
Orange data настройка в 1с
Обновлено: 06.07.2024
Обмен данными с конфигурацией через веб-сервисы
Внимание! Данный функционал доступен в "Библиотеке стандартных подсистем", начиная с версии 2.3.1.62.
Для обмена данными через формат EnterpriseData у конфигураций, использующих "Библиотеку стандартных подсистем", есть два веб-сервиса:
- EnterpriseDataUpload – упрощенный вариант для загрузки данных в информационную базу из сторонних приложений. Не требует специальных настроек на стороне конфигурации (кроме развертывания собственно веб-сервиса); однонаправленный обмен данными – ТОЛЬКО импорт данных в информационную базу.
- EnterpriseDataExchange – для двустороннего обмена данными между конфигурацией и сторонним приложением. Для работы с ним необходима настройка обмена данными на стороне конфигурации.
Собственно задача обмена данными включает в себя две подзадачи:
- Составление корректного XML-файла в формате EnterpriseData,
- Вызов веб-методов в правильной последовательности.
Особенности работы методов веб-сервисов
Большинство методов обоих веб-сервисов имеют выходной параметр – строку ErrorMessage. В случае если внутри конфигурации произошла ошибка, связанная с бизнес-логикой – в эту строку будет записана информация об этой ошибке. Если ошибок в процессе работы метода не было – в строку ErrorMessage будет помещена пустая строка. Если же в процессе работы метода возникла системная ошибка (например, на стороне конфигурации не удалось разархивировать полученный архив) – веб-метод сгенерирует исключение (exception).
Большинство методов обоих веб-сервисов возвращают строки, но в текущей версии возвращаемые строки всегда пустые (кроме EnterpriseDataUpload.PutDataActionResult – он возвращает статус обработки данных на стороне конфигурации – “Active”, “Completed” либо “Failed”).
Что нужно для работы
На стороне конфигурации
На стороне конфигурации должны быть развернуты веб-сервисы EnterpriseDataUpload и EnterpriseDataExchange соответствующих версий (в данном случае была использована версия 1.0.1.1). При открытии этих двух URL-адресов в браузере (нужно подставить правильное для вашей инсталляции «1С:Предприятия» имя веб-сервера и публикации):
должны выводиться WSDL-описания сервисов:

- В Solution Explorer в контекстном меню узла References выбрать команду Add Service Reference.
- В нижнем левом углу появившегося диалога нажать кнопку Advanced.
- В нижнем левом углу появившегося диалога нажать кнопку Add Web Reference.
Использовалась среда разработки Eclipse 4.4.2. Для генерации кода по WSDL файлов веб-сервисов применялась утилита wsdl2java из фреймворка Apache CXF 2.7.16.
Простой обмен данными с конфигурациями с помощью формата EnterpriseData
Объект может содержать в себе ссылки на другие объекты (например, документ «Акт выполненных работ» может содержать в себе одну или несколько ссылок на номенклатуру). В этом случае, если мы импортируем данные в информационную базу, все объекты, на которые мы ссылаемся из «родительского» объекта, должны либо уже существовать в системе, либо их описание должно содержаться в том же XML файле.
Если нам необходимо удалить какой-то объект, в коллекцию Body надо добавить элемент типа «УдалениеОбъекта», и в этом элементе сослаться на удаляемый объект (см. описание типа «УдалениеОбъекта» в схеме EnterpriseData_X_Y_Z.xsd).
С помощью формата EnterpriseData нам доступны операции создания, обновления и удаления объектов. На данный момент для корректной загрузки данных в типовые решения все объекты должны содержать заполненный элемент «Ссылка» из элемента «Ключевые свойства» (GUID в форме строки). Это первичный ключ объекта. Конфигурации ведут себя следующим образом:
- Если в системе нет объекта с ключом из поля «Ссылка» - создается новый объект.
- Если в системе уже есть объект с ключом из поля «Ссылка» - существующий объект обновляется новыми данными, пришедшими в XML.
- Если пришел элемент типа «УдалениеОбъекта» - объект с соответствующим ключом удаляется из системы.
Веб-сервис EnterpriseDataUpload
EnterpriseDataUpload – интерфейс исключительно для импорта данных в формате EnterpriseData в конфигурацию из сторонних приложений. Условия задачи: у нас есть XML файл с данными в формате EnterpriseData, надо передать его в конфигурацию и убедиться в том, что на стороне конфигурации данные успешно получены.
Алгоритм работы следующий:
Итак, у нас есть архив с данными в формате EnterpriseData (один или несколько файлов). Не будем описывать, как в программе создать архив и разбить его на несколько файлов, чтобы сэкономить время – желающие смогут легко найти примеры подобного кода, используя поисковые сервера и соответствующие запросы.
Реализуем функцию, которая принимает такие входные параметры:
- URL Веб-сервиса,
- Имя пользователя для соединения с Веб-сервисом,
- Пароль.
Путь до архивированного файла с данными. Если архив умещается в одном файле – это имя файла с полным путем, включая расширение (например, “C:\Exchange\data.zip”). Если же архив разбит на несколько частей, то это будет имя любого из файлов без расширения и точки (например, “C:\Exchange\data”). Предполагается, что это последовательность файлов с расширениями “.001”, “.002” и т.д.
Реализация функции (в виде статического метода) в листинге ниже. Диагностическая информация выводится в консоль.
Эта работа является естественным продолжением моей предыдущей статьи "Практика доступа в базу 1С через протокол oData. Чтение данных" и все операции будут выполняться в той же демо-базе "Управление торговлей (базовая), редакция 10.3", к которой я предоставил доступ по OData в предыдущей статье.
OData - это протокол работы с данными поверх классического протокола URL, а чтобы сообщить серверу, что именно вам необходимо с этим элементом сделать (просто получить или изменить), используются POST, которые считают методами для отправки на сервер данных из форм.
Протокол OData подразумевает применение следующих пяти методов для работы с данными:
- GET - самый популярный из методов, который предназначен для запроса данных на чтение по указанному адресу;
- POST - метод для создания нового элемента данных, в качестве адреса обычно указывают только класс объектов;
- PUT - метод для замены свойств элемента данных на сервере по указанному полному адресу теми свойствами, которые передаются вместе с этим запросом. Обычно в популярных реализациях этого метода передача неполного состава свойств приводит к ошибке; так же часто адресация несуществующего элемента данных приводит к его автоматическому созданию (как это было реализовано в платформе 1С посмотрим ниже);
- PATCH - метод для обновления только переданных свойств элементов данных;
- DELETE - метод предназначенный для удаления элементов данных.
Клиент для протокола OData
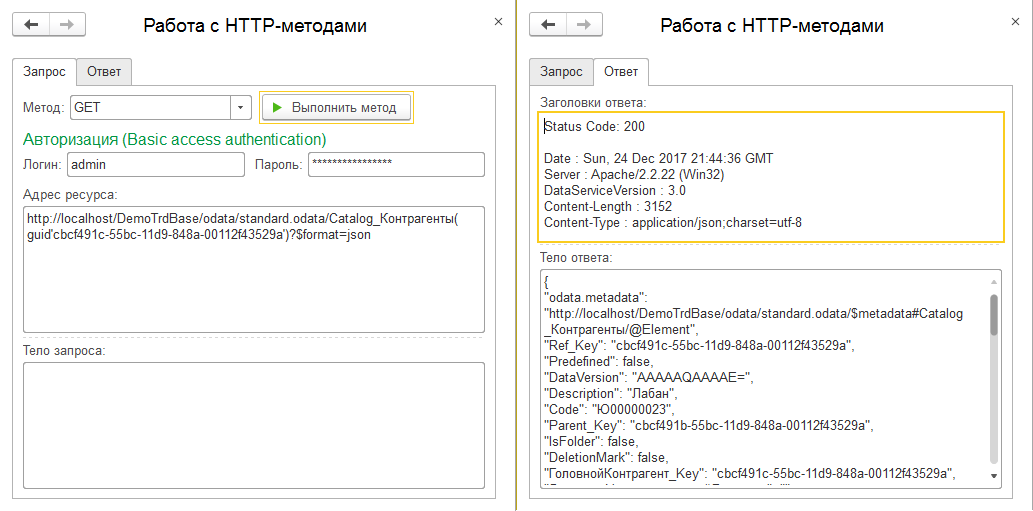
Ломать - не строить
Для начала возьмем самую простую операцию - удаление, на примере контрагента "АОЗТ Лабан" из демо базы УТ10.3. Собственно повторяем вызов строчки из выше опубликованного скриншота, но вместо метода GET воспользуемся методом DELETE. Теперь вместо ответа 200 (все хорошо), сервер нам отвечает 204 (нет содержимого) - это нормальное поведение именно для удаления.
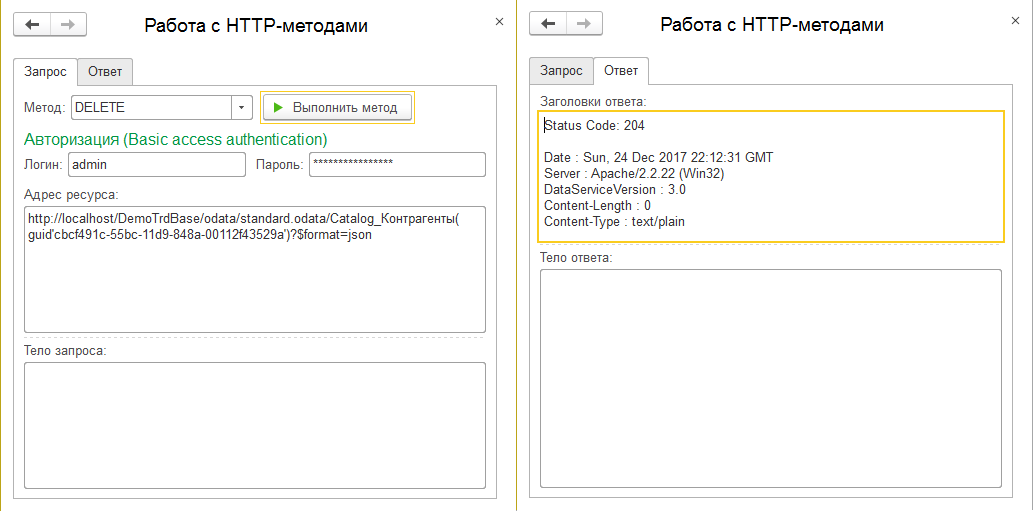
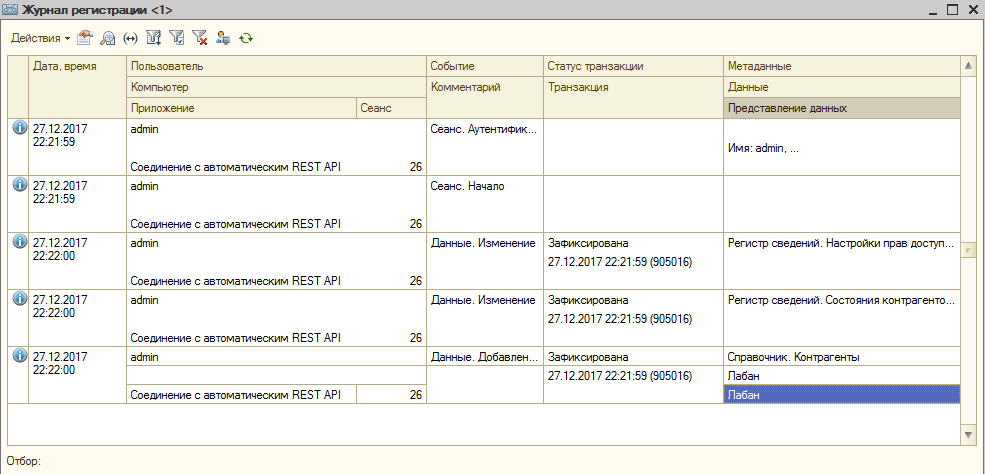
Давайте перейдем в саму базу 1С и по журналу регистрации проверим, что же произошло:
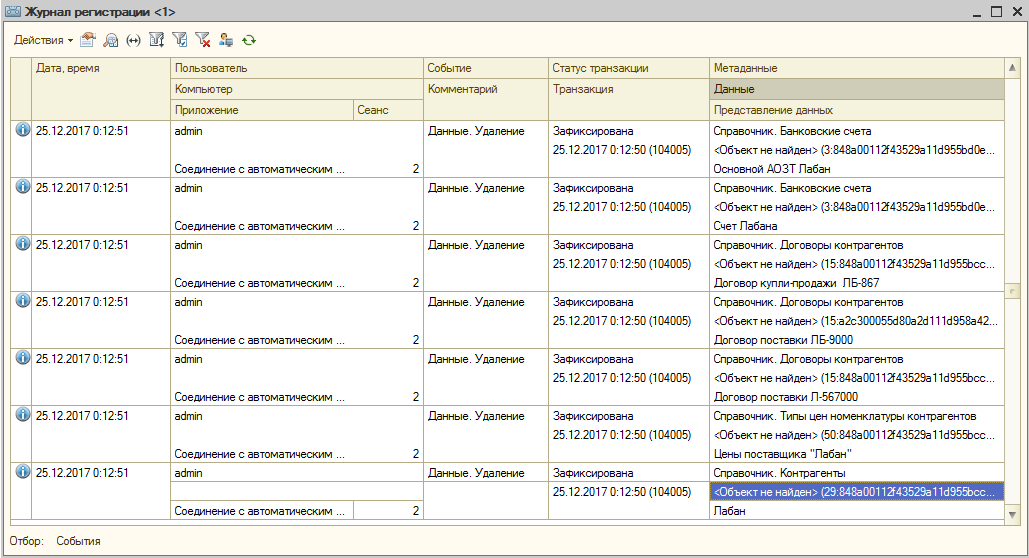
Как мы видим, наш контрагент был успешно удален вместе со всеми своими подчиненными связанными данными. Тот факт, что для всех этих справочников в роли моего пользователя было запрещено интерактивное удаление, не имеет значения. Удаление по протоколу OData приравнивается к удалению из программного кода. Но, как видим, есть и различие - при программном удалении контрагента его подчиненные элементы остались бы в базе. Это важно и потому запоминаем: если у хоть одной роли пользователя есть право "Удаление", то у вас есть риск на безвозвратную потерю множества данных без контроля на наличие ссылок:
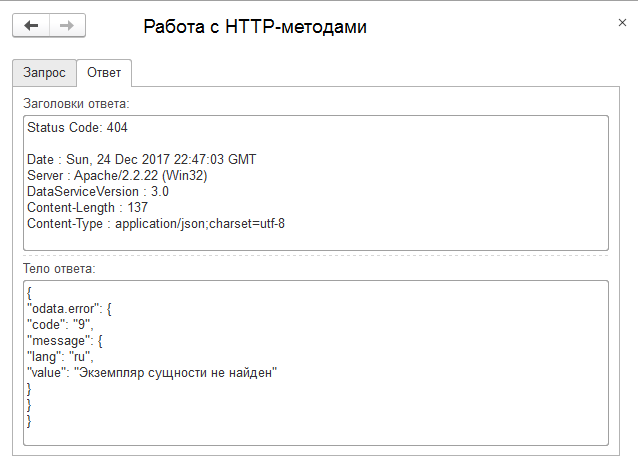
Кстати, повторная попытка удалить элемент с помощью метода DELETE аналогично запросу с помощью GET приведет к ошибке 404 (не найдено):
Создаем новое (или старое)
Как жаль, что контрагента "АОЗТ Лабан" постигла такая печальная участь. А можем ли мы его спасти без восстановления базы из бэкапа или без выполнения кода непосредственно в УТ?
Начну с цитаты из документации:
Для создания объекта следует воспользоваться POST-запросом с использованием URL набора сущностей, передав в теле запроса документ (в поддерживаемом формате), который содержит значения полей создаваемого объекта. Если передаваемый документ содержит свойства, отсутствующие у создаваемого объекта, то эти свойства игнорируются.
Больше ничего у нас с вами нет. Ни перечня обязательных полей. Ни перечня исключаемых полей. Ни упоминания о возможности создания объекта с нужным нам значением GUID. Поэтому начинаем свободные эксперименты!
И на этот раз у нас все получилось:
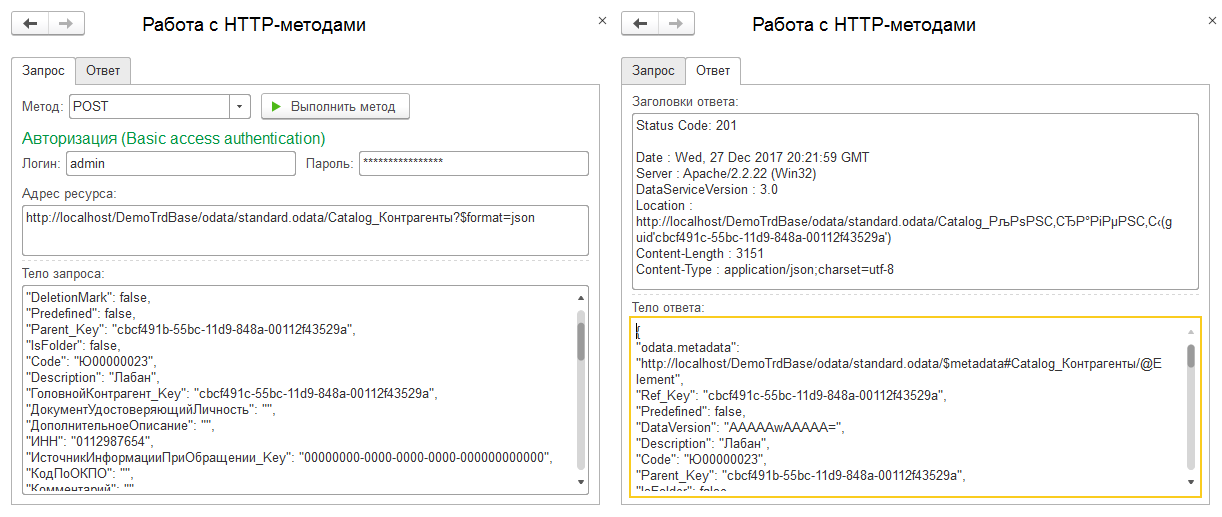
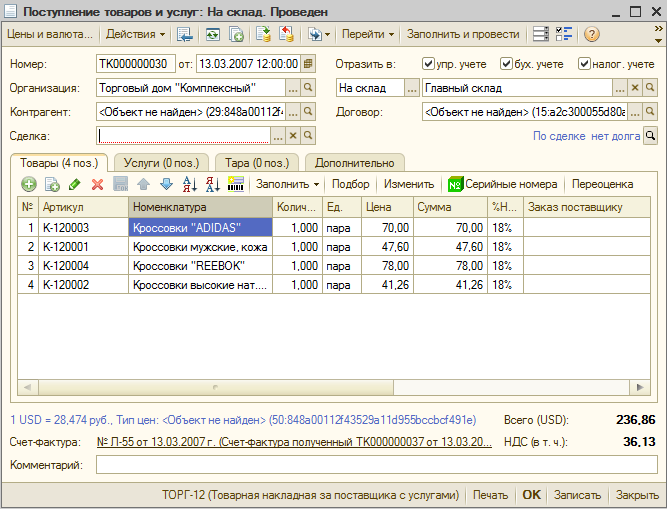
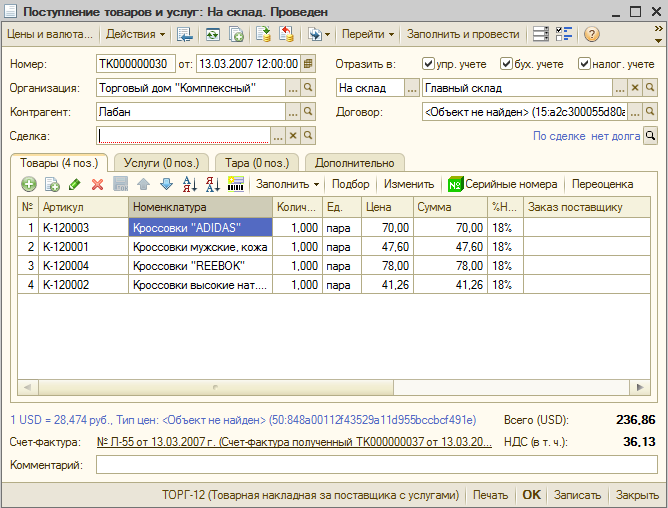
Более того, все получилось именно так как и было задумано - новый элемент был создан именно с тем GUID (а следовательно с той же ссылкой) как и ранее удаленный! Это хорошо видно на документе закупки ТК000000030 от 13.03.2007, где контрагент появился, но его договора и типа цен по прежнему нет (их можно аналогично восстановить, воспользовавшись в качестве образца для структуры подчиненные данные похожего контрагента, лишь в качестве GUID подставив правильные строки):
Это все превосходно, но а если у объекта множество свойств и они нам сейчас не интересны (пусть будут значения по умолчанию). Можем ли мы уменьшить размер передаваемого пакета и следовательно увеличить скорость гипотетического создания множества объектов в цикле? Для ответа на этот вопрос пойдем по пути экстремальной минимизации - попробуем создать элемент не указав ему вообще ни единого свойства!
Отлично, выходит, что нам нет нужды перечислять все значения по-умолчанию и платформа за нас все сделает сама. Но справочник - это слишком просто. Интереснее попробовать с документом, при записи которого, как мы знаем, обычно возникает ошибка платформы, если не указать дату. Попробуем на примере упомянутой выше приходной накладной:
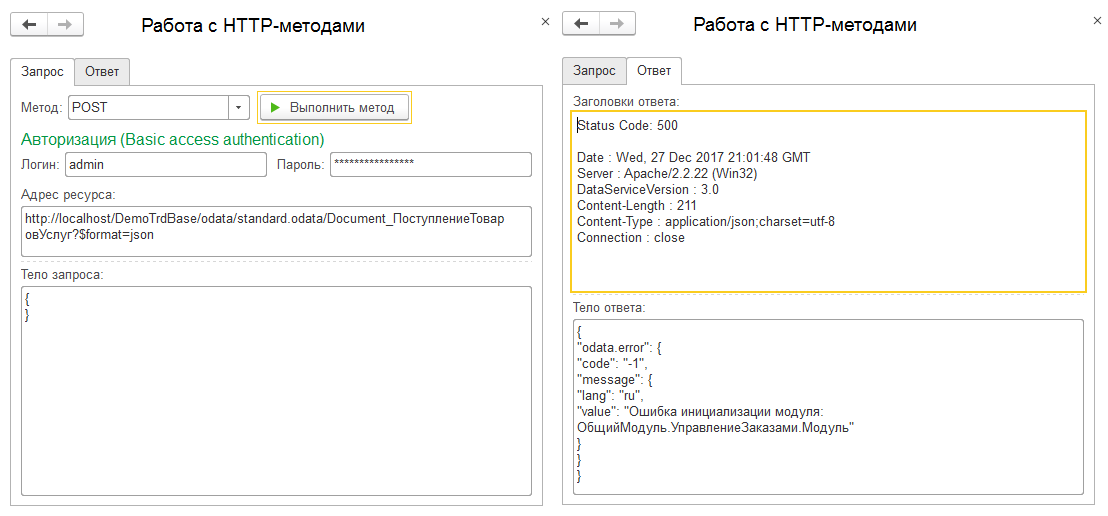
Не то чего я ожидал, но тем не менее отличный результат! Следовательно все программно-обрабатываемые события объектов не игнорируются! Это вам не тупой прямой insert в СУБД, а процедура записи полностью идентичная программной записи из какой-нибудь обработки. Но все же, что же будет с датой? Для этого нам нужен более простой документ, который крепко не привязан к рабочим процессам в УТ, к примеру Событие:
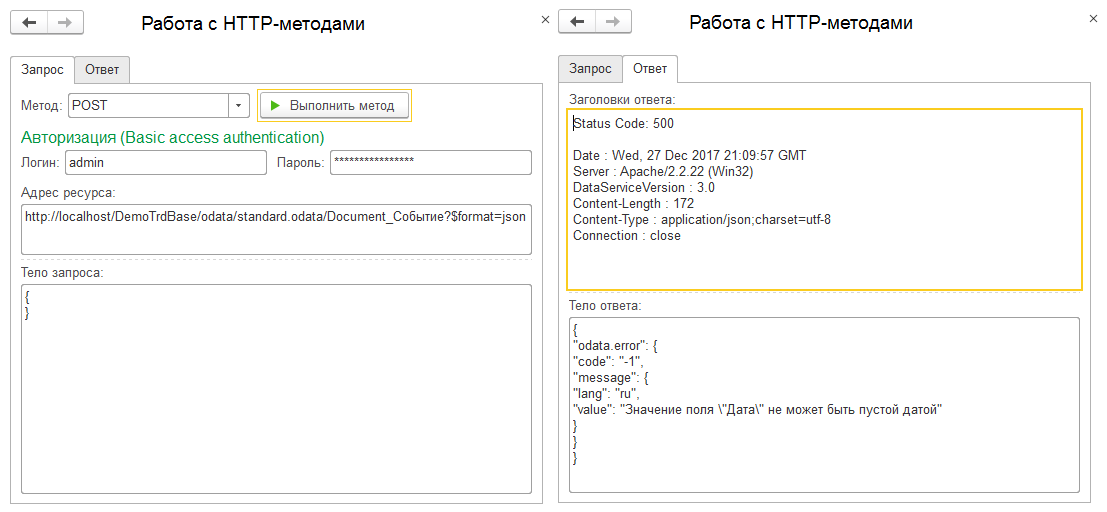
Да, ошибка получена. Теперь лично у меня к механизму создания элементов методом POST вопросов больше не осталось. Все оказалось довольно простым и без "заморочек": можно устанавливать уникальный идентификатор новым ссылкам, отсутствуют какие-либо требования к обязательным или запрещенным свойствам в описании, лишние (не относящиеся к объекту) свойства просто игнорируются, запись в базу следует всем тем же правилам, что и обычная программная запись.
Теперь будем изменять (в хорошем смысле)
Как я уже упомянул выше, для изменения данных в базе 1С посредством OData можно использовать методы PUT и PATCH.
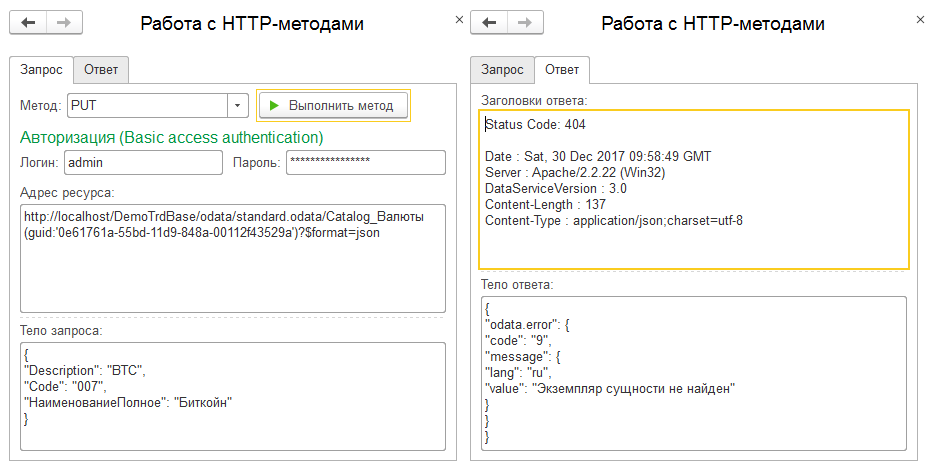
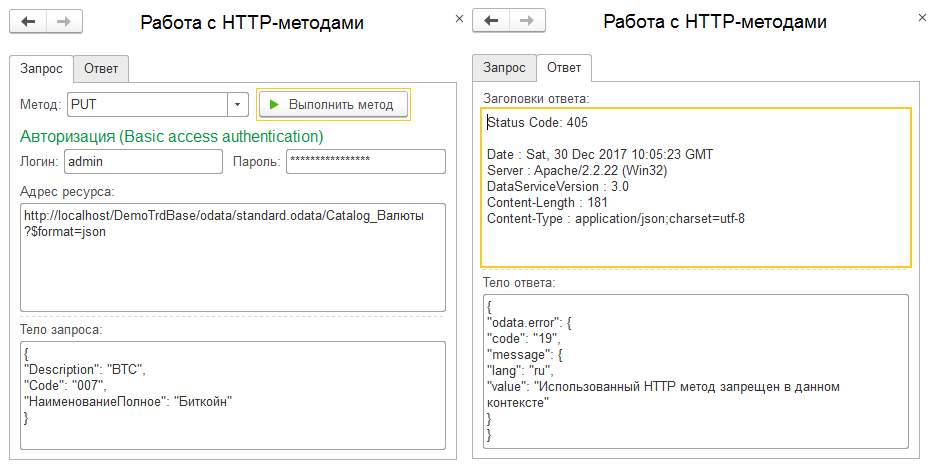
Давайте сразу же попробуем применить PUT в созидательной роли POST. К сожалению, тут ничего интересного мы не узнаем. В контексте коллекции мы получаем ошибку, что данный метод недопустим, а при указании произвольного GUID мы получим ошибку, что изменяемый экземпляр не найден:
А что если не указывать все реквизиты? Действительно, практика показала, что можно не указывать все реквизиты объекта и эти свойства станут заполняться значениями по умолчанию, что иногда может быть удобным. Ниже пример, где у справочника были затерты введенные вручную полное наименование и параметры прописи для валюты:
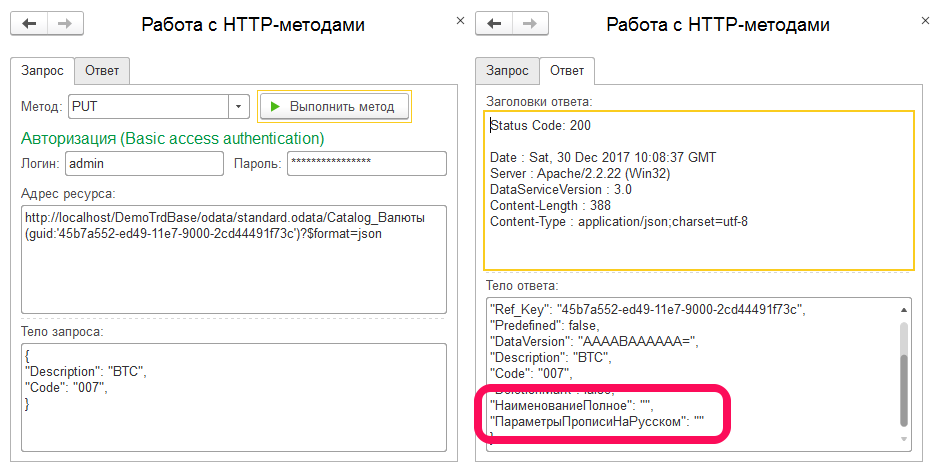
Вот и все интересное, что мы могли узнать про PUT, и потому переходим к более гибкому методу PATCH. При работе с этим методом, в отличии от его предшественника, нам для установки значения единичного реквизита больше не нужно делать предварительный GET для запроса значений всех свойств, что бы потом эти же свойства не затереть значениями по-умолчанию. Нам достаточно лишь идентификатора объекта и нового значения указанного свойства:
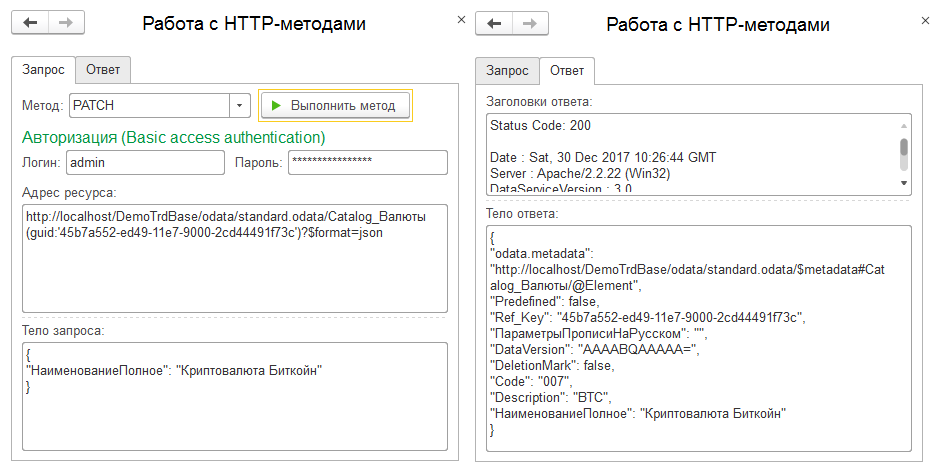
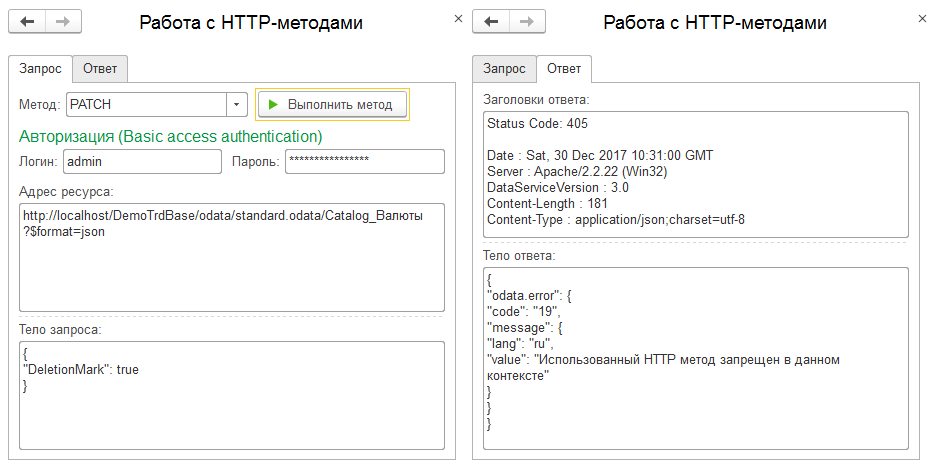
Теоретически, данный метод мог бы быть очень удобным для быстрого массового изменения элементов с помощью единого вызова. На пример, чтобы сменить основного менеджера для всех поставщиков, пометить на удаление документы без суммы и так далее. К сожалению, компания 1С не дала нам такую интересную возможность; для массового изменения нам доступна лишь только серия вызовов в цикле:
Итог
Не смотря на отсутствие некоторых удобств, протокол OData на платформе "1С:Предприятие 8" позволил нам совершать все базовые операции над данными. Таким образом, имея доступ в базу только по этому протоколу, можно реализовать полноценную интеграцию с некоторой внешней системой.
Статья вышла длинной не смотря на то, что были рассмотрены самые простые операции. Часть возможных интересных экспериментов была оставлена за кадром, но вы можете самостоятельно попрактиковаться. К примеру, как на счет записать набор записей по какому-нибудь из регистров? ;)
Начиная с версии 8.3.5 1С Предприятие умеет генерировать REST интерфейс для всей конфигурации, используя протокол OData. Это значит, что стороннее приложение может получить доступ ко всей базе 1С буквально за пару кликов.
Базы данных, которые размещаются на Платформе42, поддерживаются автоматическим REST-сервисом по протоколу OData версии 3.0. И мы подготовили для вас большую инструкцию – знакомство с OData. Чтобы не пугать вас «простыней», мы разбили ее на 11 блоков. В этой статье вы найдете краткие обзоры блоков и ссылки на подробную информацию.
Возможности и настройка
Из этой инструкции вы получите общее представление об интерфейсе OData. Тут мы рассказываем об основных возможностях протокола и о том, как настроить автоматический REST-сервис для запроса и обновления данных. Если хотите познакомиться и узнать, какие задачи можно решить при помощи OData – вам сюда.
Общие принципы работы
Здесь мы разбираем специальную терминологию OData. Рассмотрим в отдельности каждый термин из тех, которыми будем оперировать в дальнейшем, узнаем, как выполнить обращение к стандартному интерфейсу OData и подробно разберем верный URL-запрос.
Представление данных
В этой инструкции посмотрим, в каком виде стандартный интерфейс OData возвращает данные, и взглянем на соответствие между типом данных «1С:Предприятия» и типом OData. И отдельно разберем различные суффиксы, на которые могут оканчиваться имена свойств.
Правила формирования имени ресурса
Из этого текста вы узнаете, по какому принципу формируется идентификатор имени ресурса, к каким объектам можно получить доступ при помощи стандартного интерфейса OData и как уточняется имя ресурса при помощи суффикса. Возможные виды суффиксов тоже разберем.
Правила формирования условия отбора
В данном разделе мы приводим информации по различным способам формирования отбора получаемых данных, которые используются в стандартном интерфейсе OData системы «1С:Предприятие». Инструкция большая и детальная, советуем ознакомиться «с чувством, с толком, с расстановкой».
Параметры запроса
Здесь рассматриваем четыре основных параметра запроса: $count, $inlinecount, $orderby и $expand. Узнаем, что они позволяют сделать, как их правильно использовать и какие подводные камни могут встретиться на пути погружения в тему.
Способы получения описания стандартного интерфейса OData
Рассказываем при помощи каких GET-запросов можно получить сокращенное и полное описания стандартного интерфейса OData. Расскажем, каким образом формировать параметр $format при выполнении запроса, если данные получены в формате json.
Способы получения данных
А в этой инструкции расскажем, как получать и списки сущностей, и сами сущности. Эти способы получения данных отличаются URL, по которому происходит обращение к данным. Вы узнаете, чем отличается URL набора сущностей от канонического URL экземпляра сущности.
Выполнение функций и действий
Посмотрим, как формируется URL ресурса, если с сущностью или с набором сущностей связана функция (например, работа с виртуальными таблицами регистров выполняется именно через функции).
Ошибочные ситуации
Вот мы и подошли к самому интересному – к кодам ошибок, их описанию. Посмотрим, как происходит информирование об ошибках со стороны клиентского приложения и об ошибках со стороны сервера, какие коды назначаются и что с этим делать.
Примеры типовых операций
И немного практики напоследок. Рассмотрим несколько типовых операций в их практическом применении. Пошагово разберем работу с одним объектом, работу с планами обмена и другие вещи, с которыми вам наверняка придется столкнуться.
Чтобы иметь полное представление о стандартном интерфейсе OData, ознакомьтесь со всеми представленными выше инструкциями. Или сохраняйте в закладки, чтобы обращаться к этому тексту по мере необходимости.
Хотим познакомить вас с Orange, системой визуального программирования для отображения данных, машинного обучения и интеллектуального датамайнинга.
Многие из тех, кто когда-либо сталкивался с Python-ом, наверняка знают и видели Anaconda Navigator, пакет языков, библиотек и приложений для DS. В числе всего прочего в его состав входит и Orange, который можно узнать по иконке в виде улыбающегося апельсина в очках. Однако из-за того, что по умолчанию он с дистрибутивом Anaconda не поставляется и его, прежде чем запустить, нужно установить (хоть и нажатием одной кнопки), большинство пользователей до его использования не доходят.
Orange позволяет сразу «из коробки» приобщиться к увлекательному миру анализа данных даже тем, кто раньше не решался это сделать из-за опасений, что не сможет разобраться в сложных математических построениях или в программировании. Теперь вам достаточно ориентироваться в своей предметной области и иметь небольшое – совсем небольшое, буквально обзорное – представление о методах статистики и моделирования. А дальше вы просто рисуете в Orange схему обработки ваших данных.
Вот так выглядит в Orange типичный поток («workflow») обработки данных:
Процесс построения workflow в Orange происходит путём манипуляций с иконками-виджетами, которые мышкой выкладываются на холст – рабочий стол приложения. Каждый виджет представляет собой программный блок, который каким-либо образом обрабатывает поступившую на его вход информацию и передаёт её дальше, для обработки, визуализации или сохранения следующим виджетом. Связи между виджетами протягиваются мышкой, двойной щелчок открывает окно его настроек: например, отображаемые оси и масштаб для графика и сам график, гиперпараметры для алгоритма машинного обучения, имя файла для виджета загрузки или сохранения данных и т.д. и т.п.
В левой части окна Orange находится блок меню для выбора виджетов. Изначально они сгруппированы в пять разделов:
- Data: виджеты для ввода/вывода данных, фильтрации, выделения и манипулирования выборками, а также (sic!) – большое количество учебных наборов данных (от классических Titanic и Iris, до статистики ДТП в Словении за 2014 год);
- Visualize: виджеты для общей (прямоугольная диаграмма, гистограммы, точечная диаграмма) и многомерной визуализации (мозаичная диаграмма, диаграмма-сито);
- Model: набор алгоритмов машинного обучения для классификации и регрессии;
- Evaluate: кросс-валидация, процедуры на основе выборки, оценка методов предсказания;
- Unsupervised: алгоритмы кластеризации (k-средние, иерархическая кластеризация) и проекции данных (многомерное масштабирование, анализ главных компонент, анализ соответствия).
В комплекте начальной установки Orange не содержит, но при необходимости даёт возможность дополнительно загрузить ещё несколько наборов виджетов:
- Associate: датамайнинг повторяющихся наборов элементов и обучение ассоциативным правилам;
- Bioinformatica: анализ наборов генов и доступ к библиотекам геномов;
- Data fusion: объединение различных наборов данных, коллективная матричная факторизация и исследование скрытых факторов;
- Educational: обучение концепциям machine learning;
- Geo: работа с геоданными;
- Image analytics: работа с изображениями, анализ нейронными сетями;
- Network: графовый и сетевой анализ;
- Text mining: обработка естественного языка и анализ текста;
- Time series: анализ и моделирование временных рядов;
- Spectroscopy: анализ и визуализация спектральных наборов данных.
А если и этого недостаточно, то у Orange есть виджет для окончательного решения всех вопросов — Python Script, который позволяет вам написать на Python любой обработчик входных данных.
Для примера, чтобы вы представляли себе, как работает Orange, попробуем решить в нём классическую задачу обработки данных «Titanic» с Kaggle. Решать будем самыми простыми, насколько это будет возможно, методами, чтобы просто показать сам процесс создания решения.
Вот так в Orange выглядит workflow решения (один из вариантов):
Последовательно пройдём по шагам построения workflow.
Напомню, что исходными данными в этой задаче являются два набора данных, поставляемых в виде CSV-файлов:
- файл Train.csv с частью данных о пассажирах «Титаника» (возраст, семейное положение, номер каюты и т.д.) и информацией о том, выжили эти пассажиры или погибли в результате столкновения корабля с айсбергом;
- файл Test.csv, с частью информации об оставшихся пассажирах, но без указания того, остались ли они в живых.
Наша задача — используя методы DS, реализуемые виджетами Orange, предсказать, какова была судьба пассажиров из выборки Test.
- Для каждого из наборов данных выложим на холст виджет File из раздела Data. В свойствах каждого виджета пропишем пути, по которым находятся наши файлы, укажем, какие поля у загружаемых наборов будут target и features и каких типов будут эти поля – числовые, категориальные, временные или текстовые, а какие поля вообще не надо обрабатывать. Данный процесс можно оставить на усмотрение виджета, но автоматическое определение типа полей часто даёт некорректные результаты, поэтому лучше сделать всё руками:
2. Выложим виджет Data Table из раздела Data для отображения загруженного набора данных и соединим его с виджетом File набора Train. Откроем виджет Data Table и посмотрим на загруженную таблицу с данными. Обратите внимание, что в верхней левой части виджета отобразилась некоторая статистика по полям и записям загруженного набора данных:
3. К сожалению, больше века назад, когда произошла трагедия «Титаника», дела со сбором информации о пассажирах, пострадавших в кораблекрушении, обстояли не очень. Данные о многих людях были не полными, не точными, а о некоторых отсутствовали вовсе. Для очистки полученных данных выложим на холст виджет Impute из раздела Data. В его настройках укажем метод среднего, которым будем заменять отсутствующие или некорректные значения. Также передадим данные с выхода этого виджета на вход виджета Data Table, чтобы во второй вкладке, которая там появится, посмотреть на результат работы очистки:
4. Пришло время построить модель классификации, которая по известным признакам на тренировочном наборе будет пытаться предсказать, выжил пассажир или нет. Для этого выложим на холст виджеты Logistic Regression, Random Forest и Neural Network из раздела Model. При этом, для ускорения процесса, подкручивать метапараметры этих алгоритмов не будем, оставим их настройки как есть, по умолчанию:
5. Теперь нужно проверить результаты работы выбранных алгоритмов и рассчитать их оценочные метрики. Для этого выложим на холст виджет Test and Score из раздела Evaluate и подадим на его вход данные с виджетов Impute, Logistic Regression, Random Forest и Neural Network. На основе этих данных виджет Test and Score автоматически начнёт рассчитывать результаты работы моделей, построенных из очищенного набора данных этими алгоритмами, а также оценки их работы. Двойным щелчком откроем виджет Test and Score и посмотрим на рассчитанные результаты:
Как видно в левой части настроек виджета, для расчёта модели был использован метод сэмплирования, когда исходная обучающая выборка случайным образом разбивается на 80% рабочей обучающей выборки и 20% валидационной выборки; данный цикл повторяется 10 раз.
6. Судя по результатам, лучшие результаты, за исключением метрики AUC, дал метод логистической регрессии, поэтому в дальнейшем будем использовать его.Для построения рабочей модели классификации выложим на холст ещё один виджет Logistic Regression из раздела Model, виджет Data Sampler из раздела Data и виджет Predictions из раздела Evaluate. Виджет Data Sampler будет делить обучающую выборку на две части случайным образом в соотношении 80/20%, а виджет Predictions будет делать в наборе данных Test собственно предсказание целевого поля на основании модели, построенной виджетом Logistic Regression.
Подадим на вход виджета Data Sampler выход виджета Impute, выход Data Sampler подадим на вход Logistic Regression, а на вход Predictions подадим выходы с File Test и Logistic Regression. Откроем Predictions и в первом столбце таблицы посмотрим на поле, заполненное предсказанными значениями целевого поля:
7. Добавим на холст последний виджет – Save Data из раздела Data и сохраним результат выполненного предсказания:
8. Откроем сохранённый файл, оставим в нём только целевое поле и поле идентификатора пассажира, как того требует условие конкурса, и загрузим полученный submission на Kaggle:
9. И, наконец, наступил момент истины: посмотрим, насколько хорошо мы двигали мышкой для того, чтобы сделать реальный Data Science.
Жмём на «Make submission», и…
Достаточно неплохо для решения, в котором мы совершенно не делали анализ и редизайн фич, не подбирали метапараметры обучения моделей, не собирали модели в ансамбли, да и вообще не делали ничего, за исключением нескольких кликов мышью.
Конечно же, мы лишь поверхностно рассмотрели работу с системой Orange и использовали в процессе решения несколько процентов его возможностей. Для того, чтобы их изучить, в саму систему встроили очень подробную справку и множество примеров использования в разных кейсах обработки данных.
Кроме того, сообщество разработчиков Orange ведёт на YouTube блог «Orange Data Mining», в котором выкладывает видео с примерами решения задач практически на любой случай из жизни.
К сожалению, все эти материалы представлены только на английском языке. На русском языке документации по Orange практически нет, кроме пары обзорных презентаций, и ещё на YouTube есть видео, в котором очень подробно шаг за шагом рассматривается решение задачи классификации, как это делали мы с «Титаником», но для более сложного тестового датасета.
Поэтому лучше всего начать разбираться с тем, что может Orange — установив его, загрузив в примеры использования свои наборы данных, попробовав обработать их всеми возможными виджетами и посмотрев, что из этого получится. А Google поможет понять названия настроек виджетов, если у вас до сих пор по каким-либо причинам плохо с английским.
И, возможно, для вас это будет самый простой и быстрый способ почувствовать себя DS-специалистом, а там, глядишь, и до питона недалеко.
Читайте также: