
Python excel форматирование ячейки
Обновлено: 06.07.2024
Excel supports three different types of conditional formatting: builtins, standard and custom. Builtins combine specific rules with predefined styles. Standard conditional formats combine specific rules with custom formatting. In additional it is possible to define custom formulae for applying custom formats using differential styles.
The syntax for the different rules varies so much that it is not possible for openpyxl to know whether a rule makes sense or not.
The basic syntax for creating a formatting rule is:
Because the signatures for some rules can be quite verbose there are also some convenience factories for creating them.
Builtin formats¶
- ColorScale
- IconSet
- DataBar
ColorScale¶
You can have color scales with 2 or 3 colors. 2 color scales produce a gradient from one color to another; 3 color scales use an additional color for 2 gradients.
The full syntax for creating a ColorScale rule is:
There is a convenience function for creating ColorScale rules
IconSet¶
Choose from the following set of icons: ‘3Arrows’, ‘3ArrowsGray’, ‘3Flags’, ‘3TrafficLights1’, ‘3TrafficLights2’, ‘3Signs’, ‘3Symbols’, ‘3Symbols2’, ‘4Arrows’, ‘4ArrowsGray’, ‘4RedToBlack’, ‘4Rating’, ‘4TrafficLights’, ‘5Arrows’, ‘5ArrowsGray’, ‘5Rating’, ‘5Quarters’
The full syntax for creating an IconSet rule is:
There is a convenience function for creating IconSet rules:
DataBar¶
Currently, openpyxl supports the DataBars as defined in the original specification. Borders and directions were added in a later extension.
The full syntax for creating a DataBar rule is:
There is a convenience function for creating DataBar rules:
Standard conditional formats¶
- Average
- Percent
- Unique or duplicate
- Value
- Rank
Formatting Entire Rows¶
Sometimes you want to apply a conditional format to more than one cell, say a row of cells which contain a particular value.
We want to higlight the rows where the developer is Microsoft. We do this by creating an expression rule and using a formula to identify which rows contain software developed by Microsoft.
The formula uses an absolute reference to the column referred to, B in this case; but a relative row number, in this case 1 to the range over which the format is applied. It can be tricky to get this right but the rule can be adjusted even after it has been added to the worksheet’s condidtional format collection.
В сегодняшней статье я хотел бы, как можно подробнее, рассмотреть интеграцию приложений Python и MS Excel. Данные вопрос может возникнуть, например, при создании какой-либо системы онлайн отчетности, которая должна выгружать результаты в общепринятый формат ну или какие-либо другие задачи. Также в статье я покажу и обратную интеграцию, т.е. как использовать функцию написанную на python в Excel, что также может быть полезно для автоматизации отчетов.
Работаем с файлами MS Excel на Python
Для работы с Excel файлами из Python мне известны 2 варианта:
Использование библиотек
Итак, первый метод довольно простой и хорошо описан. Например, есть отличная статья для описания работы c xlrd, xlwt, xlutils. Поэтому в данном материале я приведу небольшой кусок кода с их использованием.
Для начала загрузим нужные библиотеки и откроем файл xls на чтение и выберем
нужный лист с данными:
Теперь давайте посмотрим, как считать значения из нужных ячеек:
Как видно чтение данных не составляет труда. Теперь запишем их в другой файл. Для этого создам новый excel файл с новой рабочей книгой:
Запишем в новый файл полученные ранее данные и сохраним изменения:
Из примера выше видно, что библиотека xlrd отвечает за чтение данных, а xlwt — за запись, поэтому нет возможности внести изменения в уже созданную книгу без ее копирования в новую. Кроме этого указанные библиотеки работают только с файлами формата xls (Excel 2003) и у них нет поддержки нового формата xlsx (Excel 2007 и выше).
Чтобы успешно работать с форматом xlsx, понадобится библиотека openpyxl. Для демонстрации ее работы проделаем действия, которые были показаны для предыдущих библиотек.
Для начала загрузим библиотеку и выберем нужную книгу и рабочий лист:
Как видно из вышеприведенного листинга сделать это не сложно. Теперь посмотрим как можно считать данные:
Отличие от прошлых библиотек в том, что openpyxl дает возможность отображаться к ячейкам и последовательностям через их имена, что довольно удобно и понятно при чтении программы.
Теперь посмотрим как нам произвести запись и сохранить данные:
Из примера видно, что запись, тоже производится довольно легко. Кроме того, в коде выше, можно заметить, что openpyxl кроме имен ячеек может работать и с их индексами.
К недостаткам данной библиотеки можно отнести, то что, как и в предыдущем примере, нет возможности сохранить изменения без создания новой книги.
Как было показано выше, для более менее полноценной работы с excel файлами, в данном случае, нужно 4 библиотеки, и это не всегда удобно. Кроме этого, возможно нужен будет доступ к VBA (допустим для какой-либо последующей обработки) и с помощью этих библиотек его не получить.
Однако, работа с этими библиотеками достаточно проста и удобна для быстрого создания Excel файлов их форматирования, но если Вам надо больше возможностей, то следующий подпункт для Вас.
Работа с com-объектом
В своих отчетах я предпочитаю использовать второй способ, а именно использование файла Excel через com-объект с использованием библиотеки win32com. Его преимуществом, является то, что вы можете выполнять с файлом все операции, которые позволяет делать обычный Excel с использованием VBA.
Проиллюстрируем это на той же задаче, что и предыдущие примеры.
Для начала загрузим нужную библиотеку и создадим COM объект.
Теперь мы можем работать с помощью объекта Excel мы можем получить доступ ко всем возможностям VBA. Давайте, для начала, откроем любую книгу и выберем активный лист. Это можно сделать так:
Давайте получим значение первой ячейки и последовательности:
Как можно заметить, мы оперируем здесь функциями чистого VBA. Это очень удобно если у вас есть написанные макросы и вы хотите использовать их при работе с Python при минимальных затратах на переделку кода.
Посмотрим, как можно произвести запись полученных значений:
Из примера видно, что данные операции тоже довольно просто реализовываются. Кроме этого, можно заметить, что изменения мы сохранили в той же книге, которую открыли для чтения, что достаточно удобно.
Однако, внимательный читатель, обратит внимание на переменную i, которая инициализируется не 0, как принято python, а 1. Это связано с тем, что мы работаем с индексами ячеек как из VBA, а там нумерация начинается не с 0, а с 1.
На этом закончим разбор способов работы с excel файлами в python и перейдем к обратной задаче.
Вызываем функции Python из MS Excel
Может возникнуть такая ситуация, что у вас уже есть какой-либо функция, которая обрабатывает данные на python, и нужно перенести ее функциональность в Excel. Конечно же можно переписать ее на VBA, но зачем?
Для использования функций python в Excel есть прекрасная надстройка ExcelPython. С ее помощью вы сможете вызывать функции написанные на python прямо из Excel, правда придется еще написать небольшую обертку на VBA, и все это будет показано ниже.
Итак, предположим у нас есть функция, написанная на python, которой мы хотим воспользоваться:
На вход ей подается список, состоящий из списков, это одно из условий, которое должно выполняться для работы данной функции в Excel.
Сохраним функцию в файле plugin.py и положим его в ту же директорию, где будет лежать наш excel файл, с которым мы будем работать.
Теперь установим ExcelPython. Установка происходит через запуск exe-файла и не вызывает затруднений.
Когда все приготовления выполнены, открываем тестовый файл excel и вызовем редактор VBA (Alt+F11). Для работы с вышеуказанной надстройкой необходимо ее подключить, через Tools->References, как показано на рисунке:

Ну что же, теперь можно приступить к написанию функции-обертки для нашего Python-модуля plugin.py. Выглядеть она будет следующим образом:
Итак, что же происходит в данной функции?
Для начала, с помощью PyModule , мы подключаем нужный модуль. Для этого в качестве параметров ей передается имя модуля без расширения, и путь до папки в которой он находится. На выходе работы PyModule мы получаем объект для работы с модулем.
Затем, с помощью PyCall , вызываем нужную нам функцию из указанного модуля. В качестве параметров PyCall получает следующее:
- Объект модуля, полученный на предыдущем шаге
- Имя вызываемой функции
- Параметры, передаваемые функции (передаются в виде списка)
Теперь, чтобы убедиться в работоспособности нашей связки, вызовем нашу свежеиспеченую функцию на листе в Excel:

Как видно из рисунка все отработало правильно.
Надо отметить, что в данном материале используется старая версия ExcelPython, и на GitHub'e автора доступна новая версия.
Заключение
В качестве заключения, надо отметить, примеры в данной статье самые простые и для более глубоко изучения данных методов, я рекомендую обратиться к
документации по нужным пакетам.
Также хочу заметить, что указанные пакеты не являются единственными и в статье опущено рассмотрение, таких пакетов как xlsxwriter для генерации excel файлов или xlwings, который может работать с Excel файлами «на лету», а также же PyXLL, который выполняет аналогичные функции ExcelPython.
Кроме этого в статье я попытался несколько обобщить разборасанный по сети материал, т.к. такие вопросы часто фигурируют на форумах и думаю некоторым будет полезно иметь, такую «шпаргалку» под рукой.
Эта библиотека пригодится, если вы хотите читать и редактировать файлы .xlsx, xlsm, xltx и xltm.
Установите openpyxl using pip. Общие рекомендации по установке этой библиотеки — сделать это в виртуальной среде Python без системных библиотек. Вы можете использовать виртуальную среду для создания изолированных сред Python: она создает папку, содержащую все необходимые файлы, для использования библиотек, которые потребуются для Python.
Перейдите в директорию, в которой находится ваш проект, и повторно активируйте виртуальную среду venv. Затем перейдите к установке openpyxl с помощью pip, чтобы убедиться, что вы можете читать и записывать с ним файлы:
Теперь, когда вы установили openpyxl, вы можете начать загрузку данных. Но что именно это за данные? Например, в книге с данными, которые вы пытаетесь получить на Python, есть следующие листы:

На первый взгляд, с этими объектами Worksheet мало что можно сделать. Однако, можно извлекать значения из определенных ячеек на листе книги, используя квадратные скобки [], к которым нужно передавать точную ячейку, из которой вы хотите получить значение.
Обратите внимание, это похоже на выбор, получение и индексирование массивов NumPy и Pandas DataFrames, но это еще не все, что нужно сделать, чтобы получить значение. Нужно еще добавить значение атрибута:
Помимо value, есть и другие атрибуты, которые можно использовать для проверки ячейки, а именно row, column и coordinate:
Атрибут row вернет 2;
Добавление атрибута column к “С” даст вам «B»;
coordinate вернет «B2».
Вы также можете получить значения ячеек с помощью функции cell (). Передайте аргументы row и column, добавьте значения к этим аргументам, которые соответствуют значениям ячейки, которые вы хотите получить, и, конечно же, не забудьте добавить атрибут value:
Обратите внимание: если вы не укажете значение атрибута value, вы получите <Cell Sheet3.B1>, который ничего не говорит о значении, которое содержится в этой конкретной ячейке.
Вы используете цикл с помощью функции range (), чтобы помочь вам вывести значения строк, которые имеют значения в столбце 2. Если эти конкретные ячейки пусты, вы получите None.
Более того, существуют специальные функции, которые вы можете вызвать, чтобы получить другие значения, например get_column_letter () и column_index_from_string.
В двух функциях уже более или менее указано, что вы можете получить, используя их. Но лучше всего сделать их явными: пока вы можете получить букву прежнего столбца, можно сделать обратное или получить индекс столбца, перебирая букву за буквой. Как это работает:
Вы уже получили значения для строк, которые имеют значения в определенном столбце, но что нужно сделать, если нужно вывести строки файла, не сосредотачиваясь только на одном столбце?
Конечно, использовать другой цикл.
Обратите внимание, что выбор области очень похож на выбор, получение и индексирование списка и элементы NumPy, где вы также используете квадратные скобки и двоеточие чтобы указать область, из которой вы хотите получить значения. Кроме того, вышеприведенный цикл также хорошо использует атрибуты ячейки!
Чтобы визуализировать описанное выше, возможно, вы захотите проверить результат, который вернет вам завершенный цикл:
Наконец, есть некоторые атрибуты, которые вы можете использовать для проверки результата импорта, а именно max_row и max_column. Эти атрибуты, конечно, являются общими способами обеспечения правильной загрузки данных, но тем не менее в данном случае они могут и будут полезны.
Это все очень классно, но мы почти слышим, что вы сейчас думаете, что это ужасно трудный способ работать с файлами, особенно если нужно еще и управлять данными.
Должно быть что-то проще, не так ли? Всё так!
Openpyxl имеет поддержку Pandas DataFrames. И можно использовать функцию DataFrame () из пакета Pandas, чтобы поместить значения листа в DataFrame:
Затем вы можете начать управлять данными при помощи всех функций, которые есть в Pandas. Но помните, что вы находитесь в виртуальной среде, поэтому, если библиотека еще не подключена, вам нужно будет установить ее снова через pip.
Чтобы записать Pandas DataFrames обратно в файл Excel, можно использовать функцию dataframe_to_rows () из модуля utils:
Но это определенно не все! Библиотека openpyxl предлагает вам высокую гибкость в отношении того, как вы записываете свои данные в файлы Excel, изменяете стили ячеек или используете режим только для записи. Это делает ее одной из тех библиотек, которую вам точно необходимо знать, если вы часто работаете с электронными таблицами.
И не забудьте деактивировать виртуальную среду, когда закончите работу с данными!
Теперь давайте рассмотрим некоторые другие библиотеки, которые вы можете использовать для получения данных в электронной таблице на Python.
Готовы узнать больше?
Чтение и форматирование Excel файлов xlrd
Эта библиотека идеальна, если вы хотите читать данные и форматировать данные в файлах с расширением .xls или .xlsx.
Если вы не хотите рассматривать всю книгу, можно использовать такие функции, как sheet_by_name () или sheet_by_index (), чтобы извлекать листы, которые необходимо использовать в анализе.
Наконец, можно получить значения по определенным координатам, обозначенным индексами.
О том, как xlwt и xlutils, соотносятся с xlrd расскажем дальше.
Запись данных в Excel файл при помощи xlrd
Если нужно создать электронные таблицы, в которых есть данные, кроме библиотеки XlsxWriter можно использовать библиотеки xlwt. Xlwt идеально подходит для записи и форматирования данных в файлы с расширением .xls.
Когда вы вручную хотите записать в файл, это будет выглядеть так:
Если нужно записать данные в файл, то для минимизации ручного труда можно прибегнуть к циклу for. Это позволит немного автоматизировать процесс. Делаем скрипт, в котором создается книга, в которую добавляется лист. Далее указываем список со столбцами и со значениями, которые будут перенесены на рабочий лист.
Цикл for будет следить за тем, чтобы все значения попадали в файл: задаем, что с каждым элементом в диапазоне от 0 до 4 (5 не включено) мы собираемся производить действия. Будем заполнять значения строка за строкой. Для этого указываем row элемент, который будет “прыгать” в каждом цикле. А далее у нас следующий for цикл, который пройдется по столбцам листа. Задаем условие, что для каждой строки на листе смотрим на столбец и заполняем значение для каждого столбца в строке. Когда заполнили все столбцы строки значениями, переходим к следующей строке, пока не заполним все имеющиеся строки.
В качестве примера скриншот результирующего файла:

Теперь, когда вы видели, как xlrd и xlwt взаимодействуют вместе, пришло время посмотреть на библиотеку, которая тесно связана с этими двумя: xlutils.
Коллекция утилит xlutils
Эта библиотека в основном представляет собой набор утилит, для которых требуются как xlrd, так и xlwt. Включает в себя возможность копировать и изменять/фильтровать существующие файлы. Вообще говоря, оба этих случая подпадают теперь под openpyxl.
Использование pyexcel для чтения файлов .xls или .xlsx
Еще одна библиотека, которую можно использовать для чтения данных таблиц в Python — pyexcel. Это Python Wrapper, который предоставляет один API для чтения, обработки и записи данных в файлах .csv, .ods, .xls, .xlsx и .xlsm.
Чтобы получить данные в массиве, можно использовать функцию get_array (), которая содержится в пакете pyexcel:
Однако, если вы хотите вернуть в словарь двумерные массивы или, иными словами, получить все листы книги в одном словаре, стоит использовать функцию get_book_dict ().
Имейте в виду, что обе упомянутые структуры данных, массивы и словари вашей электронной таблицы, позволяют создавать DataFrames ваших данных с помощью pd.DataFrame (). Это упростит обработку ваших данных!
Наконец, вы можете просто получить записи с pyexcel благодаря функции get_records (). Просто передайте аргумент file_name функции и обратно получите список словарей:
Записи файлов при помощи pyexcel
Так же, как загрузить данные в массивы с помощью этого пакета, можно также легко экспортировать массивы обратно в электронную таблицу. Для этого используется функция save_as () с передачей массива и имени целевого файла в аргумент dest_file_name:
Обратите внимание: если указать разделитель, то можно добавить аргумент dest_delimiter и передать символ, который хотите использовать, в качестве разделителя между “”.
Однако, если у вас есть словарь, нужно будет использовать функцию save_book_as (). Передайте двумерный словарь в bookdict и укажите имя файла, и все ОК:
Помните, что когда используете код, который напечатан в фрагменте кода выше, порядок данных в словаре не будет сохранен!
Чтение и запись .csv файлов
Если вы все еще ищете библиотеки, которые позволяют загружать и записывать данные в CSV-файлы, кроме Pandas, рекомендуем библиотеку csv:
Обратите внимание, что NumPy имеет функцию genfromtxt (), которая позволяет загружать данные, содержащиеся в CSV-файлах в массивах, которые затем можно помещать в DataFrames.
Финальная проверка данных
Когда данные подготовлены, не забудьте последний шаг: проверьте правильность загрузки данных. Если вы поместили свои данные в DataFrame, вы можете легко и быстро проверить, был ли импорт успешным, выполнив следующие команды:
Note: Используйте DataCamp Pandas Cheat Sheet, когда вы планируете загружать файлы в виде Pandas DataFrames.
Если данные в массиве, вы можете проверить его, используя следующие атрибуты массива: shape, ndim, dtype и т.д.:
Поздравляем, теперь вы знаете, как читать файлы Excel в Python :) Но импорт данных — это только начало рабочего процесса в области данных. Когда у вас есть данные из электронных таблиц в вашей среде, вы можете сосредоточиться на том, что действительно важно: на анализе данных.
Если вы хотите глубже погрузиться в тему — знакомьтесь с PyXll, которая позволяет записывать функции в Python и вызывать их в Excel.
В сегодняшней статье я хотел бы, как можно подробнее, рассмотреть интеграцию приложений Python и MS Excel. Данные вопрос может возникнуть, например, при создании какой-либо системы онлайн отчетности, которая должна выгружать результаты в общепринятый формат ну или какие-либо другие задачи. Также в статье я покажу и обратную интеграцию, т.е. как использовать функцию написанную на python в Excel, что также может быть полезно для автоматизации отчетов.
Работаем с файлами MS Excel на Python
Для работы с Excel файлами из Python мне известны 2 варианта:
Использование библиотек
Итак, первый метод довольно простой и хорошо описан. Например, есть отличная статья для описания работы c xlrd, xlwt, xlutils. Поэтому в данном материале я приведу небольшой кусок кода с их использованием.
Для начала загрузим нужные библиотеки и откроем файл xls на чтение и выберем
нужный лист с данными:
Теперь давайте посмотрим, как считать значения из нужных ячеек:
Как видно чтение данных не составляет труда. Теперь запишем их в другой файл. Для этого создам новый excel файл с новой рабочей книгой:
Запишем в новый файл полученные ранее данные и сохраним изменения:
Из примера выше видно, что библиотека xlrd отвечает за чтение данных, а xlwt — за запись, поэтому нет возможности внести изменения в уже созданную книгу без ее копирования в новую. Кроме этого указанные библиотеки работают только с файлами формата xls (Excel 2003) и у них нет поддержки нового формата xlsx (Excel 2007 и выше).
Чтобы успешно работать с форматом xlsx, понадобится библиотека openpyxl. Для демонстрации ее работы проделаем действия, которые были показаны для предыдущих библиотек.
Для начала загрузим библиотеку и выберем нужную книгу и рабочий лист:
Как видно из вышеприведенного листинга сделать это не сложно. Теперь посмотрим как можно считать данные:
Отличие от прошлых библиотек в том, что openpyxl дает возможность отображаться к ячейкам и последовательностям через их имена, что довольно удобно и понятно при чтении программы.
Теперь посмотрим как нам произвести запись и сохранить данные:
Из примера видно, что запись, тоже производится довольно легко. Кроме того, в коде выше, можно заметить, что openpyxl кроме имен ячеек может работать и с их индексами.
К недостаткам данной библиотеки можно отнести, то что, как и в предыдущем примере, нет возможности сохранить изменения без создания новой книги.
Как было показано выше, для более менее полноценной работы с excel файлами, в данном случае, нужно 4 библиотеки, и это не всегда удобно. Кроме этого, возможно нужен будет доступ к VBA (допустим для какой-либо последующей обработки) и с помощью этих библиотек его не получить.
Однако, работа с этими библиотеками достаточно проста и удобна для быстрого создания Excel файлов их форматирования, но если Вам надо больше возможностей, то следующий подпункт для Вас.
Работа с com-объектом
В своих отчетах я предпочитаю использовать второй способ, а именно использование файла Excel через com-объект с использованием библиотеки win32com. Его преимуществом, является то, что вы можете выполнять с файлом все операции, которые позволяет делать обычный Excel с использованием VBA.
Проиллюстрируем это на той же задаче, что и предыдущие примеры.
Для начала загрузим нужную библиотеку и создадим COM объект.
Теперь мы можем работать с помощью объекта Excel мы можем получить доступ ко всем возможностям VBA. Давайте, для начала, откроем любую книгу и выберем активный лист. Это можно сделать так:
Давайте получим значение первой ячейки и последовательности:
Как можно заметить, мы оперируем здесь функциями чистого VBA. Это очень удобно если у вас есть написанные макросы и вы хотите использовать их при работе с Python при минимальных затратах на переделку кода.
Посмотрим, как можно произвести запись полученных значений:
Из примера видно, что данные операции тоже довольно просто реализовываются. Кроме этого, можно заметить, что изменения мы сохранили в той же книге, которую открыли для чтения, что достаточно удобно.
Однако, внимательный читатель, обратит внимание на переменную i, которая инициализируется не 0, как принято python, а 1. Это связано с тем, что мы работаем с индексами ячеек как из VBA, а там нумерация начинается не с 0, а с 1.
На этом закончим разбор способов работы с excel файлами в python и перейдем к обратной задаче.
Вызываем функции Python из MS Excel
Может возникнуть такая ситуация, что у вас уже есть какой-либо функция, которая обрабатывает данные на python, и нужно перенести ее функциональность в Excel. Конечно же можно переписать ее на VBA, но зачем?
Для использования функций python в Excel есть прекрасная надстройка ExcelPython. С ее помощью вы сможете вызывать функции написанные на python прямо из Excel, правда придется еще написать небольшую обертку на VBA, и все это будет показано ниже.
Итак, предположим у нас есть функция, написанная на python, которой мы хотим воспользоваться:
На вход ей подается список, состоящий из списков, это одно из условий, которое должно выполняться для работы данной функции в Excel.
Сохраним функцию в файле plugin.py и положим его в ту же директорию, где будет лежать наш excel файл, с которым мы будем работать.
Теперь установим ExcelPython. Установка происходит через запуск exe-файла и не вызывает затруднений.
Когда все приготовления выполнены, открываем тестовый файл excel и вызовем редактор VBA (Alt+F11). Для работы с вышеуказанной надстройкой необходимо ее подключить, через Tools->References, как показано на рисунке:
Ну что же, теперь можно приступить к написанию функции-обертки для нашего Python-модуля plugin.py. Выглядеть она будет следующим образом:
Итак, что же происходит в данной функции?
Для начала, с помощью PyModule , мы подключаем нужный модуль. Для этого в качестве параметров ей передается имя модуля без расширения, и путь до папки в которой он находится. На выходе работы PyModule мы получаем объект для работы с модулем.
Затем, с помощью PyCall , вызываем нужную нам функцию из указанного модуля. В качестве параметров PyCall получает следующее:
- Объект модуля, полученный на предыдущем шаге
- Имя вызываемой функции
- Параметры, передаваемые функции (передаются в виде списка)
Теперь, чтобы убедиться в работоспособности нашей связки, вызовем нашу свежеиспеченую функцию на листе в Excel:
Как видно из рисунка все отработало правильно.
Надо отметить, что в данном материале используется старая версия ExcelPython, и на GitHub'e автора доступна новая версия.
Заключение
В качестве заключения, надо отметить, примеры в данной статье самые простые и для более глубоко изучения данных методов, я рекомендую обратиться к
документации по нужным пакетам.
Также хочу заметить, что указанные пакеты не являются единственными и в статье опущено рассмотрение, таких пакетов как xlsxwriter для генерации excel файлов или xlwings, который может работать с Excel файлами «на лету», а также же PyXLL, который выполняет аналогичные функции ExcelPython.
Кроме этого в статье я попытался несколько обобщить разборасанный по сети материал, т.к. такие вопросы часто фигурируют на форумах и думаю некоторым будет полезно иметь, такую «шпаргалку» под рукой.
Документ электронной таблицы Excel называется рабочей книгой. Каждая книга может хранить некоторое количество листов. Лист, просматриваемый пользователем в данный момент, называется активным. Лист состоит из из столбцов (адресуемых с помощью букв, начиная с A) и строк (адресуемых с помощью цифр, начиная с 1).
Модуль OpenPyXL не поставляется вместе с Python, поэтому его предварительно нужно установить:
Чтение файлов Excel
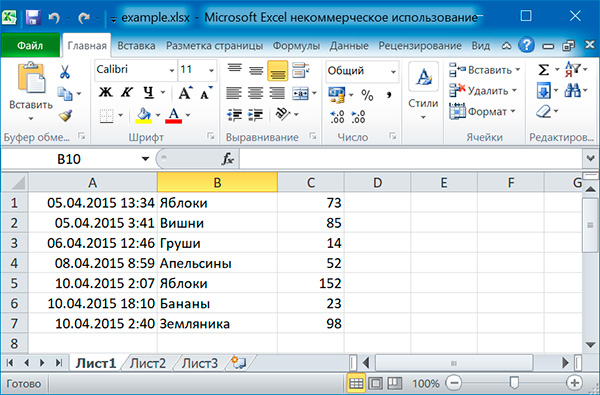
А теперь небольшой скрипт:
Как получить другой лист книги:
Как сделать лист книги активным:
Как задать имя листа:
Объект Cell имеет атрибут value , который содержит значение, хранящееся в ячейке. Объект Cell также имеет атрибуты row , column и coordinate , которые предоставляют информацию о расположении данной ячейки в таблице.
К отдельной ячейке можно также обращаться с помощью метода cell() объекта Worksheet , передавая ему именованные аргументы row и column . Первому столбцу или первой строке соответствует число 1, а не 0:
Размер листа можно получить с помощью атрибутов max_row и max_column объекта Worksheet :
Чтобы преобразовать буквенное обозначение столбца в цифровое, следует вызвать функцию
Чтобы преобразовать цифровое обозначение столбуа в буквенное, следует вызвать функцию
Для вызова этих функций загружать рабочую книгу не обязательно.
Используя срезы объектов Worksheet , можно получить все объекты Cell , принадлежащие определенной строке, столбцу или прямоугольной области.
Выводим значения второй колонки:
Выводим строки с первой по третью:
Для доступа к ячейкам конкретной строки или столбца также можно воспользоваться атрибутами rows и columns объекта Worksheet .
Выводим значения всех ячеек листа:
Выводим значения второй строки (индекс 1):
Выводим значения второй колонки (индекс 1):
Запись файлов Excel
Метод create_sheet() возвращает новый объект Worksheet , который по умолчанию становится последним листом книги. С помощью именованных аргументов title и index можно задать имя и индекс нового листа.
Метод remove() принимает в качестве аргумента не строку с именем листа, а объект Worksheet . Если известно только имя листа, который надо удалить, используйте wb[sheetname] . Еще один способ удалить лист — использовать инструкцию del wb[sheetname] .
Не забудьте вызвать метод save() , чтобы сохранить изменения после добавления или удаления листа рабочей книги.
Запись значений в ячейки напоминает запись значений в ключи словаря:
Заполняем таблицу 3x3:
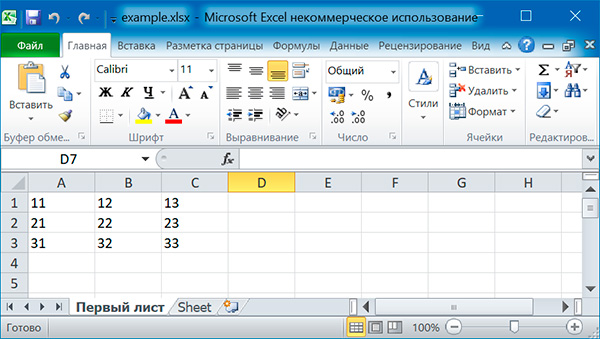
Можно добавлять строки целиком:
Стилевое оформление
Для настройки шрифтов, используемых в ячейках, необходимо импортировать функцию Font() из модуля openpyxl.styles :
Ниже приведен пример создания новой рабочей книги, в которой для шрифта, используемого в ячейке A1 , устанавливается шрифт Arial , красный цвет, курсивное начертание и размер 24 пункта:
Именованные стили применяются, когда надо применить стилевое оформление к большому количеству ячеек.
Добавление формул
Формулы, начинающиеся со знака равенства, позволяют устанавливать для ячеек значения, рассчитанные на основе значений в других ячейках.
Эта инструкция сохранит =SUM(B1:B8) в качестве значения в ячейке B9 . Тем самым для ячейки B9 задается формула, которая суммирует значения, хранящиеся в ячейках от B1 до B8 .
Формула Excel — это математическое выражение, которое создается для вычисления результата и которое может зависеть от содержимого других ячеек. Формула в ячейке Excel может содержать данные, ссылки на другие ячейки, а также обозначение действий, которые необходимо выполнить.
Использование ссылок на ячейки позволяет пересчитывать результат по формулам, когда происходят изменения содержимого ячеек, включенных в формулы. Формулы Excel начинаются со знака = . Скобки () могут использоваться для определения порядка математических операции.
Примеры формул Excel: =27+36 , =А1+А2-АЗ , =SUM(А1:А5) , =MAX(АЗ:А5) , =(А1+А2)/АЗ .
Хранящуюся в ячейке формулу можно читать, как любое другое значение. Однако, если нужно получить результат расчета по формуле, а не саму формулу, то при вызове функции load_workbook() ей следует передать именованный аргумент data_only со значением True .
Настройка строк и столбцов
С помощью модуля OpenPyXL можно задавать высоту строк и ширину столбцов таблицы, закреплять их на месте (чтобы они всегда были видны на экране), полностью скрывать из виду, объединять ячейки.
Настройка высоты строк и ширины столбцов
Объекты Worksheet имеют атрибуты row_dimensions и column_dimensions , которые управляют высотой строк и шириной столбцов.
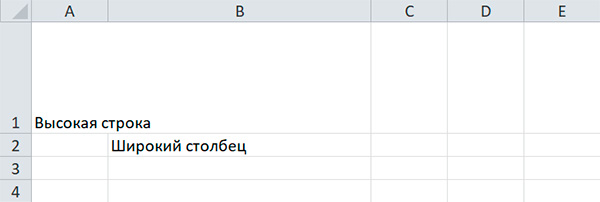
Атрибуты row_dimension s и column_dimensions представляют собой значения, подобные словарю. Атрибут row_dimensions содержит объекты RowDimensions , а атрибут column_dimensions содержит объекты ColumnDimensions . Доступ к объектам в row_dimensions осуществляется с использованием номера строки, а доступ к объектам в column_dimensions — с использованием буквы столбца.
Для указания высоты строки разрешено использовать целые или вещественные числа в диапазоне от 0 до 409. Для указания ширины столбца можно использовать целые или вещественные числа в диапазоне от 0 до 255. Столбцы с нулевой шириной и строки с нулевой высотой невидимы для пользователя.
Объединение ячеек
Ячейки, занимающие прямоугольную область, могут быть объединены в одну ячейку с помощью метода merge_cells() рабочего листа:

Чтобы отменить слияние ячеек, надо вызвать метод unmerge_cells() :
Закрепление областей
Если размер таблицы настолько велик, что ее нельзя увидеть целиком, можно заблокировать несколько верхних строк или крайних слева столбцов в их позициях на экране. В этом случае пользователь всегда будет видеть заблокированные заголовки столбцов или строк, даже если он прокручивает таблицу на экране.
У объекта Worksheet имеется атрибут freeze_panes , значением которого может служить объект Cell или строка с координатами ячеек. Все строки и столбцы, расположенные выше и левее, будут заблокированы.
| Значение атрибута freeze_panes | Заблокированные строки и столбцы |
|---|---|
| sheet.freeze_panes = 'A2' | Строка 1 |
| sheet.freeze_panes = 'B1' | Столбец A |
| sheet.freeze_panes = 'C1' | Столбцы A и B |
| sheet.freeze_panes = 'C2' | Строка 1 и столбцы A и B |
| sheet.freeze_panes = None | Закрепленные области отсутствуют |
Диаграммы
Модуль OpenPyXL поддерживает создание гистогорамм, графиков, а также точечных и круговых диаграмм с использование данных, хранящихся в электронной таблице. Чтобы создать диаграмму, необходимо выполнить следующие действия:
- создать объект Reference на основе ячеек в пределах выделенной прямоугольной области;
- создать объект Series , передав функции Series() объект Reference ;
- создать объект Chart;
- дополнительно можно установить значения переменных drawing.top , drawing.left , drawing.width , drawing.height объекта Chart , определяющих положение и размеры диаграммы;
- добавить объект Chart в объект Worksheet .
- Объект Worksheet , содержащий данные диаграммы.
- Два целых числа, представляющих верхнюю левую ячейку выделенной прямоугольной области, в которых содержатся данные диаграммы: первое число задает строку, второе — столбец; первой строке соответствует 1, а не 0.
- Два целых числа, представляющих нижнюю правую ячейку выделенной прямоугольной области, в которых содержатся данные диаграммы: первое число задает строку, второе — столбец.
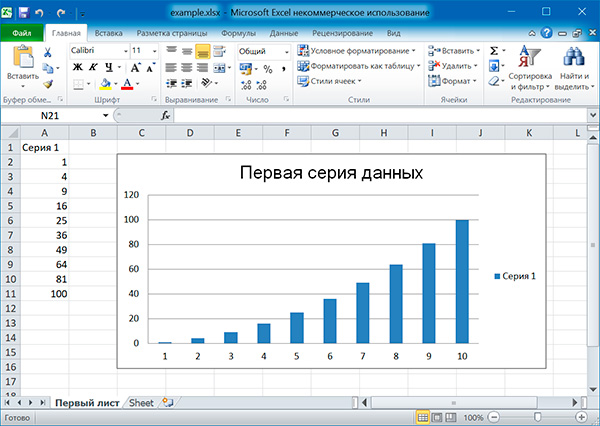
Аналогично можно создавать графики, точечные и круговые диаграммы, вызывая методы:
Читайте также: