
Какие заголовки отправляет браузер
Обновлено: 08.07.2024
Headers can be grouped according to their contexts:
-
contain more information about the resource to be fetched, or about the client requesting the resource. hold additional information about the response, like its location or about the server providing it. contain information about the body of the resource, like its MIME type, or encoding/compression applied. contain representation-independent information about payload data, including content length and the encoding used for transport.
Headers can also be grouped according to how proxies handle them:
These headers must be transmitted to the final recipient of the message: the server for a request, or the client for a response. Intermediate proxies must retransmit these headers unmodified and caches must store them.
These headers are meaningful only for a single transport-level connection, and must not be retransmitted by proxies or cached. Note that only hop-by-hop headers may be set using the Connection header.
Authentication
Defines the authentication method that should be used to access a resource.
Contains the credentials to authenticate a user-agent with a server.
Defines the authentication method that should be used to access a resource behind a proxy server.
Contains the credentials to authenticate a user agent with a proxy server.
Caching
The time, in seconds, that the object has been in a proxy cache.
Directives for caching mechanisms in both requests and responses.
The date/time after which the response is considered stale.
General warning information about possible problems.
Client hints
Servers proactively requests the client hint headers they are interested in from the client using Accept-CH . The client may then choose to include the requested headers in subsequent requests.
Servers can ask the client to remember the set of Client Hints that the server supports for a specified period of time, to enable delivery of Client Hints on subsequent requests to the server’s origin.
The different categories of client hints are listed below.
Device client hints
Response header used to confirm the image device to pixel ratio in requests where the DPR client hint was used to select an image resource.
Approximate amount of available client RAM memory. This is part of the Device Memory API.
Client device pixel ratio (DPR), which is the number of physical device pixels corresponding to every CSS pixel.
A number that indicates the layout viewport width in CSS pixels. The provided pixel value is a number rounded to the smallest following integer (i.e. ceiling value).
The Width request header field is a number that indicates the desired resource width in physical pixels (i.e. intrinsic size of an image).
Network client hints
Network client hints allow a server to choose what information is sent based on the user choice and network bandwidth and latency.
Approximate bandwidth of the client's connection to the server, in Mbps. This is part of the Network Information API.
The effective connection type ("network profile") that best matches the connection's latency and bandwidth. This is part of the Network Information API.
Application layer round trip time (RTT) in miliseconds, which includes the server processing time. This is part of the Network Information API.
A boolean that indicates the user agent's preference for reduced data usage.
Conditionals
The last modification date of the resource, used to compare several versions of the same resource. It is less accurate than ETag , but easier to calculate in some environments. Conditional requests using If-Modified-Since and If-Unmodified-Since use this value to change the behavior of the request.
A unique string identifying the version of the resource. Conditional requests using If-Match and If-None-Match use this value to change the behavior of the request.
Makes the request conditional, and applies the method only if the stored resource matches one of the given ETags.
Makes the request conditional, and applies the method only if the stored resource doesn't match any of the given ETags. This is used to update caches (for safe requests), or to prevent uploading a new resource when one already exists.
Makes the request conditional, and expects the resource to be transmitted only if it has been modified after the given date. This is used to transmit data only when the cache is out of date.
Makes the request conditional, and expects the resource to be transmitted only if it has not been modified after the given date. This ensures the coherence of a new fragment of a specific range with previous ones, or to implement an optimistic concurrency control system when modifying existing documents.
Determines how to match request headers to decide whether a cached response can be used rather than requesting a fresh one from the origin server.
Connection management
Controls whether the network connection stays open after the current transaction finishes.
Controls how long a persistent connection should stay open.
Content negotiation
Informs the server about the types of data that can be sent back.
The encoding algorithm, usually a compression algorithm, that can be used on the resource sent back.
Informs the server about the human language the server is expected to send back. This is a hint and is not necessarily under the full control of the user: the server should always pay attention not to override an explicit user choice (like selecting a language from a dropdown).
Controls
Indicates expectations that need to be fulfilled by the server to properly handle the request.
Cookies
Learn more about CORS here.
Indicates whether the response can be shared.
Indicates whether the response to the request can be exposed when the credentials flag is true.
Specifies the methods allowed when accessing the resource in response to a preflight request.
Indicates which headers can be exposed as part of the response by listing their names.
Indicates how long the results of a preflight request can be cached.
Indicates where a fetch originates from.
Specifies origins that are allowed to see values of attributes retrieved via features of the Resource Timing API, which would otherwise be reported as zero due to cross-origin restrictions.
Downloads
Indicates if the resource transmitted should be displayed inline (default behavior without the header), or if it should be handled like a download and the browser should present a “Save As” dialog.
Message body information
The size of the resource, in decimal number of bytes.
Indicates the media type of the resource.
Used to specify the compression algorithm.
Describes the human language(s) intended for the audience, so that it allows a user to differentiate according to the users' own preferred language.
Indicates an alternate location for the returned data.
Proxies
Contains information from the client-facing side of proxy servers that is altered or lost when a proxy is involved in the path of the request.
Identifies the original host requested that a client used to connect to your proxy or load balancer.
Added by proxies, both forward and reverse proxies, and can appear in the request headers and the response headers.
Redirects
Indicates the URL to redirect a page to.
Request context
Contains an Internet email address for a human user who controls the requesting user agent.
Specifies the domain name of the server (for virtual hosting), and (optionally) the TCP port number on which the server is listening.
The address of the previous web page from which a link to the currently requested page was followed.
Governs which referrer information sent in the Referer header should be included with requests made.
Contains a characteristic string that allows the network protocol peers to identify the application type, operating system, software vendor or software version of the requesting software user agent. See also the Firefox user agent string reference.
Response context
Contains information about the software used by the origin server to handle the request.
Range requests
Indicates if the server supports range requests, and if so in which unit the range can be expressed.
Indicates the part of a document that the server should return.
Creates a conditional range request that is only fulfilled if the given etag or date matches the remote resource. Used to prevent downloading two ranges from incompatible version of the resource.
Indicates where in a full body message a partial message belongs.
Security
Allows a server to declare an embedder policy for a given document.
Prevents other domains from opening/controlling a window.
Prevents other domains from reading the response of the resources to which this header is applied.
Controls resources the user agent is allowed to load for a given page.
Allows sites to opt in to reporting and/or enforcement of Certificate Transparency requirements, which prevents the use of misissued certificates for that site from going unnoticed. When a site enables the Expect-CT header, they are requesting that Chrome check that any certificate for that site appears in public CT logs.
Provides a mechanism to allow and deny the use of browser features in its own frame, and in iframes that it embeds.
Provides a mechanism to allow web applications to isolate their origins.
Sends a signal to the server expressing the client’s preference for an encrypted and authenticated response, and that it can successfully handle the upgrade-insecure-requests directive.
Disables MIME sniffing and forces browser to use the type given in Content-Type .
The X-Download-Options HTTP header indicates that the browser (Internet Explorer) should not display the option to "Open" a file that has been downloaded from an application, to prevent phishing attacks as the file otherwise would gain access to execute in the context of the application. (Note: related MS Edge bug).
Indicates whether a browser should be allowed to render a page in a <frame> , <iframe> , <embed> or <object> .
Specifies if a cross-domain policy file ( crossdomain.xml ) is allowed. The file may define a policy to grant clients, such as Adobe's Flash Player (now obsolete), Adobe Acrobat, Microsoft Silverlight (now obsolete), or Apache Flex, permission to handle data across domains that would otherwise be restricted due to the Same-Origin Policy. See the Cross-domain Policy File Specification for more information.
May be set by hosting environments or other frameworks and contains information about them while not providing any usefulness to the application or its visitors. Unset this header to avoid exposing potential vulnerabilities.
Enables cross-site scripting filtering.
Associates a specific cryptographic public key with a certain web server to decrease the risk of MITM attacks with forged certificates.
Sends reports to the report-uri specified in the header and does still allow clients to connect to the server even if the pinning is violated.
Fetch metadata request headers
Fetch metadata request headers provides information about the context from which the request originated. This allows a server to make decisions about whether a request should be allowed based on where the request came from and how the resource will be used.
It is a request header that indicates the relationship between a request initiator's origin and its target's origin. It is a Structured Header whose value is a token with possible values cross-site , same-origin , same-site , and none .
It is a request header that indicates the request's mode to a server. It is a Structured Header whose value is a token with possible values cors , navigate , no-cors , same-origin , and websocket .
It is a request header that indicates whether or not a navigation request was triggered by user activation. It is a Structured Header whose value is a boolean so possible values are ?0 for false and ?1 for true.
It is a request header that indicates the request's destination to a server. It is a Structured Header whose value is a token with possible values audio , audioworklet , document , embed , empty , font , image , manifest , object , paintworklet , report , script , serviceworker , sharedworker , style , track , video , worker , and xslt .
Server-sent events
Defines a mechanism that enables developers to declare a network error reporting policy.
Used to specify a server endpoint for the browser to send warning and error reports to.
Transfer coding
Specifies the form of encoding used to safely transfer the resource to the user.
Specifies the transfer encodings the user agent is willing to accept.
Allows the sender to include additional fields at the end of chunked message.
WebSockets
Other
A client can express the desired push policy for a request by sending an Accept-Push-Policy header field in the request.
A client can send the Accept-Signature header field to indicate intention to take advantage of any available signatures and to indicate what kinds of signatures it supports.
Used to list alternate ways to reach this service.
Contains the date and time at which the message was originated.
Indicates that the request has been conveyed in TLS early data.
Tells the browser that the page being loaded is going to want to perform a large allocation.
A Push-Policy defines the server behavior regarding push when processing a request.
Indicates how long the user agent should wait before making a follow-up request.
The Signature header field conveys a list of signatures for an exchange, each one accompanied by information about how to determine the authority of and refresh that signature.
The Signed-Headers header field identifies an ordered list of response header fields to include in a signature.
Communicates one or more metrics and descriptions for the given request-response cycle.
Links generated code to a source map.
Controls DNS prefetching, a feature by which browsers proactively perform domain name resolution on both links that the user may choose to follow as well as URLs for items referenced by the document, including images, CSS, JavaScript, and so forth.
The X-Robots-Tag HTTP header is used to indicate how a web page is to be indexed within public search engine results. The header is effectively equivalent to <meta name="robots" content=". "> .
Заголовки могут быть сгруппированы по следующим контекстам:
-
применяется как к запросам, так и к ответам, но не имеет отношения к данным, передаваемым в теле. содержит больше информации о ресурсе, который нужно получить, или о клиенте, запрашивающем ресурс . содержат дополнительную информацию об ответе, например его местонахождение, или о сервере, предоставившем его. содержат информацию о теле ресурса, например его длину содержимого или тип MIME.
Заголовки также могут быть сгруппированы согласно тому, как прокси (proxies) обрабатывают их:
Хоп-хоп заголовки (Хоп-хоп заголовки)
Эти заголовки имеют смысл только для одного соединения транспортного уровня и не должны повторно передаваться прокси или кешироваться. Обратите внимание, что с помощью общего заголовка Connection могут быть установлены только заголовки переходов.
Аутентификация
WWW-Authenticate (en-US)
Определяет метод аутентификации, который должен использоваться для доступа к ресурсу.
Authorization
Содержит учётные данные для аутентификации агента пользователя на сервере.
Proxy-Authenticate (en-US)
Определяет метод аутентификации, который должен использоваться для доступа к ресурсам на прокси-сервере.
Proxy-Authorization (en-US)
Содержит учётные данные для аутентификации агента пользователя с прокси-сервером.
For the rel=prefetch case, see Link Prefetching FAQ
Содержит URL-адрес ресурса, из которого был запрошен обрабатываемый запрос. Если запрос поступил из закладки, прямого ввода адреса пользователем или с помощью других методов, при которых исходного ресурса нет, то этот заголовок отсутствует или имеет значение "about:blank".
Примечание
Note: The Keep-Alive request header is not sent by Gecko 5.0 ; previous versions did send it but it was not formatted correctly, so the decision was made to remove it for the time being. The Connection or Proxy-Connection header is still sent, however, with the value "keep-alive".

Пример
Теперь давайте рассмотрим структуру более подробно.


- getallheaders() получает запросы headers. Вы можете использовать массив $_SERVER.
- headers_list() получает отзывы headers.
Далее в этой статье мы увидим примеры кода в PHP.

- "method" указывает, какой это запрос. Наиболее распространённые методы GET, POST и HEAD.
- "path" , как правило, является частью URL-адреса, который идёт после host (домена). Например, если запрос "https://net.tutsplus.com/tutorials/other/top-20-mysql-best-practices/" , часть path будет "/tutorials/other/top-20-mysql-best-practices/".
- Часть "protocol" содержит "HTTP" и версию, которая обычно 1.1 в современных браузерах.
Остальная часть запроса содержит HTTP headers как пары "Name: Value" в каждой строке. Они содержат различную информацию о HTTP-запросе и вашем браузере. Например, строка "User-Agent" предоставляет информацию о версии браузера и операционной системе, которую вы используете. "Accept-Encoding" сообщает серверу, может ли ваш браузер принимать сжатый output, например gzip.
И вы всё равно получите правильный ответ от веб-сервера.
Методы запроса
Три наиболее часто используемых метода запроса: GET, POST и HEAD. Вы, вероятно, уже знакомы с первыми двумя, начиная с написания html-форм.
GET: получение документа
Это основной метод, используемый для извлечения html, изображений, JavaScript, CSS и т. д. С использованием этого метода запрошено большинство данных, загружаемых в ваш браузер.
Как только html загрузится, браузер начнет отправлять GET-запрос изображений, который может выглядеть так:
Веб-формы можно настроить под метод GET. Вот пример.
Вы можете видеть, что каждый ввод формы был добавлен в строку запроса.
POST: отправка данных на сервер
Даже если вы можете отправлять данные на сервер с помощью GET и строки запроса, во многих случаях POST будет предпочтительнее. Отправка больших объёмов данных с помощью GET нецелесообразна и имеет ограничения.
Запросы POST чаще всего отправляются веб-формами. Давайте изменим предыдущий пример формы на метод POST.
Здесь нужно отметить три важных момента:
- Путь в первой строке просто /foo.php, и больше нет строки запроса.
- Добавлены заголовки Content-Type и Content-Length, которые предоставляют информацию об отправляемых данных.
- Все данные теперь отправляются после заголовков, в том же формате, что и строка запроса.
Запросы POST метода также могут быть сделаны через AJAX, приложения, cURL и т. д. И все формы загрузки файлов необходимы для использования метода POST.
HEAD: получение информации заголовка
С помощью этого метода браузер может проверить, был ли документ изменён для целей caching. Он также может проверить, существует ли документ вообще.
Например, если у вас много ссылок на веб-сайте, вы можете периодически отправлять HEAD-запросы каждой из них, чтобы проверить наличие неработающих ссылок. Это будет намного быстрее, чем при использовании GET.

Опять же, большинство этих headers на самом деле являются необязательными.
- 200 используются для успешных запросов.
- 300 для перенаправления.
- 400 используются, если возникла проблема с запросом.
- 500 используются, если возникла проблема с сервером.
200 OK
Как упоминалось ранее, этот код состояния отправляется в ответ на успешный запрос.
206 Partial Content
Если приложение запрашивает только диапазон запрошенного файла, возвращается код 206.
Это часто используется с менеджерами закачек, которые могут остановить и возобновить загрузку или разделить загрузку на части.
404 Not Found

Когда запрашиваемая страница или файл не найдена, сервер отправляет код ответа 404.
401 Unauthorized
Защищённые паролем веб-страницы отправляют этот код. Если вы не ввели логин правильно, вы можете увидеть следующее в вашем браузере.


403 Forbidden
Если вам не разрешен доступ к странице, этот код может быть отправлен в ваш браузер. Это часто происходит, когда вы пытаетесь открыть URL-адрес для папки, в которой нет индексной страницы. Если параметры сервера не позволяют отображать содержимое папки, вы получите ошибку 403.

Существуют другие способы блокировки доступа и 403 могут быть отправлены. Например, вы можете блокировать по IP-адресу с помощью некоторых директив htaccess.
302 (or 307) Moved Temporarily & 301 Moved Permanently
Эти два кода используются для перенаправления браузера. Например, когда вы используете службу сокращения URL, такую как bit.ly, именно так они перенаправляют людей, которые идут по ссылке.
500 Internal Server Error

Complete List
Почти все эти заголовки можно найти в массиве $ _SERVER в PHP. Вы также можете использовать функцию getallheaders() для извлечения всех заголовков одновременно.
Это в основном имя host, включая домен и поддомен.
User-Agent
Этот заголовок может содержать несколько частей информации, таких как:
- Имя и версия браузера.
- Название и версия операционной системы.
- Язык по умолчанию.
Именно так веб-сайты могут собирать определённую общую информацию о своих системах surfers. Например, они могут определить, использует ли surfer мобильный браузер и перенаправляет их на мобильную версию своего веб-сайта, который лучше работает с низким разрешением.
Accept-Language
Он может содержать несколько языков, разделённых запятыми. Первый - это предпочтительный язык, и каждый из перечисленных языков может иметь значение «q», которое представляет собой оценку предпочтения пользователя для языка (min. 0 max. 1).
В PHP его можно найти так: $ _SERVER ["HTTP_ACCEPT_LANGUAGE"].
Accept-Encoding
В PHP его можно найти так: $ _SERVER ["HTTP_ACCEPT_ENCODING"]. Однако, когда вы используете функцию обратного вызова ob_gzhandler(), она будет проверять значение автоматически, поэтому вам это не нужно.
If-Modified-Since
Если веб-документ уже сохранен в кеше в браузере и вы посещаете его снова, ваш браузер может проверить, был ли документ обновлён, отправив следующее:
Если он не изменялся с этой даты, сервер отправляет код ответа «304 Not Modified», а содержимое - нет, и браузер загружает содержимое из cache.
Cookie
Как следует из названия, это отправляет файлы cookie, хранящиеся в вашем браузере для этого домена.
Это пары name=value, разделённые точками с запятой. Cookies могут также содержать id сеанса.
В PHP отдельные cookie-файлы могут быть доступны с помощью массива $ _COOKIE. Вы можете напрямую обращаться к переменным сеанса, используя массив $ _SESSION, и если вам нужен id сеанса, вы можете использовать функцию session_id () вместо cookie.
Referer
Например, если я зашел на домашнюю страницу Nettuts + и нажал ссылку на статью, этот header будет отправлен в мой браузер:
Authorization
Данные внутри header имеют кодировку base64. Например, base64_decode ('bXl1c2VyOm15cGFzcw ==') возвратит 'myuser: mypass'
В PHP эти значения можно найти как $ _SERVER ['PHP_AUTH_USER'] и $ _SERVER ['PHP_AUTH_PW'].
Подробнее об этом будет, когда мы поговорим о заголовке WWW-Authenticate.
В PHP вы можете установить заголовки ответа, используя функцию header(). PHP уже отправляет определённые заголовки автоматически, для загрузки содержимого и настройки файлов cookie и прочее. Вы можете увидеть headers, которые отправляются или будут отправляться с помощью функции headers_list (). Вы можете проверить, были ли уже отправлены заголовки с помощью функции headers_sent().
Cache-Control
"public" означает, что ответ может быть кэширован кем угодно. "max-age" указывает, сколько секунд действителен кеш. Разрешение кэширования вашего сайта может снизить нагрузку на сервер и пропускную способность, а также увеличить время загрузки в браузере.
Кэширование также может быть предотвращено с помощью директивы "no-cache".
Content-Type
Этот header указывает "mime-type" документа. Затем браузер определяет, как интерпретировать содержимое на основании этого. Например, страница html (или PHP-скрипт с выходом html) может возвращать это:
"text" - это тип, а "html" - подтип документа. Заголовок также может содержать больше информации, такой как charset.
Для gif-изображения это может быть отправлено.
Браузер может использовать внешнее приложение или расширение браузера на основе mime-type. Например, это приведет к загрузке Adobe Reader:
Вы можете найти список общих типов mime here.
В PHP вы можете использовать функцию finfo_file() для определения mime-типа файла.
Content-Disposition
Этот header указывает браузеру открыть окно загрузки файла, вместо того, чтобы пытаться проанализировать содержимое. Пример:
Это заставит браузер сделать это:

Обратите внимание, что соответствующий заголовок Content-Type также должен быть отправлен вместе с этим:
Content-Length
Когда контент будет передаваться браузеру, сервер может указать его размер (в байтах), используя этот header.
Это особенно полезно при загрузке файлов. Именно так браузер может определить ход загрузки.
Например, вот сценарий-макет, который я написал, имитирует медленную загрузку.

Теперь я собираюсь закомментировать заголовок Content-Length
Теперь результат такой:

Браузер может только сказать, сколько байтов было загружено, но он не знает общую сумму. И индикатор выполнения не показывает прогресс.
Это еще один header, который используется для кеширования. Это выглядит так:
Если значение Etag документа совпадает с этим, сервер будет отправлять код 304 вместо 200, и никакого содержимого. Браузер будет загружать содержимое из своего кеша.
Last-Modified
Как следует из названия, этот header указывает дату последнего изменения документа в формате GMT:
Мы уже говорили об этом ранее в разделе "If-Modified-Since".
Location
Set-Cookie
Когда веб-сайт хочет установить или обновить файл cookie в вашем браузере, он будет использовать этот header.
Что приводит к отправке этого заголовка:
Если дата истечения срока действия не указана, cookie удаляется, когда окно браузера закрыто.
WWW-Authenticate
Что будет выглядеть так:
В руководстве PHP есть section, в котором приведены образцы кода, как это сделать в PHP.
Content-Encoding
Этот header обычно устанавливается, когда возвращаемое содержимое сжимается.
В PHP, если вы используете функцию обратного вызова ob_gzhandler(), она будет автоматически установлена.
Заключение

Сегодня быть онлайн — это привычное состояние для многих людей. Все мы покупаем, общаемся, читаем статьи, ищем информацию на разные темы. Сеть соединяет нас со всем миром, но прежде всего, она соединяет людей. Я сам пользуюсь интернетом уже 20 лет, и мои отношения с ним изменились восемь лет назад, когда я стал веб-разработчиком.
Разработчики соединяют людей.
Разработчики помогают людям.
Разработчики дают людям возможности.
Сервер отвечает запрашиваемым ресурсом, но также отправляет заголовки ответа, содержащие информацию о ресурсе или самом сервере.
Сеть должна быть безопасной
Раньше я никогда не чувствовал опасности, когда искал что-то в интернете. Но чем больше я узнавал о всемирной паутине, тем больше я беспокоился. Вы можете почитать, как хакеры меняют глобальные CDN-библиотеки, случайные сайты майнят криптовалюту в браузере своих посетителей, а также о том, как с помощью социальной инженерии люди регулярно получают доступ к успешным проектам с открытым исходным кодом. Это нехорошо. Но почему вас должно это волновать?
Если вы сегодня разрабатываете для веба, то не просто пишете код. Сегодня в веб-разработке над одним сайтом работает много людей. Возможно, вы также используете много открытого исходного кода. Кроме того, для маркетинговых целей вы можете включить несколько сторонних скриптов. Сотни людей предоставляют код, запущенный на вашем сайте. И разработчикам приходится работать в подобных реалиях.
Можно ли доверять всем этим людям и всему исходному коду?
Я не думаю, что следует доверять какому-либо стороннему коду. К счастью, есть способы защитить свой сайт и сделать его более безопасным. Кроме того, такие инструменты, как helmet могут быть полезны, например, для экспресс-приложений.
Если вы хотите проанализировать, сколько стороннего кода запускается на вашем сайте, можно посмотреть в панели разработчика или попробовать Request Map Generator.
CSP — четко укажите, что разрешено на вашем сайте
Однако CSP касается не только используемого протокола. Он предлагает детальные способы определения того, какие ресурсы и действия разрешены на вашем сайте. Вы можете, например, указать, какие скрипты должны выполняться или откуда загружать изображения. Если что-то не разрешено, браузер блокирует это действие и предотвращает потенциальные атаки на ваш сайт.
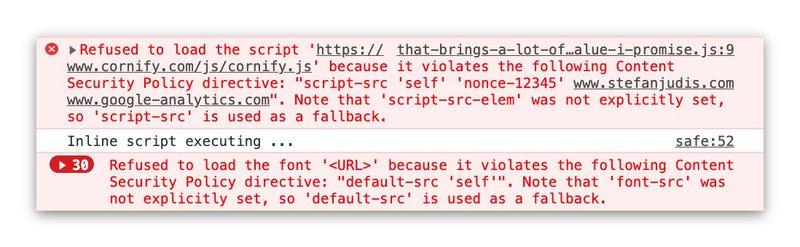
На момент написания статьи для CSP существовало 24 различных варианта конфигурации. Они варьируются от скриптов через таблицы стилей вплоть до сервис-воркеров.

Вы можете найти полный обзор на MDN.
Используя CSP, вы можете указать, что должен включать ваш сайт, а что нет.
Вышеприведенный набор правил предназначен для моего личного сайта, и если вы считаете, что этот пример определения CSP очень сложный, то вы абсолютно правы. Я внедрил у себя этот набор с третьей попытки, развёртывая и снова откатывая, потому что он несколько раз ломал сайт. Но есть способ получше.
Чтобы избежать взлома вашего сайта, CSP также предоставляет режим только для отчетов.
Используя режим Content-Security-Policy-Report-Only , браузеры просто записывают ресурсы, которые были бы заблокированы, вместо их фактической блокировки. Этот механизм отчетности позволяет проверить и настроить ваш набор правил.
Рекомендуемый процесс выглядит так: сначала запустите CSP в режиме отчета, проанализируйте входящие нарушения с реальным трафиком, и только тогда, когда не будет обнаружено нарушений ваших контролируемых ресурсов, включите его.
Общее внедрение CSP

Сеть должна быть доступной
Пока я пишу эту статью, я сижу перед относительно новым MacBook, используя быстрое домашнее Wi-Fi-подключение. Разработчики часто забывают, что такая ситуация не является стандартной для большинства наших пользователей. Люди, посещающие наши сайты, пользуются старыми телефонами и сомнительными соединениями. Тяжелые и перегруженные сайты с сотнями запросов оставляют им плохое впечатление.
И дело не только во впечатлении. Люди платят различные суммы за трафик в зависимости от места проживания. Представьте себе, вы создаете сайт для больницы. Информация на нём может иметь решающее значение и спасти жизни людей. Если страница на сайте больницы имеет размер 5 Мб, то она не только будет медленно работать, но и может оказаться слишком дорогой для тех, кто больше всего в ней нуждается. Цена пяти мегабайтов трафика в Европе или США ничтожна по сравнению с ценой в Африке. Разработчики несут ответственность за доступность веб-страниц для всех. Эта ответственность включает в себя предоставление правильных ресурсов, выбор правильных инструментов (действительно ли вам нужен JS-фреймворк для лендинга?) и недопущение запросов.
Cache-Control — избегайте запросов на неизменные ресурсы
Сегодня сайт может содержать сотни ресурсов, от CSS до скриптов и изображений. Используя заголовок Cache-Control , разработчики могут указать, как долго ресурс должен считаться «свежим» и может отдавать из кэша браузера.
При правильной настройке Cache-Control передача данных сохраняется, и файлы могут использоваться из кэша браузера в течение определенного количества секунд ( max-age ). Браузеры должны повторно проверять кэшированные ресурсы по истечении этого периода времени.
Однако, если посетители обновляют страницу, браузеры всё равно повторно проверяют её, включая ссылки на ресурсы, чтобы убедиться, что кэшированные данные всё ещё действительны. Серверы отвечают заголовком 304, сигнализируя, что кэшированные данные пока действительны, или заголовком 200 при передаче обновленных данных. Это позволяет сохранить переданные данные, но не обязательно сделанные запросы.
Именно здесь вступает в игру функция immutable .
Immutable — никогда не запрашивать ресурс дважды
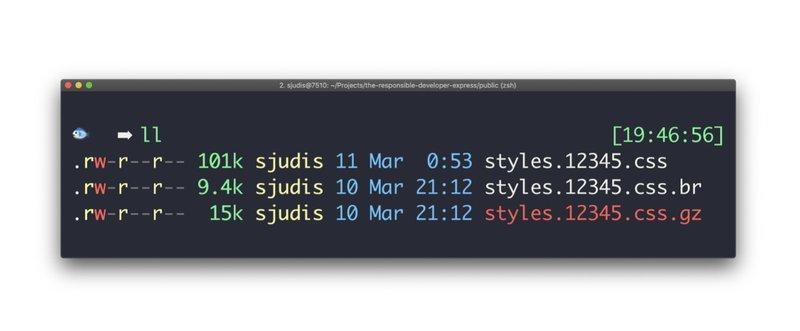
В современных frontend-приложениях файлы CSS и скриптов обычно имеют уникальные имена, например, styles.123abc.css . Имя этого файла зависит от содержимого. И при изменении содержимого файлов меняются и их имена.
Эти уникальные файлы потенциально могут храниться в кэше вечно, включая ситуацию, когда пользователь обновляет страницу. Функция immutable может запретить браузеру повторную проверку ресурса в определенный промежуток времени. Это очень важно для объектов с контрольными суммами, и помогает избежать повторных проверочных запросов.
Реализовать оптимальное кэширование очень сложно, а особенно браузерное кэширование не слишком интуитивно понятно, поскольку имеет различные конфигурации. Я рекомендую ознакомиться со следующими материалами:
- Гарри Робертс написал отличное руководство по управлению кэшем и его настройкам.
- Джек Арчибальд дал советы по лучшим методикам кэширования с иллюстрациями.
- Илья Григорик предложил отличную технологическую схему для кэширования заголовков.
Accept-Encoding — максимальное сжатие (до минимума)
С помощью Cache control мы можем сохранять запросы и уменьшать объем данных, которые многократно передаются по сети. Мы можем не только экономить запросы, но и сокращать то, что передается.
Отдавая ресурсы, разработчики должны позаботиться о том, чтобы отправлять как можно меньше данных. Для текстовых ресурсов, таких как HTML, CSS и JavaScript, сжатие играет важную роль в экономии передаваемых данных.
Самым популярным методом сжатия сегодня является GZIP. Серверам хватает мощности для сжатия текстовых файлов на лету и предоставления сжатых данных при запросе. Но GZIP уже не самый лучший вариант.
Если вы взглянете на создаваемые браузером запросы текстовых файлов, таких как HTML, CSS и JavaScript, и проанализируете заголовки, то найдете среди них accept-encoding .
Этот алгоритм сжатия был создан с учетом небольшого размера файлов. Если вы попробуете сжать файл вручную на вашем локальном устройстве, то обнаружите, что Brotli действительно сжимает лучше, чем GZIP.
Вы, возможно, слышали, что сжатие Brotli выполняется медленнее. Причина в том, что Brotli имеет 11 режимов сжатия, и по умолчанию выбирается тот, при котором получаются файлы наименьшего размера, что удлиняет процедуру. GZIP, с другой стороны, имеет 9 режимов, и по умолчанию выбирается тот, при котором учитывается как скорость сжатия, так и размера файла. В результате режим Brotli по умолчанию непригоден для сжатия «на лету», но если изменить режим, то можно добиться сжатия небольших файлов с той же скоростью, что и у GZIP. Вы можете использовать его для сжатия на лету и рассматривать как потенциальную замену GZIP для поддерживающих браузеров.
Кроме того, если вы хотите максимально экономить файлы, то можете забыть о динамическом сжатии и предварительно сгенерировать оптимизированные GZIP-файлы с помощью файлов zopfli и Brotli для их статического обслуживания.
Если вы хотите прочитать больше о сжатии Brotli и его сравнении с GZIP, сотрудники компании Akamai провели обширное исследование на эту тему.
Accept и Accept-CH — обслуживайте индивидуальные ресурсы для пользователя
Оптимизация текстовых ресурсов очень важна для экономии килобайтов, но как насчёт более тяжелых ресурсов, таких как изображения, чтобы сэкономить ещё больше объёма данных?
Accept — обслуживание изображений правильного формата
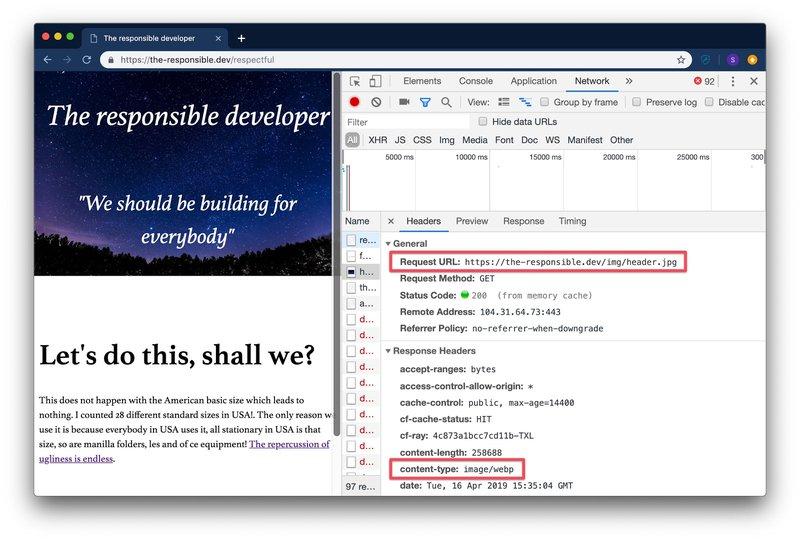
Браузеры не только показывают нам, какие алгоритмы сжатия они понимают. Когда браузер запрашивает изображение, он также предоставляет информацию о том, какие форматы файлов он понимает.
Несколько лет велась борьба вокруг нового формата изображений, но выиграл webp. Webp — это формат изображений, изобретенный Google, и поддержка этого формата сейчас очень актуальна.
Используя этот заголовок запроса, разработчики могут передавать изображение webp , даже если браузер запросил image.jpg , в результате чего размер файла будет меньше. Дин Хьюм написал хорошее руководство о том, как это применять. Очень круто!
Accept-CH — обслуживание изображений правильного размера
Вы также можете включить клиентские подсказки для поддерживающих эту функцию браузеров. Клиентские подсказки — это способ сказать браузерам, чтобы они посылали дополнительную информацию о ширине области просмотра, ширине изображения и даже сетевых условиях, таких как RTT (время на передачу и подтверждение) и типе соединения, например 2g .
Вы можете активировать подсказки, добавив мета-элемент:
Или задав заголовки в исходном запросе HTML:
В последующих запросах браузеры начнут посылать дополнительную информацию за определенный промежуток времени ( Accept-CH-Lifetime в секундах), что может помочь разработчикам адаптировать изображения к условиям пользователя, не меняя HTML.
Например, для получения дополнительной информации, такой как ширина изображения на стороне сервера, вы можете снабдить свои изображения атрибутом sizes , чтобы дать браузеру дополнительную информацию о том, как эти изображения будут выглядеть.
С полученным заголовком ответа Accept-CH и изображениями с атрибутом sizes браузеры будут включать заголовки viewport-width и width в запросы изображений, показывая вам, какое изображение подойдёт лучше всего.
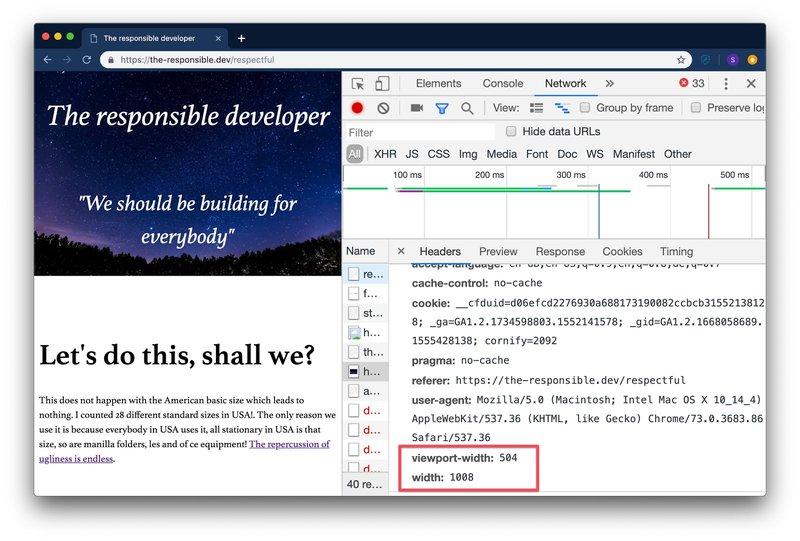
Имея поддерживаемый формат и размеры изображения, вы можете отправлять адаптированные данные без необходимости записывать ненадежные элементы изображений и обращать внимание только на формат и размер файлов, как показано ниже.
Если у вас есть доступ к ширине области просмотра (viewport) и размеру изображений, вы можете на своих серверах поставить логику изменения размера ресурсов во главу угла.
Однако нужно учитывать, что не следует создавать изображения для любой ширины просто потому, что у вас есть точная ширина изображения. Отправка изображений для определенного диапазона размеров ( image-200 , image-300 , . ) помогает использовать CDN-кэширование и экономит время вычислений.
Кроме того, с такими современными технологиями, как service worker’ы, вы даже можете перехватывать и изменять запросы прямо в клиенте, чтобы обслуживать лучшие файлы изображений. С включенными клиентскими подсказками service worker’ы получают доступ к информации о макетах, и в сочетании с API изображений, как, например, Cloudinary, вы можете настроить url изображения прямо в браузере для получения картинок надлежащего размера.
Если вы ищете более подробную информацию о клиентских подсказках, можете ознакомиться со статьями Джереми Вагнера или Ильи Григорика на эту тему.
Сеть должна быть бережной
Поскольку каждый из нас проводит в сети много часов в день, есть последний аспект, который я считаю очень важным — сеть должна быть бережной.
Preload — сокращение времени ожидания
Будучи разработчиками, мы ценим время наших пользователей. Никто не хочет терять время. Как уже говорилось в предыдущих главах, предоставление нужных данных играет большую роль в экономии времени и трафика. Речь идёт не только о том, какие запросы делаются, но и о сроках и порядке их выполнения.
Приведу пример: если вы добавите на сайт таблицу стилей, браузеры не будут ничего показывать, пока она не загрузится. Пока на экране ничего не отображается, браузер продолжает анализировать HTML в поисках других ресурсов для запрашивания. После загрузки и парсинга таблицы стилей в ней могут оказаться ссылки на другие важные ресурсы, такие как шрифты, которые тоже могут быть запрошены. Этот процесс может увеличить время загрузки страницы для ваших посетителей.
Используя Rel=preload вы можете дать браузеру информацию о том, какие ресурсы будут запрошены в ближайшее время.
Можете предварительно загрузить ресурсы через HTML-элементы:
Таким образом, браузер получает заголовок или находит элемент ссылки, и немедленно запрашивает ресурсы, чтобы они уже находились в кэше, когда понадобятся. Этот процесс экономит время ваших посетителей.
Для оптимальной предварительной загрузки ресурсов и понимания всех конфигураций я рекомендую обратить внимание на следующие материалы:
-
является экспертом по предварительной загрузке, он опубликовал прекрасный материал по этой теме.
подробно рассказал о preload и других инструментах, таких как prefetch и preconnect.
Feature-Policy — не раздражайте других
Меньше всего я хочу видеть сайты, запрашивающие у меня разрешения без причины. Я могу лишь процитировать своего коллегу Фила Нэша по этому поводу.
Не требуйте разрешение при загрузке страницы. Разработчики должны относиться с уважением и не создавать сайты, раздражающие посетителей. Люди просто кликают на все окна с разрешениями. Если мы не используем их правильно, то сайты и разработчики теряют доверие, а новые блестящие функции — свою привлекательность.
Но что, если ваш сайт обязательно должен включать много стороннего кода, и все эти скрипты запускают множество диалоговых окон с разрешением? Как убедиться, что все включённые скрипты ведут себя правильно?
Именно здесь в игру вступает заголовок Feature-Policy. С его помощью вы можете указать, какие функции разрешены, и ограничить всплывающие диалоговые окна с разрешениями, которые могут быть вызваны сторонним кодом, исполняемым на вашем сайте.
Вы можете настроить это поведение для сайта с помощью заголовка. Также можно задать этот заголовок для встроенного контента, например, плавающих фреймов, которые могут быть обязательными для интеграции со сторонними разработчиками.
На момент написания статьи заголовок Feature-Policy был, скорее, экспериментальным, но интересно посмотреть на его будущие возможности. В недалеком будущем разработчики смогут не только ограничивать себя и не допускать появления раздражающих диалоговых окон, но также блокировать неоптимизированные данные. Эти функции существенно улучшат работу пользователей.

Вы можете найти полный обзор на MDN.
Глядя на список выше, вы можете вспомнить о самом раздражающем моменте — push-уведомлениях. Оказалось, что применение Feature-Policy для push-уведомлений сложнее, чем ожидалось. Если вы хотите узнать больше, можете подписаться на соответствующую тему на GitHub.
Благодаря feature policy можете быть уверены, что вы и сторонние ресурсы не превратите ваш сайт в гонку за разрешениями, которая, к сожалению, уже стала привычной для многих сайтов.
Сеть должна быть для всех
Я знаю, что создание отличного сайта сегодня — очень сложная задача. Разработчики должны учитывать дизайн, устройства, фреймворки, и да… заголовки тоже играют определённую роль. Надеюсь, эта статья даст вам некоторые идеи, и вы будете учитывать безопасность, доступность и уважительность в ваших следующих веб-проектах, потому что это именно те факторы, которые делают сеть по-настоящему отличным местом для всех.
Читайте также: