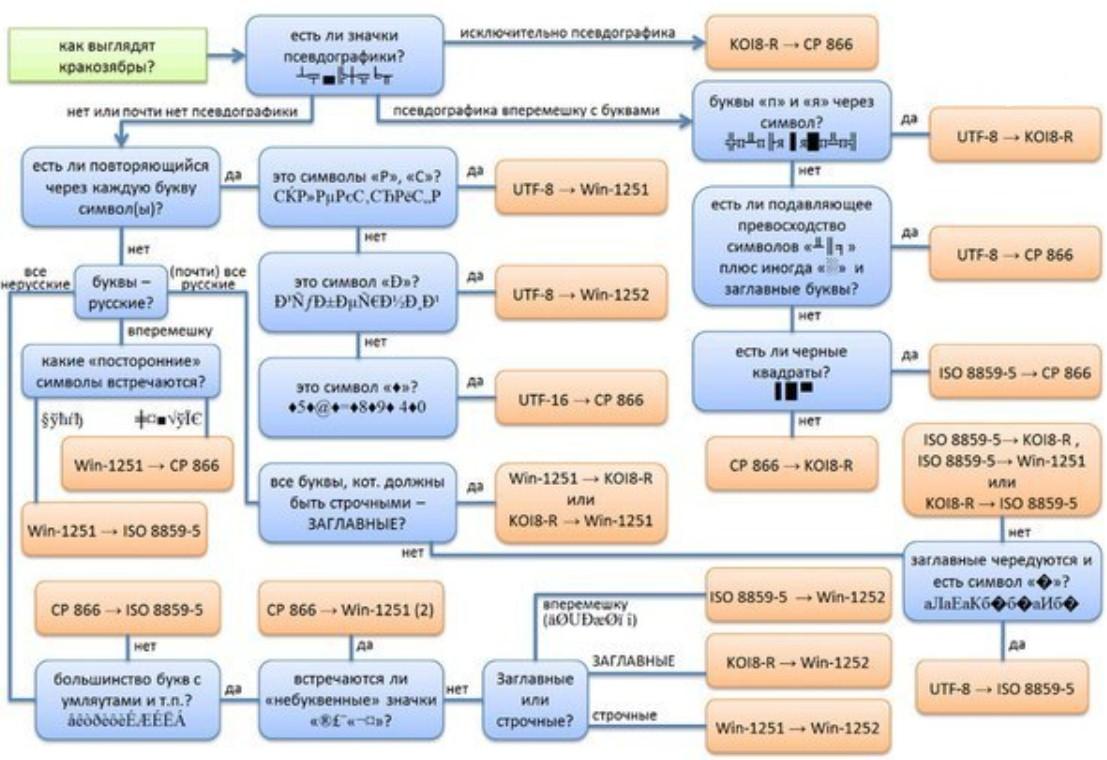
Если Вы открыли сайт и вдруг поняли, что почитать информацию Вам не дают иероглифы, тогда стоит поменять кодировку средствами браузера (“ Вид - Кодировка ”). На какую? Тут все зависит от вида этих кракозябр. Ориентируйтесь на следующую шпаргалку (см. изображение).
Чтобы такого не происходило, заходим в редактор Notepad++ и выбираем в меню пункт “ Кодировки ”. Именно он поможет преобразовать имеющийся документ. Спрашивается, какой? Чаще всего (если сайт на WordPress или Joomla ), то “ Преобразовать в UTF-8 без BOM ” (см. изображение).
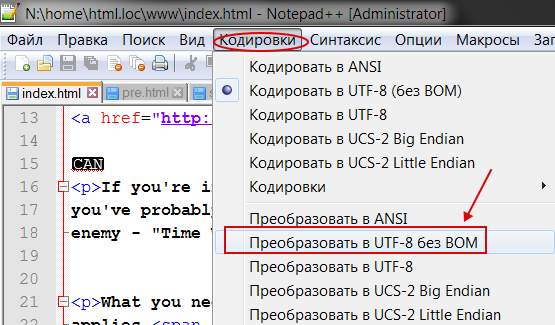
Сделав такое преобразование, Вы увидите изменения в строке статуса программы.

Также во избежание кракозябр необходимо принудительно прописать информацию о кодировке в шапке сайта. Тем самым Вы укажите браузеру на то, что сайт стоит считывать именно в прописанной кодировке. Начинающему веб-мастеру необходимо понимать, что чехарда с кодировкой чаще всего возникает из-за несоответствия настроек сервера настройкам сайта, т.е. на сервере в базе данных прописана одна кодировка, а сайт отдает страницы в браузер в совершенной другой.
Для этого необходимо прописать “внаглую” (в шапку сайта, т.е, как частенько, в файл header.php ) между тегами < head> < /head> следующую строчку:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Прописав такую строчку, Вы заставите браузер правильно интерпретировать кодировку, и иероглифы пропадут.
Также может потребоваться корректировка вывода данных из БД (MySQL). Делается сие так:
mysql_query('SET NAMES utf8' );
myqsl_query('SET CHARACTER SET utf8' );
mysql_query('SET COLLATION_CONNECTION="utf8_general_ci'" ');
Как вариант, можно еще сделать ход конём и прописать в файл .htaccess такие вот строчки:
Все вышеприведенные методы (или некоторые из них), скорее всего, помогут Вам и Вашим будущим посетителям избавиться от ненавистных иероглифов и проблем с кодировкой. К сожалению, более подробно мы здесь инструкцию по веб-мастерским штукам рассматривать не будем, думаю, что они обязательно разберутся в подробностях при желании (как-никак у нас несколько другая тематика сайта).
Ну, вот и практическая часть статьи закончена, осталось подвести небольшие итоги.
Послесловие
Сегодня мы познакомились с таким понятием, как кодировка текста. Уверен, теперь при возникновении каракулей на мониторе компьютера Вы не спасуете, а вспомните все приведенные здесь методы и решите вопрос в свою пользу!
На сим все, спасибо за внимание и до новых встреч.
P.S. Комментарии, как и всегда, ждут Ваших горячих дискуссий и вопросов, так что отписываем.
P.P.S : За существование данной статьи спасибо члену команды 25 КАДР
Вопрос пользователя
Здравствуйте.
Подскажите пожалуйста, почему у меня некоторые странички в браузере отображают вместо текста иероглифы, квадратики и не пойми что (ничего нельзя прочесть). Раньше такого не было.
Заранее спасибо.
Доброго времени суток!
Действительно, иногда при открытии какой-нибудь интернет-странички вместо текста показываются различные "крякозабры" (как я их называю), и прочитать это нереально.
Происходит это из-за того, что текст на страничке написан в одной кодировке (более подробно об этом можете узнать из Википедии ), а браузер пытается открыть его в другой. Из-за такого рассогласования, вместо текста — непонятный набор символов.

Исправляем иероглифы на текст
Браузер
Скажу даже больше, в некоторых версиях браузера уже убрали выбор кодировки, и для "ручной" настройки этого параметра нужно скачивать дополнения, или лезть в дебри настроек за 10-ток галочек.

Вместо текста одни лишь крякозабры // Браузер выставил кодировку неверно!
Поэтому, я рекомендую в ручном режиме попробовать их обе. Для этого нам понадобиться браузер MX5 (ссылка на офиц. сайт). Он один из немногих позволяет в ручном режиме выбирать кодировку (при необходимости):
Браузер MX5 — выбор кодировки UTF8 или авто-определение

Теперь отображается русский текст норм.
Текстовые документы
Очень много вопросов по крякозабрам задаются при открытии каких-нибудь текстовых документов. Особенно старых, например, при чтении Readme в какой-нибудь программе прошлого века (скажем, к играм) .
Разумеется, что многие современные блокноты просто не могут прочитать DOS'овскую кодировку, которая использовалась ранее. Чтобы решить сию проблему, рекомендую использовать редактор Bread 3.
Иероглифы при открытии текстового документа
Далее в Bred 3 есть кнопка для смены кодировки: просто попробуйте поменять ANSI на OEM — и старый текстовый файл станет читаемым за 1 сек.!
Исправление иероглифов на текст
Пример смены кодировки показан ниже: чтобы прочитать текст, достаточно в примере ниже, достаточно было сменить кодировку ANSI на UTF-8.
Смена кодировки в блокноте Notepad++

Пример работы ПО "Штирлиц"
BAT-файлы (скрипты)
На скрине видно, что вместо русского текста отображаются различные квадратики, буквы "г" перевернутые, и пр. иероглифы.

Как выглядит русский текст при выполнении BAT-файла
- в начало BAT-файла добавить код @chcp 1251 ;
- установить программу Notepad++ и в меню выбрать OEM-866: "Кодировки/Кодировки/Кириллица/OEM-866" ;
- установить программу Akelpad, в разделе "Кодировки" выбрать "Сохранить в DOS-866" .
Документы MS WORD
Очень часто проблема с крякозабрами в Word связана с тем, что путают два формата Doc и Docx . Дело в том, что с 2007 года в Word (если не ошибаюсь) появился формат Docx (позволяет более сильнее сжимать документ, чем Doc, да и надежнее защищает его).
Так вот, если у вас старый Word, который не поддерживает этот формат — то вы, при открытии документа в Docx, увидите иероглифы и ничего более.
Так же при открытии любого документа в Word (в кодировке которого он "сомневается"), он на выбор предлагает вам самостоятельно указать оную. Пример показан на рисунке ниже, попробуйте выбрать:
- Widows (по умолчанию);
- MS DOS;
- Другая.
Переключение кодировки в Word при открытии документа
Окна в различных приложениях Windows
Бывает такое, что какое-нибудь окно или меню в программе показывается с иероглифами (разумеется, прочитать что-то или разобрать — нереально).
Языки и региональные стандарты в Windows
Чтобы открыть меню настроек:
- нажмите Win+R ;
- введите intl.cpl , нажмите Enter.
intl.cpl - язык и регион. стандарты
Формат - русский / Россия
Во вкладке "Местоположение" — укажите "Россия" .
И во вкладке "Дополнительно" установите язык системы "Русский (Россия)" .
После этого сохраните настройки и перезагрузите ПК. Затем вновь проверьте, нормально ли отображается интерфейс нужной программы.
Текущий язык программ
PS
И напоследок, наверное, для многих это очевидно, и все же некоторые открывают определенные файлы в программах, которые не предназначены для этого: к примеру в обычном блокноте пытаются прочитать файл DOCX или PDF.
Естественно, в этом случае вы вместо текста будут наблюдать за крякозабрами, используйте те программы, которые предназначены для данного типа файла (WORD 2016+ и Adobe Reader для примера выше).
Читайте также: