
Перенос данных из таблицы excel в шаблон excel
Обновлено: 04.07.2024
= Мир MS Excel/Статьи об Excel
| Приёмы работы с книгами, листами, диапазонами, ячейками [6] |
| Приёмы работы с формулами [13] |
| Настройки Excel [3] |
| Инструменты Excel [4] |
| Интеграция Excel с другими приложениями [4] |
| Форматирование [1] |
| Выпадающие списки [2] |
| Примечания [1] |
| Сводные таблицы [1] |
| Гиперссылки [1] |
| Excel и интернет [1] |
| Excel для Windows и Excel для Mac OS [2] |
Таблица, предназначенная для слияния, должна удовлетворять некоторым требованиям:
- в таблице не должно быть объединенных ячеек. Вернее сказать так: ЕСЛИ в таблице есть объединённые ячейки, то надо быть готовым к тому, что при экспорте объединение будет отменено, и соответственно образуются лишние пустые строки и/или столбцы, что может нарушить структуру таблицы. В общем, объединённые ячейки - это зло :)
- все столбцы должны иметь уникальные названия, которые будут использоваться при слиянии. Если в таблице отсутствует первая строка с названиями столбцов, то её заменит первая строка данных, а значит, она в рассылке участвовать не будет.
В качестве примера возьмем таблицу с перечнем клиентов фитнес клуба "Экселент"
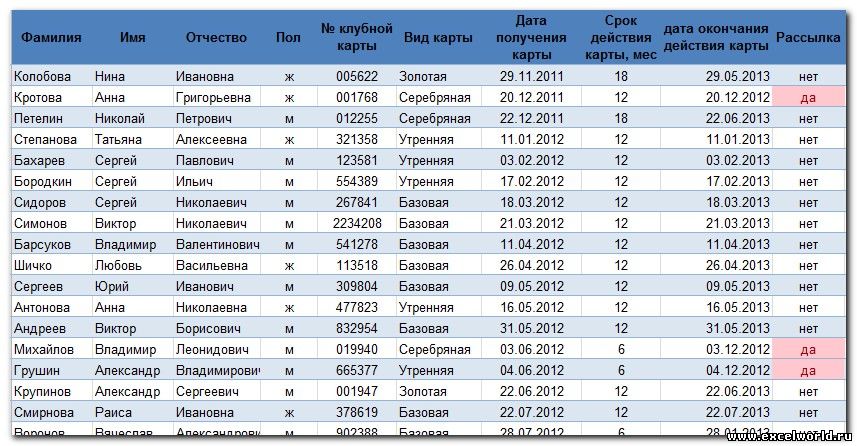
На этом этапе в текстовом редакторе Word формируется документ, в который в дальнейшем будут внедряться данные электронной таблицы. Текст этого документа представляет собой общую для всех рассылок часть.
Предположим всем клиентам, у которых срок действия клубной карты истекает в следующем месяце, планируется разослать письма с уведомлением.
Текст письма будет одинаковым за исключением обращения, номера клубной карты и даты окончания её действия. Эти данные будут импортироваться из таблицы Excel (выделено синим)

Таким образом, на этом этапе в документе Word печатается общий для всех писем текст.
Для более удобной дальнейшей работы при слиянии рекомендуется установить параметр Затенение полей в положение Всегда, чтобы отличать вставленные поля слияния от обычного текста. Если этот параметр включен, поля отображаются на сером фоне. На печать этот фон, естественно, не выводится.
Проще всего осуществить слияние данных, следуя указаниям Мастера слияния. В версиях после Word2003 Мастер слияния запускается с помощью кнопки Начать слияние на вкладке Рассылки
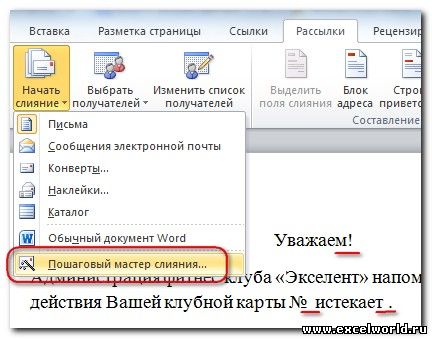
В версиях до Word2007 следует выполнить команду меню Сервис -- Письма и рассылки -- Слияние. Кроме того, для более удобной работы версиях до Word2007 можно вывести панель инструментов Слияние
Ещё раз обращаю внимание, что в бланке письма содержится только общий для всех писем текст, поэтому обращение выглядит как Уважаем!, а номер карты и дата пропущены.
Выбираем поле Имя, нажимаем Вставить, то же самое для поля Отчество. Закрываем окно Вставка полей слияния и добавляем пробелы между вставленными полями. Если параметр Затенение полей установлен в положение Всегда, то вставленные поля будут отчетливо видны на сером фоне. Устанавливаем курсор после №, снова нажимаем ссылку Другие элементы. , выбираем № клубной карты - Вставить. Аналогично вставляем поле Дата окончания действия карты
Кроме указанных выше полей требуется вставить окончание обращения ый(ая), которое зависит от значения поля Пол. Для этого воспользуемся специальным полем, позволяющим вставлять одно из двух значений в зависимости от данных. Поставим курсор сразу после слова "Уважаем", нажмём кнопку Правила на вкладке Рассылки и выберем вариант IF. THEN. ELSE. В версиях до Word2007 аналогичная кнопка называется Добавить поле Word и находится на панели инструментов Слияние
В раскрывшемся диалоговом окне зададим параметры

После нажатия ОК, получим результат



Автоматизация заполнения и вывода файлов по шаблонам рутинных документов это одна из та областей в отрасли строительства по которой традиционно софт, кроме бухгалтерского, находится на уровне вылизанных поделок, на мой скромный взгляд. Поэтому, развивая тему, приглашаю обсудить те проблемы и возможности, с которыми пришлось столкнуться в процессе реализации на базе MS Excel.
Со времени предыдущей статьи прошло уже пол года. За это время при помощи этой заготовки была разработана текстовая часть Исполнительной документации и сдана Заказчику. По итогам работы и отзывам редких участников в файл были внесены следующие правки, о которых я бы хотел поговорить и это 3 большие темы:
- Эстетика и юзабилити
- Оптимизация кода + нововведения
- Структура и связи
1. Эстетика и юзабилити
— Таблицы это в первую очередь таблицы, безликие ячейки с подписанными колонками и строками. Однако очень часто мы сталкиваемся с ситуацией, когда необходимы дополнительные пояснения к значению, которое будет находится в ячейке, или требуется дополнительно активизировать внимание пользователя на важности вводимого значения. Особенно важно, если у Вас, как в моем случае, строки в колонке очень длинной таблицы содержат разноплановую информацию, например: даты, виды работ, материалы, подписанты и многие др. В таких случаях у нас есть 2 инструмента для решения задачи:

Есть и минусы такого решения, в частности всплывающие подсказки могут раздражать, но в ситуации, когда на объекте 15" мониторы на ноутбуках с разрешением 1366×768 это разумный компромисс, что бы рабочая область была как можно больше.
Если внимательно проанализировать данные, то окажется что в таблице будут ячейки 3х типов:
- ячейки в которые непосредственно необходимо вводить новую текстовую информацию;
- ячейки, значение которых может принимать значение из ограниченного диапазона, введенного заранее, например: ФИО и должность подписантов;
- ячейки в которых прописаны формулы, например есть часть данных которая будет повторяться из акта в акт и такую информацию достаточно ввести один раз, например: наименование объекта, участок, организация и т.п.; либо формулы призванные реализовать технические возможности, например: переноса строки, подтягивание объемов работ, регалий по ФИО и т.п.
Здесь первая процедура постоянно будет защищать лист при помощи пароля 111, вторая будет блокировать функционал вырезать-вставить. Надо ли говорить, что это все работает только при включенных макросах, но с другой стороны без них и файл на 100% функционировать не будет.
Для случаев же п.2 разумно завести лист где столбцы будут содержать меняющиеся значения, прописать в них ссылки на диапазоны, присвоить им имена, т.е. на вкладке «Формулы» -> «Диспетчер имен» каждому диапазону присвоить имена и через вкладку «Данные» -> пункт меню «Проверка данных» -> вкладка «Параметры» -> условие проверки — «Список» реализовать выпадающее меню.
И, конечно, не забывайте ставить условия форматирования цветом, например для случаев, когда заполнены все необходимые строки в столбце через «Условное форматирование», например формула условного форматирования закрашивает ячейку, если следующие ячейки под ней содержат текст: =И(ДЛСТР(E5)>0; ДЛСТР(E6)>0)
2. Оптимизация кода + нововведения
Начать придется издалека, а именно вернуться к вопросу о реализации механизма заполнения шаблона. Если Вы решите заполнить шаблон в формате Excel и в формате Word, то это будут совершенно 2 разных механизма. В основе своей в файл Excel пишутся значения в конкретные ячейки файла или диапазоны ячеек и имеют привязку вида (у, х) (не спрашивайте почему у них строка идет впереди столбца при адресации — не знаю), например: Worksheet.Cells(y, x) = k. Отсюда же и первая мысль, что заполнять Excel-шаблон можно либо явным образом, т.е. непосредственно весь макрос будет содержать что откуда берется и куда закладывается, но что если придется вносить изменения в таблицы данных или выйдет новая форма шаблона? Отсюда вторая идея реализации, код которой описан в первой статье — это парсинг некоторых символов, которыми сперва заполняется массив, а так же в свою очередь содержит файл шаблона в нужных местах. Затем в каждой строке шаблона ищется совпадение с элементами массива поочередно, если совпадение есть, то порядковый номер массива привязан к строке таблицы откуда берутся данные, а столбец берется с листа в котором мы указываем какие именно акты мы хотим вывести. Итого несколько вложенных циклов, что накладывает ограничения на форматирование шаблона Excel, чем проще — тем лучше, потому что чем больше ячеек парсить — тем дольше будет происходить заполнение шаблона данными.
По многочисленным просьбам мною была интегрирована возможность вывода в шаблон формата Word, и здесь на самом деле есть 2 способа вывода текста:
когда мы так же считываем массив управляющих кодов, вручную прописываем их в шаблоне через «Вставка» -> «Закладки» и дальше просто прогоняем макросом присваивая закладке данные из соответствующей ей ячейке в файле Excel.
Здесь вынесена в отдельную процедуру обращение к закладке и arrСсылкиДанных(i) — это массив который содержит управляющие символы. Издержки метода, если Вам потребуется сослаться на значение Закладки в другом месте, например дату нужно использовать в заголовке и напротив фамилии каждого подписанта, то необходимо использовать в шаблоне Меню «Вставка» -> пункт меню «Перекрестная ссылка» -> Тип ссылки: «Закладка», Вставить ссылку на: «Текст закладки» и снять галочку «Вставить как гиперссылку». Что бы это отобрадзилось корректно не забудте обновить в конце макроса перед выводом поля Wd.Fields.Update
2. Если рисовать таблицы средствами Word, то к ним можно обращаться с адресацией в ячейкуЗдесь нужно обратить внимание, что у каждой таблицы в Word есть свой внутренний номер, методом нехитрого перебора Вы найдете нужный, а дальше принцип тот же, что и в Excel.
Между выводами в файлы форматов Word и Excel есть огромная пропасть, которая заключается в следующем:
Шаблон Excel требует перед использованием настроить отображение под конкретный принтер, т.к. фактическая область печати разнится от модели к модели. Так же перенос строки текста возможен, но только в пределах ячейки/объединенных ячеек. В последнем случае не будте автораздвигания строки, в случае переноса текста. Т.е. Вам вручную придется заранее определит границы области, которые будут содержать текст, который в свою очередь в них еще должен убраться. Зато Вы точно задали границы печати и выводимого текста и уверены, что не съедет информация (но не содержание) с одного листа на другой.
Шаблон Word при настройке автоматически переносит текст на последующую строку, если он не убрался по ширине ячейки/строки, однако этим самым он вызывает непрогнозируемый сдвиг текста по вертикали. Учитывая тот факт, что по требованиям к Исполнительной документации в строительстве ЗАПРЕЩЕНО один акт печатать на 2х и более листах, то это в свою очередь так же рождает проблемы.
Вторым большим нововведением стал отказ от реализации переноса текстовых строк с макроса VBA и заменой на функцию Excel, благодаря чему ускорилась работа с файлом.
Для первой строки:
<=ЕСЛИОШИБКА(ЕСЛИ($F$20<>"-"; ЕСЛИ(ДЛСТР('Данные для проекта'!$C$3)<106;'Данные для проекта'!$C$3; ПСТР('Данные для проекта'!$C$3;1;105-ПОИСКПОЗ(" *"; ПРАВСИМВ(ПСТР('Данные для проекта'!$C$3;1;105); СТРОКА($1:$10));))));"-")>
<=ЕСЛИОШИБКА(ЕСЛИ($F$20<>"-"; ПСТР('Данные для проекта'!$C$3; СУММ(ДЛСТР(F$1:F1))+1;105-ПОИСКПОЗ(" *"; ПРАВСИМВ(ПСТР('Данные для проекта'!$C$3; СУММ(ДЛСТР(F$1:F1))+1;105); СТРОКА($1:$10));)));"-")>
Здесь используется принцип массивов, т.е. вводится такой текст по Ctrl + Shift + Enter, а не обычному Enter. Сами формулы располагаются в ячейках F1 и F2. 'Данные для проекта'!$C$3 — ссылка на наименования объекта, длина текста которого более 105 символов. Перенос организуется в случае превышения длины текста в 105 символов.
Еще одним нововведением стал общий реестр, а так же контроль списания материалов по актам АОСР, но здесь ничего нового, просто парсинг соответствующих строк в свяске ИНДЕКС + ПОИСКПОЗ, которые расписаны во многих мануалах.
3. Структура и связи
Но мой пост так бы и остался рядовым постом с очередной игрой в изобретание велосипеда инструментами, которые рассчитаны на совершенно другое, если бы ни одно НО(!) Месячно-суточный график.

Идея о том, что можно именно на него много чего повесить, например заполнение Общего журнала работ в части Раздела 3 — наименование работ по датам, очередность и необходимость Актов освидетельствования скрытых работ и не только — завладела моими мыслями. Обычно в Excel закрашивают даты, в зависимости от диапазонов дат — начало и конец, но не на стройке. На стройке в календарном графике пишут объемы, а в зависимости от того с какой даты напротив наименования работ стоят объемы и по которую — получаются диапазоны дат отчетных периодов. На скриншоте серым помечены объемы попадающие в систематизированные отчетные периоды (1мес). Таким образом получается, что если:
Имеем базу данных (список, таблицу - называйте как хотите) с информацией по платежам на листе Данные:
Задача: быстро распечатывать приходно-кассовый ордер (платежку, счет-фактуру. ) для любой нужной записи выбранной из этого списка. Поехали!
Шаг 1. Создаем бланк
На другом листе книги (назовем этот лист Бланк) создаем пустой бланк. Можно самостоятельно, можно воспользоваться готовыми бланками, взятыми, например, с сайтов журнала "Главный Бухгалтер" или сайта Microsoft. У меня получилось примерно так:

В пустые ячейки (Счет, Сумма, Принято от и т.д.) будут попадать данные из таблицы платежей с другого листа - чуть позже мы этим займемся.
Шаг 2. Подготовка таблицы платежей
Прежде чем брать данные из таблицы для нашего бланка, таблицу необходимо слегка модернизировать. А именно - вставить пустой столбец слева от таблицы. Мы будем использовать для ввода метки (пусть это будет английская буква "икс") напротив той строки, данные из которой мы хотим добавить в бланк:
Шаг 3. Связываем таблицу и бланк
Для связи используем функцию ВПР (VLOOKUP) - подробнее про нее можно почитать здесь. В нашем случае для того, чтобы вставить в ячейку F9 на бланке номер помеченного "x" платежа с листа Данные надо ввести в ячейку F9 такую формулу:
Т.е. в переводе на "русский понятный" функция должна найти в диапазоне A2:G16 на листе Данные строку, начинающуюся с символа "х" и выдать нам содержимое второго столбца этой строки, т.е. номер платежа.
Аналогичным образом заполняются все остальные ячейки на бланке - в формуле меняется только номер столбца.
В итоге должно получиться следующее:

Шаг 4. Чтобы не было двух "х".
Если пользователь введет "х" напротив нескольких строк, то функция ВПР будет брать только первое найденное значение. Чтобы не было такой многозначности, щелкните правой кнопкой мыши по ярлычку листа Данные и выберите Исходный текст (Source Code) . В появившееся окно редактора Visual Basic скопируйте следующий код:
Этот макрос не дает пользователю ввести больше одного "х" в первый столбец.
Есть в IT-отрасли задачи, которые на фоне успехов в big data, machine learning, blockchain и прочих модных течений выглядят совершенно непривлекательно, но на протяжении десятков лет не перестают быть актуальными для целой армии разработчиков. Речь пойдёт о старой как мир задаче формирования и выгрузки Excel-документов, с которой сталкивался каждый, кто когда-либо писал приложения для бизнеса.

Какие возможности построения файлов Excel существуют в принципе?
- VBA-макросы. В наше время по соображениям безопасности идея использовать макросы чаще всего не подходит.
- Автоматизация Excel внешней программой через API. Требует наличия Excel на одной машине с программой, генерирующей Excel-отчёты. Во времена, когда клиенты были толстыми и писались в виде десктопных приложений Windows, такой способ годился (хотя не отличался скоростью и надёжностью), в нынешних реалиях это с трудом достижимый случай.
- Генерация XML-Excel-файла напрямую. Как известно, Excel поддерживает XML-формат сохранения документа, который потенциально можно сгенерировать/модифицировать с помощью любого средства работы с XML. Этот файл можно сохранить с расширением .xls, и хотя он, строго говоря, при этом не является xls-файлом, Excel его хорошо открывает. Такой подход довольно популярен, но к недостаткам следует отнести то, что всякое решение, основанное на прямом редактировании XML-Excel-формата, является одноразовым «хаком», лишенным общности.
- Наконец, возможна генерация Excel-файлов с использованием open source библиотек, из которых особо известна Apache POI. Разработчики Apache POI проделали титанический труд по reverse engineering бинарных форматов документов MS Office, и продолжают на протяжении многих лет поддерживать и развивать эту библиотеку. Результат этого reverse engineering-а, например, используется в Open Office для реализации сохранения документов в форматах, совместимых с MS Office.
Но у прямого использования Apache POI есть и недостатки. Во-первых, это Java-библиотека, и если ваше приложение написано не на одном из JVM-языков, вы ей вряд ли сможете воспользоваться. Во-вторых, это низкоуровневая библиотека, работающая с такими понятиями, как «ячейка», «колонка», «шрифт». Поэтому «в лоб» написанная процедура генерации документа быстро превращается в обильную «лапшу» трудночитаемого кода, где отсутствует разделение на модель данных и представление, трудно вносить изменения и вообще — боль и стыд. И прекрасный повод делегировать задачу самому неопытному программисту – пусть ковыряется.
Но всё может быть совершенно иначе. Проект Xylophone под лицензией LGPL, построенный на базе Apache POI, основан на идее, которая имеет примерно 15-летнюю историю. В проектах, где я участвовал, он использовался в комбинации с самыми разными платформами и языками – а счёт разновидностей форм, сделанных с его помощью в самых разнообразных проектах, идёт, наверное, уже на тысячи. Это Java-проект, который может работать как в качестве утилиты командной строки, так и в качестве библиотеки (если у вас код на JVM-языке — вы можете подключить её как Maven-зависимость).
Xylophone реализует принцип отделения модели данных от их представления. В процедуре выгрузки необходимо сформировать данные в формате XML (не беспокоясь о ячейках, шрифтах и разделительных линиях), а Xylophone, при помощи Excel-шаблона и дескриптора, описывающего порядок обхода вашего XML-файла с данными, сформирует результат, как показано на диаграмме:

Шаблон документа (xls/xlsx template) выглядит примерно следующим образом:

Как правило, заготовку такого шаблона предоставляет сам заказчик. Вовлечённый заказчик с удовольствием принимает участие в создании шаблона: начиная с выбора нужной формы из «Консультанта» или придумывания собственной с нуля, и заканчивая размерами шрифтов и ширинами разделительных линий. Преимущество шаблона в том, что мелкие правки в него легко вносить уже тогда, когда отчёт полностью разработан.
Когда «оформительская» работа выполнена, разработчику остаётся
- Создать процедуру выгрузки необходимых данных в формате XML.
- Создать дескриптор, описывающий порядок обхода элементов XML-файла и копирования фрагментов шаблона в результирующий отчёт
- Обеспечить привязку ячеек шаблона к элементам XML-файла с помощью XPath-выражений.
Если бы в форме, которую мы создаём, не было повторяющихся элементов с разным количеством (таких, как строки накладной, которых разное количество у разных накладных), то дескриптор выглядел бы следующим образом:
Здесь root – название корневого элемента нашего XML-файла с данными, а диапазон A1:Z100 – это прямоугольный диапазон ячеек из шаблона, который будет скопирован в результат. При этом, как можно видеть из предыдущей иллюстрации, подстановочные поля, значения которых заменяются на данные из XML-файла, имеют формат
(тильда, фигурная скобка, XPath-выражение относительно текущего элемента XML, закрывающая фигурная скобка).
Что делать, если в отчёте нам нужны повторяющиеся элементы? Естественным образом их можно представить в виде элементов XML-файла с данными, а помочь проитерировать по ним нужным образом помогает дескриптор. Повторение элементов в отчёте может иметь как вертикальное направление (когда мы вставляем строки накладной, например), так и горизонтальное (когда мы вставляем столбцы аналитического отчёта). При этом мы можем пользоваться вложенностью элементов XML, чтобы отразить сколь угодно глубокую вложенность повторяющихся элементов отчёта, как показано на диаграмме:

Красными квадратиками отмечены ячейки, которые будут являться левым верхним углом очередного прямоугольного фрагмента, который пристыковывает генератор отчёта.
Есть и ещё один возможный вариант повторяющихся элементов: листы в книге Excel. Возможность организовать такую итерацию тоже имеется.
Рассмотрим чуть более сложный пример. Допустим, нам надо получить сводный отчёт наподобие следующего:

Пусть диапазон лет для выгрузки выбирает пользователь, поэтому в этом отчёте динамически создаваемыми являются как строки, так и столбцы. XML-представление данных для такого отчёта может выглядеть следующим образом:
Мы вольны выбирать названия тэгов по своему вкусу, структура также может быть произвольной, но с оглядкой на простоту конвертации в отчёт. Например, выводимые на лист значения я обычно записываю в атрибуты, потому что это упрощает XPath-выражения (удобно, когда они имеют вид @имяатрибута ).
Шаблон такого отчёта будет выглядеть так (сравните XPath-выражения с именами атрибутов соответствующих тэгов):

Теперь наступает самая интересная часть: создание дескриптора. Т. к. это практически полностью динамически собираемый отчёт, дескриптор довольно сложен, на практике (когда у нас есть только «шапка» документа, его строки и «подвал») всё обычно гораздо проще. Вот какой в данном случае необходим дескриптор:
Полностью элементы дескриптора описаны в документации. Вкратце, основные элементы дескриптора означают следующее:
- element — переход в режим чтения элемента XML-файла. Может или являться корневым элементом дескриптора, или находиться внутри iteration . С помощью атрибута name могут быть заданы разнообразные фильтры для элементов, например
- name="foo" — элементы с именем тэга foo
- name="*" — все элементы
- name="tagname[@attribute='value']" — элементы с определённым именем и значением атрибута
- name="(before)" , name="(after)" — «виртуальные» элементы, предшествующие итерации и закрывающие итерацию.
- mode="horizontal" — режим вывода по горизонтали (по умолчанию — vertical)
- index=0 — ограничить итерацию только самым первым встреченным элементом
- sourcesheet —лист книги шаблона, с которого берётся диапазон вывода. Если не указывать, то применяется текущий (последний использованный) лист.
- range – диапазон шаблона, копируемый в результирующий документ, например “A1:M10”, или “5:6”, или “C:C”. (Применение диапазонов строк типа “5:6” в режиме вывода horizontal и диапазонов столбцов типа “C:C” в режиме вывода vertical приведёт к ошибке).
- worksheet – если определён, то в файле вывода создаётся новый лист и позиция вывода смещается в ячейку A1 этого листа. Значение этого атрибута, равное константе или XPath-выражению, подставляется в имя нового листа.
Ну что же, настало время скачать Xylophone и запустить формирование отчёта.
Возьмите архив с bintray или Maven Central (NB: на момент прочтения этой статьи возможно наличие более свежих версий). В папке /bin находится shell-скрипт, при запуске которого без параметров вы увидите подсказку о параметрах командной строки. Для получения результата нам надо «скормить» ксилофону все приготовленные ранее ингредиенты:
Открываем файл report.xlsx и убеждаемся, что получилось именно то, что нам нужно:![]()
Так как библиотека ru.curs:xylophone доступна на Maven Central под лицензией LGPL, её можно без проблем использовать в программах на любом JVM-языке. Пожалуй, самый компактный полностью рабочий пример получается на языке Groovy, код в комментариях не нуждается:
У класса XML2Spreadsheet есть несколько перегруженных вариантов статического метода process , но все они сводятся к передаче всё тех же «ингредиентов», необходимых для подготовки отчёта.Важная опция, о которой я до сих пор не упомянул — это возможность выбора между DOM и SAX парсерами на этапе разбора файла с XML-данными. Как известно, DOM-парсер загружает весь файл в память целиком, строит его объектное представление и даёт возможность обходить его содержимое произвольным образом (в том числе повторно возвращаясь в один и тот же элемент). SAX-парсер никогда не помещает файл с данными целиком в память, вместо этого обрабатывает его как «поток» элементов, не давая возможности вернуться к элементу повторно.
Использование SAX-режима в Xylophone (через параметр командной строки -sax или установкой в true параметра useSax метода XML2Spreadsheet.process ) бывает критически полезно в случаях, когда необходимо генерировать очень большие файлы. За счёт скорости и экономичности к ресурсам SAX-парсера скорость генерации файлов возрастает многократно. Это даётся ценой некоторых небольших ограничений на дескриптор (описано в документации), но в большинстве случаев отчёты удовлетворяют этим ограничениям, поэтому я бы рекомендовал использование SAX-режима везде, где это возможно.
Надеюсь, что способ выгрузки в Excel через Xylophone вам понравился и сэкономит много времени и нервов — как сэкономил нам.
В продолжение темы, начатой в предыдущей статье, хочу поделиться своим опытом экспорта данных, в частности, в формате XLSX.
![]()
Итак, кому интересно, как заполнить XLSX без больших и сложных библиотек, прошу под кат.
Недавно передо мной возникла задача экспортировать непредсказуемый по размеру объем табличных данных в формате XLSX. Как любой здравомыслящий программист, первым делом полез искать готовые решения.
Почти сразу наткнулся на библиотеку PHPExcel. Мощное решение, с кучей разных функций и возможностей. Порывшись еще немного нашел отзывы программистов о ней. В частности, на форумах встречаются жалобы на скорость работы и отказ работать с большим объемом данных. Отметил библиотеку как один из вариантов решения и начал искать дальше.
Находил еще несколько библиотек для работы с XLSX, но все они были или забытыми, т.к. не обновлялись по 2-3 года, или обязательно тянули за собой сторонние библиотеки, или использовали DOM для работы с файлами, что мне не очень нравилось. Каждый раз, натыкаясь на очередную библиотеку и изучая механизмы ее работы, ловил себя на мысли, что все это «из пушки по воробьям». Не нужно мне такое сложное решение!
Признаюсь честно, изучив поверхностно каждое из найденных решений, не стал ставить и тестировать ни одного. Мне нужно было более простое и надежное, как танк, решение.Задача
- Оформить экспортирующий механизм в виде автономного класса
- Реализовать в классе набор функций для записи значений ячеек и ряда
- Возможность работы с неограниченным объемом данных
- Распаковка и упаковка XLSX.
Реализация
Изначально очень хотел создавать все файлы, из которых состоит XLSX, кодом, но, к счастью, быстро понял бессмысленность своей идеи. И родилось иное, более правильно и простое решение. Надо с помощью Microsoft Excel создать файл XLSX в таком виде, в каком он нужен в итоге, но без данных, иными словами — шаблон, а потом, с помощью кода, только добавить данные!
В таком случае, класс должен будет распаковывать шаблон в отдельный каталог, вносить изменения в /xl/worksheets/sheet1.xml и упаковывать содержимое каталога обратно в XLSX.В объявлении класса присутствуют публичные переменные:
$templateFile – имя файла шаблона
$exportDir – папка, в которую будет распакован шаблон, разумеется с необходимыми правами доступа.Конструктор класса принимает имя будущего файла, количество колонок и рядов. Потом проверяет, что имя файла корректно, папка для распаковки шаблона существует и формирует полное имя конечной папки для распаковки шаблона.
После создания класса можно распаковать шаблон и открыть на запись sheet1.xml. На самом деле я не просто дописываю в файл, а полностью его перезаписываю. Однажды взяв из него начальную строку, вношу в нее изменение в тэге dimension, который отражает размер экспортируемого диапазона, и записываю в файл.Обеспечить скорость работы и возможность работы с большим объемом данных позволяют функции resetRow и flushRow. Они отвечают за очистку текущего ряда в памяти и запись текущего ряда на диск.
А вот сохранение значений ячеек с разными типами оказалось не такой простой задачей.Запись строки
Казалось бы, что сложного записать строковое значение в файл. Однако, в XLSX все не так просто. Все строки внутри XLSX хранятся в отдельном файле /xl/sharedStrings.xml. В ячейки записываются не строковые значения, а их порядковые номера — индексы. Разумное решение с точки зрения сокращения размера файла.
Но такое решение неудобно с точки зрения программного заполнения шаблона. Если выполнять указанное требование, то мне бы пришлось выполнять отдельный проход по всем строковым значениям в массиве данных, исключать повторяющиеся, сохранять их в sharedStrings.xml, проиндексировать и вместо значений в исходном массиве вписать их индексы. Медленно и неудобно.
Оказывается, можно обойти требование и сохранять строковые значения ячеек прямо в ячейках. Но в этом случае формат записи будет иной:
Запись числа
Никаких сложностей с записью целых или дробных чисел не возникло. Все просто:
Запись даты и времени
Дата и время хранятся в виде количества секунд прошедших с 01.01.1970 поделенных на количество секунд в сутках. Причем, в вычислении допущена ошибка с определением високосного года. В общем, не вдаваясь в подробности, которые несложно найти в сети, чтобы корректно вычислять дату пришлось объявить в классе две константы:
ZERO_TIMESTAMP – смещение даты в формате Excel от UNIX_TIMESTAMP
SEC_IN_DAY – секунд в сутках.
После вычисления значения даты и времени, целая часть дроби – это дата, дробная часть – время:
После записи всех данных остается закрыть рабочий лист и рабочую книгу.Применение
Как и раньше, использование описанного класса основано на экспорте данных с помощью провайдера CArrayDataProvider. Предполагая, что объем экспортируемых данных может оказаться очень большим, применен специальный итератор CDataProviderIterator, который перебирает возвращаемые данные по 100 записей (можно указать иное число записей).
Кому интересно, может получить исходный код моего класса AlxdExportXLSX совершенно безвозмездно.Читайте также:
