
Как загрузить файл пдф в 1с
Обновлено: 05.07.2024
Пользователи 1С часто сталкиваются с необходимостью работы с внешними файлами. Чтобы не возникло никаких сложностей с этим вопросом, мы решили написать на эту тему статью. В данном материале мы разберём наиболее популярные типы файлов и выясним, как их загрузить в 1С.
Для начала опишем варианты файлов:
Данный вид файлов представлен, как правило, документами в виде изображений с расширениями *.pdf/*.jpg/*.tif и пр.
Используется такой файл исключительно для присоединения к объектам конфигурации* и их дальнейшей отправкой либо хранения в составе вложения.
Данный вид файлов представлен расширениями различного типа *.mxl/*.xls/*.txt и пр.
Используется для загрузки данных в ИБ через внешние и внутренние обработки 1С.
Подобные файлы имеют расширения *.epf у внешних обработок и *.erf у внешних отчётов соответственно.
Используются данные файлы для добавления дополнительных возможностей 1С, не предусмотренных разработчиком конфигурации.
В эту группу можно отнести файлы расширения *.dt/*.1cd/*.log/*.pff/ *.v8i и пр.
Эти файлы необходимы 1С для корректного функционирования.
*В виде документов учёта, произвольным ЭД в сервисе 1С-ЭДО, письмам в сервисе 1С-Отчётность и прочее.
Определившись с группами используемых файлов, попробуем на примере разобрать наиболее частые варианты работы с каждой из групп.
Прикрепление скана договора с контрагентом к первичному документу учёта
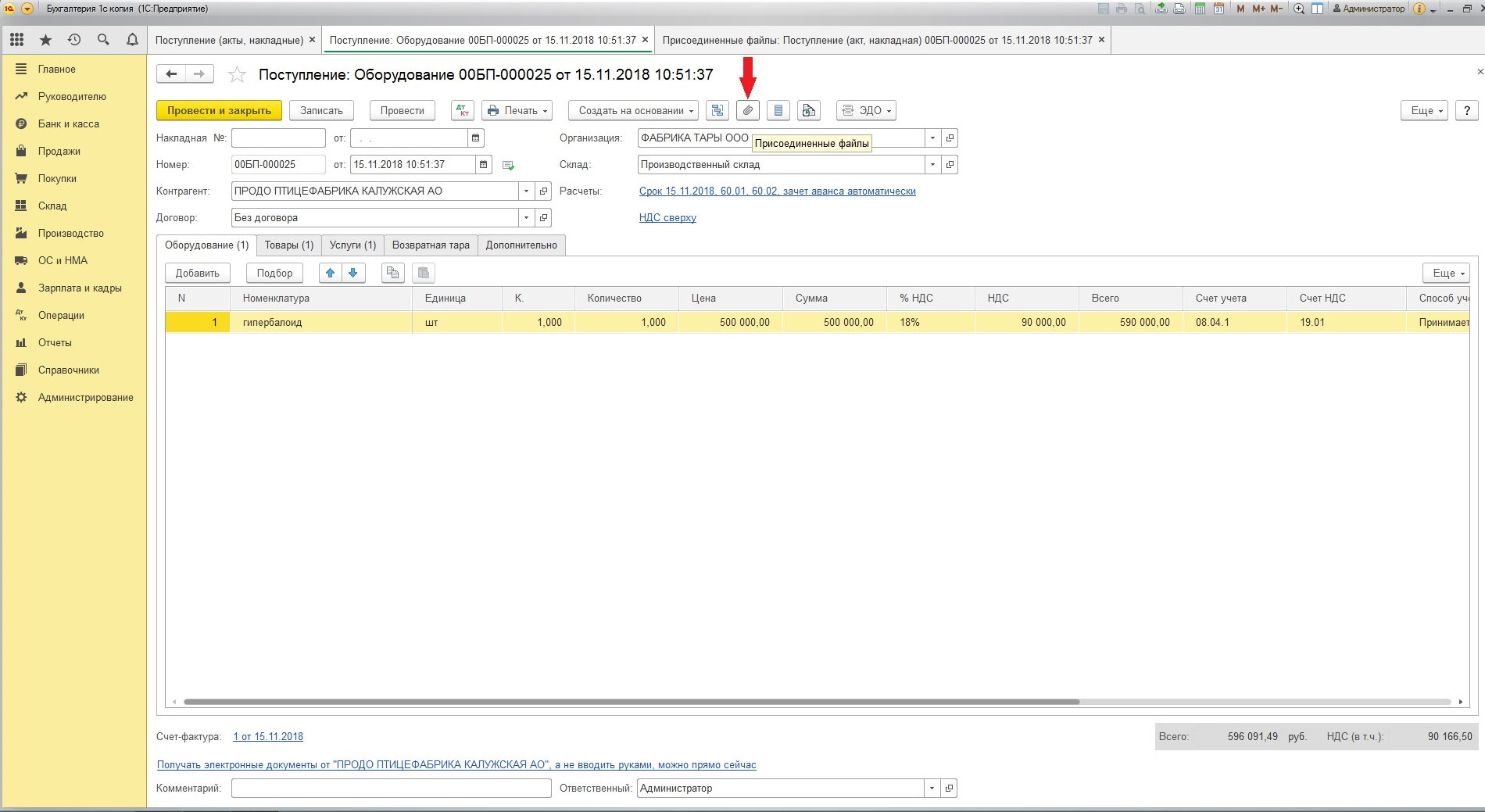
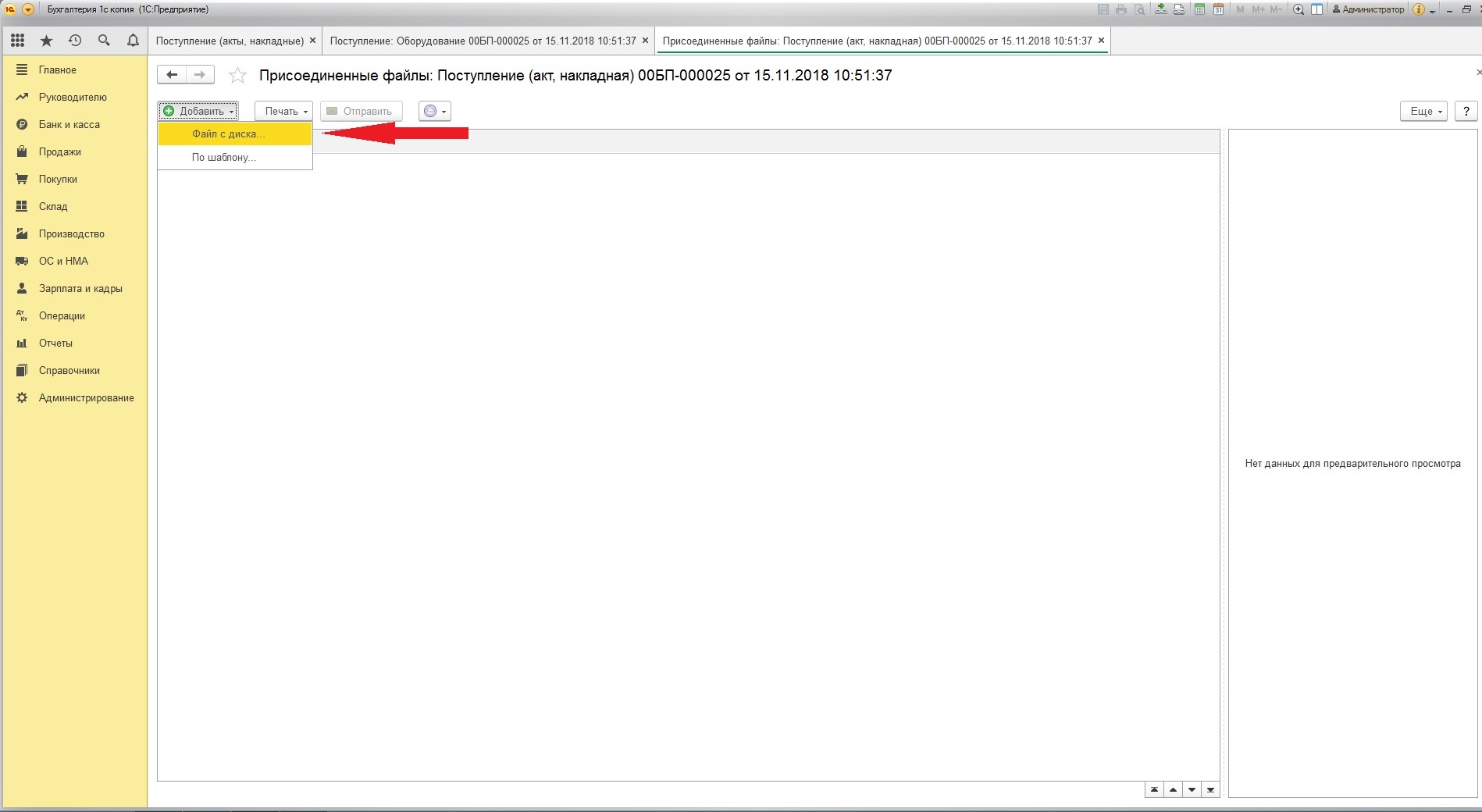
Не все формы документов учёта поддерживают возможность прикрепления вложений.
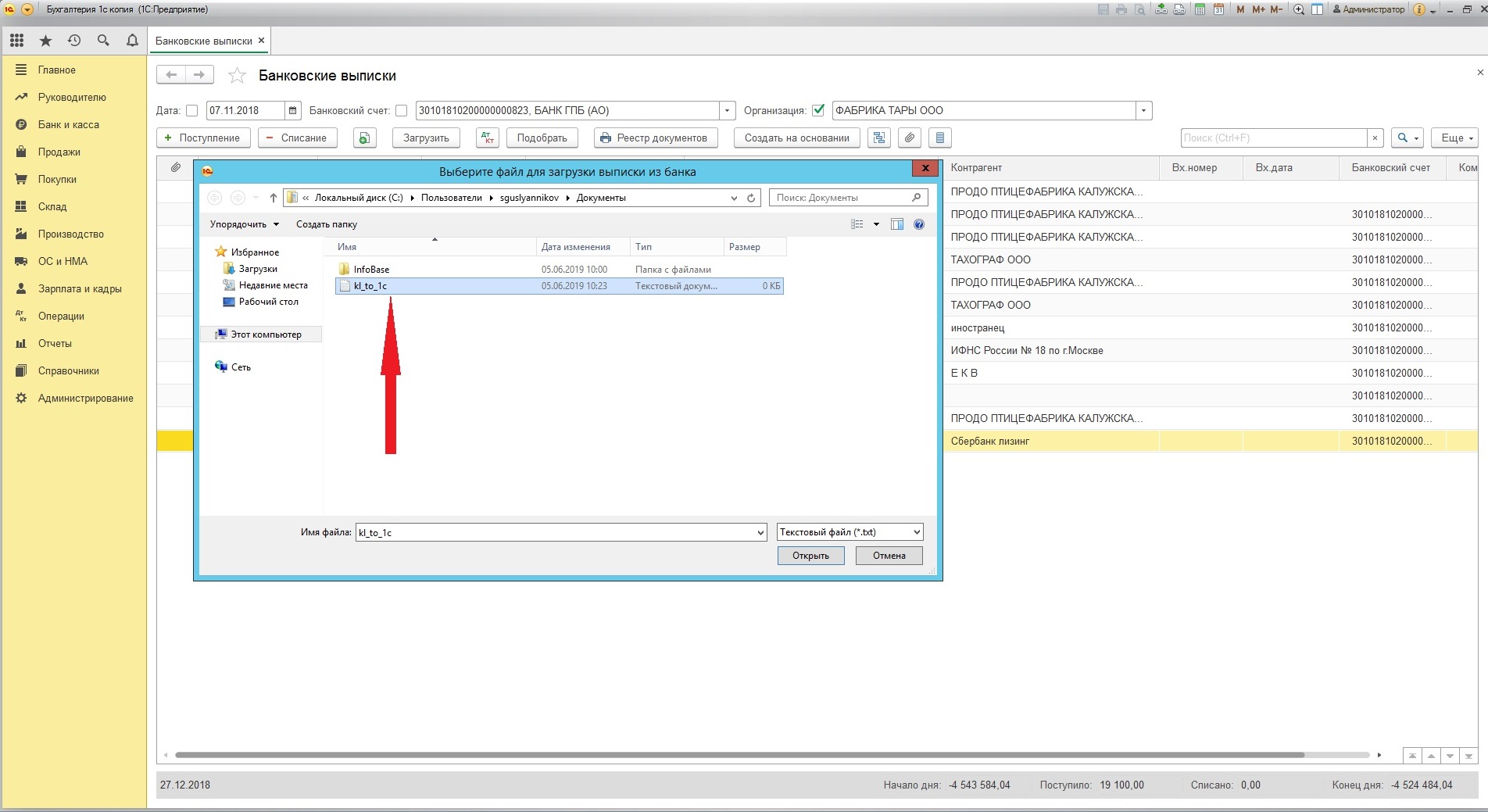
Файл обмена с банком формата *.txt, содержащий данные по движениям по счёту при загрузке в 1С
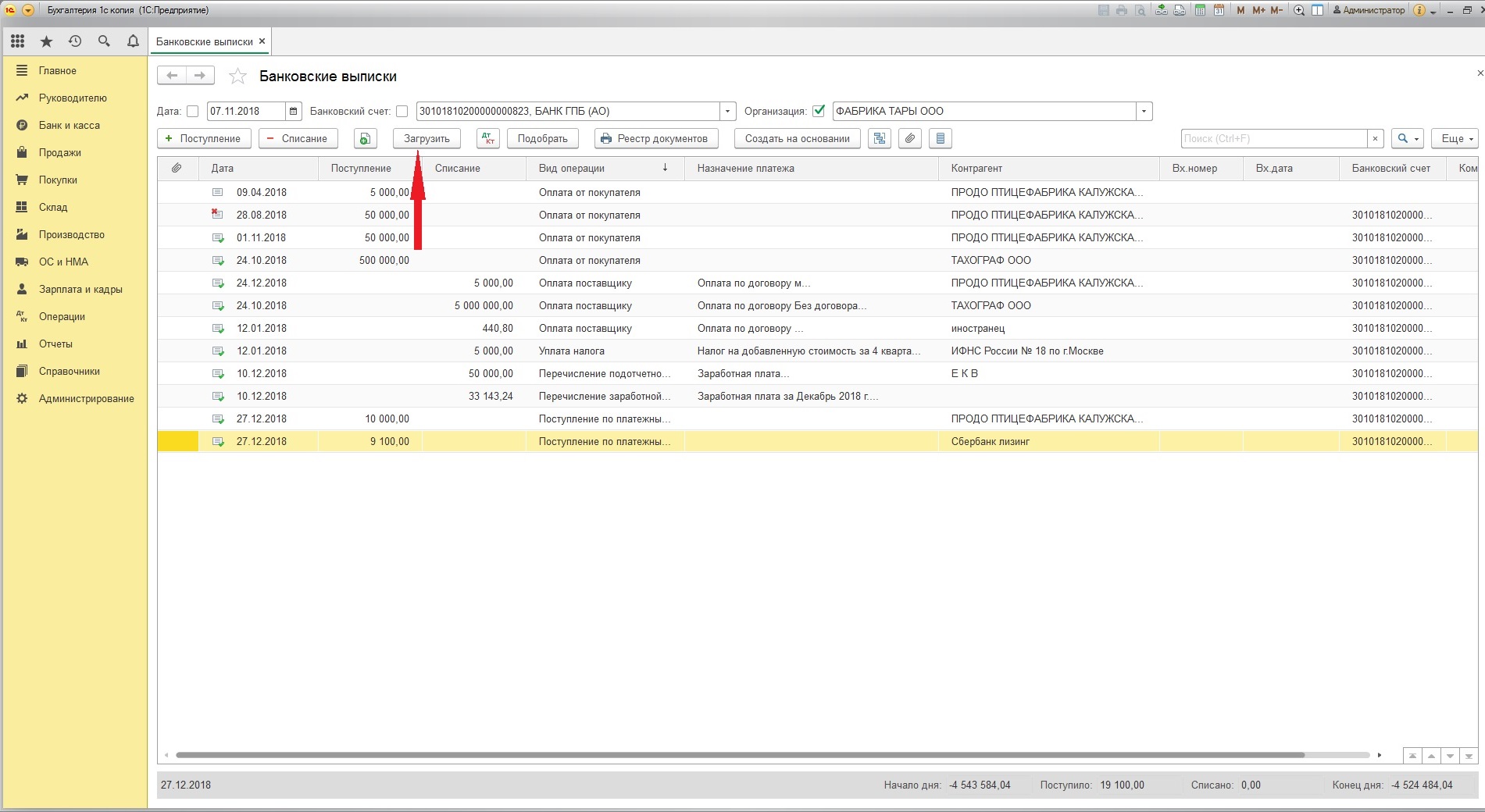
Или через встроенную в типовую конфигурацию обработку «Обмен с банком», которую можно открыть в «Банковских выписках» через «Ещё».
Файл отчётности, сформированный в другой БД или ПО в *.xml формате, для загрузки и отправки через сервис 1- Отчётность
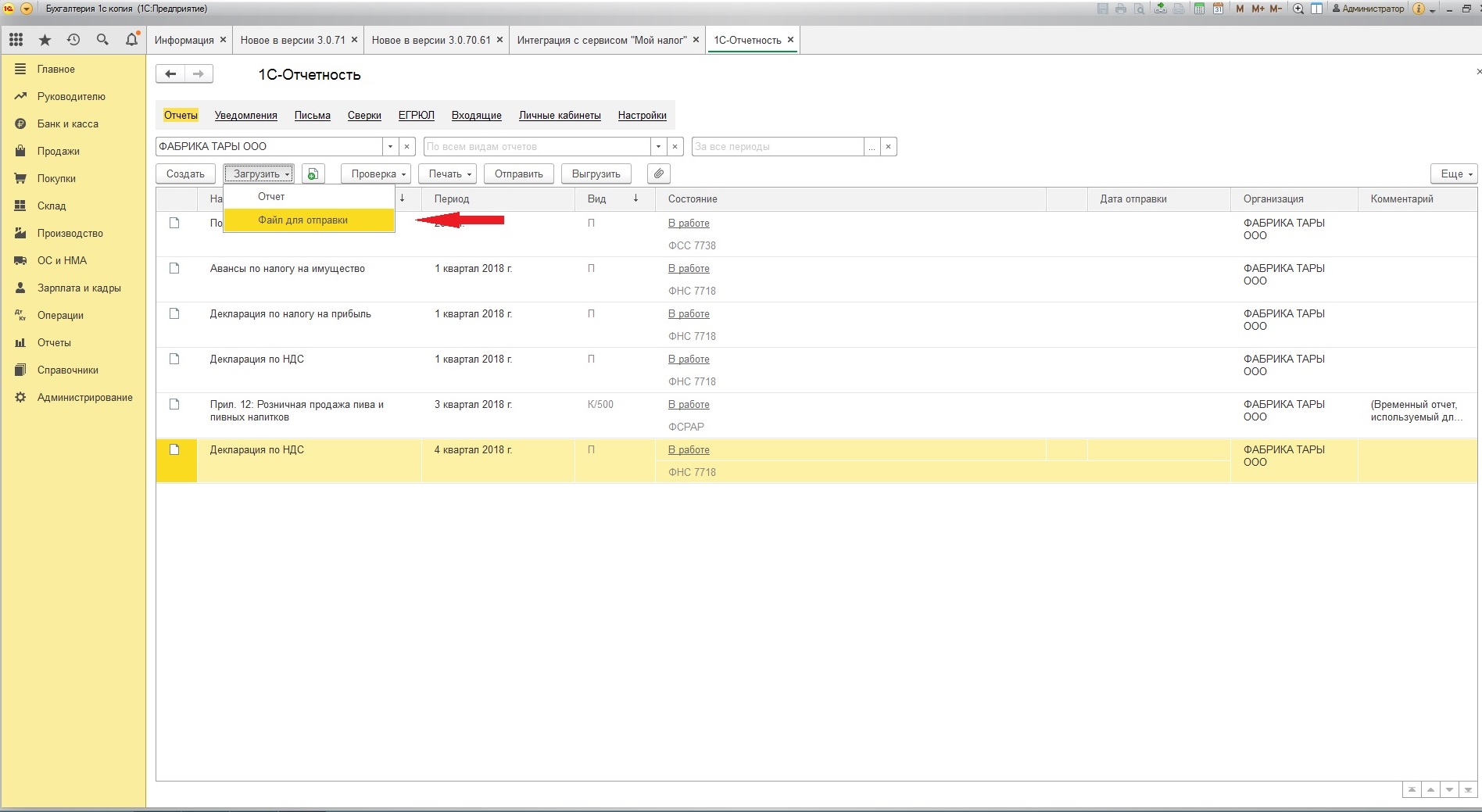
Разовое открытие обработки можно сделать из «Главного меню» – «Файл» – «Открыть»
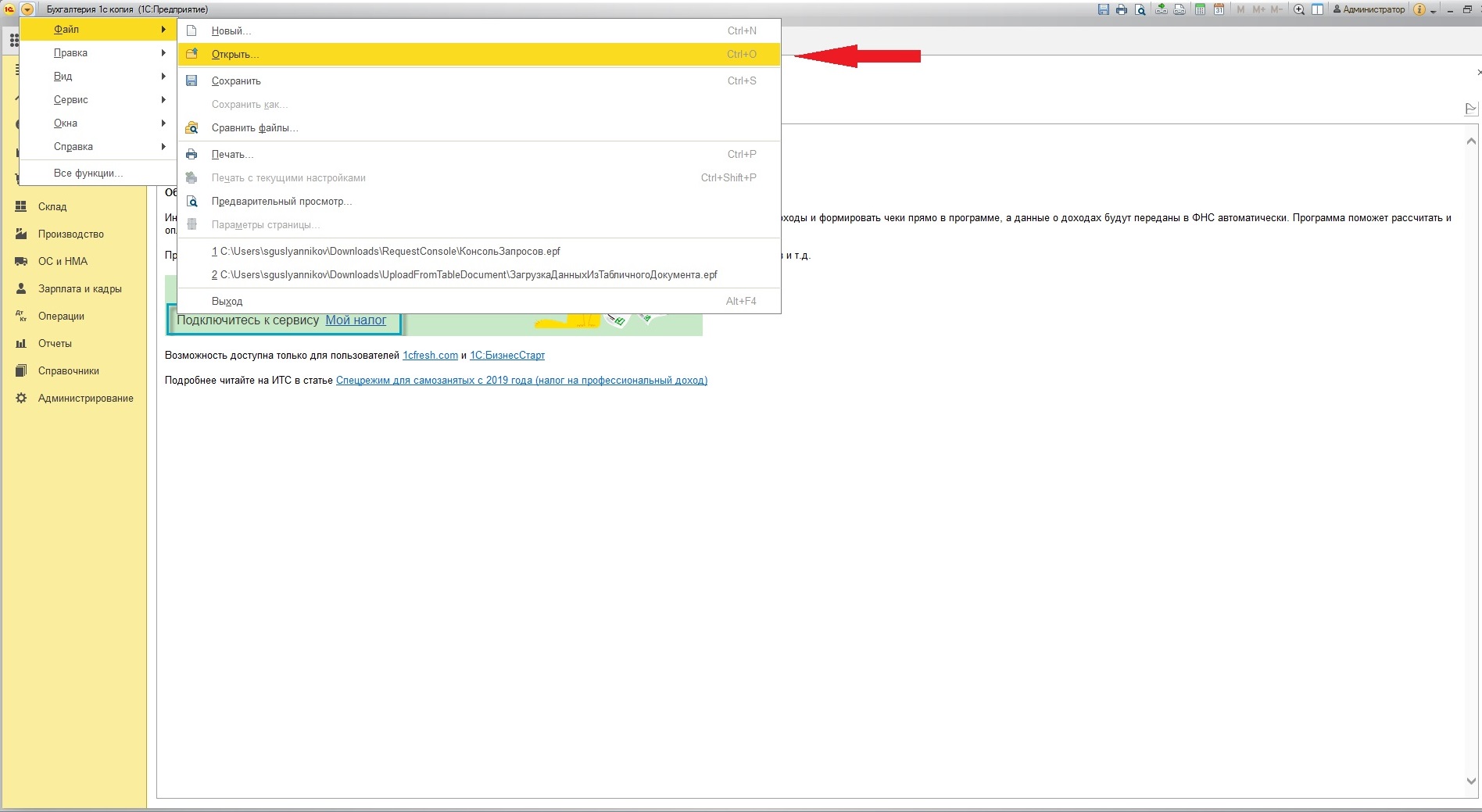
Некоторые организации предоставляют внешние обработки для интеграции 1С со сторонним ПО. Для открытия подобных файлов у пользователя 1С в настройках прав должна стоять отметка на «Открытии внешних отчётов и обработок».
Более подробно по открытию внешних отчётов и обработок можно узнать на сайте ИТС .
Пользователи 1С могут столкнуться с необходимостью переноса БД или её созданию и добавлению в список баз. В файловом варианте работы БД файл 1cv8.1cd является самой БД, остальные файлы в общей с ней папке носят вспомогательный характер.
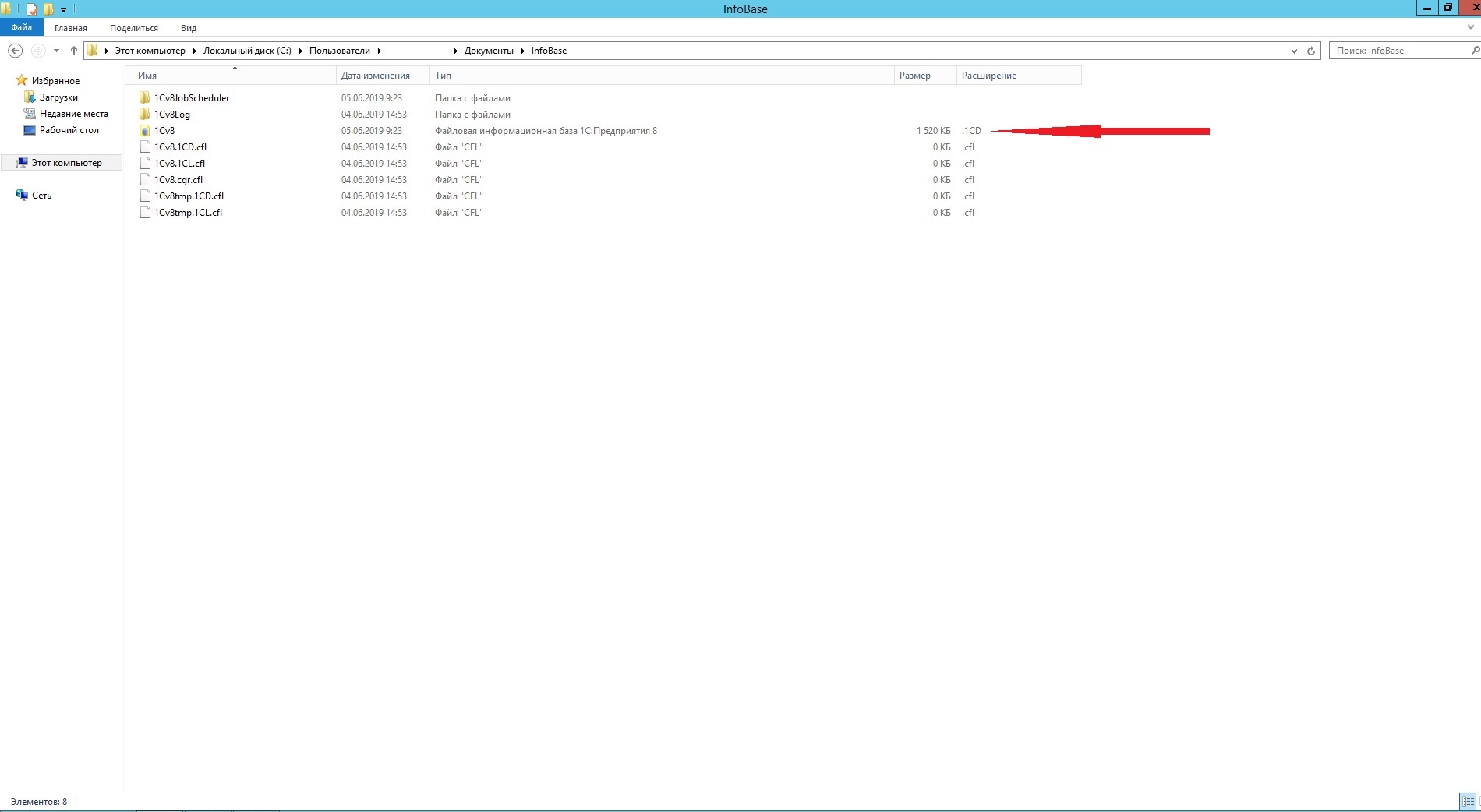
Если возникает необходимость очистки жёсткого диска, следует обращать внимание на файлы формата *.dt, так как они являются выгрузками базы (копии).
С появлением сервиса 1С:ФРЕШ выгрузка БД также может быть представлена файлом data_dump.zip, содержащий лишь данные, введённые в БД в пользовательском режиме, с описанием структуры метаданных, но без их непосредственного наличия.
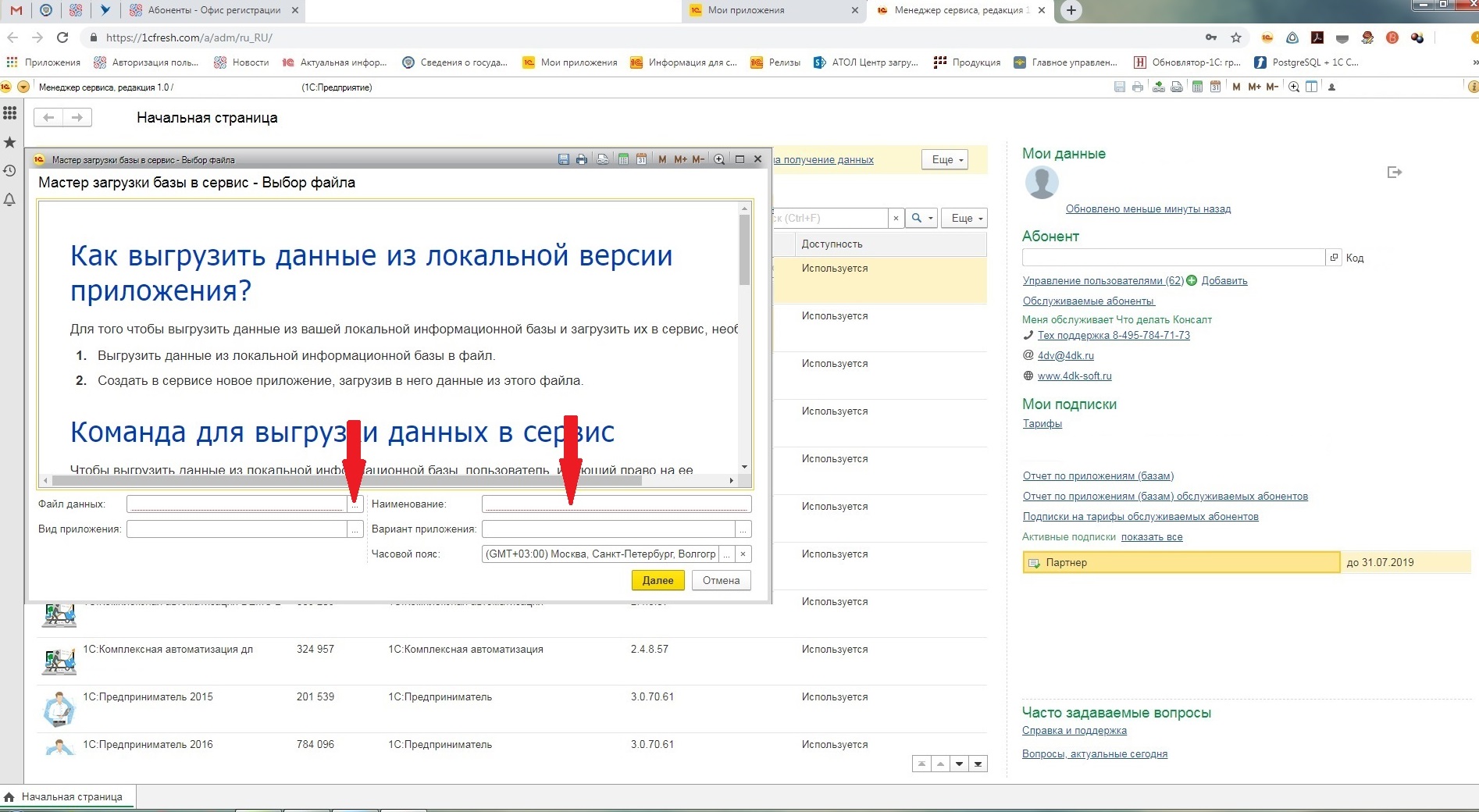
Выгрузка данных из локальной версии БД в облачную
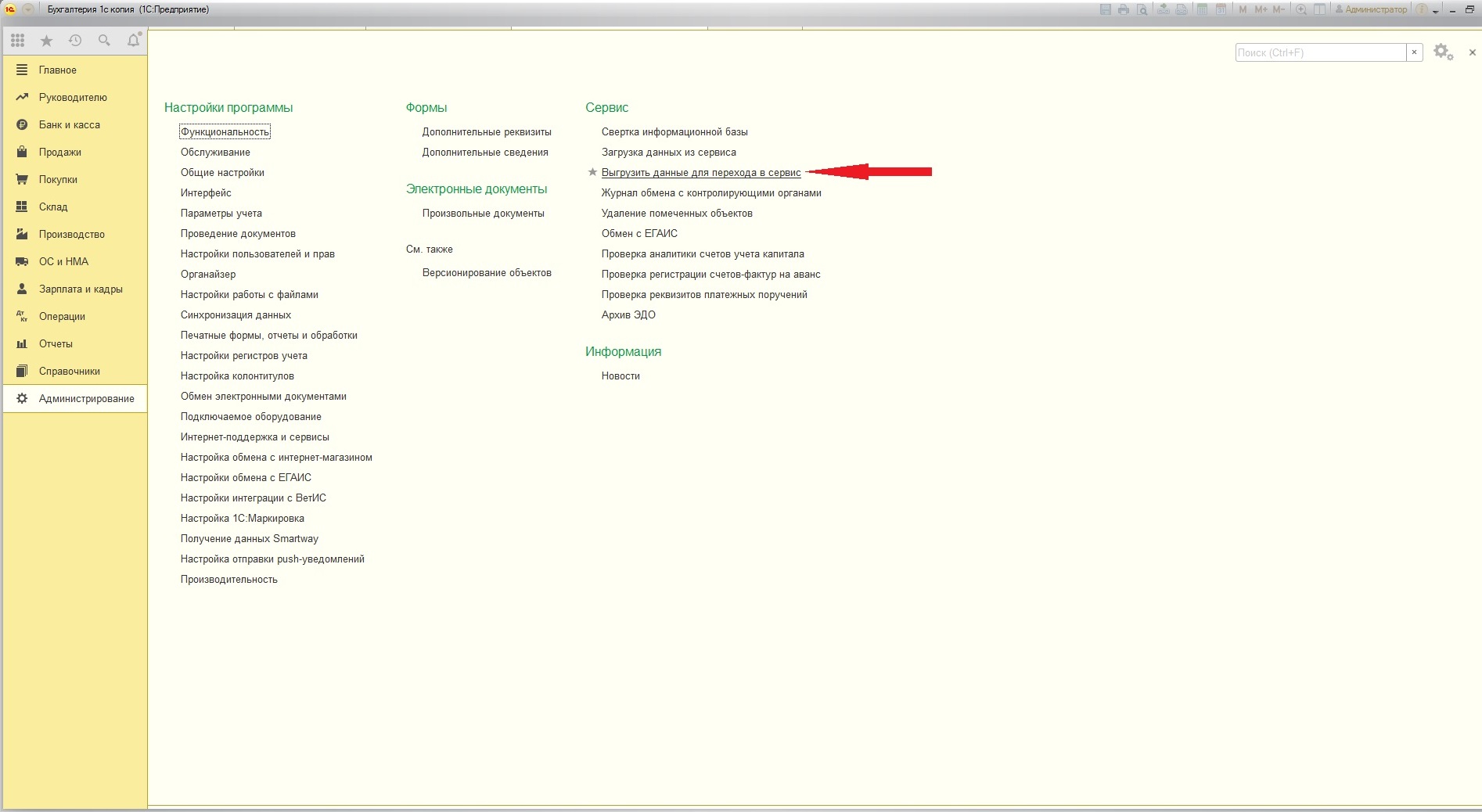
Загрузка данных из локальной версии БД в облачную
В данной статье мы рассмотрели наиболее частые варианты работы с файлами в 1С. Если вопросы всё же остались, мы будем рады вам помочь. Вам всего лишь нужно обратиться на Линию консультаций 1С компании «Что делать Консалт». Первая консультация совершенно бесплатная!
Всем привет. Как-то мне поступило задание прикреплять PDF файлы к документам в 1С, при том что было много документов и один многостраничный PDF файл, который необходимо было разделять на странички и каждая страница соответствовала определенному документу. Естественно мне хотелось автоматизировать полностью весь процесс, чтобы 1с сама разделяла файл PDF на листы, прочитывала каждый лист и сопоставляла его с документом. Я нашла решение и прикрепляю программы, которые мне в этом помогли:)
Программа Pdftk server позволила мне узнать сколько страниц есть в файле PDF:
Далее программа Pdftk server при помощи команды "cat + "номер страницы" + output" разбила мне файл PDF по страницам в цикле:
В итоге у меня в папке есть много файлов PDF по одной страничке, теперь мне необходимо прочитать каждый файл при помощи программы PDF2TXT:
Вот ссылки на программы:
Мы создали текстовый файл в кодировке UTF-8, теперь его нужно прочитать:
Вот где я скачала программу-помощницу:
Инструменты XPDF (по ссылке скачать инструменты xpdf, в архиве найдете pdftotext, остальные файлы не нужны)
Надеюсь, моя работа поможет многим!)
Специальные предложения







(0) (1) Можно воспользоваться tesseract ocr (смотрите на github'е)
Там крайне много возможностей, в том числе можно получать не только сырой текст, но и положение онного на странице.
Ставиться не сложно, на лине так вообще одной строкой в терминале.
Под винду уже есть собраные версии.
(1)Наше то,. что долго искал.
Есть вопрос - попробовал использовать закомментированный кусок кода:
Платформа благополучно отъезжает.
На сохранении файла - работает корректно все.
Этот метод работает?
Я в свое время тоже разбирался с разбиением ПДФов. Мне понравилась программа GostScript, в ней разбиение многостраничного файла делается одной командой: вот строка из bat-файла
call "C:\Program Files\gs\gs9.20\bin\gswin64.exe" -q -dSAFER -dBATCH -dNOPAUSE -sDEVICE=jpeg -r100 -sPAPERSIZE=a4 -sOutputFile="Z:\!\doc-%03d.jpg" "Z:\!\1234.pdf"
Здесь:
"Z:\!\1234.pdf" - путь к многостраничному фалу
-sOutputFile="Z:\!\doc-%03d.jpg" - параметр говорит о создании файлов по маске (1 страница - 1 файл): doc-001.jpg, doc-002.jpg, doc-003.jpg, .
В свое время остановился, на попытке понять как обработать не 1, 2, 3 многостраничный файлов, а 100+ (так до конца и не разобрался с параметрами). Может время придет - вернусь к работе
Без компонент, на двоичных данных бы. За такое и 10 $m не жалко будет!Где-то на ИС встречал в комментариях "Количество страниц в PDF-файле". (6) интересно. хотелось бы, а то этот конвертер PDF2TXT на 30 дней, еще ключи искать, бесплатную прогу найти пока не смогла
(7) Можно воспользоваться tesseract ocr (смотрите на github'е)
Там крайне много возможностей, в том числе можно получать не только сырой текст, но и положение онного на странице.
Ставиться не сложно, на лине так вообще одной строкой в терминале.
Под винду уже есть собраные версии.
UPD:
Если вопрос стоит как "искать ключи", то очивидный FineReader очивиден, дальше торрентов искать не придеться ;-)
Также практически на 100% уверен, что у гугла есть подобный вебсервис, там вроде хотели денюжек, но крайне мало и возможно есть "триал".
(27) посмотрите я дополнила статью, нашла бесплатное приложение pdftotext, работает тоже из командной строки :)Для ковыряния двоичных данных под окнами лучше использовать бесплатный HxD
(6) (7) Из личного: для решения описанной задачи (0) мы сначала воспользовались программой ABBYY Scan Station (ABBYY - по запросу спокойно предоставляет 30-дневный ключ, спокойно предоставили продление еще на 1 месяц, для тестов), после чего мы сделали приобретение, т.к. софтина ОЧЕНЬ проста в настройке и хорошо выполняет обозначенную задачу (но без распознавания).
Единственный ее недостаток и весьма значительный - это не возможность ее запустить с командной строки - то есть нет запуска по расписанию.
Но из плюсов я бы назвал цену 2-3 года назад она составляла 24 000 руб. или 10 часов франча (на тот момент).
Так мы поигрались наверное с год, пока мне не надоело запускать каждый день данную сфотину и мы приобрели ее расширенную версию - ABBYY Recognation Server. В данной софтине настроек и возможностей поболее - работает на УРА уже 1,5 года. Есть еще распознавание и индексирование - последнее требует работу оператора (при приобретении удалось зачесть стоимость ранее приобретенной ABBYY Scan Station).
По ценам уже значительно дороже и цена зависит от количества распознанных страниц в месяц. На сегодня у нас 50к страниц и этого пока хватает (1 числа каждого месяца счетчик сбрасывается).
Цены опять же в открытых источниках не найти, но я их так же приведу для понимания: Сама программа + лицензия на 15к страниц - 215 000 руб, апгрейд с 15к до 50к страниц- 170к руб, апгрейд с 15к до 100к страниц - 247к руб (цены на июль 2016)
Стоимость разовая и в дальнейшем доплат не требует.
Это не реклама , просто показал, что решили использовать у нас в организации. Иногда может быть значительно эффективнее купить готовый продукт, чем писать свое с нуля. С нуля для разработчика хорошо - ты учишься работать с "новым", но работодатель не всегда может быть заинтересован оплачивать таким образом твое обучение, если стоит вопрос в сроках и качестве (ведь сколько еще времени уйдет на отладку "подводных камней").
(17) погодите с категоричностью. Я уже изложил, что раз в пользовательском варианте возможность сделать это есть, должна быть и в программном.
(18) ничего там такого нет. Только в разрешенные поля внести текст, больше ничего. Это просто бланки с графическим оформлением. Причем, это оформление сыпется при попытке именно изменить pdf. Внести данные текстовые поля - никаких проблем, пользователь может легко это сделать и сохранить результат.
Соббсно, вроде как из jsсript в рамках страницы можно достучаться до форм внутри
>раз в пользовательском варианте возможность сделать это есть, должна быть и в программном.
это ложная ассоциация
(25) можно. Я ж об этом и говорил. Но через jscript из 1С немного неудобно. Во-первых, java практически не знаю, то есть, у меня нет примеров обращений к объектам, из которых можно было бы как-то подчерпнуть методы и/или имена объектов. Во-вторых, 1С для работы даже через java все равно требуется COM-объект, имя которого мне неизвестно.
(26) если Вам неизвестно решение, это не значит, что его нет. Или Вы - сотрудник Adobe и знаете наверняка? Да и насчет ложности могу сказать, что у меня большие сомнения в том, что такая фирма как Adobe не предусмотрела чего-то такого.
(28) мне на надо быть сотрудником адоба
помню они чего-то в jscript докручивали у себя не так давно - pdf с "плохим" внедренным скриптом мог сделать что-то вредоносное на компе(34) открылась форма, а поверх другая со смещением - куда кликать будешь?
(39) Т.е. заполнение будет происходить на экране, хоть и программно?
А если Esc нажмут?
Может не заниматься копанием канала выданной лопатой?
А сделать "Дано" > "Надо" простым способом?
Задача то отвлекаясь от PDF какая?
Или вообще нафик эти PDF и с чем то другим работать (начальные PDF можно сконвертить на другом компе/сервере)
все клиенты (банк или биллинг) что видел допускали кроме pdf еще экспорт в xls или csv как минимум.
парсинг pdf это "распечатать 2 камаза бумаги, чтобы потом эти 2 камаза распознавать"
(44) Задача - данный pdf (и именно его и именно в pdf), нарисованный в векторе (и именно поэтому не допускающий переконвертаций, дабы не потерять расцветку для типографии) заполнить и сохранить в виде другого pdf. Заполнение изначальным pdf-ом предусматривается (так называемая, форма заполнения) и работает в пользовательском режиме в Acrobat Reader. Мне необходимо тоже самое провернуть программно из 1С.
(44) забыл сказать, софтовая расширяемость практически отсутствует. Клиентов не уговорить поставить что-то еще.
(46) pdf в векторе для типографии. )) откройте для себя корел дроу.
(47) у клиентов есть интернет?
просто задача из разряда хочу на легковушке гараж перетащить.
варианты решения:
1. имитация из 1С действий юзверя по работе с реадером
2. отправка исходника и данных заполнения на другой комп/сервер возможно через инет
3. установка доп.софта, любого от полного акробата или корел дроу или ВК для 1с
(48) В котором и делались эти pdf и который никто не собирается покупать. Он стоит только у дизайнера этих pdf.
(49) Ни одно из решений не является приемлемым.
1. Лишние окна.
2. Куда? И зачем? Как будто кто-то одобрит установку софта на другом компе той же компании. А свой домашний я этим нагружать не стану, и уж тем более, он не будет включен, пока я на работе, это электричество это никто не оплатит.
3. Не обсуждается даже. ВК разве что протолкнуть, и то, если для ее установки нужны права администратора (а скорее всего так оно и есть) - админ не пропустит.
Есть версии, подходящие под условия, которые у меня имеются?
(50) есть. ценник озвучьте для операций на гландах. ректально
сразу все появится и админский доступ и софт какой надо купят и поставят
А если серьезно, расценки назначаю не я, так что выставить дикий ценник попросту не в моих силах.
а зачем нужно именно в пдф засовывать данные?
и потом из 1с просто в нужные места печатать что надо?
Блин, сейчас сижу и попросту не въезжаю. неужели без извращений и окольных путей не существует варианта приобщить 1с к Adobe Reader?
(56) я так понимаю, проблема не в приобщении, а в том, что адобе ридер не предоставляет COM-интерфейса, который позволял бы автоматизированно заполнять PDF формы. Т.е. вопрос в данном случае к фирме адобе, а не к 1С.
(57) Может, и так. Хотя на java можно это сделать, очевидно, через иной интерфейс. Тут вопрос в том, что java я почти не знаю, а хоть сколь-нибудь рабочего примера, на который можно было бы опереться в экспериментах, найти не удалось.
(59) я точно знаю, что из 1С можно дотянуться через javascript до глубин OpenOffice, уже проделывал это (но у меня был под рукой sdk и множество рабочих примеров, которые я, правда, переводил из, кажется, vb на 1С). Можно ли через те же скрипты дотянуться до ридера - фиг знает.
(61) спасибо, но это перебор. И что-то мне подсказывает, что эта компонента несколько иначе реализована, чем мне нужно, то есть даже разобрав ее, я не получу искомого. То есть, такой функционал - явно больше, чем можно получить от ридера.
(62) Отпишись если решишь задачу в заданых условиях.
Как вариант через скрипты операционки иметировать деятельность пользователя, но боюсь документы не имеют шаблона.
(13) По поводу этого AcroExch. только что проверил идею.
на компе полный Акробат не стоит. Попробовал в Ворде вставить объект "Adobe Acrobat Document", сохранив действия в макрос. Вот что получилось:
Sub Макрос1()
Из чего делается предположение, что AcroExch - таки объект Ридера. И работать с ним - можно. И обращаться к его коллекции Fields, и прописывать в нужные поля ФИО участника семинара, название, город, и проч.
Ну а дальше - пробуйте. Результат очень интересен и полезен. Хотелось бы, чтобы у Вас получилось! Успехов!

![]()
skype: live:di-sem

@programmist_1C
Импорт в 1С данных из любых документов (сделать свою обработку импорта из внешних источников))
Часто нужно импортировать данные в 1С из внешних источников (Excell,Word,Pdf,Txt, Csv, Html и т.д.).
Чтобы не подключаться к каждому документу через Com объект, нужно создать свою обработку импорт из внешних источников в 1С.
В типовых конфигурациях есть такая обработка.
В данном примере мы будем создавать свою.
Алгоритм
1 В табличный документ подгружаем нужный макет
2 Пользователь копирует в табличный документ нужные данные
3 Программа 1с анализирует данные и готовит их к загрузке в нужные объекты 1с (документы/справочники)
4 Загрузка данных
Реализация
1 Создаем форму
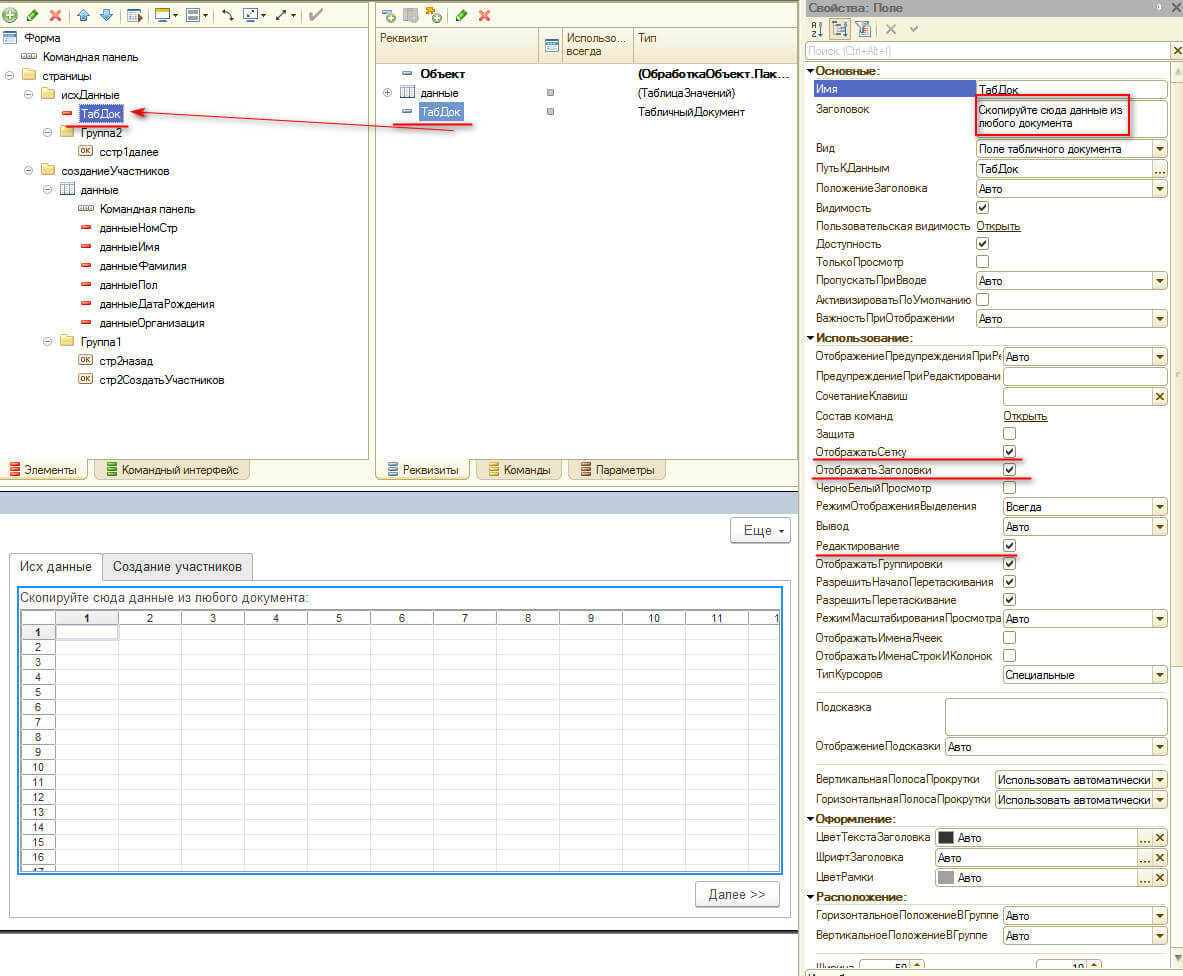
Создаем реквизит формы ТабДок - табличный документ.
В него пользователь будет копировать нужные данные, а наша задача будет программно взять их оттуда и загрузить в 1С.
Перетащим реквизит ТабДок на форму и установим свойства как на рисунке.
Но сейчас ТабДок представляет собой обычный неразмеченный документ.
Куда будет пользователь грузить нужные колонки.
Для этого мы создадим макет:
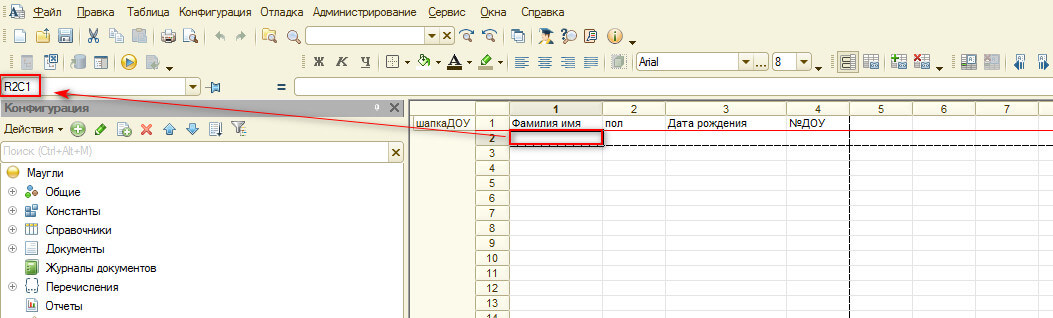
При открытии формы мы подгрузим этот макет в наш табличный документ "ТабДок" и пользователь будет знать куда ему грузить данные.
На рисунке я выделил где можно посмотреть адрес ячейки, адрес нам понадобится при импорте данных.
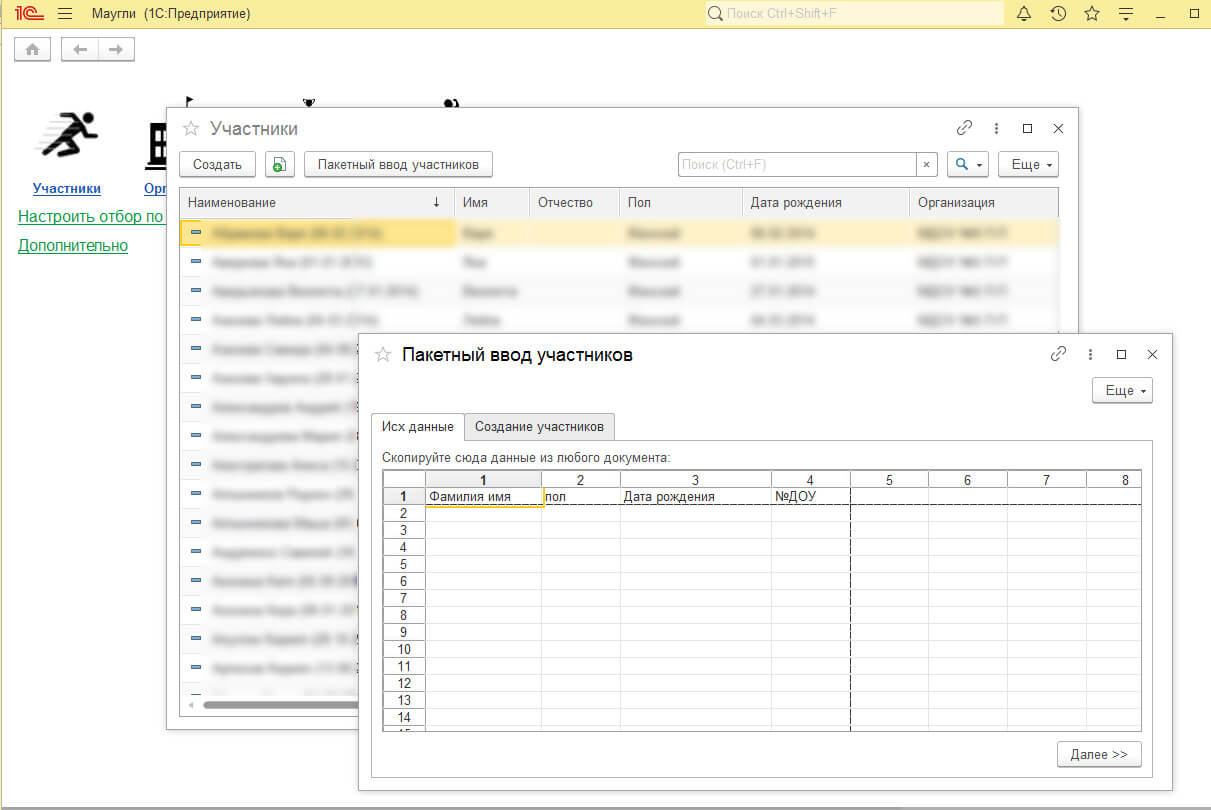
Создадим на форме реквизит "Данные" - таблица значений.
Сюда мы предварительно будем грузить введенные пользователем данные.
Это нужно для того чтобы пользователь мог скорректировать введенные данные, а мы могли бы ему точно указать на ошибку в загружаемых данных.
Реквизит "Данные" перенесем на другую страницу. В моем случае это "Создание участников".
.jpg)
Создадим процедуру, которой мы загрузим данные в 1с в таблицу значений "Данные", которую создали ранее и вывели на вторую страницу.
Работает это так:
1 открываем обработку ввода данных:
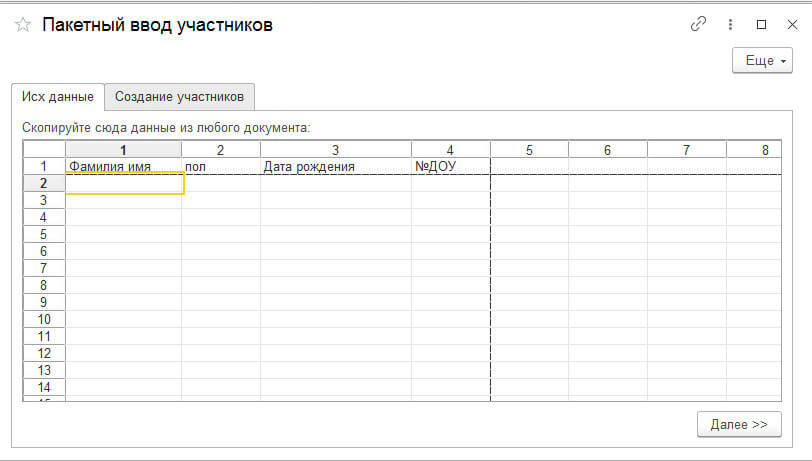
2 копируем нужные данные из Эксель для импорта в 1С:
3 Вставляем в 1С в нашу обработку:
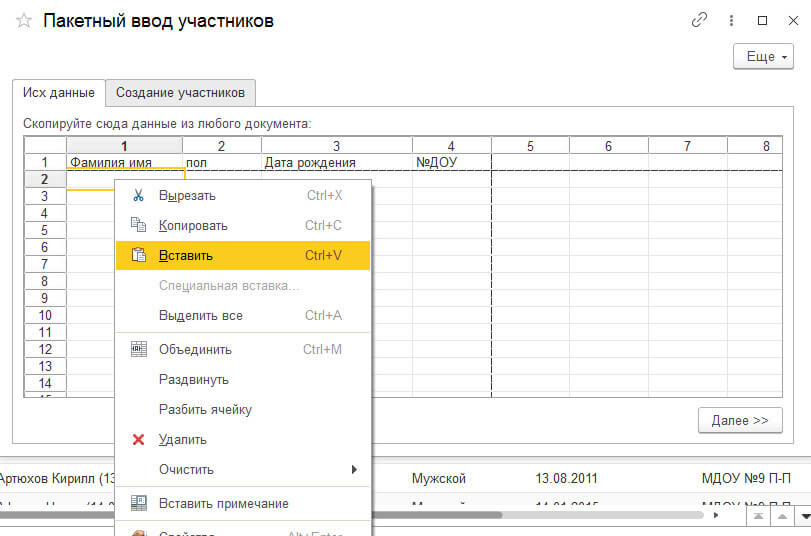
4 Смотрим чтобы данные соответствовали столбцам:
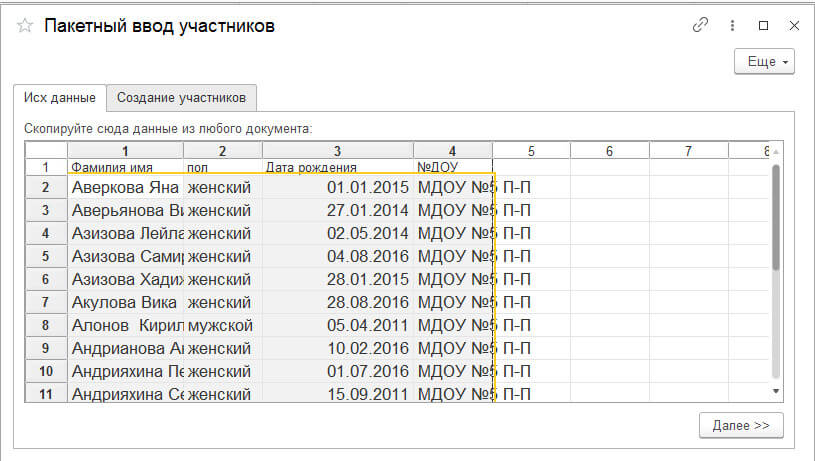
5 Жмем далее (этой кнопкой вызывается процедура, указанная выше) и получаем результат:
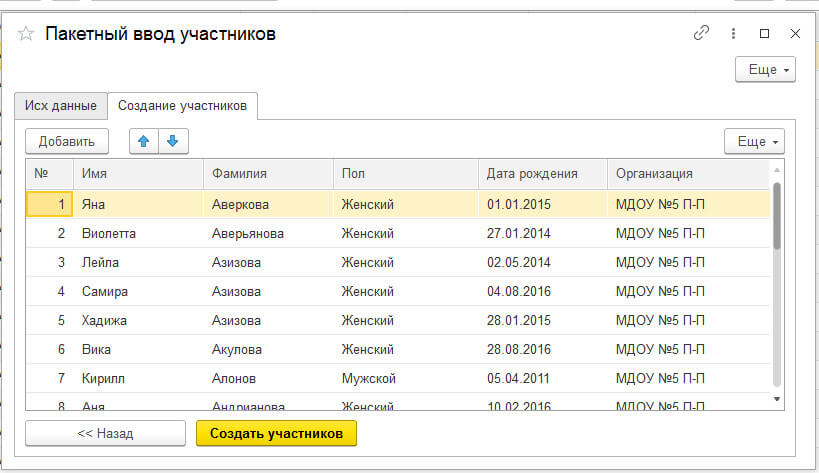
Мы получили данные в 1С. Теперь при нажатии "Создать участников" будут созданы элементы справочника "Участники".
Читайте также: