
Программы для распознавания текста для linux
Обновлено: 08.07.2024
В наши дни почти все (например, фотографии, музыка, видео) стали цифровыми, и это имеет смысл, поскольку цифровым контентом можно удобно управлять. Так как же текстовые документы могут остаться позади? Благодаря достижениям в Оптическое распознавание символов (OCR) техники, теперь стало проще, чем когда-либо оцифровывать печатные или рукописные тексты. Для этого вам нужны действительно хорошие приложения для распознавания текста, и именно об этом и рассказывается в этой статье. Это программное обеспечение может либо получать источник со сканирующих устройств, либо вы можете вводить свои собственные изображения или файлы PDF для преобразования в редактируемый текст. Заинтригованный? Ну, тогда давайте не будем биться вокруг, и перейдем к 8 лучшим программам для распознавания текста, которые вы должны использовать в 2020 году.
Лучшее программное обеспечение для распознавания текста для Windows, MacOS и Linux
1. ABBYY FineReader
Когда дело доходит до оптического распознавания символов, вряд ли найдется что-то, что даже близко подходит к ABBYY FineReader. ABBYY FineReader позволяет загружать текст со всех видов изображений на одном дыхании.
Несмотря на широкий набор функций, ABBYY FineReader очень прост в использовании. Он может извлекать текст практически из всех популярных форматы изображений, такие как PNG, JPG, BMP и TIFF. И это еще не все. ABBYY FineReader также может извлекать текст из файлов PDF и DJVU. После загрузки исходного файла или изображения (которое предпочтительно должно иметь разрешение не менее 300 т / д для оптимального сканирования) программа анализирует его и автоматически определяет различные разделы файла, имеющие извлекаемый текст. Вы можете либо извлечь весь текст, либо выбрать только некоторые конкретные разделы. После этого все, что вам нужно сделать, это использовать опцию Сохранить, чтобы выбрать формат вывода, а ABBYY FineReader позаботится обо всем остальном. Поддерживаются многочисленные форматы вывода, такие как TXT, PDF, RTF и даже EPUB.
Выводимый текст является полностью редактируемым, и текст даже из самых содержательных документов (например, имеющих несколько столбцов и сложные макеты) извлекается безупречно. Другие функции включают в себя обширная языковая поддержка, многочисленные стили шрифтов / размеры и инструменты коррекции изображения для файлов, полученных из сканеров и камер.
Сказав все это, то, что отличает ABBYY FineReader от остальных программ, это его почти идеальная точность. С новым обновлением Finereader 15, теперь программное обеспечение использует AI для улучшения распознавания символов, AI особенно используется при извлечении текстов из документов, написанных на японском, корейском и китайском языках. Таким образом, если вы хотите получить абсолютно лучшее программное обеспечение для оптического распознавания текста с расширенными функциями, расширенным форматом ввода-вывода и поддержкой обработки, выберите ABBYY FineReader.
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются с $ 199, доступна 30-дневная бесплатная пробная версия
2. Тессеракт
Тессеракт, пожалуй, самое мощное и передовое программное обеспечение для распознавания текста в этом списке, и я скажу вам почему. Прежде всего, немного истории. Он был разработан HP в 1994 году, но вскоре компания выпустила его под лицензией Apache для разработки с открытым исходным кодом. В 2006 году Google принял проект и спонсировал разработчиков для работы над Tesseract. Перенесемся вперед, и Tesseract стал самым мощным Механизм распознавания текста, который использует Deep Learning для извлечения текстов из изображений (BMP, PNG, JPEG, TIFF и т. Д.) И файлов PDF., Существует множество онлайн-сервисов, которые используют OCR API Tesseract для распознавания и преобразования больших массивов изображений и файлов PDF. И самое приятное, что он доступен для всех основных операционных систем, включая Windows, macOS и Linux. Не говоря уже о том, что в отличие от ABBYY и Adobe, Tesseract совершенно бесплатно и вы можете использовать его для преобразования тысяч изображений в текст, не платя ни копейки.
Доступность платформы: Интернет, Windows, macOS и Linux
Цена: Свободно
3. OmniPage Ultimate от Kofax
Кроме того, OmniPage Ultimate использует свою запатентованную технологию для определения макета изображений и автоматически поворачивает документ в правильной ориентации. Кроме того, вы можете запланировать большие объемы файлов PDF для пакетной обработки, используя инструмент автоматизации. Не говоря уже о том, что может обнаружить более 120 языков и может обрабатывать изображения и документы соответственно. Что касается форматов выходного файла, он поддерживает PDF, DOC, EXCL, PPT, CDR, HTML, ePUB и другие. Учитывая все вышесказанное, OmniPage Ultimate представляется надежным решением для оптического распознавания текста для корпоративных пользователей.
Доступность платформы: Windows
Цена: Бесплатная пробная версия на 15 дней, платная версия за 183 $
4. Readiris
В поисках чрезвычайно мощного программного обеспечения для оптического распознавания символов, которое имеет множество функций, но не требует ли много усилий, чтобы начать работу? Посмотрите на Readiris, так как это может быть именно то, что вам нужно.
Приложение профессионального уровня Readiris имеет обширный набор функций, который в значительной степени идентичен ранее обсуждавшемуся ABBYY FineReader. Readiris поддерживает несколько форматов изображений: от BMP до PNG и от PCX до TIFF. Кроме этого, PDF и DJVU файлы могут быть обработаны так же хорошо. Изображения могут быть получены из устройств сканера, и приложение также позволяет вам задавать пользовательские параметры обработки для исходных файлов / изображений, такие как сглаживание и регулировка DPI, перед их анализом. Хотя Readiris может обрабатывать изображения с более низким разрешением очень хорошо, оптимальное разрешение должно быть не менее 300 dpi.
Как только анализ завершен, Readiris определяет текстовые разделы (или зоны), и текст может быть извлекается из определенных зон или всего файла, Извлеченный текст доступен для редактирования и поиска и может быть сохранен в различных форматах, таких как PDF, DOCX, TXT, CSV и HTM.
Более того, облачная функция сохранения в Readiris Pro позволяет напрямую сохранять извлеченный текст в различные облачные службы хранения, такие как Dropbox, OneDrive, Google Drive и другие. Существует также множество полезных функций редактирования / обработки текста, и даже штрих-коды можно сканировать.
В общем, вы должны использовать Readiris, если хотите надежные функции извлечения / редактирования текста в простом в использовании пакете, в комплекте с обширной поддержкой формата ввода / вывода. Однако Readiris немного колеблется, когда дело доходит до обработки документов со сложными макетами, такими как несколько столбцов, таблиц и т. Д.
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются с $ 49, доступна 10-дневная бесплатная пробная версия
5. Adobe Acrobat Pro DC
Доступность платформы: Windows и macOS
Цена: Бесплатная пробная версия на 7 дней, платная версия начинается с $ 12.99 / месяц
6. Microsoft OneNote
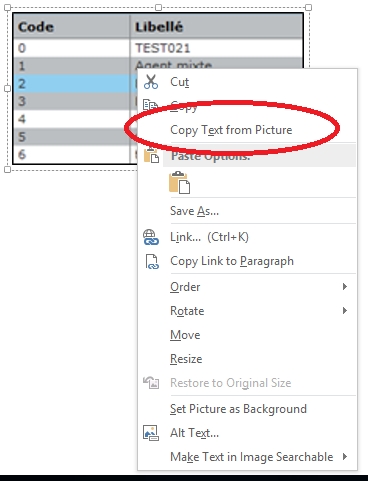
Использование OneNote для извлечения текста из изображений смехотворно просто. Если вы используете настольное приложение, все, что вам нужно сделать, это использовать Вставить Возможность добавить изображение в любой из блокнотов или разделов. Как только это будет сделано, просто щелкните правой кнопкой мыши на изображение и выберите Копировать текст с картинки вариант. Весь текстовый контент с изображения будет скопирован в буфер обмена и может быть вставлен (и, следовательно, отредактирован) куда угодно, согласно требованию. Будь то PNG, JPG, BMP или TIFF, OneNote поддерживает практически все основные форматы изображений.
Однако возможности OneNote по извлечению текста весьма ограничены, и он не может работать с изображениями, имеющими сложные макеты текстового содержимого, такие как таблицы и подразделы. Так что это то, что вы должны иметь в виду.
Доступность платформы: Windows и macOS
Цена: Свободно
7. Amazon Textract
В 2019 году Amazon запустила свое программное обеспечение для оптического распознавания текста Textract, которое имеет модель машинного обучения и обучено использованию миллионов документов. Он может автоматически определять печатный текст из изображений (JPG и PNG) и файлов PDF и отображать его в цифровом виде с почти идеальной точностью. Хотя Textract в основном доступен в веб-браузере, вы также можете загрузить его и использовать службу через командную строку. Кроме того, Textract кажется довольно мощным программным обеспечением для распознавания текста. он может извлекать не только тексты, но также таблицы, поля, числа и ключевые значения. Мне особенно нравится извлечение таблиц из отсканированных изображений, так как это может упростить процесс редактирования текста. Textract хранит данные таблицы, используя предопределенную схему, где он извлекает все данные в виде строк и столбцов.
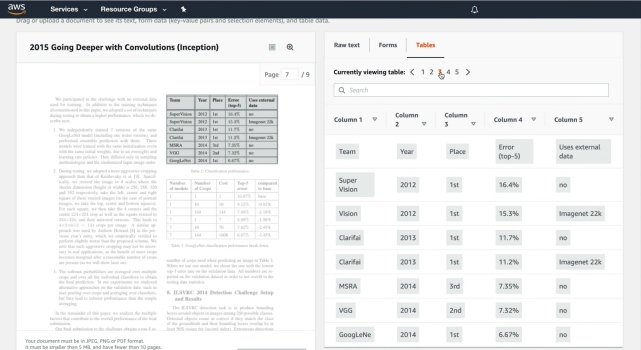
Сказав все это, Amazon Textract предлагает свои услуги как для частных лиц, так и для предприятий. Как домашний пользователь, вы можете зарегистрировать бесплатную учетную запись уровня AWS и использовать эту услугу, но имейте в виду, что вы можете конвертировать только 1000 страниц в месяц. В целом, Amazon Textract делает отличное программное обеспечение для распознавания текста и может использоваться как обычными пользователями, так и предприятиями.
Доступность платформы: Интернет, Windows, macOS, Linux
Цена: Бесплатно в течение первых 3 месяцев, Премиум план начинается с $ 1,50 за 1000 страниц
8. Документы Google
Теперь вы можете редактировать весь текст, искать его, редактировать и, наконец, сохранять файл в нескольких форматах, которые изначально поддерживаются Документами Google. В моем тестировании это работало довольно хорошо для файлов PDF которые были созданы с помощью текстовых процессоров. Однако имейте в виду, что он не может конвертировать изображения или отсканированные изображения в виде файлов PDF. Итак, если вам нужен бесплатный и простой инструмент OCR для преобразования PDF-файлов в редактируемый текст, Google Docs предоставит вам все необходимое.
Доступность платформы: Интернет, Windows, macOS, Linux
Цена: Свободно
Все готово для преобразования изображений и PDF-файлов в текст?
Оцифровка печатного и рукописного текстового содержимого чрезвычайно полезна, поскольку делает хранение, редактирование и обмен чрезвычайно легкими. И вышеупомянутое программное обеспечение для распознавания текста делает быструю работу по выполнению именно этого, независимо от того, насколько сложны или сложны ваши потребности в извлечении текста. Нужны функции извлечения текста профессионального уровня с лучшими инструментами пост-обработки? Перейти на ABBYY FineReader, Tesseract или OmniPage. Вы бы предпочли более простое программное обеспечение для оптического распознавания текста, которое только делает основы? Используйте OneNote или Google Docs. Попробуйте их, и посмотрите, как они работают для вас. Знаете ли вы о каком-либо другом программном обеспечении OCR, которое могло бы быть включено в приведенный выше список? Кричите в комментариях ниже.
Одна из областей, в которых отставание Linux от Windows считается значительным и трудно преодолимым, является оптическое распознавание текста. Так как необходимость распознать текст время от времени появляется практически у каждого пользователя компьютера, потребность в программном обеспечении такого рода надо признать актуальной проблемой. В связи с этим недавно я решил потратить немного времени и провести сравнительное тестирование имеющихся систем оптического распознавания текста (OCR), доступных в Linux. Для полноты картины рассматривались как локально устанавливаемые программы, так и онлайновые сервисы.
Методика тестирования
ABBYY FineReader for Linux
В процессе установки программа запросила ключ, после чего благополучно активировалась. Программа имеет множество ключей командной строки, позволяющих гибко настроить параметры распознавания. Я использовал команду вида:
В целом здесь все понятно. Ключи -if и -of задают распознаваемый файл и файл, в который записывается результат работы программы. С помощью -f задается формат вывода. Необходимо отметить, что если в тексте имеются слова на иностранном языке, необходимо обязательно задать его вторым после ключа -rl. В противном случае программа будет пытаться распознать все на русском.
ABBYY Fine Reader Online
Для полноты картины необходимо рассмотреть еще один продукт от ABBYY - онлайновый сервис ABBYY Fine Reader Online . Ранее он позволял после несложной регистрации распознавать бесплатно до 10 страниц в день, теперь же бесплатно можно распознать только три страницы сразу после регистрации, после чего необходимо платить. Минимальный пакет стоит 3$ за 20 страниц. Сервис поддерживает большое количество языков и форматов файлов.
Cuneiform
На второе место по известности среди систем OCR можно смело поставить программу cuniform. Первоначально программа CuneiForm была разработана компанией Cognitive Technologies как коммерческий продукт. CuneiForm поставлялся с некоторыми моделями сканеров. Однако после нескольких лет перерыва разработки, 12 декабря 2007 года анонсировано открытие исходных текстов программы, которое состоялось 2 апреля 2008 года.
По умолчанию в Ubuntu 10.10 доступна достаточно старая версия 0.7. Однако после добавления соответствующего PPA можно стать обладателем версии 1.0. Для Cuneiform написаны два графических интерфейса - YAGF и Cuneiform-Qt .
Для тестирования я использовал версию 1.0.0, установленную из вышеуказанного PPA. Распознавание производилось с помощью команды вида:
В руководстве cuneiform приводится опция --fax, которая включает оптимизацию работы программы для распознавания документов, переданных с помощью факса, однако при ее использовании результат получается хуже, поэтому я не привел его в таблице.
GOCR - это свободная кроссплатформенная система оптического распознавания текстов, работающая из командной строки. Программа пока находится в ранней стадии разработки, поэтому имеет ряд серьезных недостатков (например, распознает только одноколоночный текст). Кроме того, изучение man-страницы показало, что опций, позволяющих задать язык распознавания, программа не имеет, что подтвердилось экспериментом - русский текст gocr пытается распознать как английский. Естественно, в таблицу я данную программу включать не стал.
Ocrad
Tesseract
Tesseract - свободная программа для распознавания текстов, разрабатывавшаяся Hewlett-Packard с середины 1980-х по середину 1990-х. Затем ее разработка была заморожена на 10 лет. В августе 2006 г Google купил её и открыл исходные тексты под лицензией Apache 2.0 для продолжения разработки. В настоящий момент программа уже работает с UTF-8, поддержка языков (включая русский с версии 3.0) осуществляется с помощью дополнительных модулей.
Так как в репозиториях Ubuntu присутствует 2-я версия программы, а русский язык поддерживается только с релиза 3.0.0, программу я собирал из исходных текстов по инструкциям, найденным в сети.
Итак, скачиваем здесь архив с исходными текстами (в моем случае это tesseract-3.00.tar.gz, но с выходом новых версий название может быть другим), распаковываем его и переходим в директорию с исходными кодами.
Для корректной работы tesseract необходим пакет leptonica - ПО с открытым исходным кодом, необходимое для приложений, работающих и анализирующих изображения. Устанавливаем его:
Кроме того, для работы tesseract необходимо установить следующие пакеты: libpng12-dev, libjpeg62-dev, libtiff4-dev, zlib1g-dev, libtool build-essential. Устанавливаем и их, а затем из директории с исходным кодом начинаем конфигурирование и сборку программы:
При подтверждении опций необходимо изменить имя пакета (номер 2) на tesseract-ocr.

Все остальные опции принимаем по умолчанию. В результате будет установлен tesseract 3.0, а также собран deb-пакет, поэтому в следующий раз программу можно будет устанавливать обычным способом с помощью GDebi.
С первого раза программа у меня не собралась, пожаловавшись на отсутствие каталога /usr/local/share/tessdata. После того, как я создал его вручную, процесс завершился благополучно.
Теперь необходимо скачать с сайта программы пакет поддержки русского языка (rus.traineddata.gz), распаковать его и скопировать содержимое архива (а это должен быть один файл rus.traineddata) в директорию /usr/local/share/tessdata/.
Изображения перед распознаванием необходимо прнобразовать в формат tiff.
Для распознавания я использовал команду вида:
Если программа не заработала и возникают ошибки, связанные с отсутствием необходимых библиотек или правами доступа, выполните следующие команды:
Теперь все должно работать.
Для tesseract имеется графический интерфейс tesseract-gui , который тоже надо собирать из исходного кода. У меня он запустился, но распознавать текст почему-то не захотел. Еще есть система OCRopus , которая может использовать движок tesseract. Собственно поэтому я ее отдельно рассматривать не стал.
SILVERCODERS OCR Server
Данная программа представляет собой мощную коммерческую серверную систему распознавания, предназначенную для предприятий и поддерживающую 189 языков, среди них и русский. Она разработана специально для интегрирования в корпоративные системы документооборота. Триальной версии для свободного скачивания нет, поэтому опробовать мне эту систему не удалось.
Free OCR
Free OCR - бесплатный онлайн-сервис для оптического распознавания текста, использующий движок tesseract. Размер загружаемого изображения ограничен 2 Мб. Поддерживаются форматы JPG, GIF, TIFF BMP и PDF (только первая страница, в скором времени обещают поддержку первых 10 страниц). Также, существует лимит на 10 изображений в час.
Сервис распознает множество языков - русский, украинский, английский, немецкий, французский, турецкий, большинство восточноевропейских языков.
img2txt
img2txt - многоязычный онлайн-сервис для оптического распознавания текста. Поддерживаются форматы JPG, PNG, TIFF с размером файла до 2 Мб. В будущем обещают поддержку PDF и DJVU. На Википедии сервис обозначен как коммерческий и проприетарный, однако на самом сайте никакой информации об типе лицензии и используемом движке нет. Мои три тестовые страницы распознались без проблем. Никакой оплаты или хотя бы регистрации не просили.
OnlineOCR
NewOCR
NewOCR - бесплатный OCR сервис, поддерживающий 29 языков распознавания, включая русский. Позволяет загружать файлы в форматах JPEG, PNG, GIF, BMP, многостраничный TIFF размером до 5 Мб, а также многостраничные PDF размером до 20 Мб. Поддерживается многоколоночное форматирование текста.
Кроме того, необходимо отметить, что на рынке имеется еще одна коммерческая система распознавания от компании vividata , однако стоимость этой программы составляет $2400 (!) плюс по $100 за каждый дополнительный язык, отдельная плата, например, за модуль вывода в PDF ($1200) и т.д., поэтому я даже не стал заморачиваться с ее установкой. Ко всему прочему программа видимо очень давно не обновлялась (файлы в установочном архива датируются 2001 годом) и сами разработчики сомневаются в том, что она заработает на современных дистрибутивах. Поэтому тестировать vividata я не стал.
Также я решил включить в таблицу Google Docs, так как эта служба в настоящее время также позволяет производить распознавание русского текста. По имеющимся данным она использует tessract, однако нельзя исключить, что в своем сервисе Google использует какие-нибудь дополнительные наработки, поэтому интересно сравнить ее с остальными.
Результаты сравнительного тестирования систем оптического распознавания
| Программа (сервис) | Точность распознавания, % | ||
| Образец 1 | Образец 2 | Образец 3 | |
| FineReader for Linux | 100% | 100% | 87% |
| FineReader Online | 100% | 100% | 94% |
| Cuneiform 1.0.0 | 94% | 94% | 17% |
| Tesseract 3.0.0 | 97% | 98% | 5% |
| Free OCR | 96% | 93% | 61% |
| img2txt | 96% | 94% | 24% |
| NewOCR | 94% | 94% | 41% |
| Google Docs | 93% | 96% | 58% |
Выводы
Результаты, приведенные в таблице, показывают, что при хорошем качестве распознаваемого материала все участвовавшие в тестировании программы обеспечивают высокое качество распознавания, причем снижение разрешения с 300 до 200 dpi практически не влияет на результат. В то же время при распознавании некачественного материала ABBYY Fine Reader явно вырывается вперед, что неудивительно, учитывая ресурсы, задействованные в разработке данного приложения. Однако в целом можно отметить, что широко распространенное суждение о том, что для Linux нет хороших систем оптического распознавания текста, сегодня уже не выдерживает критики.
Для нерегулярного домашнего применения подойдет любая из представленных в обзоре бесплатных систем, а для организации, деятельность которой связана с частым использованием систем распознавания, особенно если дело касается факсов и другого материала посредственного качества, стоит подумать о покупке Fine Reader, тем более, что открытый API позволяет интегрировать его в любую корпоративную систему документооборота.

img2txt - онлайн сервис по распознаванию текстов из отсканированных изображений. Сервис работает с английским, русским и украинским языками. Стоит отметить, что загружаемое изображение не должно содержать таблицы, изображения, диаграммы, а также превышать 4 Мб. Кроме того, оно должно быть представлено в одном из следующих форматов: jpg, jpeg, png. подробнее.


SimpleOCR

SimpleOCR - бесплатное приложение для распознавания текста. Умеет распознавать рукописный текст. Поддерживаемые языки: английский, голландский, французский. Умеет читать изображения со сканера. подробнее.
Free Online OCR

Free Online OCR - бесплатный онлайн сервис для распознавания текста. К достоинствам аналога ABBYY FineReader можно отнести хорошее качество распознавания текста; неограниченное количество загрузок; работа с 70 языками, в том числе русским; распознавание текста, содержащего сразу несколько языков; отсутствие регистрации. Free Online OCR предоставляет возможность выделять, а также разворачивать часть документа, предназначенную для дальнейшей обработки. Распознает следующие форматы: JPEG, JFIF, PNG, GIF, BMP, PBM, PGM, PPM и PCX. Работает с такими форматами сжатия как Unix compress, bzip2, bzip и gzip; со следующими мультистраничными документами: TIFF, PDF и DjVu. Распознает файлы DOCX и ODT с изображениями. Работает с ZIP архивами. Результат может быть получен в виде простого текста (TXT), документа Microsoft Word (DOC) и PDF-файла Adobe Acrobat. подробнее.
В статье проведено сравнительное тестирование имеющихся систем оптического распознавания текста (OCR), доступных в Linux. Для полноты картины рассматривались как локально устанавливаемые программы, так и онлайновые сервисы. Вывод автора: При хорошем качестве распознаваемого материала все участвовавшие в тестировании программы обеспечивают высокое качество распознавания, причем снижение разрешения с 300 до 200 dpi практически не влияет на результат. В целом можно отметить, что широко распространенное суждение о том, что для Linux нет хороших систем оптического распознавания текста, сегодня уже не выдерживает критики.

Да просто взять несколько страниц из книг, газет и журналов и глянуть, у кого будет самый близкий к оригиналу результат. Распознавание на цветном фоне тоже неплохо бы потестировать, это как раз в журналах часто встречается.


> Хз. Вроде, в статье приводилась ссылка на онлайн-сервис с этим движком. Может там?
FineReader и FineReader Engine - разные вещи
>> Надо еще вытаскивать контекст.
ну для этого не оцр программа нужна
Да ладно. Хотя если подходить формально, то да. Но ведь у нас цель - получить не только текст. А форматирование, отделить колонтитулы, определить, где ссылки и тд.- а это уже контекст
У ABBYY очерь различные лицензии. Выбирайте любую

>Минимальный пакет стоит 3$ за 20 страниц
в век компьютерных технологий за 20 вонючих страниц 3 бакса, шош вы жадные такие, за 3 бакса можно студента нанять шоб распознал :)
вобще статейка неплохая, всю не читал но в одном месте собрать инфу о разных продуктах это хорошо

Да просто взять несколько страниц из книг, газет и журналов и глянуть, у кого будет самый близкий к оригиналу результат. Распознавание на цветном фоне тоже неплохо бы потестировать, это как раз в журналах часто встречается.
Можно, но нужно очень чётко выработать критерий близости. Ясно, что жирный шрифт должен быть жирным, шрифт без засечек и наклонный должны выделяться, но как только мы начинаем выбирать гарнитуру, уже становится сложно. Дальше, там наверняка есть разные рамочки, горизонтальные и вертикальные линии, рисунки, возможно, даже графики. Как оценивать точность их воспроизведения? В какой формат интегрировать результат (чтобы он поддерживал всё это форматирование) --- ODF?
В общем, я не утверждаю, что подобный тест можно составить, но дело это хлопотное и, вполне возможно, бестолковое.

FineReader и FineReader Engine - разные вещи
Да, видимо так. Ну тогда точно хз.

Ну что, ocrodjvu теперь нужен? :)
Сергей Полтавский серьёзно пилит этот кьюниформ и Qt-морду для него quneiform:
Кто плачет, что что-то не так и недостаточно хорошо - вперёд, с песней, ему помогать.
Да, deb-ы этого дела можно взять у notesalexp. Оно, конечно, иногда выпадает в кору неожиданно (я про гуй), но уже работает.
Добавлю, что у gocr достаточно хороший уровень распознавания англ. текста. Код же гокра ужасен - чтобы добавить поддержку нового языка надо фактически переписать полностью программу
Интересная статья с большим количеством полезной информации.

Это вообще Линус сказал
Да? Я вот кроме Cuneiform давно ничего интересного не видел. Ну да, проект Ocrad опять зашевелился, но где он в сводной таблице тестирования? А в итоге выиграл FineReader, который и не свободный вовсе. Поэтому мой выбор - Cuneiform.
Сомневаюсь. Если он действительно работает, то там должен быть такой алгоритм распознавания, что стоимость программы будет не меньше десятка-другого килобаксов.

> Закопать и забыть место погребения. ональный зонд со счетчиком сводит на нет все достижения ABBYY.
Очень интересно где они в Linux сумели свой хитрый, необнуляемый счетчик сделать. А то напрашивается diff /home до установки и после с последующим patch-ем как оно переполнится. Даже если они замастырили сервис, который что-то куда-то пихает с правами root, дык все равно на раз вычисляется. Это вам не виндовсь, хотя и там можно.
Кстати, там в тексте третьего образца резкость ни к чёрту. После экспорта из JPEG в PBM получается тот ещё раритет - сам не могу прочитать что написано.
Дело даже не в том работает или нет, а в том что цена ошибки в формуле намного выше, чем в печатном тексте. Потому что печатный текст информационно сильно избыточен и обычно можно восстановить текст даже после серьезных опечаток. Чего не скажешь про формулы.
Пробовал. Работает. Стоит 180 долларов за установку на два компьютера. Ограничение: кириллицу не распознаёт. Но мне и не нужно.
Справедливости ради, восстановить текст после ошибки распознавания в цифре весьма трудно. Поэтому довод несостоятелен.
InftyReader сохраняет в формате LaTeX, поэтому внести исправления не составляет труда.
Очистить ты можешь счетчик. Только зачем тебе это надо?
Процесс верификации данных сложнее
>Ну, нашли с чем сравнивать. , а . довольно молод.
Это не аргумент :)
Основная масса работы по качеству - соотв. обучение.
и к версиям ПО (читаем - молодости / старости) оно имеет, прямо скажем, небольшое отношение.
Так что, если распознает коряво или хорошо - с возрастом системы данный фактор будет меняться незначительно.

ну так я ж не против. я просто привел соответствие его фразы с русской реальностью )))
Патенты - самые главные палки в колеса свободных OCR.

>В целом можно отметить, что широко распространенное суждение о том, что для Linux нет хороших систем оптического распознавания текста, сегодня уже не выдерживает критики.
Не надо в этой области петь про патенты.
Как не надо: в области распознавания изображений вообще работа - как хождение по минному полю: куда ни плюнь, все огорожено патентами.
Ну, шрифты, как правило, большей частью стандартные везде применяются. Распознавать готический шрифт не так уж часто нужно. :)
А рамочки, рисунки и графики распознавалка должна отрабатывать. Хотя бы как изображения.
Формат - можно odf, можно тот же docx (хотя лучше не надо, вспоминая как ОО с ним работает).
HTML, на худой конец (хотя это уже из области извращений).
Ну так что же ты медлишь с приведением примера патента, огораживающего качество распознавания?
Интересная статья с большим количеством полезной информации.
Погугли, подобных патентов полным-полно.
> Очистить ты можешь счетчик. Только зачем тебе это надо?
Ну типа на случай проверок всяких, одно дело если 100% пиратка и совсем другое, если где-то какой-то счетчик иногда правится. Возможно даже как бы и не нарочно путем бэкапа.
Доказать подобное нарушение не очень просто, хотя и можно, если чисто по объемам прикинуть. Смысл возиться со счетчиком может иметься у госпредприятия, если не дают денег на нормальную версию, а обрабатывать большой массив документов нужно. У остальных при таких объемах работы найдутся и деньги.
Вообще, смысл подобных ограничений от Abbyy в том, что у них есть очень дорогие продукты для автоматизации работы. FineReader Engine и Recognition Server и они всячески препятствуют тому, чтобы обычные версии FR могли быть использованы для автоматической обработки больших массивов. У виндовой GUI версии кажется нет ограничения на количество распознаваемых страниц, но и автоматически с ней не очень-то поработаешь даже с помощью разных утилит GUI-автоматизации.
Да с цифрами тоже сложно, я забыл об этом. Можно считать цифры в документе частным случаем формулы и примером куда больших проблем при распознавании формул.
InftyReader сохраняет в формате LaTeX, поэтому внести исправления не составляет труда.
Читайте также: