
Binwalk linux как пользоваться
Обновлено: 06.07.2024
В этой статье мы будем получать информацию напрямую из источника вне какого-либо контекста.
В первой, второй и третьей частях мы изучали интересующую нас информацию и ресурсы, используемы процессами, в определенном контексте. С другой стороны, мы находились в определенных рамках, не имели доступа ко всей информации в целом и имели дело с ограниченным набором инструментов. Вполне бы могло случиться так, что мы не смогли найти последовательный порт на печатной плате, или порт был бы найден, но в системе не была бы предусмотрена стандартная учетная запись. В таких случаях необходима кардинально другая методика работы.
В этой статье мы будем получать информацию напрямую из источника вне какого-либо контекста. Данные будут выгружаться из внешней флеш-памяти, после чего будет проводиться распаковка, чтобы полученная информация была пригодна к дальнейшему анализу. Этот метод не требует дорогостоящего оборудования и каких-либо других первоначальных условий. Внешняя флеш-память в комплекте с общедоступным даташитом – прекрасный союзник реверс-инженера.
Нюансы при выгрузке памяти
Во время исследования информационных потоков в третьей части мы обзавелись даташитом на внешнюю флеш-память, и у нас нет необходимости в изучении функционала каждого пина.

Рисунок 1: Назначение некоторых пинов у внешней флеш-памяти
Кроме того, мы ознакомились с набором инструкций и можем взаимодействовать с микросхемой при помощи любого устройства, которое умеет «общаться» с шиной SPI.
Мы также знаем, что при включении роутера микроконтроллер Ralink начинает общаться с внешней флеш-памятью, что может спровоцировать конфликты во время чтения информации. Нам нужно остановить взаимодействие между Ralink и флеш-памятью, но конкретный способ решения этой задачи зависит от конструкции электронной цепи, с которой мы работаем.
Нужен демонтаж флеш-памяти? (теория)
Самый лучший способ остановить коммуникацию между Ralink и флеш-памятью – демонтаж и полная изоляция микросхемы от остальной цепи. Данный метод позволяет нам полностью управлять ситуацией и исключает все возможные источники конфликтов, но, к сожалению, требует дополнительное оборудование, опыт и время. Мы попробуем пойти более простым путем.
Второй способ – перевод Ralink в неактивный режим, в то время как все остальные элементы вокруг находятся в режиме ожидания. Зачастую у микроконтроллеров есть пин Reset, который, при подаче логического нуля, перезагружает микросхему без отключения питания на плате. Но у нас нет полной версии даташита (возможно, эта документация распространяется только среди покупателей на основе соглашения о неразглашении информации). Внешний вид микросхемы и сложность окружающей цепи серьезно затрудняю задачу по самостоятельному поиску нужного пина.
Третий способ – подача напряжения только на внешнюю флеш-память вместо включения всей цепи. Подача питания на плату недокументированным способом может привести к конфликтам. Мы могли бы изучить цепь питания, но поскольку роутер дешевый и распространенный, попробуем обойтись без дополнительных исследований. Согласно даташиту необходимое напряжение – 3 В. Я буду запитывать внешнюю флеш-память напрямую.

Рисунок 2: Схема прямого запитывания внешней-флеш памяти
Мы будем напрямую подавать питание и ожидать данные из UART порта микроконтроллера Ralink. После подачи напряжения на задней стороне платы загорелись светоизлучающие диоды, трафик на порте отсутствует, и, предположительно, Ralink находится в неактивном режиме. Однако даже в этом случае, соединение микроконтроллера с флеш-памятью может препятствовать передаче информации вследствие нюансов проектирования цепи питания и чипа. Важно не забывать об этих деталях, если мы в дальнейшем столкнемся с чем-нибудь странным. Если произойдет нечто подобное, нам нужно физически отпаять флеш-память (или, по крайней мере, пины, отвечающие за передачу информации).
Светоизлучающие диоды и другие статические компоненты не могут взаимодействовать с флеш-памятью и, соответственно, не могут стать причиной проблем, если мы подаем достаточный ток. Я использую ступенчатый источник питания, где предусмотрена подача различных токов на все случаи жизни. Если у вас нет подобного источника питания, можете попробовать воспользоваться системой питания внешнего (ведущего) устройства или каким-либо USB-адаптером питания в случае, если необходимы токи большего размера.
Теперь пришло время подключить внешнее устройство к шине SPI.
Соединение с флеш-памятью
После того как мы убедились в отсутствии необходимости демонтажа, то можем подсоединить устройство, которое умеет общаться с шиной SPI, и начать поблочное чтение памяти. Для решения этой задачи подойдет любой микроконтроллер, но намного удобнее воспользоваться специальным переходником SPI-USB. Я воспользуюсь моделью FT232H, которая поддерживает как протокол шины SPI, так и другие низкоуровневые протоколы.
Теперь, когда мы знаем назначения пинов флеш-памяти и переходника USB-SPI, пробуем подсоединиться.

Рисунок 3: Схема подключение переходника к флеш-памяти
После подготовки и настройки аппаратной части переходим к выгрузке данных.
Выгрузка информации
Нам потребуется программное обеспечение, которое «понимает» трафик, поступающий с переходника, и умеет считывать память в бинарный файл. Написание собственной утилиты не составит особого труда, но уже есть множество доступных приложений, поддерживающих различные микросхемы и шины. Попробуем воспользоваться программой flashrom, которая широко распространена и идет с открытым исходным кодом.
Flashrom – старое и нестабильное приложение, однако поддерживает модель FT232H (переходник) в качестве ведущего устройства, и модель FL064PIF (флеш-память) – в качестве ведомого. У меня возникли проблемы при работе в OSX и виртуальной машине с Ubuntu, но в конечном итоге все заработало в системе Raspberry Pi (ОС Raspbian):
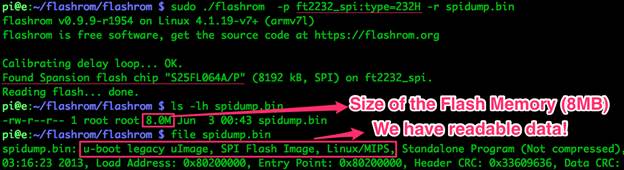
Рисунок 4: Выгрузка данных из флеш-памяти при помощи flashrom
У нас получилось выгрузить информацию, и теперь мы можем перейти от аппаратной части к подготовке данных для анализа.
Разделение бинарного файла
Мы могли бы воспользоваться командой file для идентификации некоторых частей бинарного файла, но только в том случае, если файл имел бы знакомый формат. В условия полной неопределенности мы будем пользоваться утилитой binwalk, чтобы получить хотя бы базовое представление о бинарном файле и найти информацию для извлечения.
Примечание: binwalk – очень полезная утилита для анализа бинарных файлов, созданная командой /dev/ttyS0; Если вы занимаетесь исследованиями аппаратной части, вам определенно нужно познакомиться с ребятами из этой группы.
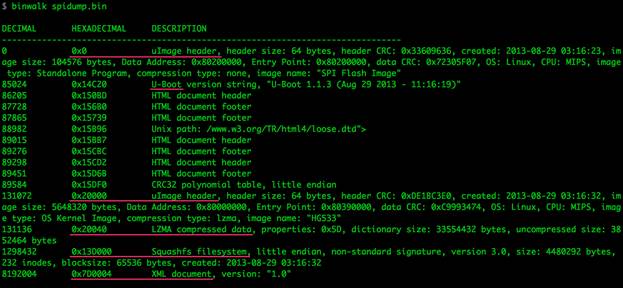
Рисунок 5: Базовая информация о бинарном файле, полученная при помощи утилиты bindwalk
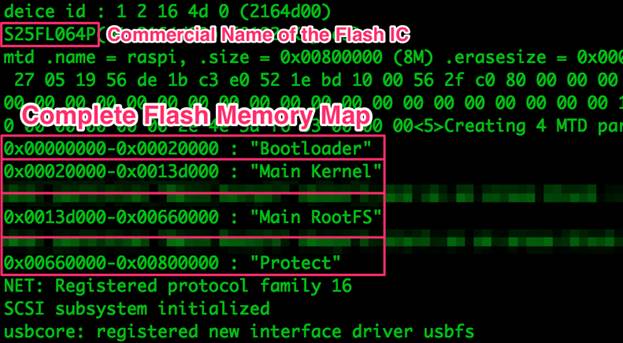
Рисунок 6: Карта флеш-памяти
При наличии нужных адресов мы можем разделить бинарный файл на 4 базовых сегмента. Утилита dd принимает на входе 3 параметра в десятичном формате: размер блока (bs, в байтах), смещение (skip, количество блоков) и размер (count, количество блоков); Для преобразования из шестнадцатеричной системы в десятичную мы можем воспользоваться либо калькулятором, либо средствами шелла и командой $(()):
$ dd if=spidump.bin of=bootloader.bin bs=1 count=$((0x020000))
131072+0 records in
131072+0 records out
131072 bytes transferred in 0.215768 secs (607467 bytes/sec)
$ dd if=spidump.bin of=mainkernel.bin bs=1 count=$((0x13D000-0x020000)) skip=$((0x020000))
1167360+0 records in
1167360+0 records out
1167360 bytes transferred in 1.900925 secs (614101 bytes/sec)
$ dd if=spidump.bin of=mainrootfs.bin bs=1 count=$((0x660000-0x13D000)) skip=$((0x13D000))
5386240+0 records in
5386240+0 records out
5386240 bytes transferred in 9.163635 secs (587784 bytes/sec)
$ dd if=spidump.bin of=protect.bin bs=1 count=$((0x800000-0x660000)) skip=$((0x660000))
1703936+0 records in
1703936+0 records out
1703936 bytes transferred in 2.743594 secs (621060 bytes/sec)
Мы создали 4 бинарных файла:
- bootloader.bin: загрузчик U-boot. Файл несжатый, поскольку микроконтроллер Ralink не умеет распаковывать эту информацию.
- mainkernel.bin: ядро в Linux. Базовая прошивка, управляющая системой bare metal. Упакована алгоритмом lzma.
- mainrootfs.bin: Файловая система. Содержит все важные бинарные и конфигурационные файлы. Упакована как squashfs при помощи алгоритма lzma.
- protect.bin: различные данные, упомянутые в третьей статье. Упаковка отсутствует.
Анализ отдельных частей бинарного файла
После разделения бинарного файла на 4 части рассмотрим подробнее каждый из этих сегментов.
Загрузчик
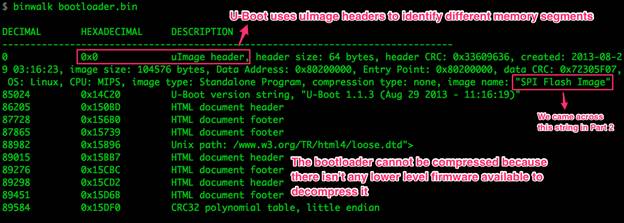
Рисунок 7: Информация о бинарном файле, имеющем отношение к загрузчику
Утилита binwalk нашла и декодировала заголовок uImage. Загрузчик U-Boot использует данные заголовки для идентификации важных областей памяти. Это та же самая информация, которая отображается командой file в случае с полным дампом памяти, поскольку вначале идет тот же самый заголовок.
Нас не особо интересует информация загрузчика, поэтому переходим к изучению других файлов.
Ядро
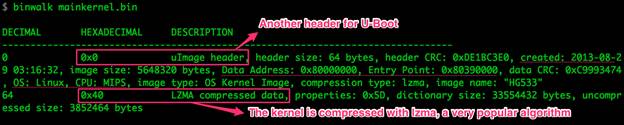
Рисунок 8: Информация о бинарном файле, имеющем отношение к ядру
Перед извлечением полезной информации необходима распаковка. После анализа через binwalk мы еще раз убедились (как и во второй статье), что ядро упаковано алгоритмом lzma, который является очень популярным среди встроенных систем. Быстрая проверка при помощи команды strings mainkernel.bin | less подтверждает, что информации, пригодной для анализа, в файле нет.
Существует множество утилит для распаковки алгоритма lzma, например, 7z или xz, однако ни одна из этих утилит не смогла распаковать файл mainkernel.bin:
$ xz --decompress mainkernel.bin
xz: mainkernel.bin: File format not recognized
Скорее всего, дело в заголовке uImage, который нужно вычленить из файла. Мы знаем, что информация, упакованная lzma, начинается с байта 0x40. То есть нам необходимо скопировать все, кроме первых 64 байт.

Рисунок 9: Копирование части файла при помощи утилиты dd
Пробуем распаковать еще раз:
$ xz --decompress mainkernel_noheader.lzma
xz: mainkernel_noheader.lzma: Compressed data is corrupt
Утилите xz удалось распознать алгоритм lzma, но не запакованные данные. Мы пытаемся распаковать весь файл mainkernel, имеющий отношение к флеш-памяти, однако хранимая информация навряд ли занимается 100% сегмента. Попробуем удалить неиспользуемую память в конце файла и распаковать вновь:
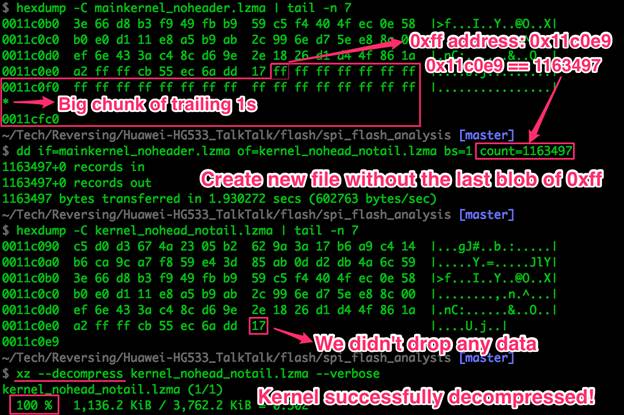
Рисунок 10: Удаление ненужной части файла и повторная распаковка
Как видно из рисунка выше, распаковка завершилась удачно, что можно проверить при помощи команды strings, которая ищет строки в формате ASCII в бинарных файлах. Попробуем поискать что-нибудь полезное:
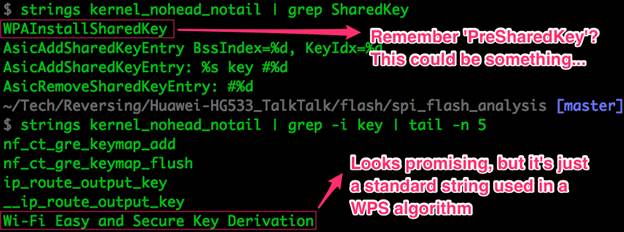
Рисунок 11: Поиск полезной информации в распакованном файле при помощи команды strings
Строка Wi-Fi Easy and Secure Key Derivation выглядит многообещающе, но впоследствии выяснилось, что данная строка определена в спецификации Wi-Fi Protected Setup spec. Ничего интересного, имеющего отношения к алгоритму генерации паролей.
С другой стороны, мы смогли распаковать информацию и можем двигаться дальше.
Файловая система

Рисунок 12: Информация о бинарном файле, имеющем отношение к файловой системе
Сегмент памяти mainrootfs не имеет заголовка uImage поскольку относится к ядру, а не к загрузчику U-Boot.
Файловая система SquashFS – очень популярна среди встроенных систем. Существует множество версий и вариаций, и иногда разработчики используют нестандартные сигнатуры, чтобы затруднить обнаружение данных внутри бинарного файла. В образовательных целях мы могли бы поиграться с различными версиями unsquashfs и/или модифицировать сигнатуры.
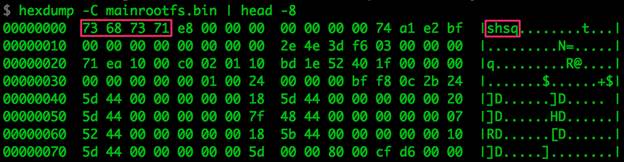
Рисунок 13: Пример сигнатуры файловой системы
Поскольку данная файловая система популярна, и поиск нужной конфигурации – довольно скучное и утомительное занятие, кто-то уже должен был написать скрипт, упрощающий решение этой задачи. Я нашел версию Firmware Modification Kit заточенную под операционную систему OSX, которая содержит скомпилированные версии unsquashfs и включает в себя скрипт unsquashfs_all.sh.
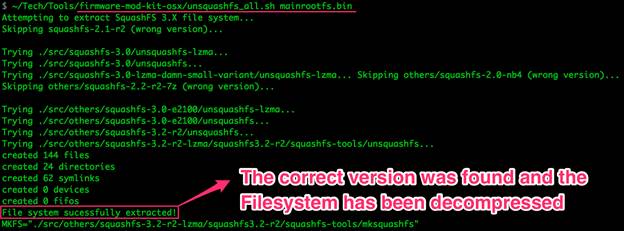
Рисунок 14: Поиск и распаковка нужной версии файловой системы
В итоге оказалось, что скрипт поддерживает сигнатуру, используемую файловой системой SquashFS в нашем случае, и распаковка завершилась успешно. Теперь у нас есть все бинарные и конфигурационные файлы, а также символические ссылки, предусмотренные в файловой системе.
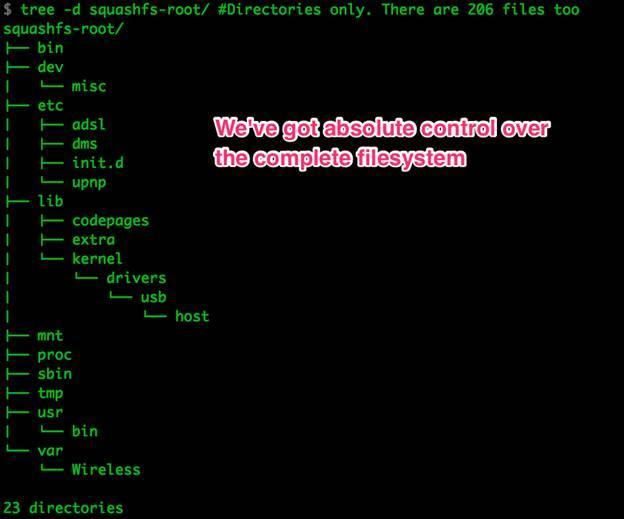
Рисунок 15: Некоторые элементы дерева файловой системы
В полной версии дерева можно найти все остальные файлы, используемые системой (а не только из папки /var/).
Теперь, используя наработки из предыдущих статей, мы можем приступить к поиску потенциально интересных бинарных файлов.
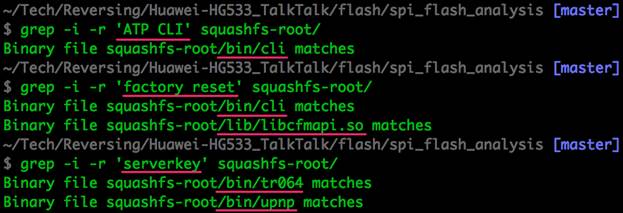
Рисунок 16: Некоторые бинарные файлы, представляющие для нас интерес
Если бы мы хотели найти уязвимости в приложениях или сетевые бреши, полный перечень бинарных и конфигурационных файлах пришелся бы весьма кстати.
Защищенная область

Рисунок 17: Информация о бинарном файле, имеющем отношение к защищенной области памяти
Как мы выяснили в третьей статье, эта область памяти не запакована и содержит информацию, используемую во время перезагрузки, но которая отличается от устройства к устройству. Для получения первоначальных сведений вполне подойдет утилита strings.
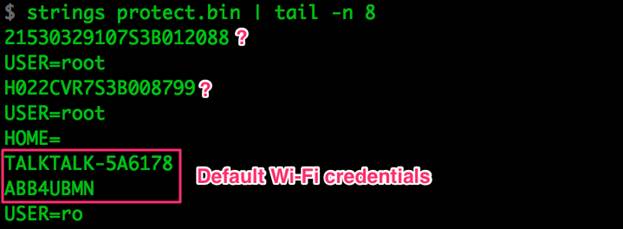
Рисунок 18: Содержимое части файла protect.bin
Содержимое файла protect.bin, скорее всего, совпадает с файлом curcfg.xml: логи и некоторые строки, показанные на рисунке выше. Эту информацию мы уже проанализировали в третьей части и не нашли ничего нового.
Что дальше
На данный момент исследование аппаратной части Ralink закончено, и мы получили все, что находится во флеш-памяти. Теперь вы можете найти, что вам необходимо. Например, мы хотим управлять роутером через отладочный UART порт, найденный в первой статье, но при попытке получить доступ к оболочке ATP CLI, мы не можем подобрать учетную запись. После выгрузки информации из внешней флеш-памяти находим XML файл в защищенной области, в котором находится учетная запись.
Если вы по какой-то причине не можете выгрузить информацию из флеш-памяти, иногда файлы, предназначенные для обновления прошивки, также могут содержать полные сегменты памяти. В этом случае во время обновления происходит перезапись соответствующих областей флеш-памяти при помощи кода, ранее загруженного в RAM. По сути, получение файлов обновления от производителя будет эквивалентно выгрузке сегментов из флеш-памяти. Вам лишь нужно выполнить распаковку. Полученной информации может быть вполне достаточно для решения ваших задач.
В следующей статье мы проведем более глубокий анализ различных бинарных файлов и попытаемся найти полезную информацию.
Подробное объяснение установки BinWalk и параметров команды
В этот понедельник Новая группа фанатов Хенгмэна: 928102972 Общий инструмент binwalk 。
Binwalk Это быстрый и простой в использовании инструмент для анализа, обратного проектирования и извлечения образов прошивки. Простые и удобные в использовании, полностью автоматизированные сценарии с настраиваемыми подписями, правилами извлечения и подключаемыми модулями, и, что важно, их можно легко расширять.
широко используется в типах вопросов CTF MISC и анализе распаковки встроенного ПО безопасности IOT, что может значительно повысить эффективность. Этот инструмент имеет хорошую поддержку Linux, но плохую поддержку функций Windows.Детская обувь с условиями может использовать этот артефакт в Linux для практики.
Если он появляется во время выполнения команды Невозможно получить блокировку / var / lib / dpkg / lock-open (11: ресурсы временно недоступны) ubuntu устанавливает vim и обрабатывает обнаруженные ошибки , Выполните следующую команду:
binwalk Необходимо установить некоторые зависимости, вы можете перейти к конкретному Wilk Проверьте, если это Debian / Ubuntu В исходном коде указан скрипт для автоматической установки зависимостей. Выполните команду:
Установить плагин IDA
binwalk Также может быть установлен binwalk IDA Плагин, эта функция очень удобна для функции реверса прошивки. установка:
Показать вывод справки binwalk (`-h, --help)
Сканирование прошивки
binwalk Основная функция - безусловно, самая популярная функция.
Binwalk Вы можете сканировать образы прошивок многих различных встроенных типов файлов и файловых систем, просто дайте ему список файлов для сканирования:
Извлечение файлов ( -e,--extract )
Эта функция также является часто используемой функцией, которая разбивается на многие файлы в CTF. разный вопрос Может быть использован binwalk Повышение эффективности по сравнению с использованием winhex Такие инструменты.
можно использовать -e Возможность извлечения любых файлов, найденных в образе прошивки.
Сигнатурный анализ ( -B,--signature )
Выполнить сигнатурный анализ целевого файла. Если другие параметры анализа не указаны, это значение по умолчанию.
Если вы хотите объединить сигнатурный анализ с другими анализаторами (например, Entropy), используйте эту опцию:
Энтропийный анализ ( -E, --entropy )
Выполните анализ энтропии для входного файла, распечатайте исходные данные энтропии и сгенерируйте карту энтропии.
Энтропийный анализ можно комбинировать с –signature, --raw или –opcodes, чтобы лучше понять целевой файл.
используется для выявления интересных частей данных, которые могут быть пропущены сканированием подписи:
В сочетании с опцией –verbose будет напечатана необработанная энтропия, рассчитанная для каждого блока данных:
Примечание: Если он используется python API Чтобы вызвать анализ энтропии, вам нужно отключить графику (–nplot), чтобы предотвратить преждевременный выход из скрипта.
При сохранении карты энтропии как файла PNG не отображается ( -J,--save )
Строка поиска ( -R, --raw=<string> )
Строка поиска включает в себя восьмеричные и / или шестнадцатеричные значения с экранированием.
Если вам нужно найти настроенную исходную последовательность байтов, вы можете использовать этот параметр:
Поиск общих исполняемых кодов операций для различных архитектур ЦП ( -A, --opcodes )
binwalk Вы можете искать общие исполняемые коды операций для различных архитектур ЦП в указанном файле.Примечание: Некоторые коды операций имеют короткие сигнатуры, поэтому они подвержены ложным срабатываниям.
Когда вам нужно найти исполняемый код в файле, если вам нужно определить архитектуру исполняемого файла, вы можете использовать эту опцию:
Искать подписанные файлы пользовательской магической подписи ( -m, --magic=<file> )
Загрузите альтернативный файл волшебной подписи вместо файла по умолчанию.
Отключить «умное» сопоставление подписей ( -b, --dumb )
Когда интеллектуальное сопоставление подписей может привести к пропуску других действительных подписей (например, через ключевое слово jump-to-offset), вы можете использовать:
Показать все результаты, в том числе неправильно помеченные как недопустимые ( -I, --invalid )
Binwalk неправильно помечает действительные результаты как недопустимые и генерирует много мусора. Вы можете использовать:
Фильтр исключения подписи ( -x, --exclude=<filter> )
Сигнатуры, соответствующие фильтру, не фильтруются. Фильтр представляет собой регулярное выражение в нижнем регистре; можно указать несколько фильтров. Магическая подпись в первой строке, которая соответствует указанному фильтру, не будет загружена вообще; поэтому использование этого фильтра может помочь сократить время сканирования подписи. Используется для исключения нежелательных или неинтересных результатов:
Подпись фильтр ( -y, --include=<filter> )
Отфильтруйте подписи, соответствующие фильтру. Фильтр представляет собой регулярное выражение в нижнем регистре; можно указать несколько фильтров. Будут загружены только волшебные подписи, соответствующие указанному фильтру в первой строке; поэтому использование этого фильтра может помочь сократить время сканирования подписи. Полезно при поиске только определенных подписей или типов подписей:
Определите архитектуру ЦП дизассемблированного кода ( -Y, --disasm )
использовать capstone Дизассемблер определяет архитектуру ЦП исполняемого кода, содержащегося в файле.
Используйте это сканирование, чтобы указать --verbose Инструкции в разобранном виде будут распечатаны дополнительно.
обычно лучше, чем --opcodes Выполненный простой сигнатурный анализ более надежен, но поддерживает меньшее количество архитектур:
Установите минимальное количество последовательных инструкций для результата разборки ( -T, --minsn )
Установите минимальное количество последовательных инструкций, чтобы результат -disasm был действительным. Значение по умолчанию - 500 инструкций:
Результат разборки выполняется непрерывно ( -k, --continue )
Инструкции-дизасм не остановится на первом результате:
Игнорируйте легенду на графике энтропии, сгенерированном --entropy ( -Q, --nngend )
Запрещается сканировать график энтропии графика --entropy ( -N, --nplot )
Установите уровень триггера энтропии нарастающего фронта ( -H, --high=<float> )
Действительно только при использовании с –entropy. Указанное значение должно быть от 0 до 1:
Установите уровень срабатывания энтропии спадающего фронта ( -L, --low=<float> )
Действительно только при использовании с –entropy. Указанное значение должно быть от 0 до 1:
Цветной вывод в шестнадцатеричном формате ( -W, --hexdump )
Зеленый - эти байты во всех файлах одинаковые
красный - эти байты разные во всех файлах
синий - эти байты различаются только в некоторых файлах
может иметь любое количество произвольных файлов; другие полезные параметры: –block, -offset, -length и –terse:
Примечание: Если вам нужен вывод страницы, установите самую утилиту, потому что она лучше поддерживает разбиение на страницы цветного вывода.
показывать включение только во время --hexdump зеленый Байтовая строка:
Показывать только содержащиеся во время --hexdump красный Байтовая строка:
Показывать только содержащиеся во время --hexdump синий Байтовая строка:
Извлечь файлы, идентифицированные при сканировании подписи ( -D, --dd=<type[:ext[:cmd]]> )
Извлечение документов, выявленных при сканировании подписи. Вы можете указать несколько параметров -dd.
Тип включен в описание подписинижний регистрСтрока (поддерживает регулярные выражения)
ext - это расширение файла, используемое при сохранении диска с данными (по умолчанию отсутствует)
cmd - необязательная команда, выполняемая после сохранения данных на диск.
По умолчанию имя файла представляет собой шестнадцатеричное смещение, в котором находится подпись, если в самой подписи не указано другое имя файла.
В следующем примере показано, как использовать параметр -dd для указания правил извлечения, которые будут извлекать любую подпись, содержащую строку «zip-архив» с расширением «zip», а затем выполнить команда "распаковать". Кроме того, изображения PNG извлекаются как есть с расширением файла «png».
Обратите внимание на использование заполнителя «% e». При выполнении команды unzip этот заполнитель будет заменен относительным путем к распакованному файлу:
Рекурсивно проверять извлеченные файлы во время проверки подписи ( -M, --matryoshka )
Допустимо только использование -extract или -dd.
Задайте выходной каталог извлеченных данных ( -C, --directory=<str> )
Значение по умолчанию: текущий рабочий каталог
применимо только при использовании параметра –extract или –dd:
Limit - глубина рекурсии матрешки ( -d, --depth=<int> )
Ограничение - глубина рекурсии матрешки. По умолчанию глубина установлена на 8.
применяется только при использовании с параметром –matryoshka:
Ограничьте размер данных, разделенных из целевого файла ( -j, --size=<int> )
По умолчанию ограничений по размеру нет.
Допустимо использовать только -extract или -dd.
Обратите внимание, что этот параметр не ограничивает размер данных, извлекаемых / распаковываемых внешними утилитами извлечения.
полезен при вырезании или извлечении данных из больших файлов с ограниченным дисковым пространством:
Очистить нулевые файлы и файлы, которые не могут быть обработаны ( -r, --rm )
Допустимо только использование -extract или -dd.
используется для удаления ложноположительных файлов, скопированных из целевого файла во время извлечения:
Записывать данные, но не извлекать / распаковывать данные автоматически ( -z, --carve )
Допустимо только использование -extract или -dd.
Распознавание методом грубой силы исходного потока сжатых данных с дефляцией ( -X, --deflate )
Используется для восстановления данных из файлов с поврежденными / измененными / отсутствующими заголовками. Можно комбинировать с -lzma.
Это сканирование может быть медленным, поэтому использование –offset и / или –length для ограничения области сканирования очень полезно:
Идентификация методом грубой силы исходного потока сжатых данных LZMA ( -Z, --lzma )
Используется для восстановления данных из файлов с поврежденными / измененными / отсутствующими заголовками. Можно комбинировать с -deflate.
Из-за разного количества параметров сжатия LZMA это сканирование может быть очень медленным, поэтому использование –offset и / или –length для ограничения области сканирования очень полезно:
Общие параметры сжатия поиск сжатых потоков ( -P, --partial )
Может значительно улучшить скорость сканирования -lzma:
Остановитесь на первом результате сканирования ( -S, --stop )
При использовании с параметрами –lzma и / или –deflate сканирование будет остановлено после отображения первого результата:
Установите количество байтов для анализа в целевом файле ( -l, --length=<int> )
Установить начальное смещение ( -o, --offset=<int> )
Установите начальное смещение целевого файла для анализа. Вы также можете указать отрицательное смещение (расстояние от конца файла):
Установите базовый адрес всех смещений печати ( -O, --base=<int> )
Это значение будет добавлено к исходному файловому смещению всех распечатанных результатов:
Установите размер блока, используемый во время анализа ( -K, --block=<int> )
Установите размер блока (в байтах), используемый во время анализа.
При использовании with-entropy это определяет размер каждого блока, анализируемого во время энтропийного анализа.
При использовании с –hexdump он устанавливает количество байтов, отображаемых на строку в шестнадцатеричном выводе.
Обратить n байтов перед сканированием ( -g, --swap=<int> )
Результаты сканирования записываются в указанный файл ( -f, --log=<file> )
Если не указан параметр -csv, данные, сохраненные в файле журнала, будут такими же, как данные, отображаемые в терминале.
Даже если указано –quiet, данные будут сохраняться в файле журнала:
Данные журнала сохраняются в формате CSV ( -c, --csv )
Если используется с –cast или –hexdump, этот параметр игнорируется.
действителен только при использовании вместе с параметром –log:
Формат вывода адаптируется к ширине окна терминала ( -t, --term )
Сделайте вывод более читабельным:
Отключить вывод на стандартный вывод ( -q, --quiet )
Это наиболее удобно при использовании –log или подробного сканирования, например –entropy:
Включите подробный вывод, включая целевой файл MD5 и отметку времени сканирования ( -v, --verbose )
Если он указан дважды и если также указан -extract, будет отображаться вывод внешней утилиты извлечения:
Проверять файлы, имена которых соответствуют заданной строке регулярного выражения ( -a, --finclude=<str> )
В сочетании с --матрешкой и --экстрактом
Не проверять файлы, имена которых соответствуют заданной строке регулярного выражения ( -p, --fexclude=<str> )
В сочетании с --матрешкой и --экстрактом
Сервер состояний включен на указанном номере порта ( -s, --status=<int> )
Сервер состояния слушает только localhost и распечатывает удобочитаемые данные ASCII, относящиеся к текущему состоянию сканирования. Вы можете подключиться к нему с помощью telnet, netcat и т. Д.
подводить итоги
Binwalk также имеет множество функций, таких как python API, используемый в сочетании с IDA, а практические приложения требуют множества небольших навыков, которые могут значительно повысить эффективность криминалистики, обратного прошивки и прочего CTF. Конечно, проблем тоже много, и детская обувь тоже может быть использована для решения этих проблем и представления. issue 。
впервые опубликованоЛекционный зал по безопасности киберпространства AnhengОбратите внимание на паблик аккаунт!

Несколько дней назад, я решил провести реверс-инжиниринг прошивки своего роутера используя binwalk.
Я купил себе TP-Link Archer C7 home router. Не самый лучший роутер, но для моих нужд вполне хватает.
Каждый раз когда я покупаю новый роутер, я устанавливаю OpenWRT. Зачем? Как правило производители не сильно заботятся о поддержке своих роутеров и со временем софт устаревает, появляются уязвимости и так далее, в общем вы поняли. Поэтому я предпочитаю хорошо поддерживаемую сообществом open-source прошивку OpenWRT.
Скачав себе OpenWRT, я так же скачал последний образ прошивки под мой новый Archer C7 с официального сайта и решил проанализировать его. Чисто ради фана и рассказать о binwalk.
Что такое binwalk?
Binwalk — это инструмент с открытым исходным кодом для анализа, реверс-инжиниринга и извлечения образов прошивок.
Созданный в 2010 году Крейгом Хеффнером, binwalk может сканировать образы прошивок и находить файлы, идентифицировать и извлекать образы файловой системы, исполняемый код, сжатые архивы, загрузчики и ядра, форматы файлов, такие как JPEG и PDF, и многое другое.
Вы можете использовать binwalk для реверс-инжиниринга прошивки для того, что бы понять как она устроена. Искать в бинарных файлах уязвимости, извлекать файлы и искать бекдоры или цифровые сертификаты. Можно так же найти opcodes для кучи разных CPU.
Вы можете распаковать образы файловой системы для поиска определенных файлов паролей (passwd, shadow и т.д.) И попытаться сломать хэши паролей. Вы можете выполнить двоичный анализ между двумя или более файлами. Вы можете выполнить анализ энтропии данных для поиска сжатых данных или закодированных ключей шифрования. Все это без необходимости доступа к исходному коду.
В общем все, что необходимо, есть :)
Как работает binwalk?
Основной особенностью binwalk является его сигнатурное сканирование. Binwalk может сканировать образ прошивки для поиска различных встроенных типов файлов и файловых систем.
Вы знаете утилиту командной строки file ?
Команда file смотрит на заголовок файла и ищет подпись (магическое число), чтобы определить тип файла. Например, если файл начинается с последовательности байтов 0x89 0x50 0x4E 0x47 0x0D 0x0A 0x1A 0x0A , она знает, что это файл PNG. На Википедии есть список распространенных подписей файлов.
Binwalk работает так же. Но вместо того, чтобы искать подписи только в начале файла, binwalk будет сканировать весь файл. Кроме того, binwalk может извлечь файлы, найденные в образе.
Инструменты file и binwalk используют библиотеку libmagic для идентификации подписей файлов. Но binwalk дополнительно поддерживает список пользовательских магических сигнатур для поиска сжатых / заархивированных файлов, заголовков прошивок, ядер Linux, загрузчиков, файловых систем и так далее.
Установка binwalk
Binwalk поддерживается на нескольких платформах, включая Linux, OSX, FreeBSD и Windows.
Чтобы установить последнюю версию binwalk, вы можете загрузить исходный код и следовать инструкции установки или краткому руководству, доступному на веб-сайте проекта.
У Binwalk много разных параметров:
Сканирования образов
Начнем с поиска сигнатур файлов внутри образа (образ с сайта TP-Link).
Теперь у нас много информации об этом образе.
Образ использует U-Boot в качестве загрузчика (заголовок образа по адресу 0x5AC0 и сжатый образ загрузчика по адресу 0x5B00 ). Основываясь на заголовке uImage по адресу 0x13270, мы знаем, что архитектура процессора — MIPS, а ядро Linux — версия 3.3.8. И на основании образа, найденного по адресу 0x11CEA5 , мы можем видеть, что rootfs является файловой системой squashfs .
Давайте теперь распакуем загрузчик (U-Boot) с помощью команды dd :
Поскольку образ сжат с помощью LZMA, нам нужно распаковать его:
Теперь у нас есть образ U-Boot:
Как насчет поиска дефолтного значения для bootargs ?
Переменная окружения U-Boot bootargs используется для передачи параметров ядру Linux. И из вышеприведенного мы лучше понимаем флэш-память устройства.
Как насчет извлечения образа ядра Linux?
Мы можем проверить, что образ был успешно извлечен с помощью команды file :
Формат файла uImage — это в основном образ ядра Linux с дополнительным заголовком. Давайте удалим этот заголовок, чтобы получить окончательный образ ядра Linux:
Образ сжат, поэтому давайте распакуем его:
Теперь у нас есть образ ядра Linux:
Что мы можем сделать с образом ядра? Мы могли бы, например, сделать поиск по строкам в образе и найти версию ядра Linux и узнать об окружающей среде, используемой для сборки ядра:
Несмотря на то, что прошивка была выпущена в прошлом году (2019 г.), когда я пишу эту статью, она использует старую версию ядра Linux (3.3.8), выпущенную в 2012 г., скомпилированную с очень старой версией GCC (4.6) также с 2012 г.!
(прим. перев. еще доверяете своим роутерам в офисе и дома?)
С опцией --opcodes мы также можем использовать binwalk для поиска машинных инструкций и определения архитектуры процессора образа:
Как насчет корневой файловой системы? Вместо того, чтобы извлекать образ вручную, давайте воспользуемся опцией binwalk --extract :
Полная корневая файловая система будет извлечена в подкаталог:
Теперь мы можем сделать много разного.
Мы можем искать файлы конфигурации, хэши паролей, криптографические ключи и цифровые сертификаты. Мы можем проанализировать бинарные файлы для поиска ошибок и уязвимостей.
С помощью qemu и chroot мы можем даже запустить (эмулировать) исполняемый файл из образа:
Здорово! Но обратите внимание, что версия BusyBox — 1.19.4. Это очень старая версия BusyBox, выпущенная в апреле 2012 года.
Таким образом, TP-Link выпускает образ прошивки в 2019 году с использованием программного обеспечения (GCC toolchain, kernel, BusyBox и т. Д.) 2012 года!
Теперь вы понимаете, почему я всегда устанавливаю OpenWRT на свои роутеры?
Это еще не все
Binwalk также может выполнять энтропийный анализ, печатать необработанные энтропийные данные и генерировать энтропийные графики. Обычно большая энтропия наблюдается, когда байты в образе случайны. Это может означать, что образ содержит зашифрованный, сжатый или обфусцированный файл. Хардкорно прописанный ключ шифрования? Почему бы и нет.

Мы также можем использовать параметр --raw для поиска пользовательской последовательности необработанных байтов в образе или параметр --hexdump для выполнения шестнадцатеричного дампа, сравнивающего два или более входных файла.
Пользовательские сигнатуры могут быть добавлены в binwalk либо через файл пользовательских сигнатур, указанный в командной строке с помощью параметра --magic , либо путем добавления их в каталог $ HOME / .config / binwalk / magic .
Вы можете найти больше информации о binwalk в официальной документации.
Расширение binwalk
Существует API-интерфейс binwalk, реализованный в виде модуля Python, который может использоваться любым скриптом Python для программного выполнения сканирования binwalk, а утилита командной строки binwalk может быть почти полностью продублирована всего двумя строками кода Python!
С помощью Python API вы также можете создавать плагины под Python для настройки и расширения binwalk.
Также существует плагин IDA и облачная версия Binwalk Pro.
Так почему бы вам не скачать образ прошивки из Интернета и не попробовать binwalk? Обещаю, вам будет очень весело :)
Этичный хакинг и тестирование на проникновение, информационная безопасность
Файлы контейнеры (матрёшки)
Многие файлы представляют собой объединения нескольких файлов. К примеру, файлы офисных документов .docx и .odt. Вы можете заменить расширение таких файлов на .zip, открыть любым архиватором и убедиться, что на самом деле это просто контейнеры, содержащие в себе множество файлов. Например, если вы вставили картинку в документ Word, то чтобы извлечь эту картинку, необязательно открывать файл в офисном редакторе — можно поменять расширение, распаковать архив и из него забрать свою картинку обратно. Практически все прошивки (для роутеров, IP камер, телефонов) это контейнеры. ISO образы и образы файловых систем тоже контейнеры. Архивы, как можно догадаться, также содержат в себе сразу несколько файлов.
2 способа объединения файлов
С практической точки зрения, с точки зрения поиска файлов можно выделить 2 способа объединить файлы:
1. Файлы хранятся без изменения, в своём начальном виде.
Пример такого объединения файлов это файловые системы без шифрования и без сжатия. Например, EXT4, NTFS — в них файлы помещены в своём первоначальном виде. Соответственно, образы таких файловых систем также относятся к этой группе. Сюда же можно отнести некоторые прошивки, например, для роутеров и IP камер.
Понятно, что в таких больших файлах (образах) можно найти хранимые файлы. Более того, хранимые файлы можно извлечь и сохранить в виде самостоятельного файла, который будет идентичен исходному.
2. Файлы обрабатываются по определённому алгоритму.
Примеры такого способа объединения файлов это файловые системы с шифрованием или сжатием (например, Squashfs), архивы со сжатием.
Для поиска отдельных файлов по их сигнатурам необходимо выполнить обратное действие, то есть если файл был сжат, необходимо его разархивировать. Если это файловая система со сжатием, то необходимо её смонтировать.
С практической точки зрения это означает, что бесполезно искать файлы по сигнатурам в архивах, пока эти архивы не распакованы (НО: некоторые программы по анализу сырых данных поддерживают работу с архивами!). Бесполезно искать файлы по сигнатурам в файловой системе Squashfs до её монтирования. При этом можно применять поиск по сигнатурам в EXT4 и NTFS и их монтирование не требуется!
Монтирование, например, образа NTFS даст нам следующее: мы сможем получать доступ к файлам этой файловой системы тем способом, каким это предусмотрели разработчики, то есть мы увидим список файлов и сможем получить доступ к любому из них без необходимости искать файлы по сигнатурам. Но при этом мы не сможем получить или даже узнать об уже удалённых файлах.
Без монтирования образа NTFS мы сможем работать с хранящимися на нём файлами напрямую, то есть с одной стороны нам придётся искать файлы по сигнатурам, но с другой стороны мы получим доступ даже к удалённым файлам. Удалённые файлы доступны в результате того, что обычно удаление на HDD заключается в том, что информация о файле просто удаляется из «журнала» файловой системы, но сам файл остаётся там же, где и был (если его впоследствии случайно не перезаписали другим файлом). Что касается с SSD, то там обычно данные всё-таки удаляются.
Ничего не мешает комбинировать эти способы, причём криминалистические инструменты позволяют сделать поиск удалённых данных более эффективным, например, поиск удалённых файлов выполняется только на тех частях диска, которые считаются пустыми.
Как распаковать прошивку камеры
Рассмотрим пример распаковки прошивки камеры Network Surveillance DVR r80x20-pq (эту камеру я использовал в тестах, например, в статье «Аудит безопасности IP камер».
Скачиваем и распаковываем архив. Он называется General_IPC_XM530_R80X20-PQ_WIFIXM711.711.Nat.dss.OnvifS_V5.00.R02.20210818_all.bin, для краткости последующих команд я переименую его в firmware.bin.
Проверим, что это за файл:
То есть это Zip архив.
Проверим с помощью Detect It Easy:
Также воспользуемся утилитой Binwalk, которая специально предназначена для анализа прошивок:

Поскольку это просто архив, распакуем его:

Видимо, следующие образы являются составными частями файловой системы:
Поинтересуемся файлом user-x.cramfs.img:

U-Boot — это загрузчик для встроенных плат на базе PowerPC, ARM, MIPS и нескольких других процессоров, который можно установить в загрузочное ПЗУ и использовать для инициализации и тестирования оборудования или для загрузки и запуска кода приложения. В вашем Linux вы можете найти пакеты uboot-tools (Arch Linux и производные) и u-boot-tools (Debian и производные) — это инструменты и утилиты для сборки прошивок и выполнения с ними других действий.
Попробуем смонтировать образ user-x.cramfs.img:

Обратимся за помощью к утилите Binwalk, которая умеет находить файлы и файловые системы даже если они находятся не в начале:

Теперь всё стало ясно — данный образ состоит из двух разделов. Первые 64 байта занимает заголовок uImage. А сама файловая система Squashfs идёт начиная с 64 байта.
Мы можем извлечь файловую систему — как это сделать сразу несколькими способами будет показано ниже, — но также по-прежнему можем её просто смонтировать, указав смещение:
Посмотрим на файлы, размещённые в образе user-x.cramfs.img:

В этом образе я не нашёл ничего интересного, размонтируем его:
Посмотрим, где начинается файловая система в romfs-x.cramfs.img:
Здесь можно найти хеш дефолтного пользователя root:

Аналогичным образом, сканируя с помощью Binwalk и монтируя разделы файловой системы, можно искать интересные файлы.
Как вырезать файловую систему из образа
1. Монтировать без извлечения
Как было показано выше, с помощью опции offset можно указать смещение и монтировать файловую систему которая является частью образа и расположена не в самом его начале:
Если образ содержит несколько файловых систем, вам может понадобиться указать ещё и опцию sizelimit — размер файловой системы:
2. Извлечение с помощью dd
Найдём разделы в прошивке:

Всего имеется три области:
- с 0 по 64 байты — заголовок uImage.
- с 64 начинаются сжатые данные LZMA
- С 1376256 начинается файловая система Squashfs, её размер 6205991 байт, это следует из строки «size: 6205991 bytes».
Для извлечения каждого из этих разделов можно использовать команду вида:
- ВХОД — начальный образ
- ВЫХОД — извлекаемый раздел
- БЛОК — размер блока, больший размер блока ускоряет запись, но последующие значения ЗАПИСАТЬ и ПРОПУСТИТЬ указывают на количество блоков, то есть если размер блока взять за единицу, то будет проще считать
- ЗАПИСАТЬ — сколько блоков записать
- ПРОПУСТИТЬ — сколько блоков от начала файла пропустить
К примеру, из файла Keenetic-II-V2.06(AAFG.0)C3.bin я хочу извлечь первые 64 байт, тогда команда следующая:
Теперь я хочу извлечь второй раздел, начинающийся с 64 байта. Этот раздел заканчивается на байте 1376256, но опция count команды dd указывает сколько байт нужно прочитать (а не границу извлечения данных), поэтому значение count рассчитывается по формуле:
В нашем случае это 1376256 - 64 = 1376192, получаем команду:
Файл LZMA можно распаковать, например, с помощью 7z:
В принципе команда извлекла данные, хотя и сообщила об ошибке:
Суть ошибки в том, что после конца полезной нагрузки были обнаружены данные. Можно сказать, что это нормально (неизбежно) в данном случае, поскольку мы не знали точный размер блока и указали в качестве его конца байт, где начинается другой раздел. Другой раздел начинается с байта (в шестнадцатеричном виде) 0x150000, поэтому можно предположить, что для паддинга (padding, выравнивания) между разделами просто «набиты» нули. В этом можно убедиться, открыв файл data.lzma в шестнадцатеричном редакторе, например в Bless:

Да, в конце этого файла нули — если точный размер неизвестен, то лучше записать лишнего, чем потерять данные.
Третий блок начинается с 1376256 байта и имеет размер 6205991 об этом нам говорит строка «size: 6205991 bytes». Команда по его извлечению следующая:
Но производители прошивки всё равно меня перехитрили использовав Squashfs version 3.0 из 2006 года и я не смог её открыть по техническим причинам:

3. Извлечение с помощью Binwalk
У программы Binwalk имеются следующие опции для извлечения:
4. Извлечение с помощью dc3dd и dcfldd
У программы dd есть улучшенные версии dc3dd и dcfldd. При желании для извлечения разделов файловой системы из образа диска вы можете использовать их.
Поиск последовательности байтов в бинарном файле
Программы file, Binwalk и Detect It Easy в поиске данных используют сигнатуры. Эти сигнатуры предопределены в их базах данных (так называемые магические файлы).
Если вам нужно выполнить поиск по вашим собственным сигнатурам, то есть по строке бинарных данных, то вы можете использовать Binwalk со следующими опциями:
Например, поиск шестнадцатеричных байтов 53EF в файле /mnt/disk_d/fs.ext4:
Программа sigfind из пакета Sleuth также позволяет искать по сигнатурам, при этом программа позволяет указать отступ от начала блока (НЕ файла). В программе прописаны несколько сигнатур для поиска файловых систем, например:
В следующем примере ищется последовательность байтов 53EF (обратный порядок записи байтов) со смещением 56 от любого блока (если не указать смещение, то будут выведены только блоки, где данная последовательность байтов имеет смещение 0):
Читайте также: