
Как выбрать представление данных xslt в word
Обновлено: 03.07.2024
Язык преобразований XSLT
XSLT (eXtensible Stylesheet Language Transformations) - расширяемый язык преобразования листов стилей.
Язык XSLT служит транслятором, с помощью которого можно свободно модифицировать исходный текст. XLST играет решающую роль в утверждении XML в качестве универсального языка хранения и передачи данных. Область применения XSLT широка - от электронной коммерции до беспроводного Web.
Фактическая сборка результирующего документа происходит, когда исходный документ и лист стилей XSLT передаются в синтаксический анализатор XSLT (XSLT-процессор).
При использовании XSLT в среде Web синтаксический анализ может происходить либо на стороне пользователя (т.е. в пользовательском браузере), либо на стороне сервера.
Анализ XSLT на стороне клиента похож на процедуру применения каскадных листов стилей. В исходный документ нужно добавить тег
Здесь transform.xsl - имя файла листа стилей XSLT.
Шаблоны
Каждый элемент XSLT начинается префиксом xsl:. Элемент xsl:stylesheet служит контейнером для листа стилей XSLT. Атрибут version="1.0" этого элемента определяет версию спецификации XSL.
Преобразования XSLT основаны на шаблонах. Шаблон определяется инструкцией xsl:template.
XSLT-процессор анализируют исходный документ и пытается найти подходящий XSL-шаблон. Если такой шаблон найден, то выполняются инструкции внутри него.
Обработка всегда начинается с шаблона, где match="/". Это значение пути адресации соответствует корневому узлу (в примере 1 это книга).
Пример 1
Исходный XML
Преобразование XSLT ( файл t01.xsl )
Михаил Булгаков
- инструкцией xsl:value-of. В этом случае содержание элемента используется без какой-либо дальнейшей обработки (см. пример 2);
- инструкцией xsl:apply-templates. В этом случае XSLT-процессор продолжает обрабатывать выбранные элементы, для которых определен шаблон (см. пример 3).
Пример 2
Исходный XML
Преобразование XSLT ( файл t02.xsl )
Мастер и Маргарита. Михаил Булгаков
Пример 3
Исходный XML
Преобразование XSLT ( файл t03.xsl )
Мастер и Маргарита. Михаил Булгаков
В качестве значений атрибутов match и select используются выражения, синтаксис которых похож на маршрут файловой системы:
Сравните результаты примера 4 (перечисление узлов) и примера 5 (все узлы).
Дата последнего изменения: 2 февраля 2011 г.
Применимо к: SharePoint Foundation 2010
В этом разделе приводится обзор системы отображения представлений списков в Microsoft SharePoint Foundation. Приступая к этой теме, необходимо иметь по крайней мере базовое представление о понятиях XSLT, включая таблицы стилей, шаблоны, параметры, деревья узлов и узлы контекста.
Отображение с помощью таблиц стилей XSLT
Таблицы стилей XSLT, которые поставляются с SharePoint Foundation, расположены XSL-файлах в папке %ProgramFiles%\Common Files\Microsoft Shared\web server extensions\14\TEMPLATE\LAYOUTS\XSL. Два самых важных файла из них — это vwsytles.xsl и fldtypes.xsl. Первый содержит таблицы стилей для отображения списков вплоть до уровня строк. Второй содержит таблицы стилей для отображения конкретных полей, то есть ячеек, в представлениях списков. Большой набор глобальных переменных XSLT определен в файле main.xsl.
Таблица стилей XSLT анализирует исходное дерево узлов на некотором языке XML и выдает результирующее дерево узлов на другом языке XML. В простейшем случае исходное дерево преобразуется в результирующее. Это выполняется с помощью XSLT-шаблонов, каждый из которых представляет собой некоторое правило, определяющее способ преобразования определенного фрагмента исходной разметки во фрагмент результирующей разметки. Однако преобразование необязательно осуществляет простую переформулировку на результирующем языке только данных исходного дерева узлов. Оно может приводить к исключению данных из исходного дерева, а также вставлять в результирующее дерево данные, отсутствующие в исходном. В частности, XSLT-шаблон может объединять данные из нескольких входных деревьев узлов. Каждое дополнительное входное дерево узлов помимо исходного передается шаблону в виде параметра. У XSLT-шаблонов для отображения представлений списков в SharePoint Foundation имеется два входных дерева узлов:
source node tree — это разметка Схема View, в которой определяется текущее представление списка. Именно это дерево анализирует и обходит XSLT-процессор при построении результирующего дерева. Таким образом, в любой момент времени в ходе XSLT-преобразования контекстным узлом XSLT-процессора является узел в этой разметке.
Дерево параметра thisNode передается каждому шаблону визуализации XSLT с помощью вызова шаблона. Эта разметка содержит фактические данные из списка. При визуализации поля фактическое значение берется из этого параметра. Полную справку о разметке в параметре thisNode см. в статье XML-разметка dsQueryResponse.
Иерархия XSLT-шаблонов
Иерархия XSLT-шаблонов в SharePoint Foundation довольно сложна. Цепочка вызовов шаблонов (через xsl:apply-templates и xsl:call-template) при отображении представления списка зависит от различных факторов, включая помимо прочего тип списка, выбранное представление списка, стиль представления и то, включает ли представление группирование строк. В этом разделе описывается простейшая возможная цепочка вызовов в случае, когда пользователь перешел на страницу со списком, у которого имеются следующие свойства.
Тип списка — 100 (общий).
Атрибут BaseViewID списка равен 1.
Стиль представления равен 0 (базовая таблица).
Группирования строк не происходит.
Система таблиц стилей XSLT вызывается событием PreRender на странице. XSLT-шаблон верхнего уровня не имеет имени и объявляется в файле vwsytles.xsl с помощью следующего открывающего тега.
Поведение этого шаблона зависит от результата ряда проверок Boolean. Однако в самом простом случае он вызывает xsl:apply-templates для шаблонов в режиме RootTemplate и выбирает текущий узел контекста, который является корнем исходного дерева узлов. (Переменная XmlDefinition определяется в файле main.xsl как ".", то есть текущий узел контекста.)
В результате шаблон View_Default_RootTemplate применяется к элементу View, который является элементом документа, то есть верхним элементом исходного дерева узлов. (Пример см. в статье Примеры входного дерева узлов и результирующего дерева узлов в XSLT-преобразованиях.) Ниже указывается открывающий тег для этого шаблона.
Этот шаблон создает HTML-элемент <table>, который отображает список. Он вызывает дочерние шаблоны с использованием следующих строк.
В этих строках вызывается xsl:applytemplates для шаблонов в полном режиме и выбирается текущий режим контекста, который на данном этапе все еще представляет собой элемент View. В рассматриваемом образце со стандартным представлением обычного списка единственным соответствующим шаблоном является первый из раздела View Templates файла vwsytles.xsl. У него следующий открывающий тег.
Этот шаблон начинает отображение некоторых HTML-данных для списка. Что более важно, он вызывает дополнительные шаблоны с использованием следующей строки.
Единственным соответствующим шаблоном является шаблон со следующим открывающим тегом.
Вызов этого неименованного шаблона отличается от предыдущих шаблонов в иерархии в одном важном отношении. В предыдущих шаблонах в качестве источника данных использовалось только исходное дерево узлов, которое определяет представление списка. Однако чтобы заполнить таблицу HTML, в которой будет отображаться список, необходимы сведения об этом конкретном списке, такие как число элементов (строк) в нем и значения конкретных полей в списке. Соответственно, этому шаблону передается параметр thisNode, в котором содержатся фактические данные списка из базы данных контента в виде разметки dsQueryResponse. При каждом последующем вызове шаблона или применении шаблонов к конкретному узлу этот же параметр передается вызываемым шаблонам. Пример содержимого параметра thisNode см. в статье Примеры входного дерева узлов и результирующего дерева узлов в XSLT-преобразованиях.
В шаблоне выполняется перебор всех строк (элементов списка) в thisNode. Для каждой применяется шаблон с режимом Item и передается ссылка на все поля в представлении. Ниже приводятся важные строки кода.
Переменная AllRows является ссылкой на элементы Row в thisNode. Хотя кажется, что параметру thisNode назначается текущий узел "." с атрибутом select, это на самом деле только значение по умолчанию, которое имеет thisNode, если в шаблон для него не передается никакое другое значение. На самом деле в качестве параметра передается разметка dsQueryResponse. Для каждой строки в списке применяются шаблоны с режимом Item, которым передается параметр Fields. Последний является ссылкой на все элементы FieldRef в исходном дереве узлов.
Существует несколько шаблонов с режимом Item, но только один подходит для случая, когда список имеет тип 100 (общий) и его стиль представления равен 0. Это самый первый шаблон в разделе Row Templates файла vwstyles.xsl. У него следующий открывающий тег.
Этот шаблон вставляет открывающий и закрывающий HTML-тег <tr>, в котором отображается строка таблицы для текущего элемента списка. Между ними он выполняет перебор всех полей в элементе списка и применяет к ним шаблоны с режимом printTbleCellEcbAllowed. Ниже приведены важные строки кода.
Единственный соответствующий шаблон имеет следующий открывающий тег.
Этот шаблон вставляет открывающий и закрывающий HTML-теги <td> для формирования ячейки таблицы для текущего поля. Он также назначает ячейке класс каскадных таблиц стилей (CSS). Между открывающим и закрывающим тегом он применяет шаблоны с режимом PrintFieldWithECB, как показано здесь.
Нужный соответствующий шаблон находится в файле fldtypes.xsl, как и все другие остальные шаблоны в иерархии. Его открывающий тег показан вверху следующего блока кода. Этот и остающиеся шаблоны в цепочке отображают определенные ячейки в таблице HTML в зависимости от того, является ли текущая строка строкой заголовка или данных, в зависимости от типа поля (например, Note или Currency) и базового типа поля (например, Text или Number) и необходимого способа отображения поля (например, в виде простого текста или в виде ссылки на форму отображения). Ниже приведены открывающие теги для оставшихся шаблонов для поля типа Text в строке данных. Каждый вызывается своим предшественником либо по имени, либо в результате применения шаблонов с конкретным режимом.
Последним является шаблон, который наконец отображает значение поля типа Text в ячейке таблицы HTML. Ниже приведена вся разметка для этого шаблона.
Обратите внимание, что шаблон разветвляется в зависимости от того, определено ли в поле автоматическое форматирование строк, которые похожи на URL-адреса, в виде HTML-ссылок <a>. Если это определено, то когда XSLT-процессор отображает HTML-разметку для поля, он не заменяет значимые символы, такие как "<" и "&" на эквивалентные им сущности (< и &), что совместимый XSLT-процессор обычно делает по умолчанию. Кроме этой ситуации шаблон просто вставляет значение поля с помощью следующей строки.
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями xml и rels
- медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
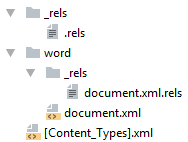
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
word/document.xml
- <w:document> — сам документ
- <w:body> — тело документа
- <w:p> — параграф
- <w:r> — run (фрагмент) текста
- <w:t> — сам текст
- <w:sectPr> — описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test .
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml . Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels . Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
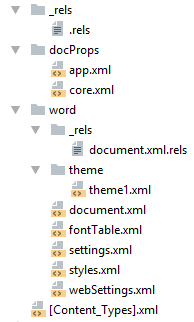
Вот что в них содержится:
- docProps/core.xml — основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].
- docProps/app.xml — общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.
- word/settings.xml — настройки относящиеся к текущему документу.
- word/styles.xml — стили применимые к документу. Отделяют данные от представления.
- word/webSettings.xml — настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.
- word/fontTable.xml — список шрифтов используемых в документе.
- word/theme1.xml — тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux: apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
- unpack file dir — распаковывает документ file в папку dir и форматирует xml
- pack dir file — запаковывает папку dir в документ file
Использование под Linux аналогично, только ./unpack.sh вместо unpack , а pack становится ./pack.sh .
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью unpack в новую папку.
- Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ bold.docx с обычным (не жирным) текстом Test.
- Распаковываем его: unpack bold.docx bold . .
- Выделяем текст Test жирным.
- Распаковываем unpack bold.docx bold .
- Изначально diff выглядел следующим образом:
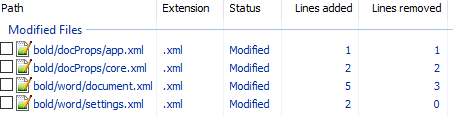
Рассмотрим его подробно:
docProps/app.xml
Изменение времени нам не нужно.
docProps/core.xml
Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/> ) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
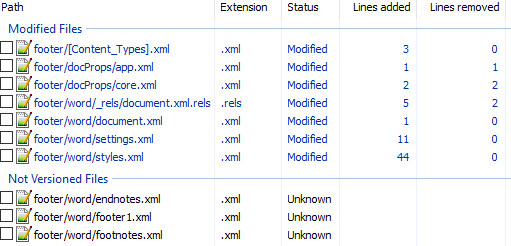
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
word/footer1.xml
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В [Content_Types].xml надо добавить footer
- В word/_rels/document.xml.rels надо добавить ссылку на footer
- В word/document.xml в тег <w:sectPr> надо добавить <w:footerReference>
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в [Content_Types].xml и word/_rels/document.xml.rels .
- В word/document.xml в тег <w:sectPr> добавляем тег <w:footerReference> или заменяем в нём ссылку на наш нижний колонтитул.
- Запаковываем документ.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
В результате получится файл нижнего колонтитула footer0.xml :
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels :
Прописываем ссылки в документе
Далее надо в каждый тег <w:sectPr> добавить тег <w:footerReference> или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега <w:sectPr> может быть 3 тега <w:footerReference> — для первой страницы, четных страниц и всего остального:
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml :
В результате
Весь код опубликован. Работает он так:
- in.docx — исходный документ
- out.docx — выходящий документ
- TEST — текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями xml и rels
- медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
word/document.xml
- <w:document> — сам документ
- <w:body> — тело документа
- <w:p> — параграф
- <w:r> — run (фрагмент) текста
- <w:t> — сам текст
- <w:sectPr> — описание страницы
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test .
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml . Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels . Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
Даже если связей нет, этот файл должен существовать.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
Вот что в них содержится:
- docProps/core.xml — основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].
- docProps/app.xml — общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.
- word/settings.xml — настройки относящиеся к текущему документу.
- word/styles.xml — стили применимые к документу. Отделяют данные от представления.
- word/webSettings.xml — настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.
- word/fontTable.xml — список шрифтов используемых в документе.
- word/theme1.xml — тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux: apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
- unpack file dir — распаковывает документ file в папку dir и форматирует xml
- pack dir file — запаковывает папку dir в документ file
Использование под Linux аналогично, только ./unpack.sh вместо unpack , а pack становится ./pack.sh .
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью unpack в новую папку.
- Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ bold.docx с обычным (не жирным) текстом Test.
- Распаковываем его: unpack bold.docx bold . .
- Выделяем текст Test жирным.
- Распаковываем unpack bold.docx bold .
- Изначально diff выглядел следующим образом:
Рассмотрим его подробно:
docProps/app.xml
Изменение времени нам не нужно.
docProps/core.xml
Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
в параграфе с Test. Видимо элемент <w:b/> и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением <w:b/> ) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:
Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
word/footer1.xml
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В [Content_Types].xml надо добавить footer
- В word/_rels/document.xml.rels надо добавить ссылку на footer
- В word/document.xml в тег <w:sectPr> надо добавить <w:footerReference>
Уменьшаем diff до этого набора изменений:
Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в [Content_Types].xml и word/_rels/document.xml.rels .
- В word/document.xml в тег <w:sectPr> добавляем тег <w:footerReference> или заменяем в нём ссылку на наш нижний колонтитул.
- Запаковываем документ.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
В результате получится файл нижнего колонтитула footer0.xml :
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels :
Прописываем ссылки в документе
Далее надо в каждый тег <w:sectPr> добавить тег <w:footerReference> или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега <w:sectPr> может быть 3 тега <w:footerReference> — для первой страницы, четных страниц и всего остального:
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml :
В результате
Весь код опубликован. Работает он так:
- in.docx — исходный документ
- out.docx — выходящий документ
- TEST — текст, который добавляется в нижний колонтитул
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Читайте также: