
Как запустить elasticsearch ubuntu
Обновлено: 07.07.2024
Elasticsearch – это платформа для распределенного поиска и анализа данных в режиме реального времени; она пользуется большой популярностью благодаря своей простоте, масштабируемости и большому количеству полезных функций.
Этот мануал поможет установить и настроить Elasticsearch на сервере Ubuntu 18.04 и начать работу с ним.
Требования
- Сервер Ubuntu 18.04, настроенный по этому мануалу. Прежде чем приступить к установке Elasticsearch, перейдите в сессию пользователя с доступом к sudo.
- 4GB RAM и 2 CPU минимум.
- OpenJDK 11 (инструкции по установке можно найти в мануале Установка Java с помощью apt в Ubuntu 18.04).
В этом мануале мы будем работать с минимальным количеством RAM и CPU, необходимым для запуска Elasticsearch. Обратите внимание, объем ресурсов, которые потребуются Elasticsearch, зависит от объема данных, которые вы хотите обрабатывать с его помощью.
1: Установка Elasticsearch
Пакетов Elasticsearch нет в стандартном репозитории Ubuntu. Чтобы установить этот пакет с помощью APT, можно добавить исходник пакета.
Все пакеты подписаны с помощью ключа Elasticsearch, чтобы защитить вашу систему от подделки. Пакеты, прошедшие проверку подлинности с помощью ключа, менеджер пакетов будет считать надежными. Давайте импортируем открытый GPG ключ Elasticsearch и добавим исходник пакета Elastic для установки Elasticsearch.
Теперь добавьте исходник Elastic в sources.list.d, где APT сможет его найти.
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Обновите список пакетов, чтоб APT нашел исходник Elastic.
sudo apt update
Чтобы установить Elasticsearch, введите:
sudo apt install elasticsearch
Теперь Elasticsearch установлен, можно приступать к его настройке.
2: Настройка Elasticsearch
Чтобы настроить Elasticsearch, нужно отредактировать его основной файл конфигурации elasticsearch.yml, в котором хранится большинство его параметров. Этот файл находится в каталоге /etc/elasticsearch.
Используйте любой удобный текстовый редактор, чтобы открыть конфигурационный файл Elasticsearch.
sudo nano /etc/elasticsearch/elasticsearch.yml
Примечание: Конфигурационный файл Elasticsearch использует формат YAML. Проверьте отступы при редактировании этого файла.
Файл elasticsearch.yml предоставляет параметры для настройки кластера, ноды, путей, памяти, сети, обнаружения и шлюза. Большинство из этих параметров предварительно сконфигурированы в файле, но вы можете изменить их настройки в соответствии со своими потребностями. Поскольку мы используем один сервер, мы настроим только параметры сетевого хоста.
Elasticsearch прослушивает весь трафик через порт 9200. Рекомендуем ограничить внешний доступ к вашему экземпляру Elasticsearch, чтобы посторонние не могли читать ваши данные или повлиять на работу кластера Elasticsearch через REST API. Чтобы ограничить доступ и таким образом повысить безопасность, найдите строку network.host, раскомментируйте ее и замените ее значение на localhost:
Мы указали значение localhost, чтобы Elasticsearch прослушивал все интерфейсы и связанные IP-адреса. Если вы хотите, чтобы он прослушивал только определенный интерфейс, вместо localhost вы можете указать его IP. Сохраните и закройте файл elasticsearch.yml. Если вы используете nano, нажмите Ctrl + X, затем Y и Enter.
Это минимальные настройки, с которых вы можете начать свою работу с Elasticsearch. Теперь можно запустить Elasticsearch.
Запустите сервис Elasticsearch с помощью systemctl. Дайте Elasticsearch несколько минут, чтобы запуститься. В противном случае вы можете получить ошибку подключения.
sudo systemctl start elasticsearch
Затем выполните следующую команду, чтобы добавить Elasticsearch в автозагрузку:
sudo systemctl enable elasticsearch
Теперь Elasticsearch будет включаться при запуске сервера.
3: Защита Elasticsearch
sudo ufw allow from 198.51.100.0 to any port 9200
После этого вы можете включить UFW с помощью команды:
sudo ufw enable
Проверьте состояние UFW с помощью следующей команды:
sudo ufw status
Если вы правильно настроили брандмауэр, вывод должен выглядеть следующим образом:
Status: active
To Action From
-- ------ ----
9200 ALLOW 198.51.100.0
22 ALLOW Anywhere
22 (v6) ALLOW Anywhere (v6)
Теперь UFW защищает порт Elasticsearch 9200 от посторонних.
Для дополнительной защиты Elasticsearch предлагает платный плагин Shield.
4: Тестирование Elasticsearch
Сейчас Elasticsearch запущен по порту 9200. Протестировать работу программы можно с помощью cURL и GET-запроса.
Вы должны увидеть такой ответ:
"node.name" : "My First Node",
"cluster.name" : "mycluster1",
"version" : "number" : "2.3.1",
"build_hash" : "bd980929010aef404e7cb0843e61d0665269fc39",
"build_timestamp" : "2020-04-04T12:25:05Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
>,
"tagline" : "You Know, for Search"
>
Если вы видите такой ответ, Elasticsearch работает правильно. Если нет, убедитесь, что вы правильно выполнили все инструкции по установке и запуску Elasticsearch.
Для более тщательной проверки работы Elasticsearch выполните следующую команду:
В выводе вышеприведенной команды вы можете проверить все текущие настройки ноды, кластера, путей к приложениям, модулей и многие другие параметры.
5: Начало работы с Elasticsearch
Чтобы начать использовать Elasticsearch, сначала нужно добавить какие-нибудь данные. Elasticsearch использует RESTful API, который отвечает на обычные команды CRUD (create, read, update и delete). Работать с ним можно с помощью команды cURL.
Вы можете добавить свою первую запись с помощью такой команды:
curl -XPOST -H "Content-Type: application/json" 'http://localhost:9200/tutorial/helloworld/1' -d '< "message": "Hello World!" >'
Вы должны получить такой результат:
- tutorial – индекс данных Elasticsearch.
- Helloworld – тип.
- 1 – ID записи в индексе и типе.
curl -X GET -H "Content-Type: application/json" 'http://localhost:9200/tutorial/helloworld/1' -d '< "message": "Hello World!" >'
Вы получите такой результат:
Изменить данные в существующей записи можно при помощи запроса PUT.
curl -X PUT -H "Content-Type: application/json" 'localhost:9200/tutorial/helloworld/1?pretty' -d '
"message": "Hello, People!"
>'
Elasticsearch сообщит, что запрос выполнен успешно:
"_index" : "tutorial",
"_type" : "helloworld",
"_id" : "1",
"_version" : 2,
"_shards" : "total" : 2,
"successful" : 1,
"failed" : 0
>,
"created" : false
>
Возможно, вы заметили дополнительный аргумент pretty в приведенном выше запросе. Он обеспечивает удобочитаемый формат, благодаря чему вы можете записать каждое поле данных в новую строку. С помощью pretty вы также можете улучшить формат результатов при извлечении данных:
Теперь вывод будет удобно отформатирован:
"_index" : "tutorial",
"_type" : "helloworld",
"_id" : "1",
"_version" : 2,
"found" : true,
"_source" : "message" : "Hello, People!"
>
>
Теперь вы знакомы с базовыми операциями Elasticsearch. Чтобы узнать о других командах, обратитесь к документации.
Заключение
Вы установили и настроили Elasticsearch, а также ознакомились с базовыми командами. С первых своих версий Elasticsearch поддерживает три дополнительных инструмента – Logstash, Kabana и Beats – которые можно использовать вместе с Elasticsearch как часть Elastic Stack. Такой стек позволяет искать, анализировать и визуализировать логи из любых источников и в любом формате. Эта практика называется логированием.
Комплекс Elastic Stack (прежнее название — комплекс ELK) представляет собой набор программного обеспечения Elastic с открытым исходным кодом, обеспечивающий возможности поиска, анализа и визуализации журналов, сгенерированных любым источником в любом формате (централизованное ведение журнала). Централизованное ведение журнала очень полезно для выявления проблем с серверами или приложениями, поскольку обеспечивает возможности поиска всех журнальных записей в одном месте. Также данная возможность позволяет выявлять проблемы, распространяющиеся на несколько серверов, посредством сопоставления их журналов за определенный период времени.
Комплекс Elastic Stack имеет четыре основных компонента:
-
: распределенная поисковая система RESTful, которая сохраняет все собранные данные. : элемент обработки данных комплекса Elastic, отправляющий входящие данные в Elasticsearch. : веб-интерфейс для поиска и визуализации журналов. : компактные элементы переноса данных одиночного назначения, которые могут отправлять данные с сотен или тысяч компютеров в Logstash или Elasticsearch.
В этом обучающем модуле вы научитесь устанавливать комплект Elastic на сервере Ubuntu 20.04. Вы научитесь устанавливать все компоненты Elastic Stack, в том числе Filebeat, инструмент для перенаправления и централизации журналов и файлов, а также настраивать эти компоненты для сбора и визуализации системных журналов. Кроме того, поскольку компонент Kibana обычно доступен только через localhost , мы будем использовать Nginx в качестве прокси для обеспечения доступа через браузер. Мы установим все эти компоненты на одном сервере, который будем называть нашим сервером Elastic Stack.
Примечание. При установке Elastic Stack необходимо использовать одну и ту же версию для всего комплекса. В этом обучающем модуле мы установим последние версии компонентов комплекта. На момент написания это Elasticsearch 7.7.1, Kibana 7.7.1, Logstash 7.7.1 и Filebeat 7.7.1.
Предварительные требования
Для этого обучающего модуля вам потребуется следующее:
Сервер Ubuntu 20.04 с 4 ГБ оперативной памяти и 2 процессорами, а также настроенный пользователь без прав root с привилегиями sudo. Вы можете это сделать, воспользовавшись указаниями руководства Начальная настройка сервера Ubuntu 18.04. В этом обучающем руководстве мы будем использовать минимальное количество процессоров и оперативной памяти, необходимое для работы с Elasticsearch. Обратите внимание, что требования сервера Elasticsearch к количеству процессоров, оперативной памяти и хранению данных зависят от ожидаемого объема журналов.
Установленный пакет OpenJDK 11. Для настройки воспользуйтесь рекомендациями раздела «Установка комплекта JRE/JDK по умолчанию» in our guide в документе «Установка Java с помощью Apt в Ubuntu 20.04».
На сервере должен быть установлен Nginx, который мы позднее настроим как обратный прокси для Kibana. Для настройки следуйте указаниям нашего обучающего модуля «Установка Nginx в Ubuntu 20.04».
Кроме того, поскольку комплекс Elastic используется для доступа ценной информации о вашем сервере, которую вам нужно защищать, очень важно обеспечить защиту сервера сертификатом TLS/SSL. Это необязательно, но настоятельно рекомендуется.
Однако поскольку вы будете вносить изменения в серверный блок Nginx в ходе выполнения этого обучающего модуля, разумнее всего будет пройти обучающий модуль «Let’s Encrypt в Ubuntu 18.04» после прохождения второго шага настоящего обучающего модуля. Если вы планируете настроить на сервере Let’s Encrypt, вам потребуется следующее:
-
Полностью квалифицированное доменное имя (FQDN). В этом обучающем руководстве мы будем использовать your_domain . Вы можете купить доменное имя на Namecheap, получить его бесплатно на Freenom или воспользоваться услугами любого предпочитаемого регистратора доменных имен.
На вашем сервере должны быть настроены обе нижеследующие записи DNS. В руководстве Введение в DigitalOcean DNS содержится подробная информация по их добавлению.
Шаг 1 — Установка и настройка Elasticsearch
Компоненты Elasticsearch отсутствуют в репозиториях пакетов Ubuntu по умолчанию. Однако их можно установить с помощью APT после добавления списка источников пакетов Elastic.
Все пакеты подписаны ключом подписи Elasticsearch для защиты вашей системы от поддельных пакетов. Ваш диспетчер пакетов будет считать надежными пакеты, для которых проведена аутентификация с помощью ключа. На этом шаге вы импортируете открытый ключ Elasticsearch GPG и добавить список источников пакетов Elastic для установки Elasticsearch.
Для начала используйте cURL, инструмент командной строки для передачи данных с помощью URL, для импорта открытого ключа Elasticsearch GPG в APT. Обратите внимание, что мы используем аргументы -fsSL для подавления всех текущих и возможных ошибок (кроме сбоя сервера), а также чтобы разрешить cURL подать запрос на другой локации при переадресации. Выведите результаты команды cURL в программу apt-key, которая добавит открытый ключ GPG в APT.
Затем добавьте список источников Elastic в директорию sources.list.d , где APT будет искать новые источники:
Затем обновите списки пакетов, чтобы APT мог прочитать новый источник Elastic:
Установите Elasticsearch с помощью следующей команды:
Теперь система Elasticsearch установлена и готова к настройке. Используйте предпочитаемый текстовый редактор для изменения файла конфигурации Elasticsearch, elasticsearch.yml . Мы будем использовать nano :
Примечание. Файл конфигурации Elasticsearch представлен в формате YAM. Это означает, что нам нужно сохранить формат отступов. Не добавляйте никакие дополнительные пробелы при редактировании этого файла.
Файл elasticsearch.yml предоставляет варианты конфигурации для вашего кластера, узла, пути, памяти, сети, обнаружения и шлюза. Большинство из этих вариантов уже настроены в файле, но вы можете изменить их в соответствии с вашими потребностями. В нашем случае для демонстрации односерверной конфигурации мы будем регулировать настройки только для хоста сети.
Elasticsearch прослушивает весь трафик порта 9200 . По желанию вы можете ограничить внешний доступ к вашему экземпляру Elasticsearch, чтобы посторонние не смогли прочесть ваши данные или отключить ваш кластер Elasticsearch через REST API. Для ограничения доступа и повышения безопасности найдите строку с указанием network.host , разкомментируйте ее и замените значение на localhost , чтобы она выглядела следующим образом:
Мы указали localhost , и теперь Elasticsearch прослушивает все интерфейсы и связанные IP-адреса. Если вы хотите, чтобы прослушивался только конкретный интерфейс, вы можете указать его IP-адрес вместо localhost . Сохраните и закройте elasticsearch.yml . Если вы используете nano , вы можете сделать это, нажав CTRL+X , затем Y , а затем ENTER .
Это минимальные настройки, с которыми вы можете начинать использовать Elasticsearch. Теперь вы можете запустить Elasticsearch в первый раз.
Затем запустите следующую команду, чтобы активировать Elasticsearch при каждой загрузке сервера:
Вы получите ответ, содержащий базовую информацию о локальном узле:
Мы настроили и запустили Elasticsearch, и теперь можем перейти к установке Kibana, следующего компонента комплекса Elastic.
Шаг 2 — Установка и настройка информационной панели Kibana
Согласно официальной документации, Kibana следует устанавливать только после установки Elasticsearch. Установка в этом порядке обеспечивает правильность установки зависимостей компонентов.
Поскольку вы уже добавили источник пакетов Elastic на предыдущем шаге, вы можете просто установить все остальные компоненты комплекса Elastic с помощью apt :
Затем активируйте и запустите службу Kibana:
Поскольку согласно настройкам Kibana прослушивает только localhost , мы должны задать обратный прокси, чтобы разрешить внешний доступ. Для этого мы используем Nginx, который должен быть уже установлен на вашем сервере.
Вначале нужно использовать команду openssl для создания административного пользователя Kibana, которого вы будете использовать для доступа к веб-интерфейсу Kibana. Для примера мы назовем эту учетную запись kibanaadmin , однако для большей безопасности мы рекомендуем выбрать нестандартное имя пользователя, которое будет сложно угадать.
Введите и подтвердить пароль в диалоговом окне. Запомните или запишите эти учетные данные, поскольку они вам потребуются для доступа к веб-интерфейсу Kibana.
Теперь мы создадим файл серверного блока Nginx. В качестве примера мы присвоим этому файлу имя your_domain , хотя вы можете дать ему более описательное имя. Например, если вы настроили записи FQDN и DNS для этого сервера, вы можете присвоить этому файлу имя своего FQDN:
Создайте файл серверного блока Nginx, используя nano или предпочитаемый текстовый редактор:
Если вы выполнили предварительный обучающий модуль по Nginx до конца, возможно вы уже создали этот файл и заполнили его. В этом случае удалите из файла все содержание и добавьте следующее:
Завершив редактирование, сохраните и закройте файл.
Затем активируйте новую конфигурацию, создав символическую ссылку на каталог sites-enabled . Если вы уже создали файл серверного блока с тем же именем, что и в обучающем модуле по Nginx, вам не нужно выполнять эту команду:
Затем проверьте конфигурацию на синтаксические ошибки:
Если вы следовали указаниям модуля по начальной настройке сервера, у вас должен быть включен брандмауэр UFW. Чтобы разрешить соединения с Nginx, мы можем изменить правила с помощью следующей команды:
Теперь приложение Kibana доступно через FQDN или публичный IP-адрес вашего сервера комплекса Elastic. Вы можете посмотреть страницу состояния сервера Kibana, открыв следующий адрес и введя свои учетные данные в диалоге:
На этой странице состояния отображается информация об использовании ресурсов сервера, а также выводится список установленных плагинов.
Примечание. Как указывалось в разделе предварительных требований, рекомендуется включить на сервере SSL/TLS. Теперь вы можете следовать указаниями обучающего модуля по Let’s Encrypt для получения бесплатного сертификата SSL для Nginx в Ubuntu 20.04. После получения сертификата SSL/TLS вы можете вернуться и завершить прохождение этого обучающего модуля.
Теперь информационная панель Kibana настроена и мы перейдем к установке следующего компонента: Logstash.
Шаг 3 — Установка и настройка Logstash
Хотя Beats может отправлять данные напрямую в базу данных Elasticsearch, мы рекомендуем использовать для обработки данных Logstash. Это даст вам гибкую возможность собирать данные из разных источников, преобразовывать их в общий формат и экспортировать в другую базу данных.
Установите Logstash с помощью следующей команды:
После установки Logstash вы можете перейти к настройке. Файлы конфигурации Logstash находятся в каталоге /etc/logstash/conf.d . Дополнительную информацию о синтаксисе конфигурации можно найти в справочнике по конфигурации, предоставляемом Elastic. Во время настройки конфигурации в файле полезно рассматривать Logstash как конвейер, принимающий данные на одном конце, обрабатывающий и отправляющий их в пункт назначения (в нашем случае пунктом назначения является Elasticsearch). Конвейер Logstash имеет два обязательных элемента, input и output , а также необязательный элемент filter . Плагины ввода потребляют данные источника, плагины фильтра обрабатывают данные, а плагины вывода записывают данные в пункт назначения.

Создайте файл конфигурации с именем 02-beats-input.conf , где вы настроите ввод данных Filebeat:
Вставьте следующую конфигурацию ввода . В ней задается ввод beats , который прослушивает порт TCP 5044 .
Сохраните и закройте файл.
Создайте файл конфигурации с именем 30-elasticsearch-output.conf :
Вставьте следующую конфигурацию вывода . Этот вывод настраивает Logstash для хранения данных Beats в Elasticsearch, запущенном на порту localhost:9200 , в индексе с названием используемого компонента Beat. В этом обучающем модуле используется компонент Beat под названием Filebeat:
Сохраните и закройте файл.
Протестируйте свою конфигурацию Logstash с помощью следующей команды:
Если тестирование конфигурации выполнено успешно, запустите и активируйте Logstash, чтобы изменения конфигурации вступили в силу:
Теперь Logstash работает нормально и полностью настроен, и мы можем перейти к установке Filebeat.
Шаг 4 — Установка и настройка Filebeat
Комплекс Elastic использует несколько компактных элементов транспортировки данных (Beats) для сбора данных из различных источников и их транспортировки в Logstash или Elasticsearch. Ниже перечислены компоненты Beats, доступные в Elastic:
-
: собирает и отправляет файлы журнала. : собирает метрические показатели использования систем и служб. : собирает и анализирует данные сети. : собирает данные журналов событий Windows. : собирает данные аудита Linux и отслеживает целостность файлов. : отслеживает доступность услуг посредством активного зондирования.
В этом обучающем модуле мы используем Filebeat для перенаправления локальных журналов в комплекс Elastic.
Установите Filebeat с помощью apt :
Затем настройте Filebeat для подключения к Logstash. Здесь мы изменим образец файла конфигурации, входящий в комплектацию Filebeat.
Откройте файл конфигурации Filebeat:
Примечание. Как и в Elasticsearch, файл конфигурации Filebeat имеет формат YAML. Это означает, что в файле учитываются отступы, и вы должны использовать точно такое количество пробелов, как указано в этих инструкциях.
Сохраните и закройте файл.
Функции Filebeat можно расширить с помощью модулей Filebeat. В этом обучающем модуле мы будем использовать модуль system, который собирает и проверяет данные журналов, созданных службой регистрации систем в распространенных дистрибутивах Linux.
Давайте активируем его:
Вы увидите список включенных и отключенных модулей с помощью следующей команды:
Вы увидите примерно следующий список:
Filebeat по умолчанию настроен для использования путей по умолчанию для системных журналов и журналов авторизации. Для целей данного обучающего модуля вам не нужно ничего изменять в конфигурации. Вы можете посмотреть параметры модуля в файле конфигурации /etc/filebeat/modules.d/system.yml .
Затем нам нужно настроить конвейеры обработки Filebeat, выполняющие синтаксический анализ данных журнала перед их отправкой через logstash в Elasticsearch. Чтобы загрузить конвейер обработки для системного модуля, введите следующую команду:
Затем загрузите в Elasticsearch шаблон индекса. Индекс Elasticsearch — это коллекция документов со сходными характеристиками. Индексы идентифицируются по имени, которое используется для ссылки на индекс при выполнении различных операций внутри него. Шаблон индекса применяется автоматически при создании нового индекса.
Используйте следующую команду для загрузки шаблона:
В комплект Filebeat входят образцы информационных панелей Kibana, позволяющие визуализировать данные Filebeat в Kibana. Прежде чем вы сможете использовать информационные панели, вам нужно создать шаблон индекса и загрузить информационные панели в Kibana.
При загрузке информационных панелей Filebeat подключается к Elasticsearch для проверки информации о версиях. Для загрузки информационных панелей при включенном Logstash необходимо отключить вывод Logstash и активировать вывод Elasticsearch:
Результат должен выглядеть примерно следующим образом:
Теперь вы можете запустить и активировать Filebeat:
Если вы правильно настроили комплекс Elastic, Filebeat начнет отправлять системный журнал и журналы авторизации в Logstash, откуда эти данные будут загружаться в Elasticsearch.
Результат должен выглядеть примерно следующим образом:
Если в результатах показано 0 совпадений, Elasticsearch не выполняет загрузку журналов в индекс, который вы искали, и вам нужно проверить настройки на ошибки. Если вы получили ожидаемые результаты, перейдите к следующему шагу, где мы увидим, как выполняется навигация по информационным панелям Kibana.
Шаг 5 — Изучение информационных панелей Kibana
Вернемся в веб-интерфейс Kibana, который мы установили ранее.
Откройте в браузере FQDN или публичный IP-адрес вашего сервера с комплексом Elastic. Если сессия была прервана, вам нужно будет повторно ввести учетные данные, которые вы определили на шаге 2. После входа в систему вы получите домашнюю страницу Kibana:
Здесь вы можете искать и просматривать журналы, а также настраивать информационные панели. Сейчас на этой странице будет немного данных, потому что вы собираете системные журналы только со своего сервера Elastic Stack.
Используйте левую панель навигации для перехода на страницу Dashboard и выполните на этой странице поиск информационных панелей Filebeat System. После этого вы можете выбрать образцы панелей управления, входящие в комплект модуля Filebeat system .
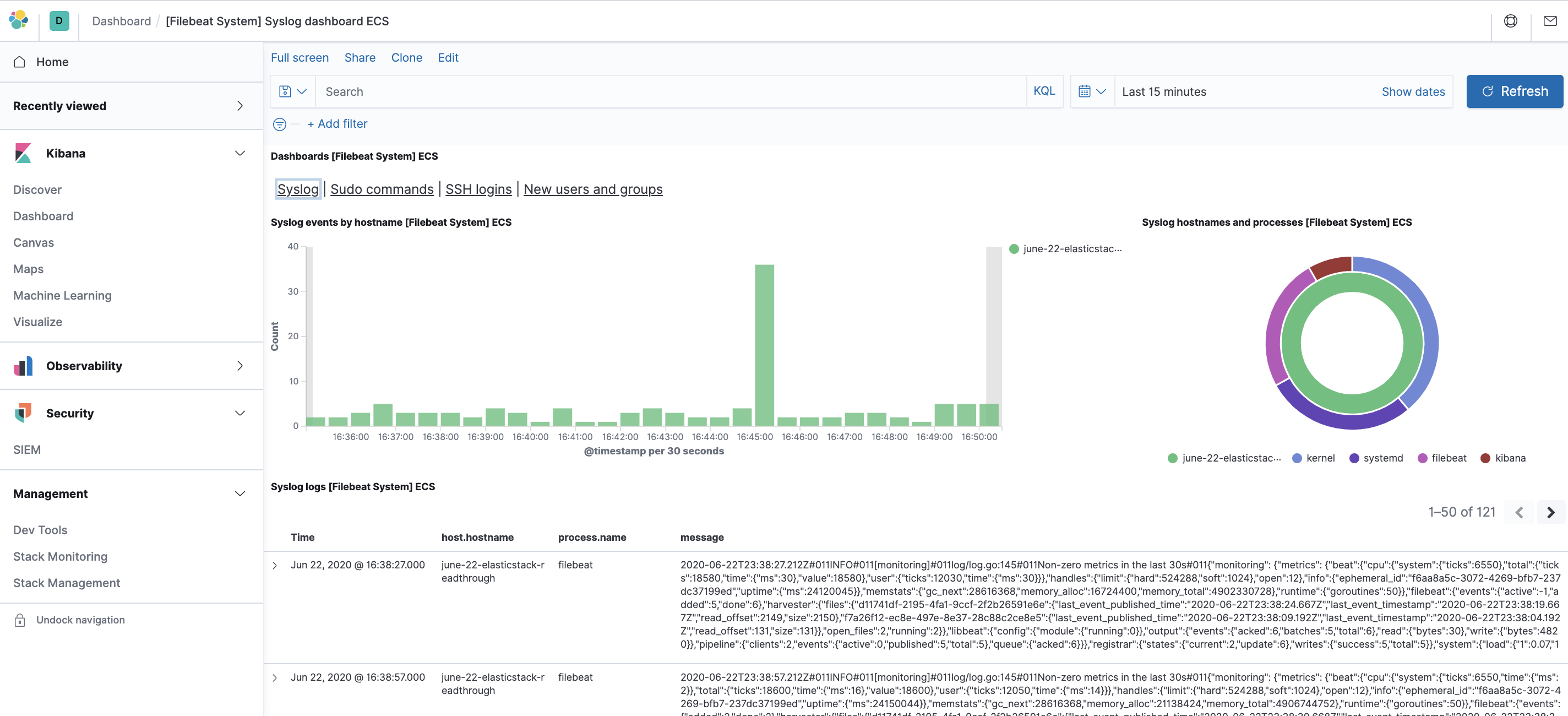
Также вы сможете видеть, какие пользователи использовали команду sudo и когда:
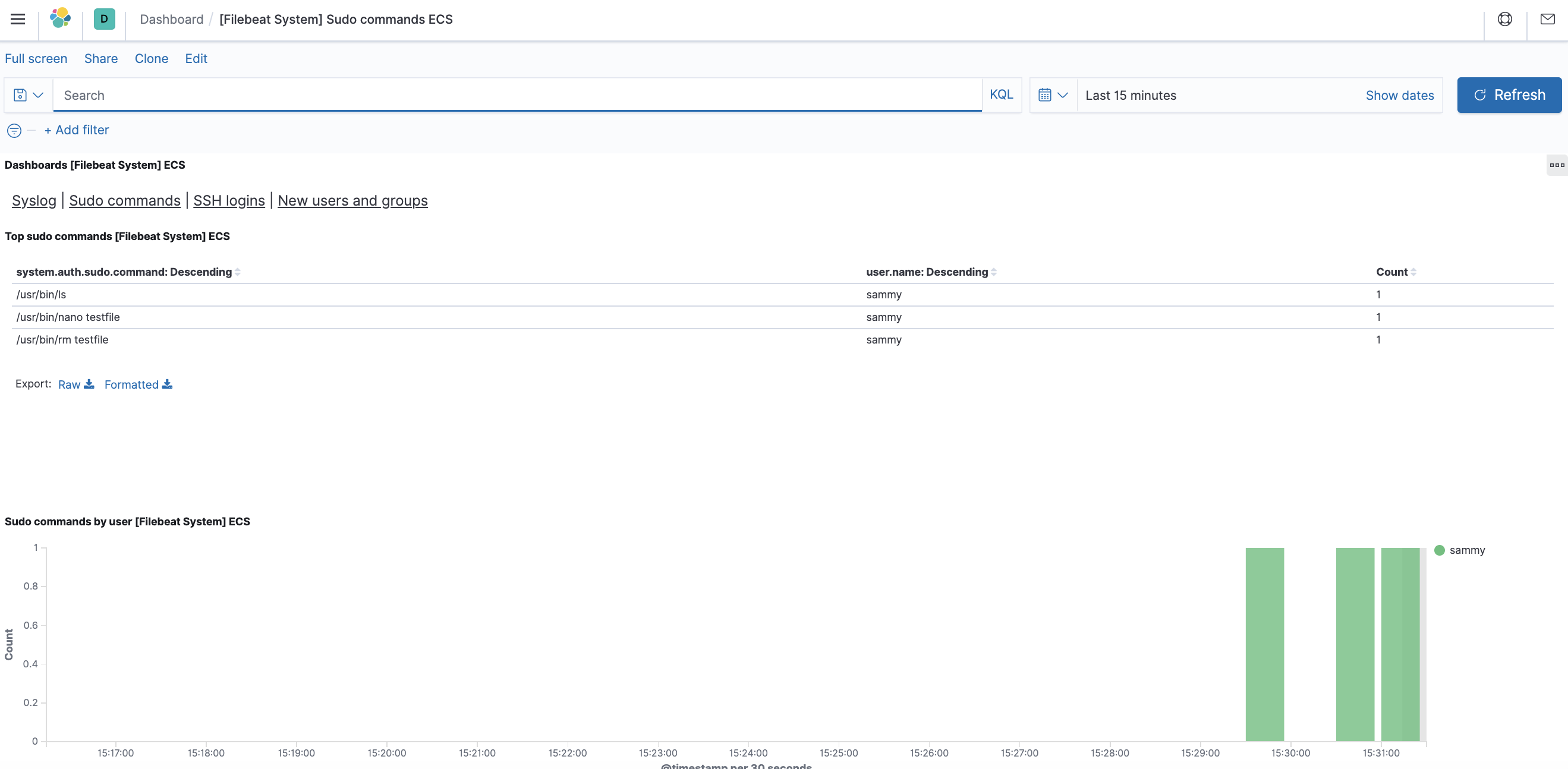
В Kibana имеется множество других функций, в том числе функции фильтрации и составления диаграмм, так что вы можете свободно их исследовать.
Заключение
В этом обучающем модуле вы научились устанавливать и настраивать комплекс Elastic Stack для сбора и анализа данных системных журналов. Помните, что вы можете отправлять в Logstash практически любые типы данных журнала и индексированных данных с помощью Beats, однако данные будут более полезны, если они будут проанализированы и структурированы с помощью фильтра Logstash, который преобразует данные в единый формат, легко читаемый Elasticsearch.
В сегодняшней статье мы поговорим про движок полнотекстового поиска и аналитики Elasticsearch. Программа очень быстро развивается, соответственно, увеличивается круг её применения. Изначально Elasticsearch использовался для поиска на сайтах, но сейчас он развился в полноценную базу данных и может применяться для аналитической обработки больших массивов данных, анализа логов серверов и многих других задач.
Тем не менее на русском языке не так много хороших инструкций, описывающих работу этой платформы. Дальше мы рассмотрим, как установить Elasticsearch, а также познакомимся с основами создания и использования индексов, управлением данными и группировкой. В общем, расскажу обо всём, что я узнал об этой программе за последние несколько недель работы с ней.
Системные требования Elasticsearch
Во-первых, надо обратить внимание на системные требования. В официальной документации заявлено, что программа будет идеально работать на машине с 64 Гб оперативной памяти, а минимальный объём - 8 Гб. И это понятно, потому что платформа работает на Java. Но это для производственных масштабов.
От себя же могу сказать, что с обработкой 1 млрд строк данных Elasticsearch неплохо справляется и на машине с 2 Гб, не так быстро как хотелось бы, но там, где MySQL задумывалась на несколько минут, Elasticsearch выдаёт результат почти мгновенно. Однако для машин с небольшим количеством ОЗУ нужна дополнительная настройка.
К процессору особых требований нет, что касается дисков, то разработчики советуют использовать SSD, так как они позволят быстрее выполнять операции индексирования и чтения данных с диска.
Установка Elasticsearch в Ubuntu
Elasticsearch - это оболочка для библиотеки Lucene, которая написана на Java. А поэтому для установки платформы вам необходимо установить Java. Разработчики рекомендуют использовать Java 8 версии 1.8.0_131 или выше. Мы будем рассматривать установку на примере Ubuntu. Установим OpenJDK:
Смотрим версию Java:
Если у вас уже установлена другая версия, то этот шаг можно пропустить. Затем добавляем репозиторий Elasticsearch:
sudo apt-get install apt-transport-https
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
И установка ElasticSearch:
sudo apt-get update && sudo apt-get install elasticsearch
В rpm дистрибутивах достаточно просто скачать и установить rpm пакет.
Настройка Elasticsearch
После завершения установки Elasticsearch нужно запустить и добавить в автозагрузку его службу, для этого выполните:
sudo systemctl start elasticsearch
sudo systemctl enable elasticsearch
Для машин с небольшим количеством ОЗУ нужно ограничить количество памяти, потребляемой программой. Для этого откройте файл /etc/elasticsearch/jvm.options и измените значение опций -Xms и -Xmx на то количество памяти, которое вы хотите, чтобы программа использовала. Например:
Теперь нужно перезапустить сервис:
sudo systemctl restart elasticsearch
Использование Elasticsearch
1. Просмотр версии Elasticsearch
Опция -X задаёт протокол, который мы используем. В этой статье мы используем не только GET, но и POST, PUT, DELETE и другие. Если вы только что перезапустили сервис и получаете ошибку "http://localhost:9200 - conection refused", то ничего страшного - система загружается, надо подождать несколько минут.
Если будете пытаться ей помешать, можете потерять уже проиндексированные данные. Просто убедитесь, что сервис уже запущен (active) командой:
sudo systemctl status elasticsearch
Когда платформа загрузиться, вы получите такой ответ:
2. Список индексов Elasticsearch
Точно так же, как MySQL может иметь несколько баз данных, Elastic может иметь несколько индексов. У каждого из них может быть несколько отдельных таблиц (type), каждая из которых будет содержать документы (doc), которые можно сравнить с записями в таблице MySQL.
Чтобы посмотреть текущий список индексов, используйте команду _cat:
Общий синтаксис использования глобальных команд такой:
curl 'localhost:9200/ _команда / имя ? параметр1 & параметр2 '
- _команда - обычно начинается с подчеркивания и указывает основное действие, которое надо сделать;
- имя - параметр команды, указывает, над чем нужно выполнить действие, или уточняет, что надо делать;
- параметр1 - дополнительные параметры, которые влияют на отображение, форматирование, точность вывода и так далее;
Например, команда _cat также может отобразить общее "здоровье" индексов (health) или список активных узлов (nodes). Параметр v включает более подробный вывод, а pretty сообщает, что надо форматировать вывод в формате json (чтобы было красиво).
3. Индексация данных
Вообще, вам не обязательно создавать индекс. Вы можете просто начать записывать в него данные, как будто бы он и таблица уже существует. Программа создаст всё автоматически. Для записи данных используется команда _index. Вот только однострочной команды curl нам будет уже недостаточно, надо добавить ещ сами данные в формате json, поэтому создадим небольшой скрипт:
Здесь я записываю данные: индекс app, таблицу data. Так как они не существуют, система их создаст. Как видите, сами данные нам нужно передать в формате json. Передаём заголовок с помощью опции -H, будем отсылать json, а потом с помощью -d передаём сами данные. Данные представляют из себя четыре(точно?, а то я просто вижу 3) поля:
Нам следует ещё остановиться на синтаксисе формата json:
"имя_поля" : "значение_поля" ,
"имя_поля1" : "значение_поля" ,
"имя_поля2" :
"имя_поля3" : "значение поля",
"имя_поля4" : [ "значение1", "значение2" ]
>
>
Если вы знакомы с JavaScript, то уже знаете этот формат. Если нет, то ничего страшного, сейчас разберёмся. Данные представляются в виде пар имя: значение. И имя поля, и его значение нужно брать в кавычки и разделять их двоеточием. Каждая пара отделяется от следующей с помощью ?ЭТО ЧТО ЗА ЗВЕРЬ ТАКОЙ? комы& . Но если пар больше нет, то кома не ставится. Причём каждое поле может иметь в качестве значения либо текст, либо ещё один набор полей, заключённый в фигурные скобки <>. Если нужно перечислить два элемента без названия поля, надо использовать не фигурные скобки, а квадратные [] (массив), как в поле4. Для удобства форматирования используйте пробелы, табуляции Elasticsearch не понимает.
Теперь сохраняем скрипт и запускаем:
Это значит, что документ добавлен в индекс. Теперь вы можете снова посмотреть список индексов.
4. Информация об индексе
Мы знаем список созданных индексов, но как посмотреть список типов (таблиц) в индексе и как узнать, какие и каких типов поля созданы в индексе? Для этого можно использовать команду _mapping. Но перед тем, как мы перейдём к ней, надо вернуться к синтаксису. Команды могут применяться как к глобально, так и для отдельного индекса или для отдельного типа. Синтаксис будет выглядеть так:
curl 'localhost:9200/ индекс / тип / _команда / имя ? параметр1 & параметр2 '
Чтобы посмотреть все индексы и их поля, можно применить команду глобально:
Или только для индекса app:
Только для типа data индекса app:
В результате программа вернула нам ответ, в котором показан индекс app, в нём есть тип data, а дальше в поле properties перечислены все поля, которые есть в этом типе: age, degree и name. Каждое поле имеет свои параметры.
5. Информация о поле и мультиполя
Каждое поле описывается таким списком параметров:
"age" :
"type" : "text" ,
"fields" :
"keyword" :
"type" : "keyword" ,
"ignore_above" : 256
>
>
>
Параметр type - указывает тип поля. В данном случае программа решила, что это текст, хотя это число. Дальше интереснее, у нас есть ещё параметр fields. Он задаёт так называемые подполя или мультиполя. Поскольку Elasticsearch - это инструмент поиска текста, то для обработки текста используются анализаторы, нормализаторы и токенизаторы, которые могут приводить слова к корневой форме, переводить текст в нижний регистр, разбивать текст на отдельные слова или фразы. Вс` это нужно для поиска и по умолчанию применяется к каждому текстовому полю.
Но если вам нужно просто проверить точное вхождение фразы без её изменений, то с проанализированным таким образом полем у вас ничего не получиться. Поэтому разработчики придумали мультиполя. Они содержат те же данные, что и основное поле, но к ним можно применять другие анализаторы, или вообще их не применять. В нашем примере видно, что система автоматически создала подполе типа keyword, которое содержит неизмененный вариант текста.
Таким образом, если вы захотите проверить точное вхождение, то нужно обращаться именно к полю age.keyword а не к age. Или же отключить анализатор для age. Анализаторы выходят за рамки этой статьи, но именно эта информация нам ещё понадобится дальше.
6. Удаление индекса
Чтобы удалить индекс, достаточно использовать вместо GET протокол DELTE и передать имя индекса:
Теперь индекс удалён. Создадим ещё один такой же вручную.
7. Ручное создание индекса
Программа создала для цифр текстовые поля, к ним применяется анализ текста и индексация, а это потребляет дополнительные ресурсы и память. Поэтому лучше создавать индекс вручную и настраивать такие поля, какие нам надо. Первых два поля сделаем int без подполей, а третье оставим как есть. Запрос будет выглядеть так:
curl -XPUT 'http://localhost:9200/app?pretty ' -H 'Content-Type: application/json' -d '
"mappings" : "data" : "properties" : "age" : "type" : "integer"
>,
"degree" : "type" : "integer"
>,
"name" : "type" : "text",
"fields" : "keyword" : "type" : "keyword",
"ignore_above" : 256
>
>
>
>
>
>
>'
Как видите, здесь используется тот же синтаксис, который программа возвращает при вызове команды _mapping. Осталось запустить скрипт, чтобы создать индекс:
Чтобы всё прошло нормально, необходимо удалить индекс, который был создан автоматически, поэтому предыдущий пункт расположен там не зря. Вы можете менять mappings для существующего индекса, но в большинстве случаев для применения изменений к существующим данным индекс надо переиндексировать. Например, если вы добавляете новое мультиполе, то в нём можно будет работать только с новыми данными. Старые данные, которые были там до добавления, при поиске будут недоступны.
5. Массовая индексация данных
Дальше я хотел бы поговорить о поиске, условиях и фильтрации, но чтобы почувствовать полную мощьность всех этих инструментов нам, нужен полноценный индекс. В качестве индекса мы будем использовать один из демонстрационных индексов, в который разложены пьесы Шекспира. Для загрузки индекса наберите:
В файле находятся данные в формате json, которые надо проиндексировать. Это можно сделать с помощью команды _bluck:
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/shakespeare/doc/_bulk?pretty' --data-binary @shakespeare_6.0.json
Индексация работает так же, как и при ручном добавлении данных, но благодаря оптимизации команды _bluck, выдаёт результат намного быстрее.
6. Поиск по индексу
Для поиска или, другими словами, выборки данных в Elasticsearch используется команда _search. Если вызвать команду без параметров, то будут обрабатываться все документы. Но выведены будут только первые 10, потому что это ограничение по умолчанию:
Здесь мы выбрали первые десять документов из индекса shakespeare и таблицы doc. Чтобы выбрать больше, передайте параметр size со значением, например 10000:
Самый простой пример поиска - передать поисковый запрос в параметре q. При этом поиск Elasticsearch будет выполняться во всех полях индекса. Например, найдём все, что касается Эдгара (EDGAR):
Но как вы понимаете, всё это очень не точно и чаще всего надо искать по определённым полям. В Elasticsearch существует несколько типов поиска. Основные из них:
- term - точное совпадение искомой строки со строкой в индексе или термом;
- match - все слова должны входить в строку, в любом порядке;
- match_phrase - вся фраза должна входить в строку;
- query_string - все слова входят в строку в любом порядке, можно искать по нескольким полям, используя регулярные выражения;
Синтаксис term такой:
" query "
" term "
" имя_поля ": " что искать "
>
>
Например, найдем записи, где говорит Эдгар с помощью term:
Мы нашли десять реплик, которые должен сказать Эдгар. Дальше испытаем неточный поиск с помощью match. Синтаксис такой же, поэтому я его приводить не буду. Найдём предложения, которые содержат слова of love:
С query_string и match_phrase разберётесь сами, если будет нужно.
8. Операторы AND и OR для поиска
Если вы хотите сделать выборку по нескольким полям и использовать для этого операторы AND и OR, то вам понадобится конструкция bool. Синтаксис её такой:
"query" :
"bool" :
"must" : [
< "поле1" : "условие" >,
< "поле2" : "условие" >,
],
"filter" : <>,
"must_not" : <>
"should" : <>
>
>
Обратите внимание на синтаксис. Поскольку у нас два элемента подряд, мы используем массив []. Но так как дальше нам снова нужно создавать пары ключ:значение, то в массиве открываются фигурные скобки. Конструкция bool объединяет в себе несколько параметров:
- must - все условия должны вернуть true;
- must_not - все условия должны вернуть false;
- should - одно из условий должно вернуть true;
- filter - то же самое что и match, но не влияет на оценку релевантности.
Например, отберём все записи, где Helen говорит про любовь:
Как видите, найдено только два результата.
9. Группировка
И последнее, о чём мы сегодня поговорим, - группировка записей в Еlasticsearch и суммирование значений по ним. Это аналог запроса GOUP BY в MySQL. Группировка выполняется с помощью конструкции aggregations или aggs. Синтаксис её такой:
"aggregations" :
"название" :
"тип_группировки" :
параметры
>,
дочерние_группировки
>
>
Разберём по порядку:
- название - указываем произвольное название для данных, используется при выводе;
- тип_группировки - функция группировки, которая будет использоваться, например terms, sum, avg, count и так далее;
- параметры - поля, которые будем группировать и другие дополнительные параметры;
- дочерние группировки - в каждую группировку можно вложить ещё одну или несколько других таких же группировок, что делает этот инструмент очень мощным.
Давайте подсчитаем, сколько отдельных реплик для каждого человека. Для этого будем использовать группировку terms:
В результате запроса Еlasticsearch получим:
Сначала пойдут все найденные документы, а затем в разделе aggregations мы увидим наши значения. Для каждого имени есть doc_count, в котором содержится количество вхождений этого слова. Чтобы продемонстрировать работу вложенных группировок, давайте найдём сумму и среднее значение поля line_number для каждого участника:
В сумме у нас очень большие числа, поэтому они отображаются в экспоненциальном формате. А вот в среднем значении всё вполне понятно.
"key" : "DUKE VINCENTIO",
"doc_count" : 909,
"total_number" : "value" : 5.4732683E7
>,
"avg_number" : "value" : 60211.97249724973
>
>
Тут key - имя персонажа, total_number.value - сумма поля, avg_number.value - среднее значение поля.
Выводы
Пожалуй это всё, статья и так очень сильно затянулась. Но и этого материала будет вполне достаточно, чтобы начать использование Elasticsearch в своих проектах. Понятно, что вы не будете там пользоваться curl, у программы есть библиотеки для различных языков программирования, в том числе и для php. Если вы нашили ошибки или неточности в описании работы Еlasticsearch, поправьте меня в комментариях!
Нет похожих записей
Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна.
Оцените статью:
(10 оценок, среднее: 4,50 из 5)Об авторе
13 комментариев
Вода вода вода
Зачем писать как работает json?!
And и or если в примере только and
must - and, should - or.
Хорошая статья. Длина - только плюс.
Тем, кому не нравятся - читайте про так как МС установить.
Можно ли cvs формат загрузить в еластик?
Спасибо! Материал действительно оказался очень полезным! В закладки.
Подскажите, если не зашло, как удалить elasticsearch с сервера? какой командой?
yum remove elasticsearch, а затем вручную удалите репозиторий /etc/yum.repos.d/elasticsearch.repo и удалите папку с индексами: /var/lib/elasticsearch
Большое спасибо. Уже месяц читаю ваш сайт, добавил в закладки, много полезного.
И сайт хороший и полезный и статья тоже. по ней и устанавливал, а критики покажите свой сайт и свои статьи, которые лучше этих. а если нет, то и не надо тут.
но я столкнулся с еще одной интересной задачей. стоит на сервере версия эластика 1.6, а хочется поставить хотя бы 6 серию, или 7ю. а у них совсем разный синтаксис и команды. пробовал просто механически на новой версии запустить. но посыпались ошибки. причем пемяю то на что жалуется, на то что само же и предлагает, а ошибки не прекращаются. долго не занимался, понял после очередного исправления, что тут без плана перехода не обойтись, а в инете все обрывочно и в основном тоже вопросы, а не ответы. если есть возможность и нужна тема для очередной статьи, прошу рассмотреть делать статью о переходе с версии 1 серии на относительно новую не менее 5й по Вашему выбору. пусть даже в основном переведенная, ибо лучшего я еще не нашел.
уточнение. содержимое индекса вообще не нужно сохранять. сайт так сконфигурирован, что через час даже не надо вспоминать что индекс был удален. а в основном все статьи как раз на сохранение индекса, а не сам перевод кода сайта, который у меня на пхп сделан.
Добрый день
Полезная статья, очень
А как удалить не один индекс, а несколько ? А место на диске освободится после удаления ?
А как настроить elasticsearch, чтобы квота на свободное место была не 90%, а скажем 95 ?
Борюсь с ошибкой high disk watermark 90 exceeded on
Elasticsearch — это платформа для распределенного поиска и анализа данных в режиме реального времени. Она пользуется популярностью благодаря удобству в использовании, наличию мощных характеристик и возможности масштабирования.
Эта статья расскажет вам о том, как установить Elasticsearch, настроить платформу под ваш вариант использования, обеспечить безопасность установки и начать работу с вашим сервером Elasticsearch.
Предварительные требования
Для работы с этим обучающим руководством вам потребуется следующее:
Сервер Ubuntu 18.04 с 4 ГБ оперативной памяти и 2 процессорами, настроенный пользователем sudo без прав root. Вы можете это сделать, воспользовавшись рекомендациями по Начальной настройке сервера с Ubuntu 18.04
Установленный OpenJDK 11
В этом обучающем модуле мы будем использовать минимальное количество процессоров и оперативной памяти, необходимое для работы с Elasticsearch. Обратите внимание, что требования сервера Elasticsearch к количеству процессоров, оперативной памяти и хранению данных зависят от ожидаемого объема журналов.
Шаг 1 — Установка и настройка Elasticsearch
Компоненты Elasticsearch отсутствуют в репозиториях пакетов Ubuntu по умолчанию. Однако их можно установить с помощью APT после добавления списка источников пакетов Elastic.
Все пакеты подписаны ключом подписи Elasticsearch для защиты вашей системы от поддельных пакетов. Ваш диспетчер пакетов будет считать надежными пакеты, для которых проведена аутентификация с помощью ключа. На этом шаге вы импортируете открытый ключ Elasticsearch GPG и добавите список источников пакетов Elastic для установки Elasticsearch.
Для начала используйте cURL, инструмент командной строки для передачи данных с помощью URL, для импорта открытого ключа Elasticsearch GPG в APT. Обратите внимание, что мы используем аргументы -fsSL для подавления всех текущих и возможных ошибок (кроме сбоя сервера), а также, чтобы разрешить cURL подать запрос на другой локации при переадресации. Выведите результаты команды cURL в программу apt-key, которая добавит открытый ключ GPG в APT.
Затем добавьте список источников Elastic в каталог sources.list.d , где APT будет искать новые источники:
Затем обновите списки пакетов, чтобы APT мог прочитать новый источник Elastic:
Установите Elasticsearch с помощью следующей команды:
Теперь система Elasticsearch установлена и готова к настройке.
Шаг 2 — Настройка Elasticsearch
Для настройки Elasticsearch мы отредактируем файлы конфигурации. В Elasticsearch имеется три файла конфигурации:
- elasticsearch.yml для настройки Elasticsearch, главный файл конфигурации
- jvm.options для настройки виртуальной машины Elasticsearch Java Virtual Machine (JVM)
- log4j2.properties для настройки журнала Elasticsearch
Для целей настоящего обучающего модуля нас интересует файл elasticsearch.yml , где хранится большая часть параметров конфигурации. Этот файл находится в каталоге /etc/elasticsearch .
Используйте предпочитаемый текстовый редактор для изменения файла конфигурации Elasticsearch. Мы будем использовать nano :
Примечание. Файл конфигурации Elasticsearch представлен в формате YAM. Это означает, что нам нужно сохранить формат отступов. Не добавляйте никакие дополнительные пробелы при редактировании этого файла.
Файл elasticsearch.yml предоставляет варианты конфигурации для вашего кластера, узла, пути, памяти, сети, обнаружения и шлюза. Большинство из этих вариантов уже настроены в файле, но вы можете изменить их в соответствии с вашими потребностями. В нашем случае для демонстрации односерверной конфигурации мы будем регулировать настройки только для хоста сети.
Elasticsearch прослушивает весь трафик порта 9200 . По желанию вы можете ограничить внешний доступ к вашему экземпляру Elasticsearch, чтобы посторонние не смогли прочесть ваши данные или отключить ваш кластер Elasticsearch через REST API. Для ограничения доступа и повышения безопасности найдите строку с указанием network.host , уберите с нее значок комментария и замените значение на localhost , чтобы она выглядела следующим образом:
Мы указали localhost , и теперь Elasticsearch прослушивает все интерфейсы и связанные IP-адреса. Если вы хотите, чтобы прослушивался только конкретный интерфейс, вы можете указать его IP-адрес вместо localhost . Сохраните и закройте elasticsearch.yml . Если вы используете nano , вы можете сделать это, нажав CTRL+X , затем Y , а затем ENTER .
Это минимальные настройки, с которыми вы можете начинать использовать Elasticsearch. Теперь вы можете запустить Elasticsearch в первый раз.
Затем запустите следующую команду, чтобы активировать Elasticsearch при каждой загрузке сервера:
Мы включили Elasticsearch при запуске и теперь перейдем к следующему шагу для обсуждения вопросов безопасности.
Шаг 3 — Защита Elasticsearch
После этого вы можете активировать UFW с помощью команды:
В заключение проверьте статус UFW с помощью следующей команды:
Если вы правильно задали правила, результат должен выглядеть так:
Теперь UFW должен быть активирован и настроен на защиту порта Elasticsearch 9200.
Если вы хотите инвестировать в дополнительную защиту, Elasticsearch предлагает к покупке платный плагин Shield.
Шаг 4 — Тестирование Elasticsearch
Сейчас система Elasticsearch должна работать на порту 9200 Вы можете протестировать ее с помощью cURL и запроса GET.
Вы должны увидеть следующий ответ:
Если вы получите ответ, аналогичный вышеуказанному, значит Elasticsearch работает корректно. Если нет, убедитесь, что вы правильно выполнили инструкции по установке и дали время системе Elasticsearch для полного запуска.
Для более тщательной проверки Elasticsearch выполните следующую команду:
В выводе для команды, указанной выше, вы можете проверить все текущие настройки для узла, кластера, путей приложения, модулей и т.д.
Шаг 5 — Использование Elasticsearch
Чтобы начать использовать Elasticsearch, в первую очередь нужно добавить некоторые данные. Elasticsearch использует RESTful API, который соответствует обычным командам CRUD: create, read, update и delete. Для работы мы снова используем команду cURL.
Ваша первая запись может выглядеть так:
Вы должны получить следующий ответ:
- tutorial — это индекс данных в Elasticsearch.
- helloworld — это тип.
- 1 — это ID нашей записи по индексу и типу.
Вывод должен выглядеть следующим образом:
Elasticsearch должна признать успешное изменение следующим образом:
В примере, представленном выше, мы изменили message первой записи на “Hello, People!”. При этом номер версии автоматически увеличился до 2 .
Возможно, вы заметили дополнительный аргумент pretty в представленном выше запросе. Он обеспечивает удобный для восприятия человеком формат, и вы можете для написания каждого поля данных использовать новый ряд. Вы также можете “приукрасить” ваши результаты при получении данных, чтобы получить более читабельный вывод, путем введения следующей команды.
Теперь ответ отформатирован так, чтобы синтаксис был удобен для человека:
Мы добавили и запросили данные в Elasticsearch. Информацию о других операциях можно найти в документации API.
Заключение
Вы установили, настроили и начали использовать Elasticsearch. С момента первоначального выпуска Elasticsearch команда Elastic разработала три дополнительных инструмента, Logstash, Kabana и Beats, предназначенные для использования совместно с Elasticsearch в составе комплекса Elastic. Вместе эти инструменты обеспечивают возможность поиска, анализа и визуализации журналов в любом формате, сгенерированных любым источником, посредством практики, называемой централизованным ведением журнала. Чтобы познакомиться с использованием комплекса Elastic в Ubuntu 18.04, воспользуйтесь нашим руководством Установка Elasticsearch, Logstash и Kibana (комплекс Elastic) в Ubuntu 18.04.
Читайте также: