
Какая кодовая таблица используется в операционной системе windows
Обновлено: 06.07.2024
Кодирование информации на ПК в среде операционной системы Windows — это представление информационных данных в формате последовательно расположенных битов, находящихся в одном из возможных состояний.
Операционная система Windows производит выборку команд программы и информационных данных, подлежащих обработке, из памяти персонального компьютера. Память представляет собой электронный модуль, состоящий из набора микросхем, которые также имеют в своём составе тысячи микроэлементов. Такие микроэлементы способны находиться лишь в двух устойчивых состояниях, условно говоря, «включено» или «выключено». Эти состояния имеют соответствие с бинарной (двоичной) системой счисления, где один бит может быть или нулём, или единицей. То есть, вся информация, расположенная в компьютерной памяти, является последовательностью битов, находящихся в одном из возможных состояний.
Кодирование текстовой информации
Когда текстовая информация вводится в память компьютера, то текстовые символы (буквенные, цифровые, знаковые) подвергаются кодированию при помощи разных систем кодирования, состоящих из разнообразных кодовых таблиц, которые размещены на определённых страницах стандартов кодировки информации в текстовом формате. В данных таблицах все символы имеют некоторый числовой код в шестнадцатеричной или десятичной системе счисления, то есть таблицы кодировки отображают соответствие начертания символов и численными кодами и предназначаются для кодировки и декодирования информации, представленной в текстовом формате.
Когда пользователь вводит текстовую информацию при посредстве компьютерной клавиатуры, то каждый заносимый символ проходит процедуру кодирования, то есть преобразования в численный код. А когда текстовая информация выводится на какое-либо периферийное устройство, к примеру, экран монитора, принтер или МФУ (многофункциональное устройство), то согласно символьному числовому коду осуществляется формирование его изображения. Назначение символу конкретного числового значения получается в результате совместного решения соответствующих организаций различных государств. На сегодняшний день не существует единообразной универсальной кодовой таблицы, которая бы удовлетворяла национальные алфавиты всех государств. Нынешние кодовые таблицы состоят из международной и национальной частей, то есть они включают в себя символы латинского и национального алфавитов, цифровые обозначения, знаки препинания и арифметических операций, управляющие и математические символы, псевдографику. Международный раздел кодовых таблиц, основанный на стандарте ASCII (American Standard Code for Information Interchange), определяет коды первой половины символов кодовой таблицы и занимает числовое пространство от нуля до 127 (7F в шестнадцатеричной системе). Следует заметить, что числа от нуля до 32 (то есть 20 в шестнадцатеричной системе) отводятся под кодирование функциональных клавиш (F1, F2, F3 и так далее) на клавиатуре компьютера. На рисунке ниже представлена кодовая таблица международной части, базирующаяся на стандарте ASCII, в десятичной системе счисления:
Готовые работы на аналогичную тему
Получить выполненную работу или консультацию специалиста по вашему учебному проекту Узнать стоимость
Рисунок 1. Кодовая таблица. Автор24 — интернет-биржа студенческих работ
И та же таблица, но в шестнадцатеричной системе счисления:

Рисунок 2. Кодовая таблица. Автор24 — интернет-биржа студенческих работ
Национальный раздел кодовых таблиц состоит из кодов национальных алфавитов, который именую также таблицей символьных наборов. На сегодняшний день есть несколько кодовых таблиц, поддерживающих символы русского алфавита (кириллица), используемых разными операционными системами. Это безусловно считается определённым недостатков и иногда может вызывать проблемы, которые сопряжены с процедурами декодирования численных величин символов. В таблице на рисунке ниже показаны наименования кодовых страниц, где имеются кириллические кодировки:

Рисунок 3. Наименования кодовых страниц, где имеются кириллические кодировки. Автор24 — интернет-биржа студенческих работ

Рисунок 4. Кодовая таблица. Автор24 — интернет-биржа студенческих работ
Сегодня для кодирования кириллического алфавита чаще всего используется кодовая таблица, входящая в страницу стандарта СР1251, которая применяется в семействе операционных систем Windows корпорации Microsoft. Данная таблица изображена на рисунке ниже:

Рисунок 5. Кодовая таблица. Автор24 — интернет-биржа студенческих работ
Все представленные кодовые таблицы, в отличие от стандарта Unicode, используют восьми битную систему кодировки одного символа. Стандарт Unicode был разработан в конце двадцатого века и в нём была применена система кодирования одного символа двумя байтами. Использование данного стандарта явилось продолжением проектирования универсального мирового стандарта, который позволяет разрешить проблему совместимости национальных кодовых таблиц символов. При помощи этого стандарта появилась возможность кодирования $2^ = 65536$ разных символьных знаков.
Кодирование графической информации
Информация в графическом формате, то есть это рисунки, фотографии, слайды, видео и так далее, может формироваться и подвергаться корректированию при помощи компьютера, но при этом она должна быть соответственно закодирована. Сегодня разработано много прикладных программ, работающих под управлением операционной системы Windows разных модификаций, способных выполнять обработку графических объектов, но все эти приложения базируются на трёх типах компьютерной графики, а именно это:
- Растровый тип графики.
- Векторный графический тип.
- Фрактальный тип графики.
При пристальном рассмотрении графического изображения на экране дисплея компьютера, можно заметить огромное число точек разных цветов, то есть пикселей (от английского pixel, являющего сокращением от picture element, то есть элемент изображения), которые и формируют все вместе видимую графическую картинку.
Отсюда проистекает следующий вывод, что все графические компьютерные изображения кодируются заданным методом и могут быть представлены в формате графического файла. Файл считается главной структурной составляющей организации и хранения информационных данных в памяти компьютера.
Кодовые страницы Windows - это наборы символов или кодовых страниц (известные как кодировки символов в других операционных системах), используемые в Microsoft Windows с 1980-х и 1990-х годов. Кодовые страницы Windows постепенно вытеснялись, когда Unicode был реализован в Windows , хотя они по-прежнему поддерживаются как в Windows, так и на других платформах, и по-прежнему применяются при использовании сочетаний клавиш Alt .
В системах Windows существует две группы кодовых страниц: OEM и собственные кодовые страницы Windows («ANSI»). Кодовые страницы в обеих этих группах являются расширенными кодовыми страницами ASCII .
СОДЕРЖАНИЕ
Кодовая страница ANSI
Кодовые страницы ANSI (официально называемые «кодовыми страницами Windows» после того, как Microsoft приняла неправильное употребление первого термина) используются для приложений, не поддерживающих Unicode (скажем, ориентированных на байты ), использующих графический пользовательский интерфейс в системах Windows. Термин «ANSI» является неправильным, потому что эти кодовые страницы Windows не соответствуют ни одному стандарту ANSI; Кодовая страница 1252 была основана на раннем проекте ANSI, который стал международным стандартом ISO 8859-1 , который добавляет еще 32 управляющих кода и пространство для 96 печатаемых символов. Среди других отличий кодовые страницы Windows выделяют печатаемые символы в дополнительное пространство управляющего кода, что делает их в лучшем случае неразборчивыми для совместимых со стандартами операционных систем.)
Большинство устаревших кодовых страниц "ANSI" имеют номера кодовых страниц в шаблоне 125x. Тем не менее, 874 (тайский) и восточноазиатские многобайтовые кодовые страницы ANSI ( 932 , 936 , 949 , 950 ), все из которых также используются в качестве кодовых страниц OEM, пронумерованы для соответствия аналогичным (но не идентичным) кодовым страницам IBM. кодировки. Хотя кодовая страница 1258 также используется как кодовая страница OEM, она является оригинальной для Microsoft, а не расширением существующей кодировки. IBM присвоила свои собственные, разные номера вариантам Microsoft, они приведены для справки в приведенных ниже списках, где это применимо.
Все кодовые страницы Windows 125x, а также 874 и 936, помечены Internet Assigned Numbers Authority (IANA) как « номер Windows», хотя «Windows-936» рассматривается как синоним « GBK ». Кодовая страница Windows 932 вместо этого помечена как «Windows-31J».
Кодовые страницы ANSI Windows, и особенно кодовая страница 1252 , были так названы, поскольку они якобы были основаны на черновиках, представленных или предназначенных для ANSI. Однако ANSI и ISO не стандартизировали ни одну из этих кодовых страниц. Вместо этого они либо:
- Надмножества стандартных наборов, таких как ISO 8859 и различных национальных стандартов (например, Windows-1252 и ISO-8859-1 ),
- Основные их модификации (делающие их несовместимыми в разной степени, например, Windows-1250 и ISO-8859-2 )
- Отсутствие параллельного кодирования (например, Windows-1257 против ISO-8859-4 ; ISO-8859-13 был введен намного позже). Кроме того, Windows-1251 не следует ни ISO-стандартизированному ISO-8859-5, ни преобладающему в то время KOI-8 .
Microsoft присвоила около двенадцати типографских и деловых символов (включая, в частности, знак евро , €) в CP1252 кодовые точки 0x80–0x9F, которые в ISO 8859 присвоены управляющим кодам C1 . Эти назначения также присутствуют во многих других кодовых страницах ANSI / Windows в тех же кодовых точках. Windows не использовала управляющие коды C1, поэтому это решение не имело прямого влияния на пользователей Windows. Однако при включении в файл, передаваемый на совместимую со стандартами платформу, такую как Unix или MacOS, информация была невидимой и потенциально опасной.
Кодовая страница OEM
В кодовые страницы OEM ( Original Equipment Manufacturer ) используются консольных Win32 приложений и виртуальной DOS , и может рассматриваться как пережиток от DOS и оригинальной IBM PC архитектуры. Отдельный набор кодовых страниц был реализован не только из-за совместимости, но и потому, что шрифты аппаратного обеспечения VGA (и его потомков) предполагают кодирование символов рисования линий для совместимости с кодовой страницей 437 . Большинство кодовых страниц OEM имеют много общих кодовых точек, особенно для небуквенных символов, со второй (не-ASCII) половиной CP437.
Типичная кодовая страница OEM во второй половине даже приблизительно не похожа ни на одну кодовую страницу ANSI / Windows. Тем не менее, две однобайтовые кодовые страницы фиксированной ширины (874 для тайского языка и 1258 для вьетнамского ) и четыре многобайтовых кодовых страницы CJK ( 932 , 936 , 949 , 950 ) используются как кодовые страницы OEM и ANSI. Кодовая страница 1258 использует комбинированные диакритические знаки , поскольку вьетнамский требует более 128 буквенно-диакритических комбинаций. Это отличается от VISCII , который заменяет некоторые управляющие коды C0 (т.е. ASCII).
История
Первоначально компьютерные системы и языки системного программирования не делали различия между символами и байтами : для сегментарных сценариев, используемых в большей части Африки, Америки, Южной и Юго-Восточной Азии, Ближнего Востока и Европы, для символа требуется всего один байт. , но два или более байта необходимы для идеографических наборов, используемых в остальном мире. Впоследствии это привело к большой путанице. Программное обеспечение и системы Microsoft, предшествующие линейке Windows NT, являются примерами этого, поскольку они используют кодовые страницы OEM и ANSI, которые не делают различий.
С конца 1990-х годов программное обеспечение и системы приняли Unicode в качестве предпочтительного формата хранения; эта тенденция была улучшена благодаря широкому распространению XML , который обеспечивает более адекватный механизм для маркировки используемой кодировки. Последние продукты Microsoft и интерфейсы прикладных программ используют Unicode внутри, но многие приложения и API продолжают использовать кодировку по умолчанию «локали» компьютера при чтении и записи текстовых данных в файлы или стандартный вывод. Таким образом, файлы могут быть разборчивыми и разборчивыми в одной части мира, а моджибаке - в другой - неразборчивыми .
UTF-8, UTF-16
Microsoft решила принять 16-битную (двухбайтовую) систему UTF-16 для всех своих операционных систем, начиная с Windows NT. Этот метод однозначно кодирует все символы Unicode в базовой многоязычной плоскости и 32-битный (четырехбайтовый) код для других, но остальная часть отрасли ( Unix-подобные системы и Интернет) выбрали UTF-8 (который использует один байт для 7-битный набор символов ASCII , два или три байта для других символов в BMP и четыре байта для остатка). Начиная с Windows 10 версии 1803 , компьютеры с Windows можно настроить так, чтобы разрешить UTF-8 в качестве кодовой страницы «ANSI» и OEM.
Список
Существуют следующие кодовые страницы Windows:
Windows-125x серии
Кодовые страницы DOS
Они также основаны на ASCII. Большинство из них включены для использования в качестве кодовых страниц OEM; кодовая страница 874 также используется как кодовая страница ANSI.
Многобайтовые кодовые страницы Восточной Азии
Часто они лишь частично совпадают с кодовыми страницами IBM с одним и тем же номером: кодовые страницы 932, 936 и 949 отличаются от кодовых страниц IBM с тем же номером, тогда как Windows-951, как часть кладжа , не связана с IBM-951. Эквивалентные кодовые страницы IBM приведены во втором столбце. Кодовые страницы 932, 936, 949 и 950/951 используются в качестве кодовых страниц как ANSI, так и OEM для рассматриваемых локалей.
| Я БЫ | Эквивалент IBM | Язык | Кодирование | Использовать |
|---|---|---|---|---|
| 932 | 943 | Японский | Shift JIS (вариант Microsoft) | ANSI / OEM (Япония) |
| 936 | 1386 | Упрощенный китайский) | ГБК | ANSI / OEM (КНР, Сингапур) |
| 949 | 1363 | Корейский | Единый код хангыля | ANSI / OEM (Республика Корея) |
| 950 | 1370, 1373 | Китайский традиционный) | Big5 (вариант Microsoft) | ANSI / OEM (Тайвань, Гонконг) |
| 951 | 5471 | Китайский традиционный) | Big5-HKSCS (изд. 2001 г.) | ANSI / OEM (Гонконг, 98 / NT4 / 2000 / XP с патчем HKSCS) |
Еще несколько многобайтовых кодовых страниц поддерживаются для декодирования или кодирования с использованием библиотек операционной системы, но не используются в качестве системного кодирования ни в одной локали.
Кодовые страницы EBCDIC
Кодовые страницы, связанные с Unicode
- 1200 - Юникод (BMP по ISO 10646, UTF-16LE ). Доступно только для управляемых приложений
- 1201 - Юникод ( UTF-16BE ). Доступно только для управляемых приложений
- 12000 - UTF-32 . Доступно только для управляемых приложений
- 12001 - UTF-32 . С прямым порядком байтов. Доступно только для управляемых приложений
- 65000 - Юникод ( UTF-7 )
- 65001 - Юникод ( UTF-8 )
Кодовые страницы совместимости с Macintosh
- 10000 - Apple Macintosh Роман
- 10001 - Apple Macintosh на японском языке
- 10002 - Apple Macintosh Chinese (традиционный) (BIG-5)
- 10003 - Apple Macintosh корейский
- 10004 - Apple Macintosh на арабском языке
- 10005 - Apple Macintosh на иврите
- 10006 - Apple Macintosh греческий
- 10007 - кириллица Apple Macintosh
- 10008 - Apple Macintosh китайский (упрощенный) (GB 2312)
- 10010 - Apple Macintosh на румынском языке
- 10017 - Apple Macintosh украинский
- 10021 - Apple Macintosh Thai
- 10029 - Apple Macintosh Roman II / Центральная Европа
- 10079 - Исландский Apple Macintosh
- 10081 - Apple Macintosh Турецкий
- 10082 - Apple Macintosh Хорватский
Кодовые страницы ISO 8859
Кодовые страницы ITU-T
- 20105 - 7-битный IA5IRV (западноевропейский)
- 20106 - 7-битный IA5 немецкий (DIN 66003)
- 20107 - 7-битный IA5 шведский (SEN 850200 C)
- 20108 - 7-битный норвежский IA5 (NS 4551-2)
- 20127 - 7-битный US-ASCII
- 20261 - T.61 (T.61-8bit)
- 20269 - ISO-6937
Кодовые страницы KOI8
Проблемы, возникающие при использовании кодовых страниц
Microsoft настоятельно рекомендует использовать Unicode в современных приложениях, но многие приложения или файлы данных по-прежнему зависят от устаревших кодовых страниц.

Таблица кодов символов в современных компьютерах может быть использована любым юзером. Что это такое? И где найти подобный элемент? Как им пользоваться и для каких целей? Далее постараемся дать ответы на все перечисленные вопросы. Обычно таблицы символов позволяют печатать уникальные знаки в текстовых документов. Главное - знать, какими они бывают, а также где искать соответствующую информацию. Все намного проще, чем кажется.
Определение
Что такое таблица кодов символов? Это, как нетрудно догадаться, база данных. В ней пользователи могут увидеть сочетание числовых значений, при обработке которых в указанное место текста вставляется символ. Например, знак ♥ или ♫. На клавиатуре таких символов нет и быть не может.
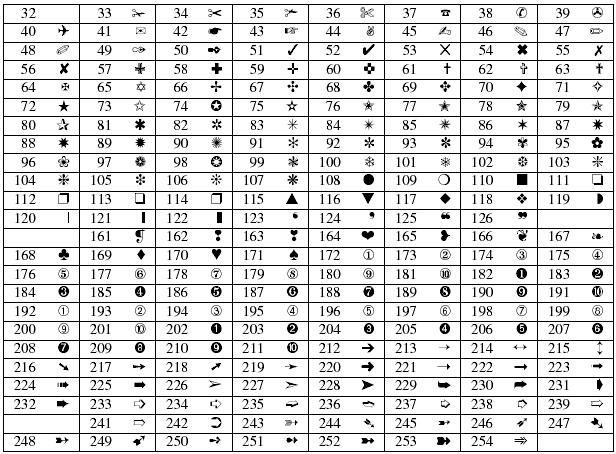
Таблица символов помогает пользователям вставлять уникальные знаки в текстовые документы. Здесь можно увидеть кодировку элемента и способ его интерпретации.
Какими бывают
Кодировки символов - тип сочетания букв, цифр и знаков, которые после обработки операционной системой преобразовываются в знак. Они бывают разными.
Сегодня можно столкнуться с такими кодировками:
- ASCII - способ печати специальных знаков, уникальные коды которых представлены цифрами. Это самый распространенный тип кодировки. Он был разработан в 1963 году в США. Кодировка является семибитной.
- Windows-1251 - стандартная кодировка для русскоязычной "Виндовс". Она не слишком обширна и почти не пользуется спросом у юзеров.
- Unicode - 16-битная кодировка для современных операционных систем. Она служит для представления символов и букв на любом языке. Используется современными пользователями наравне с ASCII.
Теперь понятно, какими бывают кодировки. Заострим внимание на первом и последнем варианте. Они пользуются самым большим спросом у современных пользователей ПК.
Где искать в Windows
Таблицы кодов символов по умолчанию вмонтированы в операционную систему "Виндовс". С их помощью юзер сможет печатать буквы и специальные знаки в любом текстовом редакторе или документе.
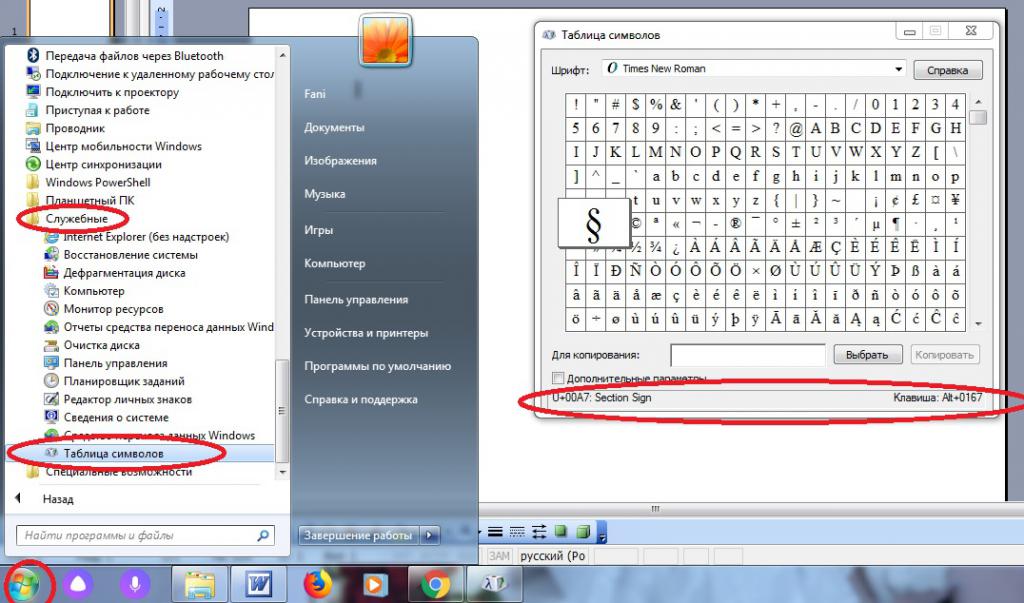
Для того, чтобы найти таблицу символов в "Виндовс", нужно:
- Открыть пункт меню "Пуск".
- Развернуть раздел "Все программы".
- Выбрать папку "Стандартные"
- Кликнуть по надписи "Служебные".
- Заглянуть в приложение "Таблица символов".
Дело сделано. Теперь можно изучить все возможные знаки, которые только могут восприниматься операционной системой. Если дважды кликнуть по миниатюре того или иного символа, а затем щелкнуть по кнопке "Скопировать", соответствующий знак будет перенесен в буфер обмена. Из него можно выгрузить данные в текстовый документ.
Важно: в нижней части окна справа можно увидеть сочетание клавиш для быстрой печати выбранного элемента, а слева - "Юникод" для набора в тексте.
В MS Word
Таблицу кодов символов можно найти даже в текстовых редакторах. Рассмотрим алгоритм действий в MS Word. Это наиболее популярная и распространенная утилита для работы с документами в "Виндовс".
Открытие таблицы кодов символов осуществляется так:
- Зайти в Word на компьютере. Можно открыть как пустой документ, так и с текстом.
- Нажать в верхней части она по пункту "Вставка". Желательно развернуть весь список опций.
- Навести курсор и щелкнуть ЛКМ по надписи "Специальный знак. ".
Вот и все. По центру экрана появится таблица символов. Здесь можно посмотреть таблицу ASCII, "Юникода" и не только. Для этого в нижней части окна в выпадающем списке нужно выбрать после надписи "из. " подходящую кодировку.
Вставка знака может осуществляться через двойной клик по элементу в таблице или путем активации кнопки "Вставить".
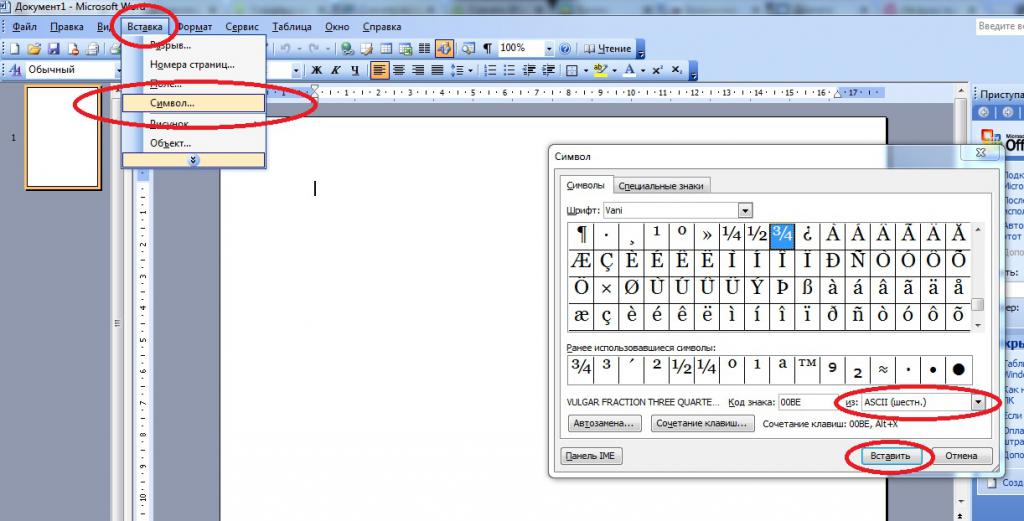
Способы обработки кода
Как мы уже говорили, таблица кодов символов помогает изучить цифро-алфавитный код того или иного символа. Как можно провести преобразование оных?
Как правило, "Юникод" обрабатывается следующим образом:
- Пользователь пишет уникальный код подходящего символа. Обычно он начинается с U+.
- Юзер нажимает сочетание клавиш Alt + X в текстовом редакторе.
- Операционная система считывает код, после чего на месте записи появляется специальный знак.
Коды обрабатываются по одному. Это крайне важно. ASCII обрабатываются аналогичным образом.
Некоторые символы можно напечатать при помощи кнопки Alt. Обычно ее нужно зажать, а затем на цифирной панели клавиатуры набрать подходящий код. В этом случае придется заранее активировать режим Num Lock.
Кодовые страницы Windows - это наборы символов или кодовых страниц (известные как кодировки символов в других операционных системах), используемые в Microsoft Windows с 1980-х и 1990-х годов. Кодовые страницы Windows постепенно вытеснялись, когда Unicode был реализован в Windows , хотя они по-прежнему поддерживаются как в Windows, так и на других платформах, и по-прежнему применяются при использовании сочетаний клавиш Alt .
В системах Windows существует две группы кодовых страниц: OEM и собственные кодовые страницы Windows («ANSI»). Кодовые страницы в обеих этих группах являются расширенными кодовыми страницами ASCII .
СОДЕРЖАНИЕ
Кодовая страница ANSI
Кодовые страницы ANSI (официально называемые «кодовыми страницами Windows» после того, как Microsoft приняла неправильное употребление первого термина) используются для приложений, не поддерживающих Unicode (скажем, ориентированных на байты ), использующих графический пользовательский интерфейс в системах Windows. Термин «ANSI» является неправильным, потому что эти кодовые страницы Windows не соответствуют ни одному стандарту ANSI; Кодовая страница 1252 была основана на раннем проекте ANSI, который стал международным стандартом ISO 8859-1 , который добавляет еще 32 управляющих кода и пространство для 96 печатаемых символов. Среди других отличий кодовые страницы Windows выделяют печатаемые символы в дополнительное пространство управляющего кода, что делает их в лучшем случае неразборчивыми для совместимых со стандартами операционных систем.)
Большинство устаревших кодовых страниц "ANSI" имеют номера кодовых страниц в шаблоне 125x. Тем не менее, 874 (тайский) и восточноазиатские многобайтовые кодовые страницы ANSI ( 932 , 936 , 949 , 950 ), все из которых также используются в качестве кодовых страниц OEM, пронумерованы для соответствия аналогичным (но не идентичным) кодовым страницам IBM. кодировки. Хотя кодовая страница 1258 также используется как кодовая страница OEM, она является оригинальной для Microsoft, а не расширением существующей кодировки. IBM присвоила свои собственные, разные номера вариантам Microsoft, они приведены для справки в приведенных ниже списках, где это применимо.
Все кодовые страницы Windows 125x, а также 874 и 936, помечены Internet Assigned Numbers Authority (IANA) как « номер Windows», хотя «Windows-936» рассматривается как синоним « GBK ». Кодовая страница Windows 932 вместо этого помечена как «Windows-31J».
Кодовые страницы ANSI Windows, и особенно кодовая страница 1252 , были так названы, поскольку они якобы были основаны на черновиках, представленных или предназначенных для ANSI. Однако ANSI и ISO не стандартизировали ни одну из этих кодовых страниц. Вместо этого они либо:
- Надмножества стандартных наборов, таких как ISO 8859 и различных национальных стандартов (например, Windows-1252 и ISO-8859-1 ),
- Основные их модификации (делающие их несовместимыми в разной степени, например, Windows-1250 и ISO-8859-2 )
- Отсутствие параллельного кодирования (например, Windows-1257 против ISO-8859-4 ; ISO-8859-13 был введен намного позже). Кроме того, Windows-1251 не следует ни ISO-стандартизированному ISO-8859-5, ни преобладающему в то время KOI-8 .
Microsoft присвоила около двенадцати типографских и деловых символов (включая, в частности, знак евро , €) в CP1252 кодовые точки 0x80–0x9F, которые в ISO 8859 присвоены управляющим кодам C1 . Эти назначения также присутствуют во многих других кодовых страницах ANSI / Windows в тех же кодовых точках. Windows не использовала управляющие коды C1, поэтому это решение не имело прямого влияния на пользователей Windows. Однако при включении в файл, передаваемый на совместимую со стандартами платформу, такую как Unix или MacOS, информация была невидимой и потенциально опасной.
Кодовая страница OEM
В кодовые страницы OEM ( Original Equipment Manufacturer ) используются консольных Win32 приложений и виртуальной DOS , и может рассматриваться как пережиток от DOS и оригинальной IBM PC архитектуры. Отдельный набор кодовых страниц был реализован не только из-за совместимости, но и потому, что шрифты аппаратного обеспечения VGA (и его потомков) предполагают кодирование символов рисования линий для совместимости с кодовой страницей 437 . Большинство кодовых страниц OEM имеют много общих кодовых точек, особенно для небуквенных символов, со второй (не-ASCII) половиной CP437.
Типичная кодовая страница OEM во второй половине даже приблизительно не похожа ни на одну кодовую страницу ANSI / Windows. Тем не менее, две однобайтовые кодовые страницы фиксированной ширины (874 для тайского языка и 1258 для вьетнамского ) и четыре многобайтовых кодовых страницы CJK ( 932 , 936 , 949 , 950 ) используются как кодовые страницы OEM и ANSI. Кодовая страница 1258 использует комбинированные диакритические знаки , поскольку вьетнамский требует более 128 буквенно-диакритических комбинаций. Это отличается от VISCII , который заменяет некоторые управляющие коды C0 (т.е. ASCII).
История
Первоначально компьютерные системы и языки системного программирования не делали различия между символами и байтами : для сегментарных сценариев, используемых в большей части Африки, Америки, Южной и Юго-Восточной Азии, Ближнего Востока и Европы, для символа требуется всего один байт. , но два или более байта необходимы для идеографических наборов, используемых в остальном мире. Впоследствии это привело к большой путанице. Программное обеспечение и системы Microsoft, предшествующие линейке Windows NT, являются примерами этого, поскольку они используют кодовые страницы OEM и ANSI, которые не делают различий.
С конца 1990-х годов программное обеспечение и системы приняли Unicode в качестве предпочтительного формата хранения; эта тенденция была улучшена благодаря широкому распространению XML , который обеспечивает более адекватный механизм для маркировки используемой кодировки. Последние продукты Microsoft и интерфейсы прикладных программ используют Unicode внутри, но многие приложения и API продолжают использовать кодировку по умолчанию «локали» компьютера при чтении и записи текстовых данных в файлы или стандартный вывод. Таким образом, файлы могут быть разборчивыми и разборчивыми в одной части мира, а моджибаке - в другой - неразборчивыми .
UTF-8, UTF-16
Microsoft решила принять 16-битную (двухбайтовую) систему UTF-16 для всех своих операционных систем, начиная с Windows NT. Этот метод однозначно кодирует все символы Unicode в базовой многоязычной плоскости и 32-битный (четырехбайтовый) код для других, но остальная часть отрасли ( Unix-подобные системы и Интернет) выбрали UTF-8 (который использует один байт для 7-битный набор символов ASCII , два или три байта для других символов в BMP и четыре байта для остатка). Начиная с Windows 10 версии 1803 , компьютеры с Windows можно настроить так, чтобы разрешить UTF-8 в качестве кодовой страницы «ANSI» и OEM.
Список
Существуют следующие кодовые страницы Windows:
Windows-125x серии
Кодовые страницы DOS
Они также основаны на ASCII. Большинство из них включены для использования в качестве кодовых страниц OEM; кодовая страница 874 также используется как кодовая страница ANSI.
Многобайтовые кодовые страницы Восточной Азии
Часто они лишь частично совпадают с кодовыми страницами IBM с одним и тем же номером: кодовые страницы 932, 936 и 949 отличаются от кодовых страниц IBM с тем же номером, тогда как Windows-951, как часть кладжа , не связана с IBM-951. Эквивалентные кодовые страницы IBM приведены во втором столбце. Кодовые страницы 932, 936, 949 и 950/951 используются в качестве кодовых страниц как ANSI, так и OEM для рассматриваемых локалей.
| Я БЫ | Эквивалент IBM | Язык | Кодирование | Использовать |
|---|---|---|---|---|
| 932 | 943 | Японский | Shift JIS (вариант Microsoft) | ANSI / OEM (Япония) |
| 936 | 1386 | Упрощенный китайский) | ГБК | ANSI / OEM (КНР, Сингапур) |
| 949 | 1363 | Корейский | Единый код хангыля | ANSI / OEM (Республика Корея) |
| 950 | 1370, 1373 | Китайский традиционный) | Big5 (вариант Microsoft) | ANSI / OEM (Тайвань, Гонконг) |
| 951 | 5471 | Китайский традиционный) | Big5-HKSCS (изд. 2001 г.) | ANSI / OEM (Гонконг, 98 / NT4 / 2000 / XP с патчем HKSCS) |
Еще несколько многобайтовых кодовых страниц поддерживаются для декодирования или кодирования с использованием библиотек операционной системы, но не используются в качестве системного кодирования ни в одной локали.
Кодовые страницы EBCDIC
Кодовые страницы, связанные с Unicode
- 1200 - Юникод (BMP по ISO 10646, UTF-16LE ). Доступно только для управляемых приложений
- 1201 - Юникод ( UTF-16BE ). Доступно только для управляемых приложений
- 12000 - UTF-32 . Доступно только для управляемых приложений
- 12001 - UTF-32 . С прямым порядком байтов. Доступно только для управляемых приложений
- 65000 - Юникод ( UTF-7 )
- 65001 - Юникод ( UTF-8 )
Кодовые страницы совместимости с Macintosh
- 10000 - Apple Macintosh Роман
- 10001 - Apple Macintosh на японском языке
- 10002 - Apple Macintosh Chinese (традиционный) (BIG-5)
- 10003 - Apple Macintosh корейский
- 10004 - Apple Macintosh на арабском языке
- 10005 - Apple Macintosh на иврите
- 10006 - Apple Macintosh греческий
- 10007 - кириллица Apple Macintosh
- 10008 - Apple Macintosh китайский (упрощенный) (GB 2312)
- 10010 - Apple Macintosh на румынском языке
- 10017 - Apple Macintosh украинский
- 10021 - Apple Macintosh Thai
- 10029 - Apple Macintosh Roman II / Центральная Европа
- 10079 - Исландский Apple Macintosh
- 10081 - Apple Macintosh Турецкий
- 10082 - Apple Macintosh Хорватский
Кодовые страницы ISO 8859
Кодовые страницы ITU-T
- 20105 - 7-битный IA5IRV (западноевропейский)
- 20106 - 7-битный IA5 немецкий (DIN 66003)
- 20107 - 7-битный IA5 шведский (SEN 850200 C)
- 20108 - 7-битный норвежский IA5 (NS 4551-2)
- 20127 - 7-битный US-ASCII
- 20261 - T.61 (T.61-8bit)
- 20269 - ISO-6937
Кодовые страницы KOI8
Проблемы, возникающие при использовании кодовых страниц
Microsoft настоятельно рекомендует использовать Unicode в современных приложениях, но многие приложения или файлы данных по-прежнему зависят от устаревших кодовых страниц.
Читайте также: