
Не учитывать регистр 1с
Обновлено: 07.07.2024
Данная статья является анонсом новой функциональности.
Не рекомендуется использовать содержание данной статьи для освоения новой функциональности.
Полное описание новой функциональности будет приведено в документации к соответствующей версии.
Полный список изменений в новой версии приводится в файле v8Update.htm.
Планируется в версии 8.3.20
Когда мы пишем запросы и создаем отчёты, нередко бывает нужно не просто показать данные в том виде, в котором они лежат в БД, а произвести над ними какие-то операции. Например, посчитать разницу между двумя датами или округлить число до нужной разрядности. Хорошо, если нужная функция есть в языке запросов (или в языке СКД) - тогда мы можем сделать с данными то, что хотим, на уровне запроса / СКД, а потом просто отобразить результат. Если же нужная функция в языке запросов не реализована – приходится делать постобработку запроса в языке 1С, проходясь в цикле по результатам запроса и выполняя нужные операции. Что приводит к разрастанию кода конфигурации и может снизить производительность.
К нам довольно часто обращаются разработчики с пожеланиями о добавлении дополнительных функций в язык запросов и язык СКД. Мы внимательно проанализировали пожелания и выделили список наиболее востребованных функций, которые планируем реализовать в версии 8.3.20.
Язык запросов
В язык запросов добавляются функции:
Строка(String) – преобразует значение в примитивного типа в строку с учетом национальных установок.
Тригонометрические функции Sin, Cos, Tan, ASin, ACos, ATan (все вычисления производятся в радианах)
Exp - вычисляет результат возведения основания натурального логарифма (числа e) в степень
Log - вычисляет натуральный логарифм числа.
Log10 - вычисляет десятичный логарифм числа.
Pow - вычисляет возведение в степень.
Sqrt – вычисляет квадратный корень.
Окр(Round) - округляет исходное число до нужной разрядности
Цел(Int) - вычисляет целую часть переданного числа, полностью отсекая дробную часть.
ДлинаСтроки(StringLength) – вычисляет длину строки.
СокрЛ(TrimL) – отбрасывает незначащие пробелы слева.
СокрП(TrimR) – отбрасывает незначащие пробелы справа.
СокрЛП(TrimAll) – отбрасывает незначащие пробелы слева и справа.
Лев(Left) – получает первые слева символы строки.
Прав(Right) – получает первые справа символы строки.
СтрНайти(StrFind) – находит первую позицию подстроки в строке (без учета регистра).
ВРег(Upper) – преобразует все символы строки в верхний регистр.
НРег(Lower) – преобразует все символы строки в нижний регистр.
СтрЗаменить(StrReplace) – заменяет все вхождения подстроки на другую подстроку (без учета регистра).
РазмерХранимыхДанных(StoredDataSize) – возвращает размер данных в байтах, которые занимают данные параметра.
Система компоновки данных
В язык выражений системы компоновки данных добавлены новые функции:
СокрЛ(TrimL) – отбросить незначащие пробелы слева.
СокрП(TrimR) – отбросить незначащие пробелы справа.
СокрЛП(TrimAll) – отбросить незначащие пробелы слева и справа.
Лев(Left) – получить первые слева символы строки.
Прав(Right) – получить первые справа символы строки.
СтрНайти(StrFind) – найти подстроку в строке (без учета регистра).
ВРег(Upper) – преобразует все символы строки в верхний регистр.
НРег(Lower) – преобразует все символы строки в нижний регистр.
СтрЗаменить(StrReplace) – заменяет все вхождения подстроки на другую подстроку (без учета регистра).
НСтр(NStr) – получает строку на языке пользователя (аналогично тому, как работает метод НСтр глобального контекста). Параметры:
ИсходнаяСтрока – строка, содержащая строки на разных языках (например, "ru = 'Добрый вечер!'; en = 'Good Evening!'").
КодЯзыка (необязательный) – строка с кодом языка, на котором нужно получать строку. Если не указан - строка получается на языке текущего пользователя.
Как-то при переносе данных в одну животноводческую базу, я столкнулся со странным поведением выполнения довольно простого кода. У меня было множество животных с уникальными шифрами, описывающими их породу. Те, кто помнят школьные уроки по генетики, знают, что доминантные гены принято изображать большими буквами, а рецессивные - маленькими. Для остальных небольшая иллюстрация для понимания:
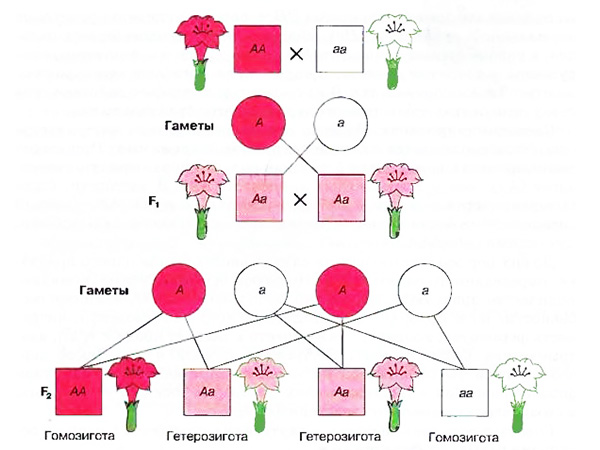
Казалось бы, что загрузку написал правильно, но результат в базе не соответствовал данным источника - данные по некоторым животным были перепутаны, а по части вообще ничего не загрузилось. Пристальное изучение несоответствий показало, что путаница наблюдались в тех случаях, когда шифры животных различались не составом, а только регистром.
Поиск по данным в базе
Давайте попробуем воссоздать пример с картинки выше и создадим справочник "Виды цветов" с тремя элементами: АА -> красный, Аа -> розовый и аа -> белый. Проблему можно увидеть сразу, если попытаться наш код внести в стандартное поле "Код":
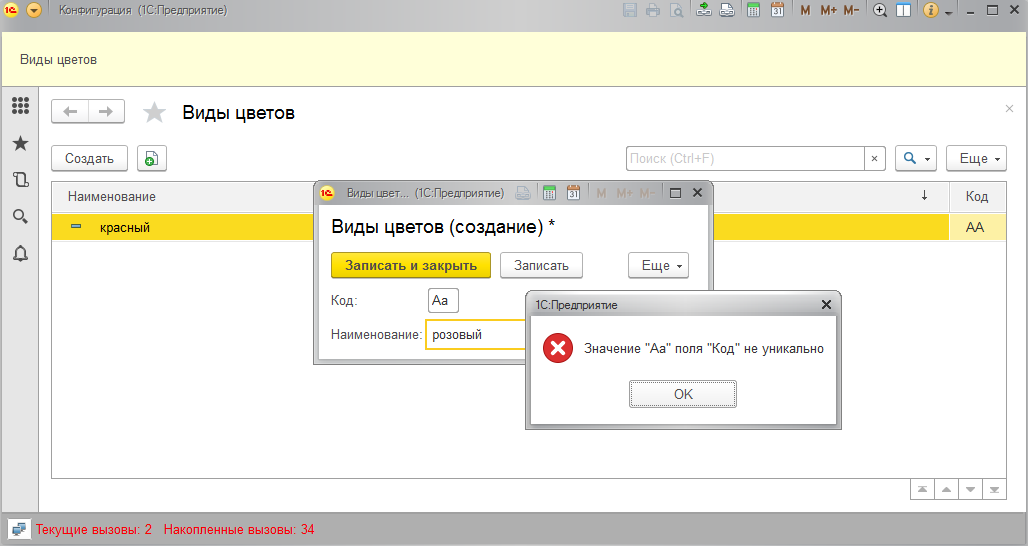
Заметим, что таким образом мы можем задать элементу справочника код А00001 и при автонумерации получим А00002, А00003 и так далее. Так же мы можем задать код а00001 и получить а00002, а00003. Но если мы при наличии А00001 по какой-то причине захотим установить номер а00001, то получить "облом".
Аналогичное поведение при тестировании кодов/номеров я обнаружел у документов, задач, бизнес-процессов, планов видов характеристик, планов счетов и планов обмена. Но у планов видов расчетов, однако, разрешается создать одновременно элементы с номерами "А00001" и "а00001", что очень странно - тут можно было бы сослаться на то, что у плана видов расчетов в настройках отсутствует свойство включения/отключения контроля уникальности номера, но этого свойства так же нет и у плана обменов. В документации о такой выборочно действующей особенности поведения ничего не написано. Если я просто не увидел, то напишите в комментариях.
Кстати, поскольку удалось создать несколько видов расчета с идентичными кодами, то это прекрасный повод проверить результат функции НайтиПоКоду(). Только предварительно я воспользуюсь отсутствием у плана видов расчетов контроля уникальности номеров и добавлю еще один элемент с большой "А" - интересно какой из этих двух элементов будет выбран:
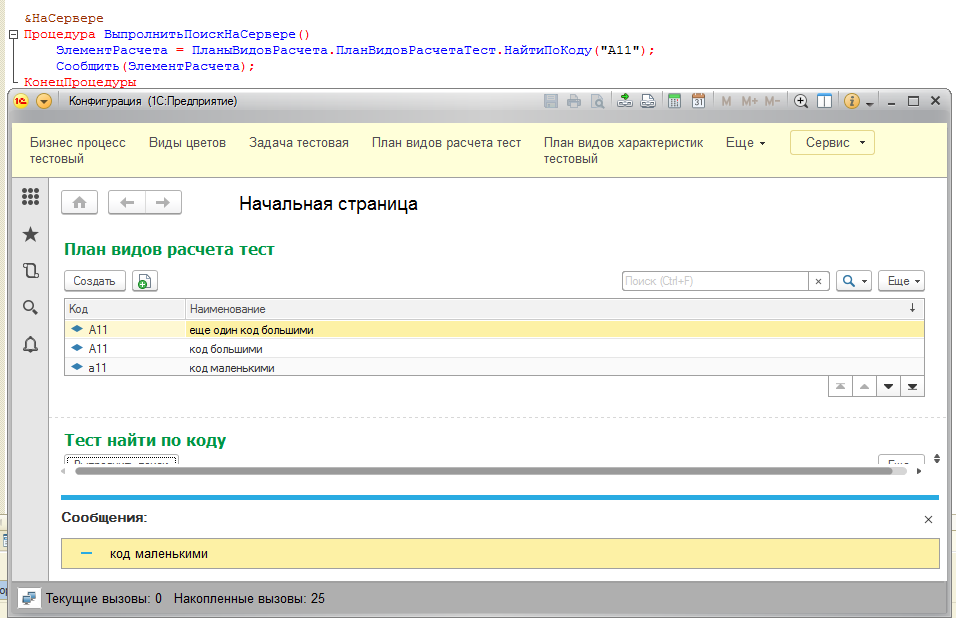
Да, уж. Согласитесь, результат оказался неожиданным и он подтверждает ранее замеченное наблюдение, что для платформы 1С регистр символов как минимум в кодах/номерах значения не умеет. Выходит, создавая код на нашей платформе, программист получает по факту выполнения: 1040 = КодСимвола("А") = КодСимвола("а") = 1072 , и лишь конечный пользователь системы видит на экране реальные символы.
Но продолжим нашу проверку. Обычно на практике для всяких внешних кодов используют реквизиты - в моем случае было так же. Создадим такой для справочника "Виды цветов" и попробуем воспользоваться другим стандартным поисковым методом - НайтиПоРеквизиту():
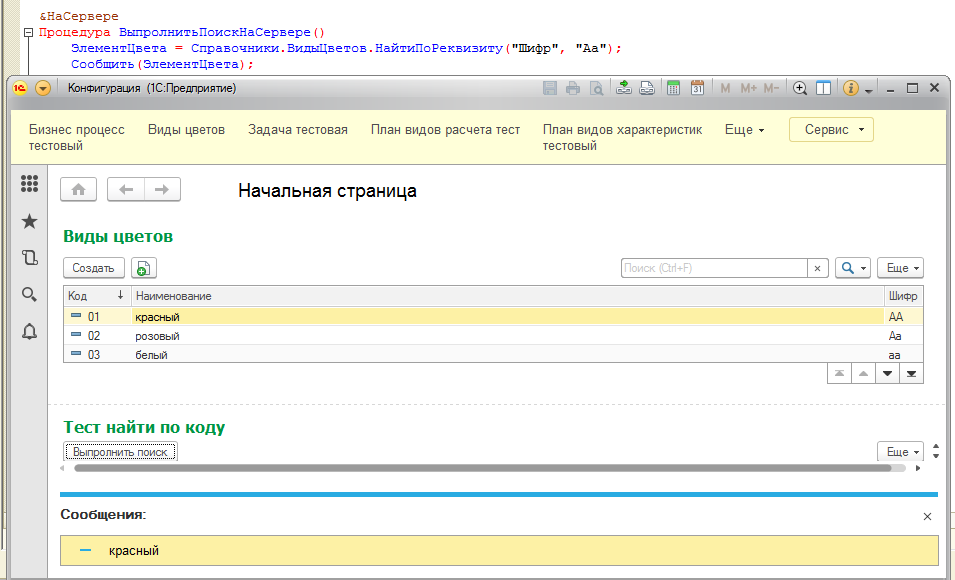
Как раз с этим я и столкнулся при переносе - в поиске по реквизиту регистр символов игнорируется.
Хотя, как оказывается, не обязательно быть программистом, что бы испытать дискомфорт при точном поиске - аналогичное поведение наблюдается и при использовании отборов СКД в динамическом списке (видимо одна и та же поисковая функция из внутренней библиотеки):

Для полноты картины, давайте протестируем последний оставшийся метод - ПоискПоНаименованию() и получим тот же результат (даже требование "точного соответствия" не помогло):
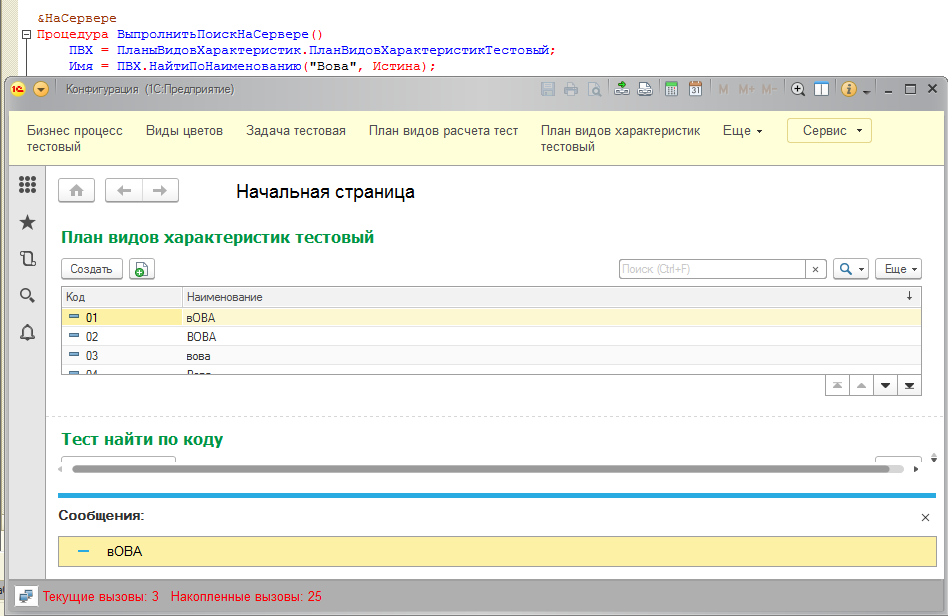
Итак, поисковые методы менеджеров объектов отказываются правильно искать чувствительные к регистру символов данные. А можно ли самостоятельно создать подобные методы с помощью механизма запросов? Давайте попробуем:
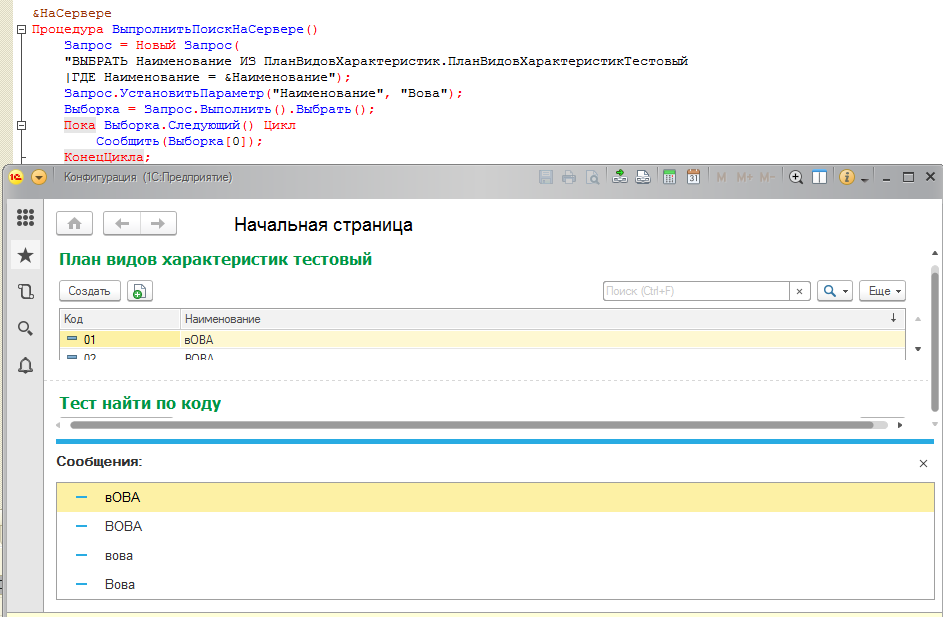
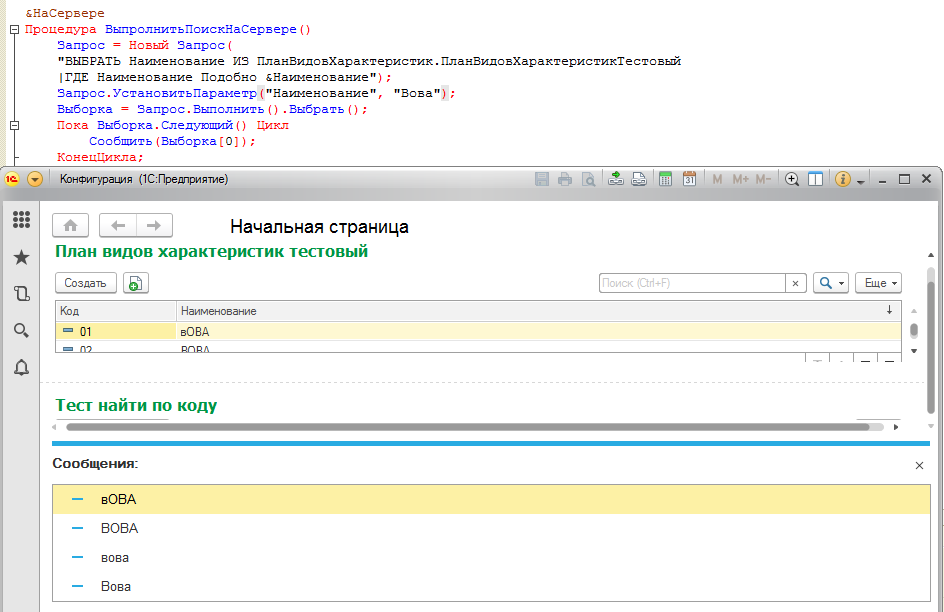
Как видите, ни использования оператора "=" в тексте запроса, ни оператор "Подобно" не помогли - каждый раз выбираются все похожие элементы, игнорируя регистры символов.
Т.е. для текста запроса, который транслируется в SQL и выполняется во внешних СУБД, снова верно выражение: 1040 = КодСимвола("А") = КодСимвола("а") = 1072. Я уже приготовился, что все во что я верил ложно и в мире 1С будет справделиво ("А" = "а") = Истина, но к счастью хотя бы примитивное сравнение строк работает и нужную нам функцию все же можно создать:
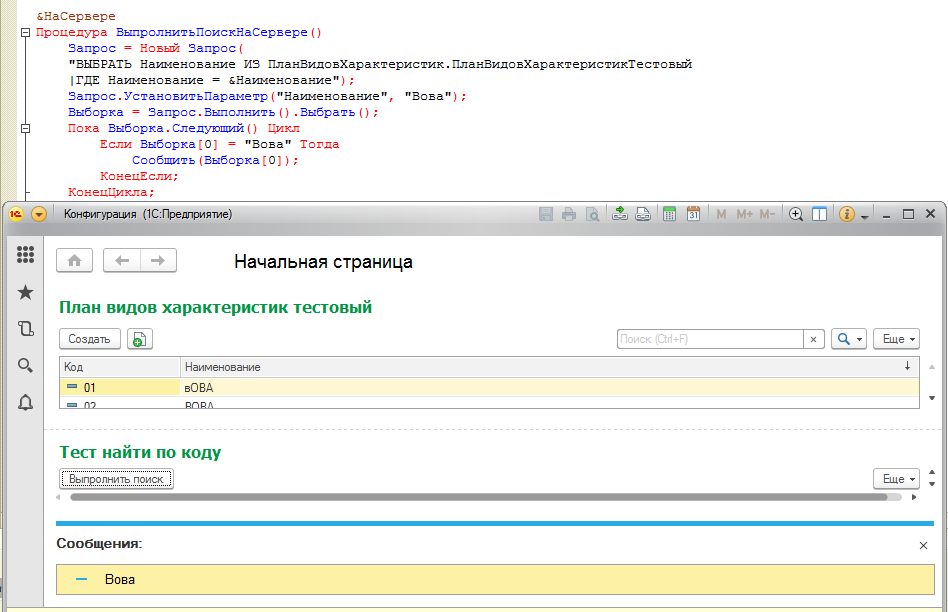
Поиск по коллекциям
С данными базы как мы уже убедились - грустно. А как дело обстоит с коллекциями?
Массив - обнаружена чувствительность к регистру символов в обычном и фиксированном вариантах для метода Найти().
Таблица значений - методы Найти() и НайтиСтроки() чувствительны к регистру.
Список значений - метод НайтиПоЗначению() чувствителен к регистру символов.
Детективная история
Сразу покажу на небольшом примере почему это так важно.
Пусть у нас есть начисление заработной платы за январь:
В начале февраля мы создаём ведомость на выплату зарплаты из кассы и нажимаем кнопку "Заполнить":
И получаем следующее:
Но ведь за январь:
- Начисление 50 000 рублей
- НДФЛ 6 500 рублей
- Итого к выплате 43 500 рублей
Где закралась ошибка? Что пошло не так? Неужели теперь всегда вводить сумму к выплате вручную?
Опытный бухгалтер тут же сделает оборотно-сальдовую ведомость по 70 счёту:
И будет в ещё большем недоумении, потому что по данным отчёта к выплате выходят всё те же 43 500! И откуда же взялись лишние 5 000 рублей?
Причём такая ситуация (с любыми расчётами) может произойти как в "тройке", так и в "двойке".
Сегодня я попытаюсь приоткрыть завесу тайны - почему же иногда программа ведёт себя так странно. Я расскажу как в таких случаях находить и устранять ошибку. Ближе к концу статьи мы разберёмся - откуда же взялись эти самые 5 000 рублей.
Учимся видеть регистры
При проведении документов 1С:Бухгалтерия 8 делает проводки по бухгалтерским счетам (кнопка ДтКт у любого документа):
Именно на основании этих проводок строятся все бухгалтерские отчёты: Анализ счёта, Карточка счёта, Оборотно-сальдовая ведомость.
Но есть огромный пласт данных, которые пишутся программой параллельно с проводками и используются для всего остального: заполнение КУДИР, книги покупок и продаж, регламентированной отчётности. заработной платы к выплате, наконец
Как вы уже, наверное, догадались этот пласт называется регистрами, вот он:
Я сейчас не буду вдаваться в подробности описания самих регистров, чтобы не запутать вас ещё больше.
Скажу лишь, что нам просто жизненно необходимо постепенно учиться "видеть" движения по этим регистрам, чтобы лучше понимать и, когда надо, корректировать поведение программы.
Давайте присмотримся к регистру "Зарплата к выплате" - именно он имеет смысл для решения нашей проблемы с лишними 5 000:
Мы видим две записи по этому регистру, сделанные в приход, то есть в плюс. Если пролистать экран в право, то мы увидим в первой строчке сумму к выплате "-6 500", а во второй "50 000".
Остаток по этому регистру -6 500 + 50 000 равен 43 500, который и должен попасть в документ "Ведомость на выплату из кассы", когда мы нажимаем на кнопку "Заполнить".
Ещё раз повторюсь - ведомость на выплату определяет нашу задолженность по заработной плате перед сотрудником не по 70 счёту, а по регистру "Зарплата к выплате" .
Получается мы знаем, что зарплата к выплате заполняется на основании этого регистра, но даже видя записи регистра не можем понять что не так.
Скорее всего мы не видим всей картины (может быть существуют другие записи по этому регистру) и напрашивается некий инструмент для анализа регистра подобный бухгалтерским отчётам.
Учимся анализировать регистры
И такой инструмент есть, он называется "Универсальный отчёт".
Переходим в раздел "Отчеты" пункт "Универсальный отчёт":
Выбираем тип регистра "Регистр накопления", регистр "Зарплата к выплате" и нажимаем кнопку "Сформировать":
Получилось не очень информативно:
Всё потому, что требуется предварительная настройка отчёта, нажимаем кнопку "Показать настройки" и на закладке "Группировка" добавляем поле "Сотрудник":
На закладке "Отборы" делаем отбор по нашей организации:
Нажимаем кнопку "Сформировать":
Вот это уже более интересно. Видим остаток к выплате нашему сотруднику те самые 48 500 рублей!
Снова заходим в настройки отчёта и добавляем на закладку "Показатели" новое поле "Регистратор":
Снова формируем отчёт:
Вот теперь мы прекрасно видим, что 5 000 появились как результат операции (видимо ввода остатков) 31 декабря 2014 года.
И нам нужно либо изменить эту операцию, либо вручную откорректировать регистр "Зарплата к выплате" и закрыть эти 5 000 рублей, например, 31 декабря 2015 года.
Давайте пойдём вторым путём. Итак, наша задача - сделать так, чтобы на начало 2016 года по регистру "Зарплата к выплате" не было нашей задолженности перед сотрудником.
Это делается ручной операцией.
Учимся корректировать регистры
Заходим в раздел "Операции" пункт "Операции, введенные вручную":
Создаём новую операцию концом 2015 года:
Из меню "Ещё" выбираем пункт "Выбор регистров. ":
Указываем регистр "Зарплата к выплате" и нажимаем ОК:
Переходим на появившуюся закладку регистра и делаем расход на 5 000 рублей:
Этим самым мы как бы отнимаем от регистра 5 000 рублей по сотруднику, чтобы выйти на ноль к началу 2016 года.
Проводим операцию и заново формируем универсальный отчёт:
Всё получилось! Видим, что наша ручная операция от 31.12.2015 вывела остаток в ноль и зарплата к выплате после начисления равна ожидаемым 43 500.
Замечательно. И сейчас мы проверим это в ведомости на выплату.
Но прежде я хочу обратить ваше внимание на ещё один важный момент:
Обратите внимание, что остатки на начало и на конец по группировке "Сотрудник" показывают ерунду. Это никакая не ошибка, это нюанс, который нужно учитывать, связанный с архитектурными особенностями 1с.
Запомните. В том случае, если универсальный отчёт выводится с детализацией до документа (регистратора) - остатки по группировкам будут показывать ерунду.
Если нам требуются остатки по группировке сотрудник - нужно сначала удалить из настроек добавленный нами показатель "Регистратор":
И только потом формировать отчёт:
Сейчас остатки показаны корректно.
Результат
Напоследок убедимся, что мы сделали всё правильно. Снова заходим в ведомость на выплату заработной платы за январь и нажимаем кнопку "Заполнить":
Мы молодцы, на этом пока всё
Кстати, подписывайтесь на новые уроки.
С уважением, Владимир Милькин (преподаватель школы 1С программистов и разработчик обновлятора).
Как помочь сайту: расскажите (кнопки поделиться ниже) о нём своим друзьям и коллегам. Сделайте это один раз и вы внесете существенный вклад в развитие сайта. На сайте нет рекламы, но чем больше людей им пользуются, тем больше сил у меня для его поддержки.
Особенности сравнения строк при работе с базой данных
Вся функциональность 1С:Предприятия делится на ту, которая выполняется в памяти компьютера (клиентского или серверного) и на ту, которая выполняется средствами базы данных (средствами СУБД). К последней относятся прежде всего, конечно, запросы. Но, кроме запросов, многие методы глобального контекста и прикладных объектов выполняются средствами СУБД.
Хотя в 1С:Предприятии 8 системы типов встроенного языка и базы данных максимально унифицированы, тем не менее, существуют отличия в работе конкретных операций.
Одним из существенных отличий является сравнение строк. Во встроенном языке все сравнения строк выполняются с учетом регистра символов (case sensitive). А во всех операциях с базой данных сравнения строк выполняются без учета регистра символов (case insensitive).
Разумеется, для проверки без учета регистра во встроенном языке можно использовать приведение к верхнему или нижнему регистру.
Например:
"Ф" = "ф" - ложь
ВРег("Ф") = ВРег("ф") – истина.
При работе с запросом или другими операциями с базой данных нужно учитывать тот факт, что сравнение выполняется без учета регистра.
Например, это влияет на механизм нумерации. Коды и номера прикладных объектов (справочников, документов и т.д.) поддерживаются без учета регистра, так как их поддержка осуществляется средствами базы данных. Например, если попытаться установить у нового объекта код, который будет отличаться от кода существующего объекта только регистром символов, то будет сформировано исключение «Код не уникален!». Префиксы нумерации также действуют без учета регистра символов. Таким образом, в кодах и номерах лучше использовать только большие символы – это облегает понимание работы системы пользователем.
Если реализуется некоторый алгоритм, выполняемый в памяти, но который должен по своей логике совпадать с логикой работы в базе данных (например, выполнять поиск строки), то может иметь смысл при сравнении строк выполнять приведение к верхнему регистру, чтобы обеспечить сравнение без учета регистра.
Читайте также: