
Как найти последнюю заполненную ячейку в excel
Обновлено: 07.07.2024
Очень часто при работе с большими таблицами возникает вопрос: как узнать последнюю заполненную ячейку в столбце? Обычно это необходимо для того, чтобы суммировать или вычислять среднее только в пределах заданной таблицы, без учета пустых строк, т.к. в случае с вычислением среднего пустые строки могут повлиять на расчеты. По сути способов не так много. Я в этой статье покажу два варианта: в первом формула проще для понимания, но менее универсальна в использовании - она требует точно знать данные какого типа хранятся в столбце: числа или текст, т.к. ориентируется исключительно на тип данных. Вторая формула более универсальна, но может дольше работать.
Формула ниже по сути будет отбирать только числа и вернет номер самой нижней строки, в которой расположено любое число, даже если это нуль:
=ПОИСКПОЗ(3E+307; A1:A100 )
=MATCH(3E+307,A1:A100)
А эта формула вернет номер строки с последней ячейкой, в которой записан любой текст
=ПОИСКПОЗ("яяя"; A1:A100 )
=MATCH("яяя",A1:A100)
Принцип работы этих формул основан на последнем аргументе функции ПОИСКПОЗ - интервальный просмотр. Если его не указывать, то принимается значения по умолчанию для этого аргумента. По умолчанию он равен 1 , что означает искать наибольшее значение, которое меньше или равно искомому . Для "правильной" работы с этим параметром справка Excel рекомендует отсортировать по возрастанию массив значений, в которых осуществляется поиск искомого значения. Но в нашем случае сортировка как раз не нужна. Происходит следующее: в случае с числом мы задает максимально возможное число (3E+307) , которого заведомо в искомых значениях быть не может. ПОИСКПОЗ сверяет каждое значение с этим числом. Определяет, что значение в массиве меньше искомого(но не равно ему!) и запоминает его позицию. Но т.к. ПОИСКПОЗ стремится найти самый подходящий вариант - то просматривает значения дальше, предполагая, что массив отсортирован по возрастанию и дальше пойдут значения ЕЩЕ БОЛЬШЕ предыдущего и там возможно есть значение, равное искомому. Но наш массив не отсортирован и значения там расположены абы как. Да и значения там все меньше указанного. В результате ПОИСКПОЗ доходит до последнего числа в указанном массиве и возвращает именно его позицию, т.к. дальше искать нечего и ПОИСКПОЗ считает, что это максимально подходящее число. Опять же потому, что считает, что значения у нас отсортированы.
Тоже самое и с текстом, только тут мы задаем текст "яяя", который в бинарной сетке будет в самом низу, т.к. буква "я" имеет самый большой числовой код. А три этих буквы подряд дают по сути "самый большой текст".
Но чаще всего как раз заранее неизвестно, какие именно данные будут в ячейках: текстовые или числовые. Т.е. по факту в столбце могут быть абсолютно любые данные. В таких случаях можно применить один из следующих вариантов формулы:
- =МАКС(ПОИСКПОЗ(; A1:A100 ))
=MAX(MATCH(,A1:A100)) - =ПРОСМОТР(2;1/( A1:A100 <>"");СТРОКА( A1:A100 ))
=LOOKUP(2,1/(A1:A100<>""),ROW(A1:A100))
Вторая формула вводится в ячейку обычным методом и вроде как не имеет никаких подводных камней. Кроме одного: не стоит указывать в качестве диапазона ВЕСЬ СТОЛБЕЦ с данными - формула может очень долго пересчитываться. Особенно это сказывается в файлах версии 2007 Excel, где строк больше миллиона. Предыдущие формулы лишены этого недостатка. Хотя я в любом случае советовал бы указывать явно диапазон "с запасом".
Принцип её работы похож на ПОИСКПОЗ с небольшими дополнениями:
Таким образом ПРОСМОТР всегда будет нам возвращать позицию последней заполненной ячейки. Последний аргумент функции ПРОСМОТР - массив, равный по размеру просматриваемому( A1:A100 ), из которого будет возвращено значение. Мы задаем в качестве этого массива значений для возврата массив номеров строк: СТРОКА( A1:A100 ) . Т.е. если в массиве A1:A100 последнее значение будет в ячейке A9 , то ПРОСМОТР вернет значение для СТРОКА( A9 ) .
Как видно, недостатки есть в любой из приведенных формул, так что выбор в любом случае за Вами и зависеть он будет напрямую от поставленной задачи.
Вот один из примеров, как можно применить определение последней ячейки в реальных формулах. Например, вычисление среднего значения:
=СРЗНАЧ( A2 :ИНДЕКС( A1:A100 ;ПОИСКПОЗ(9E+307; A1:A100 )))
Числовые данные начинаются с ячейки A2 . В A1 заголовок, а где заканчиваются данные неизвестно - они постоянно изменяются: удаляются, дополняются.
В данном случае мы первой ячейкой указываем A2 - начало числовых данных. А вот далее уже идет вычисление последней ячейки:
ПОИСКПОЗ(9E+307; A1:A100 )
В данном случае можно применить поиск последней ячейки именно с числом, т.к. СРЗНАЧ (AVERAGE) в любом случае игнорирует текст и лишние ячейки нам ни к чему. ПОИСКПОЗ (MATCH) возвращает номер последней ячейки в диапазоне A1:A100 . Но чтобы получить именно ссылку на эту ячейку, а не просто её строку мы используем ИНДЕКС (INDEX) :
ИНДЕКС( A1:A100 ;ПОИСКПОЗ(9E+307; A1:A100 ))
Т.е. по шагам формулу можно представить так:
=СРЗНАЧ( A2 :ИНДЕКС( A1:A100 ;ПОИСКПОЗ(9E+307; A1:A100 ))) =>
=СРЗНАЧ( A2 :ИНДЕКС( A1:A100 ;9)) =>
=СРЗНАЧ( A2 : A9 ) =>
4,5
В приложенном к теме примере записаны все приведенные формулы, а так же пара примеров того, как эти формулы можно использовать в других формулах для определения конца диапазона.
Рассмотрим диапазон значений, в который регулярно заносятся новые данные.

Диапазон без пропусков и начиная с первой строки
В случае, если в столбце значения вводятся, начиная с первой строки и без пропусков, то определить номер строки последней заполненной ячейки можно формулой: =СЧЁТЗ(A:A))
Формула работает для числовых и текстовых диапазонов (см. Файл примера )
Значение из последней заполненной ячейки в столбце выведем с помощью функции ИНДЕКС() : =ИНДЕКС(A:A;СЧЁТЗ(A:A))
Ссылки на целые столбцы и строки достаточно ресурсоемки и могут замедлить пересчет листа. Если есть уверенность, что при вводе значений пользователь не выйдет за границы определенного диапазона, то лучше указать ссылку на диапазон, а не на столбец. В этом случае формула будет выглядеть так: =ИНДЕКС(A1:A20;СЧЁТЗ(A1:A20))
Диапазон без пропусков в любом месте листа
Если список, в который вводятся значения расположен в диапазоне E8:E30 (т.е. не начинается с первой строки), то формулу для определения номера строки последней заполненной ячейки можно записать следующим образом: =СЧЁТЗ(E9:E30)+СТРОКА(E8)
Формула СТРОКА(E8) возвращает номер строки заголовка списка. Значение из последней заполненной ячейки списка выведем с помощью функции ИНДЕКС() : =ИНДЕКС(E9:E30;СЧЁТЗ(E9:E30))

Диапазон с пропусками (числа)
В случае наличия пропусков (пустых строк) в столбце, функция СЧЕТЗ() будет возвращать неправильный (уменьшенный) номер строки: оно и понятно, ведь эта функция подсчитывает только значения и не учитывает пустые ячейки.
Если диапазон заполняется числовыми значениями, то для определения номера строки последней заполненной ячейки можно использовать формулу =ПОИСКПОЗ(1E+306;A:A;1) . Пустые ячейки и текстовые значения игнорируются.
Так как в качестве просматриваемого массива указан целый столбец ( A:A ), то функция ПОИСКПОЗ() вернет номер последней заполненной строки. Функция ПОИСКПОЗ() (с третьим параметром =1) находит позицию наибольшего значения, которое меньше или равно значению первого аргумента (1E+306). Правда, для этого требуется, чтобы массив был отсортирован по возрастанию. Если он не отсортирован, то эта функция возвращает позицию последней заполненной строки столбца, т.е. то, что нам нужно.

Чтобы вернуть значение в последней заполненной ячейке списка, расположенного в диапазоне A2:A20 , можно использовать формулу: =ИНДЕКС(A2:A20;ПОИСКПОЗ(1E+306;A2:A20;1))
Диапазон с пропусками (текст)
В случае необходимости определения номера строки последнего текстового значения (также при наличии пропусков), формулу нужно переделать: =ПОИСКПОЗ("*";$A:$A;-1)
Пустые ячейки, числа и текстовое значение Пустой текст ("") игнорируются.
Диапазон с пропусками (текст и числа)
Если столбец содержит и текстовые и числовые значения , то для определения номера строки последней заполненной ячейки можно предложить универсальное решение: =МАКС(ЕСЛИОШИБКА(ПОИСКПОЗ("*";$A:$A;-1);0); ЕСЛИОШИБКА(ПОИСКПОЗ(1E+306;$A:$A;1);0))
Функция ЕСЛИОШИБКА() нужна для подавления ошибки возникающей, если столбец A содержит только текстовые или только числовые значения.
Другим универсальным решением является формула массива : =МАКС(СТРОКА(A1:A20)*(A1:A20<>""))
После ввода формулы массива нужно нажать CTRL + SHIFT + ENTER . Предполагается, что значения вводятся в диапазон A1:A20 . Лучше задать фиксированный диапазон для поиска, т.к. использование в формулах массива ссылок на целые строки или столбцы является достаточно ресурсоемкой задачей.
Значение из последней заполненной ячейки, в этом случае, выведем с помощью функции ДВССЫЛ() : =ДВССЫЛ("A"&МАКС(СТРОКА(A1:A20)*(A1:A20<>"")))
Как обычно, после ввода формулы массива нужно нажать CTRL + SHIFT + ENTER вместо ENTER .
СОВЕТ: Как видно, наличие пропусков в диапазоне существенно усложняет подсчет. Поэтому имеет смысл при заполнении и проектировании таблиц придерживаться правил приведенных в статье Советы по построению таблиц .
= Мир MS Excel/Статьи об Excel
| Приёмы работы с книгами, листами, диапазонами, ячейками [6] |
| Приёмы работы с формулами [13] |
| Настройки Excel [3] |
| Инструменты Excel [4] |
| Интеграция Excel с другими приложениями [4] |
| Форматирование [1] |
| Выпадающие списки [2] |
| Примечания [1] |
| Сводные таблицы [1] |
| Гиперссылки [1] |
| Excel и интернет [1] |
| Excel для Windows и Excel для Mac OS [2] |
Если Вам необходимо в таблицах, которые имеют неодинаковое количество ячеек в строках и/или столбцах, например таких:
находить последние заполненные ячейки и извлекать из них значения, то в Excel Вы, к сожалению, не найдёте функции типа ВЕРНУТЬ.ПОСЛЕДНЮЮ.ЯЧЕЙКУ()
Вот как это сделать имеющейся в стандартном наборе функций функцией ПРОСМОТР().
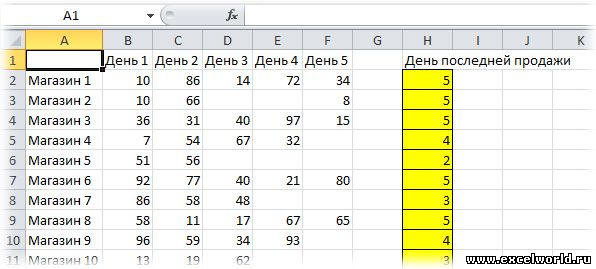
1. Для текстовых значений:
В английской версии:
Как это работает: Функция ПРОСМОТР() ищет сверху вниз в указанном столбце текст "яяя" и не найдя его, останавливается на последней ячейке в которой есть хоть какой-то текст. Так как мы не указали третий аргумент этой функции "Вектор_результатов", то функция возвращает значение из второго аргумента "Вектор_просмотра".
Пояснение: Почему именно "яяя"? Во-первых, потому что функция сравнивает при поиске текст посимвольно, а символ "я" в русском языке последний и все предыдущие при сравнении отбрасываются, во-вторых, потому что в русском языке нет такого слова.
Примечание: Вообще-то достаточно использовать и "яя", но тогда возникает мизерная возможность попасть на таблицу, в которой будет такое слово. Так называются город и река в Кемеровской области. В детстве я был в этом городе и даже купался в этой реке :)
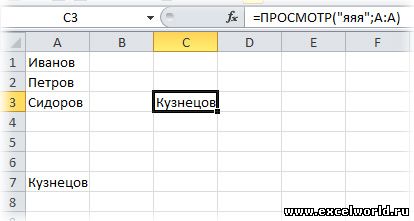
2. Для числовых значений:
В английской версии:
Как это работает: Функция ПРОСМОТР() ищет слева направо в указанной строке число "9E+307" и не найдя его, останавливается на последней ячейке в которой есть хоть какое-то число. Так как мы не указали третий аргумент этой функции "Вектор_результатов", то функция возвращает значение из второго аргумента "Вектор_просмотра".
Пояснение: Почему именно "9E+307"? Потому что это максимально возможное число в Excel. Поэтому функция найти его может только в каком-то невероятном случае, в реальной жизни пользователь такими числами просто не оперирует.
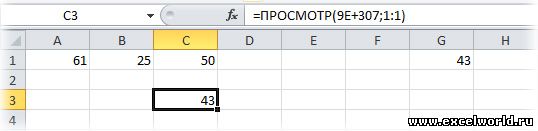
3. Для смешанных (текстово-числовых) значений:
В английской версии:
Как это работает: Функция ПРОСМОТР() ищет слева направо в указанной строке число "1" и найдя его, останавливается на последней ячейке в которой есть это число. Так как мы указали третий аргумент этой функции "Вектор_результатов", то функция возвращает значение из него, соответствующее позиции последнего вхождения искомого в просматриваемый массив.
Пояснение: Почему именно "1"? Да просто так :) С таким же успехом можно использовать число 2 или 3 или 100500, например. Главное что бы первый аргумент функции был не менее делимого в выражении 1/Диапазон. Вот пример применения другого числа в первом аргументе, при делимом отличном от единицы:
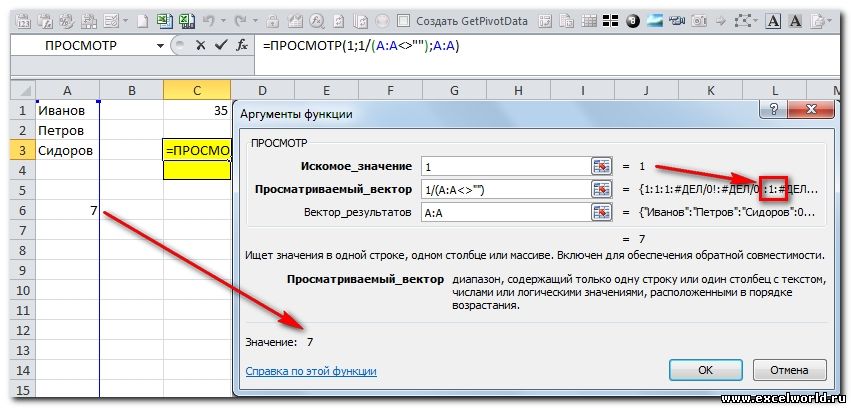
На практике часто возникает необходимость быстро найти значение последней (крайней) непустой ячейки в строке или столбце таблицы. Предположим, для примера, что у нас есть вот такая таблица с данными продаж по нескольким филиалам:

Задача: найти значение продаж в последнем месяце по каждому филиалу, т.е. для Москвы это будет 78, для Питера - 41 и т.д.
Если бы в нашей таблице не было пустых ячеек, то путь к решению был бы очевиден - можно было бы посчитать количество заполненных ячеек в каждой строке и брать потом ячейку с этим номером. Но филиалы работают неравномерно: Москва простаивала в марте и августе, филиал в Тюмени открылся только с апреля и т.д., поэтому такой способ не подойдет.
Универсальным решением будет использование функции ПРОСМОТР (LOOKUP) :

У этой функции хитрая логика:
- Она по очереди (слева-направо) перебирает непустые ячейки в диапазоне (B2:M2) и сравнивает каждую из них с искомым значением (9999999).
- Если значение очередной проверяемой ячейки совпало с искомым, то функция останавливает просмотр и выводит содержимое ячейки.
- Если точного совпадения нет и очередное значение меньше искомого, то функция переходит к следующей ячейке в строке.
Легко сообразить, что если в качестве искомого значения задать достаточно большое число, то функция пройдет по всей строке и, в итоге, выдаст содержимое последней проверенной ячейки. Для компактности, можно указать искомое число в экспоненциальном формате, например 1E+11 (1*10 11 или сто миллиардов).
Если в таблице не числа, а текст, то идея остается той же, но "очень большое число" нужно заменить на "очень большой текст":

Применительно к тексту, понятие "большой" означает код символа. В любом шрифте символы идут в следующем порядке возрастания кодов:
- латиница прописные (A-Z)
- латиница строчные (a-z)
- кириллица прописные (А-Я)
- кириллица строчные (а-я)
Поэтому строчная "я" оказывается буквой с наибольшим кодом и слово из нескольких подряд "яяяяя" будет, условно, "очень большим словом" - заведомо "большим", чем любое текстовое значение из нашей таблицы.
Вот так. Не совсем очевидное, но красивое и компактное решение. Для поиска последней непустой ячейки в столбцах работает тоже "на ура".
Читайте также: