
Что такое linux кластер
Обновлено: 05.07.2024
Оригинал: Building a Linux-Based High-Performance Compute Cluster
Автор: Tom Lehmann
Дата: 1 июня 2009
Перевод: Александр Тарасов aka oioki
Дата перевода: 11 августа 2009
Представьте, что у вас есть программа, работающая на относительно новом компьютере с двухъядерным процессором. К сожалению, начальство требует, чтобы эта программа работала быстрее, и чтобы справлялась с большим числом данных за то же самое время. Вы проводите небольшое исследование и обнаруживаете, что для вашей программы существует SMP-версия и версия для кластеров. Сейчас на вашей рабочей станции установлена SMP-версия. Можно увеличить производительность, запустив программу на четырехъядерном (или с большим числом ядер) компьютере, но босс совсем не хочет тратиться на новейшее железо, да еще в нынешнем экономическом климате. Но подождите, у вас же есть 32 старых однопроцессорных компьютера, которые были заменены в прошлом году. Да, у них всего по одному ядру, но все вместе они смогут сделать больше, чем одна двухъядерная машина. Нужно лишь найти способ, как заставить их работать сообща - другими словами, собрать из них кластер.
Так что же такое кластер? Вот одно приемлемое определение: кластер - это группа компьютеров, которые вместе решают одну задачу. Необходимо, чтобы машины кластера были соединены сетью и доверяли друг другу.
Настроить сеть и безопасность кластера возможно и вручную, однако есть более простые способы, и один из них - это воспользоваться какой-нибудь системой установки и настройки кластера. На данный момент одной из наиболее популярных систем подобного рода является пакет Rocks, разрабатываемый командой Калифорнийского университета (University of California, San Diego) при грантовой поддержке Национального научного фонда США (National Science Foundation).
Rocks определяется как пакет развертывания, управления и поддержки кластера. С его помощью можно установить кластер на месте, имея в наличии одно лишь аппаратное обеспечение. Пакет содержит средства для запуска параллельных программ и программы для поддержки и расширения кластера после его первоначальной установки.
Пакет распространяется в виде набора ISO-образов, которые нужно записать на несколько CD или DVD. Затем вы вставляете DVD или CD в машину, которая станет главным узлом и загружаетесь с диска. Дальнейшие действия вам будет подсказывать мастер установки. После ответа на минимальное число вопросов, мастер начнет устанавливать все необходимое для работы главного узла. Последним шагом перед перезагрузкой будет процедура insert-ethers, которая добавляет остальные машины в качестве вычислительных узлов. Чтобы добавить вычислительный узел, нужно загрузить его из сети, и он будет добавлен в кластер и настроен автоматически. После добавления последнего узла, у вас получится функционирующий кластер, пригодный для запуска паралелльных программ.
Таково общее описание процесса, давайте же приступим к построению кластера из невзрачных на первый взгляд компьютеров.
Добрый день хабравчане, по роду своей деятельности нередко приходится работать с кластерными решения тех или иных программных продуктов. Но рассказывать о настройках какого либо программного продукта было бы не так информативно, поэтому поискав, и наткнувшись на сайт Юрия (за что ему огромное спасибо), я решил немножко развить эту тему и на конкретном примере посмотреть прирост производительности при вычислении числа Pi в кластерном исполнении.
Итак, у нас в наличии 4 сервера HP, из которых 3 сервера будут объединены в кластер, а один будет консолью управления. На всех серверах будет развернут Linux SLES 10 SP2 и openMPI, также будет организован беспарольный доступ по SSH между консолью и серверами.
Устанавливаем Linux с минимальными настройками системы, необходимые пакеты можно будет доставить позже. Обратим внимание на то, что архитектура компонентов всех узлов кластера должна быть идентична.
Загружаем пакет openMPI на узлы кластера, собираем и устанавливаем их.
./configure
make
make install
После установки openMPI следующим шагом нашей работы будет компиляция программы вычисления числа Pi на каждом узле кластера. Для этого нам понадобится пакет libopencdk, который присутствует в YAST’e и исходный код программы вычисления числа Pi (flops.f). После того как пакет установлен, а программа помещена в ту директорию, которая будет одинакова на всех узлах кластера и узле управления (консоли), приступаем к компиляции программы:
mpif77 flops.f -o flops
Устанавливаем беспарольный доступ по ssh, тут все просто:
1) Заходим на консоль кластера и генерируем rsa-ключ командой:
ssh-keygen -t rsa
2) Копируем публичный ключ консоли (root/.ssh/id_rsa.pub) на все узлы кластера, в моем случае:
scp /root/.ssh/id_rsa.pub server1:/root/.ssh
3) На каждом узле кластера создаем файл доступа:
cat id_rsa.pub >> authorized_keys
Беспарольный доступ готов.
Следующий шаг — формирование файла со списком узлов всех наших кластеров назовем его openmpi.host и положим его в папку с нашей тестовой программой расчета числа Pi. Узлы в файле можно указывать, как по именам, так и просто, по адресам. Например:
192.168.0.1
192.168.0.2
192.168.0.3
Serv1
Serv2
Serv3
Итак, настройка консоли и узлов кластера закончена, переходим к стадии тестирования:
Запускаем программу на 1 сервере, для этого на узле управления запускаем команду:
mpirun -hostfile /var/mpi/openmpi.host -np 1 var/mpi/flops
Где:
–np число узлов кластер используемых при вычислениях.
Calculation time (s) — время вычисления операций.
Cluster speed (MFLOPS) — количество операций с плавающей запятой в секунду.
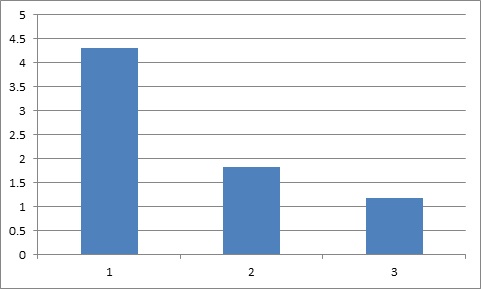
Получаем следующий результат:
Calculation time = 4.3
Cluster speed = 418 MFLOPS
Добавим еще 1 сервер в кластер:
mpirun -hostfile /var/mpi/openmpi.host -np 2 var/mpi/flops
Получаем следующий результат:
Calculation time = 1.82
Cluster speed = 987 MFLOPS
Добавим последний, 3 сервер в кластер:
mpirun -hostfile /var/mpi/openmpi.host -np 3 var/mpi/flops
Получаем следующий результат:
Calculation time = 1.18
Cluster speed = 1530 MFLOPS
Время вычисления операций (секунды):
Количество операций с плавающей запятой в секунду (MFLOPS):
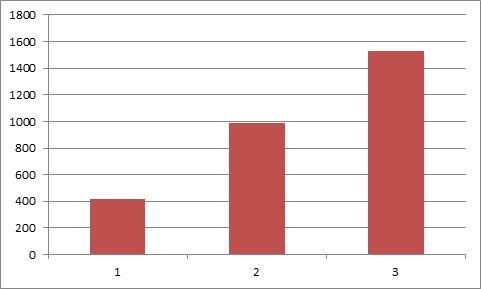
Проанализировав полученные данные, можно сделать вывод, что при добавлении нового узла в кластер, производительность всей системы в целом возрастает на (1/N) * 100%.
Я не ставил себе целью в этой статье проанализировать варианты решения конкретных прикладных задач на кластерных решениях. Моя цель состояла в том, что бы показать эффективность работы кластерных систем. А также на примере продемонстрировать архитектуру построения кластерного элемента в структуре сети.
UPD: Спасибо за конструктивную критику uMg и 80x86, соответствующие изменения были внесены в статью.
Поговорим о горизонтальном масштабировании. Допустим, ваш проект вырос до размеров, когда один сервер не справляется с нагрузкой, а возможностей для вертикального роста ресурсов уже нет.
В этом случае дальнейшее развитие инфраструктуры проекта обычно происходит за счет увеличения числа однотипных серверов с распределением нагрузки между ними. Такой подход не только позволяет решить проблему с ресурсами, но и добавляет надежности проекту — при выходе из строя одного или нескольких компонентов его работоспособность в целом не будет нарушена.
Большую роль в этой схеме играет балансировщик — система, которая занимается распределением запросов/трафика. На этапе ее проектирования важно предусмотреть следующие ключевые требования:
- Отказоустойчивость. Нужно как минимум два сервера, которые одновременно занимаются задачей распределения запросов/трафика. Без явного разделения ролей на ведущего и резервного.
- Масштабирование. Добавление новых серверов в систему должно давать пропорциональную прибавку в ресурсах.
Фактически, это описание кластера, узлами которого являются серверы-балансеры.
В этой статье мы хотим поделиться рецептом подобного кластера, простого и неприхотливого к ресурсам, концепцию которого успешно применяем в собственной инфраструктуре для балансировки запросов к серверам нашей панели управления, внутреннему DNS серверу, кластеру Galera и разнообразными микросервисам.
Договоримся о терминах:
— Серверы, входящие в состав кластера, будем называть узлами или балансерами.
— Конечными серверами будем называть хосты, на которые проксируется трафик через кластер.
— Виртуальным IP будем называть адрес, “плавающий” между всеми узлами, и на который должны указывать имена сервисов в DNS.
Что потребуется:
— Для настройки кластера потребуется как минимум два сервера (или вирт.машины) с двумя сетевыми интерфейсами на каждом.
— Первый интерфейс будет использоваться для связи с внешним миром. Здесь будут настроены реальный и виртуальный IP адреса.
— Второй интерфейс будет использоваться под служебный трафик, для общения узлов друг с другом. Здесь будет настроен адрес из приватной (“серой”) сети 172.16.0.0/24.
Вторые интерфейсы каждого из узлов должны находиться в одном сегменте сети.
Используемые технологии:
LVS, Linux Virtual Server — механизм балансировки на транспортном/сеансовом уровне, встроенный в ядро Linux в виде модуля IPVS. Хорошее описание возможностей LVS можно найти здесь и здесь.
Суть работы сводится к указанию того, что есть определенная пара “IP + порт” и она является виртуальным сервером. Для этой пары назначаются адреса реальных серверов, ответственных за обработку запросов, задается алгоритм балансировки, а также режим перенаправления запросов.
В нашей системе мы будем использовать Nginx как промежуточное звено между LVS и конечными серверами, на которые нужно проксировать трафик. Nginx будет присутствовать на каждом узле.
Для настроек VRRP и взаимодействия с IPVS будем использовать демон Keepalived, написанный в рамках проекта Linux Virtual Server.
КОНЦЕПЦИЯ
Система будет представлять собой связку из двух независимых друг от друга равнозначных узлов-балансеров, объединенных в кластер средствами технологии LVS и протокола VRRP.
Точкой входа для трафика будет являться виртуальный IP адрес, поднятый либо на одном, либо на втором узле.
Поступающие запросы LVS перенаправляет к одному из запущенных экземпляров Nginx — локальному или на соседнем узле. Такой подход позволяет равномерно размазывать запросы между всеми узлами кластера, т.е. более оптимально использовать ресурсы каждого балансера.
Работа Nginx заключается в проксировании запросов на конечные сервера. Начиная с версии 1.9.13 доступны функции проксирования на уровне транспортных протоколов tcp и udp.
Каждый vhost/stream будет настроен принимать запросы как через служебный интерфейс с соседнего балансера так и поступающие на виртуальный IP. Причем даже в том случае, если виртуальный IP адрес физически не поднят на данном балансере (Keepalived назначил серверу роль BACKUP).
Таким образом, схема хождения трафика в зависимости от состояния балансера (MASTER или BACKUP) выглядит так:
- запрос приходит на виртуальный IP. IPVS маршрутизирует пакет на локальный сервер;
- поскольку локальный Nginx слушает в том числе виртуальный IP, он получает запрос;
- согласно настройкам проксирования для данного виртуального IP Nginx отправляет запрос одному из перечисленных апстримов;
- полученный ответ отправляется клиенту.
- запрос приходит на виртуальный IP. IPVS маршрутизирует пакет на соседний сервер;
- на соседнем балансере этот виртуальный IP не поднят. Поэтому dst_ip в пакете нужно заменить на соответствующий серый IP из сети текущего балансера. Для этого используется DNAT;
- после этого локальный Nginx получает запрос на серый IP адрес;
- согласно настройкам проксирования для данного виртуального IP Nginx отправляет запрос одному из перечисленных апстримов;
- полученный ответ отправляется клиенту напрямую с src_ip равным виртуальному IP (при участии conntrack)
РЕАЛИЗАЦИЯ:
В качестве операционной системы будем использовать Debian Jessie с подключенными backports репозиториями.
Установим на каждый узел-балансер пакеты с необходимым для работы кластера ПО и сделаем несколько общесистемных настроек:
На интерфейсе eth1 настроим адреса из серой сети 172.16.0.0/24 :
Виртуальный IP адрес прописывать на интерфейсе eth0 не нужно. Это сделает Keepalived.
В файл /etc/sysctl.d/local.conf добавим следующие директивы:
Первая включает возможность слушать IP, которые не подняты локально (это нужно для работы Nginx). Вторая включает автоматическую защиту от DDoS на уровне балансировщика IPVS (при нехватке памяти под таблицу сессий начнётся автоматическое вычищение некоторых записей). Третья увеличивает размер conntrack таблицы.
В /etc/modules включаем загрузку модуля IPVS при старте системы:
Параметр conn_tab_bits определяет размер таблицы с соединениями. Его значение является степенью двойки. Максимально допустимое значение — 20.
Кстати, если модуль не будет загружен до старта Keepalived, последний начинает сегфолтиться.
Теперь перезагрузим оба узла-балансера. Так мы убедимся, что при старте вся конфигурация корректно поднимется.
Общие настройки выполнены. Дальнейшие действия будем выполнять в контексте двух задач:
Вводные данные:
- В качестве виртуального IP адреса будем использовать 192.168.0.100 ;
- У веб-серверов будут адреса 192.168.0.101 , 192.168.0.102 и 192.168.0.103 соответственно их порядковым номерам;
- У DNS серверов 192.168.0.201 и 192.168.0.202 .
Начнем с конфигурации Nginx.
Добавим описание секции stream в /etc/nginx/nginx.conf :
И создадим соответствующий каталог:
Настройки для веб-серверов добавим в файл /etc/nginx/sites-enabled/web_servers.conf
Настройки для DNS-серверов добавим в файл /etc/nginx/stream-enabled/dns_servers.conf
Далее остается сконфигурировать Keepalived (VRRP + LVS). Это немного сложнее, поскольку нам потребуется написать специальный скрипт, который будет запускаться при переходе узла-балансера между состояниями MASTER/BACKUP.
Все настройки Keepalived должны находиться в одном файле — /etc/keepalived/keepalived.conf . Поэтому все нижеследующие блоки с конфигурациями VRRP и LVS нужно последовательно сохранить в этом файле.
Скрипт, который упоминался выше — /usr/local/bin/nat-switch . Он запускается каждый раз, когда у текущего VRRP инстанса меняется состояние. Его задача заключается в том, чтобы балансер, находящийся в состоянии BACKUP, умел корректно обработать пакеты, адресованные на виртуальный IP. Для решения этой ситуации используются возможности DNAT. А именно, правило вида:
При переходе в состояние MASTER, скрипт удаляет это правило.
Здесь можно найти вариант скрипта nat-switch , написанный для данного примера.
Настройки LVS для группы веб-серверов:
Настройки LVS для группы DNS-серверов:
В завершении перезагрузим конфигурацию Nginx и Keepalived:
ТЕСТИРОВАНИЕ:
Посмотрим как балансировщик распределяет запросы к конечным серверам. Для этого на каждом из веб-серверов создадим index.php с каким-нибудь простым содержимым:
Если в процессе выполнения этого цикла посмотреть на статистику работы LVS (на MASTER узле), то мы можем увидеть следующую картину:
Здесь видно как происходит распределение запросов между узлами кластера: есть два активных соединения, которые обрабатываются в данный момент и 6 уже обработанных соединений.
Статистику по все соединениям, проходящим через LVS, можно посмотреть так:
Здесь, соответственно, видим то же самое: 2 активных и 6 неактивный соединений.
ПОСЛЕСЛОВИЕ:
Предложенная нами конфигурация может послужить отправным пунктом для проектирования частного решения под конкретный проект со своими требованиями и особенностями.
Если у вас возникли вопросы по статье или что-то показалось спорным — пожалуйста, оставляйте свои комментарии, будем рады обсудить.
Привет всем, на этот раз я решил поделиться с вами своими знаниями о кластеризации Linux в виде серии руководств под названием «Кластеризация Linux для сценария аварийного переключения».

Ниже приводится серия из 4 статей о кластеризации в Linux:
Прежде всего, вам нужно знать, что такое кластеризация, как она используется в промышленности, какие преимущества и недостатки она имеет и т. Д.
Что такое кластеризация
Кластеризация устанавливает соединение между двумя или более серверами, чтобы они работали как один. Кластеризация - очень популярный метод среди системных инженеров, который позволяет кластеризовать серверы в качестве системы аварийного переключения, системы балансировки нагрузки или параллельного процессора.
В этой серии руководств я надеюсь помочь вам создать кластер Linux с двумя узлами в RedHat/CentOS для сценария аварийного переключения.
Поскольку теперь у вас есть общее представление о том, что такое кластеризация, давайте выясним, что это значит, когда дело доходит до отказоустойчивой кластеризации. Отказоустойчивый кластер - это набор серверов, которые работают вместе для поддержания высокой доступности приложений и служб.
Например, если в какой-то момент сервер выходит из строя, другой узел (сервер) берет на себя нагрузку и не дает конечному пользователю простоя. Для такого сценария нам понадобится как минимум 2 или 3 сервера для правильной настройки.
Я предпочитаю использовать 3 сервера; один сервер как сервер с включенным кластером Red Hat, а другие как узлы (внутренние серверы). Давайте посмотрим на диаграмму ниже для лучшего понимания.

В приведенном выше сценарии управление кластером осуществляется отдельным сервером, который обрабатывает два узла, как показано на схеме. Сервер управления кластером постоянно отправляет контрольные сигналы обоим узлам, чтобы проверить, нет ли сбоев. Если кто-то потерпел неудачу, другой узел берет на себя нагрузку.
- Кластерные серверы - полностью масштабируемое решение. Впоследствии вы можете добавить ресурсы в кластер.
- Если сервер в кластере нуждается в обслуживании, вы можете сделать это, остановив его, передав нагрузку другим серверам.
- Среди вариантов высокой доступности кластеризация занимает особое место, поскольку она надежна и проста в настройке. В случае, если сервер испытывает проблемы с предоставлением услуг, кроме того, другие серверы в кластере могут взять на себя эту нагрузку.
- Стоимость высока. Поскольку для кластера требуется хорошее оборудование и конструкция, он будет дорогостоящим по сравнению с управлением некластеризованным сервером. Нерентабельность - главный недостаток этой конкретной конструкции.
- Поскольку для создания кластера требуется больше серверов и оборудования, мониторинг и обслуживание затруднены. Таким образом увеличьте инфраструктуру.
- Риччи (ricci-0.16.2-75.el6.x86_64.rpm)
- Люси (luci-0.26.0-63.el6.centos.x86_64.rpm)
- Mod_cluster (modcluster-0.16.2-29.el6.x86_64.rpm)
- CCS (ccs-0.16.2-75.el6_6.2.x86_64.rpm)
- CMAN (cman-3.0.12.1-68.el6.x86_64.rpm)
- Clusterlib (clusterlib-3.0.12.1-68.el6.x86_64.rpm)
Давайте посмотрим, что каждая установка делает для нас и их значение.
Прочтите статью, поймите сценарий, для которого мы собираемся создать решение, и установите предварительные условия для его реализации. Давайте познакомимся с частью 2 в нашей следующей статье, где мы узнаем, как установить и создать кластер для данного сценария.
Рекомендации:
- Документация ch-cman
- Документация по модификациям
Оставайтесь на связи с Tecmint, чтобы получить под рукой самые свежие инструкции. Следите за новостями о части 02 (Кластеризация серверов Linux с 2 узлами для сценария аварийного переключения на RedHAT/CentOS - Создание кластера) в ближайшее время.
Читайте также: