
Visual studio решение задач
Обновлено: 07.07.2024
Авторы - И. А. Гурин, Н. А. Спирин, В. В. Лавров, ФГАОУ ВО «Уральский федеральный университет имени первого Президента России Б.Н. Ельцина», г. Екатеринбург, Россия.
Введение
Создание математической библиотеки
Отличительной особенностью MATLAB от других математических пакетов является наличие средств, которые позволяют использовать функционал, созданный в MATLAB, при разработке автономных приложений. Такая возможность реализуется с помощью продукта MATLAB Compiler. Данный продукт позволяет собирать модули в виде [1]:
Приложения и библиотеки, созданные с помощью MATLAB Compiler, используют свободно распространяемое исполняемое ядро, называемое MATLAB Compiler Runtime (MCR). Это позволяет запускать приложения, которые используют MATLAB-функции, без необходимости установки дорогостоящей копии MATLAB.
Одним из инструментов для создания математических библиотек или внешних компонентов является Deployment Tool, представляющий собой графический интерфейс. Вызов данного инструмента осуществляется командой deploytool. На рисунке 1 представлено стартовое окно Deployment Tool, на котором предлагается выбрать тип и создать новый проект.

Рис. 1. Стартовое окно инструмента Deployment Tool в MATLAB
Рассмотрим решение задачи линейного программирования в пакете MATLAB. Решение осуществляется с помощью функции linprog [3]. Функция linprog решает задачу линейного программирования в форме:

Основными входными данными функции linprog являются: вектор коэффициентов целевой функции f, матрица ограничений-неравенств A, вектор правых частей ограничений - неравенств b, матрица ограничений - равенств Aeq, вектор правых частей ограничений - равенств beq, вектор lb, ограничивающий план x снизу, вектор ub, ограничивающий план x сверху. На выходе функция linprog даёт оптимальный план x задачи (1) и экстремальное значение целевой функции fval.
Листинг функции MOptimaGaz решения задачи линейного программирования:
Стоит заметить, что при решении практической задачи не использовались ограничения - равенства, поэтому матрица Aeq и вектор beq не передаются как входные параметры, а принимают пустые значения.
Таким образом, в MATLAB был создан проект MOptimaGaz с классом MClassOptimaGaz и функцией MOptimaGaz. Для использования написанных функций проект компилируется в динамически подключаемую библиотеку DLL.
Подключение библиотеки и ее использование

Рис. 2. Окно добавления ссылки на сборку в Visual Studio
Отметим обязательность соблюдения разрядности MATLAB и создаваемого программного обеспечения. Также замечена нестабильность работы при работе с 64-разрядной архитектурой, поэтому при разработке использовалась 32-разрядная версия MATLAB.
Для использования библиотеки необходимо добавить описание пространства имен:
Ниже приведен листинг программы с комментариями, вызывающий внешнюю функцию MATLAB и выводящий результаты решения задачи.
Из программы опущен блок, присваивающий переменным lb, ub, Aeq, beq и f значения. Если решение не найдено, то результат содержит пустой массив.
Заключение
Список использованной литературы
Кетков Ю.Л. "MATLAB 7: программирование, численные методы" – Спб.: БХВ- Петербург, 2005. – 752 с.
Расчетное задание защищено с оценкой ____________ Преподаватель ____________ Тушев А.Н.
“____”___________ 2015 г.
тема проекта (работы)
по дисциплине «Современные технологии программирования»
РЗ 09.03.01.22.000 О
![]()
Студентка группы ИВТ – 22 Анна Дмитриевна Ускова
![]()
Руководитель
проекта (работы) к.т.н., доцент Александр Николаевич Тушев
должность, ученое звание и.о., фамилия
ЗАДАНИЕ НА РАСЧЕТНУЮ РАБОТУ
![]()
По дисциплине Современные технологии программирования
Выдано студентке группы ИВТ-22 Усковой Анне Дмитриевне
![]()
1. Получение заданий
1 — 2 недели семестра
2. Описание предметной области
2 — 4 недели семестра
3. Создание программ
5 — 11 недели семестра
4. Тестирование программ
12 — 13 недели семестра
Оформление и сдача работы на проверку 14 — 15 -я недели семестра
Срок представления работы к защите 16 — 17 -я недели семестра
Руководитель работы Тушев Александр Николаевич
фамилия, имя, отчество
Подпись руководителя Подпись студента
Дата выдачи задания « 10 » февраля 2015 г.
1 Описание предметной области………………………………………………. 5
2 Обработка статических и динамических изображений .…………………. 6
3 Алгоритмы обработки матриц…………………………………………………7
4 Алгоритмы обработки слов или текста………………………………………..8
5 Комбинаторика и динамическое программирование…………………………9
6 Переборные алгоритмы…………………………… ………………………… 10
Список использованных источников…………………………………………. 12
Задачи курсовой работы:
Реализовать 5 задач по темам:
1. Обработка статических и динамических изображений.
2. Алгоритмы обработки матриц.
3. Алгоритмы обработки слов или текста.
4. Комбинаторика и динамическое программирование.
5. Переборные алгоритмы.
1 Описание предметной области
2 Обработка статических и динамических изображений
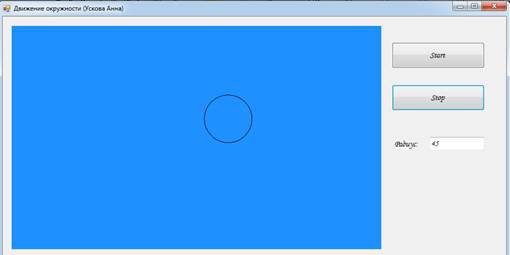
Задача. Движение окружности.
Окружность движется с постоянной скоростью от левого нижнего угла к правому верхнему. Когда она исчезнет, достигнув верхнего края, появляется новая окружность.
Внешний вид до нажатия кнопки «Start»

Задали радиус и нажали кнопку «Start»
3 Алгоритмы обработки матриц

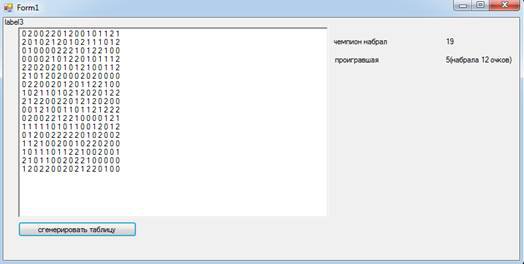
4 Алгоритмы обработки слов или текста.


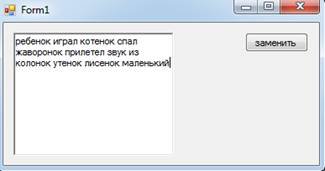
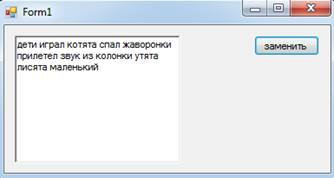
Дан текст из слов, разделенных одним пробелом. Найти слова, оканчивающиеся на ------онок или -енок и заменить их множественным числом по правилам или приведенным исключениям.
5 Комбинаторика и динамическое программирование.

Внешний вид до нажатия кнопки «подобрать» представлен на рисунке 5.1
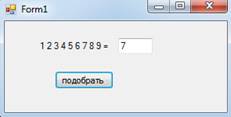
Рисунок 5.1
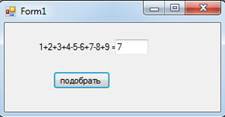
Внешний вид после нажатия кнопки «подобрать» представлен на рисунке 5.2
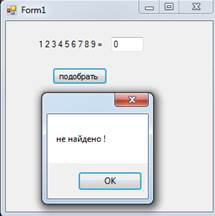
Требуемая расстановка знаков невозможна:
6 Переборные алгоритмы.

Задача решается простым тройным циклом:
Внешний вид до нажатия кнопки «найти решения» представлен на рисунке 6.1
Результат работы программы представлен на рисунке 6.2
В результате проделанной работы удалось выполнить все поставленные задачи, получив при этом готовые приложения. Приложения имеют интуитивно понятный интерфейс, удобный в использовании с персонального компьютера. Приложения имеют русскоязычные интерфейсы.
Преимущества приложений – простой, понятный для пользователя интерфейс, высокое быстродействие, простота редактирования.
Недостатки – приложения не кроссплатформенные и не могут быть запущены на других операционных системах, кроме Windows.
Список использованных источников
В отличие от простейших программ, таких как "Hello World", большинство приложений состоит из нескольких исходных файлов. Это обстоятельство порождает массу проблем, в частности, как назвать файлы, где их разместить и можно ли их использовать повторно. В интегрированной среде разработки Visual Studio принята концепция решения (solution), состоящего из ряда проектов, которые в свою очередь состоят из ряда элементов, благодаря которой разработчики могут работать с исходными файлами. Интегрированная среда разработки имеет множество встроенных инструментов, позволяющих упростить этот процесс, обеспечив разработчикам доступ к большей части их приложений. Далее рассматриваются структура решений и проектов, доступные типы проектов и способы настройки их конфигурации.
Структура решения
Работая с системой Visual Studio, пользователь открывает решение. При повторном редактировании специальных файлов создается временное решение, которое можно уничтожить по окончании работы. Однако решение позволяет управлять текущими файлами, поэтому в большинстве случаев его сохранение означает, что пользователь может вернуться к тому, что он делал накануне, и вновь открыть файлы, с которыми он работал.
Наиболее распространенным способом структурирования приложений в среде Visual Studio является одно отдельное решение, содержащее много проектов. Каждый проект можно создать из набора исходных файлов и папок. Главное окно, в котором пользователь работает с решениями и проектами, называется Solution Explorer:

Для организации работы с исходным кодом и предотвращения его ассоциации с приложениями (за исключением веб-приложений, в которых существуют специальные папки, имеющие особое предназначение в данном контексте) используются папки (folders). Некоторые разработчики используют имена папок, соответствующие пространствам имен, которым принадлежат классы. Например, если класс Person находится в папке DataClasses в проекте FirstProject, то полностью квалифицированное имя класса может выглядеть как FirstProject.DataClasses.Person.
Папки решения (solution folders) - полезный способ организации проектов в большом решении. Они отображаются только в окне Solution Explorer - физически в файловой системе их не существует. Такие действия, как Build или Unload, можно легко выполнять над всеми проектами, включенными в папку решения. Для того чтобы разгрузить окно Solution Explorer, папки решения могут быть свернуты или скрыты.
Скрытые проекты по-прежнему создаются, когда пользователь создает решение. Поскольку папки проекта не соответствуют физическим папкам, их можно добавлять, переименовывать и удалять в любое время, не рискуя повредить связи между файлами или потерять контроль над исходными файлами.
Папка Miscellaneous Files - это специальная папка решения, которую можно использовать для того, чтобы следить за тем, какие еще файлы, не являющиеся частью какого-либо проекта в решении, были открыты в системе Visual Studio. По умолчанию папка Miscellaneous Files скрыта. Для того чтобы сделать ее видимой, следует выполнить команду Tools --> Options --> Environment --> Documents --> Show Miscellaneous Files.
Несмотря на то что формат файла решения, принятый в предыдущих версиях, не изменился, в системе Visual Studio 2010 открыть файл решения, созданный в версии Visual Studio 2013, невозможно.
Кроме информации о файлах, содержащихся в приложении, файлы решения и проектов могут содержать и другие записи, например, о том, как именно должен быть скомпилирован конкретный файл, об установках проекта, о ресурсах и многом другом. Система Visual Studio 2013 имеет немодальное диалоговое окно для редактирования свойств проекта, в то время как свойства решения по-прежнему открываются в отдельном окне. Как и следовало ожидать, свойствами проекта считаются те свойства, которые относятся только к данному проекту, например информация о сборке и связях, а свойства решения определяют общую конфигурацию для сборки приложений.
Формат файла решения
Система Visual Studio 2013 фактически создает для решения два файла, имеющих расширения .suo и .sln (solution file). Первый - это довольно неинтересный бинарный файл, который сложно редактировать. Он содержит информацию, специфичную для пользователя, например, какие файлы были открыты, когда решение закрывалось в последний раз и где находились контрольные точки. Этот файл скрыт, поэтому он не должен появляться в папке решения при использовании Windows Explorer, если не снять с него соответствующую метку.
Иногда файл .suo оказывается поврежденным, и это вызывает непредсказуемые последствия при сборке и редактировании приложений. Если при работе с конкретным решением система Visual Studio становится нестабильной, необходимо выйти из нее и удалить файл с расширением .suo. Он будет создан заново системой Visual Studio, когда решение будет открыто в следующий раз. Файл решения с расширением .sln содержит информацию о решении, например список проектов, конфигурации сборки и другие настройки, не специфичные для проекта. В отличие от многих файлов, используемых в системе Visual Studio 2013, файл решения не является XML-документом. Он хранит информацию в блоках, как показано в следующем примере:
В этом примере решение состоит из трех проектов (GettingStarted, Information Services и Reference Library), а раздел Global содержит настройки, которые применяются к решению. Например, само решение будет видимым в окне Solution Explorer, потому что настройка HideSolutionNode установлена равной FALSE. Если изменить ее на TRUE, имя решения не будет отображаться в системе Visual Studio.
Свойства решения
Для того чтобы открыть диалоговое окно Properties, необходимо щелкнуть правой кнопкой мыши на узле Solution в окне Solution Explorer и выбрать команду Properties. Это диалоговое окно содержит два узла: Common properties и Configuration properties, как показано на рисунке ниже:

Более подробно узлы Common properties и Configuration properties описываются в следующих разделах.
Узел Common Properties
Определяя проект Startup Project для приложения, пользователь имеет три возможности, которые являются практически очевидными. Выбор Current Selection запускает проект, который в данный момент находится в фокусе окна Solution Explorer. Вариант Single Startup гарантирует, что каждый раз будет запускаться один и тот же проект. Эта установка задается по умолчанию, поскольку большинство приложений имеют только один стартовый проект. Последний вариант, Multiple Startup Projects, позволяет запускать несколько проектов в определенном порядке. Это может быть полезным при работе с приложением клиент/сервер в рамках одного решения, причем требуется, чтобы и клиент, и сервер выполнялись одновременно. При выполнении нескольких проектов важно контролировать порядок их запуска. Для управления порядком запуска проектов можно использовать навигационные кнопки, расположенные после списка проектов.
Раздел Project Dependencies используется для того, чтобы задавать другие проекты, от которых зависит конкретный проект. В большинстве случаев система Visual Studio сама управляет этими свойствами, когда пользователь добавляет или удаляет связи между проектами и данным проектом. Однако иногда пользователь может самостоятельно создать связи между проектами, чтобы они собирались в заданном порядке. Система Visual Studio использует этот список зависимостей, для того чтобы определить порядок сборки проектов. Окно этого раздела предотвращает неосторожное добавление циклических связей и удаление необходимых зависимостей между проектами.
В разделе Debug Source Files можно создать список каталогов, в которых система Visual Studio может искать исходные файлы при отладке. Этот список задается по умолчанию и просматривается перед открытием диалогового окна Find Source. Кроме того, пользователь может перечислить исходные файлы, которые система Visual Studio не должна искать. Если щелкнуть на кнопке Cancel в момент, когда система предлагает найти конкретный исходный файл, то он будет добавлен в этот список.
Раздел Code Analysis Settings доступен только в версии Visual Studio Team Suite. Это позволяет выбирать набор правил статического анализа кода, которые будут применяться к конкретному проекту. Более подробно раздел Code Analysis обсуждается далее.
Узел Configuration Properties
И проекты, и решения имеют конфигурации для сборки, определяющие, какие элементы должны быть собраны и почему. Это может сбить пользователя с толку, потому что на самом деле между конфигурацией проекта, определяющей, как должны собираться элементы, и конфигурацией решения, определяющей, какие проекты должны быть собраны, нет никакой корреляции, кроме случаев, когда они имеют одинаковые имена. Новое решение определит конфигурации Debug и Release (решения), что эквивалентно сборке всех проектов в решении с помощью конфигураций Debug и Release (проекта).
Например, может быть создана новая конфигурация решения Test, состоящая из двух проектов: MyClassLibrary и MyClassLibraryTest. Когда пользователь создает свое приложение в конфигурации Test, он хочет, чтобы проект MyClassLibrary был собран в режиме Release, чтобы тестировать его в виде, максимально приближенном к окончательной версии. Однако, чтобы проверить тестируемый код, необходимо собрать тестовый проект в режиме Debug.
Когда пользователь собирает проект в режиме Release, он не хочет, чтобы решение Test было собрано или развернуто вместе с приложением. В данном случае в конфигурации решения Test можно указать, что пользователь хочет, чтобы проект MyClassLibrary был собран в режиме Release, а проект MyClassLibraryTest вообще не собирался.
Пользователь может легко переключаться между этими конфигурациями с помощью меню Configuration стандартной инструментальной панели. Однако, переключаться между платформами не так легко, потому что меню Platform нет ни в одной инструментальной панели. Для того чтобы сделать ее доступной, необходимо выбрать команду View --> Toolbars --> Customize. Затем элемент Solution Platforms из категории Build на закладке Command можно перетащить на инструментальную панель.
Следует отметить, что, выбрав узел Configuration Properties в диалоговом окне Solution Properties, как показано на рисунке ниже, можно получить доступ к раскрывающимся спискам Configuration и Platform. Раскрывающийся список Configuration содержит все доступные конфигурации решения: Debug и Release (заданные по умолчанию), Active и All Configurations. Аналогично в раскрывающемся списке Platform перечислены все доступные платформы. Как только пользователь получит доступ к этим раскрывающимся спискам, он может на этой же странице задать настройки для каждой конфигурации и/или платформы. Для того чтобы добавить новые конфигурации и/или платформы для решения, пользователь может также использовать кнопку Configuration Manager.

При добавлении новых конфигураций решения существует возможность (предусмотренная по умолчанию) создания соответствующих конфигураций для существующих проектов (по умолчанию все проекты будут собираться в новой конфигурации решения), а также возможность создать новую конфигурацию на основе существующих. Если флажок Create Project Configurations установлен и новая конфигурация основана на существующей, то новые конфигурации проекта будут копировать конфигурации проекта, заданные для существующей конфигурации.
Возможности, доступные для создания новых платформенных конфигураций, ограничены типами доступных центральных процессоров: Itanium, x86 и x64. Новая платформенная конфигурация также может основываться на существующих платформенных конфигурациях, и существует возможность создания платформенной конфигурации для проекта.
В конфигурационном файле решения можно также задать тип центрального процессора, для которого оно собирается. Это особенно удобно, если нужно развернуть приложение для компьютеров с 64-битовой архитектурой. Установить настройки для всех этих решений можно непосредственно в контекстном меню, которое открывается после щелчка правой кнопкой мыши на узле Solution node в окне Solution Explorer. В то время как команда Set Startup Projects открывает окно конфигурации решения, команды Configuration Manager, Project Dependencies и Project Build Order открывают окно Configuration Manager and Project Dependencies. Команды Project Dependencies и Project Build Order отображаются в окне, только если решение состоит из нескольких проектов.
Команда Project Build Order открывает окно Project Dependencies и перечисляет порядок сборки, как показано на рисунке ниже:

Закладка Build Order демонстрирует порядок, в котором должны собираться проекты в соответствии с зависимостями между ними. Это может оказаться полезным, если пользователь поддерживает ссылки на бинарные сборки проектов, а не ссылки на проекты. Кроме того, эту возможность можно использовать для двойной проверки того, что проекты будут собраны в правильном порядке.
Пример простейшей программы на языке C++, которая решает задачу A + B:
У меня всё работает, а у вас нет!
Язык C++ позволяет создавать надёжные и действительно быстрые программы. Все задачи в системе iRunner можно сдать на C++, с запасом укладываясь в отведённое время. Однако этот язык сложен и предоставляет массу возможностей «выстрелить себе в ногу». Ошибки программиста, ведущие к неопределённому поведению, могут проявляться не всегда и самым невероятным образом. Стоит отметить, что такие ошибки крайне редко проявляются в отладочной (Debug) версии программы.
Нередки случаи, когда студенты жалуются на то, что их программа проходит тест на их локальном компьютере, но выдаёт неверный ответ или ошибку на сервере. Если вы столкнулись с такой проблемой, посмотрите раздел про наиболее частые ошибки студентов и перечитайте код, попробуйте составить свои собственные тесты и найти ошибку в программе.
Программирование в Microsoft Visual Studio
Для успешного решения задач достаточно самой базовой установки Visual Studio (в том числе Express Edition) с компилятором C++.
Создание проекта
Обратите внимание, что решение задачи должно полностью содержаться в одном файле. Например, этот файл не должен подключать файл stdafx.h, который при некоторых условиях генерируется мастером Visual Studio на этапе создания нового проекта.
Необходимо создавать пустой проект (Empty Project) типа Console Application без precompiled headers.
Решение задачи должно быть обычной консольной программой с точкой входа int main() . В решениях задач нет необходимости делать WinAPI-вызовы (создавать окна, взаимодействовать с пользователем, рисовать что-то) или использовать библиотеку MFC.
Debug- и Release-сборки
Visual Studio по умолчанию создаёт две конфигурации для сборки проекта: Debug и Release.
Debug-сборка предназначена для разработчика: код компилируется без оптимизации, с сохранением отладочных символов, которые позволяют выполнять программу по шагам в отладчике. Включаются многие проверки (например проверка выхода за границы в std::vector , проверки валидности итераторов, контроль целостности кучи и многое другое).
Правильно написанное решение всегда выдаёт одинаковый результат и завершается без ошибок как при сборке в Debug, так и при сборке в Release. Если ваш код работает по-разному (например, при сборке в Release ответ неправильный, а при сборке в Debug правильный), это повод искать ошибку в своём коде.
Предупреждения (warnings)

Вы можете выставить настройку Treat Warnings as Errors в значение Yes, тогда все предупреждения будут считаться ошибками, и вам не удастся скомпилировать и запустить программу, пока не будут исправлены все предупреждения.
Особенности компилятора
- Тип long double совпадает с типом double . Т. е. sizeof(long double) = sizeof(double) = 8 . Для решения задач всегда достаточно типа double (если только не требуется своя реализация чисел с плавающей точкой).
- Можно настраивать размер системного стека, который даётся вашей программе. По умолчанию выставляется стек размером в 1 МБ. Для того чтобы увеличить объём стека и избежать его переполнения при использовании «глубокой» рекурсии, следует использовать специальную директиву с начале файла с решением (в примере размер стека устанавливается равным 16 МБ):
Ввод и вывод данных
У тех, кто пишет на языке C++, всегда есть выбор из двух библиотек ввода/вывода:
Потоковый ввод/вывод удобен в использовании, с ним сложнее допустить ошибку, он хорошо подходит для ввода/вывода объектов пользовательских типов (путём определения операторов << , >> ), но обычно работает несколько медленнее стандартного. Это даже может стать причиной получения вердикта «Нарушен предел времени». Поэтому если в задаче надо считывать много входных данных (скажем, больше мегабайта) или много выводить, то не следует использовать потоковый ввод/вывод.
Сравнение скорости разных функций ввода/вывода и рекомендации по оптимизации можно найти тут. При выводе потоками стоит помнить, что для получения переводов строк лучше применять escape-последовательность \n вместо манипулятора std::endl , поскольку он всякий раз сбрасывает буфер и тем самым замедляет процесс вывода.
scanf() и printf()
При использовании функций scanf , printf следует быть предельно внимательным и проверять соответствие форматной строки и тех аргументов, что реально передаются в функцию. Например, пусть вы изначально написали код для считывания целого числа n таким образом:
Такая программа будет компилироваться без ошибок, но работать, скорее всего, неправильно.
- При отправке решений в систему iRunner на языке C++ с выбранным компилятором Visual Studio 2010 и старше или компилятором MinGW GCC можно использовать или спецификатор %lld , или спецификатор %I64d для ввода и вывода 64-битных знаковых целых чисел.
- При вводе чисел типа double при помощи scanf() нужно использовать %lf , а при выводе значений типа double нужно использовать %f . Объяснение.
Переопределение стандартных потоков
Иногда в решениях задач удобно для упрощения кода не создавать специальные объекты fstream или FILE для работы с файлами, а переоткрывать стандартные потоки ввода/вывода так, чтобы вместо консоли они оказались связанными с нужными файлами. Для этого используется функция freopen . Легко сделать так, чтобы ввод из std::cin на самом деле осуществлялся из файла вместо клавиатуры, а вывод в std::cout направлялся в выходной файл, при этом поток std::cerr не переопределяется и его по-прежнему можно применять для отладочного вывода в консоль каких-то служебных данных (если это нужно), которые не попадут в ответ, проверяемый тестирующей системой.
Пример решения задачи «A+B» (сумма двух чисел) при использовании потокового ввода/вывода (файлы input.txt и output.txt ):
Правда, здесь без freopen код получается ещё проще (см. решение), но иногда это не так. Заметим, что закрывать потоки, вызывая close() , нет необходимости: это будет сделано в деструкторах автоматически.
Тот же пример для ввода/вывода в C-стиле:
Обратите внимание, что вызывать fclose() нет необходимости, но если вы используете отдельные переменные FILE , это делать нужно.
первой строкой программы.
Считывание данных до конца файла
В некоторых задачах нужно считывать данные до конца файла, пока они не закончатся. Например, в файле записаны числа, но их количество заранее неизвестно, нужно прочитать все.
Для потокового ввода можно делать так (чтение идёт со стандартного ввода: с клавиатуры или из файла, если stdin был переоткрыт на чтение из файла при помощи freopen ):
Если же чтение идёт из объекта типа std::ifstream , созданного, например, так:
то в примере выше std::cin следует заменить на fin .
Пример для традиционного ввода в стиле С со стандартного ввода (или из файла, если использовался freopen ):
Приведём также пример ввода в C-стиле из произвольного файлового объекта:
Типичные ошибки при программировании на C++
Неопределённое поведение
Использование неинициализированных переменных
Одиночные переменные
Массивы
Глобальные статические массивы из примитивных типов (например int ) также инициализируются нулями, а вот локальные массивы в общем случае не инициализируются.
Для многих является новостью то, что массивы примитивных типов, которые выделяются динамически с использованием оператора new , не инициализируются нулями. Пример:
Вам может повезти (или не повезти), и эта программа распечатает n нулей. Но никто не гарантирует этого.
Решений проблемы инициализации динамически выделяемых массивов примитивных типов видится несколько.
Можно явно указывать при вызове new круглые скобки, тем самым говоря, что надо вызвать инициализатор по умолчанию:
Поля классов
Аналогичная проблема с забытой инициализацией актуальна для полей классов. Для самописных классов рекомендуется в конструкторе по умолчанию инициализировать все поля, чтобы не сталкиваться с тем, что программа работает нестабильно.
Если где-то будет чтение из поля height перед тем. как ему что-то присвоили, получим то же неопределённое поведение.
Выход за границы массива («проезд» по памяти)
VS в сборке Debug при запуске такой программы выдаёт ошибку HEAP CORRUPTION DETECTED (повреждение кучи). Но не всегда он так хорошо диагностирует ошибки «проезда» по памяти, к сожалению.
Действительно, последствия доступа по ошибке к такому «случайному» месту в памяти могут быть разными (в любом случае это неопределённое поведение). Доступ на чтение, на первый взгляд, более безопасен. Вы можете попасть на другую переменную своей же программы, можете попасть на глобальную переменную стандартной библиотеки или на неинициализированный блок памяти и прочитать какой-то мусор. Однако и чтение может стать причиной мгновенного краха вашей программы: если вы будете читать из страницы памяти, которая не выделена вовсе или которая принадлежит ядру ОС, сработают аппаратные средства защиты виртуальной памяти, встроенные в процессор, и ваша программа немедленно будет «убита» (этот случай в ОС называется segmentation fault или security violation). Доступ на запись к «случайной» ячейке памяти ещё хуже, потому что внезапно вы можете что-то затереть, что впоследствии скажется на исполнении программы непредсказуемым образом.
Тем не менее, std::vector не является универсальным решением проблемы. Например, двумерные массивы из вектора векторов не так эффективны, как обычные статические матрицы с заранее заданными размерами. В таком случае остаётся лишь внимательно писать код и уделять индексам повышенное внимание.
Забытый оператор return в функции
Если в функции, которая возвращает не void, забыть оператор return, то такая функция может работать не так, как вы ожидаете.
Студент реализовывал операцию поиска вершины по ключу в бинарном поисковом дереве при помощи рекурсии. Однако в местах рекурсивных вызовов забыл указать оператор return (из функции по логике следовало бы вернуть то значение, которое вернул рекурсивный вызов той же функции). Компилятор на такой код выдаёт предупреждение:
Это неопределённое поведение: по счастливой случайности такая программа может работать (например, при сборке локально на ноутбуке в режиме Debug работает, при сборке в Release на сервере не работает). Внимательно читайте все предупреждения компилятора.
Непонимание принципа работы функций ввода/вывода
Пусть в условии задачи говорится, что во входном файле записаны целые числа по одному в строке, и требуется прочитать их в программе на C++. Поскольку предварительно в начале файла не сообщается общее количество чисел, нужно реализовать чтение до конца файла.
Предположим, студент Вася пишет такой код:
Потом Вася создаёт в Блокноте входной файл input.txt с таким содержимым (для наглядности переводы строк показаны знаком абзаца ¶, как в Word в режиме показа непечатаемых символов):
Обратите внимание, после числа три перевод строки отсутствует, то есть Вася не нажал клавишу ввода на клавиатуре после того, как набрал тройку. Вася запускает программу, и она печатает эти же три числа, как и ожидалось:
Однако в жизни чаще все придерживаются правила, что символ перевода строки завершает строку, а не разделяет соседние строки. Тогда каждая строка, даже последняя, завершается переводом строки. Если следовать этой традиции, входной файл input.txt должен иметь вид
Если бы Вася запустил свою программу на этом вводе, он с удивлением обнаружил бы, что напечаталось четыре числа, а число три продублировалось дважды!
Причина здесь в том, что Вася не до конца понимает принцип работы с потоками ввода в C++. Когда оказывается считанной цифра три, условие in.eof() ещё ложно (файл ещё не закончился, ведь не прочитан перевод строки). Поэтому тело цикла while выполняется четыре раза. Попытка считать четвёртое число оказывается провальной: значение переменной x не изменяется, но в потоке выставляется eofbit . Однако Вася в лучших студенческих традициях не озабочен такими мелочами, как проверка ошибок. Он не проверяет, успешно ли было прочитано число, а просто использует значение, оставшееся с предыдущей итерации.
Было бы хуже, если бы Вася написал код так:
Здесь объявление локальной переменной x внесено в тело цикла. Если в файле input.txt все строки оканчиваются переводами строк, то программа студента Васи вполне могла бы напечатать
Число в последней строке может оказаться любым: в программе на последней итерации выполняется печать неинициализированной переменной x (оператор fin >> x не поместил в x значение, потому что не прочитал его из закончившегося файла), а это влечёт за собой неопределённое поведение.
Простой способ переписать программу Васи, чтобы она работала, как ожидается, и печатала три числа:
Другой вариант решения проблемы: явно считывать все пробельные символы после каждого числа, чтобы условие fin.eof() действительно приняло истинное значение, когда числа закончатся. Для реализации такого подхода удобно использовать манипулятор std::ws :
Прочие ошибки
- Практически всегда студенты забывают корректно очистить память, с которой они работали. На каждый вызов оператора new должен быть соответствующий единственный вызов оператора delete . Причём если память выделялась как под массив, то очищать её следует оператором delete[] (с квадратными скобками). Конечно, в решениях задач это может казаться не важным (всё равно программа быстро закончит свою работу, процесс завершится, и операционная система в любом случае освободит всю принадлежавшую ему память). Но в промышленном коде утечки памяти недопустимы, и лучше сразу привыкать писать правильно. А ещё лучше изучить приёмы, которые дают возможность не писать самому new и delete , например научиться пользоваться контейнером std::vector из STL вместо динамического массива.
- Некоторые студенты, когда всё же пытаются писать хороший код и очищать память, делают это неправильно и удаляют с помощью оператора delete память, которую они выделили функцией malloc . Или наоборот: выделяют память оператором new , а удаляют при помощи функции free . Следует помнить, что пары операторов new / delete и функций malloc / free нельзя путать между собой. Такая ошибка может тоже быть причиной аварийного завершения программы.
Библиотека STL
Состав
Контейнеры
Контейнеры STL представляют собой готовые реализации часто использующихся структур данных. Самыми полезными при решении задач являются:
- динамический массив vector ;
- сортированный ассоциативный массив map и сортированное множество элементов set , основанные на красно-чёрных деревьях (операции удаления, вставки и поиска элементов выполняются за логарифмическое время);
- очередь queue , очередь с приоритетами (бинарная куча) priority_queue , двусторонняя очередь deque и стек stack ,
- строка string .
Итераторы
Алгоритмы
Примеры решения задач
Сортировка массива
Рассмотрим простейшую задачу: задано число n, затем n целых чисел, требуется отсортировать их по возрастанию. Поскольку n заранее неизвестно, в программе нужно использовать динамические массивы.
Так, с точки зрения языка C память можно выделить при помощи malloc , к тому же стандартная библиотека языка C предоставляет функцию qsort для выполнения быстрой сортировки. Решение получается таким:
При помощи средств языка C++ решить эту задачу проще. Так, нет нужды выделять память вручную, ведь можно применить стандартный контейнер vector из STL и записать числа в него. Тогда не нужно будет думать о том, что память после использования надо не забыть освободить (вызов free() ).
Алгоритм сортировки sort из STL превосходит по всем параметрам функцию qsort . Код сортировки шаблонный и точно знает, с каким типом он работает, поэтому нет необходимости писать компаратор, вызывать на каждое сравнение внешнюю функцию и передавать ей сырые указатели. Программа получается проще и при этом работает быстрее!
Подсчёт числа различных строк
Пусть дан набор строк, строки поступают на стандартный ввод. Требуется вывести все различные строки в лексикографическом порядке и для каждой указать, сколько раз она встретилась в наборе.
Читайте также: