
Какая активность используется для считывания таблицы из браузера
Обновлено: 04.07.2024
В этой статье будет решение для 3.1 и 3.2 (экзаменов). Эти уроки – самые первые и самые легкие экзамены на всем курсе. Первая часть (3.1) вся состоит из вопросов, в то же время, как вторая задача, на 100% состоит из задач на программирование.
- Какая команда используется для вывода (печати) данных?
Ответ: print()
2. Выберите верные строки кода.
Верные решения:
3. Необходимо выбрать корректную строчку кода
4. Что выведет следующий код print('1', '2', '3', '4', sep='*') ?
Решение: 1*2*3*4
5. Выберите верные строчки кода.
Верные:
- print("The world's a little blurry", "Or maybe it's my eyes", end='. ', sep=' :) ')
- print("Told you not to worry", "But maybe that's a lie", sep=' :) ')
- print("Honey, what's your hurry", end='?')
6. Какая команда используется для считывания данных с клавиатуры?
Правильный вариант ответа: input()
7. Какая из указанных строк считывает целое число в переменную n ?
Решение: n = int(input())
8. Выберите верные утверждения.
Ответ:
- Имя переменной не может начинаться с цифры
- Имя переменной не может совпадать с ключевым (зарезервированным) словом
- Имя переменной может начинаться с символа подчёркивания (_)
9. Какое число выведет следующий код?
10. Какое число выведет следующий код?
Звездный прямоугольник
Напишите программу, которая выводит прямоугольник, по периметру состоящий из звездочек (*).
Примечание. Высота и ширина прямоугольника равны 44 и 1717 звёздочкам соответственно.
Сумма квадратов VS квадрат суммы
Напишите программу, которая считывает два целых числа aa и bb и выводит на экран квадрат суммы (a+b)^2(a+b)2 и сумму квадратов a^2+b^2a2+b2 этих чисел.
Формат входных данных
На вход программе подаётся два целых числа, каждое на отдельной строке.Формат выходных данных
Программа должна вывести текст в соответствии с условием.
Большое число
Как известно, целые числа в языке Python не имеют ограничений, которые встречаются в других языках программирования. Напишите программу, которая считывает четыре целых положительных числа a, \, b, \, ca,b,c и dd и выводит на экран значение выражения a^b + c^dab+cd.
Формат входных данных
На вход программе подаётся четыре целых положительных числа a, \, b, \, ca,b,c и dd , каждое на отдельной строке в указанном порядке.Формат выходных данных
Программа должна вывести значение a^b + c^dab+cd.
Размножение n-ок
Напишите программу, которая считывает целое положительное число n, \, n \in [1; \, 9]n,n∈[1;9] и выводит значение числа n+\overline+\overlinen+nn+nnn.
Формат входных данных
На вход программе подаётся одно целое положительное число n, \, n \in [1; \, 9]n,n∈[1;9].Формат выходных данных
Программа должна вывести число n+\overline+\overlinen+nn+nnn.Примечание. Для первого теста 1 + 11 + 111 = 1231+11+111=123.
Активность можно отслеживать только в текущей вкладке. Это банальные требования к безопасности и конфиденциальности браузера.
Если пользователь увел мышь за пределы окна текущей страницы, то вы никак не отследите движения и активность.
Если пользователь переключился на другую вкладку, то вы никак не отследите активность там из вашей вкладки. Нужно иметь скрипт в той вкладке. Например, браузерное расширение, которое добавляет юзерскрипт ко всем вкладкам. И даже расширение не сможет поймать мышь на элементах браузера, которые не являются частью страницы - меню, строка адреса, панель закладок и прочее.
Посмотрите Motivate Clock - это старый проект, один из первых, кто стал измерять время пользователя, потраченное на разные задачи. В какой-то момент они сделали также и расширение для браузера, чтобы там отслеживать активность. Можете у них поучиться всякому.
Ну а активность вне браузера через JS ясное дело тем более нельзя отслеживать. К сожалению разработчиков. И к спокойствию юзеров, что сайты за ними не следят. Нужно делать нативное приложение для ОС.
Chrome Remote Desktop - расширение к браузеру, которое позволяет получить доступ к машине пользователя вне браузера, т.е. какой то api на это имеется, изучите его или код расширения, хотя бы сможете реализовать задуманное в виде плагина.
Для firefox или safari стандарта на это вроде бы нет.
p.s. но зачем так извращаться?

Хочу написать таймтрекер, так как то, что сейчас есть - это боль (даже среди платных программ)
А трекер работающий в браузере решил бы вопрос кроссплатформенности.
Вы выбрали плохой инструмент для решения этой задачи.
Боюсь совсем уж кроссплатформенно собирать пользовательские действия с клавиатурой и мышкой не получится, нужно либо брать чей то проект либо пилить самому. Как минимум для windows и linux придется писать сильно разный код.
Автотесты, использующие Selenium, работают медленно уже потому, что пользовательский интерфейс сам по себе тяжёлый и неповоротливый. Действия через него выполняются дольше по сравнению с сетевыми запросами или обращениями к API, потому что результат нужно визуализировать, на это тратится время и ресурсы.
Увы, на этом проблемы с производительностью не заканчиваются. Чтение данных из пользовательского интерфейса тоже может занять много времени, если это делать неправильно.
Давайте рассмотрим такую задачу. Есть страница с информацией о столицах разных стран в виде таблицы, нужно прочитать эту информацию и представить её в виде словаря (ассоциативного массива).
Прямолинейный способ решения выглядит так (код на языке Python, открытие страницы вынесено за пределы функции):
Нашли таблицу, получили список строк (исключая заголовок), в цикле каждую строку разбили на ячейки, взяли текст ячеек и построили словарь из полученных данных.
Вроде бы всё логично, но… очень медленно.
Выполнение этой функции в браузере Internel Explorer 11 на моей машине занимает примерно 30 секунд. Полминуты! Никаких действий, только чтение данных.
Почему так долго? Потому что выполняется много обращений к браузеру.
В таблице содержится 196 строк с данными (заголовок не считаем). Следовательно, для чтения названий стран и столиц из ячеек потребуется 196*2=392 обращения к браузеру. Ещё 196 обращений нужно для разбиения каждой строки на ячейки. И ещё одно для поиска таблицы, но это уже незаметно на общем фоне.
Итого 589 обращений к браузеру. Каждое занимает примерно 50 миллисекунд, но их много.
Быстрый браузер
Одна из причин низкой производительности – медленный браузер (или драйвер браузера, но в данном случае это неважно).
Что будет, если вместо Internet Explorer взять Chrome, который среди пользователей Selenium считается самым быстрым?
Время выполнения сразу падает до 6 секунд. Неплохо!
А как думаете, сколько времени будет загружать данные Firefox? Тоже 6 секунд? 10? 15?
Неправильно. 3 секунды! В два раза быстрее, чем Chrome! И в десять раз быстрее IE (результаты получены на Firefox Nightly 54.0a1 + geckodriver 0.13.0).
| IE 11 | Chrome | Firefox | |
|---|---|---|---|
| by_rows | 29.3835 | 6.3087 | 2.9712 |
Конечно, это не означает, что Firefox во всех случаях обгоняет Chrome, но данные со страницы он читает явно лучше.
Чтение по вертикали
А что делать тем, кто вынужден использовать медленный браузер? Предположим, что ваше приложение работает только в Internet Explorer. Так иногда случается с “энтерпрайз”-приложениями. И – вот совпадение! – там часто бывает много данных.
Надо придумать способ уменьшить количество обращений к браузеру.
Для получения ячеек таблицы вовсе необязательно анализировать каждую строку таблицы и тратить на это 196 обращений. Можно читать таблицу по столбцам, а не по строкам, ведь нам нужно загрузить данные всего из двух столбцов:
Загружаем список ячеек в первом и втором столбцах – два обращения к браузеру, из каждой ячейки извлекаем текст – ещё 392 обращения к браузеру, а потом “спариваем” два получившихся списка строк.
Итого 394 обращения. В прошлый раз, напоминаю, было 589.
При таком способе загрузки данных можно ожидать сокращения времени примерно в полтора раза для всех браузеров. Так и есть:
| IE 11 | Chrome | Firefox | |
|---|---|---|---|
| by_rows | 29.3835 | 6.3087 | 2.9712 |
| by_cols | 19.9307 | 3.9300 | 2.0570 |
Мимо браузера
Вот если у приложения есть специальный программный интерфейс (API), нацеленный на получение нужных данных – тогда да, обязательно надо его использовать. Но если нет – может быть стоит вернуться обратно в браузер и поискать там другие возможности ускорения?
Use the source, Luke!
Что мы сделали в предыдущем примере? Мы получили исходный код страницы в обход браузера. Но почему бы не взять его прямо из браузера?
Теперь Selenium не используется для поиска элементов на странице и для получения их текста. Мы обращаемся к нему один единственный раз, чтобы загрузить код страницы в формате HTML, а затем при помощи совсем другого инструмента (в данном случае lxml) анализируем этот код.
А что с производительностью? Смотрите сами:
| IE 11 | Chrome | Firefox | |
|---|---|---|---|
| by_rows | 29.3835 | 6.3087 | 2.9712 |
| by_cols | 19.9307 | 3.9300 | 2.0570 |
| by_page_source | 0.0360 | 0.0210 | 0.0192 |
Фантастика! Мы получаем нужные данные за сотые доли секунды в любом браузере!
Для Internet Explorer ускорение в 1000 раз по сравнению с первым способом. Для “быстрого” Firefox производительность улучшилась “всего лишь” в 100 раз. И при увеличении количества данных эта разница будет только возрастать.
Возникает резонный вопрос – а если из браузера взять исходный код не всей страницы целиком, а только нужной таблицы – может быть это ещё сильнее повысит производительность?
| IE 11 | Chrome | Firefox | |
|---|---|---|---|
| by_rows | 29.3835 | 6.3087 | 2.9712 |
| by_cols | 19.9307 | 3.9300 | 2.0570 |
| by_page_source | 0.0360 | 0.0210 | 0.0192 |
| by_table_source | 0.1180 | 0.02818 | 0.0278 |
То ли Selenium тратит дополнительное время на поиск таблицы, то ли браузер код страницы строит быстрее, чем код отдельного элемента. Не знаю. Но факт тот, что это снижает производительность, а не увеличивает. Хотя не исключено, что на других страницах ситуация поменяется.
JavaScript
Есть ещё один способ получить нужные данные за одно единственное обращение к браузеру – выполнить фрагмент JavaScript-кода, который сразу вернёт то, что надо:
Операции, которые ранее выполнялись на языке Python – поиск элементов на странице, получение текста элементов – теперь переписаны на JavaScript и перенесены на сторону браузера. Правда, реализация Selenium для Python не умеет правильно обрабатывать ассоциативные массивы, возвращаемые из функции execute_script, поэтому пришлось вернуть список пар, который затем средствами Python превращается в словарь. Если бы мы писали, например, на Java, можно было бы немного упростить выполняемый JavaScript-код.
Давайте посмотрим, насколько быстро работает этот способ:
| IE 11 | Chrome | Firefox | |
|---|---|---|---|
| by_rows | 29.3835 | 6.3087 | 2.9712 |
| by_cols | 19.9307 | 3.9300 | 2.0570 |
| by_page_source | 0.0360 | 0.0210 | 0.0192 |
| by_table_source | 0.1180 | 0.02818 | 0.0278 |
| by_js | 0.1783 | 0.0077 | 0.0201 |
Для IE и Firefox разница невелика, но посмотрите, что вытворяет Chrome – он ускорился ещё в несколько раз и теперь уж точно стал самым быстрым!
Резюме
Если сценарий работает медленно – это не приговор. Ищите участки кода, которые “тормозят”, и оптимизируйте их.
Конечно, ускорить работу тестируемого приложения вы не сможете. Но если в низкой производительности виноваты тесты – их можно и нужно исправлять.

Автор: Алексей Баранцев
Если вам понравилась эта статья, вы можете поделиться ею в социальных сетях (кнопочки ниже), а потом вернуться на главную страницу блога и почитать другие мои статьи.
Ну а если вы не согласны с чем-то или хотите что-нибудь дополнить – оставьте комментарий ниже, может быть это послужит поводом для написания новой интересной статьи.
В статье рассматривается работа с Excel -подобными таблицами (spreadsheet) Гугл через Web API этой службы (только чтение). А также практический пример использования Google Spreadsheet для простейшей организации службы поддержки Help Desk.
Организация службы поддержки с помощью Google Spreadsheet
Google Spreadsheet – это аналог таблиц Excel, с которыми могут работать несколько пользователей одновременно. Такой функционал позволяет развернуть на их базе простейшую коммуникацию специалистов службы поддержки.
При этом желательно добавить скрипт, который будет проставлять дату и время обращения при вводе текста в новую строку, чтобы не делать это вручную:
Инструменты — Управление скриптами, далее функция onEdit :
return (value < 10 ? '0' : '') + value;
var y = date.getUTCFullYear();
var l = twoDigit(date.getUTCMonth() + 1);
var d = twoDigit(date.getUTCDate());
var h = twoDigit(date.getUTCHours()+3);
var m = twoDigit(date.getUTCMinutes());
var s = twoDigit(date.getUTCSeconds());
return d + '.' + l + '.' + y + ' ' + h + ':' + m + ':' + s;
var range = event.source.getActiveRange();
var Row= range.getRow();
var timestamp = formatRfc3339(new Date());
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sheet = ss.getActiveSheet();
var cell = sheet.getRange(Row,2);
var shname= sheet.getName();
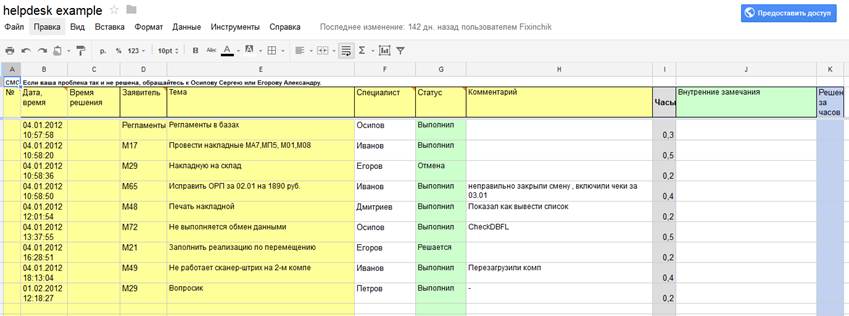
В таблице для организации службы поддержки используются следующие колонки:
- Дата, время – дата и время обращения
- Заявитель – кто обратился с заявкой
- Тема – тема, краткое содержание заявки
- Специалист – кто из специалистов поддержки взялся за задание
- Статус – статус задания
- Комментарий – комментарий по ходу выполнения
- Часы – затраченное на задание время
При этом простым пользователям можно прямо в 1С показывать состояние обработки заданий. Хотя, конечно, можно и давать ссылку на гугл-страницу, но иногда проще реализовать монитор заданий в 1С, чем объяснять пользователям куда ходить и смотреть. К тому же, можно скрыть часть служебной информации, отфильтровать записи и т.п.
Принципы чтения Google Spreadsheet
Описание API Google реализовано тут:
Нюансы, касающиеся аутентификации, рассмотрены тут:
По сути, любая гугл-таблица выступает как RSS- поток, который можно прочитать в виде XML- файла, разобрать и получить нужную информацию.
На практике для чтения публичных и приватных документов требуется указывать различные адреса потоков public/values и private/full соответственно, как это делается в коде обработки:
Демонстрационная обработка
Обработка реализована для чтения документа определенной структуры, поэтому нет поля ввода для чтения документа по другому адресу.
Читайте также: