
Среднее линейное отклонение в excel
Обновлено: 12.07.2024
Оценивает стандартное отклонение по выборке. Стандартное отклонение — это мера того, насколько широко разбросаны точки данных относительно их среднего.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции Функция СТАНДОТКЛОН.В.
Синтаксис
Аргументы функции СТАНДОТКЛОН описаны ниже.
Число1 Обязательный. Первый числовой аргумент, соответствующий выборке из генеральной совокупности.
Число2. Необязательный. Числовые аргументы 2—255, соответствующие выборке из генеральной совокупности. Вместо аргументов, разделенных точкой с запятой, можно использовать массив или ссылку на массив.
Замечания
Функция СТАНДОТКЛОН предполагает, что аргументы являются только выборкой из генеральной совокупности. Если данные представляют всю генеральную совокупность, то стандартное отклонение следует вычислять с помощью функции СТАНДОТКЛОНП.
Стандартное отклонение вычисляется с использованием "n-1" метода.
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
Учитываются логические значения и текстовые представления чисел, которые непосредственно введены в список аргументов.
Если аргумент является массивом или ссылкой, то учитываются только числа. Пустые ячейки, логические значения, текст и значения ошибок в массиве или ссылке игнорируются.
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
Чтобы включить логические значения и текстовые представления чисел в ссылку как часть вычисления, используйте функцию СТАНДОТКЛОНА.
Функция СТАНДОТКЛОН вычисляется по следующей формуле:
где x — выборочное среднее СРЗНАЧ(число1,число2,…), а n — размер выборки.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Проведение любого статанализа немыслимо без расчетов. И сегодня в рамках рубрики «Работаем в Excel» мы научимся рассчитывать показатели вариации. Теоретическая основа была рассмотрена ранее в ряде статей о вариации данных. Кстати, на этом указанная тема не закончилась, к выпуску планируются новые статьи – следите за рекламой! Однако сухая теория без инструментов реализации – вещь не сильно полезная. Поэтому по мере появления теоретических выкладок, я стараюсь не отставать с заметками о соответствующих расчетах в программе Excel.
Сегодняшняя публикация будет посвящена расчету в Excel следующих показателей вариации:
Факт возможности расчета упомянутых показателей в Excel свидетельствует о практическом их использовании. И, несмотря на очевидность некоторых моментов, я постараюсь расписать все подробно.
Максимальное и минимальное значение
Начнем с формул максимума и минимума. Что такое максимальное и минимальное значение, уверен, знают почти все. Максимум – самое большое значение из анализируемого набора данных, минимум – самое маленькое (может быть и отрицательным числом). Это крайние значения в совокупности данных, обозначающие границы их вариации. Примеры реального использования каждый может придумать сам – их полно. Это и минимальные/максимальные цены на что-нибудь, и выбор наилучшего или наихудшего решения задачи, и всего, чего угодно. Минимум и максимум – весьма информативные показатели. Давайте теперь их рассчитаем в Excel.
Как нетрудно догадаться, делается сие элементарно – как два клика об асфальт. В Мастере функций следует выбрать: МАКС – для расчета максимального значения, МИН – для расчета минимального значения. Для облегчения поиска перечень всех функций можно отфильтровать по категории «Статистические».

Выбираем нужную формулу, в следующем окошке указываем диапазон данных (в котором ищется максимальное или минимальное значение) и жмем «ОК».
Функции МАКС и МИН достаточно часто используются, поэтому разработчики Экселя предусмотрительно добавили соответствующие кнопки в ленту. Они находятся там же, где суммаи среднее значение – в разворачивающемся списке.

В общем, для вызова функции максимума или минимума действий потребуется не больше, чем для расчета средней арифметической. Все архипросто.
Среднее линейное отклонение
Среднее линейное отклонение, напоминаю, представляет собой среднее из абсолютных (по модулю) отклонений от средней арифметической в анализируемой совокупности данных. Математическая формула имеет вид:

a – среднее линейное отклонение,
x – анализируемый показатель, с черточкой сверху – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
В Excel эта функция называется СРОТКЛ.

После выбора функции СРОТКЛ указываем диапазон данных, по которому должен произойти расчет. Нажимаем «ОК». Наслаждаемся результатом.
Дисперсия

x – анализируемый показатель, с черточкой сверху – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
Excel также предлагает готовую функцию для расчета генеральной дисперсии ДИСП.Г.
При анализе выборочных данных, следует использовать выборочную дисперсию, так как генеральная оказывается смещенной в сторону занижения.
Математическая формула выборочной дисперсии имеет вид:

в Excel выборочная дисперсия рассчитывает через функцию ДИСП.В.

Выбираем в Мастере функций нужную дисперсию (генеральную или выборочную), указываем диапазон, жмем кнопку «ОК». Полученное значение может оказаться очень большим из-за предварительного возведения отклонений в квадрат, поэтому дисперсия сама по себе мало о чем говорит. Ее обычно используют для дальнейших расчетов.
Среднее квадратическое отклонение
Среднеквадратическое отклонение по генеральной совокупности – это корень из генеральной дисперсии.
Выборочное среднеквадратическое отклонение – это корень из выборочной дисперсии.
Для расчета можно извлечь корень из формул дисперсии, указанных чуть выше, но в Excel есть и готовые функции:

С названием этого показателя может возникнуть путаница, т.к. часто можно встретить синоним «стандартное отклонение». Пугаться не нужно – смысл тот же.
Далее, как обычно, указываем нужный диапазон и нажимаем на «ОК». Среднее квадратическое отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными. Об этом ниже.
Коэффициент вариации
Все показатели, рассмотренные выше, имеют привязку к масштабу исходных данных и не позволяют получить образное представление о вариации анализируемой совокупности. Для получения относительной меры разброса данных используют коэффициент вариации, который рассчитывается путем деления среднего квадартического отклонения на среднее арифметическое значение. Математическая формула такова:

В Экселе нет готовой функции для расчета коэффициента вариации, что не есть большая проблема. Расчет можно произвести простым делением стандартного отклонения на среднее значение. Для этого в строке формул пишем:
В скобках должен быть указан диапазон данных. При необходимости используется среднее квадратическое отклонение по выборке (СТАНДОТКЛОН.В).
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на ленте на закладке «Главная»:

Изменить формат также можно, выбрав «Формат ячеек» из выпадающего списка после выделения нужной ячейки правой кнопкой мышки.
Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что если коэффициент вариации менее 33%, то совокупность данных является однородной, если более 33%, то – неоднородной. Эта информация может быть полезна для предварительного описания данных и определения возможностей проведения дальнейшего анализа. Кроме того, коэффициент вариации, измеряемый в процентах, позволяет сравнивать степень разброса различных данных независимо от их масштаба и единиц измерений. Полезное свойство.
В целом, с помощью Excel все, или почти все, статистические показатели рассчитываются очень просто. Если что-то непонятно, всегда можно воспользоваться окошком для поиска в Мастере функций. Ну, и Гугл в помощь.
В этой статье описаны синтаксис формулы и использование функции СТАНДОТКЛОНА в Microsoft Excel.
Описание
Оценивает стандартное отклонение по выборке. Стандартное отклонение — это мера того, насколько широко разбросаны точки данных относительно их среднего.
Синтаксис
Аргументы функции СТАНДОТКЛОНА описаны ниже.
Значение1,значение2. Аргумент "значение1" является обязательным, последующие значения необязательные. От 1 до 255 значений, соответствующих выборке из генеральной совокупности. Вместо аргументов, разделяемых точкой с запятой, можно использовать массив или ссылку на массив.
Замечания
Функция СТАНДОТКЛОНА предполагает, что аргументы являются только выборкой из генеральной совокупности. Если данные представляют всю генеральную совокупность, то стандартное отклонение следует вычислять с помощью функции СТАНДОТКЛОНПА.
Стандартное отклонение вычисляется с использованием "n-1" метода.
Допускаются следующие аргументы: числа; имена, массивы или ссылки, содержащие числа; текстовые представления чисел; логические значения, такие как ИСТИНА и ЛОЖЬ, в ссылке.
Аргументы, содержащие значение ИСТИНА, интерпретируются как 1; аргументы, содержащие текст или значение ЛОЖЬ, интерпретируются как 0 (ноль).
Если аргументом является массив или ссылка, учитываются только значения массива или ссылки. Пустые ячейки и текст в массиве или ссылке игнорируются.
Аргументы, представляющие собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
Чтобы не включать логические значения и текстовые представления чисел в ссылку как часть вычисления, используйте функцию СТАНДОТКЛОН.
Функция СТАНДОТКЛОНА вычисляется по следующей формуле:
где x — выборочное среднее СРЗНАЧ(значение1,значение2,…), а n — размер выборки.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Рассмотрим показатели вариации, приведенные в относительных величинах. Базой для сравнения должна служить средняя арифметическая. Чаще всего относительные показатели выражаются в процентах и определяют не только сравнительную оценку вариации, но и дают характеристику однородности совокупности. Совокупность считается однородной, если коэффициент вариации не превышает 33 % (для распределений, близких к нормальному).
Различают следующие относительные показатели вариации (V):
Коэффициент осцилляции (VR): .
Пример №1 . 1. При выборочном изучении численности жителей в поселках городского типа получены следующие данные:
| Группы поселков с числом жителей, тыс. чел | До 3 | 3-5 | 5-10 | 10-15 | 15 и более | Итого |
| Число поселков | 26 | 25 | 35 | 11 | 13 | 100 |
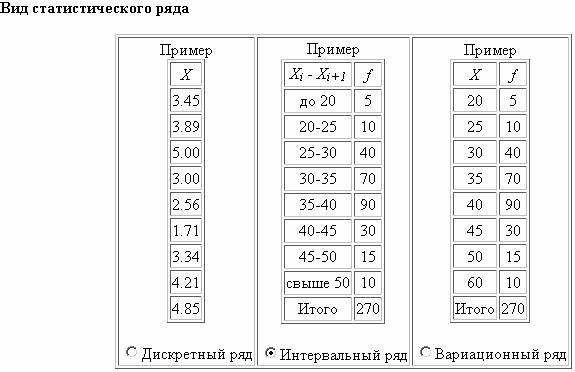
Решение. В разделе «Вид статистического ряда» выбираем Интервальный ряд (рис. 1).
Рисунок 1 – Вид статистического ряда
2. Поскольку в задании пять исходных строк (столбцов), то в поле Количество строк указываем 5. Нажимаем кнопку Далее .
3. На странице ввода данных заполняем исходные данные (рис. 2). При этом открытые интервалы корректируем на закрытые: из открытого интервала «до 3» формируем закрытый 1, из интервала «15 и более» создаем интервал 19.
Рисунок 2 – Ввод исходных данных для расчета показателей вариации
Рисунок 3 - Гистограмма
Рисунок 4 - Полигон
Рисунок 5 - Полигон частот
- Второй столбец x рассчитывается как среднее значение от границ интервалов. Например, (1 + 3)/2 = 2, (3 + 5)/2 = 4.
- Пятый столбец S (кумулята) – накопленное количество f .
- Итоговое значение столбца (x-xср)*f предназначен для расчета средней взвешенной.
- Итоговое значение столбца (x-xср) 2 *f используется при подсчете дисперсии.
- Столбец (x-xср) 3 *f - для показателей асимметрии.
- Столбец (x-xср) 4 *f – для расчета эксцесса.
- Последний столбец (частота) рассчитывается на основании третьего столбца: 26/110 = 0.24, 25/110 = 0.23 и т.д.
По умолчанию в отчет включается расчет следующих показателей вариации:
средняя взвешенная, мода, медиана, абсолютные показатели вариации (размах вариации, среднее линейное отклонение, дисперсия, среднее квадратическое отклонение), относительные показатели вариации (коэффициент вариации, линейный коэффициент вариации).
Примечание: несмещенная оценка дисперсии и оценка среднеквадратического отклонения используются при проверке гипотезы о виде распределения, определении относительной ошибки выборки, и в случаях, когда это непосредственно требуется в задании. Во всех остальных случаях данные показатели можно исключить из отчета.
Пример №2 . Для задач, где требуется предварительно сгруппировать данные, используют сервис Группировка данных .
Число групп приближенно определяется по формуле Стэрджесса
n = 1 + 3,2log n = 1 + 3,2log 50 = 7
Тогда ширина интервала составит:
| Группы | x | Кол-во f | x * f | S | (x - x ср) * f | (x - x ср) 2 * f | (x - x ср) 3 * f | (x - x ср) 4 * f | Частота |
| 32.11 - 37.01 | 34.56 | 1 | 34.56 | 1 | 17.35 | 300.88 | -5219.13 | 90531.01 | 0.02 |
| 37.01 - 41.91 | 39.46 | 5 | 197.31 | 6 | 62.23 | 774.51 | -9639.61 | 119974.57 | 0.1 |
| 41.91 - 46.81 | 44.36 | 6 | 266.17 | 12 | 45.28 | 341.65 | -2578.11 | 19454.43 | 0.12 |
| 46.81 - 51.71 | 49.26 | 12 | 591.14 | 24 | 31.75 | 84.02 | -222.31 | 588.22 | 0.24 |
| 51.71 - 56.61 | 54.16 | 11 | 595.78 | 35 | 24.79 | 55.89 | 125.97 | 283.93 | 0.22 |
| 56.61 - 61.51 | 59.06 | 10 | 590.62 | 45 | 71.54 | 511.8 | 3661.4 | 26193.63 | 0.2 |
| 61.51 - 66.41 | 63.96 | 5 | 319.81 | 50 | 60.27 | 726.49 | 8757.17 | 105558.87 | 0.1 |
| 50 | 2595.39 | 0 | 313.21 | 2795.24 | -5114.63 | 362584.66 | 1 |
Для оценки ряда распределения найдем следующие показатели:
Показатели центра распределения.
Средняя взвешенная
Выбираем в качестве начала интервала 46.81189, так как именно на этот интервал приходится наибольшее количество
Наиболее часто встречающееся значение ряда – 51.01
Медиана
Медиана делит выборку на две части: половина вариант меньше медианы, половина — больше
Таким образом, 50% единиц совокупности будут меньше по величине 52.16
Квартили
Квартили – это значения признака в ранжированном ряду распределения, выбранные таким образом, что 25% единиц совокупности будут меньше по величине Q1; 25% будут заключены между Q1 и Q2; 25% - между Q2 и Q3; остальные 25% превосходят Q3
Таким образом, 25% единиц совокупности будут меньше по величине 47.02
Q2 совпадает с медианой, Q2 = 52.16
Остальные 25% превосходят значение 57.84.
Квартильный коэффициент дифференциации.
k = Q1 / Q3
k = 47.02 / 57.84 = 0.81
Децили (децентили)
Децили – это значения признака в ранжированном ряду распределения, выбранные таким образом, что 10% единиц совокупности будут меньше по величине D1; 80% будут заключены между D1 и D9; остальные 10% превосходят D9
Таким образом, 10% единиц совокупности будут меньше по величине 40.93
Остальные 10% превосходят 61.51
Расчет показателей вариации
Размах вариации
R = Xmax - Xmin
R = 66.39923 - 32.11189 = 34.29
Среднее линейное отклонение
Каждое значение ряда отличается от другого не более, чем на 6.26
Дисперсия
Несмещенная оценка дисперсии.
Среднее квадратическое отклонение.
Каждое значение ряда отличается от среднего значения 51.91 не более, чем на 7.48
Оценка среднеквадратического отклонения.
Поскольку v<30%, то совокупность однородна, а вариация слабая. Полученным результатам можно доверять.
Показатели формы распределения.
Коэффициент осцилляции
Относительное линейное отклонение
Относительный показатель квартильной вариации
Степень асимметрии
Симметричным является распределение, в котором частоты любых двух вариантов, равностоящих в обе стороны от центра распределения, равны между собой.
Отрицательный знак свидетельствует о наличии левосторонней асимметрии
Для симметричных распределений рассчитывается показатель эксцесса (островершинности). Эксцесс представляет собой выпад вершины эмпирического распределения вверх или вниз от вершины кривой нормального распределения.
Ex > 0 - островершинное распределение
Интервальное оценивание центра генеральной совокупности.
Доверительный интервал для генерального среднего
(57.05 – 7,87; 57.05 + 7,87)
(49.18; 64.92)
Интервальное оценивание генеральной доли (вероятности события).
Доверительный интервал для генеральной доли.
- по выборке:
- среднее значение;
- моду и медиану;
- показатели вариации: размах вариации, среднее линейное отклонение, среднее квадратическое отклонение, коэффициент вариации;
- с вероятностью 0.954 пределы, в которых можно ожидать среднюю и долю более 1,5 лет;
- необходимую численность выборки при определении средней, чтобы с вероятностью 0.997 предельная ошибка выборки не превысила 3.
Типы вариации
Вариация – колеблемость или изменяемость величин признака у единиц совокупности.Под вариацией в пространстве понимается колеблемость значений признака по отдельным территориям.
Под вариацией во времени подразумевают изменение значений признака в различные моменты времени. Так, со временем изменяются средняя продолжительность жизни, мнения людей и т.д.
Меры вариации
Колеблемость или изменяемость величин признака у единиц совокупности называется вариацией.Вариация порождается комплексом условий, действующих на совокупность и ее единицы. Например, вариация оценок на экзамене в вузе порождается различными способностями студентов, неодинаковым временем, затрачиваемым на самостоятельную работу, различием социально-бытовых условий и т.д.
Вариация существует и в пространстве и во времени.
Под вариацией в пространстве понимается колеблемость значений признака по отдельным территориям.
Под вариацией во времени подразумевают изменение значений признака в различные моменты времени. Так, со временем изменяются средняя продолжительность жизни, мнения людей и т.д.
Показатели вариации делятся на две группы: абсолютные и относительные.
К абсолютным относятся размах вариации, среднее линейное отклонение, дисперсия и среднеквадратическое отклонение. Вторая группа показателей вычисляется, как отношение абсолютных показателей к средней арифметической (медиане).
Относительными показателями вариации являются коэффициенты осцилляции, вариации, относительное линейное отклонение и др.
Простой абсолютный показатель - размах вариации (R). Размах вариации рассчитывается как разность между наибольшим (Xmax) и наименьшим (Xmin) значениями варьирующего признака, т.е. R=Xmax-Xmin..
Прежде, чем определить величину размаха вариации необходимо очистить совокупность от аномальных наблюдений.
Например, нельзя вычислять размах вариации работников какого-либо частного предприятия, если наряду с заработками его работников включен заработок его владельца.
Размах вариации – важный показатель колеблемости признака, но не исчерпывающий его характеристику.
Рассмотрим среднее линейное отклонение. Оно вычисляется как средняя арифметическая из абсолютных значений отклонений вариант xi от по формуле:
Цель данной статьи показать, как математические формулы, с которыми вы можете столкнуться в книгах и статьях, разложить на элементарные функции в Excel.
В данной статье мы разберем формулы среднеквадратического отклонения и дисперсии и рассчитаем их в Excel.
Перед тем как переходить к расчету среднеквадратического отклонения и разбирать формулу, желательно разобраться в элементарных статистических показателях и обозначениях.
Рассматривая формулы моделей прогнозирования, мы встретимся со следующими показателями:

Например, у нас есть временной ряд - продажи по неделям в шт.
Для этого временного ряда i=1, n=10 , ,
Рассмотрим формулу среднего значения:
Для нашего временного ряда определим среднее значение
Также для выявления тенденций помимо среднего значения представляет интерес и то, насколько наблюдения разбросаны относительно среднего. Среднеквадратическое отклонение показывает меру отклонения наблюдений относительно среднего.
Формула расчета среднеквадратического отклонение для выборки следующая:
Разложим формулу на составные части и рассчитаем среднеквадратическое отклонение в Excel на примере нашего временного ряда.
1. Рассчитаем среднее значение для этого воспользуемся формулой Excel =СРЗНАЧ(B11:K11)
= СРЗНАЧ(ссылка на диапазон) = 100/10=10

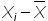
2. Определим отклонение каждого значения ряда относительно среднего

для первой недели = 6-10=-4
для второй недели = 10-10=0
для третей = 7-1=-3 и т.д.
3. Для каждого значения ряда определим квадрат разницы отклонения значений ряда относительно среднего
для первой недели = (-4)^2=16
для второй недели = 0^2=0
для третей = (-3)^2=9 и т.д.
4. Рассчитаем сумму квадратов отклонений значений относительно среднего с помощью формулы =СУММ(ссылка на диапазон (ссылка на диапазон с )

=16+0+9+4+16+16+4+9+0+16=90
5. , для этого сумму квадратов отклонений значений относительно среднего разделим на количество значений минус единица (Сумма((Xi-Xср)^2))/(n-1)

= 90/(10-1)=10
6. Среднеквадратическое отклонение равно = корень(10)=3,2
Итак, в 6 шагов мы разложили сложную математическую формулу, надеюсь вам удалось разобраться со всеми частями формулы и вы сможете самостоятельно разобраться в других формулах.
Рассмотрим еще один показатель, который в будущем нам понадобятся - дисперсия.
Как рассчитать дисперсию в Excel?
Дисперсия - квадрат среднеквадратического отклонения и отражает разброс данных относительно среднего.
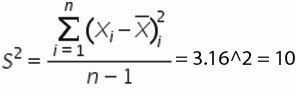
Рассчитаем дисперсию:

Итак, теперь мы умеем рассчитывать среднеквадратическое отклонение и дисперсию в Excel. Надеемся, полученные знания пригодятся вам в работе.
Точных вам прогнозов!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite - автоматический расчет прогноза в Excel .
- 4analytics - ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition - BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO - прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Читайте также: