
Удалить узел xml 1с
Обновлено: 04.07.2024
Document Object Model (DOM) представляет XML-документ в виде создаваемого в памяти дерева объектов (узлов), определяющих структуру XML. Создание дерева объектов в памяти является удобным способом работы с данными, но ограничивается ее доступным объемом. Таким образом, применение DOM отлично подходит при работе с небольшими XML документами.
XML-документ в ABL DOM представляется объектом X-DOCUMENT.
DEF VAR hDocument AS HANDLE NO-UNDO.
CREATE X-DOCUMENT hDocument.
XML-узлы, представляются объектами X-NODEREF.
DEFINE VARIABLE hNode AS HANDLE NO-UNDO.
CREATE X-NODEREF hNode.
XML-узлы разделяются по типу. Каждому XML-узлу указывается его тип, который определяет его характеристики и функциональность. Различаются следующие типы узлов:
- ATTRIBUTE;
- CDATA-SECTION;
- COMMENT;
- DOCUMENT-FRAGMENT;
- ELEMENT;
- ENTITY-REFERENCE;
- PROCESSING-INSTRUCTION;
- TEXT.
В качестве примера, рассмотрим XML-документ test.xml:
В DOM данный документ представляется следующим деревом объектов:
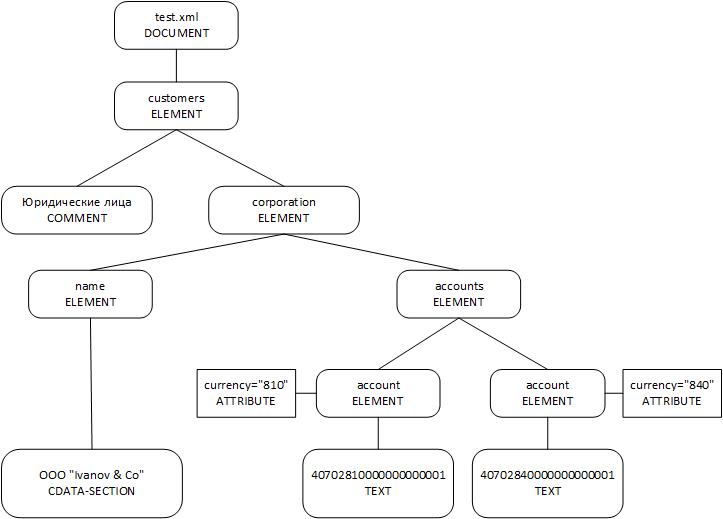
Каждый узел имеет своего единственного "родителя" (узел, располагающийся непосредственно над ним). Родительские узлы, в свою очередь, обладают так называемыми дочерними узлами (узлами, расположенными непосредственно под ними). У одного "родителя" может быть несколько дочерних узлов, при этом, каждый из них имеет свой порядковый номер начиная с 1.
На основе таких родительско-дочерних связей и формируется DOM структура XML-документа.
Стоит отметить, что атрибуты (узлы с типом ATTRIBUTE) не являются ни чьими дочерними или родительскими узлами, а относятся непосредственно к узлу элементу (узел с типом ELEMENT).
После завершения работы все созданные объекты должны быть удалены.
DELETE OBJECT hDocument.
DELETE OBJECT hNode.
Работа с XML-документом осуществляется с помощью атрибутов и методов объектов X-DOCUMENT и X-NODEREF.
ADD-SCHEMA-LOCATION(targetNamespace, location) - данный метод определяет расположение XML-схемы валидации XML-документа посредством пространства имен и физического расположения файла XML-схемы.
- targetNamespace - пространство имен, значение CHARACTER типа;
- location - значение CHARACTER типа, определяющее расположение файла XML-схемы.
APPEND-CHILD(x-node-handle) - добавляет существующий узел как последний дочерний узел в структуре XML задаваемого родительского узла. Другими словами данный метод осуществляет размещение существующего узла, открепленного раннее от структуры XML, или созданного с помощью методов CREATE-NODE(), CREATE-NODE-NAMESPACE() или CLONE-NODE().
- x-node-handle - handle X-NODREF объекта добавляемого узла.
CREATE-NODE(x-node-handle, name, type) - создает узел в текущем XML-документе.
- x-node-handle - handle X-NODREF объекта , в который будет записан указатель создаваемого нового узла.
- name - имя создаваемого узла, тип CHARACTER;
- type - SUBTYPE создаваемого элемента, тип CHARACTER.
CREATE-NODE-NAMESPACE(x-node-handle, namespace-uri, qualified-name, type) - задает пространство имен документа. Может быть заданно как в простом виде - y, так и в составном - x:y.
- x-node-handle - handle X-NODREF объекта, в который будет записан указатель создаваемого нового узла;
- namespace-uri - Uniform Resource Identifier (URI) пространства имен, CHARACTER типа;
- qualified-name -
- type - SUBTYPE узла, может принимать значение ELEMENT или ATTRIBUTE.
GET-CHILD(x-node-handle, index) - возвращает handle дочернего узла с порядковым номером index.
- x-node-handle - handle возвращаемого узла;
- index - порядковый номер узла.
GET-DOCUMENT-ELEMENT(x-node-handle) - возвращает handle X-NODEREF корневого элемента XML-документа.
IMPORT-NODE(x-node, x-source-node, deep) - данный метод осуществляет импорт узла из другого XML-документа, но не размещает его в структуре XML. После того как новый узел импортирован, его необходимо включить в структуру XML с помощью методов APPEND-CHILD() или INSERT-BEFORE().
- x-node - handle предварительно созданного X-NODREF объекта, в который будет осуществляться импорт;
- x-source-node - handle импортируемого X-NODREF объекта;
- deep - значение LOGICAL типа, определяющее осуществлять импорт всего поддерева элемента (TRUE) или импортировать только непосредственно сам элемент (FALSE). З начением по умолчанию является FALSE.
INSERT-BEFORE(x-ref-handle1, x-ref-handle2) - осуществляет добавление узла в структуру XML как дочернего по отношению к тому узлу, чей метод вызывается и размещаемого после указываемого другого дочернего узла этого же родителя. Если узел, за которым должен быть размещен добавляемый элемент не указан, то он будет последним дочерним узлом.
- x-ref-handle1 - handle объекта X-NODREF имеющегося в структуре узла, за которым необходимо разместить добавляемый в структуру узел;
- x-ref-handle2 - handle объекта X-NODREF добавляемого узла. Данный узел должен быть предварительно создан.
LOAD(mode < file | memptr | longchar >, validate) - осуществляет загрузку XML-документа из указываемого источника в память, разбирает его и формирует X-DOCUMENT для последующей работы с ним.
- mode - значение CHARACTER типа, определяющие тип источника XML-документа. Может принимать следующие значения: "FILE", "MEMPTR", или " LONGCHAR";
- < file | memptr | longchar > - идентификатор источника данных. Для файла - это его полный или относительный путь, для переменных - идентификатор переменной и т.д;
- validate - значение LOGICAL типа, определяющие осуществлять валидацию загружаемого XML-документа (TRUE), или не осуществлять ее (FALSE).
REMOVE-CHILD(x-node-handle) - открепляет узел и все его поддерево от структуры XML-документа. Сам узел при этом не удаляется, а остается в памяти.
- x-node-handle - handle X-NODREF объекта открепляемого узла .
REPLACE-CHILD(new-handle, old-handle) - осуществляет замещение одного узла другим. При этом замещаемый узел только открепляется от структуры XML-документа, а не удаляется. Если замещающий узел находится в структуре XML-документа, то он первоначально открепляется от документа, а после прикрепляется на место замещаемого.
- new-handle - handle X-NODREF объекта замещающего узла ;
- old-handle - handle X-NODREF объекта замещаемого узла.
SAVE(mode, < file | stream | stream-handle | memptr | longchar >) - осуществляет формирование и вывод текста XML-документа из X-DOCUMENT.
- mode - значение CHARACTER типа, определяющие тип приемника XML-документа. Может принимать следующие значения: "FILE", "STREAM", "STREAM-HANDLE", "MEMPTR", или "LONGCHAR";
- < file | stream | stream-handle | memptr | longchar > - определение приемника XML-документа.
CLONE-NODE(x-node-handle, deep) - осуществляет клонирование текущего узла.
- x-node-handle - handle предварительно созданного X-NODREF объекта, в который будет осуществляться клонирование;
- deep - значение LOGICAL типа, отражающее клонировать все дерево узла (TRUE), или только сам узел (FALSE). Значением по умолчанию является FALSE.
DELETE-NODE() - открепляет узел от структуры XML и удаляет его из памяти.
GET-ATTRIBUTE(name) - возвращает значение указанного атрибута элемента.
GET-ATTRIBUTE-NODE(attr-node-handle, name) - возвращает handle указанного атрибута элемента.
- attr-node-handle - handle возвращаемого атрибута;
- name - имя возвращаемого атрибута, тип CHARACTER.
GET-PARENT(x-node-handle) - возвращает handle родителя. Для корневого элемента XML возвращается неизвестное значение (?).
- x-node-handle - handle возвращаемого родительского узла.
LONGCHAR-TO-NODE-VALUE(longchar) - метод присвоения значения LONGCHAR типа атрибуту X-NODEREF:NODE-VALUE .
- longchar - присваиваемое значение LOGNCHAR типа.
MEMPTR-TO-NODE-VALUE(memptr) - метод присвоения значения MEMPTR типа атрибуту X-NODEREF:NODE-VALUE .
NODE-VALUE-TO-LONGCHAR(longchar [codepage]) - метод вывода значения X-NODEREF:NODE-VALUE с преобразованием значения в LONGCHAR тип в указываемой текстовой кодировке.
- longchar - приемник значения, тип LONGCHAR;
- codepage - текстовая кодировка, тип CHARCTER.
NODE-VALUE-TO-MEMPTR(memptr) - метод вывода значения X-NODEREF:NODE-VALUE с преобразованием значения в тип MEMPTR .
REMOVE-ATTRIBUTE(attribute-name | index> [, namespaceURI]) - удаляет атрибут элемента. Если удаляемому атрибуту определено начальное значение в описании DTD, то он устанавливается для атрибута.
- attribute-name - имя атрибута, тип CHARACTER;
- index - порядковый номер атрибута в списке атрибутов элемента (нумерация начинается с 1), тип INTEGER;
- namespaceURI - URI пространства имен элемента, тип CHARACTER.
SET-ATTRIBUTE(name, value) - добавляет атрибут элементу. Если атрибут с таким именем уже существует у элемента, то его значение заменятся значением добавляемого атрибута .
Метод removeChild() удаляет заданный узел.
Метод removeAttribute() удаляет заданный атрибут.
Удаление узла элемента
Метод removeChild() удаляет заданный узел.
Когда узел удаляется, все его дочерние узлы также удаляются.
Следующий код удалит первый элемент <book> из загруженного XML документа:
- Предположим, что файл books.xml был загружен в переменную xmlDoc
- Сохраняем в переменной "y" узел элемента, который нужно удалить
- Удаляем узел элемента с помощью метода removeChild() из родительского узла
Удалить себя - Удаление текущего узла
Метод removeChild() - единственный способ удалить заданный узел.
Когда вы перешли к узлу, который необходимо удалить, этот узел можно удалить с помощью свойства parentNode и метода removeChild():
- Предположим, что файл books.xml был загружен в переменную xmlDoc
- Сохраняем в переменной "x" узел элемента, который нужно удалить
- Удаляем узел элемента с помощью свойства parentNode и метода removeChild()
Удаление текстового узла
Метод removeChild() также можно использовать для удаления текстового узла:
- Предположим, что файл books.xml был загружен в переменную xmlDoc
- Сохраняем в переменной "x" первый элемент title
- Сохраняем в переменной "y" текстовый узел, который нужно удалить
- Удаляем узел элемента с помощью метода removeChild() из родительского узла
Только для удаления текста из узла метод removeChild() используется довольно редко. Вместо этого можно использовать свойство nodeValue.
Очистка текстового узла
Свойство nodeValue можно использовать для изменения значения текстового узла:
- Предположим, что файл books.xml был загружен в переменную xmlDoc
- Получаем первый дочерний узел первого элемента title
- Используем свойство nodeValue, чтобы очистить текстовое значение текстового узла
Удаление узла атрибута по имени
Метод removeAttribute() удаляет узел атрибута по его имени.
Следующий код удаляет атрибут "category" в первом элементе <book>:
- Предположим, что файл books.xml был загружен в переменную xmlDoc
- При помощи метода getElementsByTagName() получаем список узлов элементов book
- Удаляем атрибут "category" у первого узла элемента book книги.
Удаление узла атрибута через объект
Метод removeAttributeNode() удаляет узел атрибута, используя объект узла в качестве параметра.
XML DOM Аннотация 3 (увеличение узла DOM XML, удаление, изменение, проверка)
Найдите DOM Node
Узлы в дереве узла обращаются через взаимосвязь между узлами, обычно называемыми узлами позиционирования («навигационные узлы»).
В XML DOM отношения между узлами определяются как свойства узла:
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
Изображение ниже показываетbooks.xmlЧасть дерева китайского узла и иллюстрирует связь между узлами:

Дом - родительский узел
Все узлы имеют только один родительский узел. Следующий код расположен для родителя <Книга>:
Избегайте пустых текстовых узлов
Firefox, а также некоторые другие браузеры, пустые пустые или обертывания в качестве текстовых узлов, а IE не сделают этого.
Это будет использовать следующие свойства для создания вопроса: перфорид, lathchild, nextsibling, предыдущий страхование.
Чтобы избежать позиционирования пустого текстового узла (пробел между узлами элемента и символом Wrap), мы используем функцию для проверки типа узла:
С вышеуказанными функциями мы можем использовать Get_nextsibling (Node) вместо свойства Node.nextsBling.
Получить значение элемента
В DOM каждый ингредиент является узлом. Узел элемента не имеет текстового значения.
Текст узла элемента хранятся в уземе ребенка. Этот узел называется текстовым узлом.
Способ получения текста элемента состоит в том, чтобы получить значение этого подстережения (текстовый узел).
Получить значение элемента
Метод GetElementsByTagname () возвращает список списков узлов, которые содержат все элементы указанного имени тега, где порядка элементов является порядок, в котором они появляются в исходном документе.
Свойство Childnodes возвращает список дочерних узлов. У элемента <title> есть только один узел для ребенка, то есть текстовый узел.
Следующий код извлекает текстовый узел элемента <title>:
Свойство NODEVALUE возвращает текстовое значение текстового узла:
Получить ценность собственности
В DOM атрибут также является узлом. В отличие от узлов элементов, узел атрибута имеет текстовое значение.
Способ получения значения атрибута состоит в том, чтобы получить его текстовое значение.
Эта задача может быть достигнута с помощью метода GetAttribute () или свойство NODEVALUE узла свойств.
Получить значения атрибутов - GetAttribute ()
Метод GetAttribute () Возвращает значение свойства.
Следующий код извлекает текстовое значение свойства «lang» первого элемента <title>:
Получить значения атрибутов - GetAttributenode ()
Метод getattributenode () Возвращает узел свойств.
Следующий код извлекает текстовое значение свойства «lang» первого элемента <title>:
Изменить значение элемента
В DOM каждый ингредиент является узлом. Узел элемента не имеет текстового значения.
Текст узла элемента хранятся в уземе ребенка. Этот узел называется текстовым узлом.
Способ изменения текста элемента состоит в том, чтобы изменить значение этого подстережения (текстовый узел).
Измените значение текстового узла
Свойство NODEVALUE можно использовать для изменения значения текстового узла.
Следующий фрагмент кода меняет первое значение <title> Element Text Node:
Измените значение атрибута
В DOM атрибут также является узлом. В отличие от узлов элементов, узел атрибута имеет текстовое значение.
Способ изменения значения свойства состоит в том, чтобы изменить его текстовое значение.
Эта задача может быть выполнена с помощью метода SetAttribute () или свойство NODEVALUE узла атрибута.
Измените свойства с помощью SetAttribute ()
Метод SetAttribute () Устанавливает значение существующих свойств или создание новых свойств.
Следующий код меняет свойство категории элемента <книги>:
Примечание. Если узел свойств не существует, создайте новый атрибут (с указанным именем и значением).
Изменить свойство, используя NODEVALUE
Свойство NODEVALUE можно использовать для изменения значения узла свойств:
Удалить узел Element
Способ Removechild () Удаляет указанный узел.
Когда узел удален, все подтики также удаляются.
Следующий фрагмент кода удалит первый элемент <Book> из загруженного XML:
Удалить сам - удалить текущий узел
Метод Removechild () - единственный способ удалить указанный узел.
Когда вы найдете узел, который вам нужно удалить, вы можете удалить этот узел с помощью свойства Parentnode и метода RemoveChild ():
Удалить текстовый узел
Способ Removechild () можно использовать для удаления текстовых узлов:
Примечание. Текст удаляется из узла, необычайно используя RemoveChild (). Вы можете использовать свойство NODEVALUE вместо этого. Пожалуйста, смотрите следующий абзац.
Пустой текстовый узел
Свойство NODEVALUE можно использовать для изменения или очистки значения текстового узла:
Удалите узел свойств в соответствии с именем
Для удаления узла свойств используется метод RemovEattribute (name), используемый для удаления узла свойств на основе имени.
Следующий фрагмент кода удаляет атрибут «Категория» в первом элементе <Book>:
Удалить узлу свойства в соответствии с объектом
Метод Removettributenode (Node) удаляет узел свойств с помощью объекта узла в качестве параметра.
Следующий фрагмент кода удаляет все свойства всех элементов <Book>:
Узел альтернативного элемента
Метод refracechild () используется для замены узла.
Следующий фрагмент кода заменяет первый элемент <Book>:
Замените данные в текстовый узел
Метод FLASECANDATA () используется для замены данных в текстовом узле.
Метод заменена () имеет три параметра:
- Смещение - где начать замену символов. Значение смещения начинается с 0.
- Длина - сколько персонажей хочет заменить?
- Строка - строка, которая должна быть вставлена
Используйте свойство NODEVALUE
Свойство NODEVALUE для замены данных в текстовом узле проще.
Следующий фрагмент кода заменит значение текстового узла в первый элемент <Title> с «Easy Imalian»:
Создать новый узел элемента
Способ CreateEdement () Создает новый узел элемента:
Создайте новый узел недвижимости
CreateAttribute () используется для создания нового узла атрибута:
Примечание. Если это свойство уже существует, он заменяется новым атрибутом.
Создание свойств с помощью SetAttribute ()
Поскольку SetAttribute () может создавать новые свойства без экземпляра, мы можем использовать этот метод для создания новых свойств.
Создать текстовый узел
Метод CreateTextNode () создает новый текстовый узел:
Создать узел секции CDATA
Метод CreatecDataSection () создает новый узел секции CDATA.
Создать узл комментариев
Метод CreateComment () создает новый узел примечания.
Добавить узел - AppendChild ()
Способ AppendChild () добавляет узел ребенка к существующему узлу.
Новый узел добавит (дополнительно) к любому существующему узеру дочернего ребенка.
Примечание. Если местонахождение узла важно, используйте метод insertbefore ().
Следующий фрагмент кода создает элемент (<Edition>) и добавить его в первую <книгу> Элемент последнего ребенка:
Вставьте узел - insertbefore ()
Способ insertyfore () используется для вставки узлов перед указанным узел для ребенка.
Этот метод полезен, когда расположение добавленных узлов очень важно.
Примечание. Если второй параметр insertefore () является NULL, новый узел будет добавлен к последнему существующему узеру дочернего ребенка.
x.insertBefore(newNode,null) с участием x.appendChild(newNode)Можно добавить новый ребенок в х
Добавить новые атрибуты
Addaribute () Этот метод не существует.
Если атрибут не существует, SELTYBUTE () может создать новую недвижимость:
Примечание. Если свойство уже существует, метод SetAttribute () перезапишет существующее значение.
Добавить текст в текстовые узлы - insertData ()
Способ insertata () вставляет данные в существующий текстовый узел.
Способ insertata () имеет два параметра:
- Смещение - где начать вставлять символы (начиная с 0)
- Строка - строка, которая должна быть вставлена
Следующий фрагмент кода добавит «простой» в текстовый узел первого <title> элемента загруженного XML:
Копировать узел
Способ Clonenode () создает копию указанного узла.
Метод Clonenode () имеет параметр (true или false). Этот параметр указывает, включает ли реплицированный узел все атрибуты и субтоты исходного узла.
Следующий фрагмент кода копирует первую <книгу> узел и добавить его в корневой узел документа:

Порой при обмене данных получается ситуация когда из удаленного узла необходимо удалить определенные объекты и сделать это непосредственно очень проблематично. Возможные варианты решения такой проблемы рассматриваются в данной статье. Необходимо заметить, что в целом рассматривается ситуация с распределенными информационными базами (РИБ).
Конкретная ситуация: по некоторым причинам необходимо по обмену (а если бы был прямой или удаленный доступ к удаленной базе, то вопрос бы просто отсутствовал) удалить некоторый объект из удаленной базы данных (БД).
Вариант 1. Использование объекта УдалениеОбъекта. Суть – находим ссылку на объект и по обмену посылаем в удаленную базу. Что-то вроде этого:
Но с данным кодом возникнет следующая проблема – при наличии строки Удаление.Записать(); будет удален объект в текущей базе (а это не нужно). При отсутствии строки Удаление.Записать(); в удаленной базе данные останутся, то есть задача не будет решена.
Вот если в текущей БД нет такого объекта , то можно использовать следующее:
Примечание: в 1С8 следует различать УникальныйИдентификатор (UUID) и глобальный уникальный идентификатор (GUID). При необходимости в сети можно найти код преобразования UUID в GUID и обратно.
В итоге получаем, что данный вариант подходит для случаев когда в удаленном узле необходимо удалить объекты, которые отсутсвуют в текущем узле.
Необходимо учесть ситуацию, что в удаленном узле объект присутствует в других объектах (то есть, удалили номенклатуру «Валенки», а этот элемент присутствует в документах удаленного узла). Тут уже надо думать либо о восстановлении элемента в текущей базе либо предусмотреть замену удаляемого элемента на другой элемент.
Но зачастую требуется удалить объект в удаленной БД, но в текущей БД он должен остаться.
Вариант 2. Муторный и не правильный.
Вариант 3. Требуется вносить изменения в конфигуратор.
В модуле плана обмена в обработчике ПриОтправкеДанныхПодчиненному и/или ПриОтправкеДанныхГлавному отлавливаем нужные объекты и для них передаём Удаление.
Например:
Процедура ПриОтправкеДанныхПодчиненному(ЭлементДанных, ОтправкаЭлемента, СозданиеНачальногоОбраза)
Если ЭтоНужныйОбъект Тогда
ОтправкаЭлемента = ОтправкаЭлементаДанных.Удалить;
КонецЕсли;
КонецПроцедуры
Примечание: для универсальности возможен такой вариант. В план обмена вводим реквизит ВыполняемыйКод, тип строка неограниченной длины. В этот реквизит оперативно вставляется неоходимый программный код. Опять же следует учесть что процедура ПриОтправкеДанныхПодчиненному и ПриОтправкеДанныхГлавному срабатывает для КАЖДОГО отправляемого элемента.
Процедура ПриОтправкеДанныхПодчиненному(ЭлементДанных, ОтправкаЭлемента, СозданиеНачальногоОбраза)
Попытка
Выполнить(ВыполняемыйКод);
Исключение
КонецПопытки;
КонецПроцедуры
Вариант 4. Самостоятельно формировать файл XML.
Если Не ВыгружаемыйОбъект.ОтражатьВБухгалтерскомУчете Тогда
А теперь подводные камни.
Если вы желаете удалить некоторый объект, то помните, что на этот объект могут быть завязаны и другие объекты в базе данных. Например – подчиненные справочники, движения документа, независимые регистры сведений и т.д., то есть те объекты которые не имеют смысла при отсутствии удаляемого объекта. Часть объектов можно найти достаточно просто (подчиненные справочники, движения документа, регистры сведений где объект является ведущим измерением), а вот некоторые достаточно проблематично, так как необходимо просматривать каждый объект и смотреть в коде какие изменения он вносит в БД при записи и/или проведении.
И последний совет. Если расхождения в удаленной БД достаточно велики по сравнению с текущей БД, то гораздо быстрее и проще заново создать БД удаленного узла.
Читайте также: