
Построить две таблицы дискретных распределений зарплат указав частоты в эксель
Обновлено: 06.07.2024
На вводном уроке по математической статистике мы узнали, что такое математическая статистика, и теперь обо всём подробнее. Далее для удобства я буду нумеровать статьи и постараюсь делать их не слишком длинными. Потому что всё действительно просто, и главное, здесь научиться рациональной технике вычислений, на которую и будет сделан особый упор.
Интервальные и дискретные вариационные ряды почти сразу же встретились в предыдущей статье, и мы начинаем с дискретного случая, когда количественная эмпирическая величина может принимать лишь отдельные изолированные значения.
…что-то не понятно по терминам? Срочно изучать первый урок! (ссылка выше)
Дискретный вариационный ряд – это упорядоченное по возрастанию (как правило) множество вариант (значений величины ) и соответствующих им частот либо относительных частот.
Частоты выборочной совокупности обозначают через , частоты генеральной совокупности – через . И сразу разбираемся с новым термином. Относительные частоты рассчитываются по формулам:
, где – объем выборки, при этом, сумма всех относительных частот: .
Аналогично для совокупности генеральной:
, где – её объем, и, очевидно:
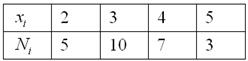
И тут вспоминается Пример 2 об оценках по матанализу в группе из студентов:
– пожалуйста, пример дискретного вариационного ряда, где варианты – это оценки, а частоты – количество студентов, получивших ту или иную оценку.
Для разминки найдём относительные частоты:
и непременно проконтролируем, что: .
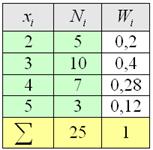
Все вычисления обычно проводят на калькуляторе либо в Экселе, а результаты заносят в таблицу, при этом, в статистике данные чаще располагают не в строках, а в столбцах:
Такое расположение обусловлено тем, что количество вариант может быть достаточно велико, и они просто не вместятся в строчку. Не редкость, когда их 10-20, а бывает, и 100-200, что тоже и неоднократно встречалось в моей практике. И это не какие-то супер-пупер расчёты, а учебные задачи!
Откуда берутся дискретные вариационные ряды? Такие ряды появляются в результате учёта дискретной характеристики статистической совокупности, причём, варианты ряда не отличаются большим разнообразием. Например, оценки (коих не так много) в примере выше.
И сейчас мы примем непосредственное участие в этом процессе:
По результатам выборочного исследования рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4, 4, 5, 2, 3, 3, 4, 5, 5, 2, 3, 6, 5, 4, 6, 4, 3. Требуется:
– составить вариационный ряд и построить полигон частот;
– найти относительные частоты и построить эмпирическую функцию распределения.
Чего томиться? – вся тема урока в одной задаче!
Решение: в условии прямо сказано о том, что перед нами выборка из генеральной совокупности (всех рабочих цеха), и первое, что логично сделать – подсчитать её объем, т.е. количество рабочих. В данном случае это легко сделать устно: .
Квалификационные разряды – есть величина дискретная, и поэтому нам предстоит составить дискретный вариационный ряд (обратите внимание, что в условии ничего не сказано о характере ряда).
Как это сделать?
Если у вас под рукой нет вычислительных программ, то вручную (Эксель разберём ниже). При этом оптимальным может быть следующий алгоритм: сначала окидываем взглядом все числа и определяем среди них минимальное (примерно) и максимальное (примерно). В данном случае ориентировочный диапазон – от 1 до 7. Записываем их в столбец на черновике и обводим в кружочки. Далее начинаем вычёркивать карандашом числа из исходного списка:
и делать около соответствующих кружков засечки:
После того, как все числа будут вычеркнуты, подсчитываем количество засечек в каждой строке:
И обязательно проверяем, получается ли у нас в сумме объём выборки :
, отлично, искомый ряд составлен, заносим полученные значения в таблицу на чистовик:
…ну что же, вполне и вполне логично – рабочих средней квалификации много, а учеников и мастеров – мало. Полученные результаты позволяют достаточно точно судить об уровне квалификации всего цеха (если, конечно, выборка представительна)
Построенный вариационный ряд также называют статистическим распределением выборки, причём, этот термин применИм не только для дискретного, но и для интервального ряда, который мы рассмотрим на следующем уроке.
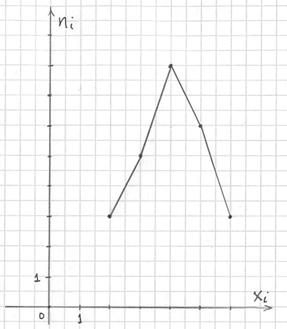
Построим полигон частот. Это статистический аналог многоугольника распределения дискретной случайной величины (кто изучал). Полигон частот – это ломаная, соединяющая соседние точки :
…эх, ностальгия. Но, пятилетку-другую, думается, так решать ещё будут.
Теперь современный способ:
Решаем! – исходные данные с пошаговой инструкцией прилагаются.
Вторая часть задачи. Найдём относительные частоты , для этого каждую частоту делим на и результат заносим в дополнительный столбец, далее я перехожу к электронной версии:
– обязательно проверяем, что сумма относительных частот равна единице!
Иногда требуется построить полигон относительных частот. Как вы правильно догадываетесь – это ломаная, соединяющая соседние точки . Но такое задание больше характерно для интервального вариационного ряда.
А теперь посмотрим на относительные частоты и задумаемся, на что они похожи? …Правильно, на вероятности. Так, например, можно сказать, что – есть примерная вероятность того, что наугад выбранный рабочий цеха будет иметь 4 разряд. «Примерная» – по той причине, что перед нами выборка.
А вот если учесть ВСЕХ рабочих цеха (всю генеральную совокупность), то рассчитанные относительные частоты – и есть в точности эти вероятности.
Построим эмпирическую функцию распределения . Это статистический аналог функции распределения из тервера. Данная функция определяется, как отношение:
, где – количество вариант СТРОГО МЕНЬШИХ, чем ,
при этом «икс» «пробегает» все значения от «минус» до «плюс» бесконечности.
И процесс пошёл:
Очевидно, что на интервале , и, кроме того, функция равна нулю ещё и в точке . Почему? Потому, что значение определяет количество вариант, которые СТРОГО меньше двух, а это количество равно нулю.
На промежутке – и опять обратите внимание, что значение не учитывает рабочих 3-го разряда, т.к. речь идёт о вариантах, которые СТРОГО меньше трёх.
На промежутке и далее процесс продолжается по принципу накопления частот:
– и, наконец, если , то – и в самом деле, для ЛЮБОГО «икс» из интервала ВСЕ частоты расположены СТРОГО левее этого «икс».
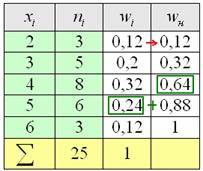
Накопленные относительные частоты удобно записывать в отдельный столбец таблицы, при этом алгоритм вычислений очень прост: сначала сносим слева 1-е значение (красная стрелка), а каждое следующее получаем как сумму предыдущего и относительной частоты из текущего левого столбца (зелёные обозначения):
Вот, кстати, ещё один довод за вертикальную ориентацию данных – справа по надобности можно приписывать дополнительные столбцы.
Саму функцию принято записывать в кусочном виде:
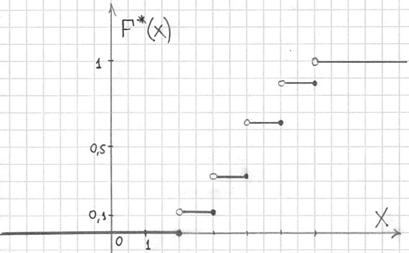
а её график представляет собой ступенчатую фигуру:
Эмпирическая функция распределения не убывает и принимает значения из промежутка , и если у вас вдруг получится не так, то ищите ошибку.
И сейчас мы автоматизируем процесс; видео, к сожалению, не вписалось по ширине, посему смотрим его на Ютубе:

Как построить эмпирическую функцию распределения?
Эмпирическая функция распределения строится по выборке и приближает теоретическую функцию распределения . Легко догадаться, что последняя образуется на основании исследования всей генеральной совокупности, но если рабочих в цехе ещё пересчитать можно, то звёзды на небе – уже вряд ли. Вот поэтому и важнА именно эмпирическая функция, и ещё важнее, чтобы выборка была репрезентативна, дабы приближение было хорошим.
Миниатюрная задача для закрепления материала:
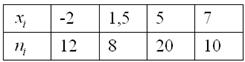
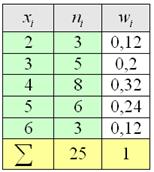
Дано статистическое распределение выборки
Составить эмпирическую функцию распределения, выполнить чертёж
Самостоятельно решить Пример 5 в Экселе, все числа и обозначения уже там.
Свериться с образцом можно ниже. По поводу красоты чертежа сильно не запаривайтесь, главное, чтобы было правильно – этого обычно достаточно для зачёта.
И я жду вас на третьем уроке, где речь пойдёт об интервальном вариационном ряде.
Решения и ответы:
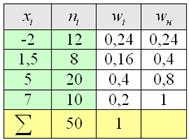
Пример 5. Решение: заполним расчётную таблицу:
Составим эмпирическую функцию распределения:
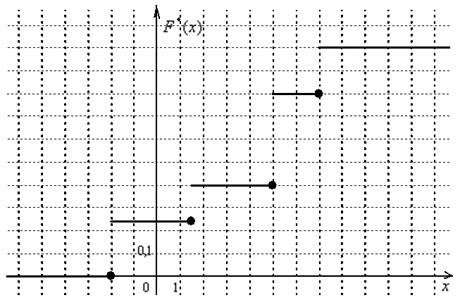
Выполним чертёж:
Автор: Емелин Александр
(Переход на главную страницу)

«Всё сдал!» — онлайн-сервис помощи студентам

В Excel частота - это встроенная функция, которая подпадает под статистическую категорию. Распределение частоты может быть определено как список данных или графика, который дает частоту различных результатов. В Excel это встроенная функция, которая часто используется для получения данных о различных результатах потока и затем возвращает вертикальный массив числа, имеющего еще один элемент, т.е. функция частоты обычно возвращает значение массива, которое должно быть обновлено как формула массива на основе данные.
Формула частоты в Excel
Ниже приведена формула частоты в Excel:

Функция частоты имеет два аргумента:
- Массив данных: набор значений массива, в котором он используется для подсчета частот. Если значения массива данных равны нулю (то есть значения NULL), то функция частоты в Excel возвращает массив нулевых значений.
- Массив бинов: набор значений массива, который используется для группировки значений в массиве данных. Если значения массива bin равны нулю (т. Е. Значения NULL), он возвращает количество элементов массива из массива данных.
Как сделать распределение частот в Excel?
Распределение частот в Excel очень простое и удобное в использовании. Давайте разберемся с работой распределения частот Excel на некотором примере.
Вы можете скачать этот шаблон Excel для распределения частот здесь - Шаблон Excel для распределения частот
В Excel мы можем найти «частотную функцию» в меню формул, которая подпадает под статистическую категорию, выполнив следующие шаги следующим образом.

- Нажмите на Дополнительные функции .

- В категории « Статистика » выберите « Функция частоты», как показано на скриншоте ниже.

- Мы получим диалоговое окно Frequency Function, как показано ниже.

Где массив данных - это массив или набор значений, где мы хотим подсчитать частоты, а Bins_array - это массив или набор значений, где мы хотим сгруппировать значения в массиве данных.
Пример № 1
В этом примере мы увидим, как найти частоту с помощью доступной базы данных студентов.
Давайте рассмотрим приведенный ниже пример, который показывает оценку студентов, которая показана ниже.

Теперь, чтобы вычислить частоту, мы должны сгруппировать данные с оценками учащихся, как показано ниже.

Теперь с помощью функции частоты мы сгруппируем данные, выполнив следующие шаги.
- Создайте новый столбец с именем Частота.
- Используйте частотную формулировку в столбце G, выбрав от G3 до G9.

- Здесь нам нужно выбрать весь столбец частоты, тогда только функция частоты будет работать правильно, иначе мы получим значение ошибки.
- Как показано на скриншоте выше, мы выбрали столбец в качестве массива данных и массив бинов в качестве меток ученика = FREQUENCY (F3: F9, C3: C22) и перейдем к сочетаниям клавиш CTRL + SHIFT + ENTER .
- Так что мы получим значения во всем столбце.
- Как только мы нажмем CTRL + SHIFT + ENTER, мы увидим открывающую и закрывающую скобки, как показано ниже.

Теперь, используя распределение частот Excel, мы сгруппировали оценки учеников по меткам, которые показывают, что ученики набрали баллы: 0-10, у нас 1 студент, 20-25, у нас 1 студент, 50-55, у нас 1 студент, 95-100. 1 студент, как показано ниже.

Пример № 2
Распределение частот Excel с использованием сводной таблицы
В этом примере мы увидим, как добиться превосходного распределения частоты, используя графические данные с доступной базой данных продаж.
Один из самых простых способов сделать распределение частоты Excel - это использовать сводную таблицу, чтобы мы могли создавать графические данные.
Рассмотрите ниже данные о продажах, которые имеют год распродажи. Теперь мы увидим, как использовать это с помощью сводной таблицы, выполнив следующие шаги.

- Создайте сводную таблицу для вышеуказанных данных о продажах. Для создания сводной таблицы нам нужно перейти в меню вставки и выбрать сводную таблицу.

- Перетащите вниз Продажи в метках строк. Перетащите вниз те же продажи в ценности.

- Убедитесь, что мы выбрали параметр поля поворота для подсчета, чтобы получить числа подсчета продаж, показанные ниже.

- Нажмите на номер продажи ярлыка строки и щелкните правой кнопкой мыши, затем выберите вариант группы.

- Так что мы получим диалоговое окно группировки, как показано ниже:

- Измените номера группировки, начиная с 5000 и заканчивая 18000, и сгруппируйте их по 1000, а затем нажмите кнопку ОК.

- После этого мы получим следующий результат, где данные о продажах были сгруппированы по 1000, как показано ниже:

Мы видим, что данные о продажах были сгруппированы по 1000 со значениями от минимума до максимума, которые могут быть показаны более профессионально при отображении в графическом формате.
- Зайдите в меню вставки и выберите столбчатую диаграмму.


Пример № 3
Распределение частот Excel с использованием гистограммы
Используя сводную таблицу, мы сгруппировали данные о продажах, теперь мы увидим, как сделать исторические данные о продажах с помощью распределения частоты в Excel.
Рассмотрим приведенные ниже данные о продажах для создания гистограммы с именем продавца с соответствующими значениями продаж. Где CP - это не что иное, как Consumer Pack, а Tins - это значения диапазона, то есть, сколько банок было распродано конкретным продавцам.

Мы можем найти гистограмму в группе анализа данных в меню данных, которое представляет собой не что иное, как надстройки. Мы увидим, как применить гистограмму, выполнив следующие шаги.
- Зайдите в меню данных справа вверху, мы можем найти анализ данных. Нажмите на анализ данных, который выделен, как показано ниже.

- Так что мы получим диалоговое окно ниже. Выберите опцию «Гистограмма» и нажмите «ОК».


- Укажите входной диапазон и диапазон бункера, как показано ниже.

- Убедитесь, что у нас есть галочка для всех опций, таких как метка, совокупный процент, выходной график, а затем нажмите кнопку ОК.

- На графике ниже мы получили вывод, который показывает совокупный процент вместе с частотой.

Мы можем отобразить вышеупомянутую гистограмму более профессионально, отредактировав данные о продажах следующим образом.
- Щелкните правой кнопкой мыши по гистограмме и выберите «Выбор данных».

- Мы получим диалоговое окно для изменения диапазонов. Нажмите на редактировать.

- Так что мы можем редактировать диапазоны, которые нам нужно дать. Измените значение Bins, что нам нужно, чтобы указать диапазон, чтобы мы получили соответствующий результат, а затем нажмите кнопку ОК.

- Таким образом, результат будет таким, как показано ниже.

Что нужно помнить о распределении частот в Excel
- В Excel Распределение частот при группировании мы можем потерять некоторые данные, поэтому убедитесь, что мы группируем должным образом.
- При использовании частотного распределения Excel убедитесь, что классы должны быть одинакового размера с верхним и нижним предельными значениями.
Рекомендуемые статьи
Это было руководство по распределению частот в Excel. Здесь мы обсуждаем формулу частоты в Excel и как сделать распределение частоты в Excel вместе с практическими примерами и загружаемым шаблоном Excel. Вы также можете просмотреть наши другие предлагаемые статьи -
Рассмотрим Равномерное дискретное распределение, построим график функции распределения, вычислим среднее значение и дисперсию. Сгенерируем случайные значения (выборку) с помощью функции MS EXCEL СЛУЧМЕЖДУ() . На основании выборки оценим среднее и стандартное отклонение распределения.
Равномерное дискретное распределение (англ. Discrete uniform distribution) имеет место, например, при подбрасывании симметричной монеты. Пусть если выпал «орёл», то случайная величина принимает значение 1, если выпала «решка» - то 0. Т.к. вероятность наступления событий одинакова и всего 2 возможных исхода, то вероятность случайной величины принять значение 1 (или 0) равна 1/2=0,5.
Распределение называется равномерным, т.к. вероятность любого исхода одинакова.
Примечание : В данном случае, когда возможно всего 2 исхода, равномерное распределение является частным случаем Распределения Бернулли с параметром p = q =1- p =0,5.
Другой пример. Результат бросания симметричной игральной кости является равномерной дискретной случайной величиной , т.к. количество точек на грани кубика принимает одно из 6 равновероятных значений. Вероятность выпадения каждой из шести граней равна 1/6.
Для этого примера функция распределения будет выглядеть следующим образом.

Примечание : Для построения графика использованы идеи из статьи про ступенчатый график .
СОВЕТ : Подробнее о Функции распределения см. статью Функция распределения и плотность вероятности в MS EXCEL .
Математическое ожидание и дисперсия
В файле примера на листе График приведен расчет математического ожидания по формуле =(a+b)/2.
Дисперсия (квадрат стандартного отклонения) для равномерного дискретного распределения может быть вычислена по формуле =((b-a+1)^2-1)/12.
Генерация случайных значений
Случайные числа, имеющие равномерное дискретное распределение , можно сгенерировать с помощью функции MS EXCEL СЛУЧМЕЖДУ() . В функции можно задать нижнюю и верхнюю границу интервала [a; b]. Функцией будут сгенерированы целые случайные числа из указанного интервала (см. файл примера лист Генерация ).

Обратите внимание, что массив случайных чисел, сгенерированных с помощью функции СЛУЧМЕЖДУ() , автоматически обновится при пересчете листа. Пересчет листа в MS EXCEL производится при вводе нового значения в ячейку или при нажатии клавиши F9 .
Примечание : Подробнее про функцию СЛУЧМЕЖДУ() см. статью Функция СЛУЧМЕЖДУ() - Случайное число из заданного интервала в MS EXCEL .
Чтобы сгенерировать нецелые случайные числа, например из интервала [1,1; 2,5], необходимо записать формулу = СЛУЧМЕЖДУ(1,1*10;2,5*10)/10 .
Множитель 10 отражает тот факт, что нецелые случайные числа будут сгенерированы с точностью до десятых. Если интервал задан с точностью до сотых, то нужно использовать множитель 100.
Как видно из формулы - границы интервала также могут быть нецелыми числами. Хотя, конечно, можно сгенерировать числа, например, с точностью до сотых с помощью формулы = СЛУЧМЕЖДУ(10*100;20*100)/100 . В этом случае случайные числа будут принадлежать интервалу [10;20] и иметь вид 10,37; 16,08; 15,43 и т.д.
Оценка среднего и стандартного отклонения
Сгенерируем 50 чисел (выборку) и разместим их в диапазоне B17:B66 . Нижнюю и верхнюю границу интервала возьмем [1; 6] и разместим их в диапазоне B5:B6 .
Математическое ожидание этого распределения =(B5+B6)/2 и равно (6+1)/2=3,5. Стандартное отклонение распределения равно = КОРЕНЬ(((B6-B5+1)^2-1)/12) =1,71
Чтобы оценить математическое ожидание воспользуемся значениями выборки =СУММ(B17:B66)/СЧЁТ(B17:B66) .
Оценить стандартное отклонение можно с помощью формулы =СТАНДОТКЛОН.В(B17:B66) в MS EXCEL 2010 или = СТАНДОТКЛОН(B17:B66) для более ранних версий.
Чтобы оценить дисперсию используйте формулу =ДИСП.В(B17:B66) в MS EXCEL 2010 или =ДИСП(B17:B66) для более ранних версий. Также можно использовать формулу =СТАНДОТКЛОН.В(B17:B66)^2 .
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье Распределения случайной величины в MS EXCEL .
Пример №1 . По данным таблицы 2 постройте ряды распределения по 40 коммерческим банкам РФ. По полученным рядам распределения определите: прибыль в среднем на один коммерческий банк, кредитные вложения в среднем на один коммерческий банк, модальное и медианное значение прибыли; квартили, децили, размах вариации, среднее линейное отклонение, среднее квадратическое отклонение, коэффициент вариации.
Решение:
В разделе «Вид статистического ряда» выбираем Дискретный ряд . Нажимаем Вставить из Excel . Количество групп: по формуле Стэрджесса
Принципы построения статистических группировок
Ряд наблюдений, упорядоченных по возрастанию, называется вариационным рядом. Группировочным признаком называется признак, по которому производится разбивка совокупности на отдельные группы. Его называют основанием группировки. В основание группировки могут быть положены как количественные, так и качественные признаки.После определения основания группировки следует решить вопрос о количестве групп, на которые надо разбить исследуемую совокупность.
При использовании персональных компьютеров для обработки статистических данных группировка единиц объекта производится с помощью стандартных процедур.
Одна из таких процедур основана на использовании формулы Стерджесса для определения оптимального числа групп:
Длину частичных интервалов вычисляют как h=(xmax-xmin)/k
Затем подсчитывают числа попаданий наблюдений в эти интервалы, которые принимают за частоты ni. Малочисленные частоты, значения которых меньше 5 (ni < 5), следует объединить. в этом случае надо объединить и соответствующие интервалы.
В качестве новых значений вариант берут середины интервалов xi=(ci-1+ci)/2.
Пример №3 . В результате 5%-ной собственно-случайной выборки получено следующее распределение изделий по содержанию влаги. Рассчитайте: 1) средний процент влажности; 2) показатели, характеризующие вариацию влажности.
Решение получено с помощью калькулятора: Пример №1
Пример. По результатам выборочного наблюдения (выборка А приложение):
а) составьте вариационный ряд;
б) вычислите относительные частоты и накопленные относительные частоты;
в) постройте полигон;
г) составьте эмпирическую функцию распределения;
д) постройте график эмпирической функции распределения;
е) вычислите числовые характеристики: среднее арифметическое, дисперсию, среднее квадратическое отклонение. Решение
- На основе структурной группировки построить вариационный частотный и кумулятивный ряды распределения, используя равные закрытые интервалы, приняв число групп равным 6. Результаты представить в виде таблицы и изобразить графически.
- Проанализировать вариационный ряд распределения, вычислив:
- среднее арифметическое значение признака;
- моду, медиану, 1-ый квартиль, 1-ый и 9-тый дециль;
- среднее квадратичное отклонение;
- коэффициент вариации.
- Сделать выводы.
Требуется: ранжировать ряд, построить интервальный ряд распределения, вычислить среднее значение, колеблемость среднего значения, моду и медиану для ранжированного и интервального рядов.
На основе исходных данных построить дискретный вариационный ряд; представить его в виде статистической таблицы и статистических графиков. 2). На основе исходных данных построить интервальный вариационный ряд с равными интервалами. Число интервалов выбрать самостоятельно и объяснить этот выбор. Представить полученный вариационный ряд в виде статистической таблицы и статистических графиков. Указать виды примененных таблиц и графиков.
- Построить ранжированный вариационный ряд;
- Найти максимальный и минимальный члены ряда;
- Найти размах вариации и количество оптимальных промежутков для построения интервального ряда. Найти длину промежутка интервального ряда;
- Построить интервальный ряд. Найти частоты попадания элементов выборки в составленные промежутки. Найти средние точки каждого промежутка;
- Построить гистограмму и полигон частот. Сравнить с нормальным распределением (аналитически и графически);
- Построить график эмпирической функции распределения;
- Рассчитать выборочные числовые характеристики: выборочное среднее и центральный выборочный момент;
- Рассчитать приближенные значения среднего квадратического отклонения, асимметрии и эксцесса (пользуясь пакетом анализа MS Excel). Сравнить приближенные расчетные значения с точными (рассчитанные по формулам MS Excel);
- Сравнить выборочные графические характеристики с соответствующими теоретическими.
Задача. Следующие данные представляют собой затраты времени клиентов на заключение договоров. Построить интервальный вариационный ряд представленных данных, гистограмму, найти несмещенную оценку математического ожидания, смещенную и несмещенную оценку дисперсии.
Пример . По данным таблицы 2:
1) Постройте ряды распределения по 40 коммерческим банкам РФ:
А) по величине прибыли;
Б) по величине кредитных вложений.
2) По полученным рядам распределения определите:
А) прибыль в среднем на один коммерческий банк;
Б) кредитные вложения в среднем на один коммерческий банк;
В) модальное и медианное значение прибыли; квартили, децили;
Г) модальное и медианное значение кредитных вложений.
3) По полученным в п. 1 рядам распределения рассчитайте:
а) размах вариации;
б) среднее линейное отклонение;
в) среднее квадратическое отклонение;
г) коэффициент вариации.
Необходимые расчеты оформите в табличной форме. Результаты проанализируйте. Сделайте выводы.
Постройте графики полученных рядов распределения. Графически определите моду и медиану.
Решение:
Для построения группировка с равными интервалами воспользуемся сервисом Группировка статистических данных.
Читайте также: