
Как браузер читает html
Обновлено: 05.07.2024
Цель статьи, если я собираюсь создавать быстрые и надежные веб-сайты, мне нужно действительно понимать механику каждого шага, который браузер выполняет для отображения веб-страницы, чтобы каждый шаг был обдуман и оптимизирован во время разработки. Этот пост представляет собой краткое изложение моих знаний о процессе отображения страниц на довольно высоком уровне.
Много идей основано на фантастическом (и БЕСПЛАТНОН!) курсе по оптимизации производительности веб-сайта Website Performance Optimization Ilya Grigorik и Cameron Pittman на Udacity. Я очень рекомендую это посмотреть.
Также очень полезной оказалась статья Пола Айриша и Тали Гарсиэль How Browsers Work: Behind the scenes of modern web browsers. Хотя эта статья 2011 года, но многие основы работы браузеров остаются актуальными до сих пор.
И так, поехали. Процесс отображения страниц можно разбить на следующие основные этапы:
- Начало разбора HTML
- Получение внешних ресурсов
- Разбор CSS и создание CSSOM
- Выполнение JavaScript
- Объединение DOM и CSSOM, для построения дерево рендеринга
- Расчет макета и отрисовка результата
1. Начало разбора HTML
Когда браузер начинает получать данные HTML страницы по сети, он немедленно запускает свой синтаксический анализатор parser для преобразования HTML в объектную модель документа (DOM) Document Object Model (DOM).

2. Получение внешних ресурсов
Когда парсер встречает внешний ресурс, такой как файл CSS или JavaScript, он пытается, получить его. Синтаксический анализатор будет продолжать работу по мере загрузки файла CSS, но он заблокирует рендеринг до тех пор, пока файл не будет загружен и проанализирован (подробнее об этом чуть позже).
defer означает, что выполнение файла будет отложено до завершения синтаксического анализа документа. Если несколько файлов имеют атрибут defer, то они будут выполняться в том порядке, в котором они были обнаружены в HTML.
async означает, что файл будет выполнен, как только он загрузится, это может быть во время или после процесса синтаксического анализа, и поэтому порядок, в котором выполняются асинхронные сценарии, не может быть гарантирован.
Предварительная загрузка ресурсов

3. Разбор CSS и создание CSSOM
Возможно, вы слышали о DOM, но слышали ли вы о CSSOM (CSS Object Model) (объектной модели CSS)? До того, как я начал исследовать эту тему, я об этом ни чего не знал!
Чем CSSOM отличается от DOM, так это тем, что он не может быть построен постепенно, поскольку правила CSS могут перезаписывать друг друга в разных точках из-за specificity (порядка применения свойства). Вот почему загрузка CSS блокирует рендеринг, поскольку до тех пор, пока весь CSS не будет проанализирован и не будет построен CSSOM, браузер не может знать, где и как разместить каждый элемент на экране.

4. Выполнение JavaScript
Как и когда ресурсы JavaScript будут загружены, определяет, в какой-то момент они будут проанализированы, скомпилированы и выполнены. В разных браузерах для выполнения этой задачи используются разные механизмы JavaScript. Анализ JavaScript может быть дорогостоящим процессом с точки зрения ресурсов компьютера, в большей степени, чем другие типы ресурсов, поэтому его оптимизация так важна для достижения хорошей производительности. Прочтите этот фантастический пост, чтобы подробнее узнать, как работает движок JavaScript.
События загрузки
После того, как синхронно загруженный JavaScript и DOM будут полностью проанализированы и готовы, будет сгенерировано событие document.DOMContentLoaded. Для любых сценариев, которым требуется доступ к DOM, например, для управления им или прослушивания событий взаимодействия с пользователем, рекомендуется сначала дождаться этого события перед выполнением сценариев.
После того, как все остальное, например асинхронный JavaScript, изображения и т. д., завершили загрузку, запускается событие window.load.

5. Объединение DOM и CSSOM, для построения дерево рендеринга
Дерево рендеринга представляет собой комбинацию DOM и CSSOM и представляет все, что будет отображаться на странице. Это не обязательно означает, что все узлы в дереве рендеринга будут визуально присутствовать, например узлы со стилями opacity: 0 или visibility: hidden будут включены и могут быть прочитаны программой чтения с экрана и т. д., тогда как те, которые настроены на display: none будет исключены. Кроме того, такие теги, как <head>, не содержащие визуальной информации, всегда будут пропущены.
Как и в случае с движками JavaScript, разные браузеры имеют разные механизмы рендеринга.

6. Расчет макета и отрисовка результата
Теперь, когда у нас есть полное дерево рендеринга, браузер знает, что рендерить, но не знает, где рендерить. Следовательно, необходимо рассчитать макет страницы (то есть положение и размер каждого узла). Механизм рендеринга проходит дерево рендеринга, начиная с вершины и идя вниз, вычисляет координаты, в которых должен отображаться каждый узел.
И вуаля! В конце концов, у нас есть полностью отрисованная веб-страница!

Когда вы посещаете веб-сайт в Интернете, ваш браузер только подключается к удаленному компьютеру (веб-серверу) и запрашивает ресурсы для раскраски страницы. Это может показаться тривиальным, но под капотом ваш браузер обрабатывает миллионы чисел, чтобы найти и отобразить веб-сайт на вашем экране.
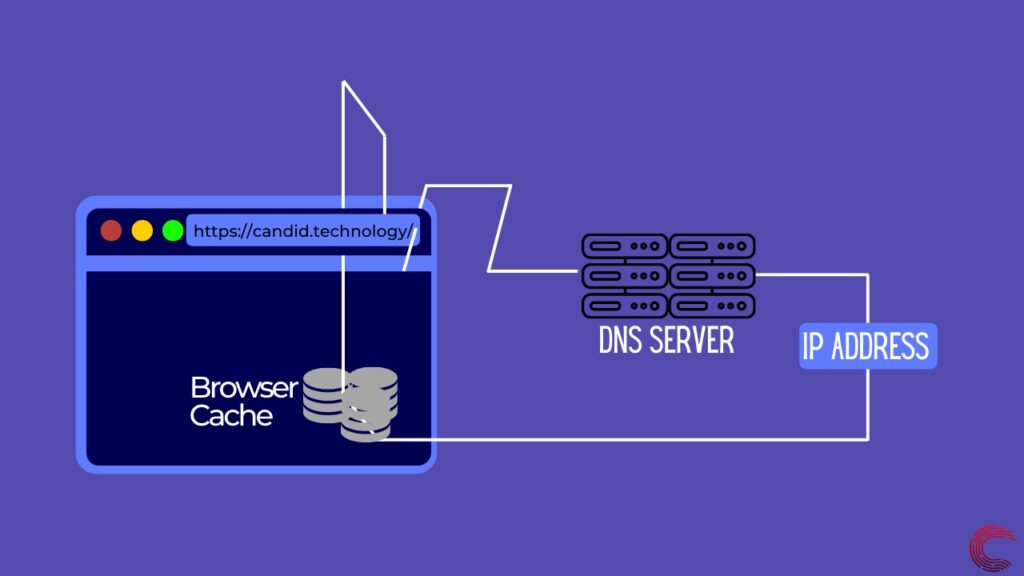
Чтобы найти IP-адрес, браузер выполняет разрешение DNS, которое можно сделать только двумя способами. Он может либо заглянуть в кеш-память вашего браузера, которая может содержать IP-адрес URL-адреса, если вы посещали сайт в прошлом. Если это не так, он запрашивает у вашего интернет-провайдера, Google или Cloudflare IP-адрес определенного веб-сайта, используя их DNS-серверы.
Как только ваш браузер получит IP-адрес веб-сайта, который вы ищете, сетевой уровень вашего браузера начнет работать. Он пытается установить соединение между вашим устройством и сервером, чтобы данные могли передаваться между двумя устройствами. Для создания этого соединения сетевой уровень использует сокеты, которые представляют собой способ соединения двух устройств в сети с использованием их IP-адреса и назначенного порта на каждом устройстве.
Чтобы зашифровать данные, сетевой уровень выполняет рукопожатие TLS между двумя взаимодействующими устройствами. После завершения рукопожатия все данные, передаваемые между устройствами, зашифровываются и не могут быть прочитаны третьими лицами.
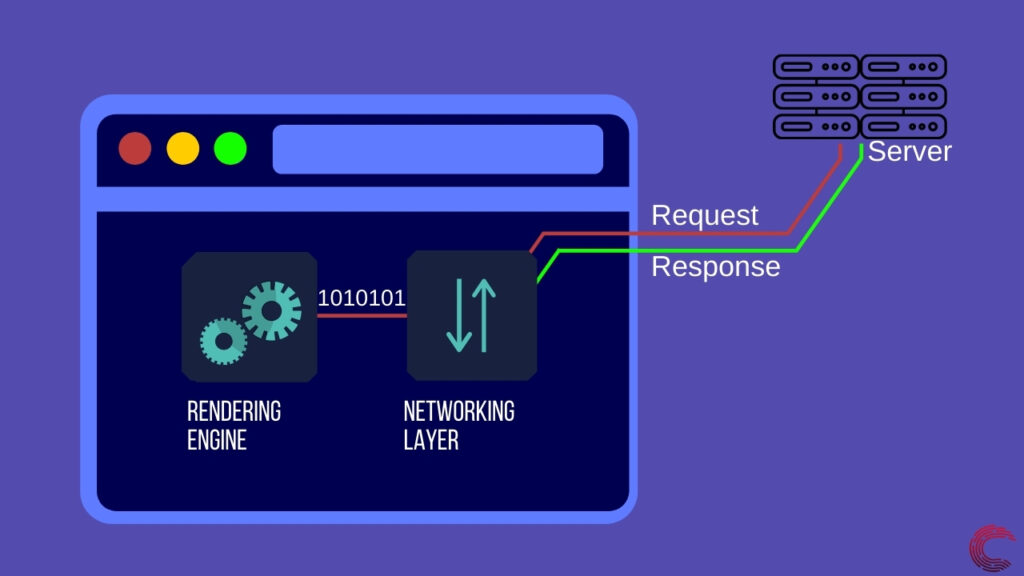
Наконец, в браузере есть ресурсы, необходимые для отображения веб-страницы, но они представлены в виде байтов и должны быть преобразованы в формат, который выглядит как веб-страница. Для этого браузер использует свой механизм рендеринга.
Теперь, когда сетевой уровень сделал запросы к веб-серверу и получил все данные, необходимые браузеру, на сцену выходит механизм визуализации.
- HTML (язык гипертекстовой разметки) используется для определения структуры веб-страницы.
- CSS (каскадные таблицы стилей) используются для указания браузеру, как должен выглядеть каждый элемент на веб-сайте.
- Javascript используется для добавления интерактивности сайту и используется для обработки пользовательского ввода, кликов или любой другой обработки, которая может понадобиться сайту.
Механизм визуализации использует синтаксические анализаторы для преобразования битов данных в значимую информацию, которая может использоваться браузером для визуализации веб-страницы. Механизм рендеринга имеет два разных парсера: один для HTML и один для CSS. Давайте посмотрим, как работает анализатор HTML, чтобы получить представление о процессе синтаксического анализа.
Разбор HTML
Анализатор HTML принимает биты данных в качестве входных данных и создает логическое представление документа HTML в памяти устройства. Это логическое представление данных известно как структура DOM и представляет данные HTML в иерархическом порядке.
Чтобы создать структуру DOM, парсер HTML выполняет несколько шагов, которые можно описать следующим образом.
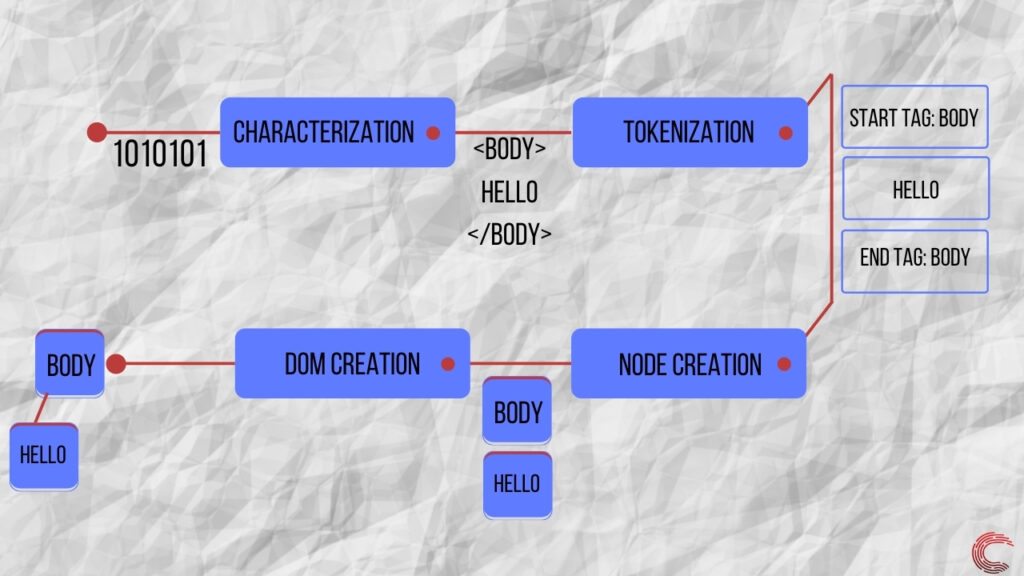
- Характеризация извлекает символы из байтов информации, которую анализатор HTML получает с сетевого уровня.
- Токенизация находит токены в потоке символов, который помогает браузеру определять структуру данных.
- Создание узла После идентификации токенов и содержащейся в них информации браузер создает узлы памяти для хранения этих данных.
- Создание DOM парсер иерархически связывает узлы памяти для создания DOM-представления полученных байтов данных.
HTML-документ, который получает браузер, содержит ссылки на файлы CSS. Эти ссылки обрабатываются сетевым уровнем и отправляются синтаксическому анализатору CSS. Этот синтаксический анализатор создает вывод CSSOM (объектная модель CSS), который определяет, как должен быть стилизован каждый элемент в DOM.
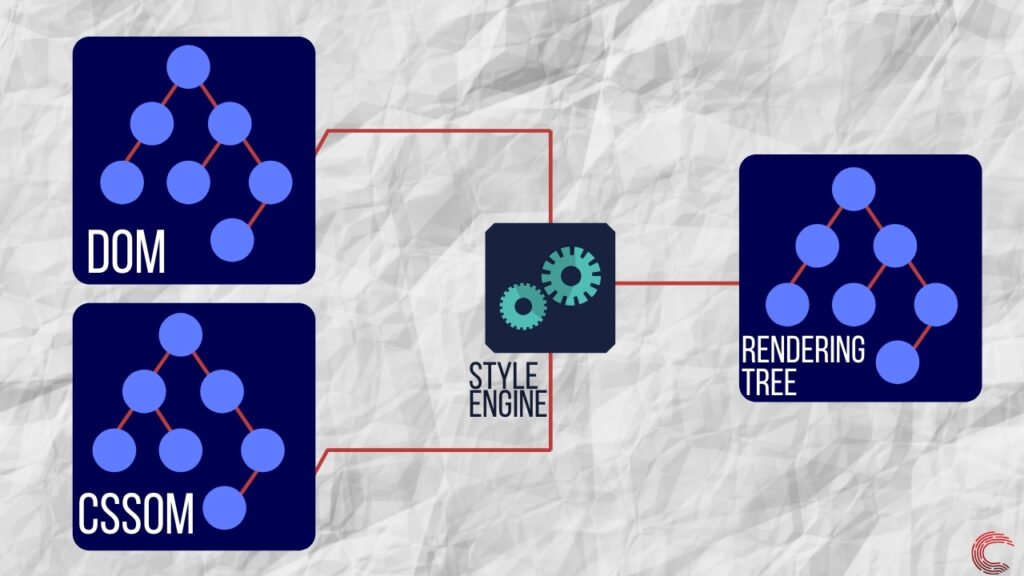
Создание дерева отрисовки и макета для веб-страницы
После создания модели DOM и завершения синтаксического анализа CSS-файла механизм визуализации использует механизм стилей для объединения как CSSOM, так и DOM. Это создает дерево визуализации, которое содержит информацию о структуре и стиле веб-страницы, которая должна отображаться. Дерево рендеринга состоит только из видимых узлов и не имеет узлов, невидимых для пользователя на экране.
После создания дерева рендеринга механизм рендеринга запускает процесс компоновки. Этот процесс учитывает разрешение экрана и то, как каждый элемент должен быть размещен на устройстве. Он также вычисляет размер каждого элемента, который будет отображаться на экране, и его относительное положение по отношению к другим элементам.
Теперь, когда движок рендеринга имеет всю информацию о веб-странице в формате, понятном нашей системе, мы можем начать рендеринг страницы в браузере.
Рисование холста и компоновка веб-страницы на экране
После того, как механизм рендеринга завершил процесс макета, ему необходимо нарисовать каждый пиксель на экране в соответствии с макетом, который был создан с использованием дерева рендеринга. Этот процесс известен как растеризация , то есть процесс рисования экрана. Большинство браузеров используют ЦП для выполнения этой задачи, но, поскольку это процесс, который включает в себя повторяющуюся обработку, для получения лучших результатов его можно передать на ГП.
Операция рисования происходит в многоуровневом формате, и механизм визуализации создает несколько слоев элементов для создания веб-страницы. Эта многоуровневая структура помогает браузеру быстрее вносить изменения, когда пользователь взаимодействует с веб-страницей.
После того, как все слои созданы, механизм визуализации отправляет эту информацию в пользовательский интерфейс, отображая веб-страницу на экране. Этот процесс известен как создание веб-страницы и является последним шагом, выполняемым механизмом рендеринга.
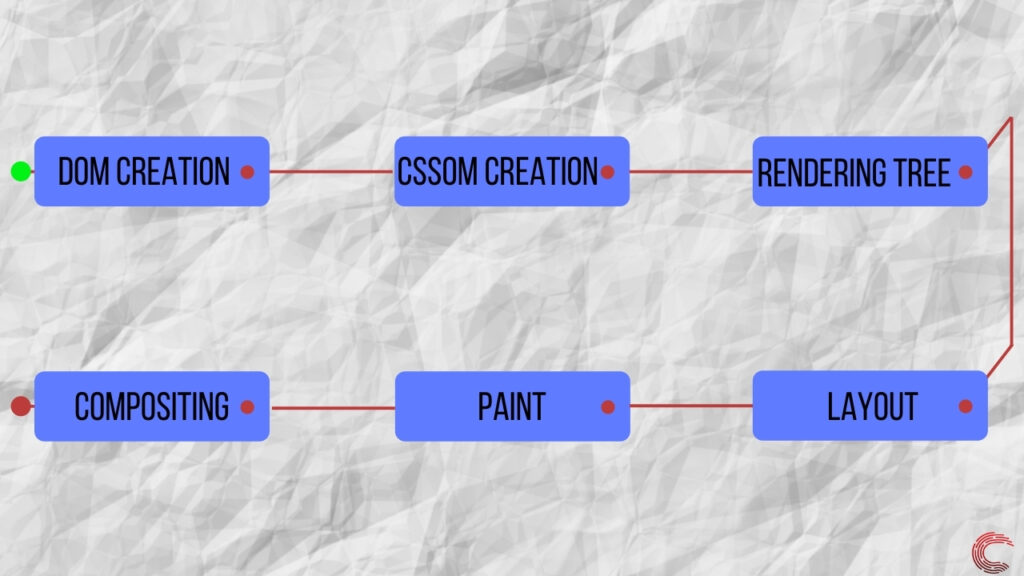
Этот процесс создания веб-страницы из битов данных известен как критический путь отрисовки и является основным фактором, определяющим производительность любой веб-страницы, которую вы посещаете в Интернете.
Теперь, когда механизм рендеринга отрисовал веб-сайт в браузере, вам может быть интересно, что мы нигде не использовали Javascript. Это связано с тем, что Javascript является независимым объектом, который отвечает за внесение изменений в структуру DOM, которая добавляет интерактивности веб-сайту.
После того, как механизм рендеринга завершил рендеринг веб-сайта в пользовательском интерфейсе, пользователь может видеть веб-сайт, но он еще не является интерактивным. Это означает, что если на веб-странице есть кнопка, которая показывает пользователю подсказку, она не будет работать, а Javascript появится на картинке.
Javascript также может вносить изменения в структуру DOM, созданную механизмом рендеринга, и даже создавать новые узлы DOM и подключать их к структуре DOM. Этот код Javascript запускается виртуальной машиной в браузере, известной как механизм Javascript.

Механизм Javascript и структура DOM не используют одну и ту же память и являются независимыми объектами. Тем не менее, движок Javascript может взаимодействовать со структурой DOM и запускаться, когда на странице происходит определенное событие. Это различие между двумя пробелами помогает браузеру отображать страницы с помощью механизма Javascript и отображать их при возникновении события.
В те дни, когда был изобретен Интернет, все браузеры отображали веб-страницы, и при этом не было задействовано много Javascript. Удаленный сервер выполнял большую часть обработки, а движок Javascript мало что делал на веб-странице. Из-за этого большой объем информации должен был передаваться между сервером и браузером, и такая архитектура подходила для Интернета, когда страницы не были такими сложными и интерактивными.
Тем не менее, современный Интернет не может работать на той же архитектуре, поскольку это сильно замедляет работу веб-сайтов. Следовательно, и браузер, и удаленный сервер должны работать симбиотически, чтобы обеспечить лучший пользовательский интерфейс. Это означает, что браузер больше не отвечает только за отображение веб-страниц, но также за обработку большого количества данных, и все это делает движок Javascript.
Javascript дебютировал в 1996 году и был создан Бренданом Эйхом всего за 10 дней. Он был частью Netscape Navigator версии 3 и был создан как язык сценариев, который можно было интерпретировать в самом браузере.
Поскольку Javascript был создан как язык, который мог обрабатываться интерпретатором в веб-браузере, он не создавал машинный код для работы на ЦП, что делало язык чрезвычайно универсальным.
Тем не менее, эта универсальная природа Javascript имела компромисс; низкая производительность. Чтобы решить эту проблему, JIT-компиляторы пришли к Javascript, что сделало их очень быстрыми. Использование JIT-компиляторов сделало Javascript настолько быстрым, что он работает на сервере, на котором размещены ваши веб-сайты.
Теперь, когда мы знакомы с ролью Javascript в работе веб-сайта, мы можем подробно разобраться в том, как работает механизм Javascript.
Как работает движок Javascript?
Точно так же, как сетевой уровень извлекает HTML и CSS в виде байтов для механизма рендеринга, он также извлекает код Javascript и передает его механизму Javascript.
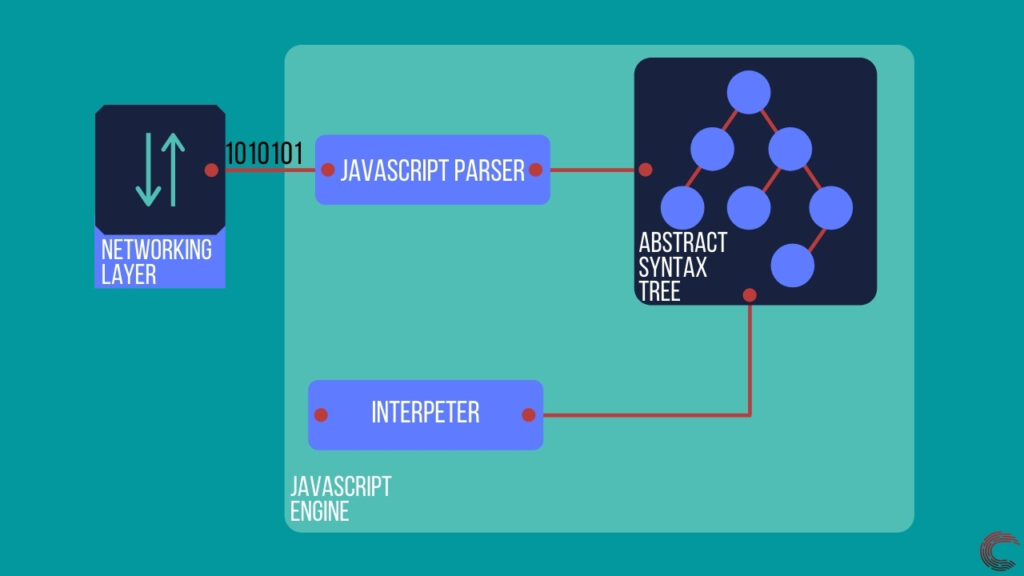
Как только движок получает код Javascript, он отправляет его синтаксическому анализатору, который создает абстрактное синтаксическое дерево (AST). Это дерево является логическим представлением кода Javascript, который может быть запущен компилятором. Компилятор преобразует дерево в промежуточный язык (байт-код), который может выполняться интерпретатором построчно.
Это выполнение Javascript используется, когда код в скрипте не выполняет повторяющиеся задачи (например, цикл). Если в коде Javascript есть обширные циклы, то движок пытается оптимизировать этот код и запускать его на ЦП устройства. Поскольку код выполняется на ЦП машины, он работает намного быстрее по сравнению с интерпретируемой версией.
Для создания машинного кода механизм Javascript использует оптимизирующий компилятор. Этот компилятор принимает байт-код, сгенерированный компилятором, и преобразует его в машинный код для конкретного устройства.
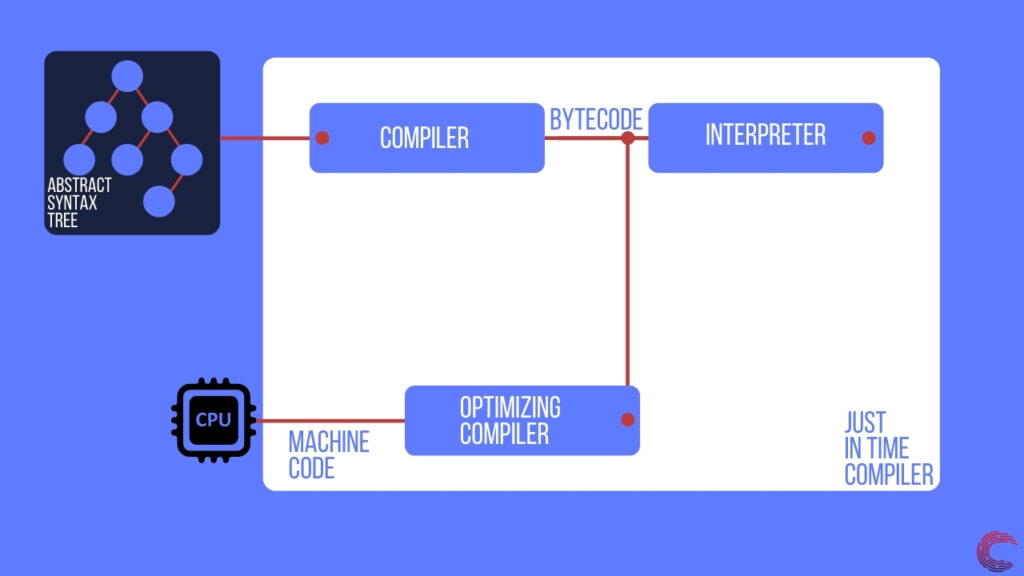
Как только у движка есть оптимизированный машинный код, он может запускать скрипт на невероятно высокой скорости, используя как процессор, так и интерпретатор Javascript.
Хотя браузеры сейчас супер мощные, постоянно появляются инновации, которые еще больше ускоряют просмотр. Одним из таких нововведений является веб-сборка, которая используется с Javascript, чтобы сделать выполнение кода еще быстрее за счет использования кода уровня сборки.
Мало того, браузеры догоняют достижения в области машинного обучения и искусственного интеллекта. С такими библиотеками, как Tensorflow, переход на Javascript означает только то, что браузеры обязательно станут умнее в будущем; дальнейшее улучшение пользовательского опыта, который они предлагают.
Рассмотрим основные компоненты браузера:

Что же происходит когда мы ищем нужный ресурс в браузере?

Модуль отображения (Rendering Engine)
Rendering Engine получает содержимое запрашиваемого документа обычно фрагментами по 8 КБ.
Сначала он проводит синтаксический анализ и парсинг HTML документа и приводит параметры в узлы для построения DOM дерева (Дерева содержания). СSS документы тоже обрабатываются и служат для построения CSSOM дерева, а так же там собирается вся информация о стилях, найдена в других источниках, например, inline стили в html. После DOM дерево и CSSOM дерево объединяются в одно, этот процесс называется Attachment, для создания Render Tree. Дерево отображения (Render Tree) состоит из объектов отображения (Render Objects). В нем элементы отображения располагаются в том порядке в котором их необходимо вывести на экран.
Из полученного Render Tree происходит компоновка (layout), в процессе которой каждому узлу дерева отображения присваиваются координаты места, где он должен появится. Затем с помощью UI Backend происходит отрисовка элементов.
Ниже представлена схема работы модуля отображения WebKit:

Синтаксический анализ HTML
DOM состоит из узлов, представляющих элементы или теги, такие как <p> или <body> , и узлы представляющие строки текста.
Рассмотрим пример как бы выглядело DOM дерево для такого html кода:

В процессе лексического анализа элементы добавляются не только в DOM, а так же и в стек открытых элементов, что позволяет исправлять неправильно вложенные или закрытые теги, тем самым, корректируя отображения ресурса пользователю.
Порядок обработки CSS & JS
Обработка CSS
В результате синтаксического анализа CSS будет построено дерево на основе всех найденных стилей, рассмотрим маленький пример:
В следствии обработки такого css будет построено CSSOM дерево:

Обработка Javascript
Javascript код выполняется сразу как был обнаружен на странице тег <script> , при этом синтаксический анализ документа останавливается до выполнения скрипта. Если речь идет о внешних источниках, которые нужно загрузить, синтаксический анализ документа точно так же ставится на паузу, но уже для загрузки и выполнения кода.
Чтобы влиять на время выполнения скрипта, можно использовать атрибуты defer или async . Они позволяют не останавливать синтаксический анализ документа для загрузки скрипта.
defer и async дают возможность выполнять загрузку скрипта асинхронно, он будет выполнен как только загрузится, а блокировки системного анализа не произойдет.
Отличием defer от async является то, что async выполнит скрипт как только он загрузился, а defer при этом сохранит порядок в котором они были подключены на страницу.
Render Tree

Компоновка (Layout)
Способ компоновки окна определяется следующими способами:
- Типом окна
- Размером окна
- Схемой позиционирования
- Внешней информацией (например размеры экрана)
Тип окна элементов отображения зависят от свойства display: block, inline, none. Блочное окно имеет собственный блок, строчное окно не имеет собственного блока и помещается внутрь контейнера,
В зависимости от свойств position и float существуют разные схемы позицинирования:
Display (Отрисовка)
На этапе отрисовки каждому объекту отображения будет вызван метод paint , в результате которого он будет отображен на экран.
Пространство, где отображается сформированная структура называется холст (canvas). В действительности он бесконечен, однако браузеры обычно определяют для него ширину исходя из размеров области просмотра.
Окна делятся на стеки, где сначала отрисовываются элементы на заднем плане, а затем на переднем. Порядок стеков определяется свойством z-index и соответствует третьей оси расположения объектов.

На собеседованиях мы часто просим кандидата рассказать настолько подробно, насколько он может, что происходит, когда вводишь в адресной строке браузера адрес сайта и нажимаешь кнопку “Ввод”. В зависимости от того, кого собеседуем — фронтендщика или бекендщика — мы ожидаем разные ответы. А как бы выглядел идеальный ответ на этот вопрос? Ниже мой вариант ответа.
Итак, пользователь вводит в адресной строке браузера адрес сайта и нажимает кнопку “Ввод”.
Браузер состоит из нескольких компонентов, одним из которых является User Interface. Адресная строка как раз является одной из частей этого компонента.
User Interface после ввода URL в адресной строке передаёт управление компоненту Browser Engine, который отвечает за взаимодействие различных компонентов браузера.
Чтобы сделать запрос по указанному URL, браузеру нужно знать IP сервера. Первым делом он смотрим в свой локальный кэш DNS.Компонент Browser Engine как раз имеет доступ к этому кэшу.
Если там нет соответствующей записи, то браузер передаёт управление операционной системе, которая проверяет свой кэш DNS. Если и там отсутствует соответствующая запись, то ОС смотрит в локальные хосты (файл /etc/hosts в Unix-системах). Если запись о хосте отсутствует, то операционная система обращается к интернет провайдеру, у которого тоже есть свой кэш DNS на своих рекурсивных серверах DNS. В случае отсутствия записи в кэше на серверах DNS провайдера, запрос идёт на корневой DNS. У корневого DNS тоже есть кэш. Если соответствующей записи в кэше корневого DNS нет, запрос идёт дальше по цепочке серверов DNS.
Если на любом из этапов находится нужная запись, то она сохраняется во всех кэшах и управление возвращается браузеру, который уже знает IP нужного сервера.
Процесс получения IP адреса называется DNS lookup.
На сервере запрос принимает веб-сервер (например, nginx или apache).
В конфигурационных файлах веб-сервера прописаны обслуживаемые хосты. Веб-сервер достаёт хост из заголовка запроса host и сопоставляет с теми, которые указаны в конфигурации. Если есть совпадение, то веб-сервер находит в конфигурационном файле правила обработки такого запроса и выполняет их. Дальнейшее поведение сервера зависит от технологии и особенностей приложения. Здесь может происходить работа с базами данных, кэшами, запросы к другим серверам и сервисам, выполнение различных скриптов. Для простоты представим, что приложение сгенерировало файл HTML, и веб-сервер отдал его браузеру.
Заголовки ответа сервера можно увидеть в Chrome DevTools на вкладке Networking, выбрав нужный запрос
Если длина контента больше нуля и тип контента поддерживается браузером, то браузер пытается его обработать. В нашем случае браузер получает файл HTML с соответствующим заголовком Content-Type. Браузер начинает разбор (parsing) этого файла с первой инструкции, которой является инструкция <!DOCTYPE>. DOCTYPE указывает на версию HTML, чтобы браузер понимал, каким правилам следовать во время разбора (какие теги как обрабатывать).
Если DOCTYPE отсутствует, то браузер переключится в режим quirks mode и попытается разобрать документ HTML, однако многие элементы будут проигнорированы. Если указан корректный DOCTYPE, то браузер будет работать в standards mode и будет разбирать документ в соответствии с правилами той версии, которая указана в DOCTYPE.
Rendering Engine начинает разбор документа HTML.
Создаётся DOM (Document Object Model). В браузере этот объект доступен по ссылке, которая хранится в переменной document. У документа есть несколько состояний. Первое состояние — loading. Оно означает, что документ только начал формироваться.
Состояние документа хранится в переменной document.readyState.
Также создаётся объект styleSheets, который будет хранить все стили.
Все стили на странице доступны по ссылке, которая хранится в переменной document.styleSheets.
Любой файл — это набор байтов. Браузер берёт полученный набор байтов и преобразует их в символы по таблице символов в соответствии с кодировкой, которая была передана в заголовке Content-Type. В нашем примере это кодировка UTF-8.
Следующий процесс —разбивание текста на смысловые блоки (tokenization). Так браузер распознаёт теги <html>, <head> и проч., а также понимает, какие правила к какому тегу применять (например, поддерживаемые атрибуты).
Далее токены собираются в узлы (nodes). Эти узлы и сохраняются в DOM со всеми взаимными связями.
Во время разбора, если Rendering Engine встречает ссылку на внешний ресурс, то он передаёт команду загрузить этот ресурс компоненту Networking Component. Это может быть ссылка на стили, скрипты, картинки и т.п. Networking Component ставит все ресурсы в очередь на загрузку. Каждому ресурсу Networking Component присваивает приоритет.
Приоритеты ресурсов можно посмотреть в Chrome DevTools на вкладке Networking в колонке Priority.
Так, у HTML, CSS и шрифтов самый высокий приоритет. У изображений приоритет изначально низкий, но если Rendering Engine обнаружит, что изображение попадает в поле видимости (view port) пользователя, то повысит приоритет до среднего. Приоритет скрипта зависит от положения на странице и способа загрузки. У асинхронных скриптов (async/defer) низкий приоритет. У скриптов, которые в документе перед изображениями — высокий, у тех, что после хотя бы одного изображение — средний.
По возможности браузер пытается загружать ресурсы параллельно. Однако, он не может загружать параллельно более 6 ресурсов с одного домена.
Кроме того, когда Rendering Engine отдаёт команду компоненту Networking Component на синхронную загрузку стиля или скрипта, он останавливает разбор документа.
С загрузкой стилей происходит подобный процесс преобразования из байтов в Object Model (CSSOM): байты -> символы -> токены -> узлы -> CSSOM.
Немного иначе происходит загрузка скрипта. Вместо того, чтобы вернуть управление Rendering Engine’у, Networking Component . передаёт управление JavaScript Interpreter, который преобразует байты в исполняемый код: байты -> символы -> токены -> Abstract Syntax Tree (evaluating). Далее в работу вступает компилятор, который оптимизирует AST, кэширует некоторые участки кода, компилирует его на лету (JIT compilation) в исполняемый код и исполняет (executing). Однако исполняется скрипт только, когда готова CSSOM. До тех пор скрипт стоит в очереди на исполнение.
Во многих современных браузерах во время исполнения JavaScript в отдельном потоке продолжается сканирование документа на наличие ссылок на другие ресурсы и постановка ресурсов в очередь на скачивание (Speculative parsing).
Каждый этап разбора HTML, CSS и JS можно увидеть в Chrome DevTools во вкладке Performance
Если при загрузке скрипта Rendering Engine видит у скрипта атрибут async, то он не останавливает разбор документа во время загрузки скрипта. Скрипт также станет в очередь на исполнение, дожидаясь, когда CSSOM будет готова.
Если при загрузке скрипта Rendering Engine видит у скрипта атрибут defer, то он не останавливает разбор документа во время загрузки скрипта, но когда скрипт загрузится, он станет в очередь на исполнение, которая заработает при возникновении события DOMContentLoaded. К этому моменту CSSOM будет уже готова.
Когда Rendering Engine заканчивает разбор документа, он вызывает событие DOMContentLoaded, и состояние документа меняется на interactive. При этом ресурсы (например, картинки) могут продолжать загружаться.
Когда все ресурсы загрузились, вызывается событие load, а состояние документа меняется на complete.
После того, как документ полностью разобран и сформированы DOM и CSSOM, Rendering Engine начинает построение Render Tree. В него попадут все элементы, которые нужно отрисовать. Некоторые элементы изначально могут быть невидимыми — их не нужно рисовать. Для каждого элемента, который “выпадает” из потока (например, используется position: absolute), будет создаваться отдельная ветка в Render Tree.
Во время Rendering Tree происходит сопоставление узлов из DOM и узлов CSSOM.
Свойства узла можно получить с помощью функции window.getComputedStyles(узел).
Когда Rendering Tree готов, Rendering Engine запускает процесс layout. Он заключается в вычислении размеров и позиций каждого элемента на странице.
Следующий этап — paint. Rendering Engine вычисляет цвет каждого пикселя.
И, наконец, последний этап — composite. Компонент UI Backend слой за слоем отрисовывает элементы на странице. При этом, если требуется отрисовать изображение, которое ещё не загрузилось, во время процесса layout, Rendering Engine зарезервирует место для изображения, если у него указаны ширина и высота. Rendering Engine вынесет на отдельный слой те элементы, стили которых содержат правила opacity, transform или will-change. Более того, эти слои Rendering Engine передаст для обработки GPU.
Если требуется отобразить текст, для которого используется нестандартный шрифт, то современные браузеры скроют текст до момента загрузки шрифта (flash of invisible text).
В современных браузерах скачивание документа, его разбор и отрисовка происходят по кускам, частями.
В документе HTML могут присутствовать некоторые мета-теги, которые могут менять порядок загрузки ресурсов, а также их приоритет.
К примеру, мета-тег dns-prefetch вынуждает Rendering Engine обратиться к Networking Component и получить IP нужного домена ещё до того, как Rendering Engine встретить его в документе.
Мета-тег prefetch вынудит Networking Component поставить указанный ресурс в очередь на загрузку с низким приоритетом.
Мета-тег preload вынудит Networking Component поставить указанный ресурс в очередь на загрузку с высоким приоритетом.
Мета-тег preconnect вынудит Networking Component заранее подключиться к другом хосту, то есть пройти нужные этапы: DNS lookup, redirects, hand shakes.
Читайте также: