
Bpf linux что это
Обновлено: 03.07.2024
Трассировка и профайлинг в Linux с помощью bcc/eBPF
18 октября 2017
Немного матчасти
Итак, что такое eBPF, и что такое bcc?
Тулкит для создания программ, использующих возможности eBPF, называется bcc (иногда также пишут прописными буквами, BCC). Название расшифровывается, как BPF Compiler Collection. При написании кода с использованием bcc в качестве языка программирования используется смесь Python и C. Также в bcc входит большой набор готовых утилит для профайлинга программ и мониторинга системы. Бытует мнение, что эти готовые программки даже полезнее возможности писать свои собственные.
Установка bcc/eBPF
Для использования bcc/eBPF вам понадобится ядро Linux версии 4.1 или старше. Если быть точнее, лучше использовать версию не младше 4.9, иначе часть клевых возможностей eBPF будет вам недоступна. Согласно файлу INSTALL.md из репозитория bcc, ядро должно быть собрано со следующими флагами:
CONFIG_BPF=yCONFIG_BPF_SYSCALL=y
CONFIG_NET_CLS_BPF=m
CONFIG_NET_ACT_BPF=m
CONFIG_BPF_JIT=y
CONFIG_HAVE_BPF_JIT=y
CONFIG_BPF_EVENTS=y
Проверить их наличие можно командой:
Установка в Ubuntu 16.04 происходит так. Создаем /etc/apt/sources.list.d/iovisor.list:
sudo apt-get updatesudo apt-get install bcc bcc-tools python-bcc
В Arch Linux установить bcc/eBPF можно так:
Про установку пакетов из AUR в этой операционной системе, а также про утилиту yaourt, ранее рассказывалось в заметке Управление пакетами в Arch Linux с помощью ABS и pacman.
Некоторые утилиты из bcc-tools
Скрипты из пакета bcc-tools лежат в каталоге /usr/share/bcc/tools/. Рассмотрим некоторые из них.
Для отображения запускаемых программ и их аргументов есть утилита execsnoop. Ее вывод выглядит как-то так:
PCOMM PID PPID RET ARGSsshd 7871 813 0 /usr/sbin/sshd -D -R
sh 7873 7871 0
uname 7878 7875 0 /bin/uname -m
cut 7885 7883 0 /usr/bin/cut -d -f4
lsb_release 7884 7883 0 /usr/bin/lsb_release -sd
.
Если хочется узнать, какие процессы какие файлы открывают, воспользуйтесь opensnoop:
PID COMM FD ERR PATH3450 i3status 4 0 /etc/mtab
3450 i3status 4 0 /proc/loadavg
754 psql 3 0 /usr/lib/locale/locale-archive
754 psql 3 0 /usr/share/locale/locale.alias
.
Посмотреть топ процессов по создаваемому ими дисковому I/O позволяет утилита biotop:
PID COMM D MAJ MIN DISK I/O Kbytes AVGms3388 dmcrypt_write W 7 0 loop0 281 3524.0 0.66
3360 loop0 W 8 0 sda 76 3524.0 0.19
378 jbd2/sda2-8 W 8 0 sda 113 676.0 0.05
3360 loop0 R 8 0 sda 10 40.0 0.14
.
С помощью tcplife можно в реальном времени посмотреть, кто сожрал весь сетевой трафик:
PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS3506 Chrome 10.128.0.6 33110 87.250.247.182 443 1 18 69347.77
3506 Chrome 10.128.0.6 37576 213.180.204.161 443 1 10 68529.41
3506 Chrome 10.128.0.6 37568 213.180.204.161 443 1 10 68529.48
3506 Chrome 10.128.0.6 42526 95.101.241.61 443 0 3 22147.14
3506 Chrome 10.128.0.6 42522 95.101.241.61 443 0 3 22147.23
3506 Chrome 10.128.0.6 56444 178.154.131.216 443 2 11 82244.22
3506 Chrome 10.128.0.6 56460 178.154.131.216 443 2 8 82157.24
3506 Chrome 10.128.0.6 56442 178.154.131.216 443 3 329 82290.86
.
Аналогичная утилита, но показывающая не лог реального времени, а топ процессов, называется tcptop:
PID COMM LADDR RADDR RX_KB TX_KB18023 openvpn 192.168.27.173:59342 46.101.213.42:443 14 17
3534 Chrome 10.128.0.6:38314 104.244.42.1:443 5 10
3534 Chrome 10.128.0.6:35538 192.229.233.50:443 5 0
3534 Chrome 10.128.0.6:38336 104.244.42.1:443 5 5
.
Еще из особо интересных утилит я бы лично отметил cpudist, runqlat, filetop, biolatency, gethostlatency, а также совершенно выносящие мозг trace и argdist.
Всего на момент написания этих строк в bcc-tools входило около 100 утилит. Само собой разумеется, рассмотреть их все в рамках одного поста не представляется возможным. К счастью, описание каждой из утилит и поддерживаемых ею флагов можно прочитать, запустив утилиту с флагом -h . Кроме того, в подкаталоге /doc/ вы найдете примеры использования каждой из утилит.
Строим флеймграфы!
Какая же заметка про DTrace или его аналог может обойтись без флеймграфов? В случае с eBPF флеймграф для процесса с заданным pid строится как-то так:
Примерный вид результата:
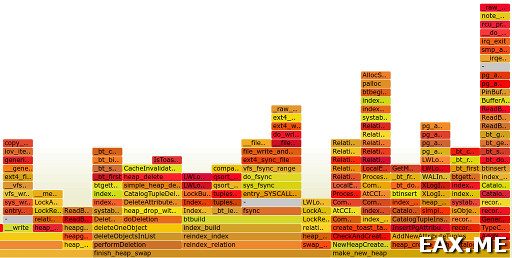
Здесь я профилировал PostgreSQL, выполняющий VACUUM FULL .
Иногда нужно замерить время, которое процесс проводит «off-cpu», к примеру, в sleep или ожидая ввода-вывода. В этом случае вам могут помочь утилиты offcputime и offwaketime. Они имеют такие же флаги, что и утилита profile.
Заключение
Написание собственных утилит с помощью bcc, увы, выходит за рамки данной заметки. Соответствующий туториал вы найдете в репозитории bcc. Кроме того, учиться можно по коду утилит из пакета bcc-tools.
Мои личные впечатления от bcc/eBPF исключительно положительные. Просто установил и пользуешься, ни о чем особо думать не нужно, и при этом не страшно запускать в продакшене. Правда, у меня возникли кое-какие проблемы с утилитой ext4slower. Кроме того, оказалось, что некоторые утилиты (например, dbstat и dbslower) требуют установки dtrace4linux для сборки профилируемых приложений с поддержкой USDT, что несколько неудобно. Но учитывая относительную молодость технологии, некоторые шероховатости были вполне ожидаемы. Я довольно уверен, что названные проблемы со временем поправят.
А доводилось ли вам пользоваться eBPF и если да, то что вы им делали и каковы ваши впечатления от него?

Дэвид Калавера и Лоренцо Фонтана помогут вам раскрыть возможности BPF. Расширьте свои знания об оптимизации производительности, сетях, безопасности. — Используйте BPF для отслеживания и модификации поведения ядра Linux. — Внедряйте код для безопасного мониторинга событий в ядре — без необходимости перекомпилировать ядро или перезагружать систему. — Пользуйтесь удобными примерами кода на C, Go или Python. — Управляйте ситуацией, владея жизненным циклом программы BPF.
Безопасность ядра Linux, его возможности и Seccomp
BPF предоставляет мощный способ расширения ядра без ущерба для стабильности, безопасности и скорости. По этой причине разработчики ядра подумали, что было бы неплохо использовать его универсальность для улучшения изоляции процессов в Seccomp путем реализации фильтров Seccomp, поддерживаемых программами BPF, известными также как Seccomp BPF. В этой главе мы расскажем, что такое Seccomp и как он применяется. Затем вы узнаете, как писать фильтры Seccomp с помощью программ BPF. После этого рассмотрим встроенные ловушки BPF, которые есть в ядре для модулей безопасности Linux.
Модули безопасности Linux (LSM) — это платформа, предоставляющая набор функций, которые можно применять для стандартизированной реализации различных моделей безопасности. LSM может использоваться непосредственно в дереве исходного кода ядра, например Apparmor, SELinux и Tomoyo.
Начнем с обсуждения возможностей Linux.
Возможности
Суть возможностей Linux заключается в том, что вам нужно предоставить непривилегированному процессу разрешение на выполнение определенной задачи, но без использования suid для этой цели, или иным образом сделать процесс привилегированным, уменьшая возможность атак и обеспечивая процессу возможность выполнения определенных задач. Например, если вашему приложению нужно открыть привилегированный порт, допустим, 80, вместо запуска процесса от имени root можете просто предоставить ему возможность CAP_NET_BIND_SERVICE.
Рассмотрим программу Go с именем main.go:


Однако, поскольку мы не предоставляем привилегии root, этот код выдаст ошибку при привязке порта:

capsh (средство управления оболочкой) — это инструмент, который запускает оболочку с определенным набором возможностей.
В этом случае, как уже говорилось, вместо предоставления полных прав root можно разрешить привязку привилегированных портов, предоставив возможность cap_net_bind_service наряду со всеми остальными, которые уже есть в программе. Для этого можем заключить нашу программу в capsh:

Немного разберемся в этой команде.
- capsh — используем capsh в качестве оболочки.
- --caps='cap_net_bind_service+eip cap_setpcap,cap_setuid,cap_setgid+ep' — поскольку нам нужно сменить пользователя (мы не хотим запускаться с правами root), укажем cap_net_bind_service и возможность фактически изменить идентификатор пользователя с root на nobody, а именно cap_setuid и cap_setgid.
- --keep=1 — хотим сохранить установленные возможности, когда выполнено переключение с аккаунта root.
- --user=«nobody» — конечным пользователем, запускающим программу, будет nobody.
- --addamb=cap_net_bind_service — задаем очистку связанных возможностей после переключения из режима root.
- — -c "./capabilities" — просто запускаем программу.
Связанные возможности — это особый вид возможностей, которые наследуются дочерними программами, когда текущая программа выполняет их с помощью execve(). Наследоваться могут только возможности, разрешенные как связанные, или, другими словами, как возможности окружения.
Вероятно, вам интересно, что значит +eip после указания возможности в опции --caps. Эти флаги используются для определения того, что возможность:
-должна быть активирована (p);
-доступна для применения (е);
-может быть унаследована дочерними процессами (i).
Поскольку мы хотим использовать cap_net_bind_service, нужно сделать это с флагом e. Затем запустим оболочку в команде. В результате запустится двоичный файл capabilities, и нам нужно пометить его флагом i. Наконец, мы хотим, чтобы возможность была активирована (мы это сделали, не меняя UID) с помощью p. Это выглядит как cap_net_bind_service+eip.
Можете проверить результат с помощью ss. Немного сократим вывод, чтобы он поместился на странице, но он покажет связанный порт и идентификатор пользователя, отличные от 0, в данном случае 65 534:

В этом примере мы использовали capsh, но вы можете написать оболочку с помощью libcap. За дополнительной информацией обращайтесь к man 3 libcap.
При написании программ разработчик довольно часто не знает заранее всех возможностей, необходимых программе во время выполнения; более того, в новых версиях эти возможности могут измениться.
Чтобы лучше понять возможности нашей программы, можем взять инструмент BCC capable, который устанавливает kprobe для функции ядра cap_capable:

Добиться того же самого мы можем, используя bpftrace с однострочным kprobe в функции ядра cap_capable:

Это выведет что-то вроде следующего, если возможности нашей программы будут активированы после kprobe:

Пятый столбец — это возможности, в которых нуждается процесс, и, поскольку эти выходные данные включают в том числе неаудитные события, мы видим все неаудитные проверки и, наконец, требуемую возможность с флагом аудита (последний в выводе), установленным в 1. Возможность, которая нас интересует, — CAP_NET_BIND_SERVICE, она определяется как константа в исходном коде ядра в файле include/uapi/linux/ability.h с идентификатором 10:

Возможности часто задействуются во время выполнения контейнеров, таких как runC или Docker, чтобы они работали в непривилегированном режиме, но им были разрешены только те возможности, которые необходимы для запуска большинства приложений. Когда приложению требуются определенные возможности, в Docker можно обеспечить их с помощью --cap-add:

Эта команда предоставит контейнеру возможность CAP_NET_ADMIN, что позволит ему настроить сетевую ссылку для добавления интерфейса dummy0.
В следующем разделе показано использование таких возможностей, как фильтрация, но с помощью другого метода, который позволит нам программно реализовать собственные фильтры.
Seccomp
Seccomp означает Secure Computing, это уровень безопасности, реализованный в ядре Linux, который позволяет разработчикам фильтровать определенные системные вызовы. Хотя Seccomp сопоставим с возможностями Linux, его способность управлять определенными системными вызовами делает его намного более гибким по сравнению с ними.
Seccomp и возможности Linux не исключают друг друга, их часто используют вместе, чтобы получить пользу от обоих подходов. Например, вы можете захотеть предоставить процессу возможность CAP_NET_ADMIN, но не разрешить ему принимать соединения через сокет, блокируя системные вызовы accept и accept4.
Способ фильтрации Seccomp основан на фильтрах BPF, работающих в режиме SECCOMP_MODE_FILTER, и фильтрация системных вызовов выполняется так же, как и для пакетов.
Фильтры Seccomp загружаются с использованием prctl через операцию PR_SET_SECCOMP. Эти фильтры имеют форму программы BPF, которая выполняется для каждого пакета Seccomp, представленного с помощью структуры seccomp_data. Эта структура содержит эталонную архитектуру, указатель инструкций процессора во время системного вызова и максимум шесть аргументов системного вызова, выраженных как uint64.
Вот как выглядит структура seccomp_data из исходного кода ядра в файле linux/seccomp.h:

Как видно из этой структуры, мы можем фильтровать по системному вызову, его аргументам или их комбинации.
После получения каждого пакета Seccomp фильтр обязан выполнить обработку, чтобы принять окончательное решение, и сообщить ядру, что делать дальше. Окончательное решение выражается одним из возвращаемых значений (кодов состояния).
— SECCOMP_RET_KILL_PROCESS — завершение всего процесса сразу же после фильтрации системного вызова, который из-за этого не выполняется.
— SECCOMP_RET_KILL_THREAD — завершение текущего потока сразу же после фильтрации системного вызова, который из-за этого не выполняется.
— SECCOMP_RET_KILL — алиас для SECCOMP_RET_KILL_THREAD, оставлен для обратной совместимости.
— SECCOMP_RET_TRAP — системный вызов запрещен, и сигнал SIGSYS (Bad System Call) отправляется вызывающей его задаче.
— SECCOMP_RET_ERRNO — системный вызов не выполняется, и часть возвращаемого значения фильтра SECCOMP_RET_DATA передается в пространство пользователя как значение errno. В зависимости от причины ошибки возвращаются разные значения errno. Список номеров ошибок приведен в следующем разделе.
— SECCOMP_RET_TRACE — используется для уведомления трассировщика ptrace с помощью — PTRACE_O_TRACESECCOMP для перехвата, когда выполняется системный вызов, чтобы видеть и контролировать этот процесс. Если трассировщик не подключен, возвращается ошибка, errno устанавливается в -ENOSYS, а системный вызов не выполняется.
— SECCOMP_RET_ALLOW — системный вызов просто разрешен.
ptrace — это системный вызов для реализации механизмов трассировки в процессе, называемом tracee, с возможностью наблюдения и контроля за выполнением процесса. Программа трассировки может эффективно влиять на выполнение и изменять регистры памяти tracee. В контексте Seccomp ptrace используется, когда запускается кодом состояния SECCOMP_RET_TRACE, следовательно, трассировщик может предотвратить выполнение системного вызова и реализовать собственную логику.
Читайте также: