Не выгружается в excel
Обновлено: 05.07.2024
- MSSQL 2000 SP3
- EXCEL 2000
Обрабатываю Excel-файл С помощью DTS Package используя представленный ActiveX Task
Наблюдая Процессы в Task Manager вижу что в момент запуска DTS там появляется строка с EXCEL .
После завершения DTS он (EXCEL) должен выгрузится (после команды objXL.Quit ) но. EXCEL остается .
Дело в том что в моем DTS еще два раза обрабатывается тот же самый Excel-файл (используются еще два аналогичных ActiveX Task). И после каждого в Task Manager остается по одному EXCEL. После запуска DTS Package 3-4 раза подряд остаются "висеть" 9-12 EXCEL'ов.
По идее - после objXL.Quit такого не должно быть.
Попробуй включить objXL.Visible = True и objXL.Application.DisplayAlerts = True. Скорее всего выдаётся ошибка или предупреждение..
Такой вариант не годится поскольку он предполагает чтобы в момент запуска DTS никакой другой EXCEL не был запущен. Все делается под конечных пользователей с которыми трудно добиться чтобы перед запуском DTS (который вызывается из ХП , которая в свою очередь вызывается из ASP) они закрывали все работающие EXCEL.
Кстати, если создать новый Excel-файл с листом по имени rates и обрабатывать его моим DTS то все нормально (EXCEL выгружается по завершении DTS).
А в оригинальном Excel-файле (в DTS его имя в переменной NAME_XLS_RATES)
кроме 8 листов со справочниками есть еще 2000 строк кода на VBA для работы с этими справочниками (один из справочников в листе rates c курсами валют за последний год).
Я сначала думал что когда при открытии Excel-файла он предуприждает насчет макросов (отключать / не отключать их) . Но нет. Для пробы удалил вообще макросы из NAME_XLS_RATES - все тоже самое.
Я вот подумал может пойти другим путем .
Можно ли из DTS после завершения каждого скрипта выгружать EXCEL принудительно на манер как в Task Manager. Наверняка какая-нибудь соответсвующая утилита есть из арсенала OS Windows 2000. А в DTS использовать Execute Process Task
1. Создал новый Excel-файл
2. Через КлипБоард перетащил в него содержание всех листов из "плохого" Excel-файла
3. Перетащил в него же все макросы из "плохого"
4. Запустил DTS
После окончания работы DTS в ТаскМенеджере никакой EXCEL не остается
Этот "плохой" Excel-файл "живет" уже два года. За это время VBA-код увеличился c 200 строк да 2000. Его раз 900 запускали юзеры (интенсивно менялся лист rate) соответсвенно раз 900 он сохранялся.Не говоря уже обо мне во время отладки.
Модератор: Модераторы
Не выгружает в эксель
ACD Чт Июл 19, 2018 14:39
Все работало. При выгрузке большой сметы в эксель наверное что-то пошло не так? Пишет ошибку (во вложение), подвал выгружает, а саму форму нет. Переустановил офис, сделал полную переустановку компонентов сметы, ничего не помогает. Пришлось ставить программу на другой компьютер. Подскажите как устранить такую ошибку (win 10)?Ваша реклама
Timur Чт Июл 19, 2018 16:26
файл по указанной директории открывается в excel без ошибок?
Если файл не открывается или выдает ошибки при открытии, то удалите его. Возможно он поврежден.
ACD Чт Июл 19, 2018 16:36
ACD Чт Июл 19, 2018 16:40
Это происходит со всеми объектами, сметами, актами, КС6 и пр.Timur Пт Июл 20, 2018 9:07
ACD писал(а): Но файл без образования выходных форм сохраняется (ошибка появляется до настроек выходных форм)Совсем непонятно о чем речь. Удаление файла MainList.xls не решило проблему?
ACD писал(а): При его открытии в нем похоже находится весь source.
ACD Пт Июл 20, 2018 9:57
Пошаговый процесс при выгрузке из сметы в ексель в моем случае: 1. нажимаю значек ексель; 2. Нажимаю сохранить файл; 3. Начинается процесс - появляется заставка ексель; 4. Через несколько секунд выдает ошибку "Ошибка при открытии книги"; 5. Закрываю ошибку; 6. Проверяю в файле MainList.xls настройки (макросы включены и т.д.), при попытке выбрать документ, опять выдает ошибку "Ошибка при открытии книги"; 7. Закрываю файл MainList.xls; 8. Выгружаемая смета однако сохранилась, но в ней нет сформированной формы (т.к. ее даже не удалось назначить), только вспомогательные листы source и др.Mikle Пт Июл 20, 2018 14:41
Что то блокирует запуск макроса по открытию и формированию отчета. Поскольку Вы утверждаете, что в настройках Excel макросы включены, Excel переустанавливался то остается вариант с блокированием средствами антивируса.Можно еще в системном логе посмотреть информацию, возможно там есть что-то связанное с этой ошибкой, что позволит ее локализовать.
Володя1990 Пт Июл 20, 2018 18:30
Если я правильно понял, то при экспорте в эксель происходит ошибка.
Когда открываем сам main, то в нём или сформированная смета или сурс той сметы, которую экспортировали.
Есть в IT-отрасли задачи, которые на фоне успехов в big data, machine learning, blockchain и прочих модных течений выглядят совершенно непривлекательно, но на протяжении десятков лет не перестают быть актуальными для целой армии разработчиков. Речь пойдёт о старой как мир задаче формирования и выгрузки Excel-документов, с которой сталкивался каждый, кто когда-либо писал приложения для бизнеса.

Какие возможности построения файлов Excel существуют в принципе?
- VBA-макросы. В наше время по соображениям безопасности идея использовать макросы чаще всего не подходит.
- Автоматизация Excel внешней программой через API. Требует наличия Excel на одной машине с программой, генерирующей Excel-отчёты. Во времена, когда клиенты были толстыми и писались в виде десктопных приложений Windows, такой способ годился (хотя не отличался скоростью и надёжностью), в нынешних реалиях это с трудом достижимый случай.
- Генерация XML-Excel-файла напрямую. Как известно, Excel поддерживает XML-формат сохранения документа, который потенциально можно сгенерировать/модифицировать с помощью любого средства работы с XML. Этот файл можно сохранить с расширением .xls, и хотя он, строго говоря, при этом не является xls-файлом, Excel его хорошо открывает. Такой подход довольно популярен, но к недостаткам следует отнести то, что всякое решение, основанное на прямом редактировании XML-Excel-формата, является одноразовым «хаком», лишенным общности.
- Наконец, возможна генерация Excel-файлов с использованием open source библиотек, из которых особо известна Apache POI. Разработчики Apache POI проделали титанический труд по reverse engineering бинарных форматов документов MS Office, и продолжают на протяжении многих лет поддерживать и развивать эту библиотеку. Результат этого reverse engineering-а, например, используется в Open Office для реализации сохранения документов в форматах, совместимых с MS Office.
Но у прямого использования Apache POI есть и недостатки. Во-первых, это Java-библиотека, и если ваше приложение написано не на одном из JVM-языков, вы ей вряд ли сможете воспользоваться. Во-вторых, это низкоуровневая библиотека, работающая с такими понятиями, как «ячейка», «колонка», «шрифт». Поэтому «в лоб» написанная процедура генерации документа быстро превращается в обильную «лапшу» трудночитаемого кода, где отсутствует разделение на модель данных и представление, трудно вносить изменения и вообще — боль и стыд. И прекрасный повод делегировать задачу самому неопытному программисту – пусть ковыряется.
Но всё может быть совершенно иначе. Проект Xylophone под лицензией LGPL, построенный на базе Apache POI, основан на идее, которая имеет примерно 15-летнюю историю. В проектах, где я участвовал, он использовался в комбинации с самыми разными платформами и языками – а счёт разновидностей форм, сделанных с его помощью в самых разнообразных проектах, идёт, наверное, уже на тысячи. Это Java-проект, который может работать как в качестве утилиты командной строки, так и в качестве библиотеки (если у вас код на JVM-языке — вы можете подключить её как Maven-зависимость).
Xylophone реализует принцип отделения модели данных от их представления. В процедуре выгрузки необходимо сформировать данные в формате XML (не беспокоясь о ячейках, шрифтах и разделительных линиях), а Xylophone, при помощи Excel-шаблона и дескриптора, описывающего порядок обхода вашего XML-файла с данными, сформирует результат, как показано на диаграмме:

Шаблон документа (xls/xlsx template) выглядит примерно следующим образом:

Как правило, заготовку такого шаблона предоставляет сам заказчик. Вовлечённый заказчик с удовольствием принимает участие в создании шаблона: начиная с выбора нужной формы из «Консультанта» или придумывания собственной с нуля, и заканчивая размерами шрифтов и ширинами разделительных линий. Преимущество шаблона в том, что мелкие правки в него легко вносить уже тогда, когда отчёт полностью разработан.
Когда «оформительская» работа выполнена, разработчику остаётся
- Создать процедуру выгрузки необходимых данных в формате XML.
- Создать дескриптор, описывающий порядок обхода элементов XML-файла и копирования фрагментов шаблона в результирующий отчёт
- Обеспечить привязку ячеек шаблона к элементам XML-файла с помощью XPath-выражений.
Если бы в форме, которую мы создаём, не было повторяющихся элементов с разным количеством (таких, как строки накладной, которых разное количество у разных накладных), то дескриптор выглядел бы следующим образом:
Здесь root – название корневого элемента нашего XML-файла с данными, а диапазон A1:Z100 – это прямоугольный диапазон ячеек из шаблона, который будет скопирован в результат. При этом, как можно видеть из предыдущей иллюстрации, подстановочные поля, значения которых заменяются на данные из XML-файла, имеют формат
(тильда, фигурная скобка, XPath-выражение относительно текущего элемента XML, закрывающая фигурная скобка).
Что делать, если в отчёте нам нужны повторяющиеся элементы? Естественным образом их можно представить в виде элементов XML-файла с данными, а помочь проитерировать по ним нужным образом помогает дескриптор. Повторение элементов в отчёте может иметь как вертикальное направление (когда мы вставляем строки накладной, например), так и горизонтальное (когда мы вставляем столбцы аналитического отчёта). При этом мы можем пользоваться вложенностью элементов XML, чтобы отразить сколь угодно глубокую вложенность повторяющихся элементов отчёта, как показано на диаграмме:

Красными квадратиками отмечены ячейки, которые будут являться левым верхним углом очередного прямоугольного фрагмента, который пристыковывает генератор отчёта.
Есть и ещё один возможный вариант повторяющихся элементов: листы в книге Excel. Возможность организовать такую итерацию тоже имеется.
Рассмотрим чуть более сложный пример. Допустим, нам надо получить сводный отчёт наподобие следующего:

Пусть диапазон лет для выгрузки выбирает пользователь, поэтому в этом отчёте динамически создаваемыми являются как строки, так и столбцы. XML-представление данных для такого отчёта может выглядеть следующим образом:
Мы вольны выбирать названия тэгов по своему вкусу, структура также может быть произвольной, но с оглядкой на простоту конвертации в отчёт. Например, выводимые на лист значения я обычно записываю в атрибуты, потому что это упрощает XPath-выражения (удобно, когда они имеют вид @имяатрибута ).
Шаблон такого отчёта будет выглядеть так (сравните XPath-выражения с именами атрибутов соответствующих тэгов):

Теперь наступает самая интересная часть: создание дескриптора. Т. к. это практически полностью динамически собираемый отчёт, дескриптор довольно сложен, на практике (когда у нас есть только «шапка» документа, его строки и «подвал») всё обычно гораздо проще. Вот какой в данном случае необходим дескриптор:
Полностью элементы дескриптора описаны в документации. Вкратце, основные элементы дескриптора означают следующее:
- element — переход в режим чтения элемента XML-файла. Может или являться корневым элементом дескриптора, или находиться внутри iteration . С помощью атрибута name могут быть заданы разнообразные фильтры для элементов, например
- name="foo" — элементы с именем тэга foo
- name="*" — все элементы
- name="tagname[@attribute='value']" — элементы с определённым именем и значением атрибута
- name="(before)" , name="(after)" — «виртуальные» элементы, предшествующие итерации и закрывающие итерацию.
- mode="horizontal" — режим вывода по горизонтали (по умолчанию — vertical)
- index=0 — ограничить итерацию только самым первым встреченным элементом
- sourcesheet —лист книги шаблона, с которого берётся диапазон вывода. Если не указывать, то применяется текущий (последний использованный) лист.
- range – диапазон шаблона, копируемый в результирующий документ, например “A1:M10”, или “5:6”, или “C:C”. (Применение диапазонов строк типа “5:6” в режиме вывода horizontal и диапазонов столбцов типа “C:C” в режиме вывода vertical приведёт к ошибке).
- worksheet – если определён, то в файле вывода создаётся новый лист и позиция вывода смещается в ячейку A1 этого листа. Значение этого атрибута, равное константе или XPath-выражению, подставляется в имя нового листа.
Ну что же, настало время скачать Xylophone и запустить формирование отчёта.
Возьмите архив с bintray или Maven Central (NB: на момент прочтения этой статьи возможно наличие более свежих версий). В папке /bin находится shell-скрипт, при запуске которого без параметров вы увидите подсказку о параметрах командной строки. Для получения результата нам надо «скормить» ксилофону все приготовленные ранее ингредиенты:
Открываем файл report.xlsx и убеждаемся, что получилось именно то, что нам нужно:![]()
Так как библиотека ru.curs:xylophone доступна на Maven Central под лицензией LGPL, её можно без проблем использовать в программах на любом JVM-языке. Пожалуй, самый компактный полностью рабочий пример получается на языке Groovy, код в комментариях не нуждается:
У класса XML2Spreadsheet есть несколько перегруженных вариантов статического метода process , но все они сводятся к передаче всё тех же «ингредиентов», необходимых для подготовки отчёта.Важная опция, о которой я до сих пор не упомянул — это возможность выбора между DOM и SAX парсерами на этапе разбора файла с XML-данными. Как известно, DOM-парсер загружает весь файл в память целиком, строит его объектное представление и даёт возможность обходить его содержимое произвольным образом (в том числе повторно возвращаясь в один и тот же элемент). SAX-парсер никогда не помещает файл с данными целиком в память, вместо этого обрабатывает его как «поток» элементов, не давая возможности вернуться к элементу повторно.
Использование SAX-режима в Xylophone (через параметр командной строки -sax или установкой в true параметра useSax метода XML2Spreadsheet.process ) бывает критически полезно в случаях, когда необходимо генерировать очень большие файлы. За счёт скорости и экономичности к ресурсам SAX-парсера скорость генерации файлов возрастает многократно. Это даётся ценой некоторых небольших ограничений на дескриптор (описано в документации), но в большинстве случаев отчёты удовлетворяют этим ограничениям, поэтому я бы рекомендовал использование SAX-режима везде, где это возможно.
Надеюсь, что способ выгрузки в Excel через Xylophone вам понравился и сэкономит много времени и нервов — как сэкономил нам.
Совсем недавно мне была поставлена задача, написать сервис, который будет заниматься всего лишь одной, но очень емкой задачей – собирать большой объем данных из базы, агрегировать и заполнять все это в Excel по определенному шаблону. В процессе поиска лучшего решения было опробовано несколько подходов, решены проблемы, связанные с памятью и производительностью. В этой статье я хочу поделиться с вами основными моментами и этапами реализации данной задачи.
1. Постановка задачи
В связи с тем, что мне нельзя разглашать подробности ТЗ, сущности, алгоритмы сбора данных и т. д. Пришлось придумать что-то аналогичное:
У нас есть 3 таблицы:
User. Хранит имя пользователя и его некий рейтинг (не важно откуда он берется и как считается)
Состав колонок будет следующим:
![]()
В Excel Заказчик хочет видеть 4 колонки 1) message_date. 2) name. 3) rating. 4) text. Ограничение по количеству строк 1 млн. Надо заполнить этими данными excel, а дальше заказчик уже будет работать с этими данными в екселе самостоятельно.
2. Задача понятна, начнем поиск решения
Так как в компании все стараются придерживаться единого стиля в разработке приложений, то и мне пришлось начать с самого обычного подхода, который используется во всех остальных микросервисах – это Spring + Hibernate для запуска приложения и работы с БД. В качестве БД используется Oracle, хотя использование любой другой СУБД будет плюс минус похожим.
Для старта приложения нам понадобится зависимость spring-boot-starter-data-jpa, которая объединяет в себе сразу Spring Data, Hibernate и JPA, все это нам понадобится для удобства работы с БД и нашими сущностями.
Для тестирования добавим spring-boot-starter-test
И еще нам нужен сам драйвер для подключения к БД
Далее нам нужно добавить некоторые настройки конфигурации. У нас будет один метод, который будет ходить в таблицу TASK, искать задачу в статусе “CREATED” и, если такая задача существует, то запускать генерацию отчета с параметрами. Предполагается, что генерация отчета может быть долгой, поэтому наш метод будет запускаться по расписанию в два потока асинхронными процессами. Так же для Spring Data укажем наш репозиторий для поиска соответствующих сущностей. Класс конфигурации будет выглядеть следующим образом:
Класс генерации отчетов содержит в себе @Scheduled метод, который раз в минуту ищет Task и, если находит, то запускает генерацию отчета с параметрами из этой таски.
Класс стартер приложения не имеет ничего примечательного, весь код можно посмотреть на GitHub.
3. Выборка данных из БД
Т.к. в компании повсеместно используется Hibernate было решено использовать его. Добавлено entity MessageData с необходимым набором полей (id, name, rating, messageDate, test). Первой попыткой выбрать необходимые данные была попытка в лоб – выгрузить все в List<Message> с помощью простого метода:
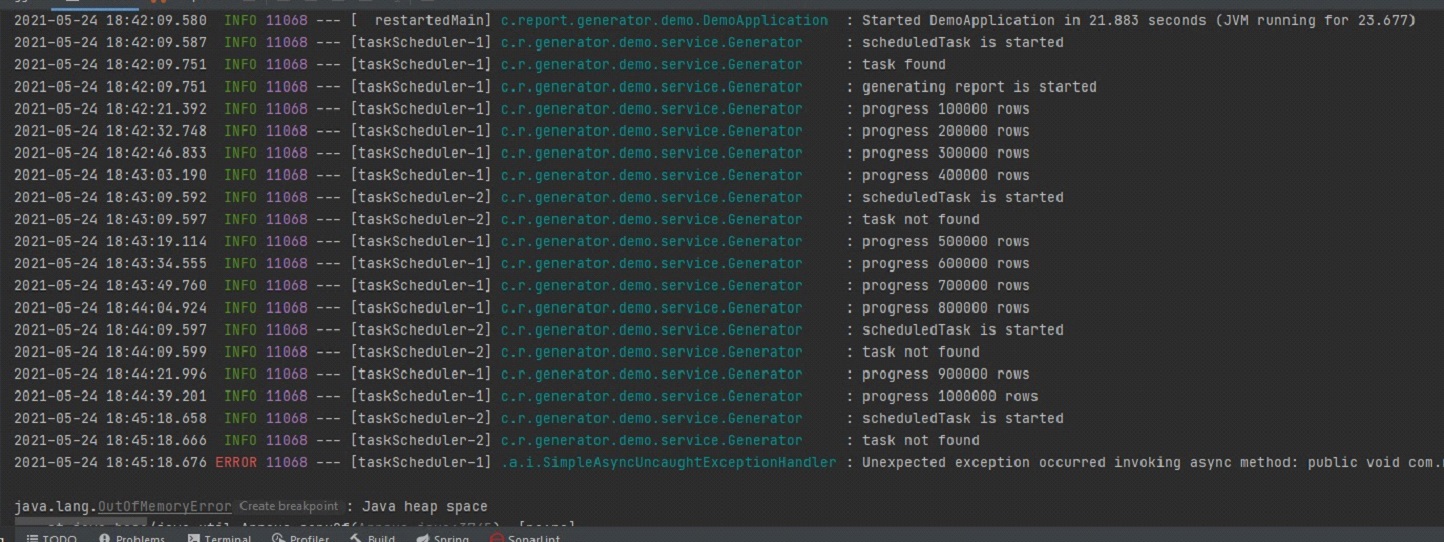
А дальше уже в цикле создавать объекты MessageData и обогащать их недостающими данными. Было очевидно, что данных подход в корне не верный и выгружать сразу миллион записей в List как минимум медленно. Но для эксперимента и замера скорости работы проверить хотелось, чтобы потом сравнить с другими вариантами. Но в результате данный набор записей выгружался около 30 минут после чего было получено OutOfMemoryError и на этом эксперимент завершился.
Даже если бы пользователь задал узкие рамки в параметрах и нам бы удалось выбрать все в один List, то дальше мы бы столкнулись со следующей проблемой – для заполнения всех необходимых колонок нужно было бы собирать id пользователей, идти снова в базу, получать их имена и рейтинги, и заполнить уже с полными данными. Сложность такого алгоритма вырастала в разы. Было понятно, что выборку надо производить по частям и переложить все возможные действия с данными на сторону бд. Чтобы не выбирать все разом и, чтобы не городить велосипедов, было решено использовать ScrollableResults. Это позволяет нам получить ссылку на курсор и итерироваться по результатам с определенным шагом. Далее пришлось переписать запрос так, чтобы он возвращал сразу все необходимые данные уже после всех джойнов, объединений, группировок и т. д.
Следующий вопрос – где хранить сам текст запроса. Это был не простая ситуация т.к. в действительности количество таблиц, которые участвовали в запросе было около десяти, количество джойнов и всяческих группировок было огромным, в результате чего текст запроса вышел на 200+ строк после ревью всевозможных коллег и утверждении самим тех лидом. Хранить такой запрос в java коде не хотелось, плюс в нем были захардкожены некоторые константы в условиях и светить ими в общем репозитории было бы неправильно. Для решения всех этих вопросов мне на помощь пришла идея использовать view. Весь текст запроса прекрасно туда вписывался, плюс на выходе мы получаем готовую сущность, с которой может работать hibernate как с обычной entity.
По началу все выглядело нормально, запрос на выборку 1 млн таких строк выполнялся за разумные 10 мин. или около того. Немного больше, чем хотелось бы, но заказчика это устраивало. Однако в процессе тестирования обнаружился серьезный минус такого подхода – когда мы выбираем 1 млн записей, запрос выполняется 10 минут, но когда мы хотим отчет по короче и указываем в параметрах границы даты поуже – у нас запрос так же выполняется 10 минут, но в результате мы можем получить хоть 1 запись, хоть миллион. Суть в том, что внутрь запроса view нельзя передавать параметры, мы можем только выполнить статический запрос и уже на результат наложить параметры. Поэтому не важно сколько будет в результате строк, в первую очередь будет выбрано все, что найдется в бд, а только потом будет применены параметры. Заказчику было все равно, его устраивало и то, что отчет с одной строкой будет формироваться практически за такое же время, что и отчет с 1 млн строк. Однако это излишне нагружало бд и было решено отказаться от этого варианта.
Оставался всего один вариант, который нам подходил – это хранимая в бд функция. В нее можно передавать параметры, она может вернуть ссылку на курсор и ее результат можно удобно маппить на нашу entity. Таким образом была описана функция, которая принимала на вход несколько параметров, и возвращала sys_refcursor, весь скрипт занял около 300 строк в реальности, а в упрощенном варианте здесь она выглядит так:
Теперь как ее использовать? Для этого отлично подходит @NamedNativeQuery. Запрос для вызова функции выглядит следующим образом: "< ? = call message_ref(?, ?) >", callable = true дает понять, что запрос представляет собой вызов функции, cacheMode = CacheModeType.IGNORE для указания не использовать кэш, т. к. скорость работы нам не так критична, как затрачиваемая память, ну и в конце resultClass = MessageData.class для маппинга результата на нашу entity. Класс MessageData выглядит следующим образом:
Для того чтобы не использовать кэш было решено выполнять запрос в StatelessSession. Однако есть важная особенность: если попытаться вызвать namedQuery то hibernate при попытке установить CacheMode выдаст UnsupportedOperationException. Чтобы этого избежать необходимо установить два хинта:
В итоге наш метод генерации имеет следующий вид:
4. Запись данных в Excel
На данном этапе вопрос с выборкой данных из БД был решен и возник следующий вопрос – как теперь все это писать в excel так, чтобы это было быстро и не затратно по памяти. Первая попытка была самой очевидной – это использование библиотеки org.apache.poi. Тут все просто: подключаем зависимость
Создаем XSSFWorkbook далее XSSFSheet, из него уже row и так далее. Ничего примечательного, примерный код ниже:
Но такой подход оказался не очень оптимальным. Примерно 3 минуты потребовалось на выборку 1 млн строк из бд и запись их в excel. И в итоге приводил к OutOfMemoryError. Вот пример:
![]()
А когда я выполнял его на терминалке с выделенной оперативной памятью в 2Gb, то падал он с OutOfMemoryError примерно на 30% прогресса.
Грузить весь миллион строк в память в excel было так же плохой идеей, как и выгружать весь запрос в List, очевидно, здесь надо было использовать некий stream, но хоть какой-то годный пример google тогда мне не дал. Была попытка написать свое подобие I/O Stream для работы с excel, но мысль о том, что я пишу велосипед не давала мне покоя. В результате я стал изучать библиотеку org.apache.poi пристальней и оказалось, что там уже есть пакет streaming. В этом пакете уже есть весь необходимый набор классов для работы с большим объемом данных в excel. Оставалось только заменить все ключевые классы на аналогичные из пакета streaming и все:
Теперь сравним скорость обработки данных с этой библиотекой:
![]()
Вся обработка заняла пол минуты и, самое главное, никаких OutOfMemoryError.
Читайте также: