
Как программировать на линукс
Обновлено: 04.07.2024
Это краткое руководство объясняет, как компилировать и запускать программы на Си/Си++ в операционной системе GNU/Linux.
Если вы студент или новый пользователь Linux, который переходит с платформы Microsoft, то вам может быть интересно, как запускать программы на Си или Си++ в дистрибутиве Linux. Мы должны понимать, что компиляция и запуск кода на платформах Linux немного отличается от Windows.
Установка необходимых инструментов
Как вы, наверное, уже понимаете, для запуска кода нужно установить необходимые инструменты и компиляторы для работы. Ниже мы опишем как установить все инструменты разработки в Linux.
Для работы и тестирования у нас должен быть сервер с Linux. Лучший вариант - это VPS. В зависимости от географии проекта обычно выбирают две страны для серверов - VPS США и VPS России.
В этом кратком руководстве мы обсудим, как установить средства разработки в такие дистрибутивы Linux, как Arch Linux, CentOS, RHEL, Fedora, Debian, Ubuntu, openSUSE и др.
Эти средства разработки включают в себя все необходимые приложения, такие как компиляторы GNU GCC C/C++, make, отладчики, man-страницы и другие, которые необходимы для компиляции и сборки нового программного обеспечения и пакетов.
Инструменты разработчика могут быть установлены как по отдельности, так и все сразу. Мы собираемся установить все сразу, чтобы нам было намного проще работать.
Установка в Arch Linux
Для установки средств разработки в Arch Linux и его дистрибутивов, таких как Antergos, Manjaro Linux, просто запустите:
Вышеуказанная команда установит следующие пакеты в ваши системы на базе Arch:
- autoconf
- automake
- binutils
- bison
- fakeroot
- file
- findutils
- flex
- gawk
- gcc
- gettext
- grep
- groff
- gzip
- libtool
- m4
- make
- pacman
- patch
- pkg-config
- sed
- sudo
- texinfo
- util-linux
- which
Просто нажми ENTER, чтобы установить их все.

Если вы хотите установить пакет в определенную группу пакетов, просто введите его номер и нажмите ENTER, чтобы продолжить установку.
Установка средств разработки в RHEL, CentOS
Для установки средств разработки в Fedora, RHEL и его клонах, таких как CentOS, Scientific Linux, выполните следующие команды как пользователь root:
Вышеуказанная команда установит все необходимые инструменты разработчика, например:
- autoconf
- automake
- bison
- byacc
- cscope
- ctags
- diffstat
- doxygen
- elfutils
- flex
- gcc/gcc-c++/gcc-gfortran
- git
- indent
- intltool
- libtool
- patch
- patchutils
- rcs
- subversion
- swig

Установка инструментов разработки в Debian, Ubuntu и дистрибутивы
Для установки необходимых инструментов разработчика в системах на базе DEB, запустите:
Эта команда предоставит все необходимые пакеты для настройки среды разработки в Debian, Ubuntu и его дистрибутивов.
- binutils
- cpp
- gcc-5-locales
- g++-multilib
- g++-5-multilib
- gcc-5-doc
- gcc-multilib
- autoconf
- automake
- libtool
- flex
- bison
- gdb
- gcc-doc
- gcc-5-multilib
- and many.

Теперь у Вас есть необходимые средства разработки для создания программного обеспечения в Linux.
Скрипт Mangi
Если Вам не нравится метод установки средств разработки выше, есть также скрипт под названием "сценарий манги" (mangi), доступный для легкой настройки среды разработки в DEB-системах, таких как Ubuntu, Linux Mint и других производных Ubuntu.
После свежей установки Ubuntu возьмите этот скрипт из репозитория GitHub, сделайте его исполняемым и начните установку всех необходимых инструментов и пакетов для настройки полной среды разработки. Вам не нужно устанавливать инструменты один за другим.
Этот скрипт установит следующие среды разработки и инструменты на вашу систему Linux:
- Node.js
- NVM
- NPM
- Nodemon
- MongoDB
- Forever
- git
- grunt
- bower
- vim
- Maven
- Loopback
- curl
- python
- jre/jdk
- gimp
- zip unzip and rar tools
- filezilla
- tlp
- erlang
- xpad sticky notes
- cpu checker
- kvm acceleration
- Calibre Ebook Reader (I often use it to read programming books
- Dict – Ubuntu Dictionary Database and Client (CLI based)
Сначала установите следующее:
Скачайте скрипт манги, используя команду:
Извлеките загруженный архив:
Вышеуказанная команда распакует zip-файл в папку под названием mangi-script-master в вашей текущей рабочей директории. Перейдите в каталог и сделайте скрипт исполняемым, используя следующие команды:
Наконец, запустите скрипт с помощью команды:

Пожалуйста, имейте в виду, что этот скрипт не полностью автоматизирован. Вам необходимо ответить на ряд вопросов "Да/Нет" для установки всех инструментов разработки.
Установка инструментов разработки в openSUSE/SUSE
Для настройки среды разработки в openSUSE и SUSE enterprise выполните следующие команды от имени root пользователя:
Проверка установки
Теперь проверим, были ли установлены средства разработки или нет. Для этого запустите:

Как видно из приведенного выше вывода, средства разработки были успешно установлены. Теперь можно начать разрабатывать свои приложения.
Настройка среды разработки
Скрипт под названием 'mangi' поможет вам настроить полное окружение в системах на базе Ubuntu.
Еще раз, после установки необходимых средств разработки проверить их можно с помощью одной из следующих команд:
Эти команды покажут путь установки и версию компилятора gcc.

Компиляция и запуск программ C, C++
Сначала посмотрим, как скомпилировать и запустить простую программу, написанную на языке Си.
Компиляция и запуск программ на C
Напишите свой код/программу в любимом редакторе CLI/GUI.
Я собираюсь написать свою программу на Си с помощью редактора nano.
Примечание. Вам необходимо использовать расширение .c для программ на Си или .cpp для программ на Си++.
Скопируйте/вставьте следующий код:

Нажмите Ctrl+O и Ctrl+X для сохранения и выхода из файла.
Чтобы скомпилировать программу, запустите:
Наконец, запустите программу с помощью команды:
Вы увидите вывод, как показано ниже:
Чтобы скомпилировать несколько исходных файлов (например, source1 и source2) в исполняемый файл, запустите:
Для разрешения предупреждений, необходима отладка символов на выходе:
Скомпилировать исходный код в инструкции ассемблера:
Скомпилировать исходный код без связывания:
Вышеприведенная команда создаст исполняемый файл под названием source.o.
Если ваша программа содержит математические функции:
За более подробной информацией обращайтесь к man-страницам (страницы руководства).
Компиляция и запуск программ на C++
Напишите вашу C++ программу в любом редакторе по вашему выбору и сохраните ее с расширением .cpp.
Пример простой C++ программы:
Чтобы скомпилировать эту программу на C++ в Linux, просто запустите:
Если ошибок не было, то можно запустить эту Си++ программу под Linux с помощью команды:
В качестве альтернативы мы можем скомпилировать приведенную выше программу на C++, используя команду "make", как показано ниже.
Вы заметили? Я не использовал расширение .cpp в вышеприведенной команде для компиляции программы. Нет необходимости использовать расширение для компиляции Си++ программ с помощью команды make.
Все действия в операционной системе выполняются с помощью программ, поэтому многим новичкам интересно не только использовать чужие программы, а писать свои. Многие хотят внести свой вклад в кодовую базу OpenSource.
Это обзорная статья про программирование под Linux. Мы рассмотрим какие языки используются чаще всего, рассмотрим основные понятия, а также возможности, разберем как написать простейшую программу на одном из самых популярных языков программирования, как ее вручную собрать и запустить.
1. На чем пишут программы?
Исторически сложилось так, что ядро Unix было написано на языке Си. Даже более того, этот язык был создан для написания ядра Unix. Поскольку ядро Linux было основано на ядре Minix (версии Unix), то оно тоже было написано на Си. Поэтому можно сказать, что основной язык программирования для Linux это Си и С++. Такая тенденция сохранялась на протяжении долгого времени.
Мы не будем рассматривать основы Си в этой статье. Си - сложный язык и вам понадобится прочитать как минимум одну книгу и много практиковаться чтобы его освоить. Мы рассмотрим как писать программы на Си в Linux, как их собирать и запускать.
2. Библиотеки
Естественно, что если вам необходимо вывести строку или изображение на экран, то вы не будете напрямую обращаться к видеокарте. Вы просто вызовете несколько функций, которые уже реализованы в системе и передадите им данные, которые нужно вывести на экран. Такие функции размещаются в библиотеках. Фактически, библиотеки - это наборы функций, которые используются другими программами. В них находится такой же код, как и в других программах, разница лишь в том, там необязательно присутствие функции инициализации.
Библиотеки делятся на два типа:
- Статические - они связываются с программой на этапе компиляции, они связываются и после этого все функции библиотеки доступны в программе как родные. Такие библиотеки имеют расширение .a;
- Динамические - такие библиотеки встречаются намного чаще, они загружены в оперативную память, и связываются с программной динамически. Когда программе нужна какая-либо библиотека, она просто вызывает ее по известному адресу в оперативной памяти. Это позволяет экономить память. Расширение этих библиотек - .so, которое походит от Shared Object.
Таким образом, для любой программы на Си нужно подключать библиотеки, и все программы используют какие-либо библиотеки. Также важно заметить, на каком языке бы вы не надумали писать, в конечном итоге все будет сведено к системным библиотекам Си. Например, вы пишите программу на Python, используете стандартные возможности этого языка, а сам интерпретатор уже является программой на Си/С++, которая использует системные библиотеки для доступа к основным возможностям. Поэтому важно понимать как работают программы на Си. Конечно, есть языки, вроде Go, которые сразу переводятся на ассемблер, но там используются принципы те же, что и здесь. К тому же системное программирование linux, в основном, это Си или С++.
3. Процесс сборки программы
Перед тем как мы перейдем к практике и создадим свою первую программу, нужно разобрать как происходит процесс сборки, из каких этапов он состоит.
Каждая серьезная программа состоит из множества файлов, это файлы исходников с расширением .c и заголовочные файлы с расширением .h. Такие заголовочные файлы содержат функции, которые импортируются в программу из библиотек или других файлов .с. Перед тем. как компилятор сможет собрать программу и подготовить ее к работе, ему нужно проверить действительно ли все функции реализованы, доступны ли все статические библиотеки и собрать ее в один файл. Поэтому, первым делом выполняется препроцессор, который собирает исходный файл, выполняются такие инструкции, как include для включения кода заголовочных файлов.
На следующем этапе к работе приступает компилятор, он выполняет все необходимые действия над кодом, разбирает синтаксические конструкции языка, переменные и преобразовывает все это в промежуточный код, а затем в код машинных команд, который мы можем потом посмотреть на языке ассемблера. Программа на этом этапе называется объектный модуль и она еще не готова к выполнению.
Далее к работе приступает компоновщик. Его задача связать объектный модуль со статическими библиотеками и другими объектными модулями. Для каждого исходного файла создается отдельный объектный модуль. Только теперь программа может быть запущена.
А теперь, давайте рассмотрим весь єтот процесс на практике с использованием компилятора GCC.
4. Как собрать программу
Для сборки программ в Linux используется два типа компиляторов, это Gcc и Clang. Пока что GCC более распространен, поэтому рассматривать мы будем именно его. Обычно, программа уже установлена в вашей системе, если же нет, вы можете выполнить для установки в Ubuntu:
sudo apt install gcc
Перед тем как мы перейдем к написанию и сборке программы, давайте рассмотрим синтаксис и опции компилятора:
$ gcc опции исходный_файл_1.с -o готовый_файл
С помощью опций мы говорим утилите что нужно сделать, какие библиотеки использовать, затем просто указываем исходные файлы программы. Давайте рассмотрим опции, которые будем сегодня использовать:
- -o - записать результат в файл для вывода;
- -c - создать объектный файл;
- -x - указать тип файла;
- -l - загрузить статическую библиотеку.
Собственно, это все самое основное, что нам понадобится. Теперь создадим нашу первую программу. Она будет выводить строку текста на экран и чтобы было интереснее, считать квадратный корень из числа 9. Вот исходный код:
int main() printf("losst.ru\n");
printf("Корень: %f\n", sqrt(9));
return 0;
>
Я специально добавил функцию корня чтобы показать как работать с библиотеками. Сначала нужно собрать объектный файл. Перейдите в папку с исходниками и выполните:
gcc -c program.c -o program.o

Это этап компиляции, если в программе нет ошибок, то он пройдет успешно. Если исходных файлов несколько, то такая команда выполняется для каждого из них. Далее выполняем линковку:
gcc -lm program.o -o program

Обратите внимание на опцию -l, с помощью нее мы указываем какие библиотеки нужно подключить, например, здесь мы подключаем библиотеку математических функций, иначе компоновщик просто не найдет где есть та или иная функция. Только после этого можно запустить программу на выполнение:

Конечно, все эти действия могут быть выполнены и с помощью различных графических сред, но выполняя все вручную, вы можете лучше понять как все работает. С помощью команды ldd вы можете посмотреть какие библиотеки использует наша программа:

Это две библиотеки загрузчика, стандартная libc и libm, которую мы подключили.
5. Автоматизация сборки
Когда мы рассматриваем программирование под Linux невозможно не отметить систему автоматизации сборки программ. Дело в том, что когда исходных файлов программы много, вы не будете вручную вводить команды для их компиляции. Можно записать их один раз, а затем использовать везде. Для этого существует утилита make и файлы Makefile. Этот файл состоит из целей и имеет такой синтаксис:
цель: зависимости
<Tab> команда
В качестве зависимости цели может быть файл или другая цель, основная цель - all, а команда выполняет необходимые действия по сборке. Например, для нашей программы Makefile может выглядеть вот так:
program: program.o
gcc -lm program.o -o program
program.o: program.c
gcc -c program.c -o program.o
Затем вам достаточно выполнить команду make для запуска компиляции, только не забудьте удалить предыдущие временные файлы и собранную программу:

Программа снова готова и вы можете ее запустить.
Выводы
Создание программ Linux очень интересно и увлекательно. Вы сами убедитесь в этом, когда немного освоитесь в этом деле. Сложно охватить все в такой небольшой статье, но мы рассмотрели самые основы и они должны дать вам базу. В этой статье мы рассмотрели основы программирования в linux, если у вас остались вопросы, спрашивайте в комментариях!
Курс программирования на Си под Linux:
Чтобы сразу начать программировать, создадим еще один клон известной программы "Hello World". Что делает эта программа, вы знаете. Откройте свой любимый текстовый редактор и наберите в нем следующий текст:
Я назвал свой файл hello.c. Вы можете назвать как угодно, сохранив суффикс .c. Содержимое файла hello.c - это исходный код программы ('program source', 'source code' или просто 'source'). А hello.c - это исходный файл программы ('source file'). Hello World - очень маленькая программа, исходный код которой помещается в одном файле. В "настоящих" программах, как правило, исходный код разносится по нескольким файлам. В больших программах исходных файлов может быть больше сотни.
Наш исходный код написан на языке программирования C. Языки программирования были придуманы для того, чтобы программист мог объяснить компьютеру, что делать. Но вот беда, компьютер не понимает ни одного языка программирования. У компьютера есть свой язык, который называют машинным кодом или исполняемым кодом ('executable code'). Написать Hello World в машинном коде можно, но серьезные программы на нем не пишутся. Исполняемый код не только сложный по своей сути, но и очень неудобный для человека. Программа, которую можно написать за один день на языке программирования будет писаться целый год в машинном коде. Потом программист сойдет с ума. Чтобы этого не случилось, был придуман компилятор ('compiler'), который переводит исходный код программы в исполняемый код. Процесс перевода исходного кода программы в исполняемый код называют компиляцией.
Вы наверняка догадались, что опция -o компилятора gcc указывает на то, каким должно быть имя выходного файла. Как вы позже узнаете, выходным файлом может быть не только бинарник. Если не указать опцию -o, то бинарнику, в нашем случае, будет присвоено имя a.out.
Осталось только запустить полученный бинарник. Для этого набираем в командной строке следующую команду:
Мы рассмотрели идеальный случай, когда программа написана без синтаксических ошибок. Попробуем намеренно испортить программу таким образом, чтобы она не отвечала канонам языка C. Для этого достаточно убрать точку с запятой в конце вызова функции printf(): Теперь, если попытаться откомпилировать программу, то компилятор выругается, указав нам на то, что он считает неправильным: В первой строке говорится, что в файле hello.c (у нас он единственный) в теле функции main() что-то произошло. Вторая строка сообщает, что именно произошло: седьмая строка файла hello.c вызвала ошибку (error). Далее идет расшифровка: синтаксическая ошибка перед закрывающейся фигурной скобкой.
Заглянув в файл hello.c мы с удивлением обнаружим, что нахулиганили мы не в седьмой, а в шестой строке. Дело в том, что компилятор обнаружил нелады только в седьмой строке, но написал 'before' (до), что означает "прокручивай назад".
Естественно, пока мы не исправим ошибку, ни о каком бинарнике не может идти и речи. Если мы удалим старый бинарник hello, доставшийся нам от прошлой компиляции, то увидим, что компиляция испорченного файла не даст никакого результата. Однако иногда компилятор может лишь "заподозрить" что-то неладное, потенциально опасное для нормального существования программы. Тогда вместо 'error' пишется 'warning' (предупреждение), и бинарник все-таки появляется на свет (если в другом месте нет явных ошибок). Не следует игнорировать предупреждения, за исключением тех случаев, когда вы на 100% знаете, что делаете.
Парадокс программирования заключается в том, что можно наделать кучу ошибок (уже не синтаксических, как в нашем случае, а смысловых) по всем правилам языка программирования. В таком случае компилятор выдает бинарник, который делает не то, что мы хотели. В таком случае программу приходится отлаживать. Отладка - это обычное дело при написании любой достаточно сложной программы. Не ошибается только тот, кто ничего не делает.
2.2. Мультифайловое программирование
Как я уже говорил, если исходный код сколько-нибудь серьезной программы уместить в одном файле, то такой код станет просто нечитаемым. К тому же если программа компилируется достаточно долго (особенно это относится к языку C++), то после исправления одной ошибки, нужно перекомпилировать весь код.
Куда лучше разбросать исходный код по нескольким файлам (осмысленно, по какому-нибудь критерию), и компилировать каждый такой файл отдельно. Как вы вскоре узнаете, это очень даже просто.
Давайте сначала разберемся, как из исходного файла получается бинарник. Подобно тому как гусеница не сразу превращается в бабочку, так и исходный файл не сразу превращается в бинарник. После компиляции создается объектный код. Это исполняемый код с некоторыми "вкраплениями", из-за которых объектный код еще не способен к выполнению. Сразу в голову приходит стиральная машина: вы ее только что купили и она стоит у вас дома в коробке. В таком состоянии она стирать не будет, но вы все равно рады, потому что осталось только вытащить из коробки и подключить.
Вернемся к объектному коду. Эти самые "вкрапления" (самое главное среди них - таблица символов) позволяют объектному коду "пристыковываться" к другому объектному коду. Такой фокус делает компоновщик (линковщик) - программа, которая объединяет объектный код, полученный из "разных мест", удаляет все лишнее и создает полноценный бинарник. Этот процесс называется компоновкой или линковкой.
Итак, чтобы откомпилировать мультифайловую программу, надо сначала добыть объектный код из каждого исходного файла в отдельности. Каждый такой код будет представлять собой объектный модуль. Каждый объектный модуль записывается в отдельный объектный файл. Затем объектные модули надо скомпоновать в один бинарник.
В Linux в качестве линковщика используется программа ld, обладающая приличным арсеналом опций. К счастью gcc самостоятельно вызывает компоновщик с нужными опциями, избавляя нас от "ручной" линковки.
Попробуем теперь, вооружившись запасом знаний, написать мультифайловый Hello World. Создадим первый файл с именем main.c: Теперь создадим еще один файл hello.c со следующим содержимым:
Здесь функция main() вызывает функцию print_hello(), находящуюся в другом файле. Функция print_hello() выводит на экран заветное приветствие. Теперь нужно получить два объектных файла. Опция -c компилятора gcc заставляет его отказаться от линковки после компиляции. Если не указывать опцию -o, то в имени объектного файла расширение .c будет заменено на .o (обычные объектные файлы имеют расширение .o): Итак, мы получили два объектных файла. Теперь их надо объединить в один бинарник: Компилятор "увидел", что вместо исходных файлов (с расширением .c) ему подбросили объектные файлы (с расширением .o) и отреагировал согласно ситуации: вызвал линковщик с нужными опциями.
Давайте разберемся, что же все-таки произошло. В этом нам поможет утилита nm. Я уже оговорился, что объектные файлы содержат таблицу символов. Утилита nm как раз позволяет посмотреть эту таблицу в читаемом виде. Те, кто пробовал программировать на ассемблере знают, что в исполняемом файле буквально все (функции, переменные) стоит на своей позиции: стоит только вставить или убрать из программы один байт, как программа тут же превратиться в груду мусора из-за смещенных позиций (адресов). У объектных файлов особая роль: они хранят в таблице символов имена некоторых позиций (глобально объявленных функций, например). В процессе линковки происходит стыковка имен и пересчет позиций, что позволяет нескольким объектным файлам объединиться в один бинарник. Если вызвать nm для файла hello.o, то увидим следующую картину: О смысловой нагрузке нулей и литер U,T мы будем говорить при изучении библиотек. Сейчас же важным является то, что в объектном файле сохранилась информация об использованных именах. Своя информация есть и в файле main.o: Таблицы символов объектных файлов содержат общее имя print_hello. В процессе линковки высчитываются и подставляются в нужные места адреса, соответствующие именам из таблицы. Вот и весь секрет.
2.3. Автоматическая сборка
В предыдущем разделе для создания бинарника из двух исходных файлов нам пришлось набрать три команды. Если бы программу пришлось отлаживать, то каждый раз надо было бы вводить одни и те же три команды. Казалось бы выход есть: написать сценарий оболочки. Но давайте подумаем, какие в этом случае могут быть недостатки. Во-первых, каждый раз сценарий будет компилировать все файлы проекта, даже если мы исправили только один из них. В нашем случае это не страшно. Но если речь идет о десятках файлов! Во-вторых, сценарий "намертво" привязан к конкретной оболочке. Программа тут же становится менее переносимой. И, наконец, простому скрипту не хватает функциональности (задание аргументов сборки и т. п.), а хороший скрипт (с многофункциональными прибамбасами) плохо модернизируется.
Выход из сложившейся ситуации есть. Это утилита make, которая работает со своими собственными сценариями. Сценарий записывается в файле с именем Makefile и помещается в репозиторий (рабочий каталог) проекта. Сценарии утилиты make просты и многофункциональны, а формат Makefile используется повсеместно (и не только на Unix-системах). Дошло до того, что стали создавать программы, генерирующие Makefile'ы. Самый яркий пример - набор утилит GNU Autotools. Самое главное преимущество make - это "интеллектуальный" способ рекомпиляции: в процессе отладки make компилирует только измененные файлы.
То, что выполняет утилита make, называется сборкой проекта, а сама утилита make относится к разряду сборщиков.
Любой Makefile состоит из трех элементов: комментарии, макроопределения и целевые связки (или просто связки). В свою очередь связки состоят тоже из трех элементов: цель, зависимости и правила.
Макроопределения позволяют назначить имя практически любой строке, а затем подставлять это имя в любое место сценария, где должна использоваться данная строка. Макросы Makefile схожи с макроконстантами языка C.
Связки определяют: 1) что нужно сделать (цель); 2) что для этого нужно (зависимости); 3) как это сделать (правила). В качестве цели выступает имя или макроконстанта. Зависимости - это список файлов и целей, разделенных пробелом. Правила - это команды передаваемые оболочке.
Теперь рассмотрим пример. Попробуем составить сценарий сборки для рассмотренного в предыдущем разделе мультифайлового проекта Hello World. Создайте файл с именем Makefile: Обратите внимание, что в каждой строке перед вызовом gcc, а также в строке перед вызовом rm стоят табуляции. Как вы уже догадались, эти строки являются правилами. Формат Makefile требует, чтобы каждое правило начиналось с табуляции. Теперь рассмотрим все по порядку.
Makefile может начинаться как с заглавной так и со строчной буквы. Но рекомендуется все-таки начинать с заглавной, чтобы он не перемешивался с другими файлами проекта, а стоял "в списке первых".
Первая связка имеет цель hello. Цель отделяется от списка зависимостей двоеточием. Список зависимостей отделяется от правил символом новой строки. А каждое правило начинается на новой строке с символа табуляции. В нашем случае каждая связка содержит по одному правилу. В списке зависимостей перечисляются через пробел вещи, необходимые для выполнения правила. В первом случае, чтобы скомпоновать бинарник, нужно иметь два объектных файла, поэтому они оказываются в списке зависимостей. Изначально объектные файлы отсутствуют, поэтому требуется создать целевые связки для их получения. Итак, чтобы получить main.o, нужно откомпилировать main.c. Таким образом файл main.c появляется в списке зависимостей (он там единственный). Аналогичная ситуация с hello.o. Файлы main.c и hello.c изначально существуют (мы их сами создали), поэтому никаких связок для их создания не требуется.
Особую роль играет целевая связка clean с пустым списком зависимостей. Эта связка очищает проект от всех автоматически созданных файлов. В нашем случае удаляются файлы main.o, hello.o и hello. Очистка проекта бывает нужна в нескольких случаях: 1) для очистки готового проекта от всего лишнего; 2) для пересборки проекта (когда в проект добавляются новые файлы или когда изменяется сам Makefile; 3) в любых других случаях, когда требуется полная пересборка (напрмиер, для измерения времени полной сборки).
Теперь осталось запустить сценарий. Формат запуска утилиты make следующий: Опции make нам пока не нужны. Если вызвать make без указания целей, то будет выполнена первая попавшаяся связка (со всеми зависимостями) и сборка завершится. Нам это и требуется: В процессе сборки утилита make пишет все выполняемые правила. Проект собран, все работает.
Теперь давайте немного модернизируем наш проект. Добавим одну строку в файл hello.c: Теперь повторим сборку: Утилита make "пронюхала", что был изменен только hello.c, то есть компилировать нужно только его. Файл main.o остался без изменений. Теперь давайте очистим проект, оставив одни исходники: В данном случае мы указали цель непосредственно в командной строке. Так как целевая связка clean содержит пустой список зависимостей, то выполняется только одно правило. Не забывайте "чистить" проект каждый раз, когда изменяется список исходных файлов или когда изменяется сам Makefile.
2.4. Модель КИС
Любая программа имеет свой репозиторий - рабочий каталог, в котором находятся исходники, сценарии сборки (Makefile) и прочие файлы, относящиеся к проекту. Репозиторий рассмотренного нами проекта мультифайлового Hello World изначально состоит из файлов main.c, hello.c и, собственно, Makefile. После сборки репозиторий дополняется файлами main.o, hello.o и hello. Практика показывает, что правильная организация исходного кода в репозитории не только упрощает модернизацию и отладку, но и предотвращает возможность появления многих ошибок.
Модель КИС (Клиент-Интерфейс-Сервер) - это элегантная концепция распределения исходного кода в репозитории, в рамках которой все исходники можно поделить на клиенты, интерфейсы и серверы.
Итак, сервер предоставляет услуги. В нашем случае это могут быть функции, структуры, перечисления, константы, глобальные переменные и проч. В языке C++ это чаще всего классы или иерархии классов. Любой желающий (клиент) может воспользоваться предоставленными услугами, то есть вызвать функцию со своими фактическими параметрами, создать экземпляр структуры, воспользоваться константой и т. п. В C++, как правило, клиент использует класс как тип данных и использует его члены.
Часто бывает, что клиент сам становится сервером, точнее начинает играть роль промежуточного сервера. Хороший пример - наш мультифайловый Hello World. Здесь функция print_hello() (клиент) пользуется услугами стандартной библиотеки языка C (сервер), вызывая функцию printf(). Однако в дальнейшем функция print_hello() сама становится сервером, предоставляя свои услуги функции main(). В языке C++ довольно часто клиент создает производный класс, который наследует некоторые механизмы базового класса сервера. Таким образом клиент сам становится сервером, предоставляя услуги своего производного класса.
Клиент с сервером должны "понимать" друг друга, иначе взаимодействие невозможно. Интерфейс (протокол) - это условный набор правил, согласно которым взаимодействуют клиент и сервер. В нашем случае (мультифайловый Hello World) интерфейсом (протоколом) является общее имя в таблице символов двух объектных файлов. Такой способ взаимодействия может привести к неприятным последствиям. Клиент (функция main()) не знает ничего, кроме имени функции print_hello() и, наугад вызывает ее без аргументов и без присваивания. Иначе говоря, клиент не знает до конца правил игры. В нашем случае прототип функции print_hello() неизвестен.
Давайте начистоту, мало кто использует отладчик GDB на Linux в консольном варианте. Но что, если добавить в него красивый интерфейс? Под катом вы найдёте пошаговую инструкцию отладки кода С/С++ на Linux в Visual Studio Code.

Передаю слово автору.
Относительно недавно я переехал на Linux. Разрабатывать на Windows, конечно, удобнее и приятнее, но и здесь я нашел эффективный способ легко и быстро отлаживать код на С/С++, не прибегая к таким методам как «printf-стайл отладки» и так далее.
Итак приступим. Писать в sublime (или gedit/kate/emacs ), а запускать в терминале — так себе решение, ошибку при работе с динамическим распределением памяти вряд ли найдёшь с первого раза. А если проект трудоёмкий? У меня есть более удобное решение. Да и ещё поддержка Git в редакторе, одни плюсы.
Сегодня мы поговорим про Visual Studio Code.
Установка
Ubuntu/Debian
- Качаем версию пакета VS Code с расширением .deb
- Переходим в папку, куда скачался пакет (cd
/Загрузки или cd
Расширения для С/С++
Чтобы VS Code полностью сопровождал нас при работе с файлами С/С++, нужно установить расширение «cpptools». Также полезным будет поставить один из наборов сниппетов.

Настоятельно рекомендую включить автосохранение редактируемых файлов, это поможет нам в дальнейшем.

Идём дальше. Открываем любую папку (новую или нет, неважно).

У меня в этой папке уже есть пара файлов для работы с C/C++. Вы можете скопировать одну из своих наработок сюда или создать новый файл.
Осталось всего ничего. Настроить компиляцию в одну клавишу и научиться отлаживать без printf .
Шаг 1. Открываем файл .c/.cpp, который (обязательно) лежит в вашей папке.
Шаг 2. Нажимаем Ctrl+Shift+B. VS Code вам мягко намекнет, что он не знает как собирать ваш проект.

Шаг 3. Поэтому дальше настраиваем задачу сборки: выбираем «Настроить задачу сборки» -> «Others».
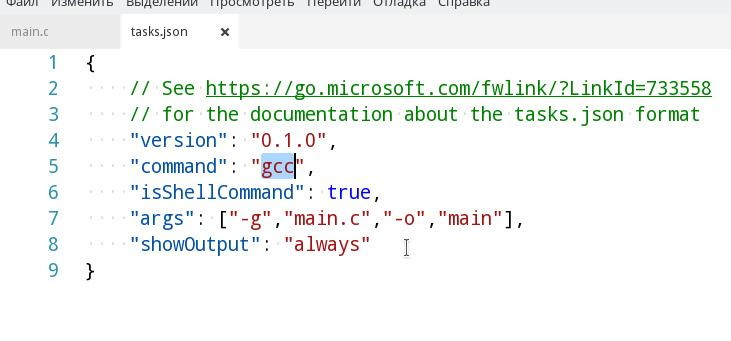
Шаг 4. Прописываем конфигурацию в соответствии с образцом. По сути мы пишем скрипт для консоли, так что всем кто имел дело с ней будет понятно дальнейшее. Прошу заметить, что для сборки исходников в системе должен стоять сам компилятор (gcc или другой, отличаться будет только значение поля command ). Поэтому для компиляции .cpp, понадобится в поле command указать g++ или c++ , а для .c gcc .
Шаг 5. В args прописываем аргументы, которые будут переданы на вход вашему компилятору. Напоминаю, что порядок должен быть примерно таким: -g, <имя файла> .
Внимание: Если в вашей программе используется несколько файлов с исходным кодом, то укажите их в разных аргументах через запятую. Также обязательным является ключ -g (а лучше даже -g3 ). Иначе вы не сможете отладить программу.
Если в проекте для сборки вы используете makefile , то в поле command введите make , а в качестве аргумента передайте директиву для сборки.
Шаг 6. Далее возвращаемся обратно к нашему исходнику. И нажимаем F5 и выбираем C++.

Шаг 7. Осталось только написать путь к файлу программы. По умолчанию это $/a.out , но я в своем файле сборки указал флаг -o и переименовал файл скомпилированной программы, поэтому у меня путь до программы: $/main .

Шаг 8. Всё, больше нам не нужно ничего для начала использования всех благ VS Code. Переходим к основному проекту.
Отладка
Для начала скомпилируем программу (нет, нет, убери терминал, теперь это делается по нажатию Ctrl+Shift+B).

Как вы видите в проводнике появился main , значит все в порядке и сборка прошла без ошибок. У меня не слишком большая программа, но выполняется она моментально. Одним словом, провал чистой воды, потому что отладка идет в отдельном терминале, который закрывается после того, как программа дошла в main() до "return 0;" .

Пришло время для брейкпоинтов. Выберем строчку с "return 0;" и нажимаем F9.
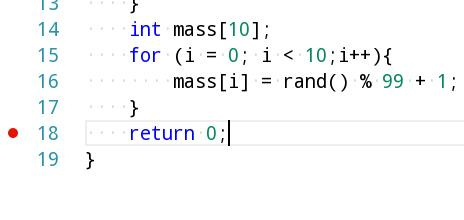
Строчка, помеченная красной точкой слева — место, где остановится программа, при выполнении.
Далее нажимаем F5.

Как я и сказал, программа остановила выполнение. Обратите внимание на окно с локальными переменными.
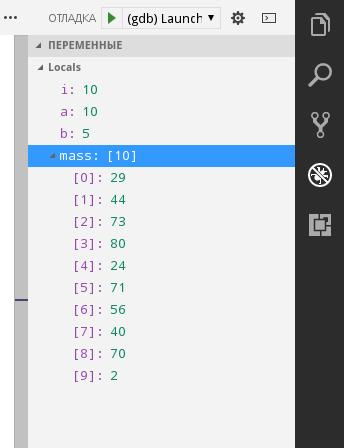
Удобненько. Также при остановке можно наводить мышкой на переменные и структуры в коде и смотреть их значения.

Также, если на каком-то этапе выполнения вам нужно посмотреть пошаговое выполнение той или иной операции, например в цикле, то поставьте брейкпоинт перед ней и нажмите F10 для выполнения текущей строчки без захода в подпрограмму и F11 с заходом.
Также есть случаи, когда считать выражение очень муторно вручную, но для отладки вам нужно знать, например, значение суммы трех элементов массива, или значение большого логического выражения. Для этого существуют контрольные значения. Все это и многое другое могут показать вам Контрольные значения (или «watch»).

- Для каждой папки вам нужно отдельно настроить файлы сборки и путь к программе.
- VS Code не решит ваших проблем, но поможет быстрее с ними разобраться. Причем в разы.
- После каждого изменения программы, ее нужно компилировать заново, нажимая Ctrl+Shift+B.
Об авторе
Читайте также: