
Аналог monit для windows
Обновлено: 05.07.2024
Скорее всего, так и есть. Для трудового договора обычное дело. Но, наверняка в компании есть аналитики или топы, которые могли бы оценить перспективы упаковки системы в продукт, если их заинтересовать. Безагентное решение тема интересная.
Не-а, если нет отдельного договора на отчуждения авторского права, то всё это принадлежит Вам. То же самое, если в трудовом договоре нет пунктов о том, что всё, что Вы сделаете на территории фирмы и на оборудовании фирмы принадлежит фирме.
Так что — весь код лично Ваш.
На Хабре появляются юристы, думаю, они подтвердят мои слова.
За оригинальное решение, если-бы мог, то поставил Вам плюс. Хотя, с 2008 сервера Винда умеет пересылать свои журналы на один компьютер-сборщик. Так-что пробегать по всем серверам может и не надо.
Кроме этого, на события в журналах можно ставить обработчики и с их помощью так-же можно построить систему мониторинга (либо доработать Вашу, если у Вас сделано не так) и автоматизировать выполнение операций по обслуживанию.
с 2008 сервера Винда умеет пересылать свои журналы на один компьютер-сборщик
А где можно подробнее почитать, как это сделать? Насколько мне известно, система журналирования Windows сделана так, что прочитать (даже сохранённый, скопированный) журнал на другой машине — та ещё задача:
Если на другом компьютере не установлен аналогичный софт, то имеем ошибку:
Не удается найти описание для идентификатора события 1000 из источника VMware Tools. Вызывающий данное событие компонент не установлен на этом локальном компьютере или поврежден. Установите или восстановите компонент на локальном компьютере.
Что сводит на нет всю идею резервирования журналов.
На мой взгляд надёжнее посылать журнал сразу в текстовом виде на linux-машину с rsyslog, может знаете какие решения?
Для самостоятельного чтения журналов Windows существуют сторонние программы которые находится очень быстро.
Резервирование журналов можно настроить нативно из встроенного средства просмотра событий. Там же можно настроить обработку возникших событий.
Если взять Ваш пример с VMware Tools, то можно написать обработчик, который установит недостающее при появлении события с кодом 1000 и источником «VMWare Tools». Скажу сразу, сам такую автоматизацию не делал, но вполне можно написать скрипт, посылающий уведомление админу и/или устанавливающий нужный софт. Придётся, правда, повозиться с отладкой скрипта, так как не всё однозначно и Майкрософт по-особому смотрит на внедряемые возможности. Если это «большая бюрократизированная компания», то было бы странно, если такого пункта в договоре не было. У «одного моего знакомого», который в очень большой софтверной компании работает, такой раздл, как и NDA, обязательно прилагается. Хм, даже у сисадминов в большой компании в договоре есть пункт «всё написанное тобой — наше»? Не нужно быть юристом, нужно просто уметь читать. ч. 4 ГК РФ статья 1295 п. 2 «чёрным по-русскому» говорит совершенно иное:
Исключительное право на служебное произведение принадлежит работодателю, если трудовым или гражданско-правовым договором между работодателем и автором не предусмотрено иное.Не стоит объединять понятия «авторского права» с «исключительным правом». Это два отдельных термина. Авторское право право включает в себя исключительное право. Весьма занимательное решение, особенно в плане инструмента. Расскажите поподробнее для непосвященных, как именно оно работает. SQL-скрипт рассылает запросы по сети с центрального компа, или выполняется локально на каждом проверяемом сервере?
Я так понял — удаленный вызов команд через WMI©
Именно, WMIC /node:servername, читает вывод xp_cmdshell во временную таблицу, где парзим строки на SQL (ах, эти извращения)Не совсем понял. То есть на каждом сервере стоит MSSQL, в котором запускаются эти вот процедуры?
Разумеется нет. У команды WMIC есть параметр /node:servername, так что SQL вам понадобится только один и то очень маленький Я работал в нескольких «больших бюрократизированных компаниях» и почти везде наблюдал этот феномен: куча всякого добра «по феншую» с тоннами документации, аудитом и прочим — и всё это накрывается, когда, условно говоря, уборщица случайно выключает рабочую станцию какого-нибудь чувака. Который устал пробивать эти бумажные тома, словно придуманные для того, чтобы никто ничего не мог сделать и сделал что-то «сбоку на коленке» — и оно работало, пока кто-то не уронил. Согласен — часто большие компании еще существуют потому, что ктото идет вопреки правилам и все таки делает работу А что, Zabbix давным давно в этой далекой галактике не изобрели еще? Он тоже где то используется, но нам спустили SCOM как копроративный стандарт. Я к тому что пока не было SCOMа поднять Zabbix заняло бы с часик. Я предлагал это шефу. Но он просто не отвечал, так как был увлечен бюрократическими битвами, в которых в итоге проиграл. На несколько месяцев я вообще был предоставлен сам себе. А в Zabbix есть агент? А, ну тогда это проблемы шерифа :) Да, конечно есть агент в т.ч. под винду.Радуйтесь, что не Tivoli. )
Расскажите! Чтобы кто нибудь не ступил туда, как эта фирма в netIQ в свое время
Для очень большой инфраструктуры — Tivoli не идеальный, но мощный и стабильный инструмент. Попробуйте не плеваться, а разобраться как это всё вместе работает. А можно конкретику — от чего там плюются? Чтобы знать.Ок, попробую систематизировать, это также ответ для thekovach и его соседа. У меня претензии одновременно как у пользователя и как у инфраструктурщика. С начала инфраструктурные моменты:
1) Как я уже говорил сложность системы мониторинга и количество потребляемых ею ресурсов возросло в десять раз. Старая система — основной сервер + прокси для мониторинга фронтов снаружи = 2 виртуальные машины (суммарно 12 vCPU, 40GB RAM, 900GB диски). Новая система 24VM + 4 физических выноса в ЦОДах + тот же самый внешний проксик (суммарно 139vCPU 496GB RAM 3,08TB диски). Про пол-сотни это я конечно сгоряча, каюсь. По дискам конечно «всего» в три раза больше заббикса, но заббикс хранит год метрик по каждому айпишнику до которого смог дотянуться, включая сетевое оборудование, а у Тиволи вполне конкретные лицензионные ограничения по объектам мониторинга, поэтому он смотрит только на особо критичные системы.
2) Агенты: заббиксу вообще не нужны, если очень хочется, то один. Ест 6МБ памяти. Тиволи — агент нужен обязательно, в базовой комплектации три службы, 2 процесса жрут 80МБ памяти. На каждый чих (IIS, SQL, Exchange, AD и т.д. нужен дополнительный агент). Бонусом kq7client.exe рандомно начинает выжирать на 100% одно ядро, пока его не рестартанёшь. IBM говорит — это норма!
3) Гремучую кучу времени\денег которые были на него потрачены, можно было потратить с большей пользой. Например, завести отдел тестирования, и купить им инструменты для работы.
С точки зрения пользователя:
1) для тех, кто не видел посконный тиволёвый интерфейс вот. Дизайнерам интерфейсов с тонкой душевной организацией лучше не смотреть.
2) В заббиксе посмотреть график по любой метрике можно в пару кликов, в тиволи для этого приходится продираться через тормоза и условности устаревшего интерфейса, или платите миллион в год за 3th party рисовалку (сорян, не помню как называется, что-то отечественное), или пилите сами.
3) Также накидать графиков на дэшборд в заббиксе можно легко и непринуждённо, в тиволи это сложнейший квест, т.к. нужно выбирать из нескольких одинаково называющихся метрик, а потом хитро указывать диапазоны времени (на лету менять нельзя). Ну и в общем если нет админских прав, то это работа бессмысленная т.к. сохранять нельзя.
Я не говорю, что Тиволи не работает, я говорю, что он монструозен в лучших традициях энтерпрайз решений от IBM.
В этой статье мы поговорим про системы мониторинга в Linux. Они позволяют отслеживать различные параметры работы сервера Linux, нагрузку на процессор, диск, доступное дисковое пространство и оперативную память. Если у вас под управлением находится только один сервер, то возможно системы мониторинга вам и не нужны. Вы можете в любой момент подключится к серверу по SSH и посмотреть все основные параметры с помощью htop.
Но если вы управляете несколькими производственными серверами, вам будет необходимо всегда иметь общее представление о том, что на них происходит. Системы мониторинга позволяют записать и посмотреть какой была нагрузка на сервер в тот или иной момент времени, а также собрать данные из кластера серверов и предоставить их в удобном формате.
1. Zabbix

Это одна из самых популярных промышленных систем мониторинга для Linux. Zabbix поддерживает сбор информации с нескольких серверов, мониторинг таких часто используемых служб, как Apache, Nginx, PHP-FPM, MySQL, PostgreSQL, Tomcat и многих других, а также обнаруживает и сообщает об различных типичных ошибках. Есть возможность отправки уведомления на электронную почту при возникновении определённого события. Это позволяет реагировать очень быстро на любые ошибки. Все настройки выполняются с помощью удобного веб-интерфейса и хранятся в базе данных MySQL. Вы также можете посмотреть текущие значения различных метрик сервера в разделе Monitoring -> Last data. Доступны графики для основных отслеживаемых параметров.
2. Nagios

3. Cacti

Эта система мониторинга тоже довольно старая и интерфейсом похожа на Nagios. Но цель у неё другая. Cacti разработана для просмотра графиков состояния различных системных параметров за определённое время. Тем не менее, при необходимости здесь тоже можно настроить уведомления. Очень часто используется не столько для мониторинга серверов, сколько для отслеживания нагрузки на сеть с помощью SNMP (Simple Network Management Protocol). Cacti достаточно сложная в настройке, потому что для неё надо создать базу данных, пользователя и установить PHP, Apache и всё подготовить.
4. Monit

Monit - это очень простой инструмент для мониторинга состояния серверов с открытым исходным кодом. Установка программы сводится к загрузке пакета из официальных репозиториев и правки одного конфигурационного файла. Но практически вся настройка мониторинга выполняется в конфигурационных файлах. Веб-интерфейс можно использовать только для просмотра информации о работе сервера и отслеживаемых сервисов. Можно отслеживать доступность портов на удалённых серверах, а также при не доступности какого либо порта или сервиса отправлять уведомление на почту.
5. Icinga 2

Icinga 2 - это улучшенная версия открытой системы мониторинга Icinga, которая в свою очередь была создана как форк Nagios в 2009 году. Для её работы вам уже понадобится создать несколько баз данных MySQL или PostgreSQL. Это одна из программ, имеющих современный интерфейс, которым приятно пользоваться. Позволяет отслеживать события в системе, а также отправлять уведомления на почту при возникновении проблем. Отслеживается место на диске, раздел подкачки, доступность запущенных сервисов, нагрузка на процессор с помощью load_average, а также доступные для обновления пакеты.
6. Observium

Observium - инструмент, написанный на PHP, позволяющий выполнять мониторинг доступности серверов в сети, а также сетевую нагрузку на их интерфейсы с помощью SNMP. Программа имеет простой и приятный интерфейс и её не очень сложно установить. Отслеживаемые серверы можно добавить как с помощью веб-интерфейса, так и в командной строке. Можно настроить отправку уведомлений если какой-либо из серверов стал недоступен.
7. Netdata

8. Munin

Munin - ещё одна очень простая система мониторинга с открытым исходным кодом, использующая RRDTool для генерации графиков. Функциональность стандартная для подобного рода систем - можно просматривать графики производительности, а если случается что-то непредвиденное - то отправлять уведомления на почту. Довольно простая в установке, потому что есть в официальных репозиториях многих дистрибутивов. Можно отслеживать не только сервер, на котором установлена система, а и другие серверы.
9. Prometheus

Это современная система мониторинга Linux с открытым исходным кодом, полностью написанная на Go. Она состоит из нескольких компонентов, которые надо устанавливать отдельно. Основной из них - сервер Prometheus, собирающий данные со всех хостов, позволяющий их анализировать и выводить графики. Для установки на удалённые машины используется компонент Node_exporter - собирающий данные и передающий их на сервер. А для отправки уведомлений об внештатных ситуациях используется компонент Alert_manager. Система не очень сложная в настройке и довольно удобная. Первый релиз состоялся в 2014 году, поэтому всё выглядит довольно современным. В веб-интерфейсе выводится только информация, большинство настроек выполняются редактированием YAML файлов.
10. Graphite

Это более старая система мониторинга, по сравнению с Prometheus, написанная на Python. Graphite тоже состоит из нескольких компонентов. Это агент для сбора данных Carbon, база данных Whisper и интерфейс для отображения графиков Graphite-Web. Как и в большинстве предыдущих систем здесь можно отправлять уведомления о возникновении проблем, а также просматривать графики различных параметров работы сервера.
Сборка из агента, базы данных и веб-интерфейса
Если вас не устраивает ни одна из существующих систем мониторинга, вы можете собрать свою на основе отдельных компонентов. Использовать агент для сбора данных из одной системы, базу данных для хранения собранного, а также удобный веб интерфейс.
В качестве агента сбора данных можно использовать один из перечисленных выше от систем мониторинга или же отдельный, например, Collectd, Telegraf или другие. В качестве базы данных часто используют InfluxDB, написанную на Go, а в качестве веб-интерфейса очень популярна Grafana. Это очень простой и красивый инструмент для рисования графиков на основе меняющихся со временем данных.
Выводы
В этой статье мы рассмотрели системы мониторинга для Linux, которые вы можете использовать в своих проектах. Конечно, это далеко не все решения, а только лучшие из них. Все программы доступны бесплатно или имеют бесплатную версию. А какие системы мониторинга используете вы для решения своих задач? Что-то было упущено в этом списке? Напишите в комментариях!
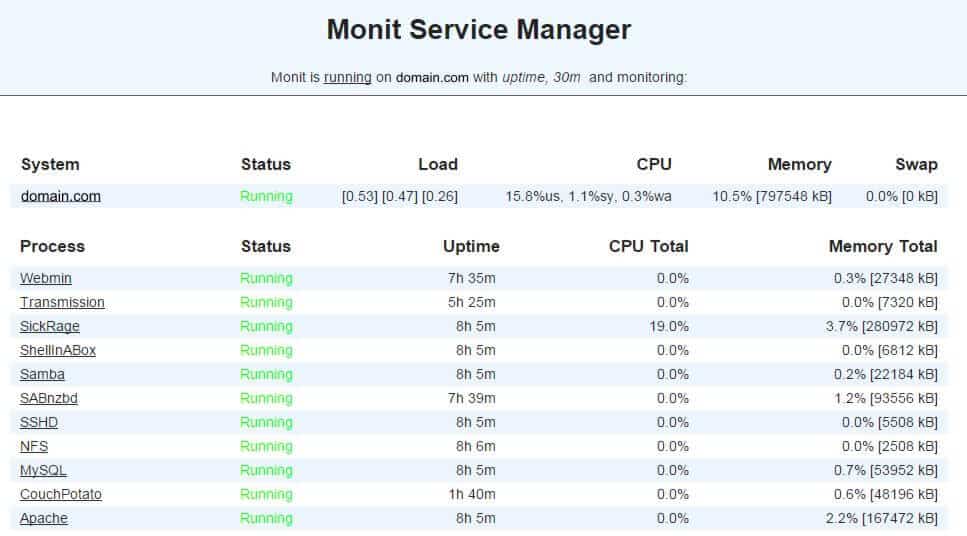
Мониторинг состояния веб-сервера с помощью Monit
На моем домашнем сервере Ubuntu я запускаю сервер Apache и сервер MySQL по причинам, описанным выше. На моем Ubuntu VPS, на котором работает этот сайт, я запускаю NGINX. Если произойдет сбой одного из них, я не узнаю, пока не попробую что-нибудь (скажем, воспроизвести видео или получить доступ к CouchPotato), и это не получится. Если мой сервер NGINX не работает, я не буду знать, пока я не выполню проверку статуса веб-сайта. Monit может уведомить о сбоях сервера, как только это произойдет. Когда я недавно установил свой новый домашний сервер, я решил использовать Monit для мониторинга системы. Я использую Monit для мониторинга нескольких служб, перечисленных ниже:
Контролируйте свой домашний сервер с Monit:
С момента его установки у меня никогда не было проблем с потоковым воспроизведением Kodi. Итак, давайте посмотрим, как автоматически управлять веб-сервером с помощью программного обеспечения Monit Server Monitor.
Перед включением мониторинга веб-сервера необходимо иметь работающий экземпляр Monit с соответствующим /etc/monit/monitrc файлом. Конфигурации Monit для различных сервисов загружаются из /etc/monit/conf.d папки.
Мониторинг сервера Apache с помощью Monit
Настройка мониторинга сервера Apache с помощью Monit осуществляется с помощью готовых шаблонов конфигурации Monit. Все, что вам нужно сделать, это скопировать существующий шаблон из /etc/monit/monitrc.d в /etc/monit/conf.d папку.
Вместо копирования вы также можете создать символическую ссылку. Процесс веб-сервера Apache создает apache2 .pid . Приведенный выше apache2 .pid файл монитора кода и, если он не существует, Monit попытается перезапустить Apache. Перезапуск вызовет оповещение по электронной почте, как показано в примере ниже. Если перезагрузка не удалась несколько раз, Monit прекращает мониторинг сервера Apache.
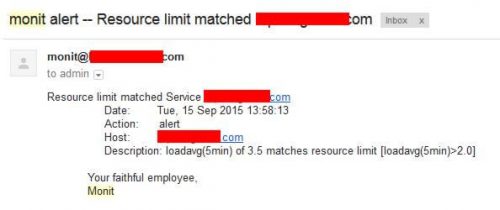
Пример оповещения по электронной почте Monit System Monitoring
Мониторинг сервера NGINX с помощью Monit
Monit также предоставляет шаблоны для мониторинга сервера NGINX. Еще раз, все, что вам нужно сделать, это скопировать существующий шаблон из /etc/monit/monitrc.d в /etc/monit/conf.d папку.
Вместо копирования вы также можете создать символическую ссылку. Процесс NGINX веб-сервер создает nginx .pid . Приведенный выше nginx .pid файл монитора кода и, если он не существует, Monit попытается перезапустить NGINX Server. Перезапуск вызовет оповещение по электронной почте, как показано в примере выше. Если перезагрузка не удалась несколько раз, Monit прекращает мониторинг сервера NGINX.
Монитор MySQL Server с помощью Monit
Monit также предоставляет шаблоны для мониторинга сервера MySQL. Еще раз, все, что вам нужно сделать, это скопировать существующий шаблон из /etc/monit/monitrc.d в /etc/monit/conf.d папку.
Вместо копирования вы также можете создать символическую ссылку. Процесс сервера базы данных MySQL создает mysqld .pid . Приведенный выше mysqld .pid файл монитора кода и, если он не существует, Monit попытается перезапустить MySQL Server. Перезапуск вызовет оповещение по электронной почте, как показано в примере выше. Если перезапуск не удается несколько раз, то Monit прекращает мониторинг сервера MySQL.
Тест и перезагрузка Монит
После внесения каких-либо изменений необходимо протестировать конфигурацию Monit:
Если Monit запущен, перезагрузите конфигурации с помощью следующей команды для мониторинга состояния веб-сервера с помощью Monit:
Если Monit не запущен, запустите его, используя sudo monit команду. Вся последовательность команд для тестирования и перезагрузки Monit показана на рисунке ниже.
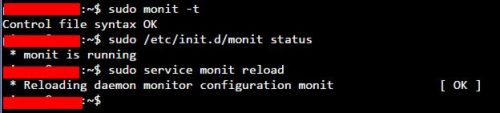
Монит Тест и Перезагрузка
Теперь запустите веб-браузер и перейдите на один из следующих URL-адресов в зависимости от того, как настроен ваш Monit (обязательно используйте правильный номер порта):
Вы должны увидеть состояния веб-сервера Apache и MySQL, как показано на рисунке ниже (NGINX не показан на этом примере изображения).
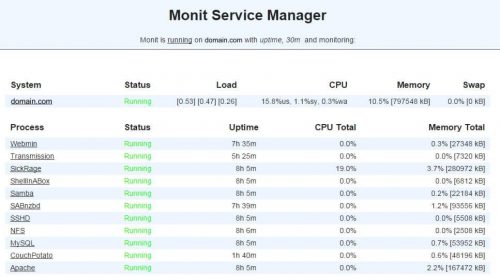
Мониторинг Apache и MySQL с помощью Monit
То есть для мониторинга состояния веб-сервера с помощью Monit. Как вы можете видеть, Monit обеспечивает автоматический мониторинг состояния веб-сервера, что может быть очень полезно для системных администраторов. На странице Monit Wiki есть несколько примеров. Больше примеров Monit для домашнего сервера, чтобы следовать, поэтому продолжайте проверять.

Установка и настройка системы мониторинга Monit
Логика скрипт довольно простая, помимо всевозможных проверок на текущую версию linux-дистрибутива, наличие программ wget и tar, скрипт так же проверяет текущую установленную у Вас версию Monit, далее он проверяет последнюю свежую версию на официальном сайте и скачивает её, далее распаковывает архив в /tmp, останавливает monit, копирует бинарник новой версии и запускает monit.
Далее запускаем скрипт:
Вывод процесса обновления:
И проверяем обновленную версию monit:
Теперь у нас есть самая свежая версия monit и можно приступить к его настройке.
Все настройки Monit находятся в файле /etc/monit/monitrc, а так же в каталоге /etc/monit/conf.d
Рассмотрим файл /etc/monit/monitrc и основные настройки которые устанавливаю я на своих серверах:
В настройках monit выше мы указали доступ к Web-интерфейсу для локальной группы monitadmin на нашем сервере, создадим эту группу:
И добавляем в неё пользователя cherts:
Так же нам необходимо создать самоподписной ssl-сертификат, для упрощения этой задачи я написал простой bash-скрипт, скачиваем его, редактируем и запускаем:
Теперь отредактируйте в файле /etc/monit/ssl/monit-create-ssl.sh параметры:
И запустите скрипт:
В ответ он сгенерирует самоподписной ssl-сертификат и выдаст его содержимое для проверки.
Теперь можно проверить синтаксис monit командой:
И перезапустить monit:

Пример страницы мониторинга сервера:
Теперь давайте рассмотрим файлы конфигурации из каталога /etc/monit/conf.d
Например простое условие:
Пример FOR CYCLES:
Таким образом проверка условия if space usage > 90% будет выполнена 2 раз и если условие будет подтверждено все 2 раза подряд то будет отправлено оповещение.
Данная конструкция и используется у нас:
Более детально о них можно почитать на странице официальной документации. принцип написания условий проверки у них такой же как и для check system.
Рассмотрим файл /etc/monit/conf.d/mysql для мониторинга работы БД MySQL:
Здесь мы используем возможность Monit осуществлять мониторинг процессов и файлов.
Мы рассмотрели пример конфигурации для мониторинга 2-х сервисов, но этим работа с monit не ограничивается, monit -t
Перезагрузка конфигурации monit:
Просмотр состояния всех сервисов на мониторинге:
Просмотр состояния сервисов в группе system:
Просмотр состояния отдельного сервиса mysqld:
Пример вывода состояния сервиса:
Включить мониторинг сервиса mysqld:
Посмотреть краткую информацию о состоянии всех сервисов:
Посмотреть краткую информацию о состоянии сервиса mysqld:
Посмотреть краткую информацию о состоянии в группе system:
И в заключении статьи я хочу написать несколько предостережений по работе с monit:
1. Если Вы обновляете какой-либо сервис который находится на мониторинге в monit или хотите перезапустить этот сервис, например Вы обновляете БД mysql, элементарно выполнив apt-get upgrade, или хотите перезапустить mysql командой /etc/init.d/mysql restart, то обязательно останавливайте мониторинг этого сервиса командой:
Пример снятия с мониторинга сервиса mysqld:
Повторно проверяем состояние:
Видим что сервис mysqld снят с мониторинга, теперь можно приступить к обновлению БД или её перезапуску.
Вы спросите: Зачем такие сложности?
Ответ: При использовании конструкций вида:
Мы осуществляем мониторинг сервиса путем тестового подключения к нему, если через заданное количество попыток подключение провалиться, то мы осуществляем перезапуск сервиса. А теперь представьте, что проверка настигнет Вас в момент когда БД будет в процессе перезапуска, что будет тогда? Ничего хорошего. Monit не сможет подключиться к БД и попробует её перезапустить.
2. Если вы используете конструкции вида
то есть вы доверяете Monit перезапуск сервисов, то обратите внимание на время которое требуется для остановки и запуска вашего сервиса.
На этом все, до скорых встреч. Если у Вас возникли вопросы или Вы хотите чтобы я помог Вам, то Вы всегда можете связаться со мной разными доступными способами.
Читайте также: