
Уровень надежности в excel что значит
Обновлено: 07.07.2024
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Трущелёв Сергей Андреевич
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Трущелёв Сергей Андреевич
Базовые методы описательной статистики в микробиологических исследованиях Исследование степени однородности цементогрунтовой смеси методом математической статистики Общие вопросы методологии статистического анализа: типы данных и алгоритмы подбора методов Педагогический эксперимент и средства описательной статистики i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.Descriptive statistics using the Data Analysis Toolpak in Microsoft Excel
The paper presents a definition of descriptive statistics , and its main indicators. The necessity of their calculation is set out step by step in the procedure of statistical analysis. The message is a training component with.
Текст научной работы на тему «Решение задач описательной статистики средствами пакета анализа Microsoft Excel»
МЕТОДОЛОГИЯ НАУЧНО-ИССЛЕДОВАТЕЛЬСКОЙ ДЕЯТЕЛЬНОСТИ
В связи с возрастающими требованиями к качеству публикаций результатов научно-исследовательских работ в «Российском психиатрическом журнале» открыта новая рубрика «Методология научно-исследовательской деятельности». Планируется публикация обучающих и информационно-разъяснительных материалов по разным разделам науковедения, организации научной работы, биоинформатике, биостатистике, биоэтике и т.д. Приглашаем ученых и исследователей поделиться опытом в этой области. Надеемся, что наша инициатива будет поддержана не только в научном сообществе, но и воспринята в среде практикующих специалистов.
© С.А. Трущелёв, 2013 Для корреспонденции
УДК 311:004 Трущелёв Сергей Андреевич - кандидат медицинских наук,
доцент, ведущий научный сотрудник ФГБУ «Московский научно-исследовательский институт психиатрии Минздрава России»
Решение задач описательной статистики средствами пакета анализа Microsoft Excel
Descriptive statistics using the Data Analysis Toolpak in Microsoft Excel
The paper presents a definition of descriptive statistics, and its main indicators. The necessity of their calculation is set out step by step in the procedure of statistical analysis. The message is a training component with. Key words: science of science, biostatistics, descriptive statistics, data analysis toolpak, Excel
ФГБУ «Московский научно-исследовательский институт психиатрии Минздрава России»
Moscow Research Institute of Psychiatry
Ключевые слова: науковедение, биостатистика, описательная статистика, пакет анализа, Excel
Каждое явление (предмет исследования) определяется многими факторами. В научном исследовании полностью учесть все факторы и обеспечить их стабильность удается редко. Следовательно, явление, определяемое этими факторами, не поддается точному предсказанию - оно приобретает вероятностные черты, т.е. ведет себя случайным образом. Этому подвержены многие явления, поэтому они определяются случайной величиной, которая принимает в результате опыта или наблюдения одно из множества значений. Случайные величины могут быть дискретными (прерывными) и непрерывными. Немаловажно их распределение - правило, которое устанавливает связь между значениями случайной величины и вероятностями (частотами) их появления.
Наглядное представление о распределении случайных величин дает разброс песчинок, образующих кучу при высыпании (рассеивании) из некоторого точечного источника. Его проекция является параметром положения и соответствует математическому ожиданию распределения, если куча симметрична. Разброс песчинок (параметр рассеяния) характеризуется радиусом кучи на высоте примерно 2/3. Такой параметр рассеяния соответствует так называемому стандартному (среднеквадратичному) отклонению случайных величин в распределении. Горизонтальные расстояния песчинок от проекции источника (математического ожидания) моделируют рассеяние случайной величины. Поверхность кучи (ее высоты) соответствует частоте случайных величин на разных расстояниях от центра. Вершина кучи, расположенная под источником, отвечает максимуму частоты. На периферии высота кучи уменьшается до нуля, что соответствует уменьшению частот больших отклонений от центра рассеяния. Статистическая обработка совокупности данных состоит в некоторых осредняющих вычислительных процедурах, погашающих сугубо индивидуальные особенности - отклонения от общей закономерности и подчеркивающих типичные (популяцион-ные) свойства явления в целом. Начальный раздел математической статистики - описательная статистика - занимается характеристикой (описанием) картины случайного рассеяния по совокупности данных. В соответствии с законом распределения данных решаются вопросы выбора и вычислений надлежащих показателей. Описательная статистика включает методы организации, суммирования и описания данных. Дескриптивные (от англ. descriptive - описательный) показатели позволяют быстро обобщать данные. К описательным методам относят частотные распределения, меры централь-
ной тенденции и меры относительного положения [4, с. 95].
К основным показателям описательной статистики относятся среднее значение (среднее арифметическое, медиана, мода), усредненное значение, разброс (диапазон разброса данных), дисперсия, стандартное среднеквадратное отклонение (СКО), квартили, доверительный интервал [2, с. 28].
Статистическая обработка результатов исследований и получение показателей описательной статистики в недалеком прошлом обычно занимали много времени, однако с внедрением средств компьютерной техники многое изменилось - вычислительные процессы стали происходить очень быстро. Для проведения статистических расчетов в электронной таблице Microsoft Excel имеется пакет анализа. Надстройка «Анализ данных» располагается во вкладке «Данные», в крайне правом блоке ленты (рис. 1).
Для демонстрации вычислений будем использовать гипотетический набор данных. Далее приведем пошаговую инструкцию по созданию описательной статистики признака (показателя систолического давления), измеренного до лечения и после него, в группе наблюдения (n=60).
Для проведения вычисления обратитесь к ленте: Данные ^ Анализ данных ^ Описательная статистика ^ ОК. Затем, перейдя в окно инструмента, выберите входной интервал, группирование (по столбцам), поставьте галочку, если в первой строке выделены метки; в параметрах вывода на поле электронной страницы выберите ячейку вывода результатов, установите галочку рядом с итоговой статистикой. Потом нажмите кнопку ОК. После этого вы получите результаты описательной статистики выбранных признаков (рис. 2 и 3).
А в с D Е F G У 1 J К 1 L _
1 Номер_исс Признак_1 Признак_2 у
3 2 178 143 Анализ данным lia
Инструменты анализа У _ 1 о, 1
4 3 320 188 Двухфакторный дисперсионный^нализ без повторений Корреляция Л* 3 J d Отмена |
6 5 159 161 Экспоненциальное сглаживание Двухвыборочный Р-тест для дисперсии Анализ Фурье Гистограмма Скользящее среднее 1 Генерация случайных чисел_| Справка
Рис. 1. Пошаговый выбор инструмента анализа данных
Рис. 2. Окно инструмента описательной статистики
Среднее (арифметическое; М; х ) - одна из наиболее распространенных мер центральной тенденции, представляющая собой сумму всех значений, деленную на их количество. Если значения интересующего нас признака у большинства объектов близки к их среднему и с равной вероятностью отклоняются от него в большую или меньшую сторону, лучшими характеристиками совокупности будут само среднее значение и стандартное отклонение. Напротив, когда значения признака распределены несимметрично относительно среднего, совокупность лучше описать с помощью медианы и процен-тилей [1, с. 27].
Стандартная ошибка (т) - показатель надежности расчетного параметра; стандартное отклонение оценок, которые будут получены при многократной случайной выборке данного размера из одной и той же совокупности. Стандартная ошибка - это убывающая функция объема выборки: чем меньше стандартная ошибка, тем более достоверной является оценка параметра. Весьма часто для описания непрерывных количественных данных используют стандартную ошибку, которая (в отличие от СКО) является не характеристикой, описывающей распределение наблюдений исследуемой выборки по области значений, а только мерой точности оценки популяционного среднего и, следовательно, не характеризует дисперсию (разброс) в анализируемой выборке. Однако часто именно стандартную ошибку среднего приводят в качестве параметра описательной статистики, пытаясь продемонстрировать тем самым малую вариабельность своих данных, так как всегда (по определению) т<ст. Такая форма описания данных неправильная [3].
Медиана (Ме) - возможное значение признака, которое делит ранжированную совокупность (вариационный ряд выборки) на две равные части: 50% «нижних» единиц ряда данных будут иметь значение признака не больше, чем медиана, а «верхние» 50% - значения признака не меньше, чем медиана. Медиана является важной характеристикой распределения случайной величины и, так же как математическое ожидание, может быть использована для центрирования распределения. Медиана определяется для широкого класса распределений (например, для всех непрерывных).
Е Р 6 Н I л К I-
58 Признак 1 Признак 2
60 Среднее 161,77 Среднее 134,03
61 Стандартная ошибка 12,46 Стандартная ошибка 6.59
62 Медиана 167 Медиана 121,5
63 Мода 72 Мода 141
64 Стандартное отклонение 96.54 Стандартное отклонение 51,03
65 Дисперсия выборки 9320.59 Дисперсия выборки 2604.34
66 Эксцесс 0.89 Эксцесс 2.75
67 Асимметричность 0.96 Асимметричность 1,43
68 Интервал 420 Интервал 254
69 Минимум 50 Минимум 55
70 Максимум 470 Максимум 309
71 Сумма 9706 Сумма 8042
72 Счет 60 Счет 60
73 74 Уровень надежности(95.0%) 24.94 Уровень надежности(95.0%) 13,18
Коэффициент вариации 60% Коэффициент вариации 38%
Рис. 3. Результаты описательной статистики двух признаков
Медиану и интерквартильный размах рекомендуется применять для описания распределения, не являющегося нормальным (а это большинство распределений медико-биологических параметров) [1, с. 34]. Интерквартильный размах указывают в виде процентилей. Рекомендуется указывать уровни 25 и 75%, которые соответствуют верхней границе 1-го и нижней границе 4-го квартилей. Пример описания: Me (25%; 75%) = 60 (23; 78).
Мода (Мо) - значение, которое встречается наиболее часто во множестве. Иногда в совокупности встречается более одной моды. Тогда говорят, что совокупность мультимодальна - свидетельство того, что набор данных не подчиняется нормальному распределению. Мода как средняя величина употребляется чаще для данных, имеющих нечисловую природу. Например, в группе пациентов наибольшая частота тяжести болезни будет равна моде. При экспертной оценке с помощью этого показателя определяют предпочтения участников исследования. Недостаток - показатель не учитывает поведение распределения в других точках.
Стандартное отклонение (синонимы: среднеквадратичное отклонение, квадратичное отклонение; стандартный разброс; СКО; в; о) - в теории вероятностей и статистике наиболее распространенный показатель рассеивания значений случайной величины относительно ее математического ожидания. Измеряется в единицах случайной величины. Равно корню квадратному из дисперсии случайной величины. Стандартное отклонение используют при расчете стандартной ошибки среднего арифметического, построении доверительных интервалов, статистической проверке гипотез, измерении линейной взаимосвязи между случайными величинами. Большое значение СО показывает большой разброс значений в представленном множестве со средней величиной множества; маленькое значение, соответственно, показывает, что значения во множестве сгруппированы вокруг среднего. Если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратичного отклонения), то полученные значения или метод их получения следует перепроверить.
Дисперсия (D; о2) - мера разброса случайной величины, т.е. ее отклонения от математического ожидания. Квадратный корень из дисперсии называется стандартным отклонением. Дисперсия измеряется в квадратах единицы измерения. Однако в самостоятельном виде (как, например, средняя арифметическая) дисперсия используется редко. Это скорее вспомогательный и промежуточный показатель, который применяют в других методах статистического анализа.
Эксцесс - скалярная характеристика островершинности графика плотности вероятности унимо-
дального распределения, которую используют в качестве некоторой меры отклонения рассматриваемого распределения от нормального. Если коэффициент эксцесса равен нулю или близок к нему, то плотность вероятности распределения имеет нормальный эксцесс. Если коэффициент эксцесса сильно больше нуля, то плотность вероятности имеет положительный эксцесс. Это, как правило, соответствует тому, что график плотности рассматриваемого распределения в окрестности моды имеет более острую и более высокую вершину, чем нормальная кривая. Когда коэффициент эксцесса сильно больше нуля, говорят об отрицательном эксцессе плотности, при этом плотность вероятности имеет в окрестности моды более низкую и плоскую вершину, чем плотность нормального закона. Для генеральных совокупностей больших объемов его малыми значениями можно пренебречь.
Асимметричность (коэффициент асимметрии или скоса) - величина, характеризующая асимметрию распределения данной случайной величины. Коэффициент асимметрии положителен, если правый хвост распределения длиннее левого, и отрицателен в альтернативном случае. Если распределение симметрично относительно математического ожидания, то его коэффициент асимметрии равен нулю.
Интервал - размах показателей, т.е. разность между максимумом и минимумом значений вариант.
Максимум - наибольшее значение вариант.
Минимум - наименьшее значение вариант.
Сумма - сумма значений вариант.
Счет - количество вариант.
Уровень надежности - свойство объекта сохранять в установленных пределах значения всех параметров. Показывает величину доверительного интервала для математического ожидания согласно заданному уровню надежности или доверия. По умолчанию уровень надежности принят равным 95%.
Коэффициент вариации случайной величины -мера относительного разброса случайной величины. Показывает, какую долю среднего значения этой величины составляет ее средний разброс. Исчисляется в процентах. Вычисляется только для количественных данных. В отличие от стандартного отклонения, он измеряет не абсолютную, а относительную меру разброса значений признака в статистической совокупности. В Excel нет готовой функции для расчета коэффициента вариации. Расчет можно провести простым делением стандартного отклонения на среднее значение. Эти значения имеются в таблице описательной статистики. Для вычисления этого важного показателя в ячейке ниже надписи Уровень надежности пишем Коэффициент вариации, затем в ячейке справа делаем запись: =G64/G60. То же необходимо по-
вторить для вычисления коэффициента вариации для другого измерения.
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на панели инструментов в закладке «Главная». Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что совокупность данных является однородной, если коэффициент вариации менее 33%, неоднородной - если более 33%. Эта информация может быть полезна для предварительного описания данных и определения возможностей проведения дальнейшего анализа. Кроме того, коэффициент вариации, измеряемый в процентах, позволяет сравнивать степень разброса различных данных независимо от их масштаба и единиц измерений.
Анализ показателей описательной статистики
При сравнении значений среднего, медианы, моды в каждом измерении следует отметить, что эти показатели сильно отличаются друг от друга.
Коэффициенты эксцесса и асимметрии значимо отличаются от установленных границ, коэффициенты вариации больше критического (предельного) значения. Следовательно, распределение данных в обеих группах измерений отлично от нормального. В последующем необходимо применять непараметрические методы статистического анализа. Для быстрой сравнительной оценки можно использовать показатели доверительных интервалов.
Для представления результатов сравнения обычно используют формат в виде М (95% ДИ) - значение среднего и указание 95% доверительного интервала. В тексте публикации запись может выглядеть следующим образом: Средний уровень систолического давления в группе пациентов до лечения составил 161,77 мм рт. ст. (95% ДИ от 136,83 до 186,71 мм рт. ст.), после лечения -134,03 мм рт. ст. (95% ДИ от 120,85 до 147,21 мм рт. ст.). Указанные доверительные интервалы имеют зону совмещения, следовательно, существенного различия в изменении признака нет. Исходя из этого с большой долей вероятности можно утверждать, что для данной группы пациентов лекарственный препарат, примененный для снижения уровня систолического артериального давления, был не эффективен.
1. Гланц С. Медико-биологическая статистика / Пер. с англ. -М., Практика, 1998. - 459 с.
2. Ланг Т.А., Сесик М. Как описывать статистику в медицине. Аннотированное руководство для авторов, редакторов и рецензентов / Пер. с англ. под ред. В.П. Леонова. -М.: Практическая медицина, 2011. - 480 с.
3. Леонов В.П. Ошибки статистического анализа биомедицинских данных // Междунар. журн. мед. практики. - 2007. -№ 2. - С. 19-35.
4. Трущелев С.А. Медицинская диссертация: руководство: 3-е изд. / Под ред. проф. И.Н. Денисова. - М.: ГЭОТАР-Медиа, 2009. - 416 с.

Пользователи Эксель знают, что данная программа имеет очень широкий набор статистических функций, по уровню которых она вполне может потягаться со специализированными приложениями. Но кроме того, у Excel имеется инструмент, с помощью которого производится обработка данных по целому ряду основных статистических показателей буквально в один клик.
Этот инструмент называется «Описательная статистика». С его помощью можно в очень короткие сроки, использовав ресурсы программы, обработать массив данных и получить о нем информацию по целому ряду статистических критериев. Давайте взглянем, как работает данный инструмент, и остановимся на некоторых нюансах работы с ним.
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».



После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Применение инструмента «Описательная статистика»
Теперь посмотрим, как инструмент описательная статистика можно применить на практике. Для этих целей используем готовую таблицу.
-
Переходим во вкладку «Данные» и выполняем щелчок по кнопке «Анализ данных», которая размещена на ленте в блоке инструментов «Анализ».


Выше мы говорили исключительно о входных данных. Теперь переходим к разбору настроек параметров вывода, которые расположены в этом же окне формирования описательной статистики. Прежде всего, нам нужно определиться, куда именно будут выводиться обработанные данные:
- Выходной интервал;
- Новый рабочий лист;
- Новая рабочая книга.
В первом случае нужно указать конкретный диапазон на текущем листе или его верхнюю левую ячейку, куда будет выводиться обработанная информация. Во втором случае следует указать название конкретного листа данной книги, где будет отображаться результат обработки. Если листа с таким наименованием в данный момент нет, то он будет создан автоматически после того, как вы нажмете на кнопку «OK». В третьем случае никаких дополнительных параметров указывать не нужно, так как данные будут выводиться в отдельном файле Excel (книге). Мы выбираем вывод результатов на новом рабочем листе под названием «Итоги».
Далее, если вы хотите чтобы выводилась также итоговая статистика, то нужно установить флажок около соответствующего пункта. Также можно установить уровень надежности, поставив галочку около соответствующего значения. По умолчанию он будет равен 95%, но его можно изменить, внеся другие числа в поле справа.
Кроме этого, можно установить галочки в пунктах «K-ый наименьший» и «K-ый наибольший», установив значения в соответствующих полях. Но в нашем случае этот параметр так же, как и предыдущий, не является обязательным, поэтому флажки мы не ставим.


- Асимметричность;
- Интервал;
- Минимум;
- Стандартное отклонение;
- Дисперсия выборки;
- Максимум;
- Сумма;
- Эксцесс;
- Среднее;
- Стандартная ошибка;
- Медиана;
- Мода;
- Счет.

Если какие-то из вышеуказанных данных для конкретного вида анализа не нужны, то их можно удалить, чтобы они не мешали. Далее производится анализ с учетом статистических закономерностей.

Отблагодарите автора, поделитесь статьей в социальных сетях.

НАХОЖДЕНИЕ ЧИСЛОВЫХ ХАРАКТЕРИСТИК ВЫБОРКИ СТАНДАРТНЫМИ СРЕДСТВАМИ ЭТ MS EXCEL
1 Филиал Южного федерального универстета в г.Новошахтинске 2 Филиал Южного федерального университета в г.Новошахтинске Ростовской области Текст работы размещён без изображений и формул.Полная версия работы доступна во вкладке "Файлы работы" в формате PDF Цель работы: овладеть навыками расчета числовых характеристик выборки с помощью Надстройки Пакет Анализа ЭТ MS Excel.
Краткая теория
В ЭТ MS Excel имеется набор мощных инструментов для работы с выборками и углубленного статистического анализа данных, называемый Пакет анализа, который может быть использован для решения задач статистической обработки выборочных данных.
Надстройка Пакет анализа вызывается командой главного меню Данные → Анализ данных. В появившемся окне Анализ данных выбираем пункт Описательная статистика.
Далее откроется окно Описательная статистика, в котором необходимо сделать нужные установки.
Группирование. Установите переключатель в положение «По столбцам» или «По строкам» в зависимости от расположения данных во входном диапазоне.
Метки в первой строке/Метки в первом столбце. Если первая строка исходного диапазона содержит названия столбцов, установите переключатель в положение Метки в первой строке. Если названия строк находятся в первом столбце входного диапазона, установите переключатель в положение Метки в первом столбце. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
Уровень надежности. Установите флажок, если в выходную таблицу необходимо вывести границу доверительного интервала для среднего. В поле введите требуемое значение в процентах. Например, значение 95% вычисляет уровень надежности среднего с уровнем значимости 0,05.
К-ый наибольший. Установите флажок, если в выходную таблицу необходимо включить строку для k-го наибольшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать максимальное значение выборки.
К-ый наименьший. Установите флажок, если в выходную таблицу необходимо включить строку для k-го наименьшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать минимальное значение выборки.
Выходной диапазон. Введите ссылку на левую верхнюю ячейку выходного диапазона. Этот инструмент анализа выводит два столбца сведений для каждого набора данных. Левый столбец содержит метки статистических данных; правый столбец содержит статистические данные. Состоящий их двух столбцов диапазон статистических данных будет выведен для каждого столбца или для каждой строки входного диапазона в зависимости от положения переключателя Группирование.
Если хотим вывести результаты расчета на новый лист, то установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
Если хотим вывести результаты расчета в новой книге, то установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
Итоговая статистика. Установите флажок, если в выходном диапазоне необходимо получить по одному полю для каждого из следующих видов статистических данных, представленных в таблице 2.
Число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана. Функция МЕДИАНА.
Оценка дисперсии генеральной совокупности .
Выборочный эксцесс. Функция ЭКСЦЕСС.
Коэффициент асимметрии. Функция СКОС.
Минимальное значение в выборке. Функция МИН.
Максимальное значение в выборке. Функция МАКС.
Сумма всех значений в выборке. Функция СУММ.
Объем выборки. Функция СЧЕТ.
k-тое наибольшее значение выборки. Если k=1, то выводится максимальное значение. Функция НАИБОЛЬШИЙ.
k-тое наименьшее значение выборки. Если k=1, то выводится минимальное значение. Функция НАИМЕНЬШИЙ
Параметр показывает возможность отклонения среднего по выборке, от среднего для генеральной совокупности, при заданном уровне надежности.
Замечание. Следует обратить внимание на то, что расчет параметров в режиме Описательная статистика имеет ряд важных особенностей:
1. В качестве значений параметров: Стандартное отклонение, Дисперсия выборки, Эксцесс, Асимметричность – Excel генерирует оценки соответствующих параметров для генеральной совокупности, а не для выборки.
2. Для применения Описательной статистики предварительное ранжирование исходных данных не требуется: при вычислении показателей ранжирование выполняется автоматически.
Стандартная ошибка или ошибка среднегонаходится из выражения
Стандартная ошибка – это параметр, характеризующий степень возможного отклонения среднего значения, полученного на исследуемой ограниченной выборке, от истинного среднего значения, полученного на всей совокупности элементов. С помощью стандартной ошибки задается так называемый доверительный интервал. 95%-ый доверительный интервал, равный х ± 2т , обозначает диапазон, в который с вероятностью р = 0,95 (при достаточно большом числе наблюдений п>30) попадает среднее значение генеральной совокупности.
Пример выполнения
Постановка задачи. Приведены объемы дневной выручки (в тыс. руб.) 24 продавцов колбасных изделий, работающих в разных районах города (см. табл.1).
Используйте мой пример расчета надежности в Excel и экономьте сотни часов рабочего времени. Покупайте и получите 3 файла: 1) Excel с типовыми расчетами надежности, 2) Word с формулами надежности для пояснительной записки и 3) Excel с данным по интенсивностям отказов самого разнообразного оборудования. А ещё скидочный купон на мой курс по надёжности;)
Описание
Пример расчета надежности в Excel
Какие расчёты можно сделать используя мой типовой расчет надежности в Excel:
1. Рассчитать вероятность безотказной работы устройства в зависимости от его времени работы и интенсивности отказов;
2. Пересчитать наработку на отказ в вероятность безотказной работы и обратно;
3. Посчитать гамма-процентную наработку изделия на отказ;
4. Оценить надежность системы с последовательным соединением элементов;
5. Посчитать надежность системы с параллельным соединением элементов, "горячим", нагруженным резервированием;
6. Рассчитать надёжность системы с комбинированным (и последовательным и параллельным) соединением элементов;
7. Посчитать надёжность системы с холодным (ненагруженным резервом);
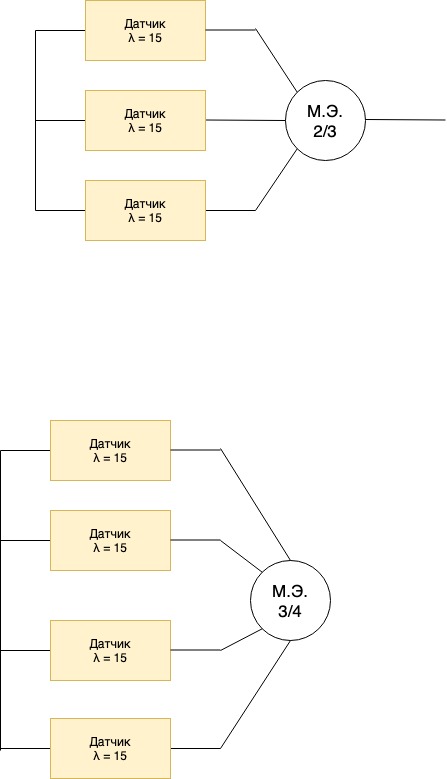
8. Оценить надёжность системы, в которой используется мажоритарное резервирование (например, должно сработать 2 из 3 компонентов);
9. Посчитать надёжность систем с резервирование k из n элементов. На мой взгляд это самый интересный расчёт, который задействует разные доли мозга. Потребуется использование комбинаторики (я объясню в файле как это делать). Например, посчитать надежность двигательной установки, состоящей из 6 двигателей, в которой возможно 2 отказа;
10. Рассчитать комплексные показатели надежности: коэффициент готовности, коэффициент оперативной готовности, вероятность своевременного завершения операции (этого нет в учебниках, но используется например в боевой авиации);
11. Оценить вероятность восстановления работоспособного состояния оборудования;
12. Посмотреть связь надежности и экономики - расчет времени простоя оборудования и стоимость для фирмы вынужденного простоя оборудования.
Апрель 2020. Добавлены новые функции:
1. Вероятность возникновения ровно n отказов;
2. Определение необходимого числа резервных элементов для удовлетворения требований по ВБР.
Типовой расчет надежности в эксель создан на основе нормативных документов, а основании ГОСТ 27.301-95 (расчет надежности - основные положения) и ГОСТ Р 51901.14-2007 (структурная схема надежности и булевы методы).
Чтобы не покупать кота в мешке, скачайте бесплатную версию шаблона расчета надежности в Excel. Она доступна по этой ссылке.
Шаблон расчёта надёжности использует в своей работе компания Нордсон.

Что вы получаете, купив мой пример расчета надежности?
1. Эксель файл, который открывается на любом компьютере (Windows, Mac, Linux) в котором вы можете выполнить все необходимые расчёты надежности.
После покупки вы просто открываете полученный файл и спокойно работаете, без установки каких-либо программ. Всё, что вам нужно - установленный на вашем компьютере или планшете Microsoft Excel.
2. Эксель файл содержит вбитые в ячейки формулы, прописанные формулы, объясняющие расчёт и структурные схемы надёжности для каждого конкретного примера. Я сделал всё, что вы максимально экономили своё время. Уверен, вы найдете куда потратить сэкономленные десятки часов:)

3. А ещё вы получите ворд файл, в который я вбил все использованные мной формулы расчётов надёжности, чтобы вам было легко оформить пояснительную записку или отчёт.
4. И чтобы вы были более автономны и могли работать даже при отключении интернета (надеюсь этого не случится), я добавил в пакет таблицу с интенсивностями отказов оборудования. Если вы мучались вопросом, где найти интенсивность отказов генератора переменного тока, то теперь ваши мучения закончены.

5. На руке 5 пальцев и пятым от меня вы получите купон на скидку в 1000 рублей на мой авторский курс по надёжности, единственный в интернете. Внимание! Скидка на курс действует в течении месяца со дня покупки примера расчета надежности.

Вот, кстати, что говорят про мой курс по надежности:
Рекомендательное письмо про мой курс по надежности

Отличный курс - все по делу, без лишней наукообразности, но и без профанации. Все, что нужно практикующему специалисту по надежности. Алексей, так держать.
Всеволод Александрович Катков, преподаватель МАИ
А вот эти люди и компании прошли мой курс по надежности и пользуются моим шаблоном для расчетов надежности:

1. Энергетическая компания, Севастополь
Курс отличный. Все лаконично, по делу и познавательно. Материал составлен разумно. Приятно поразил ответственный подход Алексея к обучению, его глубокие знания и умение подстроиться под ученика.
Обучение надежности можно смело рекомендовать всем тем, кто стремится улучшить свои знания в области надежности.
Успехов Алексею и его ученикам в этом полезном деле!
С пожеланием успеха, Сергей. Таврида Электрик

2. Оператор связи и интернета, Москва
Курс по надежности - хорошо подготовленный курс, составленный на основе практического опыта расчетов надежности в промышленности и общих понятий о надежности в классической технической литературе. Создается основа, которая позволяет дальше самостоятельно работать с документацией, стандартами и другими источниками.
Материал объясняется просто и понятно, при необходимости освещаются специальные вопросы, требующие детальной проработки. Примеры живые и понятные, упражнения продуманные и связанные с практикой. Преподавание ведется в спокойной, дружелюбной манере, тем не менее контролируется понимание и усвоение материала.
С уважением, Алексей. Мегафон.
3. Опытное конструкторское бюро, Москва

Хочу сказать большое спасибо за курсы по надёжности! Все началось с того, что мне нужно было освоить основы надёжности, я искала информацию в книгах и ГОСТах, но толку было никакого. Уже потеряв надежду решила погуглить, вдруг есть курсы по надёжности и к моему счастью я нашла Ваши курсы. ) Я не только получила отличную базу знаний по надёжности, но и стала более уверена в себе, как инженер! Спасибо ещё раз большое за такой прекрасный и самое главное ДОСТУПНЫЙ курс.
С уважением, Дарья. ФГУП МОКБ «Марс»
4. НИИ Информационных технологий, Тверь.

Алексей, спасибо!
Очень доволен, что решил всё правильно.
Но это благодаря тому, что Ваш курс очень нагляден и носит практическую направленность, чего, зачастую, и не хватает при самостоятельном изучении.
Я именно и ожидал такого. И получил. Большое спасибо!
Да, и что греха таить - есть примеры абсолютно теоретизированных, абстрактных, но пустых по практике, курсов. Я ведь лопатил интернет.
С уважением,
О.Д. Мирошниченко,
Научный сотрудник АО "НИИИТ"
Почему вы должны использовать мой типовой расчет надежности? Кто я такой?
Меня зовут Алексей Глазачев. Вопросами надежности в технике я занимаюсь более 10 лет. Я выпускник Московского Авиационного института. Специальность: проектирование космических аппаратов и разгонных блоков.
За эти десять лет мне довелось работать в таких организациях как КБТМ, ФГУП "ЦЭНКИ", ООО «КосмоКурс», АО «Кронштадт беспилотные системы». Я прошёл путь от техника до начальника бригады безопасности полёта.
Я занимался ракетными пусками на Байконуре и Морском Старте, считал надежность стартового оборудования космических комплексов, многоразовых суборбитальных космических аппаратов и беспилотных летательных аппаратов.

 |  |
|---|
В 2011-2012 годах преподавал в Московском Авиационном институте.
Сотрудничал (и продолжаю) по вопросам надежности со следующими компаниями:
1. ФГУП ЦЭНКИ - осуществление космических пусков, эксплуатация стартовых комплексов
2. ЦНИИмаш - головной научное предприятие космической отрасли
3. Роскосмос (Вова - привет!)
4. НИТС (технического стекла)
5. НПО Автоматики (г. Екатеринбург) - системы управления космических и морских ракет
6. НИИ Парашютостроения
7. Проектмонтажавтоматика - системы автоматизации технологических процессов
8. МКБ «Искра» - системы аварийного спасения космонавтов
9. ООО «КосмоКурс» - многоразовый суборбитальный космический комплекс
10. АО «Кронштадт» - один из лидеров в области беспилотных летательных аппаратов
11. ФГУП МОКБ «Марс» - системы управления разгонных блоков
12. НПП Радиосвязь (г. Красноярск) - с июля 2019
13. АО «КБХА» (г. Воронеж) - одно из ведущих предприятий по разработке ракетных двигателей
14. АО НИИИТ (г.Тверь) - разработка автоматизированных систем управления специального назначения
Как купить пример расчёта надежности?
Нажмите на кнопку «В корзину» вверху страницы. Введите ваше имя и email. Внимательно проверьте email! Мой сайт поддерживает все способы оплаты.
Сразу после оплаты платёжная система переправит вас обратно на мой сайт. Вы увидите вот такую информацию:

Вам нужно скачать на свой компьютер файлы, помеченные стрелочкой. Так вы получите пример расчета надежности.

Кроме того, сразу после оплаты вам на почту придёт вот такое письмо:
Вам нужно скачать на свой компьютер файлы, помеченные стрелочкой. Это точно такой же файл. Внимание! Если вы не получили письмо в течении 5 минут после оплаты, обязательно проверьте папку СПАМ на вашей почте.
Со мной всегда возможен формат личных консультаций, очного индивидуального и группового обучения. Можно и по скайпу. Если вы хотите заключить со мной договор на обучение надежности с вашей компанией или по любым другим вопросам:
Согласно постановлению правительства Российской Федерации от 28 октября 2013 года № 966, лицензия на осуществление обучающей деятельности не требуется, если её осуществляет индивидуальный предприниматель лично. Что я с удовольствием и делаю.
Читайте также: