
Interim recovery hp proliant что это
Обновлено: 07.07.2024
В данной статье рассмотрим процесс увеличения размера Raid массива HPE Smart Array P420i, заменив диски на большие по размеру. После этого расширим хранилище данных (Expand Datastore) на Hypervisor Esxi 6 и Esxi 7
Содержание
Введение
Все чаще стали возникать задачи, связанные с нехваткой места на сервере. Когда файловое хранилище создано на базе Synology, увеличить размер относительно простая задача. Об этом Вы можете прочитать в нашей статье "Как увеличить размер массива на Synology, замена диска".
Но когда мы говорим про увеличение места на серверах Гипервизорах, например Esxi или Hyper-V, процесс немного усложняется. Давайте разберем случай, когда у нас есть сервер HP dl360 gen8, на нем создан Raid массив 1 (зеркало) из двух дисков по 1TB.
На этом сервере на флэшку установлен гипервизор Esxi 6.7 (HPE Customized image). Как и зачем это сделано, Вы можете прочитать в нашей статье Установка Esxi на флэшку или SD карту HPE
В Esxi создано хранилище данных (Datastore) на весь размер Raid-массива, т.е. 1 TB. На сервере Esxi работают виртуальные машины, которые находятся на этом Datastore.
Нам нужно заменить два диска 1TB на два диска 4TB. После этого расширить существующее Datastore (хранилище данных).
Естественно, основная задача системного администратора обеспечить сохранность данных и минимальный простой оборудования (не забываем, что на Esxi работают виртуальные машины).
Описание тестового стенда
- Сервер HP dl360 gen8
- Raid - контроллер Smart Array P420i
- ОС-гипервизор Esxi 6.7 (HPE Customized image)
- Диски: WD Red Raid edition 1TB - 2шт. и WD Red Raid edition 4TB - 2шт.
План работ. Краткое описание действий
- На включенном сервере меняем диск с 1TB на 4 TB (горячая замена). Ждем, пока восстановится массив Raid1
- На включенном сервере меняем второй 1 TB диск (горячая замена) на второй 4 TB и ждем пока снова восстановится массив Raid1
- Проверяем через iLo, что все восстановилось
- Расширяем через hpssacli логический раздел с 1TB до 4 TB
- Проверяем через hpssacli, что логический диск расширился
- Перезагружаем сервер
- Расширяем Хранилище данных (Expand Datastore) в Esxi
Увеличение размера Raid1 (зеркало) Smart Array P420i . Замена дисков на большие по размеру.
На этом шаге главное не торопиться. Если массивы восстановятся некорректно, можно потерять данные на дисках.
Для начала заменим первый диск размером 1 TB на диск размером 4TB. Это можно делать, не выключая сервер "горячая замена".
После этого ждем и наблюдаем. Нам важно:
- Состояние массива в iLo
- Индикация на салазках жёстких дисков
Состояние в iLo будет меняться следующим образом.
После отключения первого диска, до замены его на 4TB, мы увидим:
После подключения (замены) 4TB диска:
Через некоторое время статус изменится на:
После завершения восстановления Raid-массива:
Состояние индикаторов на салазках HPE Gen8, Gen9, Gen10 будет меняться следующим образом.
После отключения первого диска, до замены его на 4TB, мы увидим:
- "Не снимайте" - Насыщенный белый (диск на 1TB)
- "Активное кольцо" - диск работает (диск на 1TB)
После подключения (замены) 4TB диска:
- "Не снимайте" - Насыщенный белый (диск на 1TB)
- "Активное кольцо" - Вращается по кругу зеленым. Диск работает (диск на 1TB)
- "Состояние привода" - мигает зелёным - Привод выполняет восстановление (Диск на 4TB)
- "Активное кольцо" - Вращается по кругу зеленым. Диск работает (диск на 4TB)
После завершения восстановления Raid-массива:
- "Состояние привода" - горит зелёным (на обоих дисках)
- "Активное кольцо" - Вращается по кругу зеленым (на обоих дисках)
После того как Raid-массив восстановился и его статус стал "OK", аналогичным образом меняем второй диск объёмом 1TB на диск объёмом 4 TB
После замены обоих дисков массива на 4TB переходим к расширению логического диска с помощью утилиты hpssacli
Расширение логического раздела через утилиту hpssacli
Перед тем как расширять логический диск Обязательно убедитесь, что Raid-массив восстановился и находится в состоянии "ОК"
Для расширения логического диска Raid-массива подключимся по ssh к серверу Esxi. Если Вы не знаете, как это сделать, прочитайте нашу статью Как подключиться к серверу ESXI по SSH
Для расширения логического диска нам понадобится информация:
- Номер слота Raid-контроллера slot
- Номер логического диска ld
Эту информацию можно получить выполнив команды:
В нашем случае slot=0, а ld=1
Для большего понимания можете изучить другие команды утилиты hpssacli в нашей статье Команды для ssacli hpssacli для работы с RAID на ESXI
Переходим к расширению логического диска. Для этого выполняем команду
В параметре size можно указать конкретный размер. Мы же расширяем диск на весь возможный объём (size=max).
После выполнения команды проверяем, что все прошло успешно. Логический диск увеличился в размерах и стал 4 TB
Если после этих действий подключиться к Esxi и попробовать расширить хранилище данных (Datastore), Вы увидите, что место не увеличилось.

esxi expand datastore failure
Для того чтобы гипервизор Esxi увидел, что логический диск увеличился, нужно перезагрузить сервер. Не забудьте корректно завершить работу виртуальных машин.
Перезагружаем сервер
Расширение хранилища данных (Expand Datastore)
После перезагрузки заходим в Esxi через веб. интерфейс и переходим в раздел Storage.
Выбираем нужное нам хранилище данных (Datastore) и нажимаем "Increase capacity".
В открывшемся мастере "Increase datastore capacity" выбираем "Expand an existing VMFS datastore extent". Нажимаем "Next".
На следующем шаге видим, что у нас появился диск на котором можно расширить хранилище данных (Datastore). Выбираем его и нажимаем "Next".

esxi expand datastore
На шаге 3 "Select partitioning options" выбираем на сколько нужно расширить хранилище данных (Datastore) и нажимаем "Next".

esxi expand datastore partition
Проверяем все ли верно и нажимаем "Finish"

esxi expand datastore partition finish
После этого хранилище данных (Datastore) будет увеличено. В нашем случае с 1 TB до 4 TB.

Как узнать прогресс rebuilding RAID на контроллере Smart Array P410i-01
Всем привет сегодня я расскажу как узнать прогресс восстановления RAID на контроллере Smart Array P410i. Под восстановлением RAID в данной статье я буду подразумевать процесс rebuild raid при замене ssd диска на сервере HP с raid контроллером P410i.
Задача: есть server hp на котором стоят ssd диски samsung evo 840, на время их покупки они выпускались с глючной прошивкой, из за которой со временем падала производительность, компания samsung выпустила новое обновление firmware исправляющее это. Я перепрошил запасные ssd evo 840 и нужно их заменить на те что у нас в сервере. Так как у меня на сервере raid 5 так как при raid 10 большого количества iops я не увидел а места скушалось половину. Так как raid 5 то отказоустойчивость один диск есть и можно менять ссд диски на живую. Вытаскиваем первый.
Выполним команду которая покажет нам статусы физических дисков установленных в server. Для того HP разработала утилиту hpssacli.
/opt/hp/hpssacli/bin/hpssacli ctrl slot=0 pd all show statusВидим, что при вытащенном ssd статус стал Filed.
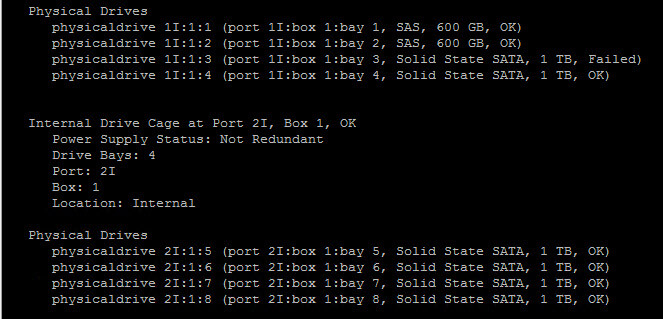
Как узнать прогресс rebuilding RAID на контроллере Smart Array P410i-02
Вставляем новый и смотрим теперь статус с помощью команды выше. Видим статус изменился и теперь он Rebuilding, что означает начало восстановление raid.
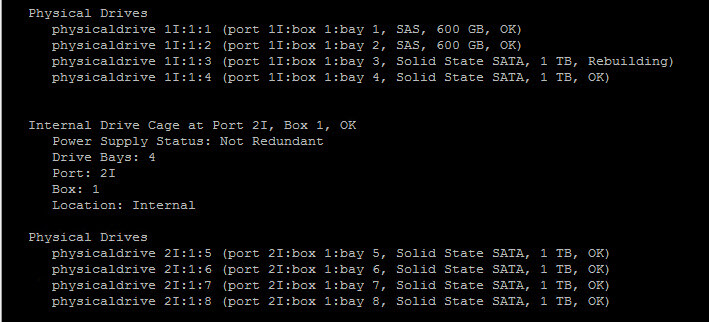
Как узнать прогресс rebuilding RAID на контроллере Smart Array P410i-03
у меня на сервере hp был установлен ESXI 5.5. В нем статус диска определяется как Unknown.
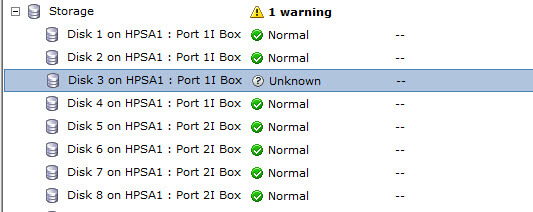
Как узнать прогресс rebuilding RAID на контроллере Smart Array P410i-05
теперь нам нужно узнать процент восстановления.
Как посмотреть прогресс восстановления RAID на контроллере Smart Array P410i
делается это командой которая показывает статус логических дисков рейда
/opt/hp/hpssacli/bin/hpssacli ctrl slot=0 logicaldrive all show statusПоявились проценты прогресса.

Как узнать прогресс rebuilding RAID на контроллере Smart Array P410i-06
Осталось только подождать завершения.
Вот так вот просто узнать процент восстановления вашего raid на серверах hp.
Абучю рускаму язаку
Репутация: нет
Всего: 7
Есть у меня сервер HP ProLiant ML370 G5
У него стоит Smart Array P400 Controller
8 винчестеров, которые объединены в RAID 1+0
один винчестер поломался и его заменили.
у нового винта ни одна лампочка не горит не мигает.
мне сказали, что нужно сделать ребилд, чтобы новый винт системой подцепился.
вопрос, как его сделать?
Вот что на странице System Management написано
Logical Drive 1 - Mirroring (RAID 1+0)
Status: Interim recovery
Total: 48 /sec
Fault Tolerance: Mirroring (RAID 1+0)
Reads: 23 /sec
Capacity: 273.34 GB
Writes: 25 /sec
Accelerator: Enabled
Sectors Read: 1120 /sec
Stripe Size: 128 KB
Sectors Written: 2197 /sec
Percent Rebuild Complete: Not Available
OS Assigned Name: Disk 0
а на странице информации об этом винте
Physical Drive - Port 1I Box 1 Bay 0
Status: Failed
Action: Replace Drive
Capacity: N/A
Model: HP DH072ABAA6
Firmware Version: N/A
Serial Number: 3PD019TC000097266ZTD
Service Hours: 9062
S.M.A.R.T. Support: Not Available
Placement: Internal
Drive Type: SAS
Negotiated Link Rate: Unknown
Rotational Speed: Unknown
Phy Count: 0
Multipath Status Disk Failed
Репутация: нет
Всего: 317
в нормальных системах rebuild происходит автоматически, при установке нового диска.
диск должен соответствовать каким-то требованиям (иногда это - какая-то опр. модель, иногда нет)
что меня удивляет в вашем RAID - это его величина.
сегодня есть диски на 1 TB
судя по данным о диске - его хреново установили.
мне кажется там данные вообще от предыдущего диска (Service Hours: 9062)
попробуйте его вытащить, и установить КОРРЕКТНО, чтобы все контакты контактились, и т.д.
то что написано здесь сверху - это единственное что видно на экране ?
можно привести ссылки на скрины (цифровика) ?
Абучю рускаму язаку
Репутация: нет
Всего: 7
я его еще помучал и вот что получилось.
8 дисков: первые 4 в стрипе, следующие 4 в стрипе и стрипы зеркалируются.
не работает диск №2.
я вытащил все диски, оставил только второй - не работает.
вставил все диски и первый со вторым поменял местами - первый не работает, второй работает.
вобщем определил поломку - винт дохлый.
а ребилд да, сам должен стартовать, я весь мануал по нему перечитал 2 раза
вобщем, жду замены винту.
Репутация: нет
Всего: 317
в общем когда работаешь с железяками и зап. частями, методология установки простая:
желательно просто иметь тестовый компьютер-Франкенштейн (а в больших фирмах таких держат несколько - сервер, лэптоп, рабочая лошадка)
когда получаешь новую память/диск/компонент - втыкаешь его на тестовую систему, в которой ВСЁ ОСТАЛЬНОЕ - работает.
и смотришь, что работает.
далее всё понятно.
хотя некоторые проблемы это не проверяет, но даёт ориентир.
Абучю рускаму язаку
Репутация: нет
Всего: 7
он тоже не включается в работу.
на странице информации о контроллере и дисках у нового диска стоят данные (модель и серийный номер) старого диска.
мне посоветовали удалить этот диск из массива и заново добавить через биос контроллера.
при загрузке компа захожу в этот биос, а там можно только удалить массив, создать массив и посмотреть инфу.
смотрю инфу и диск, который не работает обозначен номером 0, хотя он номер 2, и вообще написано, что диск failed.
в загруженной системе открываю утилиту HP management.
вот скрин этой утилиты
выбираю в ней проблемный диск
вот скрин (тут и видно, что модель и серийник от старого винта)
запускаю утилиту Array Configuration
вот она
ничего про удаление винта и добавление в ней нет. не раз уже пересматривал все пункты.
думал сменить приоритет ребилда, чтобы он заработал как-нить и новый диск увидел.
поставил приоритет скрин тут
и если нажимаю ОК, то выдается такое страшное окно с предупреждением
окно
страшно нажимать на ОК, вдруг рейд развалится.
что делать, подскажите. как заставить контроллер забыть старый диск и принять новый?
Репутация: нет
Всего: 317
ты подключен как пользователь hpsmh_local_anonymous, а не как administrator.
В одном из скринов написано, что некоторые действия можно увидеть только администратором.
Скажи мне дорогой student80, а почему ты не звонишь в поддержку HP ?
они бы тебе всё что надо объяснили.
я не понимаю из твоих скринов некоторые вещи, и не хочу понять их: твои данные.
Либо RTFM по самые уши, либо звони в саппорт.
Тип события: Ошибка
Источник события: CPQCISSE
Категория события: Отсутствует
Код события: 24597
Дата: 08.01.2005
Время: 3:01:12
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Physical Drive on SCSI Port 2, ID 1 of Embedded Array Controller, has failed. Failure Code: 0x0d.
Данные:
Тип события: Уведомления
Источник события: CPQCISSE
Категория события: Отсутствует
Код события: 24620
Дата: 08.01.2005
Время: 3:01:12
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Logical Drive 1 of the embedded Array Controller,
has changed from status code 0 to status code 3.
Status Codes:
0 = OK
1 = FAILED
2 = NOT CONFIGURED
3 = INTERIM RECOVERY MODE
4 = READY FOR RECOVERY
5 = RECOVERING
6 = WRONG PHYSICAL DRIVE REPLACED
7 = PHYSICAL DRIVE NOT PROPERLY CONNECTED
8 = HARDWARE IS OVERHEATING
9 = HARDWARE HAS OVERHEATED
10 = EXPANDING
11 = NOT YET AVAILABLE
12 = QUEUED FOR EXPANSION
13 = UNKNOWN
Тип события: Ошибка
Источник события: Storage Agents
Категория события: Events
Код события: 1062
Дата: 08.01.2005
Время: 3:01:32
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Compaq Drive Array Logical Drive Status Change. Logical drive number 1 on the array controller in slot 0 has a new status of 5.
(Logical Drive status values: 1=other, 2=ok, 3=failed, 4=unconfigured, 5=recovering, 6=readyForRebuild, 7=rebuilding, 8=wrongDrive, 9=badConnect, 10=overheating, 11=shutdown, 12=expanding, 13=notAvailable, 14=queuedForExpansion)
[SNMP TRAP: 3008 in CPQIDA.MIB]
Данные:
Тип события: Ошибка
Источник события: Storage Agents
Категория события: Events
Код события: 1064
Дата: 08.01.2005
Время: 3:01:32
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Compaq Drive Array Physical Drive Status Change. The physical drive in slot 0, port 2, bay 1 with serial number "3HZ1522X00007341N0UM", has a new status of 3.
(Drive status values: 1=other, 2=ok, 3=failed, 4=predictiveFailure)
[SNMP TRAP: 3029 in CPQIDA.MIB]
Данные:
Тип события: Уведомления
Источник события: CPQCISSE
Категория события: Отсутствует
Код события: 24580
Дата: 08.01.2005
Время: 19:38:12
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Physical Drive removed : SCSI Port 2, ID 1, of Embedded Array Controller.
Данные:
Тип события: Ошибка
Источник события: Storage Agents
Категория события: Events
Код события: 1062
Дата: 08.01.2005
Время: 19:39:56
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Compaq Drive Array Logical Drive Status Change. Logical drive number 1 on the array controller in slot 0 has a new status of 7.
(Logical Drive status values: 1=other, 2=ok, 3=failed, 4=unconfigured, 5=recovering, 6=readyForRebuild, 7=rebuilding, 8=wrongDrive, 9=badConnect, 10=overheating, 11=shutdown, 12=expanding, 13=notAvailable, 14=queuedForExpansion)
[SNMP TRAP: 3008 in CPQIDA.MIB]
Данные:
Тип события: Ошибка
Источник события: Storage Agents
Категория события: Events
Код события: 1064
Дата: 08.01.2005
Время: 19:39:56
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Compaq Drive Array Physical Drive Status Change. The physical drive in slot 0, port 2, bay 1 with serial number "3HZ1522X00007341N0UM", has a new status of 4.
(Drive status values: 1=other, 2=ok, 3=failed, 4=predictiveFailure)
[SNMP TRAP: 3029 in CPQIDA.MIB]
Данные:
Тип события: Ошибка
Источник события: CPQCISSE
Категория события: Отсутствует
Код события: 24597
Дата: 08.01.2005
Время: 19:54:12
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Physical Drive on SCSI Port 2, ID 1 of Embedded Array Controller, has failed. Failure Code: 0x1f.
Данные:
Тип события: Уведомления
Источник события: CPQCISSE
Категория события: Отсутствует
Код события: 24620
Дата: 08.01.2005
Время: 19:54:12
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Logical Drive 1 of the embedded Array Controller,
has changed from status code 5 to status code 3.
Status Codes:
0 = OK
1 = FAILED
2 = NOT CONFIGURED
3 = INTERIM RECOVERY MODE
4 = READY FOR RECOVERY
5 = RECOVERING
6 = WRONG PHYSICAL DRIVE REPLACED
7 = PHYSICAL DRIVE NOT PROPERLY CONNECTED
8 = HARDWARE IS OVERHEATING
9 = HARDWARE HAS OVERHEATED
10 = EXPANDING
11 = NOT YET AVAILABLE
12 = QUEUED FOR EXPANSION
13 = UNKNOWN
Тип события: Предупреждение
Источник события: CPQCISSE
Категория события: Отсутствует
Код события: 24605
Дата: 08.01.2005
Время: 19:54:12
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Recovery of logical drive 1 configured on Embedded Array Controller, was aborted while rebuilding physical drive with SCSI ID 1 on SCSI Port 2 due to an unrecoverable write error. The physical drive reporting the error is SCSI ID 1 on SCSI Port 2.
Данные:
Тип события: Ошибка
Источник события: Storage Agents
Категория события: Events
Код события: 1062
Дата: 08.01.2005
Время: 19:55:56
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Compaq Drive Array Logical Drive Status Change. Logical drive number 1 on the array controller in slot 0 has a new status of 5.
(Logical Drive status values: 1=other, 2=ok, 3=failed, 4=unconfigured, 5=recovering, 6=readyForRebuild, 7=rebuilding, 8=wrongDrive, 9=badConnect, 10=overheating, 11=shutdown, 12=expanding, 13=notAvailable, 14=queuedForExpansion)
[SNMP TRAP: 3008 in CPQIDA.MIB]
Данные:
Тип события: Ошибка
Источник события: Storage Agents
Категория события: Events
Код события: 1064
Дата: 08.01.2005
Время: 19:55:56
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Compaq Drive Array Physical Drive Status Change. The physical drive in slot 0, port 2, bay 1 with serial number "3HZ1522X00007341N0UM", has a new status of 3.
(Drive status values: 1=other, 2=ok, 3=failed, 4=predictiveFailure)
[SNMP TRAP: 3029 in CPQIDA.MIB]
Данные:
Тип события: Уведомления
Источник события: CPQCISSE
Категория события: Отсутствует
Код события: 24580
Дата: 08.01.2005
Время: 20:20:12
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Physical Drive removed : SCSI Port 2, ID 1, of Embedded Array Controller.
Данные:
Тип события: Ошибка
Источник события: CPQCISSE
Категория события: Отсутствует
Код события: 24597
Дата: 09.01.2005
Время: 8:24:46
Пользователь: Нет данных
Компьютер: RESERVE
Описание:
Physical Drive on SCSI Port 2, ID 1 of Embedded Array Controller, has failed. Failure Code: 0x1f.
Данные:
и тд в течении 3-х дней
Привет. На самм деле может быть просто совпадение. К сожалению, неудачное. ВО вторых может стоят не НР диски, а просто в салазки вкручены другие. Проверь наличие наклеек оригинальных НР на винтах (патномера и все такое). А вообще проще всего позвонить в представительство НР и выслать им логи, они могут чтото сказать.
Если машина гарантийная (а скорее всего так, так как на 380 гарантия три года), то на диски у НР действует так называемая предотказная гарантия на диски. То есть как только система видит, что параметры дисков ухуджаются (типа технологии Smart), она сигнализирует об этом (логи например) и ты можешь поменять диск по гарантии до того, как он выйдет из строя. Конечно если диски оригинальные.
Кстати может диски и не виноваты, а глючит RAID-контроллер (5i). В любом случае - звони в представительство НР.
Читайте также: