
Совместимость 1с и postgresql
Обновлено: 07.07.2024
Когда перед нами стал вопрос снижения стоимости серверных 1С, мы начали искать пути экономии без потери качества. И одним из самых очевидных решений стало использование свободно распространяемого ПО, которое по характеристикам не уступает платному. Так наш выбор пал на SQL сервер Postgre, официально интегрированный с продуктами 1С. А приятным бонусом для нас стало импортозамещение, которое мы при прочих равных всегда поддерживаем.
Выбор решения и архитектура
Чтобы упростить переход с MS SQL на базе ОС Windows 2016 Server, мы решили использовать SQL сервер Postgre, представленный на сайте 1С, релиз 11.5-19.1C, и при этом остаться на хорошо знакомой нам Windows 2016. Это решение позволяет более быстро осуществить переход, т.к. администрировать Windows системы нам привычнее, есть масса наработок для резервного копирования и мониторинга производительности. А еще такой подход позволил объективно сравнить показатели производительности 1С на PostgreSQL по сравнению с MS SQL, так как в обоих случаях использовались идентичные по производительности сервера с одинаковыми настройками ОС.
Для тестирования системы мы взяли сервера со следующими параметрами:
| Роль | Конфигурация |
|---|---|
| Сервер БД MS SQL | 10 vCPU 50 RAM |
| Сервер предприятия 1C | 6 vCPU 20 RAM |
| Сервер БД PostgreSQL | 10 vCPU 50 RAM |
Установка и настройка

Далее указываете порт подключения (по умолчанию 5432), задаете пароль для суперпользователя инстанса с логином postgres. При установке требуется, чтобы была запущена служба “Вторичный вход в систему”, а также выданы права к каталогу данных для NETWORK SERVICE .

Тюнинг настроек мы производили в соответствии с ресурсами сервера и с учетом рекомендаций из различных источников - мы изучили официальную документацию, тематические форумы, чаты в Телеграм, видеоматериалы.
PostgreSQL, как и MS SQL, позволяет запуск нескольких инстансов (экземпляров) на одном сервере. Этот функционал полезен в различных ситуациях, одна из популярнейших утилит резервного копирования БД Postgre - pg_probackup, позволяющая выполнять полное и журнальное бекапирование, обеспечивать валидацию данных, восстановление на произвольный момент времени. Она выполняет бекап полностью всего инстанса, а не отдельных баз, поэтому использование нескольких инстансов для различных баз или групп баз позволит настроить индивидуальные планы резервного копирования, исключит простой баз других инстансов в случае необходимости восстановления единичного инстанса. Также обычный перезапуск службы, например, для изменения конфигурации затронет только единичный инстанс.
Настройка производится стандартными утилитами initdb.exe и pg_ctl.exe, новая инсталляция Postgre SQL не требуется, пример использования:
После этого необходимо зарегистрировать службу:
Команды выполняются из командного файла или строки с привилегиями администратора.
Результат:

Изменяем в postgresql.conf параметр port = 5432 (стандартный) на другой, например, 5433. При необходимости меняем параметры авторизации службы "OriginalName-5433" и стартуем. На сервере предприятия при создании базы указываем имя хоста сервера и порт в следующем формате - “hostname port 5433”

После этого можем зайти в графический клиент управления Pgadmin 4, настраиваем подключение к серверу по порту 5433 и проверяем успешное создание базы.
Резервное копирование и обслуживание
Для резервного копирования мы выбрали утилиту pg_probackup, так как она обеспечивает нужный нам сценарий резервного копирования. Резервное копирование и обслуживание баз, в отличие от MS SQL, не имеет графического интерфейса, в котором можно настроить Maintenance plan (План обслуживания). Все команды выполняются из командной строки планировщиком заданий Windows. Мы настроили и протестировали архивирование журналов предзаписи (WAL) и создание полных копий 1 раз в сутки с планом хранения в течение 2х недель.
Два бекапа - всегда лучше, чем один, поэтому полные бекапы баз и журналы WAL синхронизируются с облачным объектным хранилищем. С этой задачей нам помогла успешно справится свободно распространяемая утилита Rclone, которая позволяет копировать, переносить, синхронизировать файлы между различными типами хранилищ, обеспечивая высокую скорость за счет многопоточности и гарантируя доставку валидных данных за счет алгоритма хеширования MD5.
Обслуживание инстанса или отдельных баз, как правило, заключается в ежедневном сборе мусора и анализе данных с помощью VACUUM, запускать который желательно перед началом рабочего дня. Для запуска из командного файла по шедулеру требуется учесть настройку авторизации, без которой командный файл не отработает, так как будет ждать ввода пароля. В каталоге %APPDATA%\postgresql\ необходимо создать файл pgpass.conf, формат записей, которые необходимо создать для всех баз : : : : , например, localhost:5432:Dbname:postgres:password. В командной строке обслуживания указываем опцию - w, и авторизация будет использовать данные из конфига.
Пример:
Тестирование
Ну вот мы и готовы приступить к тестированию. Для этого мы выбрали достаточно высоконагруженную базу 1С из прод среды размером около 40 ГБ, в которой ежедневно более 500 подключений одновременно. Загрузка базы в формате DT подготовила нам первый сюрприз - она не залилась полностью, мы убедились в том, что те ошибки, которые прощает разработчикам MS SQL, в PostgreSQL вылазят наружу и требуют более тщательного подхода к написанию кода и организации хранения данных. Мы призвали на помощь наших разработчиков 1С. Они проанализировали ошибки и нашли причину - виной всему оказалось хранение в базе крупных и даже очень крупных объектов, таких как архивы, медиа-файлы и документы. Пришлось выполнить доработки в прод базе - ограничить максимальный объем вложений. Теперь вместо крупных вложений хранятся ссылки на них (ссылки на портал компании или другие облачные хранилища, такие как Google Disk). Автотесты, которые предусмотрены в нашей базе, также не прошли сразу по причине различия правил сортировки, и снова наши разработчики 1С оказались на высоте и удачно устранили все сложности.
После доработок базы приступили к тестированию производительности на PostgreSQL и MS SQL. APDEX показал примерно одинаковые результаты на MS SQL 0.862/0.877 на Postgre 0.898/0.895. Также мы протестировали время бекапирования и восстановления, MS SQL примерно в 1.5 -2 раза превосходит по скорости таких операций, но при объеме данной базы вилка по времени не значительна. Поэтому мы сделали вывод, что использование PostgreSQL вполне оправдано.
Переход
Каким бы тщательным ни было тестирование, переход на использование новых стандартов всегда торжественно тревожен. Ни один синтетический тест не сравнится с реальной нагрузкой, которую создают практически все сотрудники нашей компании, работая в базе и открывая по несколько сеансов одновременно. Мы еще раз все тщательно проверили, взвесили все риски, детально составили план деплоя и план отката, если что-то пойдет не так. И вот однажды поздним вечером, когда все граждане уже мирно спали, наша команда приступила к переезду.
На следующее утро никто не заметил наших усилий и перемен, база работала также стабильно. На сегодняшний день она уже больше месяца функционирует на PostgreSQL. Так мы убедились, что PostgreSQL под управлением Windows 2016 Server хорошо справился с обеспечением необходимой производительности. Мы начинали проект с базовым набором знаний в PostgreSQL, в результате мы получили реальные пруфы и прокачали скиллы. Следующим этапом снижения стоимости содержания серверных баз 1С мы планируем использование Linux серверов. Таким образом мы исключим необходимость оплаты лицензий Windows.
Настройки PostgreSQL для работы с 1С:Предприятием. Часть 2
В статье описывается настройка PostgreSQL версий 9.6 и выше на максимальную производительность для работы с Платформой 1С:Предприятие. Предполагается, что сервер СУБД PostgreSQL является достаточно производительным и имеет не менее:
- 8 - 512 Gb RAM
- 4 - 256 CPU cores
- RAID 0-1 или SSD
Рекомендуемые значения индивидуальны и зависят от системы и нагрузки на нее.
Подразумевается, что читатель хотя бы поверхностно знаком с архитектурой PostgreSQL. Приведенные в документе параметры являются приблизительными и стартовыми для тонкой настройки.
Настройки сервера для PostgreSQL
Рекомендуется изменять значение по умолчанию пути к директории pg_stat_temp так, чтобы она находилась отдельно от директории кластера. Причина в интенсивном изменении файлов в этой директории, что создает значительную нагрузку на дисковую подсистему. Директорию рекомендуется размещать в RAM-диске (для Windows) или tmpfs (для linux).
Параметры клиентских сеансов
row_security = off >= 9.5
Отключение контроля на уровне записей.
Параметры подключений
Выключение шифрования, которое может приводить к увеличению загрузки CPU.
Потребление оперативной памяти
Количество памяти, выделенной PostgreSQL для совместного кеша страниц. Эта память разделяется между всеми процессами PostgreSQL.
Максимальное количество страниц для временных таблиц - верхний лимит размера временных таблиц в каждой сессии.
work_mem = RAM/32..64 или 32MB..128MB
Лимит памяти для обработки одного запроса. Эта память индивидуальна для каждой сессии. Теоретически максимально потребная память вычисляется как max_connections *work_mem, на практике она достигает такой величины крайне редко. Это рекомендательное значение используется оптимизатором: он оценивает размер памяти для выполнения запроса, и, если это значение больше work_mem, запрос будет выполняться с использованием временных таблиц (для промежуточных результатов, сортировки, группировки…). Work_mem не является в полном смысле лимитом: оптимизатор может сделать неправильную оценку, и запрос займёт больше памяти, чем изначально было выделено. Это значение можно уменьшать, следя за количеством создаваемых в системе временных файлов:
select sum(temp_files) as temp_files, pg_size_pretty(sum(temp_bytes)) as temp_size from pg_stat_database;
maintenance_work_mem = RAM/16..32 или work_mem * 4 или 256MB..4GB
Лимит памяти для обслуживающих задач, например вакуум, автовакуума или создания индексов.
В случае выявления существенной фрагментации памяти процессов PostgreSQL в Linux, имеет смысл воспользоваться переменной окружения (её нужно установить в файле/etc/systemd/system/postgresql-10.service):
Environment = MALLOC_MMAP_THRESHOLD_= 8192
Настройки WAL
Сброс буферов на диск (выполнение PostgerSQL системных вызовов fsync()). Выключение параметра приводит к росту производительности, но появляется значительный риск потери всех данных при внезапном выключении питания.
Внимание: если RAID имеет кэш и находиться в режиме write-back, проверьте наличие и функциональность батарейки кэша RAID контроллера! Иначе данные, записанные в кэш RAID, могут быть потеряны при выключении питания, и, как следствие, PostgreSQL не гарантирует целостность данных.
Выключение синхронной записи в WAL момент коммита транзакции. Создает риск потери последних нескольких транзакций (в течении 0.5-1" секунды), но гарантирует целостность базы данных. Может значительно увеличить производительность.
checkpoint_segments = 32..256 < 9.5
Максимальное количество сегментов WAL между точками восстановления - checkpoint. Слишком частые checkpoint приводят к значительной нагрузке на дисковую подсистему. Каждый сегмент имеет размер 16MB.
Степень "размазывания" checkpoint'a. Скорость записи во время checkpoint'а регулируется так, чтобы время checkpoint'а было равно времени, прошедшему с прошлого, умноженному на checkpoint_completion_target.
min_wal_size = 512MB .. 4G > = 9.5
max_wal_size = 2 * min_wal_size > = 9.5
Минимальное и максимальный объем WAL файлов. Аналогично checkpoint_segments.
commit_delay = 1000
commit_siblings = 5
Групповой коммит нескольких транзакций. Имеет смысл включать, если интенсивность транзакций превосходит 1000 TPS.
Фоновая запись на диск
Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных вshared_buffers,с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки наcheckpointпроцесс и процессы, обслуживающие сессии (backend’ы). Малое значение приведет к полной загрузке одного из ядер.
bgwriter_lru_multiplier = 4.0
bgwriter_lru_maxpages = 400
Параметры, управляющие интенсивностью записи фонового процесса записи. За один циклbgwriterзаписывает не больше, чем было записано в прошлый цикл, умноженное наbgwriter_lru_multiplier, но не больше чем bgwriter_lru_maxpages.
Настройки выполнения очистки (автовакуума)
Внимание! Не выключайте автовакуум, это приведет к росту размеров базы и серьезной деградации производительности.
autovacuum_max_workers =" CPU "cores/4..2 но не меньше 4
Количество процессов автовакуума. Общее правило - чем больше запросов на запись выполняется в системе (такие системы называются OLTP), тем больше процессов.
Время сна процесса автовакуума. Слишком большая величина будет приводить к тому, что таблицы не будут успевать «чиститься», что приведет у роста размера и снижению производительности работы. Малая величина приведет к бесполезной нагрузке.
Использование ресурсов ядра
Значение по умолчанию – 8000, его не нужно уменьшать. Оно может быть увеличено в зависимости от характера нагрузки (максимальное значение зависит от операционной системы). Один файл - это как минимум либо индекс либо таблица, но таблица/может состоять из нескольких файлов. Если PostgreSQL «упирается» в этот лимит, он начинает открывать/закрывать файлы, что может сказываться на производительности. Диагностировать проблему под Linux можно с помощью команды lsof.
Настройки планировщика запросов
effective_cache_size =" RAM - "shared_buffers
Оценка планировщика запроса о размере дискового кеша, доступного для одного запроса. Это представление влияет на оценку стоимости использования индекса. Чем выше это значение, тем больше вероятность, что оптимизатором будет выбираться сканирование по индексу (Index Scan), чем ниже, тем более вероятно, что будет выбрано последовательное сканирование (Seq Scan).
random_page_cost = 1.5-2.0 для RAID, 1.1-1.3 для SSD
Стоимость чтения рандомной страницы, на которую будет опираться оптимизатор (по-умолчанию 4). Практическое значение параметра должно зависеть от «seek time» дисковой системы: чем он меньше, тем меньше должно быть значение random_page_cost (но не менее 1.0) . Излишне большое значение параметра увеличивает склонность PostgreSQL к выбору планов с сканированием всей таблицы (PostgreSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). Оценка стоимости последовательного чтения делается, в свою очередь, с учетом параметра seq_page_cost, который равен по умолчанию 1.
Задаёт максимальное число элементов в списке FROM, до которого планировщик будет объединять вложенные запросы с внешним запросом. При меньших значениях сокращается время планирования, но план запроса может стать менее эффективным.
Задаёт максимальное количество элементов в списке FROM, до достижения которого планировщик будет сносить в него явные конструкции JOIN (за исключением FULL JOIN). При меньших значениях сокращается время планирования, но план запроса может стать менее эффективным.
GEQO - генетический оптимизатор запросов PоstgreSQL, который осуществляет планирование запросов, применяя эвристический поиск вместо полного перебора отношений. Он позволяет сократить время планирования для сложных запросов с большим числом соединений, потому не рекомендуется его отключать. Однако надо учитывать, что полученный им план может оказаться менее эффективным и, как следствие, увеличится время выполнения запроса. Управлять его включением более тонко помогает следующий параметр:
Задаёт минимальное число элементов во FROM, при котором для планирования запроса будет привлечён генетический оптимизатор. Для более простых запросов лучше использовать обычный планировщик, для запросов со множеством таблиц обычное планирование может занять слишком много времени, в этом случае выгоднее потерять на качестве плана, но выполнить планирование быстро.
Асинхронное поведение
Оценочное значение одновременных запросов к дисковой системе, которые она может обслужить единовременно. Допустимый диапазон от 1 до 1000. Значение по умолчанию равно 1, где это поддерживается, в остальных системах - 0.
Для одиночного диска можно условно поставить 1, для RAID - 2 или больше.
Сейчас эта оценка влияет только на выбор bitmap heap scan.
Параметры для платформы 1С:Предприятия
Разрешить использовать символ \ для экранирования.
Не выдавать предупреждение о использовании символа \ для экранирования.
Максимальное число блокировок индексов/таблиц в одной транзакции.
Количество одновременных соединений.
Параметры дополнительных модулей
В общем случае мы не рекомендуем использовать синхронное автообновление статистики, однако его можно включить, если есть основания полагать, что фоновое обновление не дает нужного результата / оптимизатор часто ошибается в оценке количества строк.
Все остальные параметры имеют смысл, только если online_analyze.enable = on.
Включает синхронное автообновление статистики на временных таблицах.
Выполнение инструкции ANALYZE без опции VERBOSE.
Минимальное количество записей, предшествующее обновлению статистики.
«Доля» в величине таблицы, начиная с которой будет происходить автообновление.
Отслеживание изменений в рамках соединения (для локальных временных таблиц).
PostgerSQL заточен под Linux и в своей среде он будет работать лучше и быстрее (как рыба в воде), но есть и адаптированный под Windows, требующий чуть больших настроек для оптимизации, чем просто "далее-далее-далее" в MSSQL. Хотя на небольших БД на первых этапах хватает и стандартной настройки задаваемой при установке.
Тесты о работе и производительности на разных системах разных продуктов MS SQL, PostgerSQL, под Linux, Windows легко можно найти в интернете, тут же мы рассмотрим простую установку и базовую настройку для работы 1С 8 на PostgerSQL 11.5 под Windows Server 2008 R2.
Постановка задачи:
1С Предприятие 8.3.16.1063, 1С БД Бухгалтерия 3.0.75.58 – размер файла
Сервер: i5-9400, ОЗУ DDR4 16 Гб, SSD 256, ОС Windows Server 2008R2 x64
Установка и настройка PostgreSQL:
1. Подготовка:
Перед установкой и настройкой рекомендуется отключить протокол IPv6, иначе это может затруднить дальнейшую настройку.

Также необходимо установить Microsoft Visual C++ 2015 (на сайте 1С он идет в комплекте)

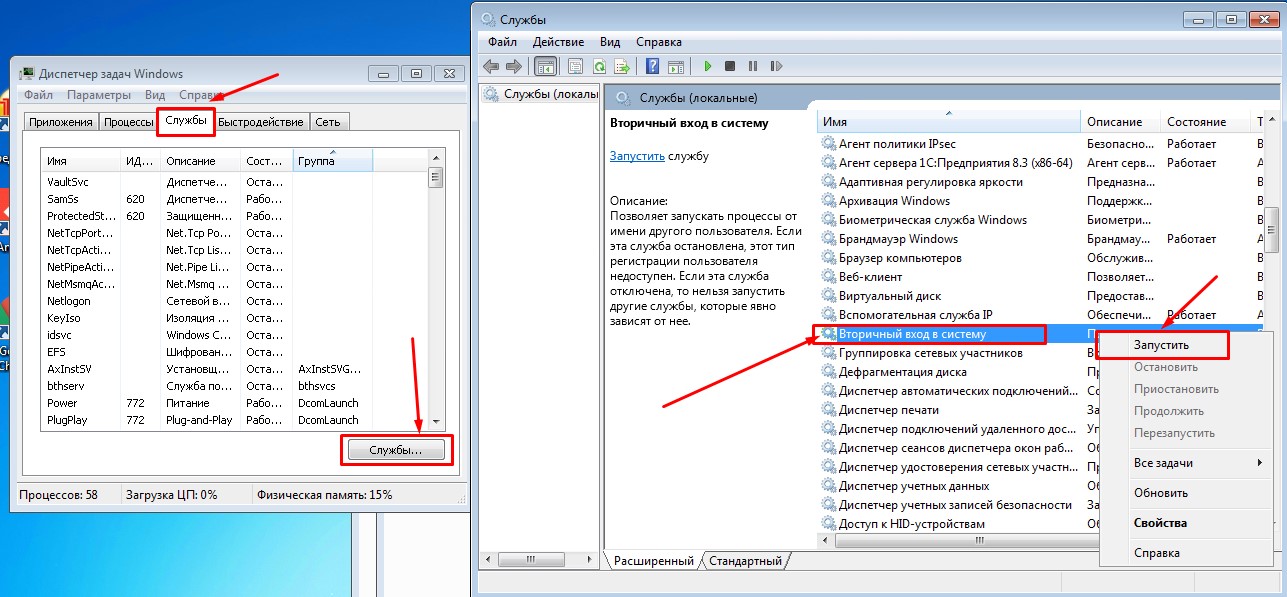
Также заранее рекомендуется включить службу "Вторичный вход в систему", иначе при установке будет ошибка.
2. Процесс установки
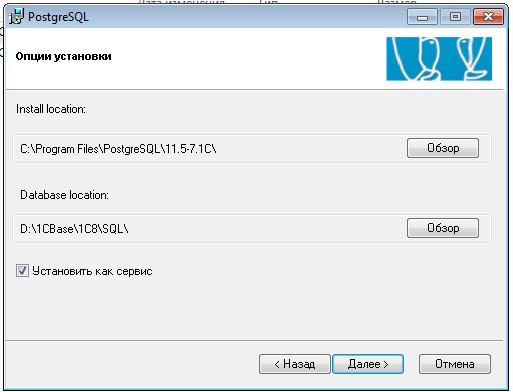
Далее указываем путь установки программы (его не меняем) и путь, где будут располагаться БД (его рекомендуется сменить, чтобы БД хранились не на системном диске)
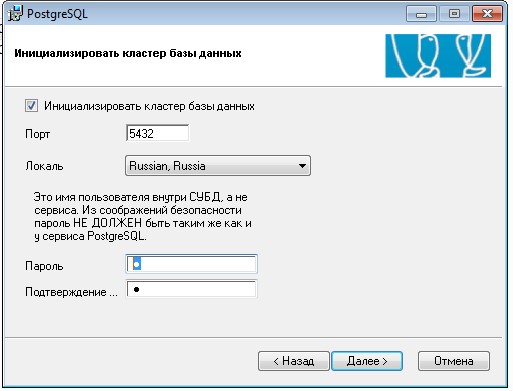
Если вы не запустили службу "Вторичный вход в систему" то у вас будет ошибка, ее можно включить на этапе установки и продолжить:
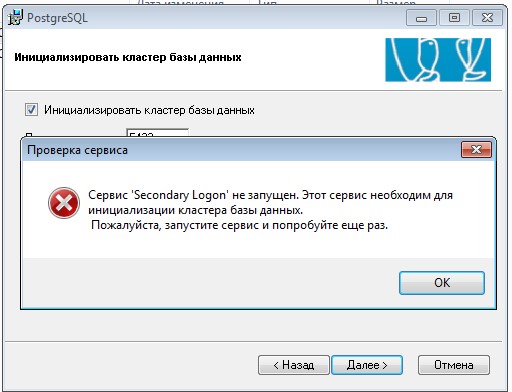

После установки запускаем консоль администратора "Пуск-PostgreSQL 11.5-7.1C(x64)-pgAdmin 4"
На этом установка PostgreSQL закончена.
3. Установка 1С сервера:
Запуститься помощник установки системы «1С:Предприятия». На первой странице жмем «Далее».
На следующей странице необходимо выбрать те компоненты, которые будут устанавливаться, нам требуются компоненты:
- Сервер 1С:Предприятия — компоненты сервера «1С:Предприятия»
- Администрирование сервера 1С:Предприятия 8 — дополнительные компоненты для администрирования кластера серверов «1С:Предприятия»

Если сервер «1С:Предприятия» устанавливается как служба Windows рекомендуется сразу создать отдельного пользователя, из под которого будет запускаться служба "Агент сервера 1С Предприятия", либо можно выбрать существующего пользователя для запуска сервера. Для создание нового пользователя необходимо:
- Выбираем флаг «Установить сервер 1С:Предприятие как сервис Windows (рекомендуется)»;
- Выбираем «Создать пользователя USR1CV8» и задаем его пароль (пароль должен отвечать политики паролей Windows).
Также пользователю обязательно следует дать необходимые права на каталог служебных файлов сервера (по умолчанию C:\Program Files\1cv8\srvinfo для 64-х разрядного и C:\Program Files (x86)\1cv8\srvinfo для 32-х разрядного сервера). Созданный автоматически пользователь USR1CV8 будет обладать всеми перечисленными правами.
Заполнив соответствующие параметры, жмем «Далее».

Далее идет установка всех необходимых файлов и служб. После чего следует убедиться что появилась и запущена соответствующая служба.

На этом установка Сервера 1С Предприятия закончена.
4. Создание 1С БД для PostgreSQL
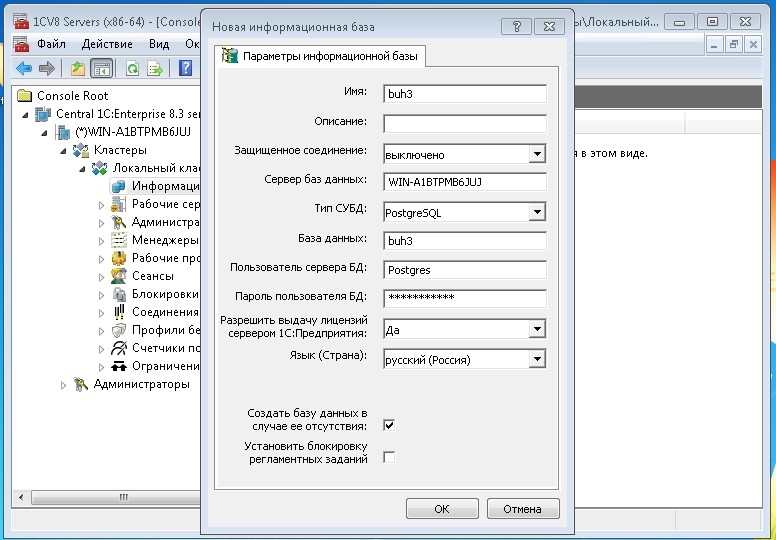
После установки 1С Сервера запускаем "Администрирование серверов 1С Предприятия x86-64", переходим в список "Информационные базы" и создаем новую БД. Заполняем основные поля:
- Имя - имя БД на сервере 1с
- Сервер баз данные - имя сервера где будет располагаться БД 1С SQL
- Тип СУБД - выбор на какой платформе у вас будет работать ваша база (MSSQL, PostgeSQL, IBM DB2, Oracle DateBase)
- База данных - имя базы которое будет создано в SQL
- Пользователь и пароль БД - пользователь в SQL
- Создавать базу данных в случае ее отсутствия - Создает БД в SQL если ее нет.
Если вы не отключили протокол IPv6 то у вас при создании будет ошибка:
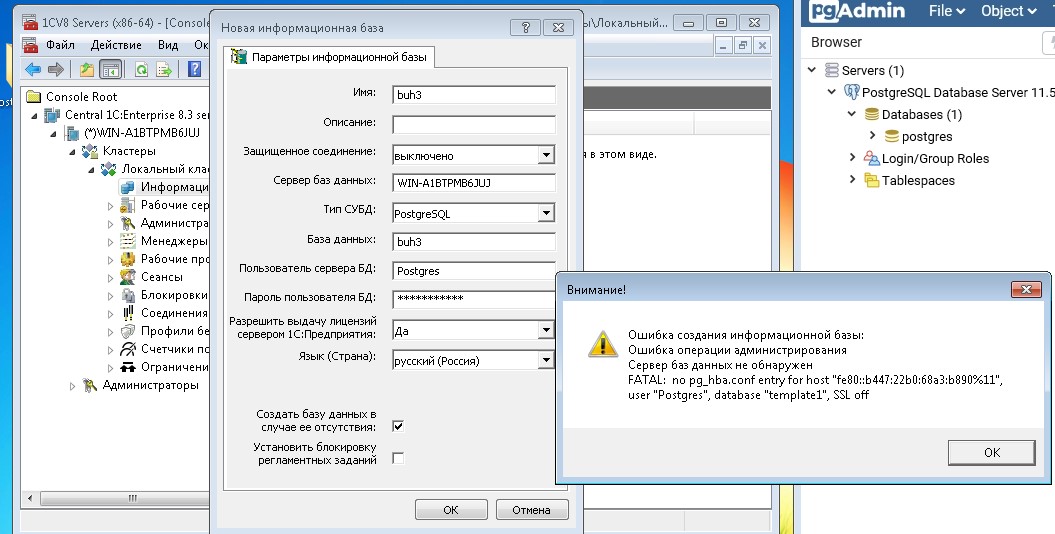
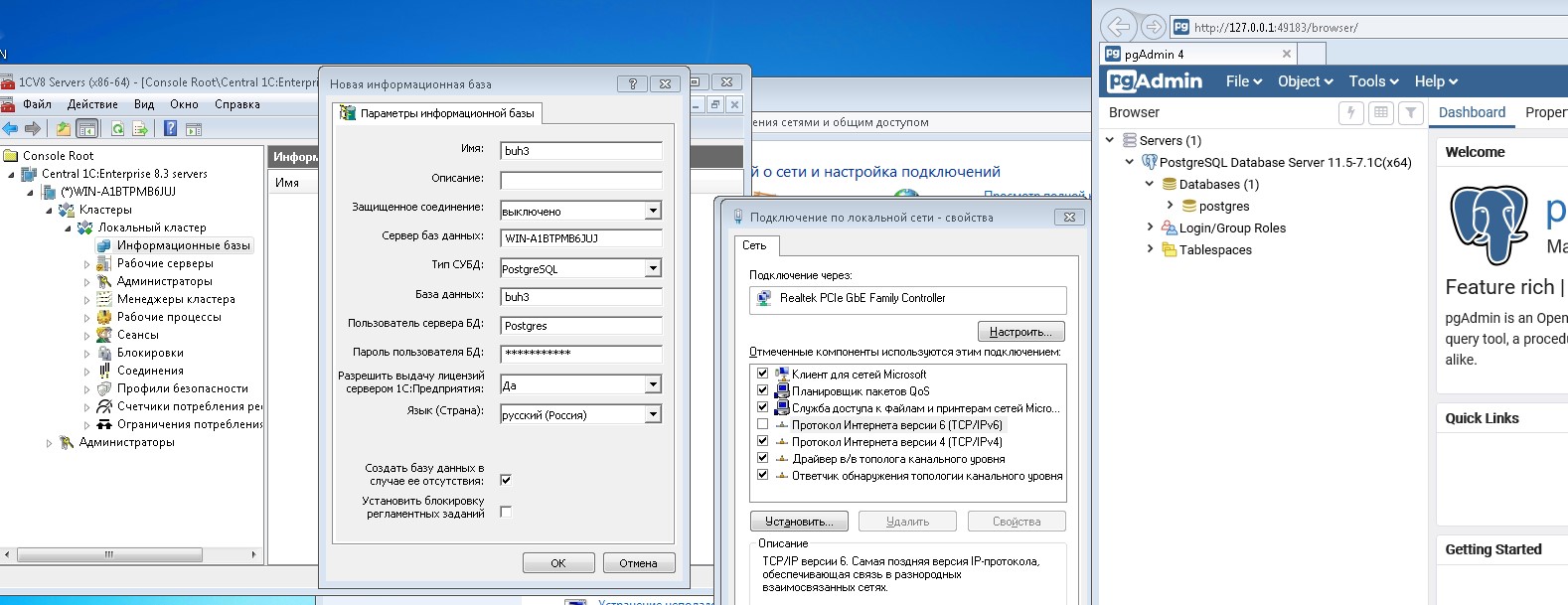
можно отключить протокол IPv6 и продолжить создание, либо можно указать IP адрес сервера без отключение протокол IPv6:
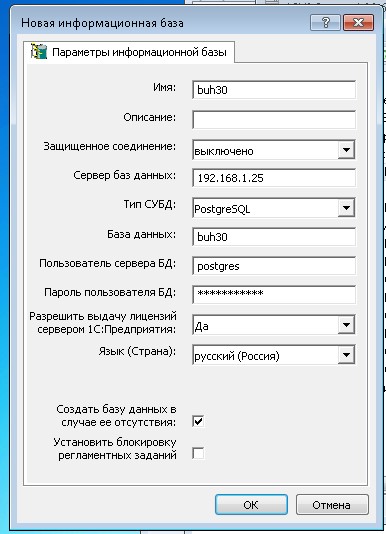
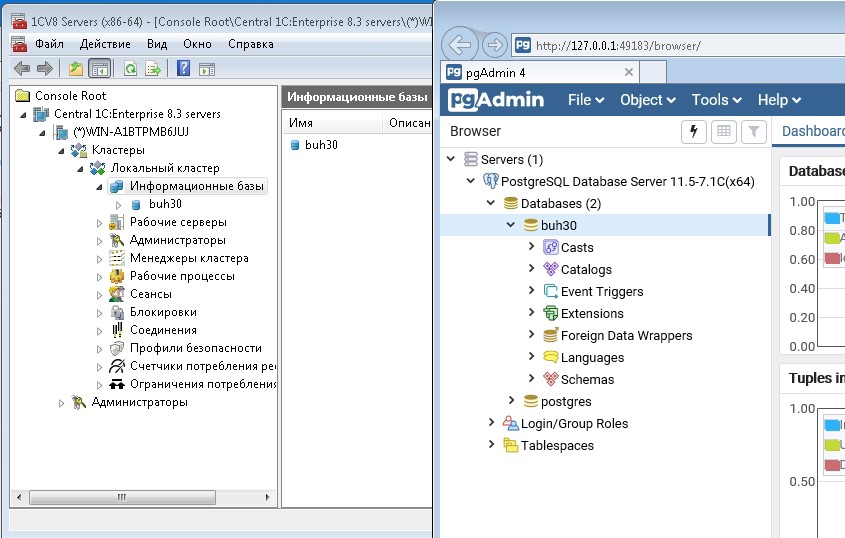
Все на этом этапе БД готова, в принципе ее можно подключать загружать в SQL и работать. Но рекомендуется сделать настройку самого Postgre сервера для оптимизации и более стабильной работы базы 1С на PostgreSQL. Делается это в 1 файле расположенном в каталоге с базами (путь который вы указывали при установке для баз по умолчанию C:\Program Files\PostgreSQL\11.5-7.1C\data). Файл postgresql.conf
5. Настройка PostgreSQL под 1С 8
ВАЖНО. Перед любыми изменения в этом файле обязательно сделайте его копию, в противном случаем если какой то параметр указан не верно у вас не запустится служба PostgreeSQL:
Перед тем как вносить изменения в файл postgresql.conf необходимо остановить службу


Изменение параметров в postgresql.conf:
После чего запускаем службу PostgreSQL и можно работать.
Так же иногда по какой то причине после загрузки в PostgreSQL в базе отключается "Полнотекстовый поиск", поэтому после настройки рекомендуется проверить и включить если выключено и обновить индексы (все функции-стандартные-управление полнотекстовым поиском).

Вопросу, какая же СУБД - Postgresql или MS SQL для 1С является наиболее оптимальной, посвящено множество статей. В этой статье мы рассмотрим шаги оптимизации обоих. Каждая СУБД вендора имеет как собственные рекомендации по настройке, так и рекомендации фирмы 1С. Следует отметить, что в зависимости от оборудования, конфигурации серверов и количества пользователей, задающих разную нагрузку, детали процесса оптимизации СУБД под 1С и реализации рекомендаций могут меняться.
Настройка PostgreSQL под 1С
Опыт эксплуатации баз 1С на PostgreSQL показал, что наибольшей производительности и оптимальной работы 1С и PostgreSQL удалось добиться на linux, поэтому желательно использовать именно ее. Но вне зависимости от операционной системы, важно помнить, что настройки, указанные по умолчанию при установке PostgreSQL, предназначены только для запуска сервера СУБД. Ни о какой промышленной эксплуатации речи идти не может! Следующим шагом после запуска станет оптимизация PostgreSQL под 1С:
Установка параметра shared_buffers в RAM/4 является рекомендацией по умолчанию, но пример Sql Server говорит о том, что чем больше памяти ему выделяется, тем лучше его производительность (при отключенном сбросе страниц в файл подкачки). То есть, чем больше страниц данных располагаются в оперативной памяти, тем меньше обращений к диску. Возникает вопрос: почему такой маленький кэш? Ответ прост: если shared_buffers большой, то часть неиспользуемых страниц свопируется на диск. Но как отследить момент, когда сброс прекратится, и показатель параметра будет оптимальным? Для достижения и выхода на оптимальный показатель shared_buffers, его значение необходимо поднимать на продуктиве ежедневно (по возможности) с определенным шагом прироста и смотреть, в какой момент начнется сброс страниц на диск (увеличится своп).
- Помимо этого, на «большой параметр» негативно влияет работа с множеством мелких страниц, которые по умолчанию имеют размер 8Кб. Работа с ними увеличивает накладные расходы. Что можно с этим сделать для оптимизации под 1С? В версии postgreSQL 9.4 появился параметр huge_pages, который можно включить, но только в Linux. По умолчанию включаются огромные страницы с размером по умолчанию 2048 kB. Дополнительно поддержку данных страниц необходимо включить в ОС. Таким образом, оптимизировав структуру хранения, можно выйти на больший показатель shared_buffers.
- work_mem = RAM/32..64 или 32MB..128MB Задает объем памяти для каждой сессии, который будет использоваться для внутренних операций сортировки, объединения и пр., прежде чем будут задействованы временные файлы. При превышении этого объема, сервер будет использовать временные файлы на диске, что может существенно снизить скорость обработки запросов. Данный параметр используется при выполнении операторов: ORDER BY, DISTINCT, соединения слиянием и пр.
- Посчитать дополнительно данный параметр можно следующим образом: (Общая память shared_buffers – память на другие программы) / число активных соединений. Это значение можно уменьшать, следя за количеством создаваемых временных файлов. Такую статистику по размеру и количеству временных файлов можно получить из системного представления pg_stat_database.
- effective_cache_size = RAM - shared_buffers основная задача этого параметра подсказать оптимизатору запроса, какой способ получения данных выбрать: полный просмотр или сканирование по индексу. Чем выше значение параметра, тем больше вероятность использования сканирования по индексу. При этом сервер не учитывает, что данные при выполнении запроса могут оставаться в памяти, и следующему запросу не надо их поднимать с диска.
Установка PostgreSQL
Установка 1С на PostgreSQL под Windows – достаточно простой процесс. При запуске установочного пакета необходимо указать кодировку UTF-8. По сути, это единственный интересный нюанс и еще какая-то настройка PostgreSQL для 1С 8.3 из-под Windows не потребуется. Установка и настройка PostgreSQL для 1С на ОС linux может вызвать ряд затруднений. Для их преодоления в качестве примера рассмотрим запуск работы (используя дистрибутивы ведущего российского вендора PostgreSQL-Pro и компании 1С) PostgreSQL на сервере Ubuntu 16.04 х64
Установка дистрибутивов 1С для СУБД PostgreSQL
1.Скачиваем указанную позицию дистрибутива СУБД PostgreSQL:
2.Выкладываем PostgreSQL на сервер;
3.Распаковать установщик СУБД PostgreSQL можно командой:
4.Перед установкой дистрибутива СУБД PostgreSQL проверим наличие в системе необходимой локали (по умолчанию ru_RU.UTF-8):
5.Если система, с которой будет работать PostgreSQL, ставилась с языком отличным от русского, необходимо создать новые локали:
6.Если необходимая локаль все же имеется, устанавливаем ее по умолчанию:
7.После перезагрузки, установим необходимые пакеты для нашей версии PostgreSQL:
8.Версия PostgreSQL пакета 9.4.2-1.1C связана с пакетом libicu версии libicu48. В репозитории нужной версии уже нет, ее можно скачать;
9.Скачиваем и помещаем в каталог, где хранятся скачанные файлы для PostgreSQL;
10.Перейдя в каталог с файлами PostgreSQL, производим установку, последовательно набирая следующие команды:
Читайте также: