
Intel mpi что это
Обновлено: 07.07.2024
Message Passing Interface — это открытая библиотека и фактически стандарт для распараллеливания распределенной памяти. Этот интерфейс обычно используется во многих рабочих нагрузках HPC. Рабочие нагрузки HPC на виртуальных машинах серии H и N с поддержкой RDMA могут использовать MPI для обмена данными по сети InfiniBand с низкой задержкой и высокой пропускной способностью.
- Размеры виртуальных машин с поддержкой SR-IOV в Azure поддерживают использование практически всех версий MPI с Mellanox OFED.
- Для обмена данными между виртуальными машинами, которые не поддерживают SR-IOV, поддерживаемые реализации MPI используют интерфейс Microsoft Network Direct (ND). Таким образом, поддерживаются только Microsoft MPI (MS-MPI) 2012 R2 и более поздних версий, а также Intel MPI 5.x. Более поздние версии библиотеки среды выполнения Intel MPI (2017, 2018) могут быть как совместимы, так и несовместимы с драйверами Azure RDMA.
Для виртуальных машин с поддержкой RDMA и SR-IOV подходят образы виртуальных машин CentOS-HPC версии 7.6 и более поздних версий. Эти образы виртуальных машин оптимизированы и предварительно загружены с помощью драйверов OFED для RDMA и различных, часто используемых библиотек MPI и пакетов для научных вычислений. Именно с них проще всего начать работу.
Несмотря на то что здесь приведены примеры для RHEL/CentOS, эти действия являются универсальными и применимыми для любой совместимой операционной системы Linux, такой как Ubuntu (16.04, 18.04, 19.04, 20.04) и SLES (12 SP4 и 15). Дополнительные примеры настройки других реализаций MPI на других дистрибутивах см. в репозитории azhpc-images.
Выполнение заданий MPI на виртуальных машинах с поддержкой SR-IOV с определенными библиотеками MPI (такими как платформа MPI) может потребовать настройки на клиенте ключей секций (p-ключей) с целью обеспечения изоляции и безопасности. Выполните действия, описанные в разделе Обнаружение ключей секций, чтобы узнать, как определить значения p-ключа и правильно их установить для задания MPI с помощью этой библиотеки MPI.
Следующие фрагменты кода приведены для примера. Рекомендуется использовать последние стабильные версии пакетов или обращаться к репозиторию azhpc-images.
Выбор библиотеки MPI
Если для приложения HPC рекомендуется определенная библиотека MPI, сначала попробуйте использовать эту версию. Если у вас есть возможность выбора MPI и вы хотите получить максимальную производительность, попробуйте использовать HPC-X. В целом HPC-X MPI работает лучше всего с платформой UCX для интерфейса InfiniBand и использует все возможности оборудования и программного обеспечения Mellanox InfiniBand. Кроме того, HPC-X и OpenMPI совместимы с ABI, поэтому вы можете динамически запускать приложение HPC с помощью средства HPC-X, которое было создано, используя OpenMPI. Intel MPI, MVAPICH и MPICH также совместимы с ABI.
На следующем рисунке показана архитектура популярных библиотек MPI.

Unified Communication X (UCX) — это платформа API обмена данными для HPC. Она оптимизирована для обмена данными по MPI через InfiniBand и работает со многими реализациями MPI, такими как OpenMPI и MPICH.
В последних сборках UCX устранена проблема, при которой при наличии нескольких интерфейсов сетевой карты выбирается правильный интерфейс InfiniBand. Дополнительные сведения см. в статье Устранение известных проблем с виртуальными машинами HPC и GPU при работе с MPI с использованием InfiniBand, если на виртуальной машине включено ускорение сети.
Набор средств программного обеспечения HPC-X содержит UCX и HCOLL и может быть построен для UCX.
Следующая команда иллюстрирует некоторые рекомендуемые аргументы mpirun для HPC-X и OpenMPI.
| Параметр | Описание |
|---|---|
| NPROCS | Указывает количество процессов MPI. Например, -n 16 . |
| $HOSTFILE | Указывает файл, содержащий имя узла или IP-адрес для указания расположения, где будут выполняться процессы MPI. Например, --hostfile hosts . |
| $NUMBER_PROCESSES_PER_NUMA | Указывает количество процессов MPI, которые будут выполняться в каждом домене NUMA. Например, чтобы задать четыре процесса MPI для каждого домена NUMA, используйте --map-by ppr:4:numa:pe=1 . |
| $NUMBER_THREADS_PER_PROCESS | Указывает количество потоков на процесс MPI. Например, чтобы задать один процесс MPI и четыре потока на каждый домен NUMA, используйте --map-by ppr:1:numa:pe=4 . |
| -report-bindings | Выводит значение сопоставления процессов MPI с ядрами. Это полезно для проверки правильности закрепления процесса MPI. |
| $MPI_EXECUTABLE | Указывает встроенную компоновку исполняемого файла MPI в библиотеках MPI. Программы-оболочки компилятора MPI делают это автоматически. Пример: mpicc или mpif90 . |
Ниже приведен пример выполнения микротестирования OSU для задержки.
Оптимизация групп MPI
Примитивы обмена данными в группе MPI предлагают гибкий, переносимый способ реализации операций обмена данными в группе. Они широко используются в различных научных параллельных приложениях и оказывают значительное влияние на общую производительность приложения. Сведения о параметрах конфигурации для оптимизации производительности обмена данными в группе с помощью HPC-X и библиотеки HCOLL для обмена данными в группе см. в статье TechCommunity.
Например, если у вас есть подозрение, что тесно связанное приложение MPI выполняет чрезмерное количество коллективных коммуникаций, можно попытаться включить Hierarchical Collectives (HCOLL). Чтобы включить эти функции, используйте следующие параметры.
При использовании HPC-X 2.7.4+ может потребоваться явная передача LD_LIBRARY_PATH, если версии UCX в MOFED и HPC-X отличаются.
OpenMPI
Установите UCX, как описано выше. HCOLL входит в состав набора средств программного обеспечения HPC-X и не требует специальной установки.
OpenMPI можно установить из пакетов, доступных в репозитории.
Рекомендуется собрать последний, стабильный выпуск OpenMPI с UCX.
Для оптимальной производительности запустите OpenMPI с ucx и hcoll . См. также пример с HPC-X.
Проверьте ключ секции, как описано выше.
Intel MPI
Скачайте версию Intel MPI по своему выбору. Выпуск Intel MPI 2019 перешел с платформы Open Fabric Alliance (OFA) на платформу Open Fabric Interfaces (OFI) и сейчас поддерживает libfabric. Существует два поставщика поддержки InfiniBand: mlx и verbs. Измените переменную среды I_MPI_FABRICS в зависимости от версии.
- Intel MPI 2019 и 2021: используйте I_MPI_FABRICS=shm:ofi , I_MPI_OFI_PROVIDER=mlx . Поставщик mlx использует UCX. Было обнаружено, что использование команд стало нестабильным и менее производительным. Дополнительные сведения см. в статье TechCommunity.
- Intel MPI 2018: используйте I_MPI_FABRICS=shm:ofa
- Intel MPI 2016: используйте I_MPI_DAPL_PROVIDER=ofa-v2-ib0
Ниже приведены некоторые рекомендуемые аргументы mpirun для Intel MPI 2019 с обновлением 5+.
| Параметр | Описание |
|---|---|
| FI_PROVIDER | Указывает, какой поставщик libfabric следует использовать, что влияет на используемые интерфейсы API, протокол и сеть. verbs является еще одним вариантом, но обычно mlx обеспечивает лучшую производительность. |
| I_MPI_DEBUG | Указывает уровень дополнительных отладочных выходных данных, которые могут содержать сведения о том, где закреплены процессы и какие протокол и сеть используются. |
| I_MPI_PIN_DOMAIN | Указывает способ закрепления процессов. Например, за ядрами, сокетами или доменами NUMA. В этом примере вы присваиваете этой переменной среде значение numa, то есть процессы будут закреплены за доменами узла NUMA. |
Оптимизация групп MPI
Существуют и другие варианты, которые можно использовать, особенно если коллективные операции занимают значительное время. Intel MPI 2019 с обновлением 5+ поддерживает указанный mlx и использует платформу UCX для взаимодействия с InfiniBand. Он также поддерживает HCOLL.
Виртуальные машины без SR-IOV
Для виртуальных машин без SR-IOV пример загрузки бесплатной ознакомительной версии среды выполнения 5.x выглядит следующим образом:
Шаги установки см. в руководстве по установке библиотеки Intel MPI. Можно включить ptrace для некорневых процессов без отладчика (требуется для последних версий Intel MPI).
SUSE Linux
Для версий образа виртуальной машины SUSE Linux Enterprise Server SLES 12 SP3 для HPC, SLES 12 SP3 для HPC (Premium), SLES 12 SP1 для HPC, SLES 12 SP1 для HPC (Premium), SLES 12 SP4 и SLES 15 на виртуальной машине установлены драйверы RDMA и распределены пакеты Intel MPI. Установите MPI, выполнив следующую команду:
MVAPICH
Далее приведен пример сборки MVAPICH2. Примечание. Могут быть доступны более новые версии по сравнению с используемыми ниже.
Ниже приведен пример выполнения микротестирования OSU для задержки.
В приведенном ниже списке перечислены несколько рекомендуемых аргументов mpirun .
| Параметр | Описание |
|---|---|
| MV2_CPU_BINDING_POLICY | Указывает используемую политику привязки, которая влияет на то, как процессы закрепляются за основными идентификаторами. В этом случае вы указываете scatter, поэтому процессы будут равномерно распределены между доменами NUMA. |
| MV2_CPU_BINDING_LEVEL | Указывает, где следует закреплять процессы. В этом случае вы задаете значение numanode, то есть процессы закрепляются за элементами доменов NUMA. |
| MV2_SHOW_CPU_BINDING | Указывает, необходимо ли получать отладочные сведения о том, где закреплены процессы. |
| MV2_SHOW_HCA_BINDING | Указывает, необходимо ли получать отладочные сведения о том, какой хост-адаптер канала используется каждым процессом. |
Платформа MPI
Установите необходимые пакеты для платформы MPI Community Edition.
Выполните этапы процесса установки.
Следующие команды являются примерами запуска команд MPI pingpong и allreduce с использованием платформы MPI на виртуальных машинах HBv3, на которых установлены образы виртуальных машин CentOS-HPC 7.6, 7.8 и 8.1.
MPICH
Установите UCX, как описано выше. Выполните сборку MPICH.
Проверьте ключ секции, как описано выше.
Тесты производительности OSU MPI
Скомпилируйте тесты производительности с помощью определенной библиотеки MPI:
Тесты MPI находятся в папке mpi/ .
Обнаружение ключей секций
Выполните обнаружение ключей секций (p-ключей) для обмена данными с другими виртуальными машинами в пределах одного клиента (группа доступности или масштабируемый набор виртуальных машин).
Больший из двух является ключом клиента, который следует использовать с MPI. Пример. Ниже представлены p-ключи. С MPI следует использовать 0x800b.
Используйте секцию, отличную от ключа секции по умолчанию (0x7fff). UCX требует очистки p-ключа. Например, задайте для 0x800b значение ключа UCX_IB_PKEY 0x000b.
Кроме того, обратите внимание, что, пока существует клиент (группа доступности или масштабируемый набор виртуальных машин), ключи PKEY остаются неизменными. Это справедливо даже при добавлении или удалении узлов. Новые клиенты получают разные ключи PKEY.
Настройка ограничений пользователей для MPI
Настройте ограничения пользователей для MPI.
Настройка ключей SSH для MPI
Настройте ключи SSH для типов MPI, которые этого требуют.
В приведенном выше синтаксисе предполагается наличие общего домашнего каталога, в противном случае каталог SSH необходимо скопировать на каждый узел.

В этом посте мы расскажем об организации обмена данными с помощью MPI на примере библиотеки Intel MPI Library. Думаем, что эта информация будет интересна любому, кто хочет познакомиться с областью параллельных высокопроизводительных вычислений на практике.
Мы приведем краткое описание того, как организован обмен данными в параллельных приложениях на основе MPI, а также ссылки на внешние источники с более подробным описанием. В практической части вы найдете описание всех этапов разработки демонстрационного MPI-приложения «Hello World», начиная с настройки необходимого окружения и заканчивая запуском самой программы.
MPI является наиболее распространенным стандартом интерфейса передачи данных в параллельном программировании. Стандартизацией MPI занимается MPI Forum. Существуют реализации MPI под большинство современных платформ, операционных систем и языков. MPI широко применяется при решении различных задач вычислительной физики, фармацевтики, материаловедения, генетики и других областей знаний.
Параллельная программа с точки зрения MPI — это набор процессов, запущенных на разных вычислительных узлах. Каждый процесс порождается на основе одного и того же программного кода.
Рассмотрим на живом примере, как устроена типичная MPI-программа. В качестве демонстрационного приложения возьмем исходный код примера, поставляемого с библиотекой Intel MPI Library. Прежде чем запустить нашу первую MPI-программу, необходимо подготовить и настроить рабочую среду для экспериментов.
Настройка кластерного окружения
Для экспериментов нам понадобится пара вычислительный узлов (желательно со схожими характеристиками). Если под руками нет двух серверов, всегда можно воспользоваться cloud-сервисами.
Для демонстрации я выбрал сервис Amazon Elastic Compute Cloud (Amazon EC2). Новым пользователям Amazon предоставляет пробный год бесплатного использования серверами начального уровня.
Работа с Amazon EC2 интуитивно понятна. В случае возникновения вопросов, можно обратиться к подробной документации (на англ.). При желании можно использовать любой другой аналогичный сервис.
Создаем два рабочих виртуальных сервера. В консоли управления выбираем EC2 Virtual Servers in the Cloud, затем Launch Instance (под «Instance» подразумевается экземпляр виртуального сервера).
Следующим шагом выбираем операционную систему. Intel MPI Library поддерживает как Linux, так и Windows. Для первого знакомства с MPI выберем OC Linux. Выбираем Red Hat Enterprise Linux 6.6 64-bit или SLES11.3/12.0.
Выбираем Instance Type (тип сервера). Для экспериментов нам подойдет t2.micro (1 vCPUs, 2.5 GHz, Intel Xeon processor family, 1 GiB оперативной памяти). Как недавно зарегистрировавшемуся пользователю, мне такой тип можно было использовать бесплатно — пометка «Free tier eligible». Задаем Number of instances: 2 (количество виртуальных серверов).
После того, как сервис предложит нам запустить Launch Instances (настроенные виртуальные сервера), сохраняем SSH-ключи, которые понадобятся для связи с виртуальными серверами извне. Состояние виртуальных серверов и IP адреса для связи с серверами локального компьютера можно отслеживать в консоли управления.
Важный момент: в настройках Network & Security / Security Groups необходимо создать правило, которым мы откроем порты для TCP соединений, — это нужно для менеджера MPI-процессов. Правило может выглядеть так:
Type: Custom TCP Rule
Protocol: TCP
Port Range: 1024-65535
Source: 0.0.0.0/0
В целях безопасности можно задать и более строгое правило, но для нашего демонстрационного примера достаточно этого.
Здесь можно прочитать инструкции о том, как связаться с виртуальными серверами с локального компьютера (на англ.).
Для связи с рабочими серверами c компьютера на Windows я использовал Putty, для передачи файлов — WinSCP. Здесь можно прочитать инструкции по их настройке для работы с сервисами Amazon (на англ.).
- На каждом из хостов запускаем утилиту ssh-keygen — она создаст в $HOME/.ssh директории пару из приватного и публичного ключей;
- Берем содержимое публичного ключа (файл с расширением .pub) с одного сервера и добавляем его в файл $HOME/.ssh/authorized_keys на другом сервере;
- Проделаем эту процедуру для обоих серверов;
- Попробуем присоединиться по SSH с одного сервера на другой и обратно, чтобы проверить корректность настройки SSH. При первом соединении может потребоваться добавить публичный ключ удаленного хоста в список $HOME/.ssh/known_hosts.
Настройка MPI библиотеки
Итак, рабочее окружение настроено. Время установить MPI.
В качестве демонстрационного варианта возьмем 30-дневную trial-версию Intel MPI Library (
300МБ). При желании можно использовать другие реализации MPI, например, MPICH. Последняя доступная версия Intel MPI Library на момент написания статьи 5.0.3.048, ее и возьмем для экспериментов.
Установим Intel MPI Library, следуя инструкциям встроенного инсталлятора (могут потребоваться привилегии суперпользователя).
$ tar xvfz l_mpi_p_5.0.3.048.tgz
$ cd l_mpi_p_5.0.3.048
$ ./install.sh
Выполним установку на каждом из хостов с идентичным установочным путем на обоих узлах. Более стандартным способом развертывания MPI является установка в сетевое хранилище, доступное на каждом из рабочих узлов, но описание настройки подобного хранилища выходит за рамки статьи, поэтому ограничимся более простым вариантом.
Для компиляции демонстрационной MPI-программы воспользуемся GNU C компилятором (gcc).
В стандартном наборе программ RHEL образа от Amazon его нет, поэтому необходимо его установить:
В качестве демонстрационной MPI-программы возьмем test.c из стандартного набора примеров Intel MPI Library (находится в папке intel/impi/5.0.3.048/test).
Для его компиляции первым шагом выставляем Intel MPI Library окружение:
Далее компилируем нашу тестовую программу с помощью скрипта из состава Intel MPI Library (все необходимые MPI зависимости при компиляции будут выставлены автоматически):
$ cd /home/ec2-user/intel/impi/5.0.3.048/test
$ mpicc -o test.exe ./test.c
$ scp test.exe ip-172-31-47-24:/home/ec2-user/intel/impi/5.0.3.048/test/
Прежде чем выполнять запуск MPI-программы, полезно будет сделать пробный запуск какой-нибудь стандартной Linux утилиты, например, 'hostname':
$ mpirun -ppn 1 -n 2 -hosts ip-172-31-47-25,ip-172-31-47-24 hostname
ip-172-31-47-25
ip-172-31-47-24
Утилита 'mpirun' — это программа из состава Intel MPI Library, предназначенная для запуска MPI-приложений. Это своего рода «запускальщик». Именно эта программа отвечает за запуск экземляра MPI-программы на каждом из узлов, перечисленных в ее аргументах.
Касательно опций, '-ppn' — количество запускаемых процессов на каждый узел, '-n' — общее число запускаемых процессов, '-hosts' — список узлов, где будет запущено указанное приложение, последний аргумент — путь к исполняемому файлу (это может быть и приложение без MPI).
В нашем примере с запуском утилиты hostname мы должны получить ее вывод (название вычислительного узла) с обоих виртуальных серверов, тогда можно утверждать, что менеджер MPI-процессов работает корректно.
В качестве демонстрационного MPI-приложения мы взяли test.c из стандартного набора примеров Intel MPI Library.
Демонстрационное MPI-приложение cобирает с каждого из параллельно запущенных MPI-процессов некоторую информацию о процессе и вычислительном узле, на котором он запущен, и распечатывает эту информацию на головном узле.
Рассмотрим подробнее основные составляющие типичной MPI-программы.
Подключение заголовочного файла mpi.h, который содержит объявления основных MPI-функций и констант.
Если для компиляции нашего приложения мы используем специальные скрипты из состава Intel MPI Library (mpicc, mpiicc и т.д.), то путь до mpi.h прописывается автоматически. В противном случае, путь до папки include придется задать при компиляции.
Вызов MPI_Init() необходим для инициализации среды исполнения MPI-программы. После этого вызова можно использовать остальные MPI-функции.
Последним вызовом в MPI программе является MPI_Finalize(). В случае успешного завершения MPI-программы каждый из запущенных MPI-процессов делает вызов MPI_Finalize(), в котором осуществляется чистка внутренних MPI-ресурсов. Вызов любой MPI-функции после MPI_Finalize() недопустим.
Чтобы описать остальные части нашей MPI-программы необходимо рассмотреть основные термины используемые в MPI-программировании.
Кроме того в MPI существуют специальные объекты, называемые коммуникаторами (communicator), описывающие группы процессов. Каждый процесс в рамках одного коммуникатора имеет уникальный ранг. Один и тот же процесс может относиться к разным коммуникаторам и, соответственно, может иметь разные ранги в рамках разных коммуникаторов. Каждая операция пересылки данных в MPI должна выполняться в рамках какого-то коммуникатора. По умолчанию всегда создается коммуникатор MPI_COMM_WORLD, в который входят все имеющиеся процессы.
Вернемся к test.c:
MPI_Comm_size() вызов запишет в переменную size (размер) текущего MPI_COMM_WORLD коммуникатора (общее количество процессов, которое мы указали с mpirun опцией '-n').
MPI_Comm_rank() запишет в переменную rank (ранг) текущего MPI-процесса в рамках коммуникатора MPI_COMM_WORLD.
Вызов MPI_Get_processor_name() запишет в переменную name строковой идентификатор (название) вычислительного узла, на котором был запущен соответствующий процесс.
Собранная информация (ранг процесса, размерность MPI_COMM_WORLD, название процессора) далее посылается со всех ненулевых рангов на нулевой с помощью функции MPI_Send():
MPI_Send() функция имеет следующий формат:
Более подробное описание функции MPI_Send() и ее аргументов, а также других MPI-функций можно найти в MPI-стандарте (язык документации — английский).
MPI_Recv() функция имеет следующий формат:
В результате работы нашей демонстрационной MPI-программы мы получим:
$ mpirun -ppn 1 -n 2 -hosts ip-172-31-47-25,ip-172-31-47-24 /home/ec2-user/intel/impi/5.0.3.048/test/test.exe
Hello world: rank 0 of 2 running on ip-172-31-47-25
Hello world: rank 1 of 2 running on ip-172-31-47-24
Вас заинтересовало рассказанное в этом посте и вы хотели бы принять участие в развитии технологии MPI? Команда разработчиков Intel MPI Library (г.Нижний Новгород) в данный момент активно ищет инженеров-соратников. Дополнительную информацию можно посмотреть на официальном сайте компании Intel и на сайте BrainStorage.
И, напоследок, небольшой опрос по поводу возможных тем для будущих публикаций, посвященных высокопроизводительным вычислениям.
Никхил Виджай Шенде (Nikhil Vijay Shende), директор, S & I Engineering Solutions, Pvt. Ltd."В компании S & I Engineering Solutions Pvt, Ltd. занимаются разработкой быстрых и точных методов решения задач вычислительной гидродинамики. Важнейшими факторами при выборе библиотек MPI для нас являются масштабируемость и эффективность. Библиотека Intel MPI Library позволяет нашим алгоритмам масштабироваться более чем до 10 тыс. ядер, обеспечивая при этом высокие эффективность и быстродействие."
Библиотека Intel MPI Library позволяет повышать быстродействие приложений, работающих на кластерах архитектуры Intel. Она реализует высокопроизводительный протокол Message Passing Interface Version 2.2, поддерживая различные типы межсоединений. Библиотека позволяет быстро обеспечивать максимальное быстродействие , в том числе при замене или модернизации межсоединений; при этом не нужно вносить изменения в программное обеспечение и операционную среду.
Данную высокопроизводительную библиотеку MPI можно применять для создания приложений, работающих поверх кластерных межсоединений разных типов, выбирать которые может пользователь в период исполнения. Для продуктов, разработанных с помощью Intel MPI Library , предоставляется не требующий лицензионных отчислений комплект среды выполнения. Библиотека позволяет обеспечить превосходное быстродействие высокопроизводительным вычислительным приложениям для предприятий, подразделений, отделов, рабочих групп, а также персональным.

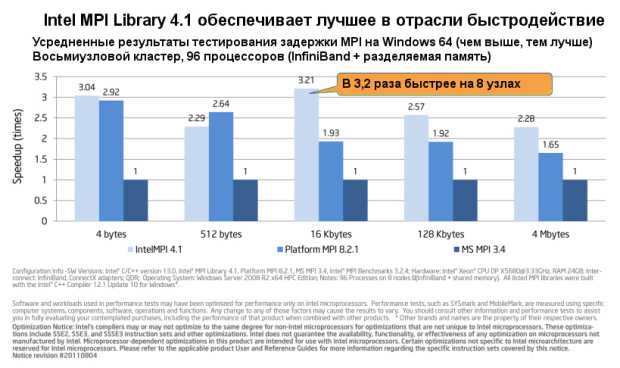
увеличить изображение
Intel MPI Library (Intel MPI) уменьшает задержку MPI, способствуя тем самым повышению пропускной способности.
Главные особенности
- Масштабирование до 120 тыс. процессов
- Диспетчер mpiexec.hydra теперь позволяет запускать больше процессов.
- Реализация MPI с низкой задержкой
- Режим разделяемой памяти с динамическим соединением, предназначенный для больших узлов симметричной многопроцессорной обработки
- Увеличенная производительность благодаря усовершенствованной поддержке протоколов DAPL и OFA
- Ускорение работы приложений с помощью улучшенной утилиты оптимизации для MPI
- Пользуйтесь межсоединениями высокого быстродействия, включая InfiniBand и Myrinet, а также TCP, разделяемой памятью и др.
- Высокоэффективная поддержка Direct Access Programming Library (DAPL*), Open Fabrics Association (OFA*) и Tag Matching Interface (TMI*) упрощает запуск и тестирование приложений поверх различных коммутирующих матриц.
- Оптимизация для коммутирующих матриц всех уровней, включая разделяемую память, Ethernet, RDMA и TMI
Подробности
Масштабируемость
Intel MPI Library 4.1 для Windows и Linux реализует отличающуюся высокой производительностью версию 2.2 спецификации MPI-2 для различных типов межсоединений. Назначение библиотеки - повышать быстродействие приложений на кластерах архитектуры IA. Intel MPI Library позволяет быстро обеспечить максимальный уровень быстродействия приложениям конечных пользователей, в том числе при замене или модернизации межсоединений; при этом не понадобится вносить серьезные изменения в ПО или операционную среду. Intel также предоставляет бесплатный комплект среды выполнения для программных продуктов, разработанных с использованием Intel MPI Library
Быстродействие
Оптимизированный интерфейс разделяемой памяти обеспечивает увеличенную пропускную способность и снижает задержку. Дополнительно ее уменьшению способствует нативный интерфейс InfiniBand (OFED Verbs). Благодаря многоканальной передаче данных обеспечивается повышение пропускной способности и ускорение межпроцессной связи, а поддержка Tag Matching Interface (TMI) увеличивает производительность при использовании межсоединений Qlogic* PSM и Myricom* MX.
Intel MPI Library поддерживает многие сетевые технологии
Intel MPI Library поддерживает TCP-сокеты, разделяемую память и различные межсоединения на основе удаленного прямого доступа к памяти (RDMA). Библиотека реализует универсальный слой поддержки межсоединений разного типа посредством методологий Direct Access Programming Library (DAPL*) и Open Fabrics Association (OFA*). Разрабатывая код для MPI, можно быть уверенным, что он будет эффективно работать независимо от того, какой тип межсоединений пользователь выбрал в период выполнения.
Intel MPI Library динамически устанавливает соединение, но только по мере необходимости, за счет чего уменьшается расход памяти. Кроме того, библиотека автоматически выбирает самый быстрый из доступных транспортных протоколов. Потребности в памяти снижаются с применением нескольких методов, в том числе с помощью механизма двухэтапного увеличения коммуникационного буфера, резервирующего в точности требуемый объем памяти.
Что нового
Варианты приобретения: пакеты для одного языка
Several suites are available combining the tools to build , verify and tune your application . The products covered in this product brief are highlighted in blue . Named-user or multi-user licenses along with volume , academic, and student discounts are available .

Кластерная архитектура
Содержание:
Ключевые особенности MPI
Допустим, есть у нас кластер. Чтобы программа начала на нем выполняться, ее необходимо скопировать на каждый узел, запустить и установить связь между процессами. Эту работу берет на себя утилита mpirun (под Linux) или mpiexec (под Windows), так например, чтобы запустить 5 процессов достаточно написать:
mpirun -np 5 path/your_mpi_program
Однако программа должна быть написана определенным образом. Вообще, технология MPI позволяет как использовать модель SPMD (Single Process, Multiple Data), так и MPMD [1], в этой статье я рассматривают только первый вариант. Далее по тексту узел и процесс будут означать одно и тоже, хотя на одном узле может быть создано несколько процессов (именно так я делаю при запуске примеров статьи, т.к. отлаживаю их на персональном компьютере). Это вводная статья, поэтому тут не пойдет речь о коммуникаторах, в которые могут группироваться процессы.
В связи с тем, что MPI-программа обладает множеством особенностей, компилироваться она должна специальным компилятором. Под Linux для этого используется mpic++, а под Windows можно применять расширение для Microsoft Visual Studio. Для сборки примеров статьи под Linux я использовал примерно следующую команду:
mpic++ main.cpp -o main
Операции точка-точка MPI
Рассмотрим первый пример:
Все обращения к функциям MPI должны размещаться между MPI_Init и MPI_Finalize. В качестве коммуникатора в этом примере используется MPI_COMM_WORLD, который включает в себя все процессы, запущенные для текущей задачи с помощью mpirun. Каждый процесс получает свой ранг с помощью вызова MPI_Comm_rank, количество процессов в коммуникаторе возвращает функция MPI_Comm_size.
Функции неблокирующего обмена имеют такие же аргументы как и их блокирующие аналоги, но в качестве дополнительного параметра принимают параметр типа MPI_Request. Чтобы нулевой процесс в приведенном выше примере работал асинхронно достаточно изменить лишь этот фрагмент кода:
Теперь функция передачи возвращает управление немедленно, сама же передача происходит параллельно с выполнением других команд процесса. Узнать о ходе выполнения асинхронной операции мы сможем с помощью специальных функций:
Чтобы избежать ошибок, необходимо представлять как именно может быть реализована работа неблокирующих функций. Например, MPI_Isend инициирует передачу данных, которая выполняется в отдельном потоке параллельно. По окончанию передачи этот поток должен изменить переменную request. Это значит, что такой код вполне может привести к ошибкам:
При использовании буферизованного режима исходный код будет не сильно отличаться от приведенного выше, ниже приведен только фрагмент, которого коснулись изменения:
Коллективные операции. Пример использования MPI_Reduce
Коллективные операции выполняются всеми процессами указанного коммуникатора. Ниже приведена картинка из стандарта [3], на которой показана суть некоторых операций:

Коллективные операции MPI
Операция MPI_Bcast теоретически (зависит от реализации библиотеки) может работать более эффективно и выполняться за \(O(log(n))\) операций вместо \(O(n)\).

Эффективная реализация MPI_Reduce и MPI_Bcast
На приведенной схеме цветом выделен узел, на котором находятся передаваемые данные. В начале работы такой узел один. После первой передачи данные есть уже на двух узлах, оба они могут участвовать в передачи. При реализации такой схемы для передачи данных на 1000 узлов будет достаточно 10 операций. Таким же образом может работать операция MPI_Reduce:
A more efficient implementation is achieved by taking advantage of associativity and using a logarithmic tree reduction. [3]
Операция MPI_Reduce не просто передает данные, но и выполняет над ними заданную операцию. В нашем примере применить ее можно вместо сбора результатов вычисления сумм:
Операция MPI_Reduce может выполняться не только над числами, но и над массивами (при этом будет применена к каждому его элементу отдельно).
Заключение
Пример с функцией MPI_Isend наглядно демонстрирует насколько сложно реализовать аналогичное поведение вручную. Дело не только в том, что передача выполняется в отдельном потоке. Сложно придумать механизм лучший, чем работа с MPI_Request, однако к объекту request может параллельно обращаться несколько потоков, поэтому все эти операции защищаются семафорами.
Читайте также: