Какая из трех моделей трансляции кода программы используется в java
Обновлено: 04.07.2024
Java — важный язык разработки во многих больших корпорациях. Мы уже рассказывали про то, как и где применяется Java, теперь настало время для практики.
Так как авторы языка Java при создании вдохновлялись языками C и C++, то в Java тоже появилось много похожих конструкций и команд. Если вы знаете C или C++, то освоить Java вам будет гораздо проще.
👉 В Java после каждой команды ставится точка с запятой.
Комментарии
Комментарии в Java точно такие же, как в C-подобных языках — есть однострочные, которые работают только для одной строки, и многострочные.
// Это однострочный комментарий
// Для каждой строки нужно добавлять его отдельно
/* А это — многострочный
его можно сделать любой длины,
если в начале и в конце поставить нужные символы */
Переменные и типы данных
Как и в C, в Java есть несколько типов данных с разным объёмом выделяемой памяти. Предполагается, что программист сам решит, какой тип использовать лучше всего в каждой ситуации и сам будет следить за тем, чтобы в переменную поместилось всё что нужно.
Присваивание и сравнение
Всё как и везде:
// это присваивание
x = 10;
// а это — сравнение x и 10
// результат сравнения отправляется в переменную b
boolean bol;
b = (x == 10);
Ещё есть метод сравнения .equal — он работает более гибко и предсказуемо, чем ==, потому что двойное равно может сравнивать только числа и строки.
Структура программы
Разработчикам Java понравилось, что в C вся программа состоит из функций, среди которых есть одна обязательная — main, поэтому сделали точно так же. В классах эта функция называется методом.
Но есть одно важное отличие: каждая java-программа — это как бы один большой класс со своими разделами, которые должны быть у каждого класса. Благодаря этому большие программы легко собираются из маленьких java-кирпичиков и работают друг с другом как с классами, используя все их возможности.
Ввод и вывод
Для ввода и вывода используют системный класс System и два его объекта — in и out. Но на практике чаще всего вместо in используют объект Scanner, чтобы можно было более гибко управлять вводом данных.
Условные операторы if и switch
Работают так же, как в C и в любых современных языках высокого уровня. Главное здесь — следить за фигурными скобками и не перепутать, что к чему относится. Проще всего это регулировать отступами:
У оператора множественного выбора есть особенность: ему не нужны фигурные скобки для действий в каждом случае. Компьютер по синтаксису понимает, что к чему относится, и выбирает нужный вариант.
Циклы
В Java есть три основных вида циклов:
- for — с известным числом повторений и счётчиком;
- do — с проверкой условия до цикла;
- while — условие проверяется после первого выполнения цикла.
Ещё есть два полезных оператора:
- break — прерывает цикл в любой момент;
- continue — сразу переходит к следующему витку цикла без выполнения остальных команд.
Функции (они же методы)
Так как каждая программа — это описание какого-то класса, то функции в Java — это и есть методы этого класса. Функций (или методов) может быть сколько угодно, главное — соблюдать правила описания классов. Покажем на примере:
Классы
В Java всё построено на классах, от самой программы до реализаций различных функций. Конечно, можно не использовать классы и работать в чисто процедурном стиле, но в Java так не принято. Это ООП-язык с родной поддержкой классов на всех уровнях.
Сами классы объявляются и используются так же, как и в любом другом ООП-языке:
Объекты
Объекты в Java работают по тому же принципу, что и все объекты в ООП: можно создавать сколько угодно объектов на основе классов и делать их любой сложности.
Обычно используют классы, прописанные в том же файле, что и программа. Если нужно использовать класс из другой программы, её подключают отдельно. Вот самый простой способ сделать объект на основе предыдущего класса с заказом:
Так получилось, что я много работал на С/С++ и не работал на Java. А теперь, смотрю, для мобильных платформ Java очень востребована. Я, как разумно-ленивый человек, хочу избежать полного изучения Java. Хотелось бы писать по-прежнему на С++, но чтобы транслировался С++-код не в нативный код, а в код для Java-машины.
- Есть-ли сейчас технологии, где С++-код транслируется не в нативный код для конкретной платформы, а в код для Java-машины? С тем, чтобы потом этот код выполнялся как Java-код на Java-машине на любой платформе.
По моим понятиям Java-код сейчас транслируется в некий промежуточный код для абстрактной Java-машины. На разных платформах есть JIT-транслятор, который при запуске этого кода переводит его в нативный код для данной платформы и запускает. Или я не прав?
Вроде бы чего проще. Взять транслятор GCC, оставить синтаксический анализатор а вместо кодогенератора под платформу x86 написать кодогенератор под Java-машину. Неужели еще никто не сделал такой гибрид?
Тогда второй вопрос, связанный с первым:
- Как распространяются Java-программы? Распространяются ли Java-программы в исходных кодах, или Java-программы распространяются в кодах для Java-машины?
Есть-ли сейчас технологии, где С++-код транслируется не в нативный код для конкретной платформы, а в код для Java-машины? С тем, чтобы потом этот код выполнялся как Java-код на Java-машине на любой платформе.
Есть парочка, но не факт что это работает для мобильных платформ и что этим реально удобно пользоваться при разработке:
NestedVM provides binary translation for Java Bytecode. This is done by having GCC compile to a MIPS binary which is then translated to a Java class file. Hence any application written in C, C++, Fortran, or any other language supported by GCC can be run in 100% pure Java with no source changes.
GCC-Bridge is a C, C++ and Fortran to Java bytecode compiler. GCC-Bridge uses GCC as a front end to generate Gimple, and then compile Gimple to a Java class file.
Спасибо за информацию. Судя по тому, что все самый свежий из этих проектов заглох 2 года назад, тема действительно не востребована. @pepsicoca1 на мой взгляд проще java освоить, чем работать с этими инструментами. [проще java освоить] Тут одно связано с другим. Если бы тема была востребована, то эти инструменты довели бы до коммерческого использования. И народ работал бы на С++ и транслировал бы код для JVM.The C to JVM bytecode compilation provided by LLJVM involves several steps. Source code is first compiled to LLVM intermediate representation (IR) by a frontend such as llvm-gcc or clang. LLVM IR is then translated to Jasmin assembly code, linked against other Java classes, and then assembled to JVM bytecode.
Давайте по порядку:
Есть-ли сейчас технологии, где С++-код транслируется не в нативный код для конкретной платформы, а в код для Java-машины?
Такие технологии есть, но только в виде некоего research'а в глубочайшем бета, а продуктиве нет таких технологий.
По моим понятиям Java-код сейчас транслируется в некий промежуточный код для абстрактной Java-машины. На разных платформах есть JIT-транслятор, который при запуске этого кода переводит его в нативный код для данной платформы и запускает. Или я не прав?
Как бы верно, но вся проблема в том, что эта работа производится на стороне виртуальной машины, то есть JVM получает байткод и отправляет его JIT, который переводит его на платформенно-зависимые инструкции.
Вроде бы чего проще. Взять транслятор GCC, оставить синтаксический анализатор а вместо кодогенератора под платформу x86 написать кодогенератор под Java-машину. Неужели еще никто не сделал такой гибрид?
Нет не проще, в С/С++ управление памятью это забота программиста (средства языка), а в Java это функционал, который решается средствами JVM (вне самого языка) - пока вы не устраните это противоречие вы не получите полноценную С/С++ в смысле семантики.
Как распространяются Java-программы? Распространяются ли Java-программы в исходных кодах, или Java-программы распространяются в кодах для Java-машины?
Java программы распространяются в виде объектных кодов .class собранных в архивы .jar/ear/war/zip
Для Android обычно упаковываются в архивы APK , которые содержат байткод инструкции транслированные в виртуальную машину Android (она не совпадает с байкодами JVM)
Update
По VM в Android. Dalvik и ее более новая инкарнация ART - отличаются от Sun JVM тем, что Android машинка имеет регистрориентированную архитектуру в отличие от сановской которая имеет стекориентированную архитектуру, что влечет за собой экономию оперативной памяти актуальной для телефонов/смартфонов.
Dalvik начиная с версии 2.2 имеет JIT, которые компилируется в нативные коды в момент первого запуска, в ART используется ее аналог которые называется AOT (Ahead-Of-Time) который компилирует в нативные коды уже в момент установки.
Java Reactive асинхронное и параллельное программирование
【Аннотация】 Реактивное программирование - это асинхронная и параллельная «серебряная пуля / артефакт» в глазах большинства людей. В этой статье анализируется принцип реактивного выполнения и показано, что реактивное программирование На основе данных , Не "событие". Реактивное программирование разделено на три основных этапа проектирования: подготовка источника данных, моделирование потока данных и распределение диспетчера для достижения асинхронного параллельного выполнения. Наконец, мы даем схему проектирования и программирования расчетной модели на основе графа потока данных.
Большие данные и облачные вычисления (облачные сервисы) превращают реактивное программирование в новое поколение программных артефактов. Хотя модель реактивного программирования значительно упрощает асинхронное и параллельное программирование, это ни в коем случае не является низким порогом. Сначала необходимо изменить режим вычислений традиционной последовательной обработки и установить модель вычислений, ориентированную на поток данных; затем вам необходимо хорошо знать потоки, сопрограммы и другой параллелизм для написания безопасных приложений; а также необходимо некоторое функциональное программирование. Знания, такие как лямбда, замыкания и т. Д. Эта статья пытается описать самые базовые знания, необходимые для реактивного программирования, и использует некоторые примеры, чтобы вы могли испытать магию и элегантность реактивного программирования.
1. Подготовьте знания
В реактивном программировании Java используется библиотека RxJava. Хотя она совместима с программированием на Java 5, вы потеряете удобство, которое предоставляет Java 8, например, поддержку асинхронных функций, таких как лямбда-выражения и CompleteableFuture. Дело в том, что без лямбда-функций реактивные Java-программы практически не читаются!
1.1 Конфигурация среды программирования
1. Конфигурация файла проекта
Требуется файл конфигурации maven pom.xml
2. Настройки IDEA
- File -> Project Structure -> Project
- File -> Project Structure -> Modules
- File -> Setting -> Build -> Compiler -> Java Compiler
1.2 Лямбда-выражение
Сейчас не так много языков, которые не поддерживают лямбда-выражения. В Java он в основном используется как анонимная реализация интерфейса с одним методом. Например:
Лямбда-выражение Синтаксис, например:
| Argument List | Arrow Token | Body |
|---|---|---|
| (int x, int y) | -> | x + y |
2、 Future<V> И многопоточное программирование
Future<V> Это общий интерфейс, если исполняемая функция (класс, реализующий Callable или Runable) работает в потоке, используйте Future<V> Вы можете использовать его метод get (), чтобы вернуть результат типа V. Обратите внимание, что get () заблокирует текущий поток. Например:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- static ExecutorService executor = Executors.newCachedThreadPool();
- Executors возвращает потоковую модель для запуска потоков;
- newCachedThreadPool () создает пул потоков кэша, часто используемый для управления потоками, блокирующими ввод-вывод.
- newFixedThreadPool (int nThreads) Создать пул потоков для управления вычислительными требованиями, n = cpu * 2;
- newSingleThreadExecutor () создает один поток
- … …
- submit используется для запуска потока с объектом, который реализует интерфейс Callable или Runable;
- Он возвращается Future<V> Интерфейс, удобное управление потоками и получение результатов
- executeor.submit запускает реализацию интерфейса Callable, или функция Lambda является потоком
- Подготовка лямбда занимает намного больше времени, чем интерфейс
- Выполнение группы трудоемких функций в пуле потоков (классы, реализующие Callable)
- TimeConsumingService - это смоделированный объект службы, у которого есть имя и время расчета. Код см. Ниже
- Порядок get () повлияет на время результата, ключ для блокировки;
- Если результаты данных могут быть переданы последующим потокам для параллельной обработки в соответствии с временными рядами результатов этих потоков, ЦП не нужно блокировать в get (). Но программирование, несомненно, будет очень сложным.
3. Реактивное (отзывчивое) программирование
Реактивное (адаптивное) программирование стало самым популярным стандартом, от обработки больших данных (например, Spark) до обработки потока событий интерфейса Android. Но как это работает? Как правильно написать реактивную программу?
3.1 Основные принципы реактивного программирования
Адаптивное программирование - это вычислительная модель сопрограмм, которая организует и обрабатывает потоки данных в конвейерном режиме (я не могу найти подходящего определения). Линия сборки состоит из источников ввода, рабочих (функций), структуры конвейера, диспетчеров и выходов. Предположим простой линейный конвейер (последовательная обработка), как показано на рисунке:
* (D0 – d1 –– d2– |) представляет поток данных последовательности с флагом завершения;
* [worker] представляет операционную функцию, которая может извлекать данные только из предыдущего процесса и передавать их следующему исполнителю после обработки;
*… Представляет буферную очередь (EndPoint) для хранения данных между двумя рабочими процессами;
* Планировщик - это диспетчер, который управляет работой воркеров.Диспетчер может управлять только одним воркером за раз, а воркер обрабатывает только один фрагмент данных за раз, либо успешно, либо неуспешно (ненормально).Эта программа - однопоточная программа (планировщик), но порядок, в котором работают фильтры, карта и планировщик, непредсказуем.Если конечная точка, из которой они извлекают данные, имеет данные, они могут быть запланированы планировщиком. Когда рабочий запланирован один раз, CPU используется до тех пор, пока операция функции не будет завершена и CPU не будет освобожден. Это стандарт Coroutine концепция.
Реактивное программирование означает запуск соответствующей функции обработки данных на основе данных в EndPoint. Это процесс асинхронного выполнения (цепная реакция) между функциями. Это полезно для уменьшения блокировки программ и уменьшения накладных расходов потоков, особенно nodejs и javascript, которые не поддерживают многопоточность. , Python и т. Д. Имеют особое значение.
Следовательно, реактивное программирование На основе данных Для программирования создание механизма параллельной обработки в модели, управляемой данными, требует введения нескольких планировщиков.
Никогда не думайте, что реактивное программирование является параллельным. Предлагаю вам иметь время Обязательно внимательно прочтите RxJava Threading Examples . Теоретически Reactive управляется данными, а не событиями.
Реактивное программирование - это не параллелизм в истинном смысле этого слова. Поскольку каждый планировщик является потоком, операционные функции, которыми он управляет, обычно не требуют блокировки данных. Эти функции управляются данными. Запускать одновременно "оф.
3.2 Начало работы с RxJava
1. Зависимость от Maven
Я лично считаю, что RxJava 1.x больше подходит для начала работы, 2.x имеет высокую степень абстракции, и начать работу с него сложно.
- Первым шагом в реактивном программировании является создание источника данных. Просто Observable.from берет число из набора или Observable.just берет число напрямую, например Observable.just (1, 2);
- Используйте функции операций для построения конвейера обработки потока данных (рабочего процесса), то есть используйте преобразование данных операции (преобразование) для определения рабочего процесса. Существуют ли официально сотни операций или функций? ? ? , Сложность обучения немного сложна! ! !
- Последняя операция подписаться , Запустить процесс и вывести данные.
subscribe поддерживает 3 функции, onNext получает результат, onError получает ошибку, и процесс onCompleted завершается.
3.3 Планировщик и потоки
- Flowable.fromCallable создает трудоемкий источник.
- subscribeOn(Schedulers.io()) Источник начинает использовать этот планировщик в пуле потоков
- observeOn(Schedulers.single()) Следующие операции используют этот планировщик
Примечание. Поскольку планировщик работает в фоновом режиме и последнего предложения нет, вы не будете ждать никаких выходных данных, и основной поток завершится. В практических приложениях, таких как основной поток интерфейса Android и асинхронный поток веб-службы, как правило, не будет результата, но дождитесь результата вашей подписки.
Пример: предположим, что у вас есть 100 URL-адресов, и вы хотите сканировать эти данные URL-адресов с веб-сайта. Можно ли запрограммировать этот способ?
- Сколько потоков в планировщике?
- Какие функции расчета есть у каждого расписания потоков?
Реактивные точки параллельного программирования
- В потоке данных разработка и управление количеством и областью управления планировщиком является ключом к параллелизму RxJava.
- В потоке данных есть текущие Планирование задач (поток) Концепция, даже если потоки неявны
- subscribeOn (Scheduler) определяет планировщик ближайшего источника данных, поэтому одного источника достаточно, а больше не имеет смысла.
- НаблюдатьОн (Расписание) определяет планировщик будущих задач.
- Параллельный разделен на уровень обработки функций (однопоточный) Одновременный , И планировщик (многопоточный) уровень Одновременный 。
3.4. Проектирование параллельного программирования на RxJava
Пример использования: зависимость от асинхронных задач
Предположим, нашей программе требуется пять микросервисов для взаимодействия для выполнения вычислительных задач, и между этими микросервисами существует зависимость данных:
![micro-services-deps]()
Для экспериментов мы создали класс TimeConsumingService, который реализует Callable:
Чтобы гарантировать одновременное выполнение этих функций, необходимо создать достаточное количество потоков, чтобы службы без зависимостей могли выполняться в разных потоках. Здесь мы принимаем
метод совместного проектирования
- Нарисуйте диаграмму потока данных;
- Выберите узел слияния процессов на блок-схеме;
- Разработайте планировщик (поток) для пути выполнения каждой точки слияния;
- Поток этих путей объединяется в точке слияния.
код показан ниже:
Примечание. В приведенной выше программе есть как лямбда-функции, так и лямбда-выражения. Разница в том, что первое нужно вернуть, а второе - нет.
Результат очень интересный. Образец загружается впервые, и процесс готов к использованию. 204 ms . Для второго выполнения время подготовки становится 0 ms
Если этот код не учитывает накладные расходы системы, он должен быть выполнен за 3 секунды.
- Метод соединения подходит для решения задач проектирования нескольких планировщиков в потоке данных.
- fromCallable создает планируемую функцию и выводит результат функции
- flatMap и map - наиболее часто используемые рабочие функции
- map подходит для возврата функции других типов данных, но не может быть наблюдаемым
- flatMap - это функция, которая возвращает поток и объединяет данные, созданные этим потоком, в следующую конечную точку.
- flatMap-merge формирует расчетную модель map-reduce
- функция уменьшения операции, используемая для агрегирования результатов потока
В этой статье используется случай, чтобы проиллюстрировать процесс выполнения и программирование вычислений, управляемых реактивными потоками данных. Бесчисленные строки потоков, семафоров и блокировок, а также управляющий код, который использовался для одновременной обработки нескольких связанных сервисов, исчезли, и он стал простой и элегантной вычислительной моделью.
В Интернете есть бесчисленное количество руководств, большинство из которых являются вводными статьями с точки зрения простых приложений. Среди них большинство программ не учитывают одновременное возникновение асинхронного и параллельного. Конечно, хороших статей тоже много, хорошие статьи читать сложно, как и официальные документы.
Реактивное программирование На основе данных , Не "событие". Реактивное программирование разделено на три основных этапа проектирования: подготовка источника данных, моделирование потока данных и распределение диспетчера для достижения асинхронного параллельного выполнения. Подготовка источника данных и моделирование потока данных включают в себя сотни рабочих функций, а асинхронная обработка данных ни в коем случае не является простым процессом; хотя диспетчер имеет только несколько функций, он является источником ошибок.
Модель реактивного программирования - это основная идея дизайна и технология приложений, которые должна освоить «микросервисная архитектура». Оркестровка и композиция сервисов всегда будут ядром SOA! ! !
![]()
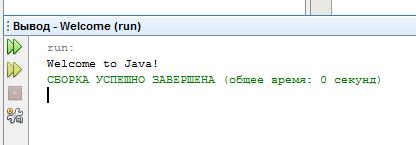
Вне IDE консольные программы (т.е. без графического интерфейса) запускают в командной строке. О командной строке в следующем разделе «Создание, компиляция и выполнения Java программ».
Исходный код программы
Строка 1 определяет класс. Каждая Java программа должна иметь по крайней мере один класс. Каждый класс имеет имя. Принято, что имена классов начинаются с заглавной буквы. В этом примере класс назван Welcome.
Строка 2 определяет метод main. Программа начинает выполнение с метода main. Метод main – это точка входа, где программа начинает выполнение.
Метод – это конструкция, которая содержит инструкции. Метод main в этой программе содержит инструкцию System.out.println. Инструкция отображает в консоли строку «Welcome to Java!». Строка (String) – это термин в программировании, означающий последовательность символов. Строка должна быть заключена в двойные кавычки. Каждая инструкция в Java заканчивается точкой с запятой ( ; ), которая служит разделителем инструкций.
Зарезервированные слова, или как их ещё называют ключевые слова, имеют определённое значение для компилятора, и они не могут использоваться для других целей в программе. Например, когда компилятор видит слово class, он понимает, что слово после class – это имя класса. Другими зарезервированными словами в этой программе являются public, static и void.
Строка 3 – это комментарий, которая документирует действия программы и её устройство. Комментарии помогают программистам общаться и понимать программу. Они не являются программными инструкциями и, таким образом, игнорируются компилятором. В Java комментариям предшествуют два слеша на строке (//), которая так и называется – строка комментария. Комментарии могут располагаться между /* и */ на одной или нескольких строках, эти строки называются блоком комментариев или параграфом комментариев. Когда компилятор видит //, то он на этой строке игнорирует весь текст после //. Когда видит /*, он сканирует следующий */ и игнорирует любой текст между /* и */.
Несколько примеров комментариев:
Пара фигурных скобок в программе формирует блок, который группирует компоненты программы. В Java каждый блок начинается с открывающей фигурной скобки ( <)и заканчивается закрывающей фигурной скобкой. (>). Каждый класс имеет блок класса, который группирует данные и методы класса. Похожим образом каждый метод имеет блок метода, который группирует инструкции в методе. Блоки могут быть вложенными, это означает, что один блок может быть помещён внутри другого, как показано на следующем коде:
![]()
Подсказка: любой открывающей фигурной скобке должна соответствовать закрывающая. Каждый раз, когда вы напечатали открывающую фигурную скобку, сразу печатайте закрывающую, для предотвращения ошибок, вызванных отсутствие скобки. Большинство IDE для языка Java автоматически вставляют закрывающую фигурную скобку для каждой открывающей.
Внимание: исходный код программ Java чувствителен к регистру. Будет неправильным, например, заменить в программе main на Main.
Вы познакомились с несколькими специальными символами в программе (например, , //, ;). Они используются практически в каждой программе. Таблица обобщает их использование:
Символ Имя Описание <> Открывающая и закрывающая фигурная скобка Обозначает блок для окружения инструкций. () Открывающая и закрывающая круглая скобка Используется с методами. [] Открывающая и закрывающая квадратная скобка Обозначает массив. // Двойной слэш Предшествует комментарию. " " Открывающая и закрывающая кавычки Окружает строку (т.е. последовательность символов). ; Точка с запятой Обозначает конец инструкции. Самыми распространёнными ошибками, которые вы будете делать пока учите программировать, это синтаксические ошибки. Как любой язык программирования, Java имеет свой собственный синтаксис, и вам нужно писать код, который удовлетворяет правилам синтаксиса. Если ваша программа нарушает правило, например, если отсутствует точка с запятой, отсутствует фигурная скобка, отсутствует кавычка или неправильно написано слово – компилятор Java сообщит об ошибках синтаксиса.
![]()
![]()
В дальнейшем вы можете выполнять математические расчёты и отображать результаты в консоли. Пример вычисления
![]()
Для умножения в Java используется *. Как вы можете увидеть, это простой процесс для преобразования арифметический выражений в Java инструкции. Подробнее это будет рассмотрено в следующей главе.
Читайте также:
- Executors возвращает потоковую модель для запуска потоков;