
Перестроение индекса sql 1с ошибка
Обновлено: 02.07.2024
На днях столкнулся с одной ошибкой SQL. Попробовал все варианты исправления, и на уровне 1С и на уровне самого SQL, даже индексы хотел было перестроить. Но помогла банальная перезагрузка (физически) сервера.
Но по пути накопал вот этот список ошибок и их решений. В будущем может пригодиться!
Duplicate key в таблице _1scrdoc
Удаление повторяющихся ключей с помощью метода описанного в статье может не помочь. При пересчете такие записи могут появиться вновь. Для решения проблемы можно применить следующую методику - создаете пустую базу в нее копируете файл конфигурации, заходите в конфигуратор, удаляете все графы отбора, сохраняете, копируете файл конфигурации в рабочую базу, запускаете пересчет служебных данных, восстанавливаете графы отбора. Все должно работать.
Восстановление базы только из MDF
1. Создаем новую базу с таким же именем и такимиже по именам и расположению .mdf и .ldf файлами
2. Останавливаем сервер, подменяем файл .mdf
3. Стартуем сервер, не обращаем внимания на статус базы
4. Из QA выполняем скрипт
Use master
go
sp_configure 'allow updates', 1
reconfigure with override
go
4.Там же выполняем
update sysdatabases set status= 32768 where name = '<db_name>'
5. Перезапускаем SQL Server
6. В принципе база должна быть видна (в emergency mode). Можно, например, заскриптовать все объекты. Заходим в EM, выбираем базу, снимаем галку Restricted access в свойствах базы.
7. Из QA выполняем
DBCC REBUILD_LOG('<db_name>', '<имя нового лога с указанием полного пути>')
SQL Server скажет - Warning: The log for database '<db_name>' has been rebuilt.
8. Если все нормально, то там же выполняем
Use master
go
sp_dboption '<db_name>', 'single_user', 'true'
go
USE <db_name>
GO
DBCC CHECKDB('<db_name>', REPAIR_ALLOW_DATA_LOSS)
go
9. Если все в порядке, то
sp_dboption '<db_name>', 'single_user', 'false'
go
Use master
go
sp_configure 'allow updates', 0
go
Ошибка violation of pirmary key при загрузке в базу УРБД
Симпотмы: При загрузке репликации в переферийную базу, SQL вылетает с ошибкой:
Violation of PRIMARY KEY constraint 'PK_RA4047'. Cannot insert duplicate key in object 'RA4047'
Лечение: Для решения данной проблемы отработана следующая технология. Запускаем SQL Profiler с регистрацией ошибок. Когда появляется ошибка смотрим последние операторы, определяем IDDOC сбойного документа. Проблема в том, что признак проведенности по регистру у документа снят (флаг RF), а движения существуют. Вот и происходит ошибка. Лечение - восстановить флаг RF и признак проведенности документы. Можно конечно удалить движения, но не факт, что это правильно отразится на итогах в регистре.
sp_change_users_login AUTO_FIX, 'user_1c'
"Cannot open user default database". Using master database instead
Какой выбрать сервер/сеть & etc для работы 1С на SQL Server Сервер двухпроцессорный , память минимум 256 (лучше больше, SQL память любит, и юзает ее грамотно)
Как производить проверку, переиндексацию базы на SQL Server
Для пересоздания индексов следует воспользоваться командой: DBCC DBREINDEX ('<имя таблицы>') или запустить хранимую процедуру, которая переиндексирует все таблицы в базе данных: EXEC _1sp_DBReindex
Время от времени возникает проблема "Доступ к базе на сервере возможен только из одного каталога информационной базы". Как лечить?
Диагноз: Такая ошибка возникает при попытке загрузить версию 1С для SQL после того, как один из пользователей некорректно вышел из системы. В редких случаях эта ошибка может быть результатом некорректной установки конфигурации.
Анамнез: После закрытия 1С на сервере NT освобождаются ресурсы, которые занимал пользователь. Однако в случае некорректного завершения работы не останавливается SQL-процесс, запущенный пользователем.
Если пользователи работают по протоколу Named pipes, то можно просто закрыть файлы на SQL-сервере, открытые повисшим пользователем. Такие файлы имеют вид \PIPE\MSSQL$NAMEDSERVER\SQL\query.
Если вышеизложенное слишком сложно для Вас, Вы можете просто перегрузить SQL server. Надо только убедиться, что ни одна другая програма не использует его в этот момент.
Если ошибка возникает постоянно, имеет смысл проверить правильность установки конфигурации: с одной базой данных на сервере пользователи должны работать из одного каталога с конфигурационными файлами. Иначе говоря, не могут одновременно работать две (даже идентичные) конфигурации, размещенные в разных каталогах и ссылающиеся на одну и ту же базу.
Умер SQL, но mdf и ldf-файлы остались. Можно ли поднять базу?
exec sp_attach_db <имя БД>,<путь к файлу *.mdf>,<путь к файлу *.ldf>
Ошибка SQL Server "Cannot resolve collation for equal operation"
Данная ошибка возникает при сравнении полей с различной collation. Подробно описание ошибки можно найти в статье "Transact-SQL ReferenceData TypesCollation Precedence" в Books OnLine. В случае 1С это может быть, например, когда различаются collation вашей рабочей базы и базы tempdb. При первоначальной установке collation базы tempdb устанавливается такой же как у сервера и обычно не меняется. Collation базы выбирается при создании базы, но может быть изменена с помощью команды ALTER DATABASE. Поэтому обычно такая ошибка возникает, когда collation базы первоначально была выбрана отличной от collation сервера. База tempdb используется для создания временных таблиц, в частности, когда используется конструкция "В" в запросе или когда используется отбор по группе в других выборках.
Чтобы устранить эту ошибку нужно поменять либо collation рабочей базы, либо collation сервера. Чтобы поменять collation рабочей базы воспользуйтесь командой ALTER DATABASE COLLATION = collation_сервера. При этом сами данные не изменяются. Поэтому необходимо сначала выгрузить ваши данные, а потом загрузить обратно. Я, например, делал это с помощью инструмента Data Transformation Services (DTS) с помощью задачи переноса объекто SQL Server с сервера на сервер. Для этого нужно создать новую базу с collation равной collation сервера, в параметрах задачи (на рабочем поле кликнете правой клавишой мышки, выберите "Disconnected Edit", затем ветку задач, вашу задачу переноса) нужно указать дополнительную опцию ScriptOptionEx = SQLDMOScript2_70Only(16777216), которая укажет не формировать для каждого поля его collation (чтобы не переносить старую). Затем нужно выполнить задачу. Все. Теперь можете пользоваться новой базой, либо загрузить данные обратно.
Про дополнительную опцию можно прочитать в статье "Data Transformation ServicesUsage Considerations in DTSData Conversion and Transformation Considerations".
Ошибка "Could not continue scan with NOLOCK due to data movement"
В BOL причина ошибки связана с сочетанием блокировки (NOLOCK) и уровнем изоляции (READ UNCOMMITED) таким образом, что при чтении данных некоторые прочитанные страницы могут быть удалены до завершения транзакции. Нам это ничего не дает. Кажется, что проблема связана с проектированием 1С. На самом деле система использует другой уровень изоляции, который не может привести к такой ситуации. Обычно ошибка появляется при разрушении данных. На моей памяти это было в двух случаях. Проверка БД производится как обычно с помощью DBCC CHECKDB. Если данные разрушены, то команда выдаст список объектов, в которых найдены повреждения. Сделайте резервную копию и попытайтесь с помощью все той же DBCC CHECKDB восстановить данные. Если повреждения несерьезные, то восстановление проходит гладко. Если нет, то проще произвести восстановление БД из резервной копии.
Совет. Чтобы не возникало данной ошибки, следите за местом на диске, следите за состоянием вашей дисковой системы, ставьте на сервер ИБП, делайте резервные копии.
Каким образом на клиентской рабочей станции можно настроить сетевой протокол (TCP/IP, Named Pipes и т.д.) взаимодействия с сервером MS SQL?
Для этого нужно воспользоваться вышеупомянутой утилитой Client Network Utility. С помощью нее можно настроить тип протокола (TCP/IP, Named Pipes, Multiprotocol и т.д.), а также ряд дополнительных параметров (например, при успользовании протокола TCP/IP можно указать порт, по которому будет производиться подключение к серверу MS SQL).
Как устранить ошибку "База не может быть открыта в однопользовательском режиме"?
Login failed for user XXX. Reason: Not associated with trusted SQL Server connection
1С поддерживает только смешанный режим подключения к SQL Server. Для установки режима подключения в свойствах сервера на закладке Security выберите Mixed mode.
При выгрузке-загрузке 1С зависает, либо вылетает
Одной из причин (довольно распространенной) является наличие реквизитов неограниченной длины. Например, такие рквизиты обычно присутствуют в общих реквизитах документа (Комментарий). При выгрузке такие реквизиты должны стоять в конце списка реквизитов. Если все же ошибка не устраняется, то поробуйте удалить эти реквизиты и произвести выгрузку-загрузку без них.
И конечно же самое первое, что вы должны сделать перед выгрузкой это тестирование базы. Подробно про переход на весрию SQL 1С (в том числе про выгрузку-загрузку) вы можете прочитать в этой статье.
Восстановление базы данных только из MDF
1. Создаем пустую базу с_тем_же_именем, остановливаем сервер и записываем вместо "родного" файла этой базы свой *.mdf.
2. Запускаем сервер. Он переведет базу в suspect.
3. Выводим базу из состояния suspect:
use master
go
sp_configure 'allow updates',1
go
reconfigure with override
go
--Для сброса признака suspect выполняем в БД master ХП sp_resetstatus:
update sysdatabases set status=32768 where name='Base_New'
go
--А теперь запретим прямое изменение системных таблиц:
sp_configure 'allow updates',0
go
4. База находится в "emergency mode", поэтому копируем данные из этой базы в новую, используя режим "Copy objects and data, between SQL Server databases".
Автор ответа Джинн, neatmen
База находится в состоянии suspect. Как ее "оживить"?
use master
go
sp_configure 'allow updates',1
go
reconfigure with override
go
--Для сброса признака suspect выполняем в БД master ХП sp_resetstatus:
update sysdatabases set status=32768 where name='Base_New'
go
--А теперь запретим прямое изменение системных таблиц:
sp_configure 'allow updates',0
go
Проблемы при соединении с SQL Server установленном на Windows 2003 Server
Пользователи жаловатся начали на тормоза работы в 1с. Так как база почти стандартная УТ,
решил начать с оптимизации работы SQL,т.к. на нем вообще никаких регламентных
заданий не проводилось с рождения.
Начитался информации (продолжаю её "употреблять"). В результате ,что задумал -сделать
план обслуживания по бэкапированию базы данных и проведения рег. операции (обновление статистики,
операция DBCC FREEPROCCACHE, реорганизация индекса, перестроение индексов, удаление старых архивов).
Что сделал и что имеем на данный момент:
в Microsoft SQL Server Management Studio создал один план обслуживания -BackUp1c.
В нем создал 2 вложенных плана
1.BackUp1c_daily
2.BackUp1c_Week
Далее по шагам подчинения (связи) перечислю, что создал в каждом субплане.
1.BackUp1c_daily (расписание каждый день в 3 часа ночи, кроме субботы)
1.1. Резервное копирование базы данных.(бэкап файла данных -тип резервной копии -Полный)
1.2 Резервное копирование базы данных1.(бэкап журнала транзакции).
1.3. Обновление статистики (вся статистика , полный просмотр)
1.4. Выполнение инструкции DBCC FREEPROCCACHE
1.5. Реорганизация индексов (стоит галка "Сжатие больших объемов")
1.6. Очистка после обслуживания (удаление файлов бэкапа старше 3 дней- много места занимают )
2.BackUp1c_Week(расписание каждую субботу 3 часа ночи)
2.1. Резервное копирование базы данных.(бэкап файла данных -тип резервной копии -Полный)
2.2. Перестроение индекса (Реорганизовать страницы использованием объема свободного места по умолчанию =1)
Все это в Агенте SQl сервера висит. Дополнительно висит созданное не мной задание:
имя - syspolicy_purge_history
ШАги:
1. Verify that automation is enabled.
Команда:
IF (msdb.dbo.fn_syspolicy_is_automation_enabled() != 1)
BEGIN
RAISERROR(34022, 16, 1)
END
2.Purge history.
Команда:
EXEC msdb.dbo.sp_syspolicy_purge_history
3.Erase Phantom System Health Records.
Команда:
(Get-Item SQLSERVER:\SQLPolicy\DSQ\DEFAULT).EraseSystemHealthPhantomRecords()
Смысл последнего задания (не моего) -понял очень приблизительно (если кто расшифрует подробно -буду
благодарен)-удаляет ошибки и фантомные записи.
Теперь результат:
запускал субпланы в рабочее время -проверял работет или нет.
Запустил первый субплан -крутилось минут 15-20 все. Итог -MDF=18,8ГБ, LDF=22ГБ.
Запуси второй субплан -крутилось минут 10-15 все. Итог -MDF=18,8ГБ, LDF=45,6 ГБ.
в итоге лог не растет, но в бэкап уходит целиком 44,8 гб.
Как я понял из прочитанного операцию shrink logа делать не нужно (не реомендуется?)
P.S. Обычно самое узкое место это операции ввода-вывода. Оптимизируй большие запросы и пользователи будут рады.
Если есть хоть малейшая (с т.з. обеспечения целостности данных) возможность провести урезание - бэкап его выполняет.
Планы обслуживания/Maintenance Plan в MS SQL Server
Вообще, планы обслуживания нужно подстраивать под конкретное оборудование и базы данных. Оставим это на усмотрение профессионалов администрирования баз данных. В общем случае, для базы данных не более 200 Гб в MS SQL Server рекомендуется выполнять следующие регламентные операции:
- Проверка целостности базы данных
- Реорганизация индекса/Восстановить индекс
- Обновление статистики
Рекомендуется регулярно контролировать своевременность и правильность выполнения данных регламентных процедур.
Проверка целостности базы данных/DBCC CHECKDB
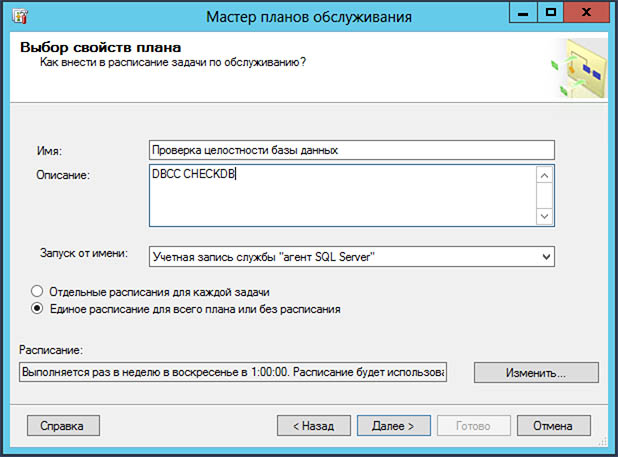
Периодичность: 1 раз в неделю.
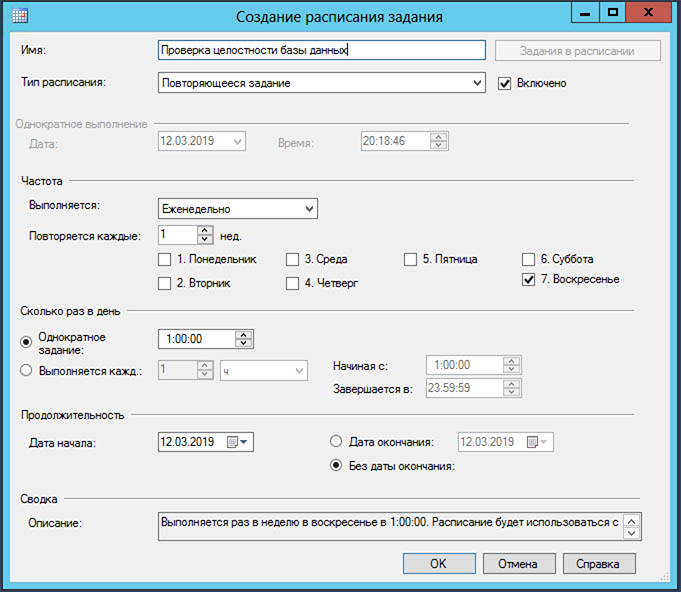

Выбираем необходимые базы данных для обслуживания: либо какую-то определенную, либо несколько, либо все пользовательские.
Реорганизация индекса/Восстановить индекс
MS SQL Server самостоятельно создает и изменяет индексы при работе с базой. С течением времени данные в индексе становятся фрагментированными, т.е. разбросанными по базе данных. Существенно фрагментированные индексы могут серьезно снижать производительность запросов и служить причиной замедления работы базы. Если фрагментация составляет от 5 до 30%, то рекомендуется ее устранить с помощью реорганизации, при фрагментации свыше 30% необходимо полное перестроение индексов.
В простейшем случае получить информацию по фрагментации индексов можно с помощью кода:
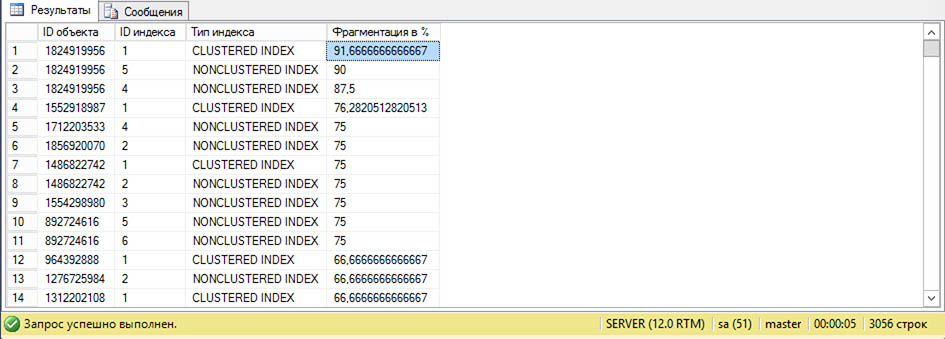
Почему регулярно стоит использовать именно реорганизацию индекса?
В свою очередь, реорганизация индексов — это серия небольших локальных перемещений страниц так, чтобы индекс не был фрагментирован. После реорганизации статистика не обновляется. Во время выполнения почти все данные доступны, пользователи смогут работать.
Вывод: Если фрагментация более 30%, нужно выполнить разовое полное перестроение индексов (восстановить индекс). После перестроения планово использовать только реорганизацию.
Периодичность: 1 раз в сутки.
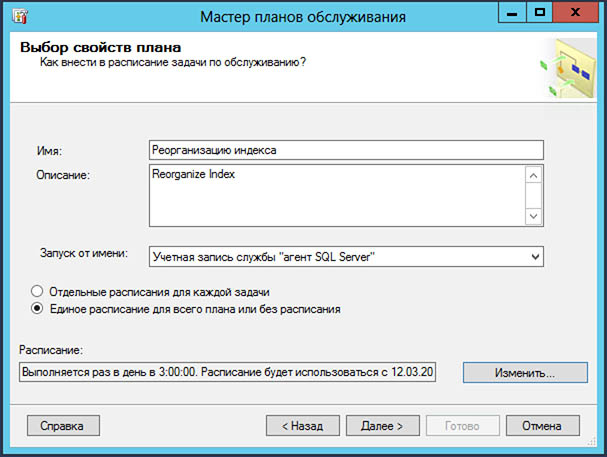
Выбираем необходимые базы данных для обслуживания: либо какую-то определенную, либо несколько, либо все пользовательские.
Обновление статистики
Статистика — небольшая таблица (обычно до 200 строк), в которой хранится обобщенная информация о том, какие значения и как часто встречаются в таблице. На основании статистики сервер принимает решение, как лучше построить запрос. Обычно, оптимизатор запросов создает необходимую статистику, но иногда необходимо создать дополнительные статистические данные для достижения лучших результатов.
Периодичность: 1 раз в сутки.
Выбираем необходимые базы данных для обслуживания: либо какую-то определенную, либо несколько, либо все пользовательские.
Обновление статистик и реорганизацию индекса и создание полного архива можно уместить в одну задачу, выбрав в окне выбора задач обслуживания соответствующие флаги.
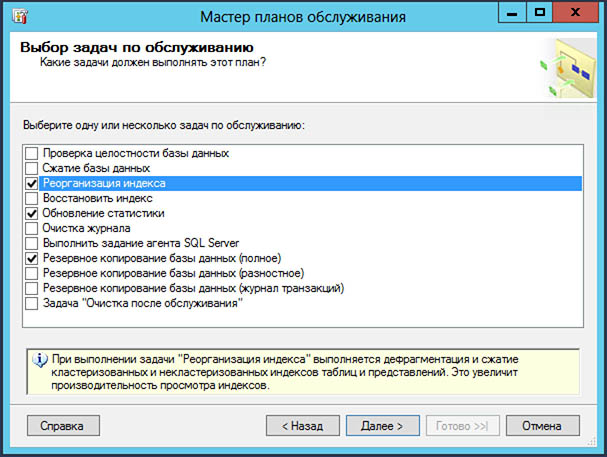
Контроль выполнения планов обслуживания
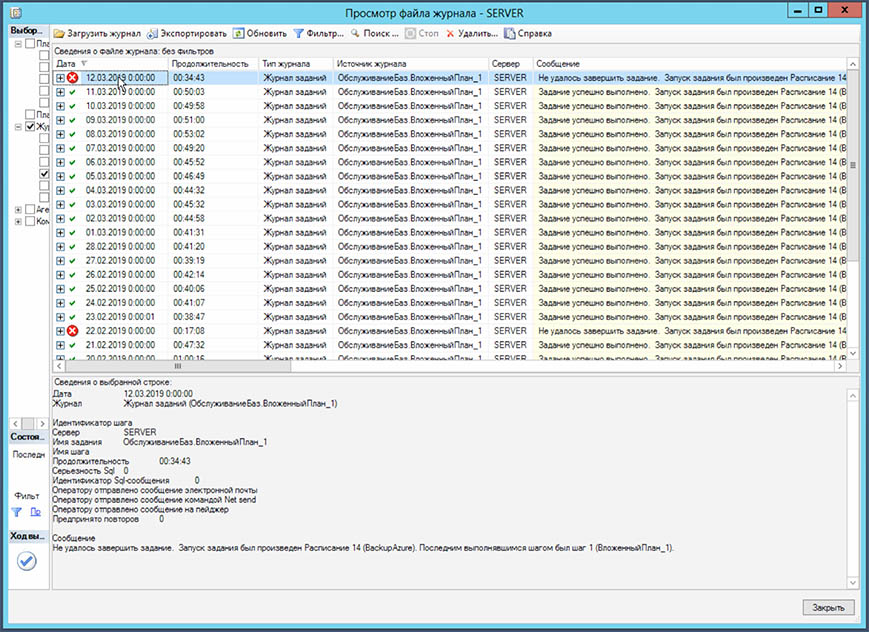
Если в журнале будут обнаружены ошибки, стоит изучить проблему и принять меры. Планы обслуживания должны отрабатывать успешно.
Почему не стоит использовать сжатие базы данных (шринк/shrink)?
В остальных случаях:
- сжатие файла базы данных (MDF) приводит к увеличению индексов;
- сжатие файла журнала транзакций (LDF) не нужно при правильной настройке резервного копирования и обслуживании индексов. При использовании полной модели восстановления (Full Recovery Model) базы SQL важно делать регулярные резервные копии файла журнала транзакций и только перестроение индексов. Тогда, файл LDF будет соизмерим с размером файла базы данных и не будет бесконтрольно расти.
Краткий ответ на вопрос заголовка заключается в том, что это позволит выполнять запросы быстро и уменьшать негативное влияние блокировок на производительность в многопользовательском режиме.
Что такое индекс?
Подобно содержанию в книге, индекс в базе данных позволяет быстро искать конкретные сведения в таблице.
Сначала поговорим про индексы в MS SQL Server.
Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов.
Индекс содержит ключи, построенные из одного или нескольких столбцов таблицы или представления, и указатели, которые сопоставляются с местом хранения заданных данных.
Индексы сокращают объем данных, которые необходимо считать, чтобы возвратить результирующий набор.
Хотя индекс и связан с конкретным столбцом (или столбцами) таблицы, все же он является самостоятельным объектом базы данных.

Просто объекта «Индекс» в платформе 1С:Предприятие 8 нет.
Индексы таблиц в базе данных 1С:Предприятие создаются неявным образом при создании объектов конфигурации, а также при тех или иных настройках объектов конфигурации.

Еще одним явным способом можно считать добавление объекта метаданных в объект метаданных «критерий отбора».

Можно указать индекс для таблицы значений и в запросах для временных таблиц.
ВЫБРАТЬ
Код,
Наименование
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ Справочник.Номенклатура
ИНДЕКСИРОВАТЬ ПО Код
В любом случае, надо понимать, что говоря об индексах, мы фактически подразумеваем индексы СУБД, которая используется для 1С:Предприятие. Исключению составляют объекты типа Таблица значений, когда индексы находятся в RAM (оперативной памяти).
Физическая сущность индексов в MS SQL Server.
Несмотря на достоинства, индексы так же имеют и ряд недостатков. Первый из них – индексы занимают дополнительное место на диске и в оперативной памяти. Каждый раз когда вы создаете индекс, вы сохраняете ключи в порядке убывания или возрастания, которые могут иметь многоуровневую структуру. И чем больше/длиннее ключ, тем больше размер индекса. Второй недостаток – замедляются операции вставки, обновления и удаления записей.
В среде MS SQL Server реализовано несколько типов индексов:
- некластерные индексы;
- кластерные (или кластеризованные) индексы;
- уникальные индексы;
- индексы с включенными столбцами
- индексированные представления
- полнотекстовый
- XML
Некластерный индекс
Некластерные индексы – не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки.
Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя:
- информацию об идентификационном номере файла, в котором хранится строка;
- идентификационный номер страницы соответствующих данных;
- номер искомой строки на соответствующей странице;
- содержимое столбца.
Некластерных индексов может быть несколько для одной таблицы.
Некластеризованный индекс по таблице, не имеющей кластеризованного индекса
Некластеризованный индекс по таблице, имеющей кластеризованный индекс
Кластерный (кластеризованный) индекс
Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту.
Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными. Если в таблице определен некластерный индекс, то сервер должен сначала обратиться к индексу, а затем найти нужную строку в таблице. При использовании кластерных индексов следующая порция данных располагается сразу после найденных ранее данных. Благодаря этому отпадают лишние операции, связанные с обращением к индексу и новым поиском нужной строки в таблице.
Естественно, в таблице может быть определен только один кластерный индекс. Кластерный индекс может включать несколько столбцов.
Необходимо избегать создания кластерного индекса для часто изменяемых столбцов, поскольку сервер должен будет выполнять физическое перемещение всех данных в таблице, чтобы они находились в упорядоченном состоянии, как того требует кластерный индекс. Для интенсивно изменяемых столбцов лучше подходит некластерный индекс.
При создании в таблице первичного ключа (PRIMARY KEY) сервер автоматически создает для него кластерный индекс, если его не существовало ранее или если при определении ключа не был явно указан другой тип индекса.
Когда же в таблице определен еще и некластерный индекс, то его указатель ссылается не на физическое положение строки в базе данных, а на соответствующий элемент кластерного индекса, описывающего эту строку, что позволяет не перестраивать структуру некластерных индексов всякий раз, когда кластерный индекс меняет физический порядок строк в таблице.
Уникальный индекс
Уникальность значений в индексируемом столбце гарантируют уникальные индексы. При их наличии сервер не разрешит вставить новое или изменить существующее значение таким образом, чтобы в результате этой операции в столбце появились два одинаковых значения.
Уникальный индекс является своеобразной надстройкой и может быть реализован как для кластерного, так и для некластерного индекса. В одной таблице может существовать один уникальный кластерный и множество уникальных некластерных индексов.
Уникальные индексы следует определять только тогда, когда это действительно необходимо. Для обеспечения целостности данных в столбце можно определить ограничение целостности UNIQUE или PRIMARY KEY, а не прибегать к уникальным индексам. Их использование только для обеспечения целостности данных является неоправданной тратой пространства в базе данных. Кроме того, на их поддержание тратится и процессорное время.

1С:Предприятие 8 активно использует кластерные уникальные индексы. Это означает, что можно получить ошибку не уникального индекса.
Если не уникальность заключается в датах с нулевыми значениями, то проблема решается созданием базы с параметром смещения равным 2000.
«Рыба» скрипта для определения не уникальных записей:
SELECT COUNT(*) Counter, <перечисление всех полей соответствующего индекса> from <имя таблицы>
GROUP BY <перечисление всех полей соответствующего индекса>
HAVING Counter > 1
Понятие первичного и внешнего ключа
Первичный ключ (primary key) – это набор столбцов таблицы, значения которых уникально определяют строку.
Внешний ключ (foreign key) . Внешним ключом называется поле таблицы, предназначенное для хранения значения первичного ключа другой таблицы с целью организации связи между этими таблицами. Внешний ключ в таблице может ссылаться и на саму эту таблицу. Такие внешние ключи, в основном, используются для хранения древовидной структуры данных в реляционной таблице. СУБД поддерживают автоматический контроль ссылочной целостности на внешних ключах.
1С не использует внешние ключи. Ссылочная целостность обеспечивается логикой приложения.
Ограничения индексов
Индекс может быть создан на основании нескольких полей. В этом случае существует ограничение – длина ключа индекса не должна превышать 900 байтов и не более 16 ключевых столбцов. На практике это означает что при создании индекса, включающего более 16 полей, индекс усекается. Это может оказать влияние на производительность при количестве субконто составного типа более 4х.
Статистика индексов
Microsoft SQL Server собирает статистику по индексам и полям данных, хранимых в базе. Эта статистика используется оптимизатором запроса SQL Server при выборе оптимального плана исполнения запросов на выборку или обновление данных.
При создании индекса оптимизатор запросов автоматически сохраняет данные статистики о проиндексированых столбцах.
Фрагментация индексов

Оптимизация размещения индексов
При объеме таблиц не позволяющем им «разместиться» в оперативной памяти сервера, на первое место выходит скорость дисковой подсистемы (I/O). И здесь можно обратить внимание возможность размещать индексы в отдельных файлах расположенных на разных жестких дисках.

Влияние индексов на блокировки
Эффективность индексов
Мы уже отметили в заголовке статьи, что нас интересуют влияние индексов на быстродействие запросов. Итак, индексы наиболее подходят для задач следующего типа:
Правда при всей полезности индексов, есть одно очень важное НО – индекс должен быть «эффективно используемым» и должен позволять находить данные с использованием меньшего числа операций ввода-вывода и объема системных ресурсов. И наоборот, неиспользуемые (редко используемые) индексы скорее ухудшают скорость записи данных (поскольку каждая операция, изменяющая данные, должна также обновлять страницы индексов) и создают избыточный объем базы.
Покрывающим (для данного запроса), называется индекс в котором есть все необходимые поля для этого запроса. Например, если индекс создан по колонкам a, b и c, а оператор SELECT запрашивает данные только из этих колонок, то требуется доступ только к индексу.
Читайте также: