
Как узнать кодировку файла linux
Обновлено: 02.07.2024
Мне нужно найти кодировку всех файлов, которые размещены в каталоге. Есть ли способ найти используемую кодировку?
Команда file не может сделать это.
Интересующая меня кодировка: ISO-8859-1. Если кодировка является чем-то еще, я хочу переместить файл в другой каталог.
Если у вас есть представление о том, какой язык сценариев вы хотите использовать, пометьте свой вопрос названием этого языка. Это может помочь . Или, может быть, он просто пытается создать сценарий оболочки? Может быть, не связано с этим ответом, но совет в целом: когда вы можете описать все ваши сомнения в одном слове («кодировка», здесь), просто сделайте apropos encoding . Он ищет названия и описания всех справочных страниц. Когда я делаю это на моей машине, я вижу 3 инструментов , которые могли бы помочь мне, судя по их описаниям: chardet , chardet3 , chardetect3 . Затем, man chardet прочитав man-страницу, вы узнаете, что chardet мне нужна именно эта утилита. Кодировка может измениться при изменении содержимого файла. Например, в vi, когда пишете простую программу на c, это возможно us-ascii , но после добавления строки китайского комментария это становится utf-8 . file можно узнать кодировку, прочитав содержимое файла и угадать.Похоже, вы ищете enca . Он может угадывать и даже конвертировать между кодировками. Просто посмотрите на справочную страницу .
Или, если это не удалось, используйте file -i (linux) или file -I (osx). Это выведет информацию MIME-типа для файла, которая также будет включать кодировку набора символов. Я тоже нашел для этого справочную страницу :)
Согласно справочной странице, он знает о наборе ISO 8559. Возможно, прочитайте немного менее внимательно :-) Энка звучит интересно. К сожалению, обнаружение кажется очень зависимым от языка, и набор поддерживаемых языков не очень большой. Шахта (де) отсутствует :-( В любом случае классный инструмент. enca кажется, совершенно бесполезен для анализа файла, написанного на английском языке, но если вы что-то просматриваете на эстонском языке, это может решить все ваши проблемы. Очень полезный инструмент, который . </ @vladkras, если в вашем файле utf-8 нет символов, отличных от ascii, то это неотличимо от ascii :)Если вы хотите сделать это для нескольких файлов
Однако, если файл представляет собой файл xml с атрибутом «encoding = 'iso-8859-1» в объявлении xml, команда file скажет, что это iso-файл, даже если истинная кодировка - utf-8 . Почему вы используете аргумент -b? Если вы просто делаете файл -i *, он выводит угаданную кодировку для каждого файла. Нет необходимости анализировать вывод файла, file -b --mime-encoding выводит только кодировку charset -b означает «быть кратким», что в основном означает не выводить имя файла, которое вы только что дали.uchardet - библиотека детекторов кодирования, портированная из Mozilla.
Различные дистрибутивы Linux (Debian / Ubuntu, OpenSuse-packman, . ) предоставляют двоичные файлы.
Спасибо! Я не в восторге от еще большего количества пакетов, но sudo apt-get install uchardet настолько легко, что я решил не беспокоиться об этом . Как я только что сказал в комментарии выше: uchardet ложно говорит мне, что кодировка файла была «windows-1252», хотя я явно сохранил этот файл как UTF-8. Учардет даже не говорит «с уверенностью 0.4641618497109827», что, по крайней мере, даст вам подсказку, что это говорит вам полную чушь. Файл, Enca и Encguess работали правильно. uchardet имеет большое преимущество по сравнению file с тем enca , что анализирует весь файл (только что попробованный с файлом 20 ГБ), а не только начало.Вот пример сценария с использованием файлов -I и iconv, который работает на MacOsX. Для вашего вопроса вам нужно использовать mv вместо iconv
file -b --mime-encoding выводит только кодировку, так что вы можете избежать обработки всех Спасибо. Как указано в MacOS, это не будет работать: file -b - mime-encoding Использование: file [-bchikLNnprsvz0] [-e test] [-f namefile] [-F separator] [-m magicfiles] [-M magicfiles ] file . file -C -m magicfiles Попробуйте `file --help 'для получения дополнительной информации.Кодирование - одна из самых сложных вещей, потому что вы никогда не знаете, ничего не говорит вам
Это может помочь попробовать грубую силу. Следующая команда попытается преобразовать из всех форматов кодирования с именами, которые начинаются с WIN или ISO, в UTF8. Затем необходимо вручную проверить вывод, чтобы найти ключ к правильной кодировке. Конечно, вы можете изменить отфильтрованные форматы, заменив ISO или WIN на что-то подходящее, или удалить фильтр, удалив команду grep. для меня в $ (iconv -l | tail -n +2 | grep "(^ ISO \ | ^ WIN)" | sed -e 's / \ / \ ///'); сделать эхо $ я; iconv -f $ i -t UTF8 santos; сделано;В Debian вы также можете использовать encguess :
Я установил uchardet в Ubuntu, и он сказал мне, что мой файл был WINDOWS-1252 . Я знаю, что это было неправильно, потому что я сохранил это как UTF-16 с Кейт, чтобы проверить. Однако, encguess угадайте правильно, и он был предварительно установлен в Ubuntu 19.04.Чтобы преобразовать кодировку из 8859 в ASCII:
Что касается этого комментария, он находится на chardet / chardet на github. Обновленный ответ. chardet сообщает "None", chardet3 задыхается в первой строке файла точно так же, как мой скрипт на python.Это не то, что вы можете сделать безошибочно. Одной из возможностей будет проверка каждого символа в файле, чтобы убедиться, что он не содержит символов в диапазонах 0x00 - 0x1f или 0x7f -0x9f , но, как я уже сказал, это может быть верно для любого количества файлов, в том числе , по меньшей мере , одного другого варианта ISO8859.
Другой возможностью является поиск определенных слов в файле на всех поддерживаемых языках и возможность их найти.
Так, например, найдите эквивалент английского «и», «но», «к», «of» и т. Д. На всех поддерживаемых языках 8859-1 и посмотрите, есть ли у них большое количество вхождений в пределах файл.
Я не говорю о буквальном переводе, таком как:
хотя это возможно Я говорю об общих словах на целевом языке (насколько я знаю, в исландском языке нет слова "и" - вам, вероятно, придется использовать их слово для "рыбы" [извините, это немного стереотипно, я не имею в виду любое нарушение, просто иллюстрирующее точку зрения]).
Я знаю, что вы заинтересованы в более общем ответе, но то, что хорошо в ASCII, обычно хорошо в других кодировках. Вот строка Python, чтобы определить, является ли стандартный ввод ASCII. (Я почти уверен, что это работает в Python 2, но я тестировал его только на Python 3.)
Если вы говорите о XML-файлах (ISO-8859-1), XML-объявление внутри них определяет кодировку: <?xml version="1.0" encoding="ISO-8859-1" ?>
так что вы можете использовать регулярные выражения (например, с perl ), чтобы проверить каждый файл на предмет такой спецификации.
Более подробную информацию можно найти здесь: Как определить кодировку текстового файла .
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или --mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
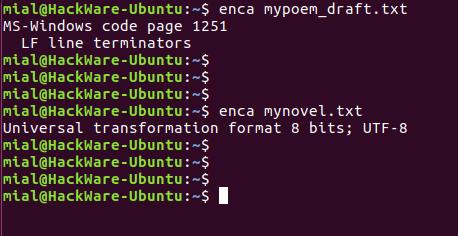
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
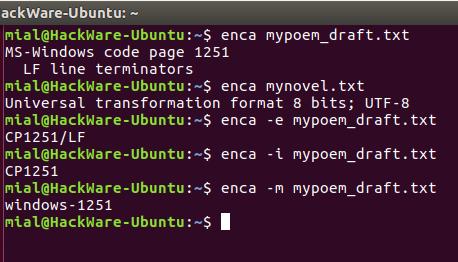
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.

то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или --from-code означает кодировку исходного файла -t или --to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
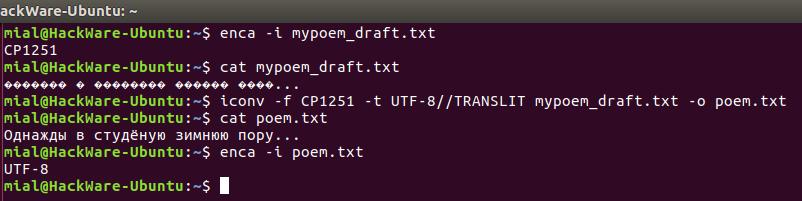
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
Что бы изменить кодировку файла нужно использовать замечательную утилиту iconv. В параметрах необходимо указывать исходную кодировку, а в этом нам поможет команда:
Ну а далее вот такие действия:
iconv -f WINDOWS-1251 -t UTF-8 -o output_file.txt original_file.txt
Остальные ключики как обычно в man iconv.
iconv и большие файлы
В простом варианте чтобы разбить файл на куски объёмом по 1Gb выполнить:
Это самые просты решения, эти команды можно использовать в различных скриптах и получить от этого много кайфов. Надеюсь эта заметка вам чем-то помогла.
К сожалению ни в gEdit, ни в Leafpad я не нашёл функции, которая бы могла сказать в какой кодировке находится файл. Но на выручку, как всегда приходить консоль:
file -i file.txt
Как узнать кодировку файла в Ubuntu Linux: 5 комментариев
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Чтобы вывести список всех кодировок, запустите команду:
Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
В Linux всё является файлами и tty терминалы не исключение.
Или аналогичную команду
crw--w----. 1 andrei tty 136, 1 Nov 19 12:43 /dev/pts/1
Первый символ - это тип файла.
Доступно семь типов файлов: обычные, директории, символьные, блоки, сокеты, именованые каналы, символьные ссылки
- : regular file
d : directory
c : character device file
b : block device file
s : local socket file
p : named pipe
l : symbolic link
Тип c означает character. То есть этот файл может принимать и показывать символы
drwxr-xr-x. 118 root root 8192 Nov 19 11:02 /etc
Видно, что тип файла d. То есть directory
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 7G 0 part ├─centos-root 253:0 0 6.2G 0 lvm / └─centos-swap 253:1 0 820M 0 lvm [SWAP] sr0 11:0 1 57.7M 0 rom /run/media/andrei/VBox_GAs_6.1.10
brw-rw----. 1 root disk 8, 0 Nov 19 11:02 /dev/sda brw-rw----. 1 root disk 8, 1 Nov 19 11:02 /dev/sda1 brw-rw----. 1 root disk 8, 2 Nov 19 11:02 /dev/sda2
Можно убедитсья, что тип файлов b. То есть block
? означает что должен быть один любой символ.
brw-rw----. 1 root disk 8, 1 Nov 19 11:02 /dev/sda1 brw-rw----. 1 root disk 8, 2 Nov 19 11:02 /dev/sda2
[12] означает что должен быть либо символ 1 либо символ 2
brw-rw----. 1 root disk 8, 1 Nov 19 11:02 /dev/sda1 brw-rw----. 1 root disk 8, 2 Nov 19 11:02 /dev/sda2
Когда вы хотите узнать версию системы вы можете выполнить
ls -l /etc/system-release
lrwxrwxrwx. 1 root root 14 Nov 17 13:44 /etc/system-release -> centos-release
Тип файла l означает link то есть это не настоящий файл, а ссылка
ls -l /etc/system-release /etc/centos-release /etc/redhat-release
-rw-r--r--. 1 root root 37 Oct 23 17:53 /etc/centos-release lrwxrwxrwx. 1 root root 14 Nov 17 13:44 /etc/redhat-release -> centos-release lrwxrwxrwx. 1 root root 14 Nov 17 13:44 /etc/system-release -> centos-release
Если бы вы пользовались redhat то настоящим был бы redhat-release
Ещё один способ получить информацию о версии - выполнить lsb_release -d где -d означает description
Description: CentOS Linux release 7.9.2009 (Core)
Узнать расположение файла
Узнать где находится файл lsb_release можно командой which lsb_release. Чтобы сразу получить дополнительную информацию выполните
ls -lF $(which lsb_release)
-rwxr-xr-x. 1 root root 15929 Mar 27 2015 /usr/bin/lsb_release*
Опция -F означает показать тип файлов. Поэтому нам удалось увидеть * после lsb_release. * означает, что файл исполняемый.
Чтобы узнать откуда взялся файл можно воспользоваться командой rpm с опциями q (query) и f (file)
rpm -qf $(which lsb_release)
Чтобы скопировать файл в интерактивном режиме воспользуйтесь командой cp с опцией i (interactive)
interactive означает, что если файл с таким имененм существует, вас спросят прежде чем затирать его
cp -i /etc/hosts .
cp -i /etc/hosts .
cp: overwrite ‘./hosts’?
Чтобы создать директорию сразу же с поддиректорией внутри воспользуйтесь командлой mkdir с опцией p (parent)
mkdir -p sites/heiheiru
ls -l sites
total 0
drwxrwxr-x. 2 andrei andrei 6 Nov 19 13:40 heiheiru
Создать сразу несколько файлов
Чтобы создать одновременно несколько файлов с именами идущими по порядку выполните touch с <>
touch files/file
ls -l files
-rw-rw-r--. 1 andrei andrei 0 Nov 19 13:46 file1 -rw-rw-r--. 1 andrei andrei 0 Nov 19 13:46 file2 -rw-rw-r--. 1 andrei andrei 0 Nov 19 13:46 file3 -rw-rw-r--. 1 andrei andrei 0 Nov 19 13:46 file4 -rw-rw-r--. 1 andrei andrei 0 Nov 19 13:46 file5
Чтобы скопировать директорию files в директорию sites со всем содержимым выполните
cp -R files sites
ls -l sites/files/
total 0 -rw-rw-r--. 1 andrei andrei 0 Nov 19 13:49 file1 -rw-rw-r--. 1 andrei andrei 0 Nov 19 13:49 file2 -rw-rw-r--. 1 andrei andrei 0 Nov 19 13:49 file3 -rw-rw-r--. 1 andrei andrei 0 Nov 19 13:49 file4 -rw-rw-r--. 1 andrei andrei 0 Nov 19 13:49 file5
Директория files была скопирована в директорию sites, то есть теперь у sites есть поддиректория files.
Если у вас установлен модуль tree вы можете наглядно изучить вложенность. Если нет - выполните сперва
sudo yum install tree
sites └── files ├── file1 ├── file2 ├── file3 ├── file4 └── file5 1 directory, 5 files
Пришла в GAIM кракозяка -- пробовал разные варианты с iconv - все без толку. Правильно я понимаю -- человеческий текст не восстановить, т.к. она запорчен? НА будущее: как узнать в какой кодировке кракозяквы?



pidgin ненужен. licq - наше всьо
>echo "message" | iconv -f utf-8 -t cp1251 уже пробовали?
iconv: illegal input sequence at position 0
Да хрен с ним с Пиджин то. Интересно вообще: есть набор символов псевдограифики и ощущение того, что за ними скрывается осмысленный текст. Как за разумное время его прочитать?

>pidgin ненужен. licq - наше всьо
licq может irc, jabber?
for e in `iconv -l`; do echo $e; iconv -f $e <<< 'образец'; echo; done 2>/dev/null | less
Если в образце лежит осмысленный текст, то обычно за него легко зацепиться глазом при просмотре выхлопа этой команды. Конечно, это не поможет в случае дважды закодированного текста.


Есть такая хорошая штука, konwert.
>Есть такая хорошая штука, konwert.
Любопытная вещь. Спасибо - не знал. Она определила кодировку, оказалось непонятно как cp866. Вот только результат работы команды
]iconv --verbose erunda.txt --from-code cp866 --to-code utf-8 -o erundautf
более чем странный. Вот например кусок (не знаю как будет в браузере читаться конечно)
Читайте также: