
Intel gaussian mixture model 1911 что это
Обновлено: 02.07.2024
Фоновое моделирование обучения OpenCV3 (10.3) на основе модели гауссовой смеси BackgroundSubtractorMOG / MOG2
Основные классы, используемые для фонового моделирования в OpenCV: BackgroundSubtractor, BackgroundSubtractorMOG, BackgroundSubtractorMOG2, BackgroundSubtractorKNN. BackgroundSubtractor имеет большое различие между версиями OpenCV2.x и 3.x. 3.x предоставляет более богатый интерфейс API, отменяет моделирование фона Гаусса 1 (BackgroundSubtractorMOG) в 2.4 и сохраняет моделирование фона Гаусса 2 (BackgroundSubtractorMOG2) Введено KNN фоновое моделирование (BackgroundSubtractorKNN).
Происхождение идеи фонового моделирования
В системе наблюдения фон съемки обычно представляет собой фиксированную сцену с небольшими изменениями. Обычно мы предполагаем, что статические сцены без навязчивых объектов имеют некоторые общие характеристики, которые могут быть описаны статистической моделью. GMM использует гауссову модель и представляет собой взвешенную сумму нескольких гауссовских моделей для моделирования характеристик фона. Таким образом, как только фоновая модель известна, вторгающийся объект может быть обнаружен путем маркировки части изображения сцены, которая не соответствует фоновой модели. Этот процесс называется вычитанием фона. После того, как фон имитируется моделью гауссовой смеси, теперь подтверждается, что эта модель становится серией параметров в формуле модели гауссовой смеси. Для решения параметров обычно используется ЭМ-алгоритм. ЭМ-алгоритм делится на два этапа: Э-шаг И М-шаг. к
Необходимость модели гауссовой смеси:
(1) Если условия освещения в сцене стабильны, а фон зафиксирован, то значение пикселя в определенной точке будет относительно стабильным. Учитывая наличие шума, для лучшего описания можно использовать распределение Гаусса Значение пикселя в этой точке
(2) В реальных сценах условия освещения часто нестабильны, и есть некоторые локально движущиеся фоновые объекты (например, колышущиеся ветви). В настоящее время более целесообразно использовать несколько гауссовых распределений для выражения
(3) Фоновая область в реальной сцене также может изменяться в реальном времени, поэтому требуется стратегия обновления параметров распределения гауссовой смеси в реальном времени
Gaussian Mixture Distribution (GMM) - классический алгоритм фонового моделирования, с момента его появления было много работ по его улучшению и применению. opencv2.4.13 также представил алгоритм и его улучшенную версию. Opencv инкапсулирует базовую версию GMMo как BackgroundSubtractorMOG, улучшенную версию GMM, а opencv инкапсулирует ее как класс алгоритма BackgroundSubtractorMOG2. Mog2 использует адаптивную модель гауссовой смеси (Adaptive GMM, модель гауссовой смеси) .В программе испытаний результаты нескольких алгоритмов извлечения фона MOG, MOG2, GMG с открытым исходным кодом в OpenCV, MOG2 действительно находятся на переднем плане непрерывности и вычислительного времени Выше всего выделяются, а результаты сравнения будут приведены позже.
Усовершенствованный алгоритм GMM, то есть алгоритм BackgroundSubtractorMOG2, имеет два основных улучшения: (1) Увеличение функции обнаружения тени (2) Эффективность алгоритма значительно улучшена (число гауссовых компонентов не фиксировано). Значение последнего самоочевидно: значение первого заключается в том, что если некоторые методы не используются для обнаружения теней, то он может быть распознан как объект переднего плана, в результате чего объект переднего плана приобретет неправильную форму, что вызовет проблемы при последующей обработке (например, отслеживание). положительный эффект







«Сортировать и удалить» на приведенном выше рисунке немного неточно. В фактическом процессе распределение индекса Гаусса после N не будет «удалено», а является условием для оценки предыдущего сценического места
В процессе расчета критерии оценки бывшего живописного места включают в себя точки, которые не соответствуют текущему набору гауссовых моделей, и хотя индекс совпадающей модели превышает N, рассчитанный по T, последний, как правило, является новым явлением в сцене. пиксель

Это алгоритм сегментации переднего плана / фона, основанный на модели гауссовой смеси. Это было предложено P.KadewTraKuPong и R.Bowden в 2001 году. Он использует K (K = 3 или 5) гауссовых распределений для моделирования фоновых пикселей. Используйте промежуток времени, в течение которого эти цвета (во всем видео) существуют в качестве веса микса.Цвет фона обычно длится дольше и более статичен.Как может пиксель иметь распределение? Пиксель на плоскости x, y - это пиксель без распределения, но фоновое моделирование, о котором мы говорим, основано на временных рядах, поэтому положение каждого пикселя находится во всем временном ряду. Там будет много значений, таким образом формируя распределение.
При написании кода нам нужно использовать функцию: createBackgroundSubtractorMOG () для создания фонового объекта. Эта функция имеет несколько необязательных параметров, таких как продолжительность времени для моделирования сцены, количество компонентов гауссовой смеси, пороговые значения и т. Д. Установите их все как значения по умолчанию. Затем во всем видео нам нужно использовать фоны subsubtractor.apply (), чтобы получить маску переднего плана.
Прототип MOG находится в модуле bgsegm в библиотеке opencv_contrib (версия opencv3.4.3):
нотаРазличные реализации функций BackgroundSubtractorMOG / MOG2 в opencv3.0 и opencv2.4.
В версии opencv2 пример алгоритма MOG:
Это также алгоритм сегментации фона / переднего плана, основанный на модели гауссовой смеси. Он основан на двух статьях З.Зивковича в 2004 и 2006 годах. Как упомянуто выше, MOG представлен взвешенной суммой нескольких гауссовских моделей. Принимая во внимание M гауссовых компонентов, обсуждение значения M является предметом исследования автора MOG2: MOG принимает фиксированное количество гауссовых компонентов, MOG2 автоматически выбирает количество компонентов в соответствии с различными входными сценариями , Особенностью этого алгоритма является то, что он выбирает соответствующее количество гауссовых распределений для каждого пикселя. (В предыдущем методе мы использовали распределение K Гаусса). Это лучше адаптируется к изменениям сцены, вызванным изменениями яркости. В более простых сценах будет выбран только еще один важный гауссов компонент, который экономит время выбора того компонента, которому принадлежит, при последующем обновлении фона и повышает скорость. Как и прежде, нам нужно создать фоновый объект. Но здесь мы можем выбрать, обнаруживать ли тени. Если detectShadows = T rue (по умолчанию), он будет обнаруживать и отмечать тени, но это замедлит скорость обработки. Тень будет отмечена серым цветом.

Преимущество этого состоит в том, что в качестве доказательства есть два результата теста: один - использовать тестовую программу в OpenCV для тестирования различных алгоритмов на одной и той же простой сцене, чтобы проверить время выполнения видео, как показано в следующей таблице, очевидно, что mog2 намного быстрее;
Метод создания объекта и описание параметра:
Обнаружение движения применить функцию:
eg:mog2->apply(src_Y, foreGround, 0.005);
- исходное изображение
- передний план маски (двоичное изображение)
- скорость обучения learningRate, значение 0-1, когда оно равно 0, фон не обновляется, когда оно равно 1, оно обновляется кадр за кадром, по умолчанию используется значение -1, то есть алгоритм автоматически обновляется;
Официальная процедура фонового моделирования MOG2 для opencv3 выглядит следующим образом:
Сравнение MOG и MOG2:
Эффект извлечения фона показан на рисунке ниже, слева слева - эффект алгоритма BackgroundSubtractorMOG2, а справа - эффект BackgroundSubtractorMOG. Сначала игнорируя некоторый шум на левом изображении, мы видим, что самое большое различие между ними состоит в том, что на левом изображении есть области, заполненные серым. Это улучшение алгоритма обнаружения теней BackgroundSubtractorMOG2. Эти серые области вычисляются по алгоритму. «Теневая» область. Другое отличие заключается во времени выполнения алгоритма.В соответствии с выводом консоли, BackgroundSubtractorMOG2 обнаруживает около 0,03 с на кадр, а BackgroundSubtractorMOG обнаруживает около 0,06 с на кадр. Алгоритм BackgroundSubtractorMOG2 имеет большее улучшение времени выполнения (на самом деле не все из-за самого алгоритма) (BackgroundSubtractorMOG2 выполняется параллельно через несколько потоков во время выполнения).
Привет, Хабр. Я бы хотел рассказать об одном из подходов в решении задачи диаризации дикторов и показать, как этот метод можно реализовать на языке python. Чтобы не отпугивать читателя, я не буду приводить сложные математические формулы (отчасти потому что я и сам «не настоящий сварщик»), а постараюсь изложить всё простым языком и рассказать всё так, чтобы понял разработчик, никогда прежде не сталкивавшийся с машинным обучением.
Готовясь написать эту статью, я выбирал между двумя вариантами изложения: для тех, кто уже знаком с Data Science и тех, кто просто хорошо программирует. В итоге я выбрал второй вариант, решив, что это будет неплохой демонстрацией возможностей DS.
Постановка задачи
Как говорит нам Википедия, диаризация — это процесс разделения входящего аудиопотока на однородные сегменты в соответствии с принадлежностью аудиопотока тому или иному говорящему. Иными словами, запись нужно разделить на кусочки и пронумеровать: вот в этих местах говорит один человек, а вот в этих другой. С точки зрения машинного обучения, подобного рода задачи принадлежат к классу обучения без учителя и называются кластеризацией. О том, какие методы кластеризации существуют можно почитать например здесь или здесь, я же рассажу только о тех, которые нам пригодятся — это Гауссова Смесь Распределений (Gaussian Mixture Model) и Спектральная Кластеризация (Spectral Clustering). Но о них чуть позже.
Начнём с самого начала.
Подготовка окружения
Не был уверен, стоит ли оставлять этот раздел — не хотелось превращать статью в совсем уж туториал. Но в итоге оставил. Кому не нужно, тот пропустит, а тем, кто будет делать всё с нуля, этот шаг облегчит старт.Вообще говоря, помимо R, язык python является основным при решении задач Data Science, и если вы еще не пробовали программировать на нём, то я очень рекомендую это сделать, потому что python позволяет сделать многие вещи изящно, буквально в несколько строк (кстати, есть даже такой мем).
Существуют две отдельно развивающиеся ветки питона — версии 2 и 3. В моих примерах я использовал версию 3.6, но при желании их легко можно портировать на версию 2.7. Любую из этих веток удобно разворачивать вместе с инсталятором Анаконда, установив который вы сразу же получите интерактивную оболочку для разработки — IPython.
Помимо самой среды разработки понадобятся дополнительные библиотеки: librosa (для работы с аудио и извлечением признаков), webrtcvad (для сегментации) и pickle (для записи обученных моделей в файл). Все они устанавливаются простой командой в Anaconda Prompt
Feature Extraction
Начнём с извлечения признаков — данных, с которыми будут работать модели машинного обучения. В принципе, звуковой сигнал сам по себе — это уже данные, а именно упорядоченный массив значений амплитуды звука, к которому добавляется заголовок, содержащий количество каналов, частоту дискретизации и прочую информацию. Но анализировать эти данные напрямую мы не сможем, поскольку они не содержат таких вещей, глядя на которые, наша модель может сказать — ага, вот эти куски принадлежат одному и тому же человеку.
В задачах обработки речи существует несколько подходов к извлечению признаков. Одним из них является получение мел-частотных кепстральных коэффициентов (Mel Frequency Cepstral Coefficients). О них здесь уже писали, поэтому я лишь слегка напомню.

Исходный сигнал нарезают на фреймы длиной 16-40 мс. Далее, применив к фрейму окно Хемминга, делают быстрое преобразование Фурье и получают спектральную плотность мощности. Затем специальной «гребёнкой» фильтров, расположенных равномерно по мел-шкале делают мел-спектрограмму, к которой применяют дискретное косинусное преобразование (DCT) — широко используемый алгоритм сжатия данных. Полученные таким образом коэффициенты представляют из себя некую сжатую характеристику фрейма, при этом, поскольку фильтры, которые мы применяли, расположены были в мел-шкале, коэффициенты несут больше информации в диапазоне восприятия человеческого уха. Как правило, используют от 13 до 25 MFCC на фрейм. Поскольку помимо самого спектра индивидуальность голоса формируется скоростью и ускорениями, MFCC комбинируют с первой и второй производными.
Вообще, MFCC — это самый распространённый вариант работы с речью, но помимо них существуют и другие признаки — LPC (Linear Predictive Coding) и PLP (Perceptual Linear Prediction), а еще иногда можно встретить LFCC, где вместо мел-шкалы используется линейная.
Посмотрим, как извлечь MFCC в python.
Как видим, делается это действительно всего в несколько строк. Теперь перейдём к первому алгоритму кластеризации.
Gaussian Mixture Model
Модель смеси Гауссовых распределений предполагает что наши данные — это смесь многомерных распределений Гаусса с определёнными параметрами.
При желании можно легко найти и детальное описание модели и как работает EM-алгоритм, обучающий эту модель, я же обещал не наводить тоску сложными формулами и поэтому покажу красивые примеры из этой статьи.
Сгенерируем четыре кластера и нарисуем их.

Создадим модель, обучим на наших данных и снова отрисуем точки но уже с учётом предсказанной моделью принадлежности к кластерам.

Модель неплохо справилась с искусственными данными. В принципе, регулируя число компонент смеси и тип матрицы ковариаций (число степеней свободы гауссиан), можно описывать достаточно сложные данные.

Итак, мы знаем как делать параметризацию данных и умеем обучать модель смеси гауссовых распределений. Теперь можно было бы попробовать сделать кластеризацию в лоб — обучая GMM на извлеченных из диалога MFCC. И, наверное, в каком-то идеальном сферически-вакуумном диалоге, в котором каждый диктор будет укладываться в свою гауссиану, мы получим хороший результат. Понятное дело, что в реальности такого никогда не будет. На самом деле с помощью GMM моделируют не диалог, а каждого человека в диалоге — т. е. представляют, что голос каждого диктора в извлечённых признаках описывается своим набором гауссиан.
Подытоживая, мы потихоньку подбираемся к основной теме.
Сегментация
Традиционно процесс диаризации состоит из трёх последовательных блоков — обнаружение речи (Voice Activity Detection), сегментация и кластеризация (есть модели, в которых последние два шага совмещены, см. LIA E-HMM).
В первом шаге происходит отделение речи от различного рода шумов. Алгоритм VAD определяет является ли поданный на него кусок аудиозаписи речью, или это, например, звучит сирена или кто-то чихнул. Понятное дело, что для того, чтобы такой алгоритм был качественным необходимо обучение с учителем. А это в свою очередь означает, что необходимо размечать данные — иными словами создавать базу данных с записями речи и всевозможных шумов. Мы поступим лениво — возьмём готовый VAD, который работает не идеально, но для начала нам хватит.
Второй блок нарезает данные с речью на сегменты с одним активным говорящим. Классическим подходом в этом плане является алгоритм определения смены диктора на основе байесовского информационного критерия — BIC. Суть этого метода заключается в следующем — скользящим окном проходятся по аудиозаписи и в каждой точке прохода отвечают на вопрос: «Как данные в этом месте лучше описываются — одним распределением или двумя?». Для ответа на этот вопрос вычисляется параметр , исходя из знака которого принимается решение о смене диктора. Проблема в том, что этот метод будет работать не очень хорошо в случае частой смены диктора, да еще в присутствии шумов (которые очень характерны для записи телефонного разговора).
В оригинале я работал с записями телефонных разговоров кол-центра средней продолжительностью около 4-х минут. По понятным причинам эти записи я выложить не могу, поэтому для демонстрации я взял запись интервью с одной радиостанции. В случае с длинным интервью этот метод возможно дал бы приемлемый результат, но на моих данных он не сработал.В условиях, когда дикторы друг друга не перебивают, и их голоса не накладываются друг на друга, VAD, который мы будем использовать, более менее справляется с задачей сегментации, поэтому первые два шага у нас будут выглядеть следующим образом.
В действительности люди конечно будут говорить одновременно. Более того, VAD в некоторых местах сплоховал, из-за того, что запись не живая, а представляет собой склейку, в которой вырезаны паузы. Вы можете попробовать повторить нарезку на сегменты, увеличив агрессивность VAD'а с 2-х до 3-х.
GMM-UBM
Теперь у нас есть отдельные сегменты, и мы решили, что будем с помощью GMM моделировать каждого диктора. Извлечём признаки из сегмента и на этих данных обучим модель. Сделаем так на каждом сегменте и получившиеся модели сравним между собой. Вполне оправдано ожидать, что модели, обученные на сегментах, принадлежащих одному и тому же человеку, будут как-то схожи. Но тут мы сталкиваемся со следующей проблемой, извлекая признаки из аудиофайла длиной 1 сек с частотой дискретизации 8000 Гц при размере окна 10 мс, мы получим набор из 800 векторов MFCC. На таких данных наша модель обучиться не сможет, потому что это ничтожно мало. Даже, если это будет не одна секунда, а десять, данных все равно будет недостаточно. И здесь на помощь приходит Универсальная Фоновая Модель (UBM — Universal Background Model), её еще называют дикторонезависимой. Идея заключается в следующем. Мы обучим GMM на большой выборке данных (в нашем случае это полная запись интервью) и получим на выходе акустическую модель обобщённого диктора (это и будем наша UBM). А затем, используя специальный алгоритм адаптации (о нём чуть ниже), мы будем «подгонять» эту модель под признаки, извлекаемые из каждого сегмента. Этот подход широко используется не только для диаризации, но и в системах распознавания по голосу. Для распознания человека по голосу сначала нужно обучить модель на нём и без UBM нужно было бы иметь в распоряжении по несколько часов записи речи этого человека.
Из каждой адаптированной GMM мы извлечём вектор коэффициентов сдвига (он же медиана или мат. ожидание, если угодно) и, основываясь, на данных об этих векторах со всех сегментов, будем делать кластеризацию (ниже будет понятно почему именно вектор сдвигов).

MAP Adaptation
Метод, которым мы будем подгонять UBM под каждый сегмент называется Maximum A-Posteriori Adaptation. В общем случае алгоритм следующий. Сначала рассчитывается апостериорная вероятность на адаптационных данных и достаточные статистики для веса, медианы и дисперсии каждой гауссианы. Затем полученные статистики комбинируются с параметрами UBM и получаются параметры адаптированной модели. В нашем случае мы будем адаптировать только медианы, не затрагивая остальных параметров. Не смотря на то, что обещал не углубляться в математику, приведу всё-таки три формулы, потому что MAP адаптация — ключевой момент в этой статье.
Здесь — апостериорная вероятность, — достаточная статистика для , — медиана адаптированной модели, — коэффициент адаптации, — фактор соответствия.
Если все это кажется белибердой и вызывает уныние — не отчаивайтесь. На самом деле для понимания работы алгоритма необязательно вникать в эти формулы, его работу легко можно продемонстрировать следующим примером:

Допустим у нас есть какие-то достаточно большие данные, и мы обучили на них UBM (левый рисунок, UBM — это двухкомпонентная смесь гауссовых распределений). Появляются новые данные, которые не укладываются в нашу модель (рисунок посередине). С помощью указанного алгоритма мы будем смещать центры гауссиан так, чтобы они ложились на новые данные (рисунок справа). Применяя этот алгоритм на экспериментальных данных, мы будем ожидать, что на сегментах с одним и тем же диктором гауссианы будут смещаться в одном направлении, образуя таким образом кластеры. Именно поэтому для кластеризации сегментов мы будем использовать данные о сдвиге .
Итак, давайте проведём MAP адаптацию для каждого сегмента. (Для справки: помимо MAP Adaptation широко используется метод MLLR — Maximum Likelihood Linear Regression и некоторые его модификации. Также пробуют эти два метода объединять.)
Теперь, когда для каждого сегмента у нас есть данные о , мы наконец переходим к финальному шагу.
Спектральная кластеризация
Спектральная кластеризация вкратце описана в статье, ссылку на которую я приводил в самом начале. Алгоритм строит полный граф, где вершины — это наши данные, а рёбра между ними — это мера схожести. В задачах распознавания голоса в качестве такой меры используется косинусная метрика, поскольку она учитывает угол между векторами, игнорируя их магнитуду (которая не несёт информации о дикторе). Построив граф, рассчитываются собственные векторы матрицы Кирхгофа (которая по сути является представлением полученного графа) и затем применяется какой-нибудь стандартный метод кластеризации, например метод k-средних. Укладывается всё это в две строчки кода
Выводы и дальнейшие планы
Описанный алгоритм был опробован с различными параметрами:
- Количество MFCC: 7, 13, 20
- MFCC в комбинации с LPC
- Тип и количество смесей в GMM: full [8, 16, 32], diag [8, 16, 32, 64, 256]
- Методы адаптации UBM: MAP (с covariance_type = 'full') и MLLR (с covariance_type = 'diag')
К сожалению, у меня не хватило терпения (эту статью я начал писать больше месяца назад) для того, чтобы разметить полученные сегменты и посчитать DER (Diariztion Error Rate). Субъективно работу алгоритма я оцениваю как «в принципе неплохо, но далеко от идеала». Сделав кластеризацию на векторах, полученных из первой сотни сегментов (с одним проходом MAP), а затем выделив те, где говорит интервьюер (девушка, она там говорит гораздо меньше гостя), кластеризация выдаёт список , что является 100% попаданием. При этом выпадают сегменты, где присутствуют оба диктора (например 14), но это уже можно свалить на ошибку VAD'а. Причём такие сегменты начинают учитываться с увеличением числа проходов MAP. Важный момент. Интервью, с которым мы работали — более менее «чистое». Если добавляются различные музыкальные вставки, шумы и прочие неречевые штуки, кластеризация начинает хромать. Поэтому в планах попробовать обучить собственный VAD (потому что webrtcvad, например, не отделяет музыку от речи).
В связи с тем, что изначально я работал с телефонным разговором, у меня не было необходимости оценивать количество дикторов. Но не всегда количество дикторов предопределено, даже если это интервью. Например в этом интервью в середине звучит анонс, наложенный на музыку, и озвученный дополнительными двумя людьми. Поэтому интересно было бы попробовать метод оценки количества дикторов, указанный в первой статье в разделе списка литературы (основанный на анализе собственных значений нормализованной матрицы Лапласа).
Список литературы
Помимо материалов, расположенных по ссылкам в тексте и Jupyter ноутбуках, для подготовки этой статьи были использованы следующие источники:
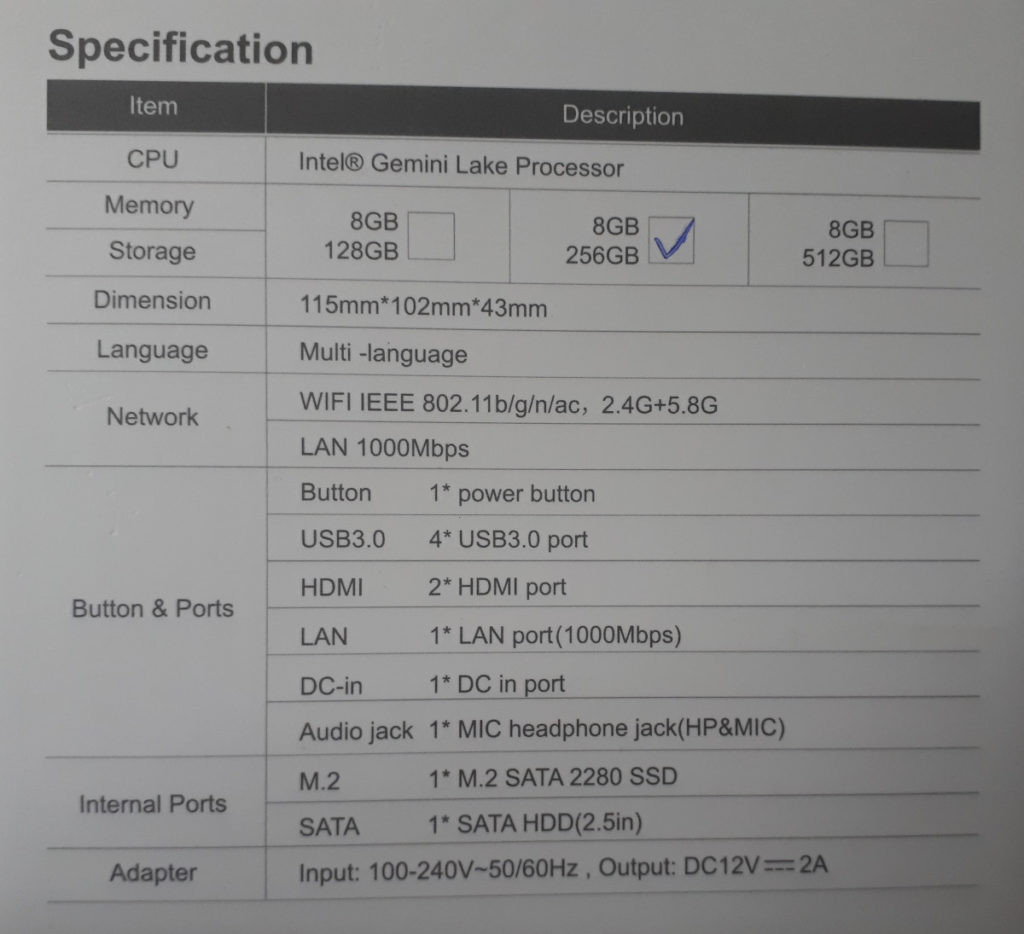
Компания Beelink недавно выпустила еще один мини-ПК в малом форм-факторе (SFF), похожий на традиционный Intel ‘NUC’ под названием GKmini, который будет рассмотрен сегодня в обзоре. Он представляет собой полностью настроенный мини-ПК с Windows 10 Pro, который готов к работе прямо из коробки.

Обзор оборудования
Beelink GKmini поставляется в прямоугольном пластиковом корпусе размером 115 x 102 x 43 мм (4.53 x 4.02 x 1.69 дюймов). Он также имеет активное охлаждение и оснащен 14-нм процессором J4125 Gemini Lake Refresh, который представляет собой четырехъядерный / 4-поточный процессор с тактовой частотой 2,00 ГГц (Boost до 2.70 ГГц) и графикой Intel UHD Graphics 600.
На передней панели есть кнопка включения, разъем для наушников, два порта USB 3.0 и отверстие с кнопкой ‘CLR CMOS’, которая при нажатии очищает CMOS. Задняя панель включает в себя разъем питания, два порта HDMI, Gigabit Ethernet порт и еще два порта USB 3.0.
Данная модель включает в себя 256 Гб M.2 2280 SATA SSD-накопитель и 8 Гб памяти DDR4 2400 МГц, а также есть возможность добавить 2,5-дюймовый SATA диск:

Но есть некоторые ограничения, поскольку доступен только один канал памяти, однако память не припаяна и ее можно менять.
На коробке указаны следующие технические характеристики:
Содержимое коробки
Комплект включает в себя блок питания, два кабеля HDMI разной длины и монтажный кронштейн вместе с винтами для крепления устройства за монитором (телевизором). Также есть руководство пользователя:

Методика обзора
В данном обзоре будет использоваться Windows 10 версии 20H2 и Ubuntu 20.04 LTS, а также система будет протестирована с помощью набора часто используемых тестов в Windows и их аналогами для Linux вместе с ‘sbc-bench’, который представляет собой небольшой набор различных тестов производительности процессора. Кроме того, будет использоваться ‘Phoronix Test Suite’ для сравнения одного и того же набора тестов как в Windows, так и в Ubuntu. В Ubuntu также будет скомпилировано ядро Linux v5.4 (в конфигурации по умолчанию) в качестве теста производительности с использованием реального сценария.
Перед тестированием будут выполнены все необходимые установки и обновления. Также будут зафиксированы некоторые основные детали этого мини-ПК в каждой ОС.
Проблемы с установкой
В Ubuntu не работает звук через 3,5-мм разъем для наушников, но звук был доступен через HDM:

Производительность Windows
Мини-ПК Beelink GKmini поставляется с лицензионной копией Windows 10 Pro версии 20H. Операционная система будет обновлена до сборки 19042.985 и информация об оборудовании выглядит следующим образом:




Быстрая проверка показала, что аудио, Wi-Fi, Bluetooth и Ethernet работают.
Затем в схеме управления питанием было выбрана ‘Максимальная производительность’ и был запущен стандартный набор инструментов для тестирования производительности (2021 год), чтобы проверить производительность под Windows:
Для конкретного набора тестов Phoronix Test Suite результаты были следующие:

Все эти результаты можно затем сравнить с другими недавними мини-ПК:
Производительность Ubuntu на Beelink GKmini
После сжатия раздела Windows вдвое и создания нового раздела, была установлена Ubuntu, использовался ISO образ Ubuntu 20.04.2 в качестве двойной загрузки. После установки ОС и обновлений, была сделана быстрая проверка, которая показала, что Wi-Fi, Bluetooth и Ethernet работают, однако звук через 3,5 мм разъем для наушников так и не работал.
Ключевая информация об оборудовании в Ubuntu 20.04.2 выглядит следующим образом:
Сабж,перерыл весь интернет и ничего дельного не нашел. Всего чего добился так это в кедах в настройках аудиодевайса увидеть Comet Lake PCH-LP cAVS с единственной доступной опцией: «Off».
cat /proc/asound/card*/codec* | grep Codec выдает лишь Intel Cabylake HDMI.
Но в результате ничего не вышло, может есть те у кого есть такой же ноутбук и у кого звук завелся?
ядро хоть самое новое?
Да, я пробовал все от Арча до Убунты и везде обновлялся до самых новых ядер после установки.
EDIT: Самой удачной попыткой была установка убунты, там я и получил эту опцию с Comet Lake cAVS. В других дистрах до такого я не добирался.
crazyfrog ( 19.09.21 11:14:07 )Последнее исправление: crazyfrog 19.09.21 11:15:47 (всего исправлений: 1)
- aplay -l
- lspci -k | grep -iEA 5 "aud|sound"
- journalctl -b | grep -iE "Linux version|audio"
- cat /etc/*-release
P.S Сейчас сижу за офтопиком ибо работать надо, а без звука как то не очень.
crazyfrog ( 22.09.21 11:30:09 )Последнее исправление: crazyfrog 22.09.21 11:36:51 (всего исправлений: 1)

возможные варианты решения проблемы:
0) обновить ядро до последней версии
1) sudo apt install firmware-sof-signed
2) добавить параметр ядра snd_hda_intel.dmic_detect=0
Куча каких-то ошибок связанных с pulseaudio, это аудиосервер, попробуй на чистой альсе проиграть что-нибудь. Найди какие-нибудь звуки в wav, хотяб так find /usr -name "*.wav" -exec du -a <> \; | sort -n , и запусти через aplay, например так: aplay /usr/lib/libreoffice/share/gallery/sounds/untie.wav
Ты серьезно пользуешься clear linux? Мне кажется это просто полигон для бенчмарков, а не пользовательский дистр. Ты можешь взять флешку с новейшими live образами Ubuntu или Fedora и проверить без установки на диск работает ли звук там, и если там все просто работает то использовать них.
Я просто хотел потыкать Clear Linux он ведь для интел процов заточен и теоретически там все могло завестись из коробки.
Если запустить через aplay:
EDIT: Сейчас попробую записать флешку с кубунту и посмотреть что будет там
crazyfrog ( 22.09.21 12:13:13 )Последнее исправление: crazyfrog 22.09.21 12:14:36 (всего исправлений: 1)
А… все правильно, у тебя нет аудиокарты:
Это видеокарта говорит что может вывести цифровой звук через HDMI, а аудиоинтерфейса нету. Я сразу не заметил.
Intel Corporation Device 02c8 - это аудиинтерфейс в твоем ноуте. Его нужно было гуглить, вот например тут проблема с ним же.
Там опциями ядра модулю snd-intel-dspcfg предан параметр snd-intel-dspcfg.dsp_driver=1 и это вроде помогло. Только там ubuntu а у тебя clearlinux и наверное нету /etc/default/grub чтоб все сделать просто по той инструкции, так что гугли как указать параметры ядра в clear linux.
firmware-sof-signed не устанавливается:
А прописывание параметра ядра так же не помогает
Накатил кубунту и прописал этот параметр, к сожалению не помогло
попробуй лайв сд последней Manjaro
Все, что имеет строчку HDMI, относится к звуку, выводимому по HDMI. А тебе нужен звук. И скорее всего это реалтековский чип. Полный lspci в студию!

для начала, стоит установить дистрибутив linux.
без него звука не будет.
Все еще мало инфы, и у меня нет доверия к тому что ты смог указать параметры ядра корректно, кинь сюда как минимум modinfo snd-intel-dspcfg | grep -E "filename|parm" и aplay -l из установленной кубунту.|
Упс, modinfo не показывает установленные параметры, надо так: sudo grep -H '' /sys/module/snd_intel_dspcfg/parameters/*
Но уже девайс виден в alsa - HDA Intel PCH , попытайся проиграть wav файл с помощью aplay как я указывал.
Это из параметров ядра (я пробовал убирать этот параметр и ничего не менялось) /sys/module/snd_intel_dspcfg/parameters/dsp_driver:1
aplay ничего не дает
Ошибок нет? Если просто ничего не слышно то запусти alsamixer , нажми F6 выбери что-то вроде HD-Audio Generic главное не HDMI , у тебя должно отобразиться множество ползунков громкости, все их установи на максимум, где-то возможно установлен mute, буквой m он снимается и попытайся снова проиграть аудио через aplay.
в alsamixer только тот самый Intel PCH, больше ничего а ползунков у этого Intel PCH вообще нет
Тогда не знаю, у тебя относительно новое ядро 5.11 (февраль 2021 года), нужно попробовать новое ядро 5.14 (сентябрь 2021) или хотяб 5.13.
Тебе не обязательно ставить дистрибутив на диск, достаточно найти live дистрибутив с таким ядром, чтоб просто проверить. Самые новые ядра я думаю будут в manjaro (форк arch linux).
В linux ядро это и есть драва, новое ядро - новые драйверы, старое ядро - старые драйверы, потому если железо совсем новое то приходится искать пути ставить самые свежие ядра даже на обычный дистрибутив у которого релизный цикл сильно отстает от новинок.
И если на manjaro все заработает тебе нужно записать на память вывод aplay -l и самое главное запомнить версию ядра, и тогда почти на любом дистрибутиве где ты сможешь поставить эту версию ядра будет звук, это значит поддержку конкретного чипа/кодека только реализовали. К сожалению поддержку железа не бэкпортируют в старые ядра.
HDA кодеки они не на шине pci, а на шине hdaudio. Поэтому lspci их не покажет. Вот эти команды должны внести ясность: какие кодеки, какие из них с драйверами, какие драйверы кодеков загружены:
Так же в sofproject об этой звуковой карте знают и вроде как работают над ее поддержкой, но до тех пор пока ее не доделают завести ее надежды 0.
crazyfrog ( 10.10.21 07:45:07 )Последнее исправление: crazyfrog 10.10.21 07:45:20 (всего исправлений: 1)
Ну тогда взять их ядро и допатчить до актуального самого нового можно. Или купить USB звук, или выводить звук на смартфон по сети и слушать с него. Ну или просто их ядро воткнуть. Ситуация не безвыходная.
USB звук с ноутом ИМХО архаично, можно bluetooth использовать, какие-нибудь tws наушники или колонку.
Сейчас наоборот USB DAC популярны.
Можно и так, я что ль против? С пайпвайром вроде даже сносный звук получается, но воткнуть крошечную затычку может быть проще. К тому же USB звуковухи не имеют наводок и предпочтительней, так как даже USB 2 за глаза предостаточно чтобы вывести нужное количество данных.
Я попробовал накатить это ядро на кубунту, звук все еще не завелся, но в настройках было явно больше опций. Явно еще пилить и пилить эти дрова, думаю через пару месяцев можно и потыкать, а пока посижу на Win 11…
Читайте также: