
При копировании текста из pdf в word непонятные символы
Обновлено: 04.07.2024
Согласно распространённым представлениям, извлечение текста из PDF не должно быть такой уж сложной задачей. Ведь вот он, текст, прямо у нас перед глазами, и люди постоянно и с большим успехом воспринимают содержимое PDF. Откуда взяться трудностям в автоматическом извлечении текста?
Оказывается, точно так же, как работа с именами людей сложна для алгоритмов из-за множества пограничных случаев и неправильных предположений, так и работа с PDF сложна из-за чрезвычайной гибкости PDF-формата.
Основная проблема в том, что PDF не предполагался как формат для ввода данных – его разрабатывали, как канал вывода, дающий возможность тонкой подстройки вида итогового документа.
По сути, формат PDF состоит из потока инструкций, описывающих, как создаётся изображение на странице. В частности, текстовые данные хранятся не в виде параграфов – или даже слов – а в виде символов, нарисованных на определённых местах в странице. В итоге при преобразовании текста или документа Word в PDF большая часть семантики контента теряется. Вся внутренняя структура текста превращается в аморфный суп из плавающих на странице символов.
Наполняя FilingDB, мы извлекли текстовые данные из десятков тысяч PDF-документов. В процессе мы наблюдали за тем, как оказались неверными абсолютно все наши предположения о структуре PDF-файлов. Наша миссия оказалась особенно трудной потому, что нам приходилось обрабатывать PDF-документы, приходящие от разных источников, с совершенно разными стилями, шрифтами и внешним видом.
Ниже описывается, какие особенности PDF-файлов делают сложной или даже невозможной задачу извлечения из них текста.
Защита от чтения PDF
Вы могли встречать PDF-файлы, запрещающие копировать из них текстовое содержимое. К примеру, вот, что выдаёт программа SumatraPDF при попытке скопировать текст из защищённого от копирования документа:

Интересно, что текст виден, но при этом программа для просмотра отказывается передавать выделенный текст в буфер обмена.
Это реализовано при помощи нескольких флагов с «разрешениями доступа», один из которых управляет разрешением на копирование. Важно понимать, что сам PDF-файл это делать не заставляет – его содержимое от этого не меняется, и задача по его реализации лежит полностью на программе для просмотра.
Естественно, это на самом деле не защищает от извлечения текста из PDF, поскольку любая достаточно продвинутая библиотека для работы с PDF позволит пользователю либо поменять эти флаги, либо проигнорировать их.
Символы за пределами страниц
Частенько в PDF можно встретить больше текстовых данных, чем те, что показаны на странице. Возьмём эту страницу из ежегодного отчёта Nestle за 2010-й.

К этой странице прикреплено больше текста, чем видно. В частности, в содержимом, связанном с нею, можно найти следующее:
KitKat отметила свой 75-й день рождения в 2010-м, но остаётся молодой и успевает за тенденциями, имея более 2,5 млн фанатов на Facebook. Её продукция продаётся в более чем 70 странах, а продажи хорошо растут в развитых странах и на развивающихся рынках, например, на Среднем Востоке, в Индии и России. Япония – второй по величине рынок компании.
Этот текст расположен вне границ страницы, поэтому большинство просмотрщиков PDF его не показывают. Однако данные там есть, и их можно извлечь программно.
Такое иногда бывает из-за принимаемых в последнюю минуту решений о замене или удалении текста в процессе утверждения.
Мелкие или невидимые символы
Иногда на странице PDF можно встретить очень маленькие или вообще невидимые символы. Вот, к примеру, страница из отчёта Nestle за 2012 год.

На странице имеется мелкий белый текст на белом фоне, где написано следующее:
Wyeth Nutrition logo Identity Guidance to markets
Vevey Octobre 2012 RCC/CI&D
Иногда это делается для повышения доступности, с теми же целями, которым служит тег alt в HTML.
Слишком много пробелов
Иногда в PDF между буквами слов вставлены дополнительные пробелы. Это наверняка сделано в целях кернинга (изменения интервала между символами).
К примеру, в отчёте Hikma Pharma от 2013 года есть такой текст:

Если его скопировать, получим:
В общем случае сложно решить задачу реконструкции исходного текста. Наиболее успешно у нас работает подход с применением оптического распознавания символов, OCR.
Недостаточно пробелов
Иногда в PDF не хватает пробелов, или они заменены другим символом.
Пример 1: следующая выдержка сделана из ежегодного отчёта SEB за 2017.

Пример 2: отчёт Eurobank от 2013 содержит следующее:

И снова лучше всего оказалось использовать для таких страниц OCR.
Встроенные шрифты
PDF работает со шрифтами, мягко говоря, сложным образом. Чтобы понять, как хранятся в PDF текстовые данные, сначала нам нужно разобраться в глифах, названиях глифов и шрифтах.
- Глиф – это набор инструкций, описывающих, как изображать символ или букву.
- Название глифа – это название, связанное с этим глифом. К примеру, «торговая марка» для ™ или «а» для глифа «а».
- Шрифт – это список глифов и связанных с ними названий. К примеру, в большинстве шрифтов есть глиф, который большинство людей распознает, как букву «а», при этом в разных шрифтах содержатся различные способы изображения этой буквы.
К примеру, PDF может содержать код символа 116, который он сопоставляет с названием глифа «t», который, в свою очередь, сопоставлен глифу, описывающему, как выводить на экран символ «t».

Большинство PDF используют стандартную кодировку символов. Кодировка символов – это набор правил, присваивающих смысл самим кодам символов. К примеру:
- В ASCII и Unicode для обозначения буквы «t»используется код символа 116.
- Unicode сопоставляет код символа 9786 глифу «белый смайлик», который выводится, как ☺, а в ASCII такой код не определён.

Хотя для человека итоговый результат ничем не отличается, машина запутается из-за таких кодов символов. Если коды символов не соответствуют стандартной кодировке, программным способом почти невозможно понять, что обозначают коды 1, 2 или 3.
Зачем же в PDF нужно включать нестандартные шрифты и кодировку?
- Одна причина – усложнить извлечение текста.
- Вторая – использование субшрифтов. В большинстве шрифтов есть глифы для очень большого числа кодовых символов, при этом в PDF может использоваться небольшое их подмножество. Для экономии места создатель PDF может обрезать все ненужные глифы и создать компактный субшрифт, который скорее всего будет использовать нестандартную кодировку.
Карта кодирования, которую вы только что сделали – та, что сопоставляет цифры 1 и 116 – называется в PDF-стандарте картой ToUnicode. В PDF-документах могут содержаться собственные карты ToUnicode, однако это не обязательно.
Распознавание слов и параграфов
Воссоздание параграфов и даже слов из аморфного символьного супа PDF-файлов – задача сложная.
PDF-документ содержит список символов на странице, а распознавать слова и параграфы должен потребитель. Люди от природы эффективно справляются с этим, поскольку чтение – навык распространённый.
Чаще всего используется алгоритм группировки, сравнивающий размеры, расположение и выравнивание символов, с целью определить, что является словом или параграфом.
У простейших реализаций таких алгоритмов сложность легко может достичь O(n²), из-за чего обработка плотно забитых страниц может проходить долго.
Порядок текста и параграфов
Распознавание текста и порядка параграфов – задача сложная по двум причинам.
Во-первых, иногда правильного ответа просто нет. Если у документов с обычным типографским набором с одной колонкой последовательность чтения выходит естественной, то у документов с более смелым расположением элементов определить её сложнее. К примеру, не совсем ясно, должна ли следующая вставка идти до, после или в середине статьи, рядом с которой она расположена:

Во-вторых, даже когда человеку ответ ясен, компьютеры определить точный порядок параграфов бывает очень сложно – даже с использованием ИИ. Возможно, это утверждение покажется вам чересчур смелым, но в некоторых случаях правильную последовательность параграфов можно определить, только понимая содержимое текста.
Рассмотрим данное расположение компонентов в два столбца, где описано приготовление овощного салата.

В западном мире разумно предположить, что чтение идёт слева направо и сверху вниз. Поэтому мы, не изучая содержимого текста, можем свести все варианты к двум: A B C D и A C B D.
Изучив содержание, поняв, о чём там говорится, и зная, что овощи моют перед нарезкой, мы можем понять, что правильным порядком будет A C B D. Алгоритмически это определить крайне сложно.
При этом «в большинстве случаев» работает подход, полагающийся на порядок хранения текста внутри PDF-документа. Обычно он соответствует порядку вставки текста во время создания. Когда большие отрезки текста содержат по многу параграфов, они обычно соответствуют тому порядку, который подразумевал их автор.
Встроенные изображения
Нередко часть содержимого документа (или весь документ) оказывается отсканированным изображением. В таких случаях в нём нет текстовых данных, и приходится прибегать к OCR.
К примеру, ежегодный отчёт Yell от 2011 года доступен только в виде скана:

Почему бы просто всё не распознать?
Хотя OCR может помочь с некоторыми описанными проблемами, у него тоже есть свои недочёты.
- Длительное время обработки. Запуск OCR на скане из PDF обычно отнимает на порядок больше времени (а то и ещё дольше), чем прямое извлечение текста из PDF.
- Сложности с нестандартными символами и глифами. Алгоритмам OCR сложно работать с новыми символами – смайликами, звёздочками, кружочками, квадратиками (в списках), надстрочными индексами, сложными математическими символами, и т.п.
- Нет подсказок о последовательности текста. Упорядочивать текст, извлекаемый из PDF-документа, легче, поскольку большую часть времени этот порядок соответствует порядку вставки текста в файл. При извлечении текста с изображений таких подсказок не будет.
Тестирование
Пока что мы ещё не упоминали о том, насколько сложно подтвердить, что текст был извлечён правильно или ожидаемо. Мы обнаружили, что лучше всего проводить обширный набор тестов, изучающих как базовые метрики (длину текста, длину страницы, соотношение количества слов и пробелов), так и более сложные (процент английских слов, процент нераспознанных слов, процент чисел), а также следить за предупреждениями типа подозрительных или неожиданных символов.
Что мы можем посоветовать для извлечения текста из PDF? Прежде всего убедиться, что у текста нет более удобного источника.
Если интересующие вас данные идут только в формате PDF, тогда важно понимать, что эта проблема кажется простой лишь на первый взгляд, а решить её со 100% точностью может и не получиться.

Я не уверен, что следующие советы помогут для всех решить проблему, но частичное решение ее все же возможно.
Давайте сразу отбросим отсканированые и нераспознанные PDF документы, из которых просто невозможно скопировать текст. Это равносильно попытке копирования текста из обычной фотографии, сделанной на ваш смартфон. В таком случае текст нужно распознать специальной программой, вроде ABBYY FineReader.
Наша книга (тестовая) полностью поддерживает копирование текста и изображений. Но при попытке перенести такой текст в Microsoft Office Word, можно видеть такие нечитабельные символы как на скриншоте сверху статьи.
Способ 1 (длинный).
Вся проблема в шрифтах и системе кодирования. PDF документ, с которого производится копирование имеет встроенные шрифты. И если такие шрифты отсутствуют в вашей операционной системе, то вы увидите такие кракозябры .
Чтобы можно было видеть нормальные буквы, при переносе текста нужно устанавливать соответствующие шрифты .
Чтобы узнать какие именно нужно инсталлировать на компьютер шрифты, нужно открыть наш PDF документ поддерживаемой программой (на примере PDF-XChange Viewer ). Далее идем в «Файл» → «Свойства документа» (можно нажать сочетание клавиш Ctrl + D).
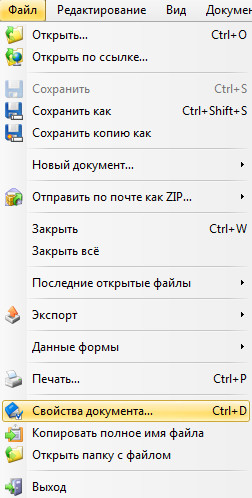
Далее нажимаем на параметр «Шрифты» и видим список шрифтов, установленных в документе. Их и нужно найти в интернете и установить на компьютер. Для этого на загруженном шрифте два раза нажимаем левой клавишей мыши (то есть, открываем его), а потом нажимаем на кнопку «Установить» .
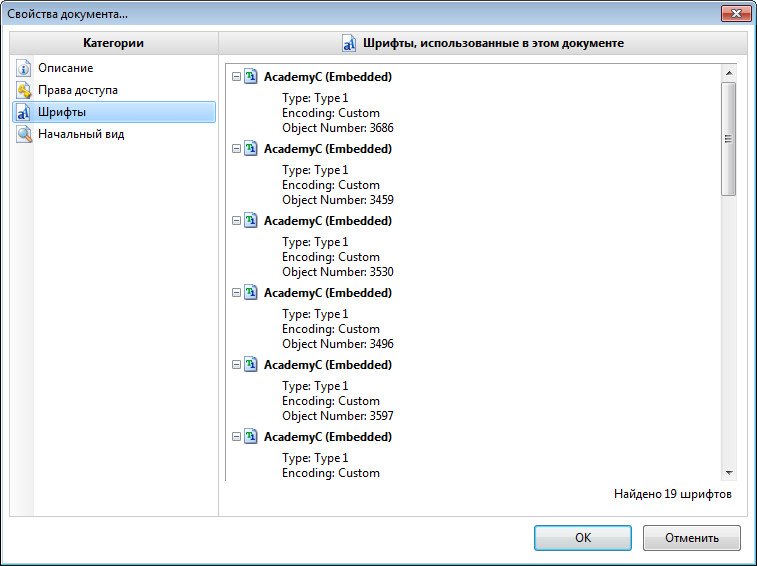
Далее копируем и вставляем текст из PDF документа, выделяем его в Microsoft Office Word (или в другом офисном редакторе, который у вас установлен) и выбираем из списка недавно установленный шрифт. Все должно быть нормально. Снизу на скриншоте видно, что я намеренно применил нужный шрифт только на одно предложение, другую часть текста прочитать невозможно.

Способ 2 (быстро и удобно).
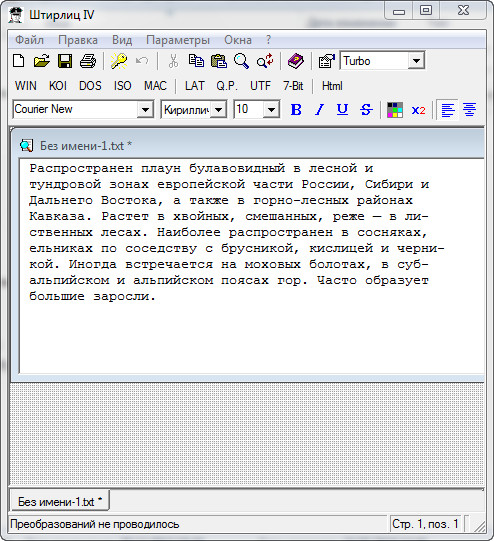
Другой, более правильный и простой вариант – это использование программы (или плагина к редактору Notepad ++ ), которая называется Shtirlitz. Программа старая, давно не обновлялась, однако работает отлично. Прямо на лету выполняется вставка нормального текста. Никаких шрифтов не требуется. После копирования текста с данной программы и дальнейшей вставкой его в редактор Microsoft Office Word, все буквы и символы будут читаться и с использованием любого шрифта. Первый вариант не позволяет изменить шрифт. То есть, всегда, и на каждом компьютере нужно будет инсталлировать нужные шрифты для чтения только определенного документа. А если таких документов несколько сотен? Поэтому желательно воспользоваться этой программой для декодирования.
Способ 3 (онлайн).
Кто не хочет использовать программу Shtirlitz или она не работает, может использовать следующие онлайн сервисы для перекодирования (отдельные сервисы имеют ограничения по объему текста).
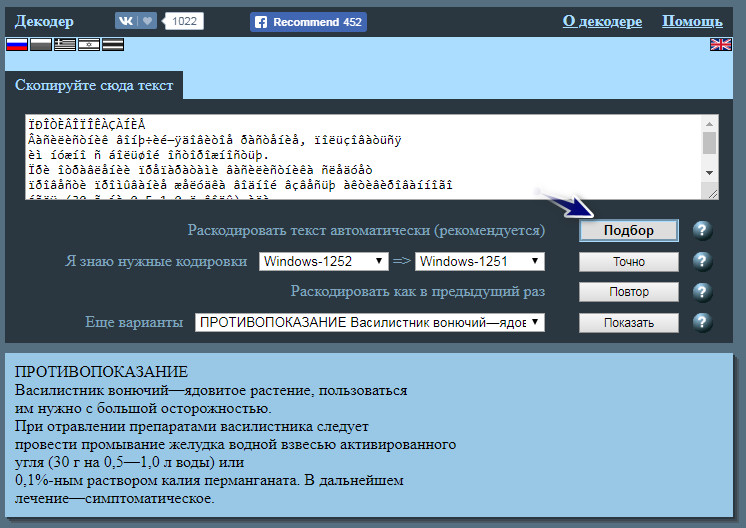
Там можно видеть окно, где написано «Скопируйте сюда текст». Вставляем наш непонятный текст и нажимаем на кнопку «Подбор». Такой способ будет правильно использовать если вам неизвестна система кодирования. Декодер попытается подобрать ее автоматически. Если вы знаете исходное кодирование своей кракозябры, то можете смело нажимать кнопку «Точно», указав перед этим кодирование, напротив текста «Я знаю нужные кодировки».
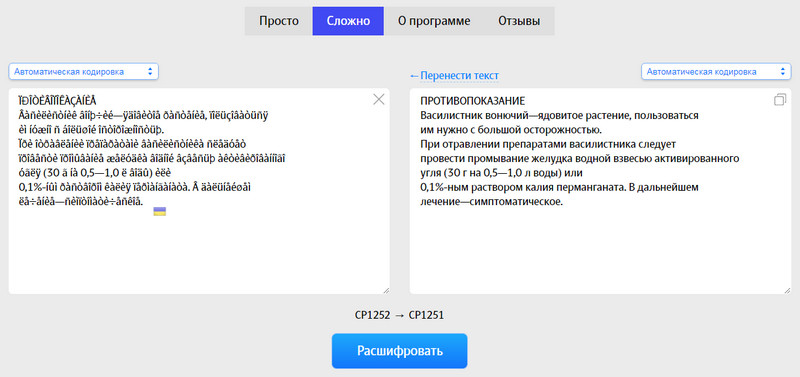
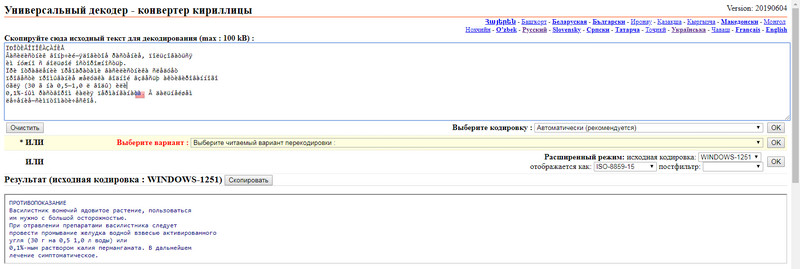
Есть также два режима: автоматический и режим эксперта. Во втором можно указывать исходное и конечное кодирование. Рекомендуется автоматический режим. После того как вставили текст, напротив слов «Выберите кодировку : » , нужно выбрать «Автоматически (рекомендуется)» и нажать на кнопку «Ок».
Все три сервиса отлично работали на моей тестовой книге в формате PDF с кракозябрами.
Способ 4 (с помощью макросов для Microsoft Office Word ).
Еще один вариант для программы Microsoft Office Word. Никаких шрифтов ставить не нужно. Создаем макрос со следующим кодом:
Код 1: «Перекодирование 1252 в 1251»
Код 2: «Перекодирование 1252 в 1251 (с учетом русской буквы Ё)»
Выделяем вставленный текст с иероглифами. Тогда запускаем макрос на выполнение и получаем нормальный текст, который можно спокойно редактировать, изменять шрифты и т.д.
Для добавления готового макроса в Word делаем следующее:
Открываем редактор и переходим в «Вид».

Там находим кнопку «Макросы» и нажимаем на нее.
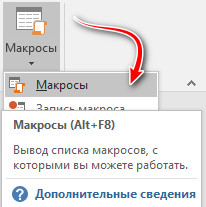
Даем для макроса имя (любое, оно будет автоматически изменено при полном копировании кода выше).
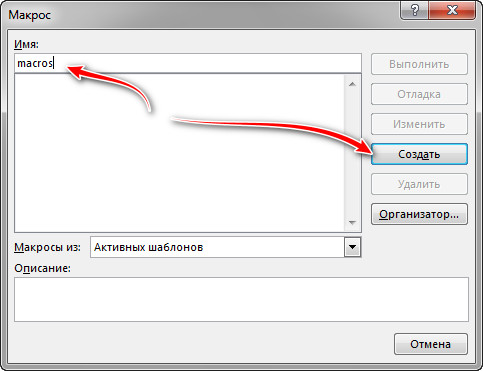
Откроется окно в котором можно заметить название нашего макроса. При желании можете оставить свое имя. Но лучше, чтобы не было ошибок, полностью заменить весь код на готовый (код смотрите сверху).
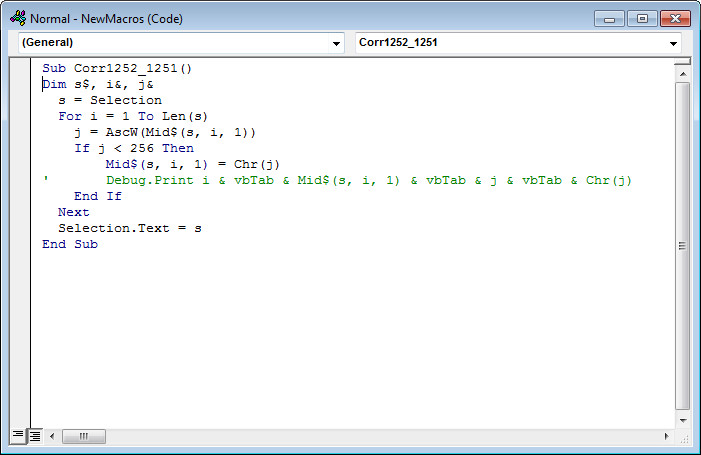
Как видно, макрос начинается так:
Sub названиемакроса()
дальше идет код макроса
End Sub
Название макроса может любым, но не цифры и не должно быть пробелов. Может быть так: декодирование_кракозябр_с_ё. Но не может быть так: декодирование кракозябр с ё.
То есть, для нас нужно заменить для нашего созданного пустого макроса весь текст с кодом, который показан выше.
После того как заменили, нужно закрыть окно редактирования макросов (можно нажать на иконку сохранения, хотя изменения сохраняются автоматически). Далее выделяем наш иероглифический текст, открываем макросы, выбираем из списка (если их у вас несколько) нужный и нажимаем на кнопку «Выполнить».

Ваш текст должен стать читабельным.

Как ни крути, но это не полное решение ситуации. Поиск после данных действий в самом PDF документе работать не будет. Проблема остается. Кто может подсказать ее решение, просьба писать в комментариях.
Адекватного решения на просторах интернета я не нашел.
Пост для таких же как и я.
Решение оказалось простым это программа Adobe Acrobat.
Инструкция: 1) Открываем приложение Adobe Acrobat
2) В левом столбике нажимаем "Мой компьютер" -> "рабочий стол"
3) Выбираем нужный нам файл ( у меня он был на рабочем столе)
4) В правом столбике (правой части экрана) ищем иконку в виде листика со стрелочкой в кружке, при наведение будет написано "Экспорт PDF" нажимаем
5) Далее нажимаем "Экспорт" и выбираем папку куда сохранить файл.

Студенческое общество
793 поста 3.4K подписчик
@moderator, а можно добавить возможность менять сообщество также, как редактируем теги? Народ частенько промахивается, а сделать ничего нельзя каждый раз.
Автору: совет дельный, конечно, но PDF формат был разработан Adobe, которая, собственно, и делает Acrobat специально для работы с этим форматом, поэтому совсем неудивительно, что без Акробата у вас были проблемы с копированием из файла, особенно если файл был специально так сделан, например.
Да ты просто гений!
Спасибо, полезная информация, хоть и немного не своевременно, но может кому-то еще это реально поможет.
Где ты был 5 лет назад, но спасибо
В Чечне учения местных сил обороны, без флагов РФ

Нет работы.
Сегодня ехал в троллейбусе и подслушал разговор. Трудно было не подслушать, перешли уже на повышенные.
Женщине лет пятидесяти, видимо, не хватало чуть-чуть на проезд (начало разговора не слышал). Она начала объяснять кондуктору, что у неё сложная жизненная ситуация, муж потерял паспорт и уже ооочень долго не может устроиться на работу. Еще бы, кто ж его без паспорта возьмёт. А восстановить паспорт - это пять тыщ, сейчас нет таких денег, и когда они появятся - неизвестно, ведь на работу же не берут. Даже жрут (цитата) что попало.
Кондуктор же парировала, что эти пять тысяч можно заработать всегда, неважно, есть документы или нет.
Ой, что тут началось. и на "приведите пример, возьмут ли его куда-то кондуктором?", я вмешался. Мне сейчас нужен упаковщик. Вот прям срочно! На тестовую партию. нужно упаковать три тысячи отправлений. А у меня нет такой штатной единицы. Просто взять из большой коробки и переложить в маленькие. Я предложил её супругу 20 000 за десять дней за такую работу. Женщина обрадовалась и согласилась.
Должна была сегодня позвонить)))
Как вы поняли, сижу пакую)))
С днём рождения Юра!

Мигранты


Идеальное название
Прометей дарит огонь людям

Мать солдата
Это было в январе 2010го. Я служил срочную службу в Бурятии, в городе Улан-Удэ. На станции Дивизионной. Была суббота и нас, как водится, повели в баню. Баня от части находилась в паре километров, недалеко от станции. По пути движения я упросил сержанта отпустить меня в магазин.
Стою я в очереди и замечаю, что рядом стоит женщина и смотрит на меня. Прям как в упор. Тут она подошла, крепко обняла меня и сказала, что я очень похож на ее сына. Он тоже служит и она очень по нему скучает. Она попросила подождать ее на выходе. А когда вышла, вручила мне полный пакет пряников, шоколада и пару бутылок лимонада.
Трогательный момент был. Было немного неудобно. Я поблагодарил, она ещё раз обняла меня со словами -"иди, хорошо служи". Мать солдата.
В Орле арестовали человека национальности, которую нельзя называть
В Орле арестовали человека неопределённой национальности, за то, что тот силой затащил в машину 14-летнюю русскую девочку и надругался над ней.
Девочка чудом смогла убежать и сообщить обо всем родителям.
О национальности насильника не известно, кроме того что его зовут Аслаханов Ислам и он уроженец Чечни.
Может русский, может украинец, или норвежец. Тут сложно понять, нужен антрополог.
Возбуждено уголовное дело по ч. 3 ст. 132 УК РФ. Лицо неустановленной национальности помещено в СИЗО.
P. S. Данный пост не является дубликатом. 96%-ая схожесть с этим постом - только лишь из-за картинки.
Избивавший русского срочника в армии, боец ММА избежал наказания
Избивавший срочника в армии, боец ММА избежал наказания. Сейчас он с компанией гоняет по улицам со скоростью 200 км в час
Итак, нередко при копировании с какого-нибудь сайта мы сталкиваемся с ситуацией, когда фон у этого текста остается таким же, каким он был на этом самом сайте. И фон этот не убирается простым снятием выделения или заливки текста.

Многие знают, а кто не знает, узнает в этом предложении, что это решается при помощи копирования текста сначала в "Блокнот", а уже из "Блокнота" в Word. Но можно же обойтись и средствами самого продукта мелкомягких. Причем способы эти не должны вызвать особой сложности.
Итак, способ первый и, возможно, самый оптимальный. Заключается в том, что после копирования следует не просто "вставить" текст, а использовать "специальную вставку". Для этого нужно выбрать ее из подменю кнопки "Вставить", нажав на стрелочку под оной. Или же, как видно на скрине, любителям горячих клавиш вместо Ctrl+V для вставки можно просто нажать Ctrl+Alt+V.

Выпадает окошко, где выбираем "вставить как неформатированный текст". В итоге текст вставится без фона, но возможны мелкие недочеты вроде курсива.

Вроде просто, и на этом можно остановиться. Но есть же и другие варианты решения, которые могут показаться более интересными и простыми.
Итак, вариант второй. У нас есть текст с фоном. Выделяем его. Ищем на ленте/панели инструментов кнопку "Очистить формат" (кнопка с буквами Aa и ластиком). Жмем на нее:

- и параметры текста сбрасываются на знакомый Calibri, 11 пт, с выравниванием по левому краю, но уже без злосчастного фона. Нам остается только выставить нужные выравнивание, шрифт и размер. В принципе, данный способ идентичен по результату способу с "Блокнотом", но занимает меньше времени.

Способ третий, "формат по образцу". В "Ворде" имеется одноименный инструмент, и работает он следующим образом:
Выделяем какой-нибудь "беспроблемный" кусок текста (в другом месте документа), тот, который без фона. Нажимаем на кнопку "формат по образцу":

Кнопка "фиксируется". Далее просто выделяем абзац с фоном, и фон пропадает (возможно появление курсива). После чего кнопка "отжимается". Чтобы провернуть операцию с несколькими кусками текста - нужно щелкать по кнопке "формат по образцу" двойным ЛКМ: тогда она "зафиксируется", пока мы ее сами не отключим.
Ну и последний на сегодня, способ номер четыре. Убирает фон, "насылает" других "проклятий", зато незначительных. Выделяем текст с фоном. Обращаем взор на панель инструментов, а точнее на блок "Стили". Нам нужно просто-напросто выбрать любой понравившийся стиль без "лишних наворотов". Я обычно выбираю серый курсив:

После применения стиля останется лишь сменить цвет текста (в зависимости от выбранного стиля), убрать курсив и выбрать нужный шрифт. "Лишних" операций хватает, но от проблемы избавиться помогает.
Первый мой серьезный пост, поэтому, может, и страшновато смотрится. Но надеюсь я кому-то помог сделать "офисную" жизнь немного проще :)
Здравствуйте. Решил зарегистрироваться, чтобы поблагодарить. Спасибо , большое, Вы мне сэкономили часа два бить по клавишам, чтобы избавиться от фона перепечатыванием . Всего Вам доброго. С уважением, Сергей.
Самый простой способ это перед вставкой в Word текст скопировать в блокнот или любой другой текстовый редактор а из блокнота уже в Word.
Таким образом из текста уберется информация о html разметке и в Word он уже вставится нормальным.
Спасибо тебе, добрый человек !! Огромное.
Дай тебе бог здоровья, добрый человек)
Еще способ. Вставляем текст как обычно -- простым Ctrl+V. Появляется летучая менюшка вставки (обычно сразу в конце выделения). В ней несколько вариантов, последний -- вставить только текст (все параметры форматирования обнуляются).
А вообще рекомендую стилями пользоваться. Позволяют быстро переформатировать весь документ в пару кликов, если вдруг возникает необходимость.
Храни тебя господь, ты спас мою курсовую ))
Чел, щас 3 часа ночи, а мне еще нужно написать реферат по психологии. Просто огромное тебе спасибо, что бы я без тебя делал? Ах да, не спал. Спасибо еще раз
"хитрости жизни". то чему учат везде
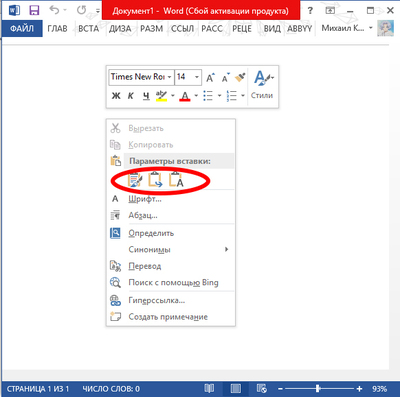
Способ нулевой, ещё более оптимальный:
Кликаем правой кнопкой мыши куда вставить, далее выбираем один из вариантов. Слева направо: 1) сохраняет всё форматирование, 2) убирает фон, цвет, гарнитуру, размер шрифта (делает, как уже есть в документе), оставляет выделения курсивом и жирным, 3) убирает всё форматирование, оставляет голый текст.
Я только один способ знаю, пользоваться бесплатным аналогом - ОpenОffice.
По мне, так намного удобнее программа
"Как можно спасти людей без пролития крови?"
Опять еду со смены, никого не трогаю.
Вечер, закат заливает салон красными лучами. На остановке в салон заходит усталый люд с работы.
И среди них находиться яркая личность. На этот раз индивиду мужского пола не понравился водитель автобуса.
Как и почему не видел, потому что сидел около задней двери и втыкал в мобилу. И тут слышу уже натуральный ор на передней площадке. Водила и чувачок ругаются через окошко для продажи билетов. На скорости около 70 км. Салон от эмоций уже начинает ощутимо шатать. Пассажиры смотрят на это действие и молчат.
"Ну почему именно я?" (Брюс Виллис. "Крепкий орешек-2"). Начинаю успокаивать оратора через весь салон. Благо натренированный на службе голос это позволяет. Половина дела сделана -- от водилы этот клоун оторвался.
В наш содержательный диалог вслушиваются люди и водила. Мой оппонент предлагает выйти на улицу и продолжить нас диспут путем боксирования. Нет проблем.
Автобус остановился около обочины, до следующей остановки около 2 км.
Чувак вылетает и начинает выть в снежную пустыню: " Я вышел и жду тебя. ".
Кричу водителю:" Закрывай дверь и поехали. Этот пешком дойдет".
Двери с шипением закрываются, машина плавно трогается. Любитель приключений остается стоять как черный столб на снежной простыне.
Читайте также: