
Как браузер читает css
Обновлено: 07.07.2024
в частности, я хотел бы уточнить, как и почему JavaScript и CSS отличаются тем, что с JavaScript вам нужно специально подождать до окна.onload, чтобы интерпретатор мог правильно getElementById. Однако в CSS вы можете выбрать и применить стили для классов и идентификаторов всех коварных nily.
(Если это даже имеет значение, предположим, что я имею в виду базовую HTML-страницу с внешней таблицей стилей в голове)
Если вы работали с медленным соединением в последнее время, вы обнаружите, что CSS будет применяться к элементам по мере их (медленного) появления, фактически отражая содержимое страницы по мере загрузки структуры DOM. Поскольку CSS не является языком программирования, он не полагается на объекты, доступные в данный момент для правильного анализа (JavaScript), и браузер может просто повторно оценить структуру страницы, поскольку он извлекает больше HTML, применяя стили к новым элементам.
возможно вот почему, даже сегодня, узким местом мобильного Safari не является 3G-соединение во все времена, но это рендеринг страницы.
CSS-рендеринг-интересная тема, и все конкуренты процветают, чтобы ускорить рендеринг слоя просмотра (HTML и CSS), чтобы доставить лучшие результаты конечным пользователям в мгновение ока.
во-первых, да, разные браузеры имеют свои собственные CSS-парсер/рендеринга
- Chrome, Opera (из версии 15) - использует в WebKit форк под названием Блинк Движок
- Safari-использует Webkit (теперь переход к Webkit2)
- Internet Explorer-использует Тризуб движок
- Mozilla firefox-использует Gecko
все эти движок рендеринга содержат интерпретатор CSS и HTML DOM parser.
все эти двигатели следуют ниже перечисленных моделей, это набор стандарт W3C
да, браузеры имеют встроенный интерпретатор CSS. Причина, по которой вы не "подождите до окна.onload " - это потому, что, хотя Javascript является императивным языком программирования Turing, CSS-это просто набор правил стиля, которые браузер применяет к соответствующим элементам, с которыми он сталкивается.
возьмите, например, эту строку CSS:'.пункт Н4'. Браузер ищет все теги " h4 "на странице, а затем смотрит, имеет ли тег h4 родителя с именем класса "item". Если он находит его, он применяет правило CSS.
Я недавно наткнулся на эту статью на скорость страницы:
когда браузер анализирует HTML, он создает внутреннее дерево документов, представляющее все элементы, которые будут отображаться. Затем он сопоставляет элементы со стилями, указанными в различных таблицах стилей, в соответствии со стандартными правилами каскада CSS, наследования и упорядочения. В реализации Mozilla (и, возможно, других) для каждого элемента CSS-движок ищет правила стиля, чтобы найти соответствие. Этот engine оценивает каждое правило справа налево, начиная с самого правого селектора (называемого "ключом") и перемещаясь через каждый селектор, пока не найдет совпадение или не отбросит правило. ("Селектора" - это элемент документа, к которому должно применяться правило.)
Это лучшее описание, которое я нашел о том, как браузер имеет дело с HTML и CSS:
обработчик рендеринга начнет разбор HTML-документа и превратит теги в узлы DOM в дереве, называемом "дерево содержимого". Он будет анализировать данные стиля, как во внешних файлах CSS, так и в элементах стиля. Информация о стиле вместе с визуальными инструкциями в HTML будет использоваться для создания другого дерева-дерева рендеринга.
В общем задания механизма рендеринга:
- Токенизируйте правила (разбивая входные данные на токены AKA Lexer)
- построение дерева синтаксического анализа путем анализа структуры документа в соответствии с правилами синтаксиса языка
CSS parser
В отличие от HTML, CSS является контекстно-свободной грамматики(С детерминированной грамматики).
Так что у нас будет спецификация CSS определение лексического и синтаксис грамматика, что парсер применяется, проходя через таблицу стилей.
лексическая грамматика (словарь) определяется регулярными выражениями для каждого токена:
грамматика синтаксиса описана в BNF.
для подробного описания рабочего процесса браузера взгляните на это статьи.
Я считаю, что браузер интерпретирует CSS, как он его находит, с тем эффектом, что CSS в теле (встроенный) имеет приоритет над CSS (внешний, а также) в голове

Автор: Антон Реймер
Статья основана на вебинаре, который я проводил некоторое время назад. Рассчитана она, в первую очередь на тех, кто не знает, как работают браузеры, или тех, у кого есть пробелы в знаниях. Вероятно, здесь будет много очевидного для тех кто не первый день в веб-разработке. Статью я решил разделить на две части. В первой рассмотрим общие принципы работы браузера. Во второй части я акцентирую внимание на некоторых важных моментах: reflow и repaint, event loop.
Что такое браузер?
Браузер — программа, работающая в операционной системе. Большинство браузеров написано на языке C++. Основное предназначение браузера — воспроизводить контент с веб-ресурсов. В качестве веб-ресурса в большинстве случаев выступает html-страница. Это также может быть pdf-файл, png, jpeg, xml-файлы и другие типы. Среди огромного количества браузеров можно выделить самые популярные: Chrome, Safari, Firefox, Opera и Internet Explorer. Мы рассмотрим браузеры с открытым исходным кодом: Chrome, Firefox, Safari.
Из чего состоит и как работает браузер?
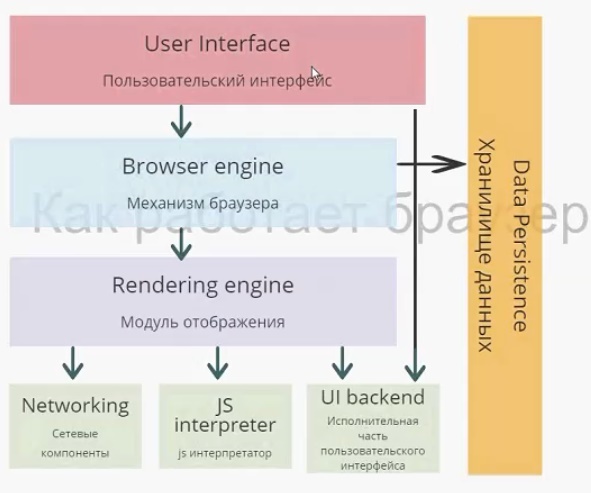
На схеме изображены модули браузера, каждый выполняет собственную функцию. Начнем с пользовательского интерфейса.
Пользовательский интерфейс — то, что видит перед собой пользователь, т. е. адресная строка, элементы навигации, собственное меню и т. д. Несмотря на то что пользовательские интерфейсы очень похожи друг на друга, никакого стандарта, который их описывал бы, не существует. Так исторически сложилось, что браузеры постепенно перенимали интерфейс друг у друга и становились все более похожими.
Механизм браузера отвечает за взаимодействие пользовательского интерфейса и модуля отображения, а также за сохранение данных в памяти.
Модуль отображения. Этот модуль — самый важный для разработчиков. Работа разработчика, в первую очередь, происходит именно с ним, а как можно понять по названию — отвечает он за отображение информации на экране.
Когда мы говорим о браузерных движках, таких как Webkit или Gecko (первый находится «под капотом» у Safari и до 2013 года был у Chrome, второй у Firefox), в первую очередь имеем в виду модуль отображения. Далее мы подробно рассмотрим модуль отображения и более детально разберем, как он работает.
Следующий модуль — сетевые компоненты. Он отвечает за запросы по сети, берет данные с внешних ресурсов и взаимодействует с модулем отображения.
Модуль JS Interpreter отвечает за интерпретацию скрипта, и его выполнение. Существует несколько JS-движков. Самые известные это V8 и JavaScriptCore. Важно не путать движок браузера и JS-движок, который работает в модуле JS Interpreter.
Следующий модуль — исполнительная часть пользовательского интерфейса (UI backend). Она отвечает за отрисовку всего на экране и работу пользовательского интерфейса.
Последний модуль — хранилище данных. Браузеру нужно где-то хранить данные, обычно для этого используется оперативная память. Какие данные нужно хранить? Например, кэш, собственные настройки. Также к хранилищу данных можно отнести indexedDB, который появился в стандарте html5 — собственные базы данных браузера.
Модуль отображения
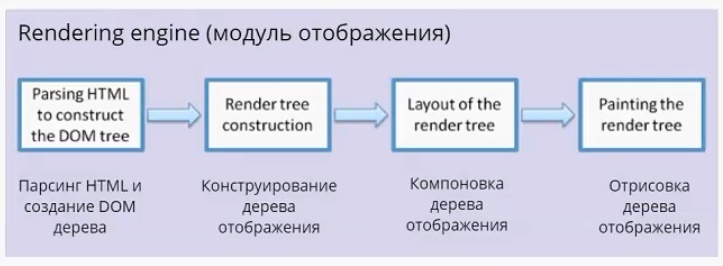
Модуль отображения получает данные от сетевого модуля. Данные поступают пакетами по 8 Кб. Что важно — модуль отображения не ждет, пока придут все данные, он начинает обрабатывать и выводить их на экран по мере поступления. В случае с html-страницами, он начинает их анализировать, происходит парсинг html (это отдельная большая тема, я на ней останавливаться не буду). Главное, что нужно понимать: в результате парсинга у нас появляется DOM-дерево. Также по окончании парсинга срабатывает событие load, которое можно обрабатывать в скрипте. Это значит, что документ готов и скрипт может с ним работать.
DOM-дерево — document object model. По большому счету, «интерфейс», который предоставляет браузер JS-движку для работы с тем или иным html-документом. На основе DOM-дерева происходит конструирование дерева отображения (render tree). Дерево отображения — тоже важная часть модуля отображения. По большому счету, два этих дерева — DOM-дерево и дерево отображения — наиболее важные элементы для разработчика. Дерево отображения во многом повторяет структуру DOM-дерева (далее будет пример, где это будет представлено нагляднее), но имеет некоторые отличия:
- Дерево отображения не содержит скрытых элементов. Если у нас есть html-элемент, у которого прописан display:none , в дереве отображения он присутствовать не будет. При этом, если visibility:hidden , то в дереве отображения он будет. Некоторые DOM-узлы, которые в DOM-дереве представлены как единый узел, в дереве отображения могут быть представлены в виде нескольких. Яркий пример — составной тэг select. Если в DOM-дереве это один узел, в дереве отображение он преобразовывается в минимум три узла. Первый узел отвечает за отображение выбранного элемента. Второй — за выпадающий список с возможными пунктами. И, наконец, третий блок отвечает за стрелочку.
- Текст в DOM-дереве представлен как простая node. DOM-дереву нет никакого дела до того, что там написано, сколько строк этот текст занимает. В то время, как для дерева отображения — это важно, и текст трансформируется в несколько узлов, в зависимости от того сколько строк он занимает. Это нагляднее рассмотрим чуть позже.
Дерево отображения служит для того, чтобы браузер понимал, что выводить на экран. Оно содержит информацию о том, из каких блоков состоит страница. Дальше в тексте для простоты я буду называть составные части дерева отображения прямоугольниками, чтобы не путать с html блоками.
Дерево отображения — совокупность прямоугольников, которая должна быть выведена на экране. После того как дерево отображения сконструировано, следует этап компоновки. На этом этапе всем прямоугольникам присваиваются размеры и координаты. Каждый прямоугольник получает свои ширину и высоту, координаты в окне браузера. После компоновки происходит отрисовка дерева отображения. Пользователь видит уже конечный результат. Модуль отображения в каждом браузере устроен по-своему, но схема работы схожая.

Предлагаю рассмотреть два браузерных движка: Webkit и Gecko.
Webkit. Модуль отображения получает html и стили. В результате парсинга html возникает DOM-дерево. В результате парсинга CSS возникает дерево правил таблиц стилей (Style Rules). Далее идет важный этап, который называется Attachment, можно перевести, как «совмещение». На этом этапе CSS-стили накладываются на DOM-дерево, в результате чего появляется Render Tree. После чего происходит компоновка дерева. Называется она здесь Layout. И в завершении происходит отрисовка (Painting).
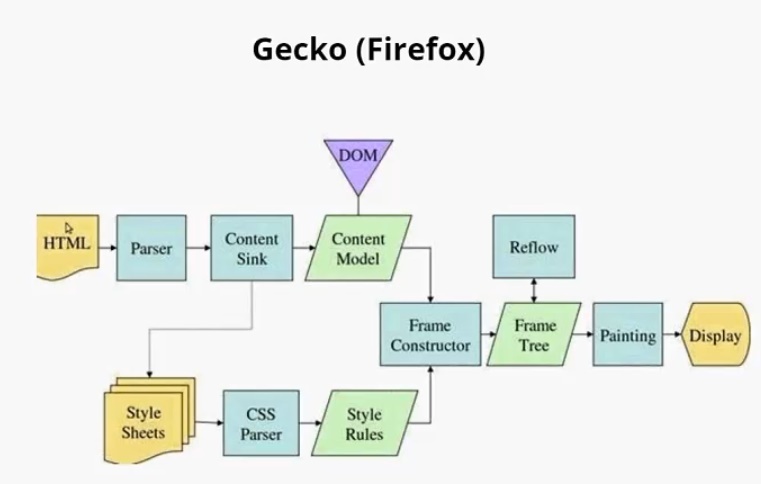
Если посмотреть на Gecko, можно заметить, что схемы очень похожи. Главные отличия — в терминологии. Здесь тоже парсятся HTML, CSS. В результате чего создается DOM-дерево, которое здесь называется Content Model. Парсятся стили, образуется дерево стилей. Этап Attachment здесь называется Frame Constructor, но, по сути, это тоже самое. В результате совмещения образуется дерево отображения, здесь оно называется Frame Tree. Компоновка здесь называется Reflow. А отрисовка называется Painting, так же, как и в Webkit.
- Attachment = Frame constructor = Совмещение
- Render Tree = Frame Tree = Дерево отображения
- Layout= Reflow = Компоновка
Пример

Здесь у нас есть теги:

Модуль отображения строит DOM-дерево. В данном случае оно будет выглядеть следующим образом. Есть корневой элемент (он всегда присутствует), называется он documentElement и соответствует тегу html . В этом дереве присутствуют все теги. И заметим, что текст представлен, как [text node] . И DOM-дереву больше ничего о тексте знать не нужно. На основе этого DOM-дерева строится Render Tree.
Пример
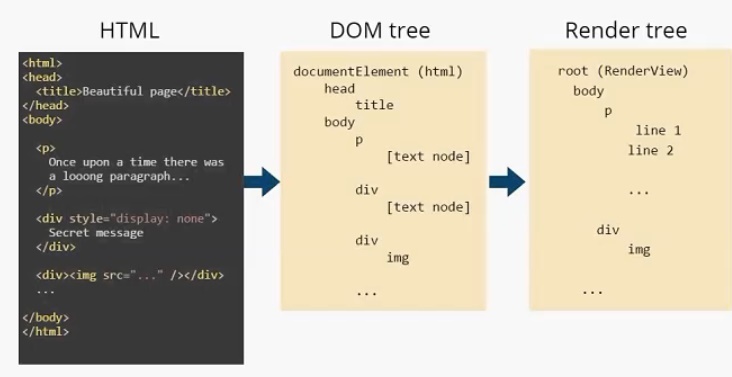
Дерево отображения. У него также есть корневой элемент (RenderView), но уже можно увидеть отличия между DOM-деревом и деревом отображения. Во-первых, нет тега head , т. к. он не отображается на экране. Нет <div style =” display: none”> , есть только
Текст в дереве отображения разделился на две строки и представляет собой два элемента: line 1 и line2. Как я писал выше, узлы дерева отображения мы будем называть прямоугольниками. Для наглядности я так и отобразил их на иллюстрации.
Пример
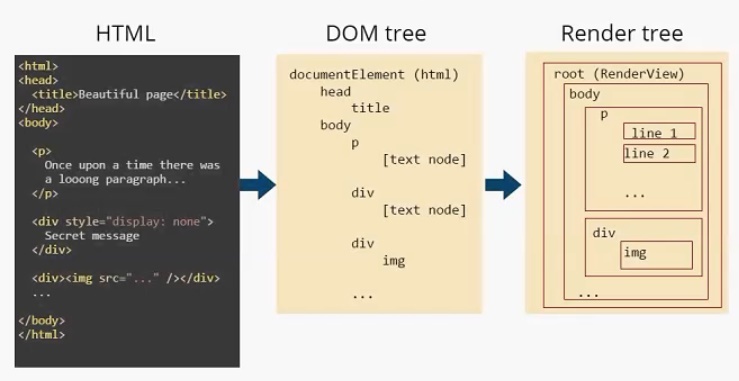
Каждый прямоугольник имеет своего «родителя», кроме корневого элемента root.
Модуль отображения также занимается обработкой скриптов.
Порядок обработки скриптов и таблиц стилей
Важно понимать порядок, в котором происходит обработка скриптов. Рассмотрим следующий пример, где я попытался продемонстрировать все возможные способы подключения скриптов и стилей.
Скрипт 1. Первое, что нужно знать про скрипты, — когда при парсинге html анализатор встречает скрипт, он останавливает дальнейший парсинг документа. Т. е., как только анализатор дошел до скрипта 1, браузеру ничего неизвестно о том, что будет дальше. И пока скрипт 1 не выполнится, дальнейший анализ документа происходить не будет.
Но при этом браузер продолжает выполнять ориентировочный синтаксический анализ. Что это значит? Браузер все равно смотрит, что следует за скриптом. Если находятся ссылки на внешние ресурсы, которые нужно скачать и загрузить, он подгрузит эти данные, пока выполняется скрипт 1. Сделано это для оптимизации.
При этом скрипт 3 все равно не будет выполняться, пока не выполнится скрипт 1. К моменту, когда скрипт 1 уже выполнится, скрипт 3 уже может быть полностью загружен. Скрипты можно вставлять в теги head и body . Разница в том, что в скрипте 2, в отличии от скрипта 1, практически весь документ уже будет проанализирован.
У скрипта могут быть атрибуты, такие как defer и async . Они похожи, но у них есть отличия:
- Атрибут defer сообщает браузеру, чтобы тот не ждал окончания выполнения скрипта, а продолжал парсинг html-страницы. При этом скрипт 4 выполнится только после того, как весь html-документ будет проанализирован и построено DOM-дерево.
- Атрибут async тоже говорит браузеру, что дальнейший html-документ может быть проанализирован, пока скрипт выполняется. При этом он загружается в параллельном потоке и выполняется сразу после загрузки. Это означает, что он может быть выполнен раньше, чем скрипт1, если последний тоже имеет атрибут async. Т. е. порядок подключения в этом случае не соблюдается.
В случае с defer скрипт 4 всегда выполняется после скрипта 1. С атрибутом async неизвестно, когда он будет выполнен и какая часть документа уже будет проанализирована к этому моменту.
Стили, в отличие от скриптов, никак не могут повлиять на документ. Если скрипты могут добавить дополнительные узлы или теги, то стили этого сделать не могут. Поэтому никакой надобности для браузера блокировать дальнейший анализ документа нет.
При этом есть небольшой нюанс. Например, скрипт 1 может работать с теми или иными стилям, и может потребоваться доступ к ним. Т.е. если мы хотим поменять (или узнать) какие-то стили, но при выполнении скрипта 1 они ещё не подгружены — может случиться ошибка.
Браузеры стараются этот нюанс учесть. Firefox, например, если находит какие-то не подгруженные стили в процессе ориентировочного синтаксического анализа, блокирует выполнение скрипта, подгружает стили, после чего завершает выполнение скрипта. Chrome действует аналогичным образом, но чуть более оптимизировано. Он останавливает скрипт, только если понимает, что в этом скрипте происходит работа с не подгруженными стилями.
Компоновка окон

Окно = Прямоугольник = Узел дерева отображения
- Тип окна (свойство display).
- Схема позиционирования (свойства position и float).
- Размеры окна.
- Внешняя информация (размеры изображения, размер экрана).
Компоновка окон — это этап компоновки дерева отображения. Я думаю многим верстальщикам знакома эта схема, она называется “Box model”. Я не буду подробно на ней останавливаться.
При компоновке окон учитываются следующее факторы:
CSS-свойство display. Два основных типа — inline и block. Другие, такие как inline-block table и прочие, появились уже позже. Отличие в том, что display:block, указывает, что ширина прямоугольника будет вычисляться в зависимости от ширины «родителя». А display:inline указывает, что ширина прямоугольника будет вычисляться в зависимости от его содержимого. Если в элементе два слова, ширина прямоугольника будет равна ширине, необходимой для вывода этих слов. Inline-элементы выстраиваются друг за другом. А блочные элементы — друг под другом.
Следующее, что влияет на компоновку элемента, — свойства position и float. Position по умолчанию static, при этом прямоугольник идет в стандартном потоке компоновки. Также есть position:relative и position:absolute. Position:relative указывает, что прямоугольнику выделяется место в стандартном потоке компоновки. При этом позиция элемента может быть сдвинута относительно этого места: влево, вправо, вверх, вниз с помощью соответствующего свойства.
Абсолютное позиционирование, к которому относится position:absolute и position:fixed, указывает, что элемент выходит за пределы своего прямоугольника из общего потока компоновки. Остальные прямоугольники его не учитывают. Он также не учитывает соседние элементы. Координаты его вычисляются относительно корневого элемента страницы, либо относительно предка, у которого position не static. Размеры же вычисляются тоже относительно родителя. Также на позиционирование влияет свойство float. Оно указывает, что наш прямоугольник идет в стандартном потоке, но при этом занимает либо крайнюю левую, либо крайнюю правую позиции. При этом все остальные прямоугольники «обтекают» этот элемент.
В заключение этой части стоит сказать что, основной поток браузера представляет собой бесконечный цикл, поддерживающий рабочие процессы. Он ожидает отправки событий, таких как reflow и repaint. Эти события ему приходят от модуля отображения. Получив их, он выполняет соответствующие действия.
В Firefox модуль отображения работает в одном потоке. Он един на весь браузер. В Chrome все немного иначе: модуль отображения и поток выполнения у каждой вкладки свои.
Важно, что сетевой модуль работает в отдельных параллельных потоках, которые не связаны с модулем отображения. Следовательно, сетевой компонент может использовать ресурсы независимо от того, что происходит в модуле отображения. Обычно у такого компонента есть возможность работать одновременно с несколькими подключениями и подгружать сразу несколько файлов. В Firefox, например, может быть шесть параллельных потоков, с помощью которых можно подгружать контент, скрипты и т. д.
В следующей части мы детально рассмотрим события reflow и repaint и попытаемся понять как грамотная работа с ними может повысить скорость работы приложения.
Если клиент не поддерживает постоянные соединения, он обязан включать такой заголовок в любой запрос.
После отправки запроса и заголовков, браузер отправляет пустую строку, сигнализирующую об окончании контента запроса. Сервер отвечает кодом, обозначающим статус запроса, за которым следуют заголовки ответа:
и не включать в ответ содержимое файла. Тогда браузер загружает файл из кэша.
Сервер проверяет:
— наличие виртуального хоста, соответствующего запрошенному домену
— этот домен принимает GET-запросы
— клиент имеет право делать такой запрос (возможные ограничения по ip, авторизация, и т.д.)
При наличии у сервера модуля преобразования путей (mod_rewrite у Apache или URL Rewrite у IIS) он пытается сопоставить запрос одному из заданных правил. Если правило найдено, сервер преобразовывает запрос согласно ему.
Затем сервер читает файл, соответствующий запросу. Если, например, Google работает на PHP, тогда сервер использует PHP для интерпретации файла индексов, и выдаёт результат интерпретации клиенту.
За кулисами браузера
После получения браузером всех ресурсов (HTML, CSS, JS, картинки, и т.д.) браузер парсит текстовые ресурсы (HTML, CSS, JS), и запускает рендер страницы. Для этого строится дерево DOM, затем оно обрабатывается, просчитывается расположение элементов и они выводятся на экран.
Браузер
Функция браузера – предоставить выбранный веб-ресурс, запросив его с сервера, и показать его в окне. Обычно это HTML-документ, но это может быть и PDF, картинка и другой контент. Местоположение ресурса задаётся универсальным идентификатором URI.
То, как браузер интерпретирует и показывает HTML-файл, задано в спецификациях HTML и CSS, которые поддерживаются консорциумом W3C (World Wide Web Consortium).
У всех браузеров обычно есть:
— адресная строка для вставки URI
— кнопки назад и вперёд
— возможность делать закладки
— кнопки обновления и останова
— кнопка «домой»
Высокоуровневая структура браузера
Разбор HTML (парсер)
Движок рендера получает контент запрошенного документа, обычно кусочками по 8 Кб. Задача парсера – превратить разметку в дерево. Дерево парсера – древовидная структура DOM-элементов и узлов. DOM, или Document Object Model – это представление HTML-документа и его элементов для других движков, например для JavaScript. До обработки скриптов DOM имеет почти полное взаимно однозначное соответствие с разметкой.
Алгоритм парсера
HTML нельзя разобрать обычными парсерами, работающими сверху вниз или снизу вверх. Разметка слишком либеральная, браузеры допускают определённые ошибки в разметке, а работа скриптов иногда принуждает процесс разбора возвращаться к уже пройденным местам. В связи с этим процесс разбора иногда меняет входные данные. Подробнее алгоритм разбора описан в спецификации HTML5.
По окончанию парсинга
Браузер запрашивает внешние ресурсы (CSS, images, JavaScript, и т.д.). На этом этапе документ становится интерактивным и начинают обрабатываться скрипты, которые выполняются по готовности документа (режим deferred). Затем статус документа устанавливается в complete и запускается событие load.
В этой статье мы возьмём простой HTML-документ и применим к нему CSS, изучая некоторые практические вещи о языке.
| Необходимые знания: | Базовая компьютерная грамотность, Базовое программное обеспечение, базовые знания работа с файлами, и базовые знания HTML (смотрите Введение в HTML.) |
|---|---|
| Задача: | Понять основы связывания CSS-документа с HTML-файлом и уметь выполнять простое форматирование текста с помощью CSS. |
Начнём с HTML
Нашей отправной точкой является HTML-документ. Вы можете скопировать код снизу, если вы хотите работать на своём компьютере. Сохраните приведённый ниже код как index.html в папке на вашем компьютере.
Примечание: Если вы читаете это на устройстве или в среде, где вы не можете легко создавать файлы, не беспокойтесь — ниже представлены редакторы кода, чтобы вы могли написать код прямо здесь, на странице.
Добавление CSS в наш документ
Самое первое, что нам нужно сделать, — это сообщить HTML-документу, что у нас есть некоторые правила CSS, которые мы хотим использовать. Существует три различных способа применения CSS к документу HTML, с которым вы обычно сталкиваетесь, однако сейчас мы рассмотрим наиболее обычный и полезный способ сделать это — связать CSS с заголовком вашего документа.
Создайте файл в той же папке, что и документ HTML, и сохраните его как styles.css . Расширение .css показывает, что это файл CSS.
Чтобы связать styles.css с index.html, добавьте следующую строку где-то внутри <head> HTML документа:
Элемент <link> сообщает браузеру, что у нас есть таблица стилей, используя атрибут rel, и местоположение этой таблицы стилей в качестве значения атрибута href. вы можете проверить, работает ли CSS, добавив правило в styles.css. Используя ваш редактор кода, добавьте следующее в ваш файл CSS:
Сохраните файлы HTML и CSS и перезагрузите страницу в веб-браузере. Заголовок первого уровня в верхней части документа теперь должен быть красным. Если это произойдёт, поздравляю — вы успешно применили CSS к документу HTML. Если этого не произойдёт, внимательно проверьте, правильно ли вы ввели всё.
Вы можете продолжить работу в styles.css локально, или вы можете использовать наш интерактивный редактор ниже, чтобы продолжить этот урок. Интерактивный редактор действует так, как если бы CSS на первой панели был связан с документом HTML, как это было в нашем документе выше.
Стилизация HTML-элементов
Делая наш заголовок красным, мы уже продемонстрировали, что можем нацеливать и стилизовать элемент HTML. Мы делаем это путём нацеливания на элемент selector — это селектор, который напрямую соответствует имени элемента HTML. Чтобы нацелиться на все абзацы в документе, вы должны использовать селектор p . Чтобы сделать все абзацы зелёными, вы должны использовать:
Вы можете выбрать несколько селекторов одновременно, разделив их запятыми. Если я хочу, чтобы все параграфы и все элементы списка были зелёными, моё правило выглядит так:
Попробуйте это в интерактивном редакторе ниже (отредактируйте поля кода) или в своём локальном документе CSS.
Изменение поведения элементов по умолчанию
Когда мы смотрим на хорошо размеченный HTML-документ, даже такой простой, как наш пример, мы можем увидеть, как браузер делает HTML читаемым, добавив некоторые стили по умолчанию. Заголовки большие и жирные, в нашем списке есть маркеры. Это происходит потому, что в браузерах есть внутренние таблицы стилей, содержащие стили по умолчанию, которые по умолчанию применяются ко всем страницам; без них весь текст работал бы вместе, и мы должны были бы стилизовать всё с нуля. Все современные браузеры по умолчанию отображают HTML-контент практически одинаково.
Однако вам часто захочется что-то другое, кроме выбора, сделанного браузером. Это можно сделать, просто выбрав элемент HTML, который вы хотите изменить, и используя правило CSS, чтобы изменить его внешний вид. Хорошим примером является наш <ul> — неупорядоченный список. Он добавляет маркеры, и если я решу, что я не хочу эти маркеры, я могу удалить их вот так:
Попробуйте добавить это в свой CSS сейчас.
Свойство list-style-type — это хорошее свойство, информацию о котором можно найти на MDN, чтобы увидеть, какие значения поддерживаются. Взгляните на страницу для list-style-type и вы найдёте интерактивный пример в верхней части страницы, чтобы опробовать некоторые другие значения, затем все допустимые значения будут подробно описаны ниже.
Глядя на эту страницу, вы обнаружите, что помимо удаления маркеров списка вы можете изменить их — попробуйте изменить их на квадратные маркеры, используя значение square .
Добавление класса
Пока у нас есть стилизованные элементы, основанные на их именах HTML-элементов. Это работает до тех пор, пока вы хотите, чтобы все элементы этого типа в вашем документе выглядели одинаково. В большинстве случаев это не так, и вам нужно будет найти способ выбрать подмножество элементов, не меняя остальные. Самый распространённый способ сделать это — добавить класс к вашему HTML-элементу и нацелиться на этот класс.
В своём HTML-документе добавьте Атрибут class ко второму пункту списка. Ваш список теперь будет выглядеть так:
В вашем CSS вы можете выбрать класс special к любому элементу на странице, чтобы он выглядел так же, как и этот элемент списка. Добавьте следующее в ваш файл CSS:
Сохраните и обновите, чтобы увидеть результат.
Вы можете захотеть, чтобы <span> в абзаце также был оранжевым и жирным. Попробуйте добавить класс " special" , затем перезагрузите страницу и посмотрите, что получится.
Иногда вы увидите правила с селектором, который перечисляет селектор HTML-элемента вместе с классом:
Этот синтаксис означает «предназначаться для любого элемента li, который имеет класс special». Если бы вы сделали это, вы бы больше не смогли применить класс к <span> или другому элементу, просто добавив к нему класс; вы должны добавить этот элемент в список селекторов:
Как вы можете себе представить, некоторые классы могут быть применены ко многим элементам, и вам не нужно постоянно редактировать свой CSS каждый раз, когда что-то новое должно принять этот стиль. Поэтому иногда лучше обойти элемент и просто обратиться к классу, если только вы не знаете, что хотите создать некоторые специальные правила для одного элемента и, возможно, хотите убедиться, что они не применяются к другим элементам.
Стилизация элементов на основе их расположения в документе
Есть моменты, когда вы хотите, чтобы что-то выглядело иначе, в зависимости от того, где оно находится в документе. Здесь есть несколько селекторов, которые могут вам помочь, но сейчас мы рассмотрим только пару. В нашем документе два элемента <em> — один внутри абзаца, а другой внутри элемента списка. Чтобы выбрать только <em> который вложен в элемент <li> , я могу использовать селектор под названием descendant combinator (комбинатор-потомок), который просто принимает форму пробела между двумя другими селекторами.
Добавьте следующее правило в таблицу стилей.
Этот селектор выберет любой элемент <em> , который находится внутри (потомка) <li> . Итак, в вашем примере документа вы должны найти, что <em> в третьем элементе списка теперь фиолетовый, но тот, который находится внутри абзаца, не изменился.
Ещё можно попробовать стилизовать абзац, когда он идёт сразу после заголовка на том же уровне иерархии в HTML. Для этого поместите + (соседний братский комбинатор) между селекторами.
Попробуйте также добавить это правило в таблицу стилей:
Пример ниже включает в себя два правила выше. Попробуйте добавить правило, чтобы сделать элемент span красный, если он внутри абзаца. Вы узнаете, правильно ли вы это сделали, так как промежуток в первом абзаце будет красным, но цвет в первом элементе списка не изменит цвет.
Примечание: Как вы можете видеть, CSS даёт нам несколько способов нацеливания на элементы, и мы пока только слегка изучили его! Мы будем внимательно смотреть на все эти селекторы и многое другое в нашей статье Селекторы позже в нашем курсе.
Стилизация элементов на основе состояния
Последний тип стилей, который мы рассмотрим в этом уроке, — это возможность стилизовать элементы в зависимости от их состояния. Прямым примером этого является стиль ссылок. Когда мы создаём ссылку, мы должны нацелить элемент <a> (якорь). Он имеет различные состояния в зависимости от того, посещается ли он, посещается, находится над ним, фокусируется с помощью клавиатуры или в процессе нажатия (активации). Вы можете использовать CSS для нацеливания на эти разные состояния — CSS-код ниже отображает невидимые ссылки розового цвета и посещённые ссылки зелёного цвета.
Вы можете изменить внешний вид ссылки, когда пользователь наводит на неё курсор, например, удалив подчёркивание, что достигается с помощью следующего правила:
В приведённом ниже примере вы можете поиграть с разными значениями для разных состояний ссылки. Я добавил к нему правила, приведённые выше, и теперь понимаю, что розовый цвет довольно лёгкий и трудно читаемый — почему бы не изменить его на лучший цвет? Можете ли вы сделать ссылки жирным шрифтом?
Мы удалили подчёркивание на нашей ссылке при наведении курсора. Вы можете удалить подчёркивание из всех состояний ссылки. Однако стоит помнить, что на реальном сайте вы хотите, чтобы посетители знали, что ссылка является ссылкой. Оставив подчёркивание на месте, люди могут понять, что на какой-то текст внутри абзаца можно нажимать — к такому поведению они привыкли. Как и всё в CSS, существует возможность сделать документ менее доступным с вашими изменениями — мы постараемся выделить потенциальные подводные камни в соответствующих местах.
Примечание: вы часто будете видеть упоминание о доступности в этих уроках и по всей MDN. Когда мы говорим о доступности, мы имеем в виду требование, чтобы наши веб-страницы были понятными и доступными для всех.
Ваш посетитель вполне может быть на компьютере с мышью или сенсорной панелью или на телефоне с сенсорным экраном. Либо они могут использовать программу чтения с экрана, которая считывает содержимое документа, либо им может потребоваться использовать текст значительно большего размера, либо перемещаться по сайту только с помощью клавиатуры.
Простой HTML-документ, как правило, доступен каждому — когда вы начинаете оформлять этот документ, важно, чтобы вы не сделали его менее доступным.
Сочетание селекторов и комбинаторов
Стоит отметить, что вы можете комбинировать несколько селекторов и комбинаторов вместе. Вот пример:
Вы также можете комбинировать несколько типов вместе. Попробуйте добавить следующее в ваш код:
Это будет стиль любого элемента с классом special , который находится внутри <p> , который приходит сразу после <h1> , который находится внутри <body> . Уф!
В оригинальном HTML, который мы предоставили, единственный элемент в стиле <span > .
Не беспокойтесь, если это покажется сложным — вы скоро начнёте понимать это, когда будете писать больше на CSS.
Завершение
В этом уроке мы рассмотрели несколько способов стилизации документа с использованием CSS. Мы будем развивать эти знания по мере прохождения остальных уроков. Однако вы уже знаете достаточно, чтобы стилизовать текст, применять CSS на основе различных способов нацеливания на элементы в документе и искать свойства и значения в документации MDN.
Читайте также: