
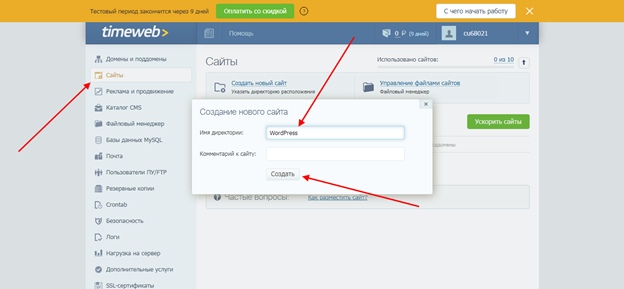
Как найти веб страницу с помощью браузера зная ее адрес
Обновлено: 07.07.2024
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.

Английская аббревиатура URL расшифровывается как Uniform Resource Locator, что в переводе на русский означает «унифицированный указатель ресурса». Впервые URL стал применяться в 1990 году. Слава его изобретения принадлежит создателю Всемирной паутины — Тиму Бернерсу-Ли.
Что такое URL

Определить URL-адрес веб-страницы просто — он показан в адресной строке браузера. Оттуда его можно скопировать, кликнув по адресной строке правой кнопкой мыши (при этом адрес выделяется) и в контекстном меню выбрав команду «Копировать».
Чтобы скопировать адрес отдельного изображения на странице, нужно кликнуть правой кнопкой мыши по картинке и выбрать пункт «Копировать адрес изображения» или «Копировать URL картинки» (в разных браузерах название команды может отличаться).
Для копирования адреса документа в контекстном меню ведущей к нему ссылки следует выбрать команду «Копировать адрес ссылки».
Структура URL адреса
URL-адрес, который мы видим в адресной строке браузера, состоит из нескольких частей:
Затем указывается путь к странице (3), состоящий из каталогов и подкаталогов, который, в свою очередь, включает в себя ее название.
URL также может включать параметры, которые указываются после знака «?» и разделяются символом «&». Пример адреса страницы с результатами поиска по слову «url» в поисковой системе Google:
Виды URL
URL-адреса веб-страниц бывают статические и динамические.
С точки зрения SEO предпочтительнее статические ссылки, так как динамические URL имеют ряд недостатков:
- они бывают очень длинными, настолько, что могут не помещаться в строке поиска и обрезаться при копировании.
- динамические адреса сложно запоминаются и не дают пользователю понимания, какое содержимое отобразится на странице при переходе по ссылке;
- CTR (click-through rate — показатель кликабельности) у них ниже, чем у статических;
- в динамических URL не учитываются ключевые слова.
Форматы URL
Транслитерация
Для обозначения названий статей обычно используют транслитерацию. Такие адреса легко читаются и понятны для восприятия пользователей.
По такому адресу сразу можно судить, какое содержимое вы увидите на странице. Поисковые системы легко распознают в подобных адресах ключевые слова, что также оказывает положительное влияние на SEO. Если в URL используется транслитерация, становится четко видна структура сайта и, чтобы попасть в нужный раздел, пользователь просто может стереть в адресной строке часть адреса.
Латиница
Латинские URL представляют собой адреса, переведенные на английский язык. Например, вместо «/novosti/» в адресе будет значиться «/news/».
Такой формат УРЛ часто используется для обозначения веб-страниц категорий и рубрик. Этот вариант считается универсальным, так как легко воспринимается пользователями и без труда обрабатывается поисковыми роботами.
Кириллические URL
Такой формат URL чаще всего применяют в кириллических доменах или когда часть адреса не очень длинная.
К их преимуществам относятся:
- удобство и простота запоминания;
- достаточное количество свободных доменов из-за невысокой популярности кириллицы;
- возможность использования ключевых слов в УРЛ.
Это объясняется тем, что запись URL-адресов возможна только определенными символами из разрешенного набора, а символы кириллицы в него не входят. Поэтому адрес, в котором используется кириллица, шифруется, хотя при этом ссылка все равно будет работать.
К минусам кириллических УРЛов можно отнести и трудность для восприятия зарубежными пользователями, привыкшими к латинским символам, а также сложности при чтении адресов этого формата поисковыми роботами (такие URL приходится переводить в понятный для робота вид).
Человекопонятные URL
Кроме того, что они позволяют понять содержание веб-страницы еще до перехода по ссылке, подобные адреса имеют и другие преимущества:
При формировании ЧПУ на своем сайте следует придерживаться определенных правил:
- использовать транслитерацию в соответствии с приведенной ниже таблицей (с одним исключением — «ый» — транслитерируется как «iy»).

- пробелы, а также знаки препинания менять на дефис или нижнее подчеркивание, а два таких символа подряд заменять на один;
- удалять символ «-» в начале или в конце адреса;
- не использовать заглавные буквы, так как УРЛы чувствительны к регистру;
- стараться формировать короткие URL.
Рекомендации по созданию URL
- Правильно сформированный URL должен включать в себя ключевые слова, так как поисковые системы учитывают этот фактор при ранжировании. Однако не стоит злоупотреблять ими в УРЛ, чтобы поисковик не посчитал, что вы применяете спамные методы продвижения.
- Следует создавать максимально короткий URL, желательно не более 4-5 слов, а общая длина адреса не должна быть более 80 символов. Длинные ссылки не показываются в поисковой выдаче, адрес может обрезаться на середине.
- Чем дальше подраздел сайта или веб-страница находится от главной, тем длиннее будет URL конечной страницы. Поэтому иногда необходимо убирать из URL упоминания о категориях и рубриках.
- Латинские символы в URL более предпочтительны, чем символы кириллицы, так как такие сайты легче продвигать.
- Рекомендуется разделять слова в адресе веб-страницы символом дефиса «-», а не нижнего подчеркивания «_».
- Если вы хотите изменить адреса страниц, чтобы избежать их дублирования, вам обязательно нужно настроить 301 редирект.
Соблюдайте указанные выше рекомендации, формируйте человекопонятные URL, чтобы при прочих равных условиях получить преимущество над другими сайтами.


Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
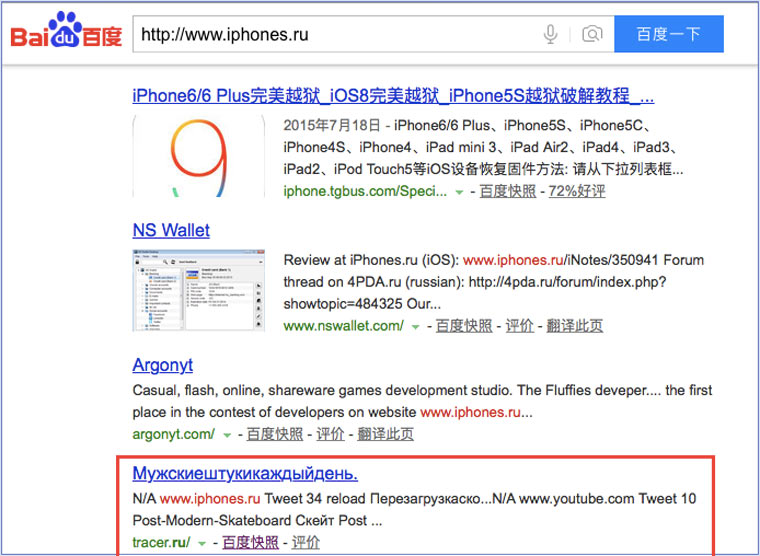
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
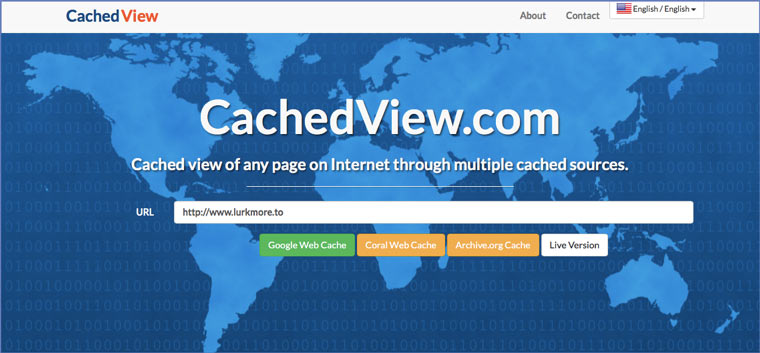
6. Archive.is, для собственного кэша
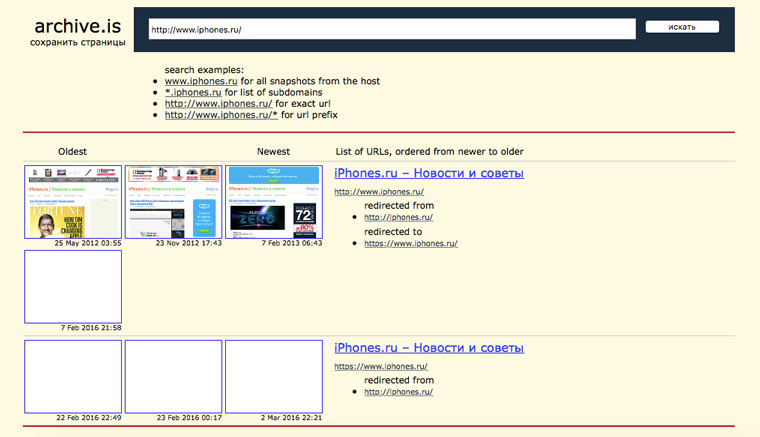
7. Кэши других поисковиков, мало ли
8. Кэш браузера, когда ничего не помогает
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
(25 голосов, общий рейтинг: 4.80 из 5)
Вы когда-нибудь были разочарованы результатами веб-поиска? Конечно, мы все были там! Однако, для более эффективного поиска в интернете существует несколько базовых навыков, которые необходимо изучить, чтобы сделать поиск более успешным.
Будьте конкретнее
Чем более конкретнее будет поисковый запрос с самого начала, тем более успешным будет поиск. Например, если вы ищете «кофе», вы получите гораздо больше результатов, чем вам нужно; однако, если вы сузите его до фразы естественного языка «жареный кофе арабика в Самаре», вы добьетесь большего успеха.
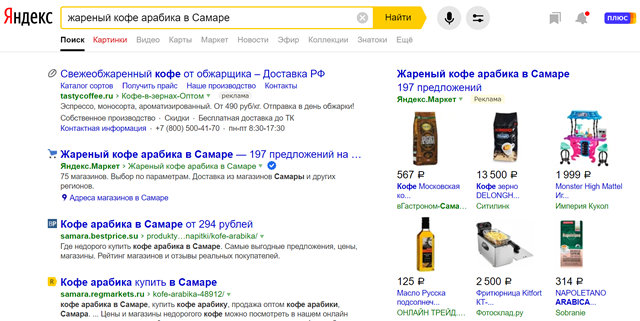
Естественный язык – это способ, которым вы говорите в обычной жизни, хотя вы можете не говорить «жареный кофе арабика в Самаре, когда говорите о кофе, но если вы будете использовать эту конкретную фразу при поиске кофе, сваренного в Самаре, то быстрее найдёте то, что ищете.
Используйте кавычки, чтобы найти конкретную фразу
Вероятно, одна из вещей номер один, которую вы можете сделать, чтобы сэкономить время при веб-поиске, – заключение поисковой фразы в кавычки.
Когда вы используете кавычки вокруг фразы, вы предлагаете поисковой системе возвращать только те страницы, которые содержат указанный поисковый запрос в том виде, как вы его ввели. Этот совет работает почти в каждой поисковой системе и очень успешен в поиске сфокусированных результатов.
Если вы ищете точную фразу, поместите её в кавычки. В противном случае вы получите огромного количеством бесполезных результатов.
Например, если вы ищете "кошки с длинной шерстью" , ваш поиск вернёт результаты с этими словами, расположенными рядом друг с другом и в том порядке, в котором вы их хотели, а не разбросанными по странице сайта.
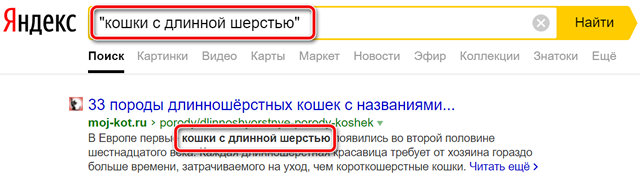
Если вы используете поисковую фразу без кавычек, некоторые из возвращенных результатов поиска будут содержать не все три слова, или слова могут быть в разных порядках и совсем не находиться рядом друг с другом. Таким образом, страница, которая говорит о длинноволосой блондинке, которая ненавидит кошек, может оказаться в результатах.
Поиск на любом сайте
Если вы когда-либо пытались использовать собственный инструмент поиска веб-сайта, чтобы найти что-то, и не добились успеха, вы определенно не одиноки! Однако, вы можете использовать глобальную поисковую систему для поиска по любому сайту, и, поскольку большинство инструментов поиска по сайту не так хороши, это хороший способ найти то, что вы ищете, с минимальными усилиями.
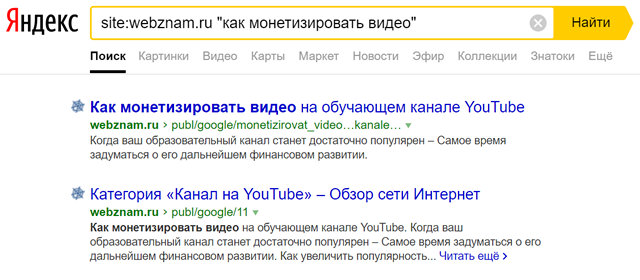
Найти слова в веб-адресе
Вы можете осуществлять поиск по веб-адресу с помощью команды inurl через Google; это позволяет вам искать слова в URL.
Это просто ещё один интересный способ поиска в интернете и поиска сайтов, которые вы, возможно, не нашли, просто введя слово или фразу. Например, если вы хотите найти результаты только с сайтов, в URL-адресе которых содержится слово «website», вы должны включить этот запрос в строку поиска Google: inurl: website. Результаты вашего поиска будут содержать только сайты с этим словом в URL.
Поиск в заголовках веб-страниц
Заголовки веб-страниц находятся в верхней части браузера и в результатах поиска. Вы можете ограничить свой поиск только заголовками веб-страниц с помощью команды поиска allintitle . Термин allintitle – это поисковый оператор, специфичный для Google, который возвращает результаты поиска, ограниченные поисковыми терминами, найденными в заголовках веб-страниц.
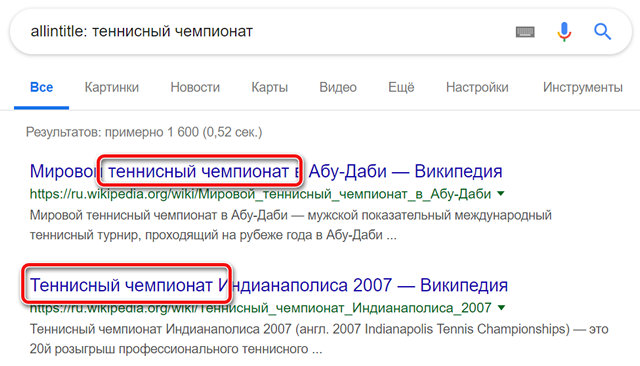
Например, если вы хотите получить результаты поиска только со словосочетанием «теннисный чемпионат», вы должны использовать этот синтаксис: allintitle: теннисный чемпионат
Это вернет результаты поиска Google со словами «теннисный чемпионат» в заголовках веб-страниц.
Просмотр кэшированной версии сайта
Если сайт или контент на странице был удалено, вы больше его не видите, верно? Это не обязательно правда. Google хранит кэшированную копию большинства сайтов. Это архивная версия веб-сайта, которая позволяет вам легко просматривать информацию или страницы, которые были удалены (по какой-либо причине).
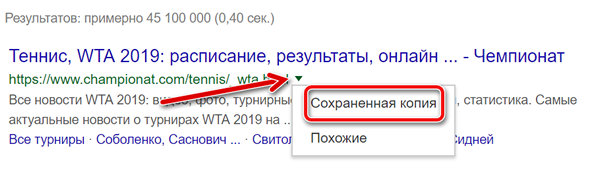
Это также удобная функция, когда веб-сайт страдает от слишком большого трафика и не отображается правильно.
Какие страницы ссылаются на определенный сайт
Если вы хотите узнать, какие сайты ссылаются на определенную страницу, вы можете узнать это, воспользовавшись оператором link: Этот оператор в сочетании с URL-адресом веб-сайта показывает, какие страницы ссылаются на этот URL-адрес.
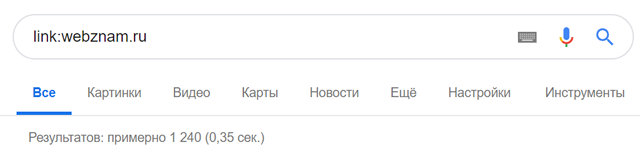
Результатом этого поиска стали 1240 страниц других сайтов, которые ссылаются на сайт WebZnam.
Поиск конкретных слов на веб-странице
Скажем, вы ищете конкретную концепцию или тему, возможно, чьё-то имя, бизнес или конкретную фразу. Вы используете свою любимую поисковую систему, нажимаете на несколько страниц и кропотливо просматриваете тонны контента, чтобы найти то, что ищете. Правильно?
Не обязательно. Вы можете использовать чрезвычайно простой трюк веб-поиска для поиска слов на веб-странице, и это будет работать в любом браузере, который вы используете.
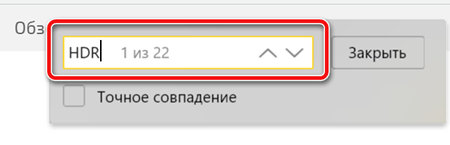
Откройте страницу сайта, нажмите Ctrl + F , а затем введите искомое слово в появившемся поле поиска. Всё просто, и вы можете использовать его в любом веб-браузере, на любом веб-сайте.
Ограничение поиска по доменам верхнего уровня
Используйте Basic Math, чтобы сузить результаты поиска
Ещё один обманчиво простой способ поиска в интернете заключается в использовании сложения и вычитания для повышения релевантности результатов поиска. Базовая математика может действительно помочь вам в поиске (ваши учителя всегда говорили вам, что когда-нибудь вы будете использовать математику в реальной жизни, верно?). Это называется булевым поиском и является одним из руководящих принципов, по которым большинство поисковых систем формируют свои результаты поиска.
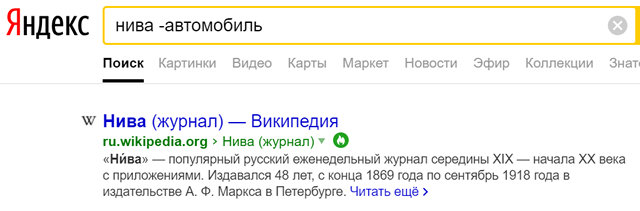
Например, вы ищете «нива», но вы получите много результатов об автомобиле марки «Нива». Чтобы решить проблему, просто объедините здесь несколько правил веб-поиска: нива -автомобиль. Теперь ваши результаты вернутся без всех этих страниц об автомобилях.
Найти конкретные форматы файлов
Поисковые системы не просто индексируют веб-страницы, написанные на HTML и других языках разметки. Вы также можете использовать их для поиска большинства популярных форматов файлов, включая файлы PDF, документы Word и электронные таблицы Excel.
Выполняйте поиск по типу файла с помощью команды filetype:(type) , заменяя (type) расширением файла, который вы хотите найти. Например, если вы хотите искать только файлы PDF, которые ссылаются на «длинношерстных кошек», ваш запрос будет выглядеть так: filetype:pdf "длинношерстных кошек".
Расширение запроса с помощью подстановочных знаков
Используйте подстановочные знаки, если хотите расширить поиск. Например, если вы ищете сайты, которые обсуждают грузовики и темы, связанные с грузовиками, не ищите просто «грузовик», а найдите грузовик*. Это вернёт страницы, которые содержат слово «грузовик», а также страницы, которые содержат «грузовик», «грузоперевозки», «форум водителей грузовиков» и так далее.
Попробуйте несколько поисковых систем
Не впадайте в рутину использования одной поисковой системы для всех ваших поисковых запросов. Каждая поисковая система возвращает разные результаты. Кроме того, существует множество поисковых систем, которые фокусируются на определенных нишах: игры, блоги, книги, форумы и т.д.

Чем внимательнее вы будете выбирать поисковую систему, тем успешнее будут ваши поиски. Проверьте этот список поисковых систем, чтобы использовать в следующий раз, когда вы что-то ищете.
У вас будет большой соблазн воспользоваться вашей любимой поисковой системы и использовать только самые известные функции; тем не менее, большинство поисковых систем имеют широкий спектр расширенных опций поиска, инструменты и сервисы, которые позволяют здорово экономить время. Всё это может сделать ваши поиски более продуктивными.
Кроме того, если вы только начинаете изучать, как искать в интернете, легко оказаться перегруженным огромным количеством информации, которая доступна вам, особенно если вы ищете что-то очень конкретное. Не сдавайтесь! Продолжайте пробовать, и не бойтесь пробовать новые поисковые системы, новые комбинации фраз, новые методы веб-поиска и т.д.
Читайте также: