
Какие языки понимает браузер
Обновлено: 17.05.2024
Начнём с рассмотрения того что представляют собой API на высоком уровне и выясним, как они работают, как их использовать в своих программах и как они структурированы. Также рассмотрим основные виды API и их применение.
| Необходимые знания: | Базовая компьютерная грамотность, понимание основ HTML и CSS, основы JavaScript (см. первые шаги, building blocks, объекты JavaScript). |
|---|---|
| Цель: | Познакомиться с API, выяснить что они могут делать и как их использовать. |
Что такое API?
Интерфейс прикладного программирования (Application Programming Interfaces, APIs) - это готовые конструкции языка программирования, позволяющие разработчику строить сложную функциональность с меньшими усилиями. Они "скрывают" более сложный код от программиста, обеспечивая простоту использования.
Для лучшего понимания рассмотрим аналогию с домашними электросетями. Когда вы хотите использовать какой-то электроприбор, вы просто подключаете его к розетке, и всё работает. Вы не пытаетесь подключить провода напрямую к источнику тока — делать это бесполезно и, если вы не электрик, сложно и опасно.

Точно также, если мы хотим, например, программировать 3D графику, гораздо легче сделать это с использованием API, написанных на языках высокого уровня, таких как JavaScript или Python.
Note: Смотрите также API в словаре.
API клиентской части JavaScript
Для JavaScript на стороне клиента, в частности, существует множество API. Они не являются частью языка, а построены с помощью встроенных функций JavaScript для того, чтобы увеличить ваши возможности при написании кода. Их можно разделить на две категории:
- API браузера встроены в веб-браузер и способны использовать данные браузера и компьютерной среды для осуществления более сложных действий с этими данными. К примеру, API Геолокации (Geolocation API) предоставляет простые в использовании конструкции JavaScript для работы с данными местоположения, так что вы сможете, допустим, отметить своё расположение на карте Google Map. На самом деле, в браузере выполняется сложный низкоуровневый код (например, на C++) для подключения к устройству GPS (или любому другому устройству геолокации), получения данных и передачи их браузеру для обработки вашей программой, но, как было сказано выше, эти детали скрыты благодаря API.
- Сторонние API не встроены в браузер по умолчанию. Такие API и информацию о них обычно необходимо искать в интернете. Например, Twitter API позволяет размещать последние твиты (tweets) на вашем веб-сайте. В данном API определён набор конструкций, осуществляющих запросы к сервисам Twitter и возвращающих определённые данные.

Взаимодействие JavaScript, API и других средств JavaScript
Итак, выше мы поговорили о том, что такое JavaScript API клиентской части и как они связаны с языком JavaScript. Давайте теперь тезисно запишем основные понятия и определим назначение других инструментов JavaScript:
- JavaScript — Язык программирования сценариев высокого уровня, встроенный в браузер, позволяющий создавать функциональность веб-страниц/приложений. Отметим, что JavaScript также доступен на других программных платформах, таких как Node. Но пока не будем останавливаться на этом.
- API браузера (Browser APIs) — конструкции, встроенные в браузер, построенные на основе языка JavaScript, предназначенные для облегчения разработки функциональности.
- Сторонние API (Third party APIs) — конструкции, встроенные в сторонние платформы (такие как Twitter, Facebook) позволяющие вам использовать часть функциональности этих платформ в своих собственных веб-страницах/приложениях (например, показывать последние Твиты на вашей странице).
- Библиотеки JavaScript — Обычно один или несколько файлов, содержащих пользовательские (custom) функции. Такие файлы можно прикрепить к веб-странице, чтобы ускорить или предоставить инструменты для написания общего функциональности. Примеры: jQuery, Mootools и React.
- JavaScript фреймворки (frameworks) — Следующий шаг в развитии разработки после библиотек. Фреймворки JavaScript (такие как Angular и Ember) стремятся к тому, чтобы быть набором HTML, CSS, JavaScript и других технологий, после установки которого можно "писать" веб-приложение с нуля. Главное различие между фреймворками и библиотеками - "Обратное направление управления" ( “Inversion of Control” ). Вызов метода из библиотеки происходит по требованию разработчика. При использовании фреймворка - наоборот, фреймворк производит вызов кода разработчика.
На что способны API?
Широкое разнообразие API в современных браузерах позволяет наделить ваше приложение большими возможностями. Достаточно посмотреть список на странице MDN APIs index page.
Распространённые API браузера
В частности, к наиболее часто используемым категориям API (и которые мы рассмотрим далее в этом модуле) относятся :
Распространённые сторонние API
Существует множество сторонних API; некоторые из наиболее популярных, которые вы рано или поздно будете использовать, включают:
-
для добавления такой функциональности, как показ последних твитов на сайте. для работы с картами на веб-странице (интересно, что Google Maps также использует этот API). Теперь это целый набор API, который может справляться с широким спектром задач, как свидетельствует Google Maps API Picker. позволяет использовать различные части платформы Facebook в вашем приложении, предоставляя, например, возможность входа в систему с логином Facebook, оплаты покупок в приложении, демонстрация целевой рекламы и т.д. , предоставляющий возможность встраивать видео с YouTube на вашем сайте, производить поиск, создавать плейлисты и т.д. - фреймворк для встраивания функциональности голосовой и видео связи в вашем приложении, отправки SMS/MMS из приложения и т.д.
Note: вы можете найти информацию о гораздо большем количестве сторонних API в Каталоге Web API.
Как работает API?
Работа разных JavaScript API немного отличается, но, в основном, у них похожие функции и принцип работы.
Они основаны на объектах
Взаимодействие с API в коде происходит через один или больше объектов JavaScript, которые служат контейнерами для информации, с которой работает API (содержится в свойствах объекта), и реализуют функциональность, которую предоставляет API (содержится в методах объекта).
Note: Если вам ещё не известно как работают объекты, советуем вернуться назад и изучить модуль Основы объектов JavaScript прежде чем продолжать.
Вернёмся к примеру с API Геолокации — очень простой API, состоящий из нескольких простых объектов:
-
, содержит три метода для контроля и получения геоданных. , предоставляет данные о местоположении устройства в заданный момент времени — содержит Coordinates - объект, хранящий координаты и отметку о текущем времени. , содержит много полезной информации о расположении устройства, включая широту и долготу, высоту, скорость и направление движения и т.д.
Так как же эти объекты взаимодействуют? Если вы посмотрите на наш пример maps-example.html (see it live also), вы увидите следующий код:
Note: Когда вы впервые загрузите приведённый выше пример, появится диалоговое окно, запрашивающее разрешение на передачу данных о местонахождении этому приложению (см. раздел У них есть дополнительные средства безопасности там, где это необходимо далее в этой статье). Вам нужно разрешить передачу данных, чтобы иметь возможность отметить своё местоположение на карте. Если вы всё ещё не видите карту, возможно, требуется установить разрешения вручную; это делается разными способами в зависимости от вашего браузера; например, в Firefox перейдите > Tools > Page Info > Permissions, затем измените настройки Share Location; в Chrome перейдите Settings > Privacy > Show advanced settings > Content settings и измените настройки Location.
Во-первых, мы хотим использовать метод Geolocation.getCurrentPosition() , чтобы получить текущее положение нашего устройства. Доступ к объекту браузера Geolocation производится с помощью свойства Navigator.geolocation , так что мы начнём с
Это эквивалентно следующему коду
Но мы можем использовать точки, чтобы связать доступ к свойствам/методам объекта в одно выражение, уменьшая количество строк в программе.
Метод Geolocation.getCurrentPosition() имеет один обязательный параметр - анонимную функцию, которая запустится, когда текущее положение устройства будет успешно считано. Сама эта функция принимает параметр, являющийся объектом Position (en-US) , представляющим данные о текущем местоположении.
Note: Функция, которая передаётся другой функции в качестве параметра, называется колбэк-функцией (callback function).
Такой подход, при котором функция вызывается только тогда, когда операция была завершена, очень распространён в JavaScript API — убедиться, что операция была завершена прежде, чем пытаться использовать данные, которые она возвращает, в другой операции. Такие операции также называют асинхронными операциями (asynchronous operations). Учитывая, что получение данных геолокации производится из внешнего устройства (GPS-устройства или другого устройства геолокации), мы не можем быть уверены, что операция считывания будет завершена вовремя и мы сможем незамедлительно использовать возвращаемые ею данные. Поэтому такой код не будет работать:
Если первая строка ещё не вернула результат, вторая вызовет ошибку из-за того, что данные геолокации ещё не стали доступны. По этой причине, API, использующие асинхронные операции, разрабатываются с использованием callback function, или более современной системы промисов, которая появилась в ECMAScript 6 и широко используются в новых API.
Мы совмещаем API Геолокации со сторонним API - Google Maps API, который используем для того, чтобы отметить расположение, возвращаемое getCurrentPosition() , на Google Map. Чтобы Google Maps API стал доступен на нашей странице, мы включаем его в HTML документ:
Чтобы использовать этот API, во-первых создадим объект LatLng с помощью конструктора google.maps.LatLng() , принимающим данные геолокации Coordinates.latitude (en-US) и Coordinates.longitude (en-US) :
Этот объект сам является значением свойства center объекта настроек (options), который мы назвали myOptions . Затем мы создаём экземпляр объекта, представляющего нашу карту, вызывая конструктор google.maps.Map() и передавая ему два параметра — ссылку на элемент <div> , на котором мы хотим отрисовывать карту (с ID map_canvas ), и объект настроек (options), который мы определили выше.
Когда это сделано, наша карта отрисовывается.
Последний блок кода демонстрирует два распространённых подхода, которые вы увидите во многих API:
- Во-первых, объекты API обычно содержат конструкторы, которые вызываются для создания экземпляров объектов, используемых при написании программы.
- Во-вторых, объекты API зачастую имеют несколько вариантов (options), которые можно настроить и получить именно ту среду для разработки, которую вы хотите. API конструкторы обычно принимают объекты вариантов (options) в качестве параметров, с помощью которых и происходит настройка.
Note: Не отчаивайтесь, если вы что-то не поняли из этого примера сразу. Мы рассмотрим использование сторонних API более подробно в следующих статьях.
У них узнаваемые точки входа
При использовании API убедитесь, что вы знаете где точка входа для API. В API Геолокации это довольно просто — это свойство Navigator.geolocation , возвращающее объект браузера Geolocation , внутри которого доступны все полезные методы геолокации.
Найти точку входа Document Object Model (DOM) API ещё проще — при применении этого API используется объект Document , или экземпляр элемента HTML, с которым вы хотите каким-либо образом взаимодействовать, к примеру:
Точки входа других API немного сложнее, часто подразумевается создание особого контекста, в котором будет написан код API. Например, объект контекста Canvas API создаётся получением ссылки на элемент <canvas> , на котором вы хотите рисовать, а затем необходимо вызвать метод HTMLCanvasElement.getContext() :
Всё, что мы хотим сделать с canvas после этого, достигается вызовом свойств и методов объекта содержимого (content) (который является экземпляром CanvasRenderingContext2D ), например:
Note: вы можете увидеть этот код в действии в нашем bouncing balls demo (see it running live also).
Они используют события для управления состоянием
Мы уже обсуждали события ранее в этом курсе, в нашей статье Introduction to events — в этой статье детально описываются события на стороне клиента и их применение. Если вы ещё не знакомы с тем, как работают события клиентской части, рекомендуем прочитать эту статью прежде, чем продолжить.
Следующий код содержит простой пример использования событий:
Note: вы можете увидеть этот код в действии в примере ajax.html (see it live also).
Затем функция-обработчик onload определяет наши действия по обработке ответа сервера. Нам известно, что ответ успешно возвращён и доступен после наступления события load (и если не произойдёт ошибка), так что мы сохраняем ответ, содержащий возвращённый сервером объект JSON в переменной superHeroes , которую затем передаём двум различным функциям для дальнейшей обработки.
У них есть дополнительные средства безопасности там, где это необходимо
К тому же, некоторые WebAPI запрашивают разрешение от пользователя, как только к ним происходит вызов в коде. В качестве примера, вы, возможно, встречали такое диалоговое окно при загрузке нашего примера Geolocation ранее:

Notifications API запрашивает разрешение подобным образом:

Запросы разрешений необходимы для обеспечения безопасности пользователей — не будь их, сайты могли бы скрытно отследить ваше местоположение, не создавая множество надоедливых уведомлений.
Итоги
На данном этапе, у вас должно сформироваться представление о том, что такое API, как они работают и как вы можете применить их в своём JavaScript-коде. Вам наверняка не терпится начать делать по-настоящему интересные вещи с конкретными API, так вперёд! В следующий раз мы рассмотрим работу с документом с помощью Document Object Model (DOM).

Доброго времени суток, Хабр! В очередной раз читая комментарии, наткнулся на мысль о том, что далеко не все понимают, как обстоит ситуация с браузерами для Windows на данный момент. От чего хотелось бы провести небольшой обзор текущего положения. Ну, и сразу к делу!
Браузерные движки
Браузер — программа не простая, это целый набор компонентов, взаимодействующих между собой. Для краткого обзора потребуются всего два компонента из множества — движок отрисовки содержимого и движок исполнения JavaScript.
Существующие движки отрисовки содержимого
- Trident (так же известный как MSHTML) — движок, ранее разрабатываемый Microsoft для браузера Internet Explorer;
- EdgeHTML — преемник Trident, ранее разрабатываемый Microsoft для браузера Legacy Edge (ранее просто Edge);
- WebKit — движок, разрабатываемый Apple для браузера Safari;
- Blink — преемник WebKit, разрабатываемый Google для браузера Chrome;
- Gecko — движок, разрабатываемый Mozilla для браузера Firefox;
- Servo — исследовательский проект Mozilla, некоторые технологии со временем перетекают в Gecko.
Существующие движки исполнения JavaScript
- Chakra JScript — движок JS, ранее разрабатываемый Microsoft для браузера Internet Explorer;
- Chakra JavaScript — преемник Chakra JScript, ранее разрабатываемый Microsoft для браузера Legacy Edge;
- Nitro — движок JS, разрабатываемый Apple для браузера Safari;
- V8 — движок JS, разрабатываемый Google для браузера Chrome;
- SpiderMonkey — движок JS, разрабатываемый Mozilla для браузера Firefox.
И тут вроде бы очевидно, какие браузеры какие движки используют, но Microsoft внёс не много путаницы в понимание данной темы, поэтому рассмотрим браузеры отдельно.
Браузеры
Chromium

Chromium — это open-source ответвление браузера Chrome. Браузеры на основе Chromium составляют большую часть из всех используемых браузеров на планете Земля.
Обычно, браузеры на базе Chromium между собой отличаются только визуально, ведь у всех под капотом движки Blink и V8, хотя, какие-то компании пытаются привнести больше функционала в браузер, чем имеется.
Это в конечном итоге встанет разработчикам браузеров боком, потому что в любой момент главный разработчик Chromium — Google может вставить палки в колёса разработчикам модификаций.
Всех браузеров на основе Chromium подсчитать одному человеку вряд ли под силу, поэтому приведу список только тех, что помню:
- Chrome — в представлении не нуждается, браузер от Google;
- Chr Edge — новый браузер от Microsoft со старым названием. Поговаривают, отличается большей производительностью от Chrome. С некоторых пор предустанавливается в систему;
- Brave — браузер с повышенной безопасностью настолько, что приватный режим использует Tor;
- Яндекс.Браузер, Opera, Vivaldi, тысячи их.
Firefox
Firefox использует движки Gecko и SpiderMonkey для своей работы. Имеет небольшое количество базирующихся на Firefox браузеров, но самый известный — Tor Browser. Является единственным рубежом до полного перехода интернета на браузеры на основе Chromium.
Internet Explorer
Это любимая всеми утилита для скачивания браузеров. Как и Chrome — не нуждается в представлении. До 11 версии использовал движки Trident и Chakra JScript. В 11 версии, за исключением режима совместимости, стал использовать движки Trident и Chakra JavaScript. Этот браузер ещё долго будет использоваться для всякого рода систем видеонаблюдения, поскольку имеет, почему-то, популярный в узких кругах API для расширений. В Windows 8 и Windows 8.1 имел особую модификацию движка Trident на базе WinRT для Metro режима.
(Legacy) Edge
Браузер, начавший своё существование с кодовым названием Project Spartan, являлся новым браузером от Microsoft в 2015 году, использующим движки EdgeHTML и Chakra JavaScript. Конечной целью проекта была полная совместимость с сайтами, отлично работающими в Chrome. В итоге — получилось нечто своеобразное, но, очевидно, не выжившее под давлением Google.
Safari

Safari? А нет его больше, этого вашего Safari, кончился.
Нецелевое использование браузеров
Вроде бы браузеры — законченный продукт, ни добавить ни отнять. Однако, они используются в разного рода других приложениях. Причины в следующем (в порядке убывания значимости):
- П р ограммистов на JS нечем занять;
- На JS+HTML новичкам проще программировать;
- Кроссплатформенность;
- Требуется возможность отображать веб-страницы.
Приведу примеры подобного использования:
Chromium
Нынешние браузеры настолько сложны, что одному человеку создать собственный браузер не под силу (либо это должен быть гений). Они по сложности сравнимы с операционными системами! А, постойте, вот и первый кандидат на нецелевое использование — Chrome OS. Да, весь пользовательский интерфейс — просто модифицированный Chromium.
Однако, помимо этого, в виде CEF (Chromium Embedded Framework), Chromium используется в:
Internet Explorer
Почти любое Win32 приложение, умеющее отображать WEB-страницы и при этом в распакованном виде занимающее меньше 60 мегабайт использует внутри Internet Explorer. Кстати, это касается не только маленьких по размеру приложений, например, Visual Studio использует Internet Explorer для отображения WEB-страниц, когда это требуется в работе IDE. Ещё существуют HTA приложения — древний предшественник CEF на базе Internet Explorer. И ведь до сих пор работает.
(Legacy) Edge
Новым приложениям — новые движки! Любое UWP приложение, использующее внутри отображение WEB-страниц работает на базе Edge. Не то, чтобы Microsoft запрещали использовать что-то другое, но никто просто и не старался. Так же, пока что, в предварительных сборках Windows новая клавиатура с GIF панелью тоже использует Edge для рендеринга. В будущих версиях, полагаю, перейдут на Chr Edge.

Производительность
Постойте, столько приложений, а что там с производительностью? Лично я — не специалист в оценке производительности, но хочу поделится с вами некоторыми занимательными фактами.
Prefetcher
В Windows есть такая штука — Prefetcher. Она занимается подгрузкой программ в ОЗУ при старте ОС и на протяжении её работы. Штука эта достаточно умная, и она анализирует чаще всего запускаемые программы, чтобы в дальнейшем их подгружать.
Как это связано с браузерами? Идея в том, что это может смазать первый пользовательский опыт с другим браузером, например, пользуясь постоянно Chrome, имеете установленную версию Firefox. При запуске Firefox будет вести себя крайне медленно — медленнее, чем ваш основной браузер. Всё потому что он запылился в глазах Prefetcher. В конечном итоге всё будет работать быстро, но первое впечатление после долгого неиспользования будет ужасным. Особенно это касается пользователей с HDD или малым количеством ОЗУ.
Области распределённой памяти
Да, звучит не очень. Но суть, в данном случае, простая — если одна единица исполняемого кода требуется к исполнению больше одного раза, будь то exe или dll , то в память она загрузится лишь один раз. Поясню: если два различных приложения в ходе своей работы загрузят одну и ту же библиотеку, например, edgehtml.dll , то этот файл будет загружен в ОЗУ компьютера на самом деле только один раз, хотя, казалось бы, потребуется два или больше раз. Таким образом ОС экономит нам оперативную память.
Движки нормального человека
К чему это я? А вот дело в том, что в отличии от других браузеров, Internet Explorer и (Legacy) Edge предустановлены в систему, а их движки хранятся в папке System32 . Это, вкупе с API для разработки приложений, означает, что все приложения в системе, использующие данные движки будут загружать их в память только однажды. И этот принцип распространяется на все приложения.
У людей часто возникают проблемы с UWP приложениями, а точнее — с их скоростью запуска. Всё дело в WinRT — огромном наборе библиотек, при помощи которых UWP приложение взаимодействует с ОС. Если не использовать UWP приложения часто, то этот набор библиотек не будет прогружен в памяти полностью, и придётся ожидать окончания этого процесса перед использованием приложения. Но забавный факт — используя два и более UWP приложения время их старта и общая производительность резко увеличиваются и часто даже превосходят Win32 программы. Исключением из этого является приложение "Фотографии" — тут отдельная история, покрытая туманом.
Движки курильщика
А вот с приложениями (в том числе и браузерами) на основе Chromium это так не работает. Каждое приложение комплектует с собой собственную сборку библиотеки CEF, что, кроме раздувания размера приложения, не позволяет операционной системе иметь только одну копию dll в ОЗУ. Итого это сильно замедляет производительность при использовании множества подобных приложений. Помимо того, сам размер CEF довольно удручающий.
Microsoft Store
У многих возникает вопрос — почему в Microsoft Store нет ни одного браузера(не считая нескольких кривых поделок на EdgeHTML)? Ответ, на самом деле, прост — все браузеры, включая Chr Edge имеют собственную систему обновления, что прямо запрещено правилами Microsoft Store. В остальном никто никого не ограничивает.
Как удалить новый Microsoft Edge
Это не очень сложно. Для начала требуется найти папку с Microsoft Edge, она расположена по пути:
C:\Program Files (x86)\Microsoft\Edge\Application
Далее заходим в любую версию Edge и переходим в папку Installer . Полный путь может выглядеть следующим образом:
C:\Program Files (x86)\Microsoft\Edge\Application\83.0.478.58\Installer
Далее необходимо открыть командную строку от имени администратора в данной папке и выполнить следующую команду:
setup.exe --uninstall --system-level --verbose-logging --force-uninstall
Готово! Через несколько секунд этот браузер исчезнет из системы. Но при следующем же обновлении он появится снова, будте бдительны.
Заключение
Пожалуй, эта статья получилась даже больше, чем я предполагал. В любом случае, какой браузер использовать — выбор ваш, но, зато, вы теперь знаете чуточку больше. Всем спасибо.
Администраторы Хабра, пожалуйста, почините HabraStorage в Legacy Edge! Совсем не дело.

Автор: Антон Реймер
Статья основана на вебинаре, который я проводил некоторое время назад. Рассчитана она, в первую очередь на тех, кто не знает, как работают браузеры, или тех, у кого есть пробелы в знаниях. Вероятно, здесь будет много очевидного для тех кто не первый день в веб-разработке. Статью я решил разделить на две части. В первой рассмотрим общие принципы работы браузера. Во второй части я акцентирую внимание на некоторых важных моментах: reflow и repaint, event loop.
Что такое браузер?
Браузер — программа, работающая в операционной системе. Большинство браузеров написано на языке C++. Основное предназначение браузера — воспроизводить контент с веб-ресурсов. В качестве веб-ресурса в большинстве случаев выступает html-страница. Это также может быть pdf-файл, png, jpeg, xml-файлы и другие типы. Среди огромного количества браузеров можно выделить самые популярные: Chrome, Safari, Firefox, Opera и Internet Explorer. Мы рассмотрим браузеры с открытым исходным кодом: Chrome, Firefox, Safari.
Из чего состоит и как работает браузер?
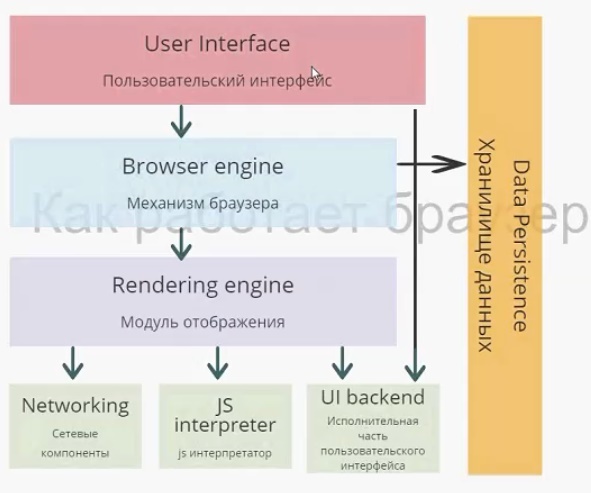
На схеме изображены модули браузера, каждый выполняет собственную функцию. Начнем с пользовательского интерфейса.
Пользовательский интерфейс — то, что видит перед собой пользователь, т. е. адресная строка, элементы навигации, собственное меню и т. д. Несмотря на то что пользовательские интерфейсы очень похожи друг на друга, никакого стандарта, который их описывал бы, не существует. Так исторически сложилось, что браузеры постепенно перенимали интерфейс друг у друга и становились все более похожими.
Механизм браузера отвечает за взаимодействие пользовательского интерфейса и модуля отображения, а также за сохранение данных в памяти.
Модуль отображения. Этот модуль — самый важный для разработчиков. Работа разработчика, в первую очередь, происходит именно с ним, а как можно понять по названию — отвечает он за отображение информации на экране.
Когда мы говорим о браузерных движках, таких как Webkit или Gecko (первый находится «под капотом» у Safari и до 2013 года был у Chrome, второй у Firefox), в первую очередь имеем в виду модуль отображения. Далее мы подробно рассмотрим модуль отображения и более детально разберем, как он работает.
Следующий модуль — сетевые компоненты. Он отвечает за запросы по сети, берет данные с внешних ресурсов и взаимодействует с модулем отображения.
Модуль JS Interpreter отвечает за интерпретацию скрипта, и его выполнение. Существует несколько JS-движков. Самые известные это V8 и JavaScriptCore. Важно не путать движок браузера и JS-движок, который работает в модуле JS Interpreter.
Следующий модуль — исполнительная часть пользовательского интерфейса (UI backend). Она отвечает за отрисовку всего на экране и работу пользовательского интерфейса.
Последний модуль — хранилище данных. Браузеру нужно где-то хранить данные, обычно для этого используется оперативная память. Какие данные нужно хранить? Например, кэш, собственные настройки. Также к хранилищу данных можно отнести indexedDB, который появился в стандарте html5 — собственные базы данных браузера.
Модуль отображения
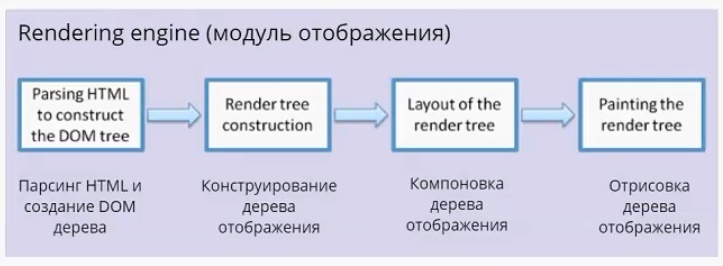
Модуль отображения получает данные от сетевого модуля. Данные поступают пакетами по 8 Кб. Что важно — модуль отображения не ждет, пока придут все данные, он начинает обрабатывать и выводить их на экран по мере поступления. В случае с html-страницами, он начинает их анализировать, происходит парсинг html (это отдельная большая тема, я на ней останавливаться не буду). Главное, что нужно понимать: в результате парсинга у нас появляется DOM-дерево. Также по окончании парсинга срабатывает событие load, которое можно обрабатывать в скрипте. Это значит, что документ готов и скрипт может с ним работать.
DOM-дерево — document object model. По большому счету, «интерфейс», который предоставляет браузер JS-движку для работы с тем или иным html-документом. На основе DOM-дерева происходит конструирование дерева отображения (render tree). Дерево отображения — тоже важная часть модуля отображения. По большому счету, два этих дерева — DOM-дерево и дерево отображения — наиболее важные элементы для разработчика. Дерево отображения во многом повторяет структуру DOM-дерева (далее будет пример, где это будет представлено нагляднее), но имеет некоторые отличия:
- Дерево отображения не содержит скрытых элементов. Если у нас есть html-элемент, у которого прописан display:none , в дереве отображения он присутствовать не будет. При этом, если visibility:hidden , то в дереве отображения он будет. Некоторые DOM-узлы, которые в DOM-дереве представлены как единый узел, в дереве отображения могут быть представлены в виде нескольких. Яркий пример — составной тэг select. Если в DOM-дереве это один узел, в дереве отображение он преобразовывается в минимум три узла. Первый узел отвечает за отображение выбранного элемента. Второй — за выпадающий список с возможными пунктами. И, наконец, третий блок отвечает за стрелочку.
- Текст в DOM-дереве представлен как простая node. DOM-дереву нет никакого дела до того, что там написано, сколько строк этот текст занимает. В то время, как для дерева отображения — это важно, и текст трансформируется в несколько узлов, в зависимости от того сколько строк он занимает. Это нагляднее рассмотрим чуть позже.
Дерево отображения служит для того, чтобы браузер понимал, что выводить на экран. Оно содержит информацию о том, из каких блоков состоит страница. Дальше в тексте для простоты я буду называть составные части дерева отображения прямоугольниками, чтобы не путать с html блоками.
Дерево отображения — совокупность прямоугольников, которая должна быть выведена на экране. После того как дерево отображения сконструировано, следует этап компоновки. На этом этапе всем прямоугольникам присваиваются размеры и координаты. Каждый прямоугольник получает свои ширину и высоту, координаты в окне браузера. После компоновки происходит отрисовка дерева отображения. Пользователь видит уже конечный результат. Модуль отображения в каждом браузере устроен по-своему, но схема работы схожая.

Предлагаю рассмотреть два браузерных движка: Webkit и Gecko.
Webkit. Модуль отображения получает html и стили. В результате парсинга html возникает DOM-дерево. В результате парсинга CSS возникает дерево правил таблиц стилей (Style Rules). Далее идет важный этап, который называется Attachment, можно перевести, как «совмещение». На этом этапе CSS-стили накладываются на DOM-дерево, в результате чего появляется Render Tree. После чего происходит компоновка дерева. Называется она здесь Layout. И в завершении происходит отрисовка (Painting).
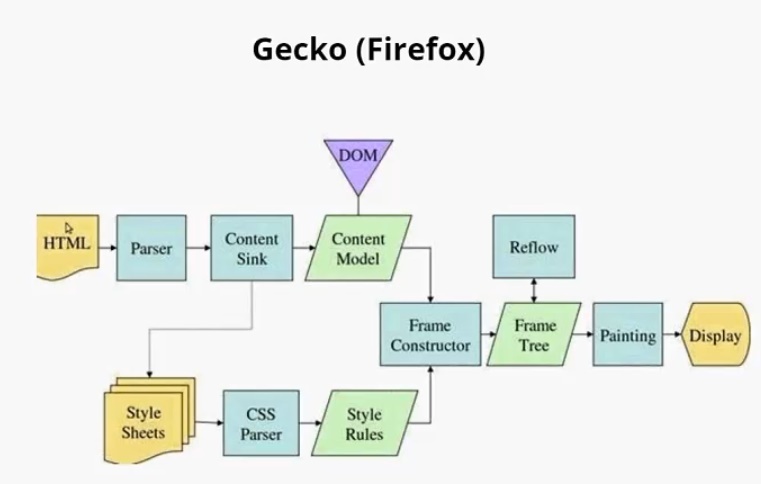
Если посмотреть на Gecko, можно заметить, что схемы очень похожи. Главные отличия — в терминологии. Здесь тоже парсятся HTML, CSS. В результате чего создается DOM-дерево, которое здесь называется Content Model. Парсятся стили, образуется дерево стилей. Этап Attachment здесь называется Frame Constructor, но, по сути, это тоже самое. В результате совмещения образуется дерево отображения, здесь оно называется Frame Tree. Компоновка здесь называется Reflow. А отрисовка называется Painting, так же, как и в Webkit.
- Attachment = Frame constructor = Совмещение
- Render Tree = Frame Tree = Дерево отображения
- Layout= Reflow = Компоновка
Пример

Здесь у нас есть теги:

Модуль отображения строит DOM-дерево. В данном случае оно будет выглядеть следующим образом. Есть корневой элемент (он всегда присутствует), называется он documentElement и соответствует тегу html . В этом дереве присутствуют все теги. И заметим, что текст представлен, как [text node] . И DOM-дереву больше ничего о тексте знать не нужно. На основе этого DOM-дерева строится Render Tree.
Пример
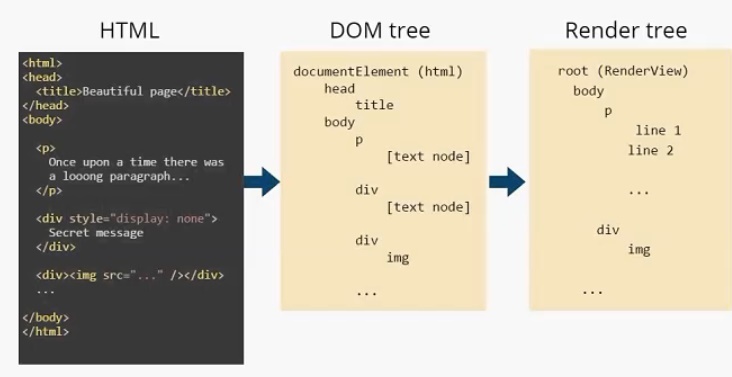
Дерево отображения. У него также есть корневой элемент (RenderView), но уже можно увидеть отличия между DOM-деревом и деревом отображения. Во-первых, нет тега head , т. к. он не отображается на экране. Нет <div style =” display: none”> , есть только
Текст в дереве отображения разделился на две строки и представляет собой два элемента: line 1 и line2. Как я писал выше, узлы дерева отображения мы будем называть прямоугольниками. Для наглядности я так и отобразил их на иллюстрации.
Пример
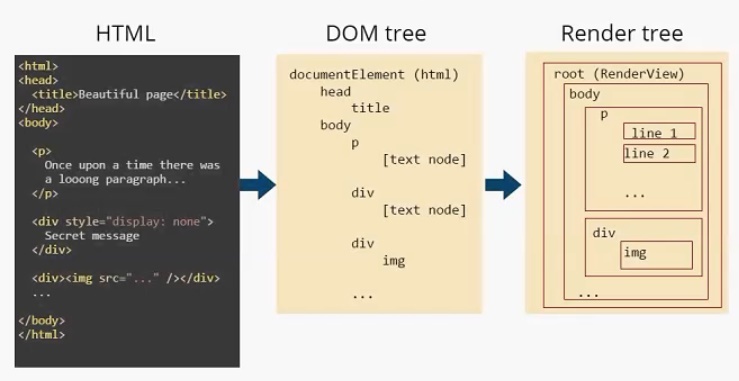
Каждый прямоугольник имеет своего «родителя», кроме корневого элемента root.
Модуль отображения также занимается обработкой скриптов.
Порядок обработки скриптов и таблиц стилей
Важно понимать порядок, в котором происходит обработка скриптов. Рассмотрим следующий пример, где я попытался продемонстрировать все возможные способы подключения скриптов и стилей.
Скрипт 1. Первое, что нужно знать про скрипты, — когда при парсинге html анализатор встречает скрипт, он останавливает дальнейший парсинг документа. Т. е., как только анализатор дошел до скрипта 1, браузеру ничего неизвестно о том, что будет дальше. И пока скрипт 1 не выполнится, дальнейший анализ документа происходить не будет.
Но при этом браузер продолжает выполнять ориентировочный синтаксический анализ. Что это значит? Браузер все равно смотрит, что следует за скриптом. Если находятся ссылки на внешние ресурсы, которые нужно скачать и загрузить, он подгрузит эти данные, пока выполняется скрипт 1. Сделано это для оптимизации.
При этом скрипт 3 все равно не будет выполняться, пока не выполнится скрипт 1. К моменту, когда скрипт 1 уже выполнится, скрипт 3 уже может быть полностью загружен. Скрипты можно вставлять в теги head и body . Разница в том, что в скрипте 2, в отличии от скрипта 1, практически весь документ уже будет проанализирован.
У скрипта могут быть атрибуты, такие как defer и async . Они похожи, но у них есть отличия:
- Атрибут defer сообщает браузеру, чтобы тот не ждал окончания выполнения скрипта, а продолжал парсинг html-страницы. При этом скрипт 4 выполнится только после того, как весь html-документ будет проанализирован и построено DOM-дерево.
- Атрибут async тоже говорит браузеру, что дальнейший html-документ может быть проанализирован, пока скрипт выполняется. При этом он загружается в параллельном потоке и выполняется сразу после загрузки. Это означает, что он может быть выполнен раньше, чем скрипт1, если последний тоже имеет атрибут async. Т. е. порядок подключения в этом случае не соблюдается.
В случае с defer скрипт 4 всегда выполняется после скрипта 1. С атрибутом async неизвестно, когда он будет выполнен и какая часть документа уже будет проанализирована к этому моменту.
Стили, в отличие от скриптов, никак не могут повлиять на документ. Если скрипты могут добавить дополнительные узлы или теги, то стили этого сделать не могут. Поэтому никакой надобности для браузера блокировать дальнейший анализ документа нет.
При этом есть небольшой нюанс. Например, скрипт 1 может работать с теми или иными стилям, и может потребоваться доступ к ним. Т.е. если мы хотим поменять (или узнать) какие-то стили, но при выполнении скрипта 1 они ещё не подгружены — может случиться ошибка.
Браузеры стараются этот нюанс учесть. Firefox, например, если находит какие-то не подгруженные стили в процессе ориентировочного синтаксического анализа, блокирует выполнение скрипта, подгружает стили, после чего завершает выполнение скрипта. Chrome действует аналогичным образом, но чуть более оптимизировано. Он останавливает скрипт, только если понимает, что в этом скрипте происходит работа с не подгруженными стилями.
Компоновка окон

Окно = Прямоугольник = Узел дерева отображения
- Тип окна (свойство display).
- Схема позиционирования (свойства position и float).
- Размеры окна.
- Внешняя информация (размеры изображения, размер экрана).
Компоновка окон — это этап компоновки дерева отображения. Я думаю многим верстальщикам знакома эта схема, она называется “Box model”. Я не буду подробно на ней останавливаться.
При компоновке окон учитываются следующее факторы:
CSS-свойство display. Два основных типа — inline и block. Другие, такие как inline-block table и прочие, появились уже позже. Отличие в том, что display:block, указывает, что ширина прямоугольника будет вычисляться в зависимости от ширины «родителя». А display:inline указывает, что ширина прямоугольника будет вычисляться в зависимости от его содержимого. Если в элементе два слова, ширина прямоугольника будет равна ширине, необходимой для вывода этих слов. Inline-элементы выстраиваются друг за другом. А блочные элементы — друг под другом.
Следующее, что влияет на компоновку элемента, — свойства position и float. Position по умолчанию static, при этом прямоугольник идет в стандартном потоке компоновки. Также есть position:relative и position:absolute. Position:relative указывает, что прямоугольнику выделяется место в стандартном потоке компоновки. При этом позиция элемента может быть сдвинута относительно этого места: влево, вправо, вверх, вниз с помощью соответствующего свойства.
Абсолютное позиционирование, к которому относится position:absolute и position:fixed, указывает, что элемент выходит за пределы своего прямоугольника из общего потока компоновки. Остальные прямоугольники его не учитывают. Он также не учитывает соседние элементы. Координаты его вычисляются относительно корневого элемента страницы, либо относительно предка, у которого position не static. Размеры же вычисляются тоже относительно родителя. Также на позиционирование влияет свойство float. Оно указывает, что наш прямоугольник идет в стандартном потоке, но при этом занимает либо крайнюю левую, либо крайнюю правую позиции. При этом все остальные прямоугольники «обтекают» этот элемент.
В заключение этой части стоит сказать что, основной поток браузера представляет собой бесконечный цикл, поддерживающий рабочие процессы. Он ожидает отправки событий, таких как reflow и repaint. Эти события ему приходят от модуля отображения. Получив их, он выполняет соответствующие действия.
В Firefox модуль отображения работает в одном потоке. Он един на весь браузер. В Chrome все немного иначе: модуль отображения и поток выполнения у каждой вкладки свои.
Важно, что сетевой модуль работает в отдельных параллельных потоках, которые не связаны с модулем отображения. Следовательно, сетевой компонент может использовать ресурсы независимо от того, что происходит в модуле отображения. Обычно у такого компонента есть возможность работать одновременно с несколькими подключениями и подгружать сразу несколько файлов. В Firefox, например, может быть шесть параллельных потоков, с помощью которых можно подгружать контент, скрипты и т. д.
В следующей части мы детально рассмотрим события reflow и repaint и попытаемся понять как грамотная работа с ними может повысить скорость работы приложения.
Подскажите, как сделать: если пользователь из России (СНГ) то направлять его на версию русской страницы сайта, а если из любой другой страны, то на другую. Как я понял есть вариант по языку браузера, самый простой, но со своими недостатками. на данный момент мне бы подошел самый простой вариант. Интересует его реализация!

Пользователь должен сам выбирать язык сайта, независимо от того, в какой стране он находится и каким браузером пользуется.
Гуглить хотя бы для начала не пробовал?

В случае с языковыми предпочтениями браузера:
Или варианты аналогичные описанным выше(по IP) с использованием mod_geoip.

Если пользователей будет много, то ожидай от них тёплые «лучи счастья» за такую фичу.

обязательно нужно оставить возможность выбора языка. а с таким вариантом такое не прокатит.
>обязательно нужно оставить возможность выбора языка. а с таким вариантом такое не прокатит
Прокатит: у пользоватеся всегда есть возможность изменить настройки своего бровзера.

>Прокатит: у пользоватеся всегда есть возможность изменить настройки своего бровзера.
Счастливый ты! Твои пользователи умеют сам менять настройки браузера.
Или перехать в другую страну.

Ну во-первых т.к. языковых версии все равно две, должен быть механизм переключения языков (ибо ни страна, ни браузер не дают гарантии того, что человек по ту сторону экрана говорит на языке этой страны или на языке браузера (мало ли, может, в инет кафешку зашел).
И второе - языком по умолчанию ставить en если geoip сказал что он знает эту страну и страна не россия, не украина и не беларусь, а иначе - инглиш. Как-то так. Странички статика или динамические?
Спасибо всем участникам. для меня это важный вопрос. У меня на сайте есть выбор языка в любом случае!
не получилось. как открывалась страница по умолчанию на англ. так и открывается. хотя у меня русский бразуер
Прикладные протоколы, веб-браузер и гипертекст – что это такое

PHP – самый распространенный в мире язык программирования сайтов

Сайты пишутся в готовых интегрированных средах, которые используют для создания пользовательских шаблонов язык PHP. Это довольно простая и самая распространенная среда для создания веб-приложений различной функциональности. Для обычного пользователя не имеет смысла писать интегрированную среду «с нуля», а стоит воспользоваться готовой cms-системой (системой управления сайтами), позволяющей написать собственную адаптацию сайта на выбранном «движке». Этого достаточно и для создания сайтов на русском языке.
Самой распространенной средой для сайтов является Wordpress, Joomla, более простой – Wordstat и другие. Каждая из этих систем поддерживает написание шаблонов в HTML, PHP, Java, C++ и на других языках (указаны по степени популярности в прикладных средах).
Особенностью современных языков программирования является использование высокоинтегрированныхсред для создания приложений. То есть программисты обычно не пишут код, как говорится, руками. Им даже достаточно составить UML-сценарии, а среда их преобразует в конечный результат на выбранном языке.
По этому принципу работают и интегрированные среды систем управления сайтами. Wordpressпозволяет создавать и переделывать сайты в удобных редакторах. И только некоторую функциональность пользователь может добавить путем внесения изменений в исходный код (таблица CSS-стилей и пользовательский Function.php). Опять же из среды можно получить доступ к этому разделу и написать короткое дополнение или функцию. Важным замечанием является тот факт, что PHPработает на стороне сервера, то есть не требует установки приложений на стороне клиента.
Языки для создания сайтов и высоконагруженных проектов
Как выяснили, задача языка программирования для сайта состоит в том, чтобы создавать тем или иным способом описание страницы. Язык гипетекста достаточно простой, к сайтам добавляется графика, функции и возможности, это делается с помощью специализированных языков программирования:
Из приведенного списка видно, что языки программирования ориентированы на разные запросы пользователей и разработчиков, пытающихся создать сайт. Профессиональные среды подразумевают создание уникальных веб-сервисов с широкой функциональностью. Это избыточно для обычного пользователя, планирующего написать свой сайт.
Какой язык выбрать для сайта?
Для создания собственного веб-сайта нужно подобрать систему управления сайтами CMS. Адаптация своего ресурса предполагает доработку готового шаблона. В Wordpress шаблоны называются темами. Для этих целей потребуется разработать собственные функции. Чтобы создавать сайт, достаточно двух языков программирования PHP и JavaScript. Для оформления текстов, конечно, необходимо знать синтаксис HTML&CSS.
Читайте также: