
Как установить greenplum на windows
Обновлено: 04.07.2024
База данных Greenplum представляет собой сервер базы данных с массивной параллельной обработкой (MPP) с архитектурой, специально разработанной для управления крупномасштабными аналитическими хранилищами данных и рабочими нагрузками бизнес-аналитики. MPP относится к системам с двумя или более процессорами, которые взаимодействуют для выполнения операции, причем каждый процессор имеет собственную память, операционную систему и диски. Greenplum использует эту высокопроизводительную системную архитектуру для распределения нагрузки на много терабайтные хранилища данных и может использовать все ресурсы системы параллельно для обработки запроса.
Содержание
Основные особенности
База данных Greenplum основана на технологии PostgreSQL с открытым исходным кодом. По сути, это несколько экземпляров базы данных PostgreSQL, которые действуют вместе как одна сплоченная система управления базами данных (СУБД). Greenplum (GP) – реляционная СУБД, имеющая массово-параллельную (massive parallel processing) архитектуру без разделения ресурсов (Shared Nothing).
Связь с PostgreSQL
Внутренние элементы PostgreSQL были модифицированы или дополнены для поддержки параллельной структуры базы данных Greenplum. Например, системный каталог, оптимизатор, исполнитель запросов и компоненты диспетчера транзакций были изменены и расширены, чтобы иметь возможность выполнять запросы одновременно во всех параллельных экземплярах базы данных PostgreSQL. Соединение Greenplum (сетевой уровень) обеспечивает связь между отдельными экземплярами PostgreSQL и позволяет системе вести себя как одна логическая база данных.
Массовый параллелизм
Архитектура базы данных Greenplum обеспечивает автоматическое распараллеливание всех данных и запросов в архитектуре с масштабируемым общим доступом. [Источник 1]
Дополнительное машинное обучение
Предоставлена Apache MADlib, библиотека для масштабируемой аналитики в базе данных, расширяющей возможности базы данных через пользовательские функции.
Компания
Компания Greenplum была основана в сентябре 2003 года Скоттом Ярой и Люком Лонерганом. Это было слияние двух небольших компаний: Metapa (основанной в августе 2000 года недалеко от Лос-Анджелеса) и Didera в Фэрфаксе, штат Вирджиния.
Среди инвесторов были SoundView Ventures, Hudson Ventures и Royal Wulff Ventures. В результате слияния было объявлено о финансировании на общую сумму 20 миллионов долларов США. Greenplum, базирующаяся в Сан-Матео, штат Калифорния, в апреле 2005 года выпустила программное обеспечение для системы управления базами данных на основе PostgreSQL, назвав его Bizgres. Раунды венчурного капитала в размере около 15 миллионов долларов США были инвестированы в марте 2006 года и феврале 2007 года.
В июле 2006 года было объявлено о партнерстве с Sun Microsystems. Sun, которая также приобрела MySQL AB, приняла участие в раунде инвестиций в размере 27 миллионов долларов США в январе 2009 года, который возглавлял Meritech Capital Partners. Проект Bizgres включал в себя несколько других участников, и его поддерживали примерно в 2008 году, когда продукт также назывался просто «Greenplum». Sun Fire X4500 был эталонной архитектурой и использовался большинством пользователей, пока в то время не был осуществлен переход на Linux. Greenplum была приобретена корпорацией EMC в июле 2010 года и стала основой подразделения программного обеспечения EMC для больших данных. Хотя EMC не раскрывает стоимость, она оценивается в 300 миллионов долларов США. На момент приобретения продуктами Greenplum были база данных Greenplum, Chorus (инструмент управления) и Data Science Labs. У Greenplum были клиенты на вертикальных рынках, включая eBay. Он стал частью Pivotal Software в 2012 году.
Вариант использования Apache Hadoop для хранения данных в файловой системе Hadoop под названием Hawq был анонсирован в 2013 году. В 2015 году были объявлены проекты с открытым исходным кодом GreenplumDB и Hawq.
Архитектура
Как и любая распределенная Big Data система, кластер Greenplum работает по определенным принципам взаимодействия узлов. Эта MPP-СУБД представляет модифицированную версию популярной архитектуры master-slave, где для повышения надежности добавлен резервный главный сервер. Таким образом, между компонентами кластер Greenplum существуют следующие отношения:
- Master instance (он же просто «мастер») – инстанс Postgres. Мастер - это точка входа в систему базы данных Greenplum. Это экземпляр базы данных, к которому клиенты подключаются и отправляют SQL-запросы. Мастер координирует свою работу с другими экземплярами базы данных в системе, называемыми сегментами, которые хранят и обрабатывают данные. Конечные пользователи базы данных Greenplum взаимодействуют с базой данных Greenplum (через мастера), как и с обычной базой данных PostgreSQL. Они подключаются к базе данных с помощью клиентских программ, таких как psql или через интерфейсы прикладного программирования (API), такие как JDBC или ODBC. Мастер - это место, где находится глобальный системный каталог. Глобальный системный каталог представляет собой набор системных таблиц, содержащих метаданные о самой базе данных Greenplum. Мастер не содержит никаких пользовательских данных; данные хранятся только на сегментах. Мастер аутентифицирует клиентские соединения, обрабатывает входящие команды SQL, распределяет рабочие нагрузки между сегментами, координирует результаты, возвращаемые каждым сегментом, и представляет конечные результаты клиентской программе.

- Master host («сервер-мастер») – сервер, на котором работает Master instance.
- Secondary master instance — инстанс Postgres, являющийся резервным мастером, включается в работу в случае недоступности основного мастера (переключение происходит вручную);
- Primary segment instance («сегмент») — инстанс Postgres. Ячейки сегментов базы данных Greenplum являются независимыми базами данных PostgreSQL, каждая из которых хранит часть данных, выполняет с ними операции и отдают результаты мастеру (в общем случае). Когда пользователь подключается к базе данных с помощью мастера Greenplum и выдает запрос, в каждой базе данных сегмента создаются процессы для обработки работы этого запроса. Пользовательские таблицы и их индексы распределяются по доступным сегментам в системе базы данных Greenplum. Каждый сегмент содержит свою часть данных. Процессы сервера базы данных, обслуживающие данные сегмента, выполняются в соответствующих экземплярах сегмента. Пользователи взаимодействуют с сегментами Greenplum через мастера.
- Mirror segment instance («зеркало») — инстанс Postgres, являющийся зеркалом одного из primary сегментов, автоматически принимает на себя роль primary в случае падения оного(см. Рисунок 1).
GP поддерживает только 1-to-1 репликацию сегментов: для каждого из primary может быть только одно зеркало.
- Segment host («сервер-сегмент») – Сегменты выполняются на серверах, называемых сегментами хостов. Хост сегмент обычно держит от двух до восьми сегментов Greenplum, в зависимости от ядер процессора, оперативной памяти, хранилища, сетевых интерфейсов и рабочих нагрузок. Ожидается, что хост сегменты будут идентично настроены. Ключом к достижению наилучшей производительности в базе данных Greenplum является равномерное распределение данных и рабочих нагрузок по большому числу сегментов, с одинаковыми мощностями, чтобы все сегменты одновременно работали над задачей и выполняли свою работу одновременно. [Источник 2]
Версия Greenplum 5
В сентябре 2017 года была выпущена версия 5 базы данных Greenplum. Версия 5 включает в себя первую итерацию стратегии проекта Greenplum по слиянию более поздних версий PostgreSQL с Greenplum и основана на PostgreSQL версии 8.3 по сравнению с предыдущей версией 8.2. В версии 5 также представлена общая доступность оптимизатора GPORCA для оптимизации SQL на основе затрат, предназначенной для больших данных.
Версия Greenplum 6
В сентябре 2019 года была выпущена версия 6 базы данных Greenplum. Версия 6 основана на PostgreSQL версии 9.4 и обеспечивает значительное повышение производительности OLTP. Greenplum 6 был рассмотрен в СМИ несколькими источниками и упоминается за его выравнивание с открытым исходным кодом Postgres и за его производительность OLTP.
Установка
Следующий пример будет для установки на CentOs 7.
Подготовка к установке
Установка nano и исправление проблем с сетью
Этот раздел не обязателен, если Вы разумист не по годам.
Для выполнения следующих действий, будем использовать текстовой редактор nano. Можно использовать vi, но nano удобнее. Если сборка его не содержит, установим его следующей командой:
При этом может возникнуть следующая ошибка:
Выходит ошибка Сеть недоступна или Network is unreachable, делаем следующие действия:
- С помощью команды cd переходим в директорию /etc/sysconfig/network-scripts/
- Используя команду ls находим файл, с названием наиболее похожим на ifcfg-eth0. В моем случае это ifcfg-enp0s3
- Необходимо, чтобы в этом файле было прописано ONBOOT = “yes”
- Для редактирования будем использовать редактор VI, вводим следующую команду:
- Для редактирования с помощью VI нужно знать следующие команды:
Для выхода из файла без сохранения:
Для выхода из файла, сохранив изменения:
Для выхода из файла с сохранением, одной командой:
Для перехода в режим ввода нужно нажать команды типа:
- После внесения изменения, сохранения его и выхода из редактора, нужно перезапустить сеть следующей командой:
- Проверяем работоспособность сети с помощью команды:
- Если пингуется бесконечно, то выйти из этого состояния можно комбинацией клавиш "Crtl+C"
- Теперь можем установить nano:
- Не забываем пару раз нажать клавишу y, когда это потребуется
Настройка Linux перед установкой GreenPlum DB
Перед установкой GreenPlum DB необходима конфигурация некоторых параметров системы:
Также нужно заглянуть в каталог /etc/security/limits.d/ в файле x0-nproc.conf могут быть значения параметров, отличные от установленных, и тут у них больший приоритет. Меняем их на нужные нам и в x0-nproc.conf.
- У каждого диска параметр read-ahead должен быть равен 16384
- Узнаем название диска, например
После чего увидим следующее(см. Рисунок 2):

Где (на Рис. 2) sda1 - нужное нам название.
- Устанавливаем значение read-ahead (blockdev):
- Чтобы узнать значение этого параметра вводим команду:
- Для GreenplumDB рекомендовано использовать планировщик ввода/вывода (I/O Scheduler) под названием deadline. Для CentOs 7.x этот параметр можно установить с помощью утилиты grubby, запущенной из под рута:
После чего необходимо перезапустить систему.
- Проверить настройки ядра можно с помощью команды
- Отключаем Transparent Huge Pages (THP), аналогично используем grubby:
После чего требуется перезагрузка Проверить состояние параметра THP можно следующей командой:
Ответ должен быть never.
- Также настройка RemoveIPC=yes убирает IPC соединения, когда не системный пользователь разлогинивается. Это мешает работе GreenplumDB. Чтобы этого не случалось, в файле /etc/systemd/logind.conf необходимо прописать RemoveIPC=no.
Установка GreenplumDB

После чего находим нужную нам версию GreenplumDB и получаем ссылку для скачивания:

Далее формируем wget запрос следующего вида
Во время установки нужно будет согласиться с лицензионным соглашением и указать путь установки.
Работа с БД
Добавление пользователей и ролей
База данных Greenplum управляет доступом к базе данных с использованием ролей. Первоначально существует одна роль суперпользователя - роль, связанная с пользователем ОС, который инициализировал экземпляр базы данных, обычно gpadmin. Этот пользователь владеет всеми файлами базы данных Greenplum и операциями ОС, поэтому важно оставить роль gpadmin только для системных задач.
Создание пользователя с помощью команды createuser
- Необходимо выполнить вход как gpadmin.
- Ввести следующую команду:
Где user1 - имя нового пользователя.
Создание пользователя с помощью команды CREATE USER
- Подключаемся к базе данных template1 как gpadmin:
- Создаем пользователя с именем user2 с паролем 'wkvles':
- Выводим список ролей:
Создание группы и добавление к ней пользователей
- Пока подключены к базе данных template1 вводим следующие sql команды:
- Теперь при выводе списка ролей, можно увидеть принадлежность пользователей user1 и user2 к группе users
- Выходим из базы данных:
Создание и подготовка базы данных
Создайте новую базу данных с помощью команды CREATE DATABASE SQL в psql или командой утилиты createdb в терминале. Новая база данных является копией базы данных template1, если вы не указали другой шаблон. Чтобы использовать команду CREATE DATABASE, вы должны быть подключены к базе данных. С недавно установленной базой данных Greenplum вы можете подключиться к базе данных template1, чтобы создать свою первую пользовательскую базу данных.
Создание базы данных
- Введем следующую команду для уничтожения уже существующей базы данных:
Где tutorial - название базы данных
- Создадим базу данных tutorial с дефолтными параметрами:
- Убедимся, что база данных была создана с помощью команды psql -l:
- Подключаемся к базе данных tutorial как пользователь user1
Предоставление прав пользователям базы данных
В работающей базе данных необходимо предоставить пользователям минимальные разрешения для выполнения своей работы. Например, пользователю может потребоваться разрешение SELECT для просмотра данных таблицы, но не UPDATE, INSERT или DELETE для изменения данных.

Ванильный Greenplum устанавливается через ручное выполнение пошаговых инструкций и выставления параметров множества настроек. Поскольку это СУБД с массивно-параллельной архитектурой, число серверов в кластере может доходить до 200. В базовом сценарии это влечёт за собой огромные объёмы работ в ручном режиме.
Так, на каждом сервере необходимо создать пользователя, настроить ключи авторизации по SSH, настроить параметры операционной системы, установить необходимые пакеты и выставить оптимальные для работы СУБД параметры. Крайне важно, чтобы эти настройки были одинаковыми на всех серверах. Конечно, есть специальные системы, которые позволяют управлять сразу группой серверов, но для их запуска и поддержки всё равно потребуется специалист с соответствующими навыками и знаниями.
По сути, Greenplum не существует в виде готового дистрибутива. Есть только официальная документация по ручной установке и конфигурированию всех необходимых компонентов. В своём продукте мы пошли другим путём: заменили все ручные операции по установке загрузкой бандлов через веб-интерфейс. Знаний о том, какие настройки ядра были изменены или как были подмонтированы диски, не потребуется. Всё это (и многое другое) зашито внутри бандла в виде автоматизированного сценария на основе ansible-скриптов.
Полную автоматизацию этих процессов обеспечивает Arenadata Cluster Manager (ADCM) — полностью нами разработанный продукт с открытым исходным кодом. Если кратко — это универсальный оркестратор гибридного ИТ-ландшафта, благодаря которому в автоматическом режиме происходят установка, настройка и обновление кластеров, настройки операционной системы, сервисов, сети и монтирование дисков. С помощью ADCM можно разворачивать data-сервисы как в облаке, так и on-premise, а также она может служить в качестве PaaS-сервисов. Подробнее об этом можно почитать в разделе про ADCM.
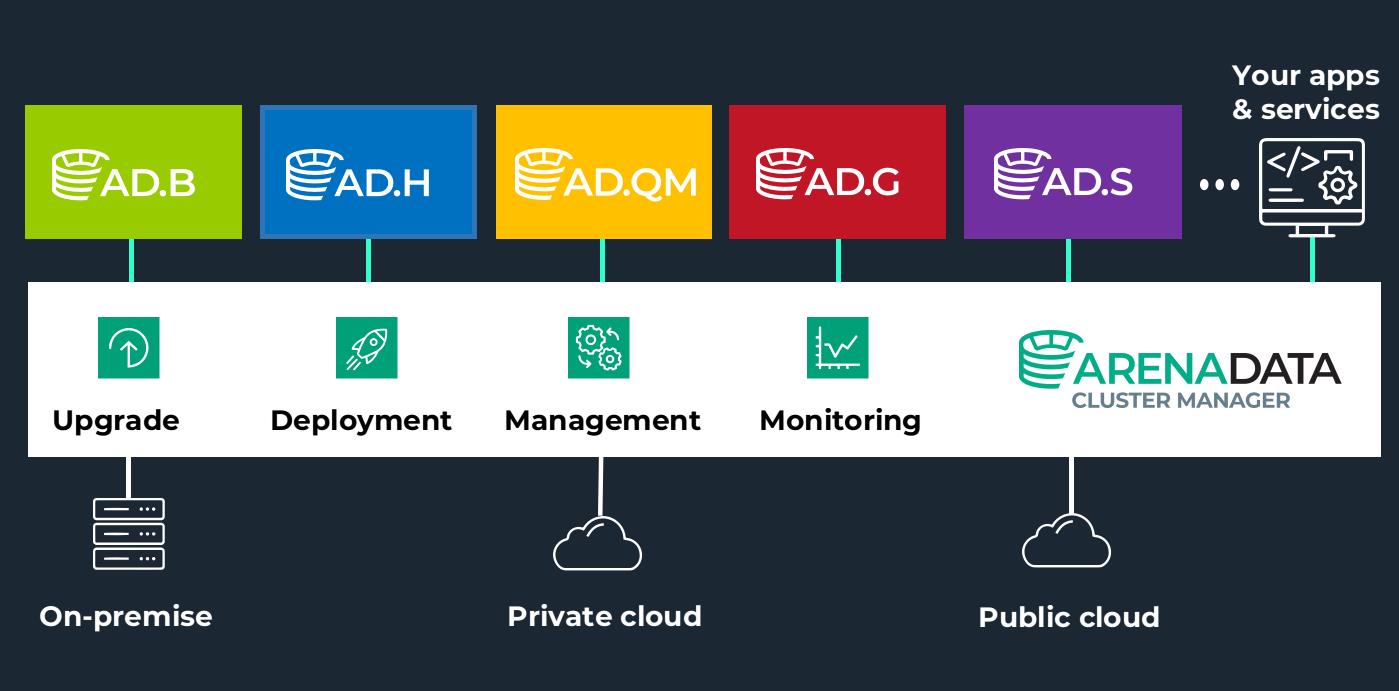
Базовый алгоритм развёртывания ADB
Если мы говорим про окружение разработки или тестовое окружение, то можно использовать любую виртуальную инфраструктуру. Это может быть приватное облако на VMware либо любые публичные облака. Для начала необходимо установить и настроить сервер ADCM. На нашем сайте есть подробная инструкция по его установке.
- Разворачиваем сервер с совместимой операционной системой и подключаемся к нему по SSH.
- Устанавливаем на него ADCM в виде Docker-контейнера.
- Запускаем контейнер и коннектимся к ADCM через web-интерфейс.
- Загрузить необходимые бандлы.
- Создать кластер мониторинга (опционально):
- загрузить бандл мониторинга;
- создать хосты для кластера мониторинга;
- создать экземпляр кластера мониторинга и установить его.
- Создать хосты для кластера ADB.
- Создать экземпляр кластера ADB и установить его.
Где скачать бандлы?
Инфраструктурные бандлы, которые помогают создать хосты и развернуть кластер мониторинга, доступны в разделе Arenadata ADCM Infrastructure Bundles, здесь. Например, для установки кластера на виртуальные или физические сервера, которые уже есть в наличии и на которых уже развёрнута операционная система, потребуется бандл SSH Common Bundle, а для кластера мониторинга нужен бандл Monitoring Bundle.
В инструкции указан пример с использованием бандла Datafort. Что делать, если у нас свои сервера и нужно развернуть кластер на них?
- Загружаем бандл в ADCM, как указано в инструкции.
- Переходим на вкладку HOSTPROVIDERS, нажимаем на Create provider. Выбираем из списка бандлов SSH Common, даём имя и нажимаем Create. Провайдер готов.
- Переходим на вкладку Host и нажимаем Create host. Выбираем провайдер SSH и указываем имя сервера. Нажимаем Create.
Как только хост будет создан, необходимо на него кликнуть мышкой и заполнить параметры подключения к серверу:- Username — пользователь, из-под которого будет происходить подключение к серверу, у него должны быть права на установку пакетов;
- Password или SSH private key — пароль или приватный SSH-ключ для подключения;
- Hostname — имя или IP-адрес сервера;
- Port — порт для подключения SSH;
- SSH args — параметры подключения по SSH;
- Ansible become — есть ли у пользователя sudo (требуется, если не используется root);
- Ansible become password — пароль, если требует команда sudo.
- Для проверки доступности хоста нужно кликнуть на Run Action в правом верхнем углу и выбрать Check Connection. Или можно установить status checker (кнопка Install statuschecker), который с определённой периодичностью проверяет доступность хоста и отображает его статус в консоли ADCM.
В инструкции указано, что можно создать кластер мониторинга. Как это сделать?
- Создаём хост в ADCM, на который будут установлены сервисы мониторинга (см. выше в примере с SSH-бандлом).
- Далее переходим на вкладку Clusters и кликаем на Create Cluster. В появившемся окне, в поле Bundle нужно выбрать Monitoring, в поле Cluster name указать Monitoring и нажать Save:
Что делать если во время установки произошла ошибка?
Для этого есть специальная вкладка JOBS, где можно посмотреть все статусы выполнения задач, а также их логи. Достаточно кликнуть на задачу и перейти на вкладку ansible [stdout]:
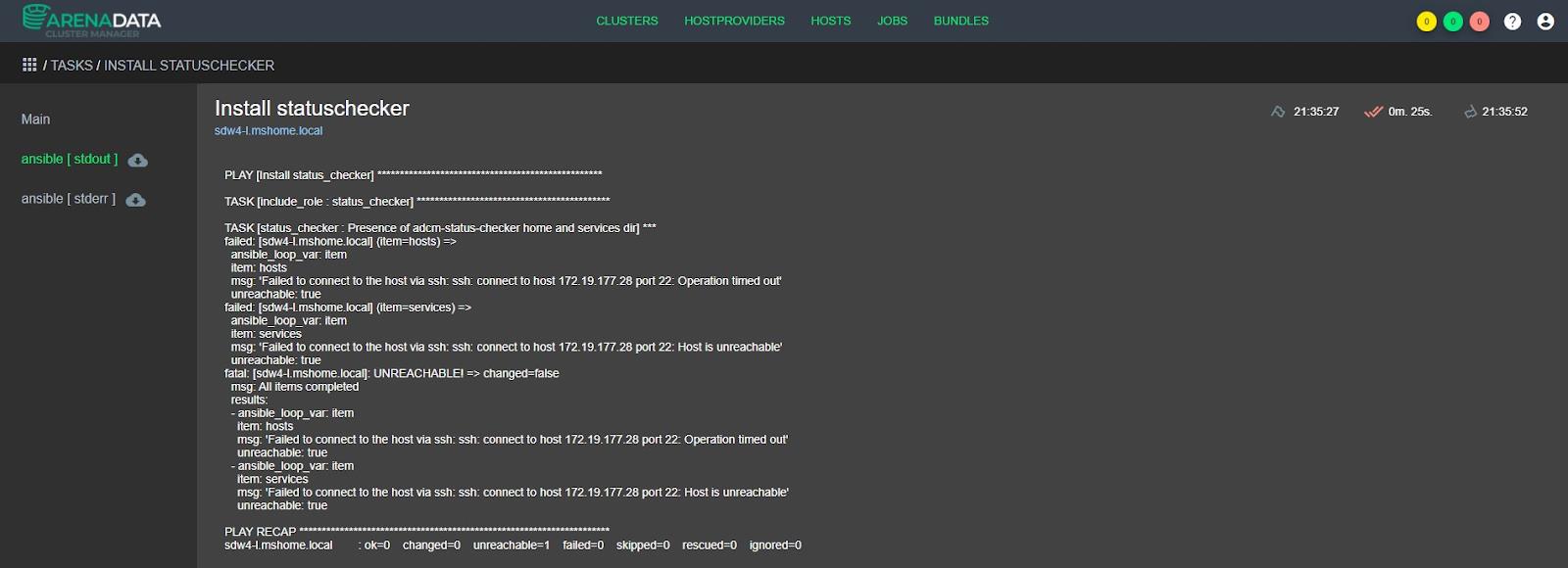
Если в выводе не совсем понятна причина ошибки, то можно повысить уровень логирования. Для этого достаточно поставить галку Verbose во время запуска любой задачи:
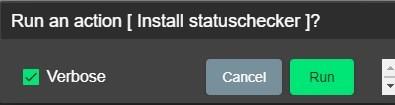
После этого, если вновь заглянуть в ansible [stdout] «упавшей» задачи, можно увидеть дополнительную информацию, которая поможет прояснить детали ошибки.
Как настроить бандлы?
Точечной ручной настройки для запуска сервиса ADB не требуется, но она возможна. Например, если мы зайдём в настройки ADB-кластера, там будет определённый набор настроек с параметрами, заданными по умолчанию. Некоторые нужно знать, для этого в документации есть описание, какие значения они могут принимать.
Так как это автоматизированная установка, то вначале потребуется задать конфигурационные параметры: указать, куда подключаться; какие значения параметров установить; какого пользователя привлечь; какие диски использовать и так далее. Прежде всего, к настраиваемым параметрам относится количество логических сегментов, которые устанавливаются на серверах.
СУБД Arenadata DB по своей сути — набор инстансов PostgreSQL. Просто обычно каждая такая PostgreSQL СУБД работает на одном сервере, а СУБД Greenplum — это набор PostgreSQL, которые работают на серверах внутри одного кластера. Другими словами, на одном сервере может работать сразу несколько инстансов PostgreSQL, а самих серверов внутри кластеров может быть очень много. Инстанс PostgreSQL в Greenplum называют логическим сегментом или просто сегментом. Очень важно указать их правильное число, чтобы рационально утилизировать все ресурсы сервера.
Это самый кастомизируемый параметр ADB. Все остальные — указаны по умолчанию, хотя можно, например, распределить данные по 5 дискам или директориям (для этого нужно внести соответствующие изменения в настройки бандла).
Можно ли интегрировать ADB с системой мониторинга?
Да. Если кластер мониторинга был установлен позже кластера ADB, то есть возможность импортировать мониторинг текущего кластера ADB. Сейчас в качестве решений мониторинга используются Graphite и Grafana. Graphite — набор сервисов, которые хранят данные, а Grafana — это инструмент для их визуализации.
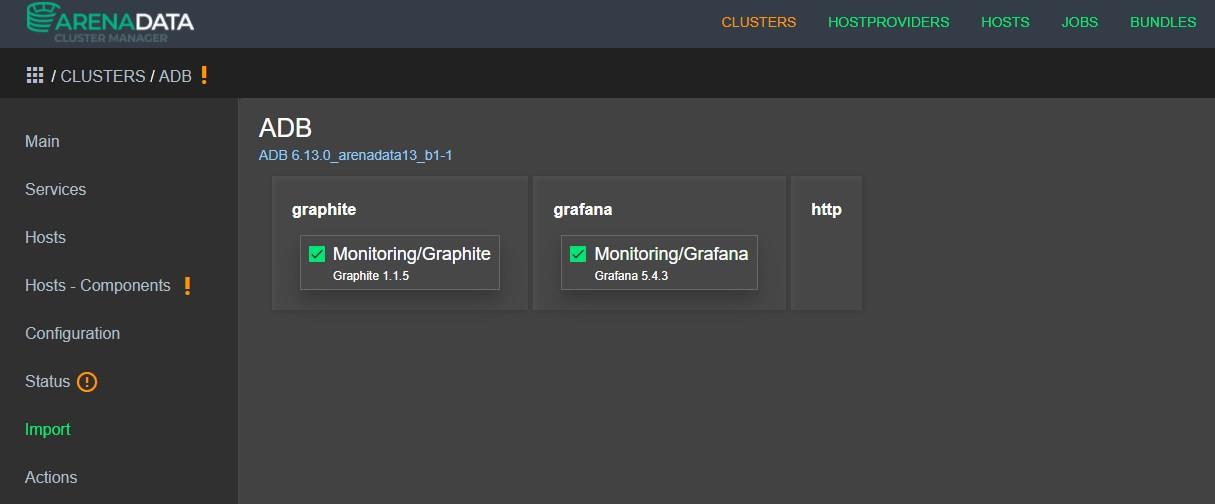
Для этого нужно зайти в настройки кластера ADB и добавить сервис Monitoring Clients:
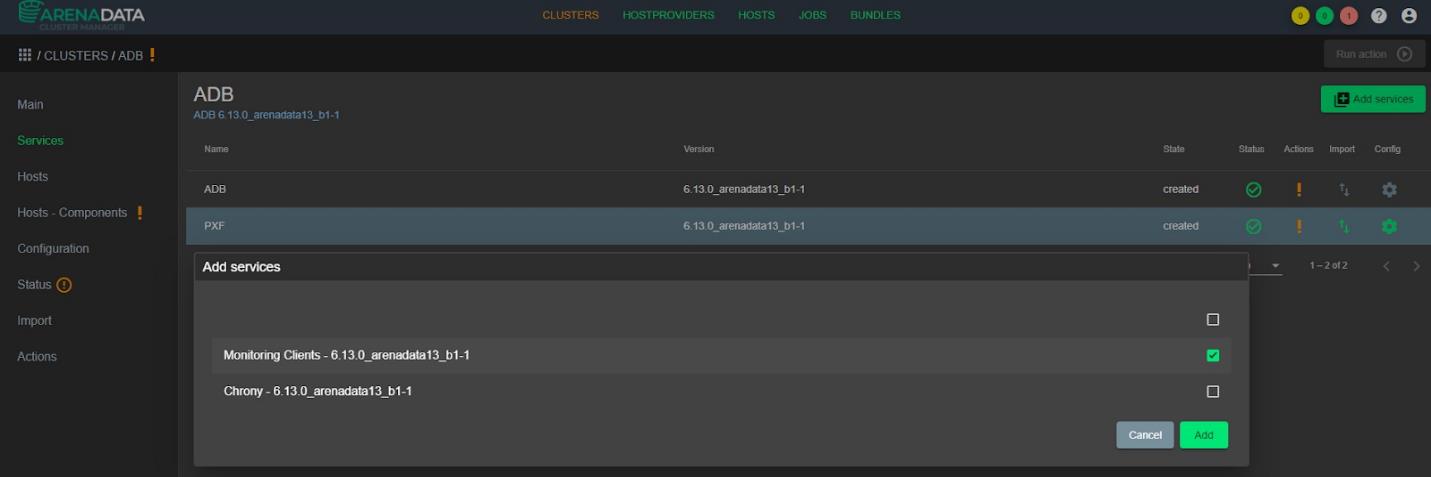
Во вкладке Import необходимо отметить галочками сервисы мониторинга, чтобы агенты мониторинга понимали, на какой сервер отправлять информацию:
Для каждого сервиса есть предустановленные панели dashboard (ничего настраивать не нужно). После того как установлены мониторинг и ADB, открываем веб-интерфейс Grafana и говорим, что нам нужен dashboard по ADB. В нём уже выведены основные метрики работы серверов: загрузка CPU, памяти, дисков, сетевые интерфейсы и информация о состоянии самой СУБД (как чувствуют себя Postgres-инстансы, все ли они работают и т. д.).
Как использовать виртуальные среды для установки ADB?
Мы рекомендуем работать с виртуальными средами только в тех ситуациях, когда ADB разворачивается в среде разработки или в среде тестирования. Для промышленной — рекомендуем Bare-metal.
Почему это обычная практика
Во-первых, виртуализация — это чаще всего shared-ресурсы, то есть на одном железном сервере запускается несколько виртуальных серверов. Поскольку сама СУБД является кластером, где работает n-количество серверов, главная особенность решения состоит в том, что все они работают одновременно. Если в кластере Greenplum 10 серверов, то после запуска запроса они все начнут работать одномоментно. При этом нагружается одновременно и гипервизор, и сама железка, на которой размещены виртуальные сервера.
Во-вторых, слой виртуализации между железом и ПО вносит задержки. Если в этом слое что-то ломается, то такие сбои отследить непросто.
ADCM поддерживает установку кластера ADB и управление серверами в облаке с помощью специальных облачных бандлов. Например, для Google Cloud Platform или для Yandex Cloud. Если стоит задача использовать конкретное публичное облако, то под него разрабатывается специальный бандл или можно воспользоваться стандартным SSH Bundle.
Все виртуальные среды разные и, если есть задача развернуть ADB в облаке, стоит учесть эти моменты.
Greenplum — система управления данными из мира big data. Она нужна тем, кто анализирует и обрабатывает десятки терабайтов информации и кому тесно и некомфортно работать с обычными СУБД. Расскажем о том, что это за система, где и как ее использовать и в чем ее отличие от других систем, работающих с большими данными.
Самое главное: как устроена Greenplum
В основе Greenplum две вещи:
- знакомая многим база данных PostgreSQL;
- архитектурная концепция MPP.
Про PostgreSQL в Greenplum более-менее все известно, в работе инженеров она встречается часто, а вот MPP упоминается реже.
MPP — massively parallel processing, или массивно-параллельная обработка данных. Такая архитектура весьма сложно устроена под капотом, но ее можно свести к простому концептуальному описанию. Это умная автоматическая разбивка данных по разным серверам (шардинг) с умной автоматической системой выполнения запросов к этим данным. Всё вместе это позволяет хранить петабайты записей и выполнять запросы к ним за вполне разумный срок.
Конечно, разбивку большого количества данных по серверам базы данных (шардинг) можно сделать и руками, например, первый миллион записей хранится на первом сервере, а второй на втором. Решение выглядит простым, но есть куча минусов. Если сразу всем клиентам системы понадобится прочитать записи с одного сервера — этот сервер может не выдержать. Масштабировать такую систему тоже очень сложно.
Greenplum берет на себя все эти заботы и организует шардирование своими силами, заботясь обо всех нюансах. А еще Greenplum можно настраивать на различные стратегии выполнения запросов, ориентируясь на количество записей, количество процессоров и памяти на каждой машине.
Сама система за хранение данных не отвечает, для этих целей она использует PostgreSQL.
Сочетаний крутой архитектуры и надежной СУБД дает в сумме надежную и производительную систему для тех, кому надо справляться с большими данными и масштабной аналитикой.Кому нужна СУБД Greenplum
О самом очевидном применении мы уже поговорили — такая система незаменима, когда данных слишком много. Если 2-4 терабайта можно как-то втиснуть на один-три сервера и даже обращаться к этим данным, то миллиард терабайт в обычную СУБД поместить весьма проблематично.
То есть Greenplum нужна тем, у кого данных больше, чем очень много, то есть для работы с большими данными.
Кроме того, хранить данные — часть дела. Если к записям нельзя обращаться за адекватное время и выполнять над ними нужные операции — толку от таких данных нет.
Поэтому Greenplum нужна тем, кто не только хранит огромные объемы информации, но и активно с ними работает.
Конечно, проблемы работы с большими объемами появились не вчера, инструменты под эти задачи на рынке есть: ClickHouse, Cassandra и другие. Но после чтения документации можно заметить, что несмотря на общую сферу применения, у Greenplum есть особенности, которые четко определяют, когда точно нужна эта система, а когда стоит выбрать другую.
Сейчас мы поговорим о конкретных случаях и отличиях Greenplum от аналогов.
Чем Greenplum отличается от других СУБД для работы с большими данными
Greenplum поддерживает реляционную модель данных, сохраняет неизменность данных, поэтому ее можно применять для данных, чувствительных к точности и структурности. Например, для финансовых операций. Greenplum — хороший выбор для банков, ритейла и других компаний, где проводят большое число транзакций и их нельзя потерять.
От систем типа ClickHouse Greenplum отличается сферой применения. Если Clickhouse больше подходит для статистики, то Greenplum намного ближе к полноценной СУБД с индексами и хитрыми запросами. Это позволяет быстрее обращаться к определенным записям. При этом Greenplum справляется с аналитическими нагрузками от бизнес-аналитики до машинного обучения.
Также Greenplum поддерживает различные виды репликации и шардинга, оставляя далеко позади все аналоги. Это дает хорошую производительность, но требует очень тонкой настройки и множества серверов, если вы хотите развернуть такую систему on-premise.
Greenplum лежит в основе облачной СУБД Arenadata DB, которую можно арендовать в облаке VK Cloud Solutions (бывш. MCS) — тогда возиться с настройками не придется и в руках мгновенно окажется вся мощь этой системы. Вы сможете в несколько кликов развернуть базу для хранения и обработки больших данных, не вкладываясь в собственную инфраструктуру и ее поддержку. Интеграция Greenplum с Hadoop, Spark и другими инструментами анализа big data позволят еще эффективнее работать с большими данными.Близкие по функциональности СУБД с похожей архитектурой часто сложнее внедрить. Например, этот аргумент может стать решающим при сравнении Greenplum и Teradata. Также Greenplum построена на базе PostgreSQL, поэтому проще найти специалистов для работы с ней.
В этой статье описано, как с помощью действия копирования в фабрике данных Azure или конвейера синапсе Analytics копировать данные из Greenplum. Это продолжение статьи об обзоре действия копирования, в которой представлены общие сведения о действии копирования.
Поддерживаемые возможности
Этот соединитель Greenplum поддерживается для следующих действий:
Данные из Greenplum можно скопировать в любое поддерживаемое хранилище данных, которое используется в качестве приемника. Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия копирования, приведен в таблице Поддерживаемые хранилища данных и форматы.
Служба предоставляет встроенный драйвер для обеспечения подключения, поэтому вам не нужно вручную устанавливать драйверы с помощью этого соединителя.
Предварительные требования
Если хранилище данных размещено в локальной сети, виртуальной сети Azure или виртуальном частном облаке Amazon, для подключения к нему нужно настроить локальную среду выполнения интеграции.
Если же хранилище данных представляет собой управляемую облачную службу данных, можно использовать Azure Integration Runtime. Если доступ предоставляется только по IP-адресам, утвержденным в правилах брандмауэра, вы можете добавить IP-адреса Azure Integration Runtime в список разрешений.
Вы также можете использовать функцию среды выполнения интеграции в управляемой виртуальной сети в Фабрике данных Azure для доступа к локальной сети без установки и настройки локальной среды выполнения интеграции.
Дополнительные сведения о вариантах и механизмах обеспечения сетевой безопасности, поддерживаемых Фабрикой данных, см. в статье Стратегии получения доступа к данным.
Начало работы
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
Создание связанной службы для Greenplum с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу для Greenplum с помощью пользовательского интерфейса на портале Azure.
Перейдите на вкладку «Управление» в рабочей области Фабрики данных Azure или Synapse, выберите элемент «Связанные службы» и щелкните «Создать».


Выполните поиск Greenplum и выберите соединитель Greenplum.

Настройте сведения о службе, проверьте подключение и создайте связанную службу.

Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые используются для определения сущностей фабрики данных, относящихся к соединителю Greenplum.
Свойства связанной службы
Для связанной службы Greenplum поддерживаются следующие свойства:
| Свойство | Описание | Обязательно |
|---|---|---|
| type | Для свойства type необходимо задать значение Greenplum. | Да |
| connectionString | Строка подключения к Greenplum через интерфейс ODBC. Вы можете также поместить пароль в Azure Key Vault и извлечь конфигурацию pwd из строки подключения. Ознакомьтесь с приведенными ниже примерами и подробными сведениями в статье Хранение учетных данных в Azure Key Vault. | Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Дополнительные сведения см. в разделе Предварительные требования. Если не указано другое, по умолчанию используется интегрированная среда выполнения Azure. | Нет |
Пример.
Пример: хранение пароля в Azure Key Vault
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. В этом разделе содержится список свойств, поддерживаемых набором данных Greenplum.
Чтобы скопировать данные из Greenplum, задайте для свойства type набора данных значение GreenplumTable. Поддерживаются следующие свойства:
| Свойство | Описание | Обязательно |
|---|---|---|
| type | Свойство type для набора данных должно иметь значение GreenplumTable | Да |
| схема | Имя схемы. | Нет (если свойство query указано в источнике действия) |
| table | Имя таблицы. | Нет (если свойство query указано в источнике действия) |
| tableName | Имя таблицы со схемой. Это свойство поддерживается только для обеспечения обратной совместимости. Для новых рабочих нагрузок используйте schema и table . | Нет (если свойство query указано в источнике действия) |
Пример
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. Этот раздел содержит список свойств, поддерживаемых источником Greenplum.
GreenplumSource в качестве источника
Чтобы копировать данные из Greenplum, задайте для типа источника в действии копирования значение GreenplumSource. В разделе source действия копирования поддерживаются следующие свойства:
| Свойство | Описание | Обязательно |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение GreenplumSource. | Да |
| query | Используйте пользовательский SQL-запрос для чтения данных. Например: "SELECT * FROM MyTable" . | Нет (если для набора данных задано свойство tableName) |
Пример.
Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Дальнейшие действия
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия Copy, приведен в таблице Поддерживаемые хранилища данных и форматы.
Читайте также: