Как запустить tensorboard на windows
Обновлено: 04.07.2024
Создание и обучение нейронных сетей не простой процесс, если вы не играете с набором данных MNIST, своего рода приложением «Hello world» в мире глубокого обучения. Очень легко совершить ошибку и потратить несколько дней на размышления о том, почему сеть не имеет ожидаемой производительности. Как правило, библиотеки глубокого обучения имеют некоторый API, позволяющий исследовать модели и поведение моделей во время обучения. Но они довольно ограничены и требуют дополнительного программирования для визуализации. В этой статье мы будем использовать TensorBoard для визуализации обучения CNN. Например, мы будем использовать семантическую сегментацию дляНабор данных ISBI Challenge 2012, Полный код этой статьи можно найти наGithub,
Что такое TensorBoard?
TensorBoard - это инструмент для визуализации графиков TensorFlow, количественных метрик выполнения графиков и дополнительных данных, которые могут помочь вам понять поведение вашей нейронной сети.
С точки зрения программного обеспечения TensorBoard - это веб-сервер, который отслеживает некоторые каталоги и отображает данные, хранящиеся в его файлах, в виде графиков, графиков, гистограмм, изображений и т. Д. Программа TensorFlow снабжает каталог данными во время выполнения. Сервер читает данные и визуализирует их. Разработчик должен решить, какие данные должны быть показаны. TensorBoard может рисовать скалярные графики (например, линейные графики потерь, точности), изображения (например, изображения с текущим прогнозом), гистограммы (как распределение весов). В дополнение к этому TensorBoard может показать вашу модель в виде интерактивного графика.
Использовать сервис TensorBoard очень просто: добавьте в свой программный код, который записывает промежуточные данные обучения, запустите TensorBoard, и вы сможете отслеживать ход обучения вашей модели.
TensorBoard предустановлен с помощью TensorFlow. Следующая команда запускает службу TensorBoard:
гдебревнапуть к каталогу с данными для мониторинга.
Если вы хотите запустить TensorBoard на определенном порту, вы можете использоватьпортпараметр:
По умолчанию TensorBoard работает только на локальном хосте. параметрbind_allпозволяет связывание на всех сетевых интерфейсах.
Кроме того, вы можете указать имя хоста или IP-адрес, используяхозяинпараметр для выставления TensorBoard на конкретный хост.
Как записать свои данные?
TensorFlow предоставляет набор API для сериализации ваших данных в формате, понятном TensorBoard. Доступны следующие функции сериализации:
- скаляр- записывает историю одного значения, такого как потеря, точность и т. Д.
- образ- пишет историю изображения.
- гистограмма- пишет историю распространения данных некоторого тензора.
- текст- записывает историю тензора строкового типа.
- аудио- записывает историю аудиосэмпла (тензор, содержащий аудиоданные).
- tensor_summary- пишет историю произвольного тензора.
Каждая из функций принимает тензор в качестве входных данных и возвращает строку protobuf, которая может быть записана на дискFileWriterобъект. Кроме того, резюме могут быть объединены в коллекции с использованием функцийслияниеа такжеmerge_all.
Если вы используете Keras, вам не нужно использовать функции напрямую. Керас обеспечивает удобныйTensorBoardобратный вызов, который сделает большую часть работы за вас.
Одна из приятных особенностей TensorBoard - это возможность показывать метрики нескольких трасс на одном графике. Таким образом, можно сравнить поведение модели с различными гиперпараметрами. Вам нужно только сохранить журналы разных запусков в разных подкаталогах папки TensorBoard. Вы всегда можете включить / выключить визуализацию трасс.
В следующем примере мы будем использовать TensorBoard для визуализации обучения модели для сегментации нейронных структур в стеках EM (Набор данных ISBI Challenge).
Описание набора данных
Обучающие данные представляют собой набор из 30 изображений из серийной секции просвечивающей электронной микроскопии (ssTEM).
Соответствующие двоичные метки предусмотрены как входящие, то есть белые для пикселей сегментированных объектов и черные для остальных пикселей (которые в основном соответствуют мембранам).
Другими словами, у нас есть 30 изображений в градациях серого, объединенных в один файл TIFF (каждое изображение на отдельной странице) и 30 черно-белых масок, объединенных в другой файл TIFF.

Очевидно, что 30 изображений недостаточно для обучения сверточной сети, поэтому используется увеличение, такое как вращение, сдвиг, сдвиг, масштабирование и отражение.
Сетевая архитектура

Модель выше реализована в Керасе. Полный исходный код можно найти вGithub хранилище,
Keras предоставляет удобную функцию обратного вызова, которая делает использование TensorBoard намного проще.
В этой статье мы будем использовать следующие параметры:
- log_dir- путь к каталогу, в котором должны быть сохранены данные.
- histogram_freq- как часто гистограммы весов должны быть сохранены. 1 - для каждой эпохи, 2 - для каждой второй эпохи и т. Д.
- write_graph -логический флаг. Истинно, если график модели должен быть сохранен.
- update_freq -как часто данные должны быть сериализованы. Возможные значения: «партия» для каждой партии, «эпоха» для каждой эпохи или целое число, которое определяет частоту сериализации в количестве выборок.
Сетевые графики
Настройка параметраwrite_graphвПравдазапускает сериализацию графа модели. Важно дать вашим слоям понятные имена, чтобы вы могли распознать их на диаграмме. Изображение ниже было создано TensorBoard для архитектуры U-net, использованной в этой статье. Обратите внимание, что график очень похож на рисунок сети выше. Приятной особенностью TensorBoard является окрашивание слоев одинаковой структуры в один цвет.

Скалярные участки
параметрupdate_freqконтролирует частоту сериализации метрик. В этой статье, в дополнение кпотерямы сериализуемточностьи пользовательская метрика - относительное количество ошибочно классифицированных пикселей:
Примечание: функция будет выполняться во время обучения, поэтому мы должны использовать функции TensorFlow для манипулирования тензорами. Numpy функции здесь не сработают.
Это весь код, который вам нужно написать для сериализации графика и метрик модели для TensorBoard. Обратите внимание, что в этом примере каталог TensorBoard содержит имя функции потерь и скорость обучения. Так как я хотел изучить, как моя модель сходится с разной функцией потерь и разными скоростями, я выводил файлы для каждого прогона в отдельном подкаталоге папки журнала. Это позволяет мне сравнивать визуально разные прогоны на одном графике и сравнивать производительность модели:

Гистограмма и графики распределения
Настройка параметраhistogram_freq1 приводит к сериализации веса и активации сетевых уровней для каждой эпохи. Два новых пункта меню:распределенияа такжегистограммпоявляются на панели инструментов TensorBoard. Важно знать, что мы не можем использовать генераторы для данных проверки, если мы хотим визуализировать гистограммы. TensorFlow выдаст ошибку, если вы попытаетесь это сделать.


Сериализация пользовательских изображений
Обратный вызов Keras TensorBoard предоставляет параметрwrite_imagesкоторый запускает сериализацию изображений сетевых слоев. Для семантической сегментации полезно визуализировать результат прогнозирования, чтобы получить представление о том, насколько хорошо работает сеть. Это возможно путем создания пользовательского обратного вызова и использования TensorFlow Summary API для изображений. Давайте посмотрим на структуру пользовательского обратного вызова Keras:
Класс пользовательского обратного вызова содержит несколько методов, которые будут выполняться для определенного события. Для отслеживания прогресса процесса обучения мы используем метод on_batch_end и создаем изображения результатов прогнозирования и соответствующие метки для каждой партии.
Теперь мы создаем экземпляр класса и добавляем его в список обратных вызовов.
А теперь - начните тренировку, запустите TensorBoard и следите за прогрессом. На рисунке ниже показан снимок экрана с приборной панелью TensorBoard, в которой сравнивается прогресс сегментации для среднеквадратичной ошибки и бинарных функций кросс-энтропийной потери.

Я нашел TensorBoar очень полезным для мониторинга процесса обучения модели. Это позволяет визуализировать промежуточные шаги с помощью нескольких строк кода.
В этой статье вы узнаете, как просматривать запуски и метрики экспериментов в TensorBoard с помощью пакета tensorboard в основном пакете SDK Машинного обучения Azure. Изучив запуски экспериментов, вы сможете лучше настроить и переобучить модели машинного обучения.
TensorBoard — это набор веб-приложений для проверки и понимания структуры и производительности эксперимента.
Способ запуска TensorBoard с экспериментами Машинного обучения Azure зависит от типа эксперимента.
Если ваш эксперимент самостоятельно выводит файлы журналов, которые могут использоваться TensorBoard, например PyTorch, Chain или TensorFlow, то можно запустить TensorBoard напрямую из журнала выполнения эксперимента.
Для экспериментов, которые не выводят файлы, которые понимает TensorBoard, например Scikit-learn или Машинное обучение Azure, используйте метод export_to_tensorboard() , чтобы экспортировать журналы запуска в виде журналов TensorBoard, и запустите TensorBoard из них.
Сведения в этом документе предназначены главным образом для специалистов по обработке и анализу данных и разработчиков, желающих отслеживать процесс обучения модели. Если вы являетесь администратором, который заинтересован в наблюдении из Машинного обучения Azure за использованием ресурсов и событиями, такими как квоты, завершенные обучающие запуски или завершенные развертывания моделей, см. раздел Мониторинг Машинного обучения Azure.
Предварительные требования
- Чтобы запустить TensorBoard и просмотреть журналы запуска экспериментов, необходимо предварительно включить в экспериментах ведение журнала для отслеживания метрик и производительности.
- Код в этом документе можно запустить в любой из следующих сред.
- Вычислительная операция Машинного обучения Azure — загрузка или установка не требуется
- Следуйте инструкциям из документа Краткое руководство по началу работы со службой "Машинное обучение Azure", чтобы создать выделенный сервер записной книжки с заранее загруженным пакетом SDK и образцом репозитория.
- В папке samples на сервере записных книжек найдите две готовые и развернутые записные книжки в следующих каталогах.
- how-to-use-azureml > track-and-monitor-experiments > tensorboard > export-run-history-to-tensorboard > export-run-history-to-tensorboard.ipynb
- how-to-use-azureml > track-and-monitor-experiments > tensorboard > tensorboard > tensorboard.ipynb
-
с дополнением tensorboard . . .
Вариант 1. Просмотр журнала выполнения непосредственно в TensorBoard
Этот вариант применим для экспериментов, которые изначально выводят файлы журналов в формате TensorBoard, такие как PyTorch, Chainer и TensorFlow. Если в вашем случае это не так, используйте метод export_to_tensorboard() .
В следующем примере кода используется демонстрационный эксперимент MNIST из репозитория TensorFlow в удаленном целевом объекте вычислений среды Машинного обучения Azure. Далее мы настроим и запустим обучение модели TensorFlow, а затем запустим TensorBoard в этой экспериментальной среде TensorFlow.
Задание имени эксперимента и создание папки проекта
Здесь мы дадим эксперименту имя и создадим для него папку.
Загрузка демонстрационного кода эксперимента TensorFlow
В репозитории TensorFlow есть демонстрационная версия MNIST с расширенными инструментами TensorBoard. Для работы с Машинным обучением Azure не нужно вносить никаких изменений в этот демонстрационный код. В следующем коде мы скачиваем код MNIST и сохраняем его во вновь созданную папку эксперимента.
Настройка эксперимента
Ниже мы настроим эксперимент и укажем каталоги для журналов и данных. Эти журналы будут отправлены в журнал выполнения, к которому TensorBoard получит доступ позже.
Для этого примера необходимо установить TensorFlow на локальном компьютере. Кроме того, модуль TensorBoard (то есть модуль, входящий в состав TensorFlow) должен быть доступен для ядра этой записной книжки, так как TensorBoard выполняется именно на локальном компьютере.
Создание кластера для эксперимента
Для этого эксперимента мы создадим кластер AmlCompute, но эксперименты можно создавать в любой среде, и вы по-прежнему сможете запускать TensorBoard для журналов выполнения экспериментов.
Вы можете использовать низкоприоритетные виртуальные машины для выполнения части или всех рабочих нагрузок. Узнайте, как создать низкоприоритетную виртуальную машину.
Настройка и отправка запроса на выполнение обучения
Настройте задание обучения, создав объект ScriptRunConfig.
Запуск TensorBoard
Вы можете запустить TensorBoard во время выполнения или после завершения. В следующем примере создается экземпляр объекта TensorBoard tb , который принимает журнал запуска эксперимента, загруженный в run , а затем запускает TensorBoard с помощью метода start() .
Конструктор TensorBoard принимает массив запусков, поэтому убедитесь, что запуск передается в виде одноэлементного массива.
Хотя в этом примере мы использовали TensorFlow, вы можете с такой же легкостью использовать TensorBoard с PyTorch или Chainer. TensorFlow должен быть доступен на компьютере с TensorBoard, но не обязательно на компьютере, выполняющем вычисления PyTorch или Chainer.
Вариант 2. Экспорт журнала для просмотра в TensorBoard
Следующий код настраивает пример эксперимента, начинает процесс ведения журнала с помощью API журнала выполнения Машинного обучения Azure и экспортирует журнал запуска эксперимента в формат, который можно использовать в TensorBoard для визуализации.
Настройка эксперимента
Следующий код настраивает новый эксперимент и присваивает каталогу запуска имя root_run .
Здесь мы загружаем набор данных диабетиков — встроенный небольшой набор данных, который поставляется вместе с Scikit-learn, и разбиваем его на наборы для тестов и обучения.
Запуск эксперимента и регистрация метрик
Для этого кода мы обучаем модель линейной регрессии и регистрируем в журнале выполнения ключевые метрики, альфа-коэффициент alpha и среднеквадратическую ошибку mse .
Экспорт запусков в TensorBoard
С помощью метода export_to_tensorboard () пакета SDK можно экспортировать журнал выполнения эксперимента Машинного обучения Azure в журналы TensorBoard, чтобы мы могли просматривать их в TensorBoard.
В следующем коде мы создаем папку logdir в текущем рабочем каталоге. В эту папку мы экспортируем журнал выполнения эксперимента и журналы из root_run , а затем помечаем запуск как завершенный.
Можно также экспортировать в TensorBoard определенный запуск, указав имя запуска: export_to_tensorboard(run_name, logdir)
Запуск и остановка TensorBoard
После экспорта журнала выполнения для этого эксперимента можно запустить TensorBoard с помощью метода start().
По завершении убедитесь, что вызвали метод stop() объекта TensorBoard. В противном случае TensorBoard будет продолжать работать, пока не завершится работа ядра записной книжки.
Дальнейшие действия
В этом практическом руководстве вы создали два эксперимента и узнали, как запустить TensorBoard для своих журналов выполнения, чтобы определить области для потенциальной настройки и повторного обучения.
пример
Изображение ниже взято из графика, который вы создадите в этом уроке. Это основная панель:
![]()
На картинке ниже вы можете увидеть панель Tensorboard. Панель содержит различные вкладки, которые связаны с уровнем информации, которую вы добавляете при запуске модели.
![]()
- Скаляры: показать различную полезную информацию во время обучения модели
- Графики: показать модель
- Гистограмма: отображение весов с помощью гистограммы
- Распределение: Показать распределение веса
- Проектор: Показать анализ главных компонентов и алгоритм T-SNE. Техника использует для уменьшения размерности
В этом уроке вы научитесь простой модели глубокого обучения. Вы узнаете, как это работает, в следующем уроке.
Если вы посмотрите на график, вы сможете понять, как работает модель.
- Поставьте данные в модель: добавьте количество данных, равное размеру пакета, в модель, т. Е. Количество подачи данных после каждой итерации
- Подайте данные на Тензор
- Тренируй модель
- Показать количество партий во время тренировки. Сохраните модель на диске.
![]()
Основная идея тензорной доски заключается в том, что нейронная сеть может называться черным ящиком, и нам нужен инструмент для проверки того, что находится внутри этого ящика. Вы можете представить себе тензорную доску в качестве фонарика, чтобы начать погружение в нейронную сеть.
Это помогает понять зависимости между операциями, как вычисляются веса, отображает функцию потерь и много другой полезной информации. Когда вы соберете все эти фрагменты информации вместе, у вас появится отличный инструмент для отладки и поиска способов улучшения модели.
Чтобы дать вам представление о том, насколько полезным может быть график, посмотрите на рисунок ниже:
![]()
Нейронная сеть решает, как соединить различные «нейроны» и сколько слоев до модели может предсказать результат. После того как вы определили архитектуру, вам нужно не только обучать модель, но и метрики для вычисления точности прогноза. Этот показатель называется функцией потерь. Цель состоит в том, чтобы минимизировать функцию потерь. Другими словами, это означает, что модель делает меньше ошибок. Все алгоритмы машинного обучения будут повторять вычисления много раз, пока потери не достигнут более плоской линии. Чтобы минимизировать эту функцию потерь, вам нужно определить скорость обучения. это скорость вы хотите, чтобы модель учиться. Если вы установите слишком высокую скорость обучения, модель не успеет что-либо изучить. Это случай на левой картинке. Линия движется вверх и вниз, а это означает, что модель предсказывает с чистым предположением результат. Рисунок справа показывает, что потери уменьшаются в течение итерации, пока кривая не станет плоской, что означает, что модель нашла решение.
Как использовать TensorBoard?
В этом руководстве вы узнаете, как открыть TensorBoard из терминала для MacOS и из командной строки для Windows.
Код будет объяснен в следующем уроке, основное внимание здесь уделено TensorBoard.
Во-первых, вам нужно импортировать библиотеки, которые вы будете использовать во время обучения
Вы создаете данные. Это массив из 10000 строк и 5 столбцов
Вывод
Приведенные ниже коды преобразуют данные и создают модель.
Обратите внимание, что скорость обучения равна 0,1. Если вы измените эту скорость на более высокое значение, модель не найдет решение. Это то, что произошло на левой стороне рисунка выше.
В большинстве учебников по TensorFlow вы будете использовать оценщик TensorFlow. Это TensorFlow API, который содержит все математические вычисления.
Чтобы создать файлы журнала, вам нужно указать путь. Это делается с помощью аргумента model_dir.
![tensorflow]()
Проект TensorFlow масштабнее, чем вам может показаться. Тот факт, что это библиотека для глубинного обучения, и его связь с Гуглом помогли проекту TensorFlow привлечь много внимания. Но если забыть про ажиотаж, некоторые его уникальные детали заслуживают более глубокого изучения:
- Основная библиотека подходит для широкого семейства техник машинного обучения, а не только для глубинного обучения.
- Линейная алгебра и другие внутренности хорошо видны снаружи.
- В дополнение к основной функциональности машинного обучения, TensorFlow также включает собственную систему логирования, собственный интерактивный визуализатор логов и даже мощную архитектуру по доставке данных.
- Модель исполнения TensorFlow отличается от scikit-learn языка Python и от большинства инструментов в R.
Все это круто, но TensorFlow может быть довольно сложным в понимании, особенно для того, кто только знакомится с машинным обучением.
Как работает TensorFlow? Давайте попробуем разобраться, посмотреть и понять, как работает каждая часть. Мы изучим граф движения данных, который определяет вычисления, через которые предстоит пройти вашим данным, поймем, как тренировать модели градиентным спуском с помощью TensorFlow, и как TensorBoard визуализирует работу с TensorFlow. Наши примеры не помогут решать настоящие проблемы машинного обучения промышленного уровня, но они помогут понять компоненты, которые лежат в основе всего, что создано на TensorFlow, в том числе того, что вы напишите в будущем!
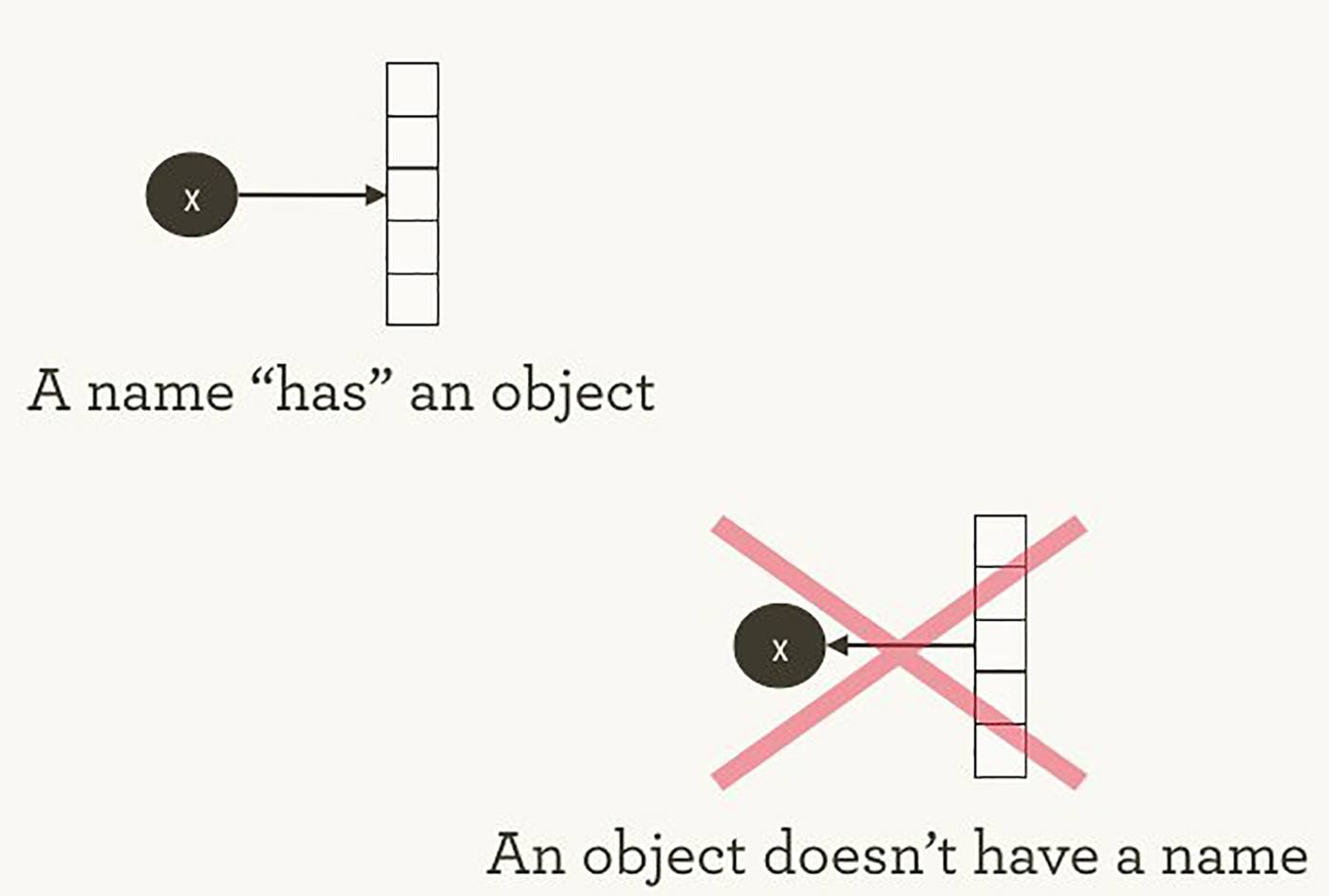
То, как TensorFlow управляет вычислениями, не сильно отличается от того, как это обычно делает Python. В обоих случаях важно помнить, что, перефразируя Хэдли Уикэма, у объекта нет имени (см. изображение 1). Чтобы понять схожие черты и отличия между принципами работы Python и TensorFlow, давайте взглянем на то, как они ссылаются на объекты и обрабатывают вычисление.
![]()
Изображение 1. У имен «есть» объекты, но не наоборот. Иллюстрация Хэдли Уикэма, используется с разрешения автора.
Имена переменных в Python это не то, что они представляют. Они просто указывают на объекты. Так что, когда вы пишете в Python foo = [] и bar = foo , это не значит, что foo равен bar ; foo это bar , в том смысле что они оба указывают на один и тот же объект списка.
Также можно удостовериться, что id(foo) и id(bar) одинаковы. Эта идентичность, особенно с изменяемыми структурами данных вроде списков, может привести к серьезным багам, если понимать ее неправильно.
Внутри Python управляет всеми вашими объектами и следит за именами переменных и за тем, на какой объект каждое имя ссылается. Граф TensorFlow представляет еще один слой такого типа управления. Как мы увидим позже, имена в Python будут ссылаться на объекты, которые соединены с более детальными и более четко управляемыми операциями на графе TensorFlow.
Когда вы вводите выражение на Python, например, в интерактивном интерпретаторе REPL (Read Evaluate Print Loop), всё, что вы набираете почти всегда будет вычислено сразу. Python горит желанием сделать то, что вы ему прикажете. Так что, если я скажу ему сделать foo.append(bar) , он сразу произведет добавление, даже если я никогда не буду использовать foo .
Более ленивая альтернатива — это просто запомнить, что я сказал foo.append(bar) , и, если в какой-то момент в будущем я буду вычислять foo , тогда Python произведет добавление. Это уже ближе к тому, как ведет себя TensorFlow: в нем определение отношения не имеет никакого отношения к вычислению результата.
TensorFlow еще сильнее отделяет определение вычисления от его исполнения, так как они происходят вообще в разных местах: граф определяет операции, но операции происходят только внутри сессий. Графы и сессии создаются независимо друг от друга. Граф — это что-то вроде чертежа, а сессия — это что-то вроде строительной площадки.
Возвращаясь к нашему простому примеру с Python, напомню, что foo и bar указывают на один и тот же список. Добавив bar к foo , мы вставили список внутрь себя. Можно представить себе это как граф с одним узлом, который указывает сам на себя. Вложенные списки — это один из способов представления структуры графа, подобного вычислительному графу TensorFlow.
Настоящие графы TensorFlow будут интереснее!
Чтобы погрузиться в тему, давайте создадим простейший граф TensorFlow с нуля. К счастью, TensorFlow легче установить, чем некоторые другие фреймворки. Пример здесь будет работать с Python 2.7 или 3.3+, и мы используем версию TensorFlow 0.8.
К этому моменту TensorFlow уже начал управлять кучей состояний за нас. К примеру, уже существует явный граф по умолчанию. Внутри граф по умолчанию находится в _default_graph_stack , но у нас нет доступа туда напрямую. Мы используем tf.get_default_graph() .
Узлы графа TensorFlow называются операциями (“operations” или “ops”). Набор операций можно увидеть с помощью graph.get_operations() .
Сейчас в графе пусто. Нам нужно будет добавить туда все, что нужно будет вычислить библиотеке TensorFlow. Давайте начнем с добавления простой константы со значением единицы.
Теперь эта константа существует как узел, операция в графе. Python'овское имя переменной input_value косвенно указывает на эту операцию, но ее также можно найти в графе по умолчанию.
TensorFlow внутри использует формат protocol buffers. (Protocol buffers — это что-то вроде JSON уровня Google). Вывод на экран node_def у константной операции выше показывает, что TensorFlow хранит в представлении protocol buffer для числа один.
Люди, не знакомые с TensorFlow иногда недоумевают, в чем суть создания «TensorFlow-версий» существующих вещей. Почему нельзя просто использовать обычную переменную Python вместо дополнительного определения объекта TensorFlow? В одном из руководств по TensorFlow есть объяснение:
Чтобы производить эффективные численные вычисления в Python, обычно используются библиотеки вроде NumPy, которые совершают такие дорогие операции как перемножение матриц вне Python'а, используя крайне эффективный код, реализованный в другом языке. К сожалению, возникает дополнительная нагрузка при переключении обратно в Python после каждой операции. Эта нагрузка особенно заметна когда нужно производить вычисления на GPU или в распределенном режиме, где передача данных является дорогой операцией.
TensorFlow также производит сложные вычисления вне Python, но он идет еще дальше чтобы избежать дополнительной нагрузки. Вместо того, чтобы запускать одну дорогую операцию независимо от Python, TensorFlow позволяет нам описать граф взаимодействующих операций, которые работают полностью вне Python. Схожий подход используется в Theano и Torch.
TensorFlow умеет делать много крутых штук, но он может работать только с тем, что было явно передано ему. Это справедливо даже для одной константы.
Если взглянуть на наш input_value , то можно увидеть ее как 32-битный тензор нулевого измерения: просто одно число.
Заметьте, что значение не указано. Чтобы вычислить input_value и получить численное значение, нужно создать «сессию», в которой можно вычислять операции графа, а потом явно вычислить или «запустить» input_value . (Сессия использует граф по умолчанию).
Может показаться странным «запускать» константу. Но это не сильно отличается от обычного вычисления выражения в Python. Просто TensorFlow управляет собственным пространством для данных — вычислительным графом, и у него есть свои методы для вычисления.
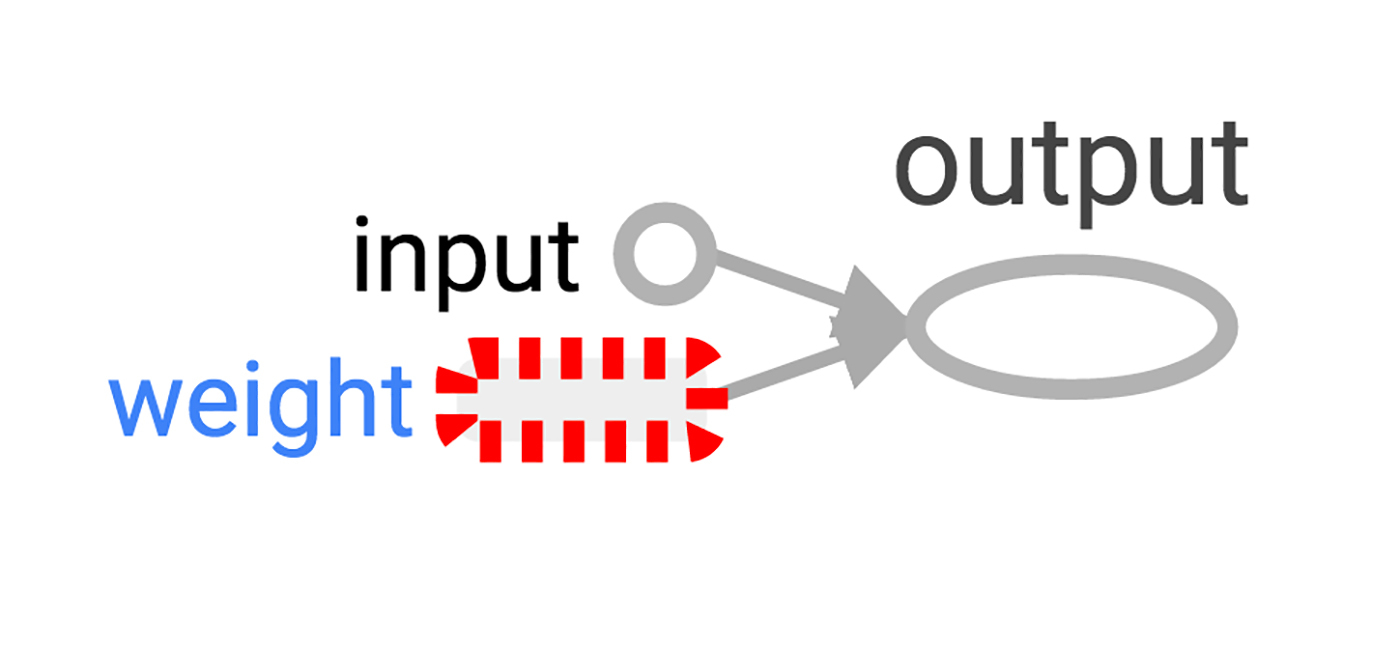
Теперь, когда у нас есть сессия с простым графом, давайте построим нейрон с одним параметром или весом. Зачастую, даже простые нейроны также включают в себя bias term и non-identity activation function, но мы обойдемся без них.
Вес нейрона не будет константным. Мы ожидаем, что он будет меняться при обучении, основываясь на истинности входных и выходных данных, используемых для обучения. Вес будет переменной TensorFlow. Мы дадим ей начальное значение 0.8.
Можно подумать, что добавление переменной добавит операцию в граф, но на самом деле одна эта строчка добавит четыре операции. Можно узнать их имена:
Не хочется слишком долго разбирать каждую операцию "по косточкам", давайте лучше создадим хотя бы одну, похожую на настоящее вычисление:
Теперь в графе шесть операций, и последняя — это перемножение.
Здесь видно, как операция умножения следит за источником входных данных: они приходят из других операций в графе. Человеку довольно сложно следить за всеми связями чтобы понять структуру всего графа. Визуализация графа TensorBoard создана специально для этого.
Как определить результат умножения? Нужно «запустить» операцию output_value . Но эта операция зависит от переменной weight . Мы указали, что начальное значение weight должно быть 0.8, но значение еще не было установлено в текущей сессии. Функция tf.initialize_all_variables() генерирует операцию, которая инициализирует все переменные (в нашем случае только одну), и потом мы можем запустить эту операцию.
Результат выполнения tf.initialize_all_variables() включает инициализаторы для всех переменных, которые находятся в графе на текущий момент, так что если вы добавите новые переменные, то нужно будет запускать tf.initialize_all_variables() заново; простой init не включит новые переменные.
Теперь мы готовы запустить операцию output_value .
Это 0.8 * 1.0 с 32-битными float'ами, а 32-битные float'ы с трудом понимают число 0.8. Значение 0.80000001 это самое близкое, что они смогли сделать.
Наш граф пока еще довольно прост, но уже было бы хорошо увидеть его представление в виде диаграммы. Используем TensorBoard, чтобы сгенерировать такую диаграмму. TensorBoard читает поле имени, которое хранится в каждой операции (это совсем не то же, что имена переменных Python). Можно использовать эти имена TensorFlow и перейти на более привычные имена переменных Python. Использование tf.mul эквивалентно простому умножению с * в примере выше, но здесь можно установить имя для операции.
TensorBoard смотрит в директорию вывода, созданную из сессий TensorFlow. Мы можем писать в этот вывод с помощью SummaryWriter , и, если не делать ничего кроме одного графа, то будет записан только один граф.
Первый аргумент при создании SummaryWriter — это название директории для вывода, которая будет создана при необходимости.
Теперь можно запустить TensorBoard в командной строке.
![]()
Изображение 2. Визуализация TensorBoard простейшего нейрона TensorFlow.
Мы создали нейрон, но как он будет обучаться? Мы установили вводное значение 1.0. Допустим, правильное конечное значение это ноль. То есть у нас есть очень простой набор данных для обучения с одним примером с одной характеристикой: значение равно единице и отметка равна нулю. Мы хотим научить нейрон преобразовывать единицу в ноль.
Сейчас система принимает единицу и возвращает 0.8, что не является корректным поведением. Нужен способ определить, насколько система ошибается. Назовем эту меру ошибочности «потерей» ("loss") и зададим системе цель минимизировать потерю. Если потеря может быть отрицательным числом, то минимизация не имеет смысла, поэтому давайте определим потерю как квадрат разницы между текущем входным значением и желаемым выходным значением.
До этого момента ничто в графе не учится. Для обучения нам нужен оптимизатор. Мы используем функцию градиентного спуска чтобы иметь возможность обновлять вес на основе значения производной потери. Оптимизатору нужно задать уровень обучения для управления размерном обновлений, мы зададим 0.025.
Оптимизатор необыкновенно умен. Он может автоматически определить и использовать нужный градиент на уровне всей сети, производя пошаговое движение назад для обучения.
Взглянем на то, как выглядит градиент для нашего простого примера.
Почему значение градиента 1.6? Значение потери возводится в квадрат, и производная — это ошибка, умноженная на два. Сейчас система возвращает 0.8 вместо 0, так что ошибка это 0.8, и ошибка, умноженная на два — это 1.6. Работает!
В более сложных системах будет особенно полезно, что TensorFlow автоматически вычисляет и применяет эти градиенты за нас.
Давайте применим градиент чтобы закончить обратное распространение.
Вес уменьшился на 0.04 потому что оптимизатор отнял градиент, умноженный на уровень обучения, 1.6 * 0.025, двигая вес в нужную сторону.
Вместо того, чтобы вести оптимизатор за ручку таким образом, можно сделать операцию, которая вычисляет и применяет градиент: train_step .
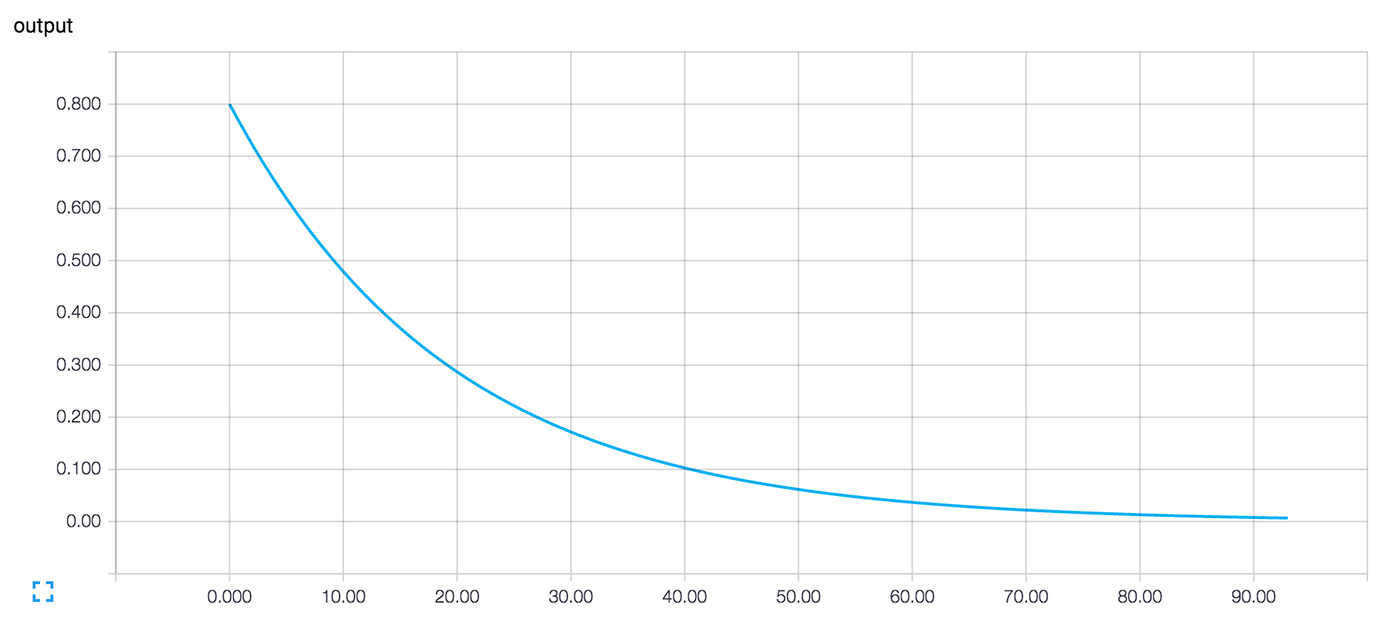
После многократного запуска обучающего шага вес и конечное значение стали очень близки к нулю. Нейрон научился!
Нам может быть интересно, что происходит во время обучения. Например, мы хотим проследить за тем, что система предсказывает на каждом шагу обучения. Можно выводить значение на экран в каждом шаге цикла.
Это сработает, но есть некоторые проблемы. Сложно воспринимать список цифр. График был бы лучше. Даже с одним значением вывода слишком много. А мы скорее всего захотим следить за несколькими значениями. Хорошо бы записывать все более систематично.
К счастью, та же система, что использовалась раньше для визуализации графа, включает в себя нужный нам механизм.
Добавим в вычислительный граф операцию, которая вкратце описывает его состояние. В нашем случае операция докладывает текущее значение y , текущий вывод нейрона.
Запуск этой операции возвращает строку в формате protocol buffer, которую можно записывать в директорию логов с помощью SummaryWriter .
![]()
Изображение 3. Визуализация TensorBoard выходного значения нейрона и номера итерации обучения.
Вот конечная версия кода. Его не так много, и каждая часть показывает полезную (и понятную) функциональность TensorFlow.
Этот пример еще проще, чем примеры из Neural Networks and Deep Learning Майкла Нильсена, которые и послужили вдохновением. Лично мне изучение таких деталей помогает понимать и строить более сложные системы, которые используют простые строительные блоки как основу.
Если хотите продолжить эксперименты с TensorFlow, то советую попробовать сделать более интересные нейроны, например, с другой функцией активации. Можно производить обучение с более интересными данными. Можно добавить больше нейронов. Можно добавить больше слоев. Можно нырнуть в более сложные готовые модели, или провести больше времени за изучением собственных пособий и гайдов TensorFlow. Успехов!
![]()
TensorBoard - это структура визуализации тензорного потока для понимания и проверки потока алгоритма машинного обучения.
Оценка модели машинного обучения может быть выполнена по многим показателям, таким как потери, точность, график модели и многое другое. Производительность алгоритма машинного обучения зависит от выбора модели и гиперпараметров, введенных в алгоритм. Эксперименты выполняются путем изменения значений этих параметров.
Модели глубокого обучения подобны черному ящику, в нем трудно найти обработку. Важно понять, как построить модель. С помощью визуализации вы можете узнать, какие параметры нужно изменить, на какую величину получить улучшение производительности модели. Таким образом, TensorBoard является важным инструментом для визуализации каждой эпохи на этапе обучения модели.
Установка
Чтобы установить тензорную доску с помощью pip, выполните следующую команду:
pip install tensorboard
Кроме того, он может быть установлен с помощью команды conda,
Conda install tensorboard
использование
Использование тензорной доски с моделью Keras:
Keras - это библиотека с открытым исходным кодом для моделей глубокого обучения. Это высокоуровневая библиотека, которую можно запустить поверх tenorflow, theano и т. Д.
Чтобы установить tenorflow и библиотеку Keras с помощью pip:
pip install tensorflow pip install Keras
Давайте рассмотрим простой пример классификации с использованием набора данных MNIST. MNIST - это английский набор цифровых данных, содержащий изображения чисел от 0 до 9. Он доступен с библиотекой Keras.
- Импортируйте тензор потока библиотеки, так как мы будем использовать Keras с бэкэндом тензор потока.
import tensorflow as tf
- Сначала загрузите набор данных MNIST из Keras в набор обучающих и тестовых данных.
![]()
- Последовательная модель создается с использованием,
- Для обучения используется модель Model.fit (). Журналы могут быть созданы и сохранены с использованием,
По умолчанию он выключен.
Код для вышеупомянутой классификации набора данных MNIST выглядит следующим образом:
Чтобы запустить тензорную доску на локальном сервере, перейдите в каталог, где установлен тензорный поток, а затем выполните следующую команду:
![]()
Скаляры
![]()
Скаляры показывают изменения с каждой эпохой. На приведенном выше рисунке показан график точности и потерь после каждой эпохи. Epoch_acc и epoch_loss - это точность обучения и потеря обучения. Тогда как epoch_val_acc и epoch_val_loss - это точность и потеря данных проверки.
Более светлые оранжевые линии показывают точную точность или потерю, а более темные - сглаженные значения. Сглаживание помогает визуализировать общую тенденцию в данных.
диаграммы
Чтобы визуализировать график, нам нужно создать сеанс, а затем объект TensorFLow FileWriter. Чтобы создать объект записи, нам нужно передать путь, где хранится сводка, и sess.graph в качестве аргумента.
writer = tf.summary.FileWriter(STORE_PATH, sess.graph)
tf.placeholder () и tf.Variable () используются для заполнителей и переменных в коде тензорного потока.
![]()
Это показывает графическую визуализацию модели, которую мы построили. Все прямоугольники со скругленными углами являются пространствами имен. А овалы показывают математические операции.
Константы показаны в виде маленьких кружков. Чтобы уменьшить беспорядок в графике, тензорная доска делает некоторые упрощения, используя пунктирные овалы или скругленные прямоугольники с пунктирными линиями. Это узлы, которые связаны со многими другими узлами или со всеми узлами. Таким образом, они хранятся в виде точек на графике, а их детали можно увидеть в правом верхнем углу. В верхнем правом углу указана связь с градиентами, градиентными спусками или узлами инициализации.
![]()
Чтобы узнать количество тензоров, входящих и выходящих из каждого узла, вы можете увидеть ребра на графике. Ребра графа описывают количество тензоров, протекающих в графе. Это помогает идентифицировать входные и выходные размеры каждого узла. Это помогает в отладке любой проблемы.
![]()
Распределения и гистограммы
Это показывает тензорные распределения во времени, а также мы можем видеть веса и смещения. Это показывает прогресс входов и выходов с течением времени для каждой эпохи. Есть два варианта просмотра:
Смещение и наложение.
Смещение гистограммы будет следующим:
![]()
Вид наложения гистограммы:
![]()
![]()
Преимущества
- TensorBoard помогает визуализировать процесс обучения, записывая резюме модели, такие как скаляры, гистограммы или изображения. Это, в свою очередь, помогает повысить точность модели и легко отлаживать.
- Обработка глубокого обучения - это черный ящик, а тензорная доска помогает понять обработку, происходящую в черном ящике, с помощью графиков и гистограмм.
Вывод - TensorBoard
TensorBoards предоставляет визуализацию для модели глубокого заработка, которая обучается и помогает в их понимании. Может использоваться как с TensorFlow, так и с Keras. Он в основном обеспечивает визуализацию поведения скаляров, метрик с помощью гистограмм и графа модели в целом.
Рекомендуемые статьи
Это руководство по TensorBoard. Здесь мы обсуждаем установку и использование Tensboard, используя его с моделью Keras с преимуществами. Вы также можете взглянуть на следующие статьи, чтобы узнать больше -
Читайте также:
- Вычислительная операция Машинного обучения Azure — загрузка или установка не требуется