
Как открыть hadoop в браузере
Обновлено: 07.07.2024
Спасибо. Но это 64-битная ОС.
Почему существует щедрость, когда пользователь нашел решение? Какой ответ ожидается? @ green7 Цель состоит в том, чтобы найти ответ, который на самом деле помечен как принятый, очень подробный и нравится. Так как, кажется, его нет, я могу понять, как Хорхе добавляет награду. @TheLordofTime Подробный ответ должен содержать не более 5 строк, поскольку вопрос слишком локализован. И если ожидается ответ, содержащий инструкции по установке Hadoop, он будет излишним, поскольку ссылка, упомянутая в этом вопросе, прекрасно его объясняет. Более того, поскольку ответ, набравший наибольшее количество голосов, был опубликован самим спрашивающим, очень маловероятно, что он / она примет любой другой ответ. @ green7 если вопрос слишком локализован, то проголосуй, чтобы закрыть его как таковой?Руководства, за которыми я следовал, когда у меня было 12.04, были:
На самом деле я был против MyLearning, потому что первым, что он порекомендовал, была Oracle Java 7 вместо OpenJDK 7, но у меня были некоторые проблемы с OpenJDK 7, когда я пробовал это, поэтому мне пришлось пойти с Oracle.
Руководство в основном прямо вперед и вот оно:
Создать пользователя Hadoop
Где hduser - это пользователь Hadoop, которого вы хотите иметь.
Чтобы убедиться, что установка SSH прошла успешно, вы можете открыть новый терминал и попытаться создать сессию ssh, используя hduser следующую команду:
переустановите ssh, если localhost не подключается (вам может потребоваться добавить hduser в sudo, как показано ниже)
Добавьте в конце строку, чтобы добавить hduser в sudoers
Для сохранения нажмите CTRL + X , введите Y и нажмите ENTER
Скопируйте следующие строки в конец файла:
Вы тоже можете сделать, sudo sysctl -p но я лучше перезагрузить.
После перезагрузки убедитесь, что IPv6 выключен:
это должно сказать 1 . Если он говорит 0 , вы что-то пропустили.
Есть несколько способов сделать это, один из которых предлагает Руководство, это загрузить его с сайта Apache Hadoop и распаковать файл в вашей hduser домашней папке. Переименуйте извлеченную папку в hadoop .
Другой способ - использовать PPA, протестированный на 12.04:
ПРИМЕЧАНИЕ: PPA может работать для некоторых, а для других - нет. Тот, который я попробовал, был загружен с официального сайта, потому что я не знал о PPA.
Вам нужно будет обновить .bashrc для hduser (и для каждого пользователя вам нужно администрировать Hadoop). Чтобы открыть .bashrc файл, вам нужно открыть его как root:
Затем вы добавите следующие конфигурации в конец .bashrc файла
Теперь, если у вас есть OpenJDK7, это будет выглядеть примерно так:
Здесь следует обратить внимание на папку, в которой находится Java с версией AMD64. Если вышеупомянутое не работает, вы можете попробовать поискать в этой конкретной папке или настроить Java, который будет использоваться с:
Теперь для некоторого полезного псевдонима:
Ниже приведены файлы конфигурации, которые мы можем использовать для правильной настройки. Вот некоторые из файлов, которые вы будете использовать с Hadoop (дополнительная информация на этом сайте ):
start-dfs.sh - Запускает демоны Hadoop DFS, наменоды и датододы. Используйте это перед start-mapred.sh
stop-dfs.sh - Останавливает демоны Hadoop DFS.
start-mapred.sh - Запускает Hadoop Map / Снижение демонов, трекеров и треккеров.
stop-mapred.sh - Останавливает карту Hadoop / Уменьшает демонов.
start-all.sh - Запускает все демоны Hadoop, namenode, датододы, трекеры и треккеры. Устаревшие; используйте start-dfs.sh, затем start-mapred.sh
stop-all.sh - Останавливает все демоны Hadoop. Устаревшие; используйте stop-mapred.sh, затем stop-dfs.sh
Но прежде чем мы начнем их использовать, нам нужно изменить несколько файлов в /conf папке.
hadoop-env.sh
Ищите файл hadoop-env.sh , нам нужно только обновить переменную JAVA_HOME в этом файле:
или в последних версиях он будет в
Затем измените следующую строку:
ядро-site.xml
Теперь нам нужно создать временный каталог для фреймворка Hadoop. Если вам нужна эта среда для тестирования или быстрого прототипа (например, разработка простых программ hadoop для вашего личного теста . ), я предлагаю создать эту папку в /home/hduser/ каталоге, в противном случае вам следует создать эту папку в общем месте в общей папке ( как / usr / local . ) но вы можете столкнуться с некоторыми проблемами безопасности. Но чтобы преодолеть исключения, которые могут быть вызваны безопасностью (например, java.io.IOException), я создал папку tmp в пространстве hduser.
Чтобы создать эту папку, введите следующую команду:
Обратите внимание, что если вы хотите сделать другого пользователя-администратора (например, hduser2 в группе hadoop), вы должны предоставить ему разрешение на чтение и запись для этой папки, используя следующие команды:
Теперь мы можем открыть hadoop/conf/core-site.xml для редактирования записи hadoop.tmp.dir. Мы можем открыть core-site.xml с помощью текстового редактора:
Затем добавьте следующие конфигурации между <configure> элементами xml :
Сейчас редактирую mapred-site.xml
Сейчас редактирую hdfs-site.xml
Теперь вы можете начать работу над узлом. Первый формат:
Вы должны отформатировать NameNode в вашей HDFS. Вы не должны делать этот шаг, когда система работает. Обычно это делается один раз при первой установке.
Запуск кластера Hadoop
Вам нужно будет перейти в каталог hadoop / bin и запустить ./start-all.sh скрипт.
Если у вас есть версия, отличная от показанной в руководствах (которая, скорее всего, будет у вас, если вы сделаете это с PPA или более новой версией), попробуйте это следующим образом:
Это запустит Namenode, Datanode, Jobtracker и Tasktracker на вашей машине.
Проверка, работает ли Hadoop
Есть хороший инструмент под названием jps . Вы можете использовать его, чтобы убедиться, что все услуги работают. В вашей папке hadoop bin введите:
Он должен показать вам все процессы, связанные с Hadoop.
ПРИМЕЧАНИЕ: Поскольку это было сделано около 6 месяцев назад для меня, если какая-либо часть не работает, дайте мне знать.
Hadoop Используя Juju (Очарование Джуджу для Hadoop)
Я предполагаю, что следующее уже установлено:
- У вас есть сервер с уже установленным Juju
- У вас есть доступ к серверу (локально или удаленно)
- Вы настроили Juju и готовы начать добавлять чары
- Вы используете 12.04 (это потому, что я проверил все это с 12.04)
- Вы уже настроили
Хорошо, теперь выполните следующие действия, чтобы запустить сервис Hadoop:
Загрузите среду для Hadoop
Подождите, пока он не закончится, затем проверьте, правильно ли он подключается:
Развернуть Hadoop (Мастер и Раб)
Expose Hadoop (поскольку вы уже развернули и создали отношения, служба должна работать)
И проверьте статус, чтобы увидеть, работает ли он правильно:
До сих пор у вас работает Hadoop. Есть еще много вещей, которые вы можете сделать, которые можно найти в приведенной ссылке или в официальном Чаржу Джуджу для Hadoop.
Чтобы ознакомиться с последними версиями JuJu Charms (настройки, пошаговое руководство и т. Д.), Посетите: JuJu Charms и создайте собственную среду JuJu и посмотрите, как настраивается каждый файл и как подключается каждая служба.
Hadoop поддерживается платформой GNU / Linux и ее разновидностями. Поэтому нам нужно установить операционную систему Linux для настройки среды Hadoop. Если у вас есть ОС, отличная от Linux, вы можете установить в нее программное обеспечение Virtualbox и установить Linux внутри Virtualbox.
Настройка перед установкой
Перед установкой Hadoop в среду Linux нам нужно настроить Linux с помощью ssh (Secure Shell). Следуйте приведенным ниже инструкциям для настройки среды Linux.
Создание пользователя
Откройте корень с помощью команды «su».
Создайте пользователя из учетной записи root с помощью команды «useradd username».
Теперь вы можете открыть существующую учетную запись пользователя с помощью команды «su username».
Откройте корень с помощью команды «su».
Создайте пользователя из учетной записи root с помощью команды «useradd username».
Теперь вы можете открыть существующую учетную запись пользователя с помощью команды «su username».
Откройте терминал Linux и введите следующие команды, чтобы создать пользователя.
Настройка SSH и генерация ключей
Настройка SSH требуется для выполнения различных операций в кластере, таких как запуск, остановка, операции распределенной оболочки демона. Для аутентификации разных пользователей Hadoop требуется предоставить пару открытого / закрытого ключа для пользователя Hadoop и поделиться ею с разными пользователями.
Следующие команды используются для генерации пары ключ-значение с использованием SSH. Скопируйте открытые ключи из формы id_rsa.pub в authorized_keys и предоставьте владельцу права на чтение и запись в файл authorized_keys соответственно.
Установка Java
Java является основной предпосылкой для Hadoop. Прежде всего, вы должны проверить существование java в вашей системе, используя команду «java -version». Синтаксис команды версии Java приведен ниже.
Если все в порядке, это даст вам следующий вывод.
Если java не установлен в вашей системе, следуйте приведенным ниже инструкциям для установки java.
Шаг 1
Затем jdk-7u71-linux-x64.tar.gz будет загружен в вашу систему.
Шаг 2
Обычно вы найдете загруженный файл Java в папке Downloads. Проверьте его и извлеките файл jdk-7u71-linux-x64.gz, используя следующие команды.
Шаг 3
Чтобы сделать Java доступным для всех пользователей, вы должны переместить его в папку «/ usr / local /». Откройте root и введите следующие команды.
Шаг 4
Для настройки переменных PATH и JAVA_HOME добавьте следующие команды в файл
Теперь примените все изменения в текущей работающей системе.
Шаг 5
Теперь проверьте команду java -version из терминала, как описано выше.
Загрузка Hadoop
Загрузите и извлеките Hadoop 2.4.1 из программного обеспечения Apache, используя следующие команды.
Режимы работы Hadoop
Загрузив Hadoop, вы можете управлять кластером Hadoop в одном из трех поддерживаемых режимов:
Установка Hadoop в автономном режиме
Здесь мы обсудим установку Hadoop 2.4.1 в автономном режиме.
Демоны не запущены, и все работает в одной виртуальной машине Java. Автономный режим подходит для запуска программ MapReduce во время разработки, поскольку их легко тестировать и отлаживать.
Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл
Если с вашими настройками все в порядке, вы должны увидеть следующий результат:
Это означает, что настройка автономного режима вашего Hadoop работает нормально. По умолчанию Hadoop настроен для работы в нераспределенном режиме на одной машине.
пример
Давайте проверим простой пример Hadoop. Установка Hadoop предоставляет следующий пример jar-файла MapReduce, который предоставляет базовые функциональные возможности MapReduce и может использоваться для вычисления, например, значения Pi, количества слов в заданном списке файлов и т. Д.
Шаг 1
Создайте временные файлы содержимого во входном каталоге. Вы можете создать этот входной каталог в любом месте, где бы вы хотели работать.
Эти файлы были скопированы из домашнего каталога установки Hadoop. Для вашего эксперимента вы можете иметь разные и большие наборы файлов.
Шаг 2
Давайте запустим процесс Hadoop, чтобы подсчитать общее количество слов во всех файлах, доступных во входном каталоге, следующим образом:
Шаг 3
Он перечислит все слова вместе с их общим количеством, доступным во всех файлах, доступных во входном каталоге.
Установка Hadoop в псевдо-распределенном режиме
Выполните шаги, указанные ниже, чтобы установить Hadoop 2.4.1 в псевдораспределенном режиме.
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл
Теперь примените все изменения в текущей работающей системе.
Вы можете найти все файлы конфигурации Hadoop в папке «$ HADOOP_HOME / etc / hadoop». Необходимо внести изменения в эти файлы конфигурации в соответствии с вашей инфраструктурой Hadoop.
Чтобы разрабатывать программы Hadoop на языке java, необходимо сбросить переменные среды java в файле hadoop-env.sh , заменив значение JAVA_HOME местоположением java в вашей системе.
Ниже приведен список файлов, которые вы должны отредактировать для настройки Hadoop.
ядро-site.xml
Файл core-site.xml содержит такую информацию, как номер порта, используемый для экземпляра Hadoop, память, выделенная для файловой системы, лимит памяти для хранения данных и размер буферов чтения / записи.
Откройте файл core-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration>.
HDFS-site.xml
Файл hdfs-site.xml содержит такую информацию, как значение данных репликации, путь namenode и пути datanode вашей локальной файловой системы. Это место, где вы хотите хранить инфраструктуру Hadoop.
Допустим, следующие данные.
Откройте этот файл и добавьте следующие свойства между тегами <configuration> </ configuration> в этом файле.
Примечание. В приведенном выше файле все значения свойств определяются пользователем, и вы можете вносить изменения в соответствии с инфраструктурой Hadoop.
Пряжа-site.xml
Этот файл используется для настройки пряжи в Hadoop. Откройте файл yarn-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
mapred-site.xml
Этот файл используется, чтобы указать, какую платформу MapReduce мы используем. По умолчанию Hadoop содержит шаблон yarn-site.xml. Прежде всего, необходимо скопировать файл из mapred-site.xml.template в файл mapred-site.xml с помощью следующей команды.
Откройте файл mapred-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
Проверка правильности установки Hadoop
Следующие шаги используются для проверки установки Hadoop.
Настройте namenode с помощью команды «hdfs namenode -format» следующим образом.
Ожидаемый результат заключается в следующем.
Следующая команда используется для запуска dfs. Выполнение этой команды запустит вашу файловую систему Hadoop.
Ожидаемый результат следующий:
Следующая команда используется для запуска скрипта пряжи. Выполнение этой команды запустит ваши демоны пряжи.
Большие данные искусственные интеллектуальные Hadoop - Hadoop установка
Последний блог сделал основные введения в Hadoop, и свет не практикует подделку, давайте посмотрим, как установлен Hadoop.
Hadoop поддерживается платформой GNU / Linux (рекомендуется). Следовательно, вам необходимо установить операционную систему Linux и установить среду Hadoop. Если есть операционная система Linux, вы можете установить ее в VirtualBox (чтобы иметь Linux опыт в VirtualBox, и вы можете научиться попробовать его).
Установить перед установкой
Перед установкой Hadoop вам необходимо ввести среду Linux, подключите Linux, чтобы использовать SSH (Secure Shell). Настройте среду Linux в соответствии с процедурами, приведенными ниже.
Создать использование
В начале рекомендуется создать отдельный пользователь Hadoop для выделения файловой системы Hadoop из файловой системы Unix. Создайте пользователя в соответствии с шагами, приведенными ниже:
- Используйте команду «SU», чтобы включить root.
- Создайте пользователя из корневой учетной записи, используя команду «userAdd username».
- Теперь вы можете использовать команду, чтобы открыть существующую учетную запись пользователя «SU username».
Откройте терминал Linux, введите следующую команду для создания пользователя.
SSH Настройки и Генерация ключей
Настройки SSH требуют разных операций на кластере, например, начало, остановка, распределенная операция опекуна. Различные пользователи Hadoop сертифицированы, требуя от открытых ключевых / частных ключевых ключей для пользователей Hadoop и совместного использования различных пользователей.
Следующая команда используется для создания использования пары значения ключа SSH. Скопируйте открытый ключ, формируя ID_RSA.PUB в файл авторизованных_Ком и предоставляет авторизованное имя пользователя владельца?
Установите Java
Java - главная предпосылка для Hadoop. Во-первых, вы должны использовать команду «Java-версию», чтобы убедиться, что Java существует в системе. Синтаксис команды версии Java заключается в следующем.
Если все пойдет хорошо, он даст следующий вывод.
Если Java не установлен в системе, то установите Java в соответствии с шагами, приведенными ниже.
шаг 1
Тогда JDK-7U71-Linux-X64.tar.gz затем будет загружен в систему.
Шаг 2
В целом, файл Java в папке загрузки. Используйте следующую команду для извлечения файла JDK-7U71-Linux-X64.gz.
Шаг 3
Для того, чтобы предоставить Java всем пользователям, переместите его в каталог «/ usr / local /». Откройте корневой каталог и введите следующую команду.
Шаг 4.
Используется для установки переменных Path и Java_Home, добавьте следующую команду в файл
Теперь проверьте команду Java -version с терминала, как описано выше.
Загрузите из программного обеспечения Foundation Apache, извлеките Hadoop2.4.1, используя следующую команду.
Режим работы Hadoop
После загрузки Hadoop вы можете управлять одним из следующих трех режимов поддержки в следующих трех режимах поддержки.
Аналоговый распределенный режим: это распределенное моделирование одной машины. Hadoop защищает каждый процесс, такой как HDF, пряжа, MapReduce и т. Д., будет работать как отдельная программа Java. Эта модель очень полезна для развития.
Полностью распределенный режим: этот режим является полностью распределенным минимумом два или более компьютеров. Мы используем эту модель в будущей главе.
Установить Hadoop в однократном режиме
Здесь Hadeoop2.4.1 будет обсуждаться в автономном режиме.
Есть один JVM для запуска любого демона, все работает. Независимый режим подходит для запуска программы Maprecuce во время разработки, потому что она легко проверить и отладки.
Установить Hadoop.
Переменные среды Hadoop могут быть установлены путем добавления следующей команды в файл
Если все установлено, то вы должны увидеть следующие результаты:
Это означает, что Hadoop работает нормально в автономном режиме. По умолчанию Hadoop сконфигурирован для запуска на одном машине в ненушенном режиме.
Пример
Давайте посмотрим на простой пример Hadoop. Установка Hadoop предоставляет следующий пример файла JAR Mapreatuce, который предоставляет основные функции Maprectuce и могут использоваться для расчета, таких как значения PI, так и слов в файле и т. Д.
Существует входной каталог, который запрашивает несколько файлов, запрашивающих общее количество слов для этих файлов. Чтобы рассчитать общее количество слов, не нужно писать MapReduce, при условии, что файл .jar содержит количество реализаций. Вы можете попробовать другие примеры, используя один и тот же файл .jar; отправьте следующую команду, чтобы проверить программу, которая поддерживает функцию Mapreatuce Via Hadoop Hadoop-Maprecuce-Trives-2,2.0.jar.
шаг 1
Создайте файл содержимого, который вводит временный каталог. Вы можете создать этот входной каталог в любом месте для работы.
Он дает следующие файлы в каталоге ввода:
Эти файлы были скопированы из домашнего каталога установки Hadoop. Для экспериментов могут быть разные большие файлы.
Шаг 2
Давайте начнем подсчет процесса Hadoop во всех общем количестве слов, доступных во всех файлах, доступных в входном каталоге, следующим образом:
Шаг 3
Шаг 2 сделает необходимую обработку и сохранить выходные данные в файле вывода / PAT-R00000, вы можете использовать его по запросу:
Он перечисляет все слова и их файлы во всех каталогах ввода.
Аналоговый распределенный режим Установка Hadop
Шаги для установки Hadoop2.4.1 в режиме псевдо-рассылки будут описаны ниже.
Шаг 1: установить Hadoop
Переменные среды Hadoop могут быть установлены путем добавления следующей команды в файл
Теперь все изменения, которые в настоящее время работают, теперь работает.
Шаг 2: Конфигурация Hadoop
Вы можете найти все профили Hadoop под местоположением «$ hadoop_home / etc / hadoop». Это необходимо изменить эти файлы конфигурации на основе инфраструктуры Hadoop.
Для разработки программ Hadoop используют Java, вы должны заменить значения java_home в систему в системе и сбросить переменную среду Java файлов Hadoop-ev.sh.
Ниже приведен список файлов, которые необходимо редактировать для настройки Hadoop.
Файл Core-Site.xml содержит такую информацию, как номер порта буфера для чтения / записи для примера Hadoop, присвоен хранилище файловой системы для хранения ограничений и размеров памяти данных.
Откройте Core-Site.xml и добавьте следующие свойства между <Configuration>, </ Configuration> Tag
Файл HDFS-Site.xml содержит значение значения пути Namenode, пути пути Namenode, путь узла данных локальной файловой системы. Это означает, что именно здесь хранится фонд Hadoop Foundation.
Давайте предположим следующие данные.
Откройте этот файл и добавьте следующие свойства между вкладкой <Configuration> </ Configuration> в этом файле.
Примечание. В указанном выше файле все значения атрибутов определены пользователем, и могут быть изменены в соответствии с их собственной инфраструктурой Hadoop.
Этот файл используется для настройки пряжи в Hadoop. Откройте файл Yarn-Site.xml и добавьте следующие свойства между тегом <Configuration> </ Configuration> в файле.
Этот файл используется для указания карки MapReCuce. По умолчанию шаблон Hadoop Yarn-Site.xml включен. Во-первых, он должен быть реплицирован из MapRed-Site.xml. Получите файл шаблона MapRed-Site.xml, используя следующую команду.
Откройте файл MapRed-Site.xml и добавьте следующие свойства между тегом <Configuration> </ Configuration> в этом файле.
Убедитесь, что установка Hadoop
Следующие шаги используются для проверки установки Hadoop.
Шаг 1: Название узла Настройки
Используйте команду «HDFS NameNode -Format», чтобы установить NODE NODE.
Результат ожидаемых результатов заключается в следующем
Шаг 2: Убедитесь, что Hadoop DFS
Следующая команда используется для запуска DFS. Выполнить эту команду запускает файловую систему Hadoop.
Желаемый выход следующий:
Шаг 3: Проверьте сценарии пряжи
Следующая команда используется для запуска скрипта пряжи. Выполнить эту команду начнет демон пряжи.
Ожидается, что вывод выглядит следующим образом:
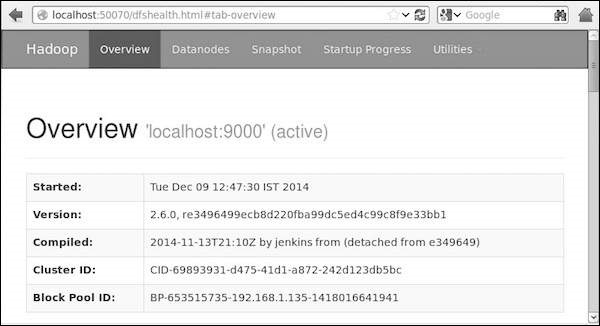
Шаг 4: Доступ к Hadoop в браузере
Доступ к номеру порта по умолчанию Hadoop составляет 50070, получите сервис Hadoop браузера, используя следующий URL.

Шаг 5: Проверьте кластер всех приложений
Номер порта по умолчанию всех приложений в кластере составляет 8088. Используйте следующий URL для доступа к сервису.

Главное меню » Ubuntu » Как установить и настроить Apache Hadoop в Ubuntu

Основными компонентами Apache Hadoop являются:
Теперь ознакомьтесь с приведенными ниже методами установки и настройки Apache Hadoop в вашей системе Ubuntu. Итак, начнем!
Как установить Apache Hadoop в Ubuntu
Прежде всего, мы откроем наш терминал Ubuntu, нажав «CTRL + ALT + T», вы также можете ввести «терминал» в строке поиска приложений.
Следующим шагом будет обновление системных репозиториев:
Теперь мы установим Java в нашу систему Ubuntu, выполнив следующую команду в терминале:
Введите «y/Y», чтобы продолжить процесс установки.
Теперь проверьте наличие установленной Java, проверив ее версию:
Мы создадим отдельного пользователя для запуска Apache Hadoop в нашей системе с помощью команды adduser :
Введите пароль нового пользователя, его полное имя и другую информацию. Введите «y/Y», чтобы подтвердить правильность предоставленной информации.
Пришло время переключить текущего пользователя на созданного пользователя Hadoop, которым в нашем случае является «hadoopuser»:
Теперь используйте приведенную ниже команду для создания пар закрытого и открытого ключей:
Введите адрес файла, в котором вы хотите сохранить пару ключей. После этого добавьте парольную фразу, которую вы собираетесь использовать во всей настройке пользователя Hadoop.
Затем добавьте эти пары ключей в ssh authorized_keys:
Поскольку мы сохранили сгенерированную пару ключей в авторизованном ключе ssh, теперь мы изменим права доступа к файлу на «640», что означает, что только мы, как «владелец» файла, будем иметь права на чтение и запись, у групп есть только разрешение на чтение. Никакие разрешения не будут предоставлены «другим пользователям»:
Читать pip Uninstall / удаление пакета, установленного с помощью pipТеперь аутентифицируйте локальный хост, выполнив следующую команду:
Используйте приведенную ниже команду wget для установки фреймворка Hadoop в вашей системе:
Распакуйте загруженный файл «hadoop-3.3.0.tar.gz» с помощью команды tar:
Вы также можете переименовать извлеченный каталог, как мы это сделаем, выполнив приведенную ниже команду:
Теперь настройте переменные среды Java для настройки Hadoop. Для этого мы проверим расположение нашей переменной «JAVA_HOME»:
/.bashrc» в любимом текстовом редакторе, например nano:
Добавьте следующие пути в открытый файл «
После этого нажмите «CTRL + O», чтобы сохранить изменения, внесенные в файл.
Теперь напишите приведенную ниже команду, чтобы активировать переменную среды «JAVA_HOME»:
Следующее, что нам нужно сделать, это открыть файл переменных среды Hadoop:
Мы должны установить нашу переменную «JAVA_HOME» в среде Hadoop:
Снова нажмите «CTRL + O», чтобы сохранить содержимое файла.
Как настроить Apache Hadoop в Ubuntu
До этого момента мы успешно установили JAVA и Hadoop, создали пользователей Hadoop, настроили аутентификацию на основе ключей SSH. Теперь мы продвинемся вперед, чтобы показать вам, как настроить Apache Hadoop в системе Ubuntu. Для этого нужно создать два каталога: datanode и namenode внутри домашнего каталога Hadoop:
Мы обновим файл Hadoop «core-site.xml», добавив наше имя хоста, поэтому сначала подтвердите имя хоста вашей системы, выполнив эту команду:
Теперь откройте файл « core-site.xml » в редакторе nano:
Имя хоста нашей системы в «andreyex-VBox», вы можете добавить следующие строки с именем хоста системы в открытый файл Hadoop «core-site.xml»:
Нажмите «CTRL + O» и сохраните файл.
В файле «hdfs-site.xml» мы изменим путь к каталогам «datanode» и «namenode»:
Опять же, чтобы записать добавленный код в файл, нажмите «CRTL + O».
Читать Как использовать SSH-туннелирование или переадресацию портовЗатем откройте файл «mapred-site.xml» и добавьте в него приведенный ниже код:
Нажмите «CTRL + O», чтобы сохранить изменения, внесенные в файл.
Запишите приведенные ниже строки в файл «yarn-site.xml»:
Мы должны запустить кластер Hadoop для работы с Hadoop. Для этого сначала отформатируем наш «namenode»:
Теперь запустите кластер Hadoop, выполнив следующую команду в своем терминале:
Сохраните файл «/etc/host», и теперь все готово для запуска кластера Hadoop:
На следующем шаге мы запустим службу пряжи Hadoop:
Чтобы проверить статус всех сервисов Hadoop, выполните в терминале команду «jps»:
Hadoop прослушивает порты 8088 и 9870, поэтому вам необходимо разрешить эти порты через брандмауэр:
Теперь перезагрузите настройки брандмауэра:
Теперь откройте браузер и войдите в свой «namenode» Hadoop, введя свой IP-адрес с портом 9870.
Используйте порт 8080 со своим IP-адресом для доступа к диспетчеру ресурсов Hadoop:

В веб-интерфейсе Hadoop вы можете найти «Каталог просмотра», прокрутив открытую веб-страницу вниз следующим образом:

Это все об установке и настройке Apache Hadoop в системе Ubuntu. Для остановки кластера Hadoop, вы должны остановить услуги «yarn» и «NameNode»:
Заключение
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.

В данной статье будет по шагам разобран процесс создания небольшого кластера Hadoop для опытов.
Несмотря на то, что в интернете на иностранных ресурсах есть полно материала про настройку/развертывание Hadoop, большинство из них либо описывают настройку ранних версий (0.X.X и 1.X.X), либо описывают только настройку в режиме single mode/pseudo distributed mode и лишь частично fully distributed mode. На русском языке материала практически нет вовсе.
Когда мне самому понадобился Hadoop, то я далеко не с первого раза смог все настроить. Материал был неактуален, часто попадались конфиги, которые используют deprecated параметры, поэтому использовать их нежелательно. А даже когда все настроил, то задавался многими вопросами, на которые искал ответы. Также встречались похожие вопросы у других людей.
Всем кому интересно, прошу пожаловать по кат.
Предварительные настройки
В качестве операционной системы для нашего кластера я предлагаю использовать Ubuntu Server 12.04.3 LTS, но при минимальных изменениях можно будет проделать все шаги и на другой ОС.
Все узлы будут работать на VirtualBox. Системные настройки для виртуальной машины я выставлял небольшие. Всего 8 GB пространства для жёсткого диска, одно ядро и 512 Мб памяти. Виртуальная машина также оснащена двумя сетевыми адаптерами: один NAT, а другой для внутренней сети.
После того, как была скачена и установлена операционная система, необходимо обновиться и установить ssh и rsync:
Для работы Hadoop можно использовать либо 6 или 7 версию.
В данной статье будем работать с OpenJDK 7 версии:
Хотя можно использовать версию от Oracle.
Очищаем ОС от всех зависимостей OpenJDK sudo apt-get purge openjdk*
Устанавливаем python-software-properties который позволит добавлять новые PPA:
Создание отдельной учетной записи для запуска Hadoop
Мы будем использовать выделенную учетную запись для запуска Hadoop. Это не обязательно, но рекомендуется. Также предоставим новому пользователю права sudo, чтобы облегчить себе жизнь в будущем.
Во время создания нового пользователя, необходимо будет ввести ему пароль.
/etc/hosts
Нам необходимо, чтобы все узлы могли легко обращаться друг к другу. В большом кластере желательно использовать dns сервер, но для нашей маленькой конфигурации подойдет файл hosts. В нем мы будем описывать соответствие ip-адреса узла к его имени в сети. Для одного узла ваш файл должен выглядеть примерно так:
Для управления узлами кластера hadoop необходим доступ по ssh. Для созданного пользователя hduser предоставить доступ к master.
Для начала необходимо сгенерировать новый ssh ключ:
Во время создания ключа будет запрошен пароль. Сейчас можно его не вводить.
Следующим шагом необходимо добавить созданный ключ в список авторизованных:
Проверяем работоспособность, подключившись к себе:
Отключение IPv6
Если не отключить IPv6, то в последствии можно получить много проблем.
Для отключения IPv6 в Ubuntu 12.04 / 12.10 / 13.04 нужно отредактировать файл sysctl.conf:
Добавляем следующие параметры:
Сохраняем и перезагружаем операционную систему.
Для того, чтобы отключить ipv6 только в hadoop можно добавить в файл etc/hadoop/hadoop-env.sh:
Установка Apache Hadoop
На момент декабря 2013 года стабильной версией является 2.2.0.
Создадим папку downloads в корневом каталоге и скачаем последнюю версию:
Распакуем содержимое пакета в /usr/local/, переименуем папку и выдадим пользователю hduser права создателя:
Обновление $HOME/.bashrc
Для удобства, добавим в .bashrc список переменных:
На этом шаге заканчиваются предварительные подготовки.
Настройка Apache Hadoop
Все последующая работа будет вестись из папки /usr/local/hadoop.
Откроем etc/hadoop/hadoop-env.sh и зададим JAVA_HOME.
Опишем, какие у нас будут узлы в кластере в файле etc/hadoop/slaves
Этот файл может располагаться только на главном узле. Все новые узлы необходимо описывать здесь.
Основные настройки системы располагаются в etc/hadoop/core-site.xml:
Настройки HDFS лежат в etc/hadoop/hdfs-site.xml:
Здесь параметр dfs.replication задает количество реплик, которые будут хранится на файловой системе. По умолчанию его значение равно
3. Оно не может быть больше, чем количество узлов в кластере.
Параметры dfs.namenode.name.dir и dfs.datanode.data.dir задают пути, где будут физически располагаться данные и информация в HDFS. Необходимо заранее создать папку tmp.
Сообщим нашему кластеру, что мы желаем использовать YARN. Для этого изменим etc/hadoop/mapred-site.xml:
Все настройки по работе YARN описываются в файле etc/hadoop/yarn-site.xml:
Настройки resourcemanager нужны для того, чтобы все узлы кластера можно было видеть в панели управления.
Запустим hadoop службы:
*В предыдущей версии Hadoop использовался скрипт sbin/start-all.sh, но с версии 2.*.* он объявлен устаревшим.
Необходимо убедиться, что запущены следующие java-процессы:
Протестировать работу кластера можно при помощи стандартных примеров:
Теперь у нас есть готовый образ, который послужит основой для создания кластера.
Далее можно создать требуемое количество копий нашего образа.
На копиях необходимо настроить сеть. Необходимо сгенерировать новые MAC-адреса для сетевых интерфейсов и выдать и на них необходимые ip-адреса. В моем примере я работаю с адресами вида 192.168.0.X.
Для удобства, изменить имена новых узлов на slave1 и slave2.
Необходимо изменить два файла: /etc/hostname и /etc/hosts.Сгенерируйте на узлах новые SSH-ключи и добавьте их все в список авторизованных на узле master.
На каждом узле кластера изменим значения параметра dfs.replication в etc/hadoop/hdfs-site.xml. Например, выставим везде значение 3.
Добавим на узле master новые узлы в файл etc/hadoop/slaves:
Когда все настройки прописаны, то на главном узле можно запустить наш кластер.
На slave-узлах должны запуститься следующие процессы:
Теперь у нас есть свой мини-кластер.
Давайте запустим задачу Word Count.
Для этого нам потребуется загрузить в HDFS несколько текстовых файлов.
Для примера, я взял книги в формате txt с сайта Free ebooks — Project Gutenberg.
Перенесем наши файлы в HDFS:
Запустим Word Count:
Отслеживать работу можно через консоль, а можно через веб-интерфейс ResourceManager'а по адресу master:8088/cluster/apps/
По завершению работы, результат будет располагаться в папке /out в HDFS.
Для того, чтобы скачать его на локальную файловую систему выполним:
Читайте также: